29 nov. 2025·8 min
Hur du bygger en webbapp för att hantera kundfeedback‑loopar
Lär dig hur du designar och bygger en webbapp som samlar in, routar, spårar och stänger kundfeedback‑loopar med tydliga workflows, roller och mätvärden.
Lär dig hur du designar och bygger en webbapp som samlar in, routar, spårar och stänger kundfeedback‑loopar med tydliga workflows, roller och mätvärden.
En app för feedbackhantering är inte "en plats att lagra meddelanden." Det är ett system som hjälper ditt team att pålitligt gå från input till action till kundsynlig uppföljning, och sedan lära sig av vad som hände.
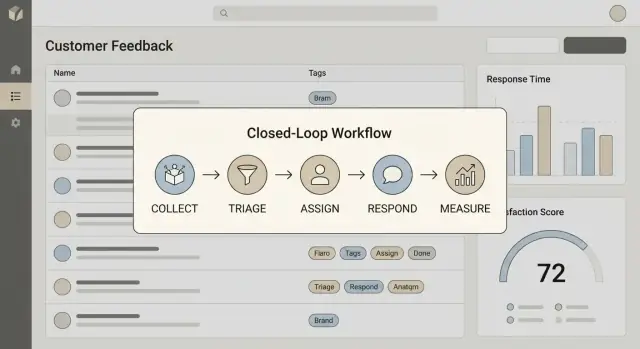
Skriv en mening som ditt team kan upprepa. För de flesta team innebär att stänga loopen fyra steg:
Om något av dessa steg saknas kommer din app att bli en gravplats för backlogg.
Din första version bör tjäna verkliga dagliga roller:
Var specifik om "beslut per klick":
Välj en liten uppsättning mått som speglar hastighet och kvalitet, t.ex. time to first response, resolution rate och CSAT‑förändring efter uppföljning. Dessa blir er ledstjärna för senare designval.
Innan du designar skärmar eller väljer databas, kartlägg vad som händer med feedback från det att den skapas tills ni svarar. En enkel journey‑karta håller teamen enade om vad "klart" betyder och förhindrar att ni bygger funktioner som inte passar verkligt arbete.
Lista era feedbackkällor och notera vilken data varje källa pålitligt ger:
Även om input skiljer sig åt bör din app normalisera dem till en konsekvent "feedback item"‑form så att team kan triagera allt på ett ställe.
En praktisk första modell brukar inkludera:
Statusar att börja med: New → Triaged → Planned → In Progress → Shipped → Closed. Skriv ner vad status betyder så att "Planned" inte betyder "kanske" för ett team och "begånget" för ett annat.
Dubbletter är oundvikliga. Definiera regler tidigt:
Ett vanligt tillvägagångssätt är att behålla en kanonisk feedback item och länka andra som dubbletter, bevara attribution (vem frågade) utan att fragmentera arbetet.
En feedback‑loop‑app lyckas eller misslyckas på dag ett baserat på om folk kan bearbeta feedback snabbt. Sikta på ett flöde som känns som: "skumma igenom → bestäm → gå vidare", samtidigt som kontext bevaras för senare beslut.
Inboxen är teamets delade kö. Den bör stödja snabb triage genom ett litet set kraftfulla filter:
Lägg till "Sparade vyer" tidigt (även om de är enkla), eftersom olika team skummar olika: Support vill ha "urgent + paying", Produkt vill ha "feature requests + high ARR".
När en användare öppnar en item ska hen se:
Målet är att undvika att byta flikar för att svara på: "Vem är detta, vad menade de, och har vi redan svarat?"
Från detaljvyn bör triage vara ett klick per beslut:
Ni kommer troligen behöva två lägen:
Oavsett vad ni väljer, gör "svara med kontext" till sista steget—så att att stänga loopen är en del av workflowen, inte en eftertanke.
En feedback‑app blir snabbt ett gemensamt register: produkt vill ha teman, support vill svara snabbt och ledning vill ha export. Om ni inte definierar vem som kan göra vad (och bevisa vad som hände) bryts tilliten.
Om ni ska serva flera företag, behandla varje workspace/org som en hård gräns från dag ett. Varje kärnpost (feedback item, customer, konversation, taggar, rapporter) bör innehålla en workspace_id, och varje fråga bör scoperas till den.
Detta är inte bara en databasdetalj—det påverkar URL:er, inbjudningar och analys. Ett säkert standardval: användare tillhör en eller flera workspaces, och deras behörigheter utvärderas per workspace.
Håll första versionen enkel:
Kartlägg sedan behörigheter till åtgärder, inte skärmar: visa vs redigera feedback, mergea dubbletter, ändra status, exportera data och skicka svar. Det gör det enkelt att lägga till en "Read‑only"‑roll senare utan att skriva om allt.
En audit‑logg förhindrar "vem ändrade detta?"‑debatter. Logga nyckelhändelser med aktör, tidsstämpel och före/efter när det är hjälpsamt:
Tvinga en rimlig lösenordspolicy, skydda endpoints med rate limiting (särskilt login och ingestion) och säkra sessionhantering.
Designa med SSO (SAML/OIDC) i åtanke även om ni släpper det senare: spara en identity provider‑id och planera för kontolänkning. Det hindrar att enterprise‑förfrågningar tvingar fram en smärtsam refaktor.
Tidigt är den största arkitekturrisken inte "kommer det att skalas?" utan "kommer vi kunna ändra det snabbt utan att bryta saker?" En feedback‑app utvecklas snabbt när ni lär er hur team faktiskt triagerar, routar och svarar.
En modulär monolit är ofta bästa första valet. Ni får en deploybar tjänst, en uppsättning loggar och enklare felsökning—samtidigt som kodbasen hålls organiserad.
En praktisk modulesplit ser ut så här:
Tänk "separerade mappar och gränssnitt" innan "separerade tjänster". Om en gräns blir besvärlig senare (t.ex. hög ingestion) kan ni extrahera den med mindre drama.
Välj ramverk och bibliotek som teamet kan leverera med. En tråkig, välkänd stack brukar vinna eftersom:
Nyskapande verktyg kan vänta tills ni har verkliga begränsningar. Fram tills dess, optimera för tydlighet och stadig leverans.
De flesta kärn‑entiteter—feedback items, customers, accounts, tags, assignments—fungerar naturligt i en relationsdatabas. Ni vill ha bra fråge‑möjligheter, constraints och transaktioner för workflow‑ändringar.
Om fulltextsökning och filtrering blir viktiga kan ni lägga till en dedikerad sökindex senare (eller använda inbyggda möjligheter först). Undvik två sanningars‑källor tidigt.
Ett feedback‑system samlar snabbt "gör detta senare"‑arbete: skicka e‑postsvar, synka integrationer, processa bilagor, generera digestar, skicka webhooks. Lägg detta i en kö/bakgrunds‑worker från start.
Det håller UI:t responsivt, minskar timeouts och gör fel återkörbara—utan att tvinga er in i mikrotjänster dag ett.
Om målet är att validera workflow och UI snabbt (inbox → triage → replies), överväg att använda en vibe‑coding‑plattform som Koder.ai för att generera första versionen från en strukturerad chattspec. Den kan hjälpa er att få upp en React‑front med en Go + PostgreSQL‑backend, iterera i "planning mode" och fortfarande exportera källkoden när ni vill övergå till ett klassiskt ingenjörsflöde.
Ert lagringslager avgör om feedback‑loopen känns snabb och tillförlitlig—eller långsam och förvirrande. Sikta på ett schema som är lätt att fråga för dagligt arbete (triage, tilldelning, status) samtidigt som ni bevarar tillräckligt med rådetalj för audit.
För ett MVP täcker ni oftast behoven med ett litet set tabeller/collections:
En användbar regel: håll feedback lean (vad ni frågar ofta) och lägg "allt annat" i events och kanal‑specifik metadata.
När ett ärende kommer via e‑post, chatt eller webhook, spara det råa inkommande payloadet exakt som det mottogs (t.ex. ursprungliga e‑postheaders + body, eller webhook JSON). Detta hjälper er att:
Vanligt mönster: en ingestions‑tabell med source, received_at, raw_payload (JSON/text/blob) och en länk till skapad/uppdaterad feedback_id.
De flesta vyer reduceras till ett fåtal förutsägbara filter. Lägg till index tidigt för:
(workspace_id, status) för inbox/kanban‑vyer(workspace_id, assigned_to) för "mina items"(workspace_id, created_at) för sortering och datumfilter(tag_id, feedback_id) på join‑tabellen eller ett dedikerat tagguppslagsindexOm ni stödjer fulltextsök, överväg ett separat sökindex (eller databasens inbyggda text‑sök) i stället för tunga LIKE‑frågor i produktion.
Feedback innehåller ofta personuppgifter. Bestäm i förväg:
Implementera retention som policy per workspace (t.ex. 90/180/365 dagar) och verkställ den med ett schemalagt jobb som först expirerar råa ingestions, sedan äldre events/replies om så krävs.
Ingestion är där er kundfeedback‑loop antingen håller sig ren och användbar—eller blir en röra. Sikta på "lätt att skicka, konsekvent att bearbeta." Börja med några kanaler era kunder redan använder, och utöka sedan.
En praktisk första uppsättning brukar inkludera:
Ni behöver inte tung filterlogik dag ett, men ha grundläggande skydd:
Normalisera varje event till ett internt format med konsekventa fält:
Behåll både råa payloadet och den normaliserade posten så ni kan förbättra parsningen senare utan att tappa data.
Skicka en omedelbar bekräftelse (för email/API/widget när möjligt): tacka, beskriv vad som händer härnäst och undvik löften. Exempel: ”Vi granskar varje meddelande. Om vi behöver mer information återkommer vi. Vi kan inte svara individuellt på allt, men din feedback spåras."
En feedback‑inbox förblir användbar om team snabbt kan svara på tre frågor: Vad är detta? Vem äger det? Hur brådskande är det? Triage är delen av appen som förvandlar råa meddelanden till organiserat arbete.
Fritexttaggar känns flexibla, men fragmenterar snabbt ("login", "log‑in", "signin"). Börja med en liten kontrollerad taxonomi som speglar hur era produktteam redan tänker:
Tillåt användare att föreslå nya taggar, men kräv en ägare (t.ex. PM/Support‑ledare) för godkännande. Det håller rapporteringen meningsfull senare.
Bygg en enkel regelmotor som kan routa feedback automatiskt baserat på förutsägbara signaler:
Gör regler transparenta: visa "Routed because: Enterprise plan + keyword 'SSO'." Team litar på automation när den går att granska.
Lägg till SLA‑timers på varje item och i varje kö:
Visa SLA‑status i listvyn ("2h kvar") och på detaljsidan så att brådska delas i teamet—inte fast i någons huvud.
Skapa en tydlig väg när items fastnar: en overdue queue, dagliga digest till ägare och en lättviktig eskalationskedja (Support → Teamlead → On‑call/Manager). Målet är inte press—utan att förhindra att viktig kundfeedback tyst förfaller.
Att stänga loopen är när ett feedback‑hanteringssystem slutar vara en "insamlingslåda" och blir ett verktyg för att bygga förtroende. Målet är enkelt: varje feedback ska kunna kopplas till verkligt arbete, och kunder som frågade ska kunna få veta vad som hände—utan manuella kalkylblad.
Börja med att tillåta att en feedback‑post pekar på ett eller flera interna arbetsobjekt (bugg, uppgift, feature). Försök inte spegla hela issue‑trackern—lagra lätta referenser:
work_type (t.ex. issue/task/feature)external_system (t.ex. jira, linear, github)external_id och valfri external_urlDet håller datamodellen stabil även om ni byter verktyg senare. Det möjliggör också "visa all kundfeedback kopplad till denna release"‑vyer utan att skrapa andra system.
När kopplat arbete går till Shipped (eller Done/Released) bör er app kunna notifiera alla kunder som är knutna till relaterade feedback‑poster.
Använd en mallad text med säkra platshållare (namn, produktområde, sammanfattning, länk till release‑anteckningar). Låt den vara redigerbar vid utskick för att undvika klumpig formulering. Om ni har offentliga anteckningar, länka dem med en relativ path som /releases.
Stötta svar via de kanaler ni pålitligt kan skicka från:
Sporra alltid svar per feedback‑post med en auditvänlig tidslinje: sent_at, channel, author, template_id och leveransstatus. Om en kund svarar tillbaka, spara inkommande meddelanden med tidsstämplar också, så teamet kan bevisa att loopen verkligen stängdes—inte bara "markerad som shipped."
Rapportering är bara användbar om den förändrar vad team gör härnäst. Sikta på några vyer folk kan kolla dagligen, och expandera när ni är säkra på att underliggande workflow‑data (status, taggar, ägare, tidsstämplar) är konsekvent.
Börja med operationella dashboards som stödjer routing och uppföljning:
Håll diagrammen enkla och klickbara så en manager kan borra ner till exakta items bakom en topp.
Lägg till en "customer 360"‑sida som hjälper support och success att svara med kontext:
Denna vy minskar duplicerade frågor och gör uppföljningar mer avsiktliga.
Team kommer be om exporter tidigt. Erbjud:
Gör filtreringen konsekvent överallt (samma taggnamn, datumintervall, statusdefinitioner). Denna konsekvens förhindrar "två versioner av sanningen."
Hoppa över dashboards som bara mäter aktivitet (ärenden skapade, taggar tillagda). Föredra resultatmått kopplade till handling och svar: time to first reply, % av items som nådde ett beslut, och återkommande problem som faktiskt åtgärdats.
En feedback‑loop fungerar bara om den lever där folk redan spenderar tid. Integrationer minskar copy‑paste, behåller kontext nära arbetet och gör "stäng loopen" till en vana istället för ett specialprojekt.
Prioritera systemen teamet använder för kommunikation, bygg och kundspårning:
Håll första versionen enkel: enkelriktade notiser + djupa länkar tillbaka till er app, lägg till write‑back‑åtgärder (t.ex. "Tilldela ägare" från Slack) senare.
Även om ni släpper bara några native‑integrationer, låter webhooks kunder och interna team koppla vad de vill.
Erbjud ett litet, stabilt set events:
feedback.createdfeedback.updatedfeedback.closedInkludera en idempotency‑nyckel, tidsstämplar, tenant/workspace id och ett minimalt payload plus en URL för att hämta fullständiga detaljer. Det undviker att konsumenter går sönder när ni utvecklar datamodellen.
Integrationer misslyckas av normala skäl: återkallade token, rate limits, nätverksproblem, schema‑mismatch.
Designa för detta från början:
Om ni paketerar detta som produkt är integrationer också en köp‑trigger. Lägg till tydliga nästa steg från er app (och marknadssida) till /pricing och /contact för team som vill ha demo eller hjälp att koppla stacken.
En effektiv feedback‑app är inte "klar" efter lansering—den formas av hur team faktiskt triagerar, agerar och svarar. Målet med första releasen är enkelt: bevisa workflowen, minska manuellt arbete och fånga ren data ni kan lita på.
Håll scope tight så ni kan leverera snabbt och lära er. Ett praktiskt MVP brukar inkludera:
Om en funktion inte hjälper ett team att bearbeta feedback end‑to‑end kan den vänta.
Tidiga användare förlåter saknade funktioner, men inte förlorad feedback eller felaktig routing. Fokusera tester där misstag är dyra:
Sikta på förtroende i workflowen, inte perfekt kodtäckning.
Även ett MVP behöver några "tråkiga" saker:
Börja med en pilot: ett team, begränsade kanaler och ett tydligt framgångsmått (t.ex. "svara på 90% av högprioriterad feedback inom 2 dagar"). Samla problem veckovis och iterera workflowen innan ni bjuder in fler team.
Behandla användardata som er roadmap: var folk klickar, var de avbryter, vilka taggar som är oanvända och vilka "workarounds" som avslöjar verkliga behov.
"Stänga loopen" betyder att ni på ett tillförlitligt sätt kan gå från Collect → Act → Reply → Learn. I praktiken ska varje feedback‑item sluta i ett synligt utfall (shipped, declined, förklarat eller köat) och—när det är lämpligt—ett kundriktat svar med en tidsram.
Börja med mått som speglar hastighet och kvalitet:
Välj ett litet antal så att team inte optimerar för fåfängaaktiviteter.
Normalisera allt till en intern "feedback item"‑form samtidigt som ni behåller originaldatan.
Ett praktiskt tillvägagångssätt:
Det gör triage konsekvent och låter er omprocessa gamla meddelanden när parsern förbättras.
Håll kärnmodellen enkel och lätt att fråga:
Skriv ner en kort, gemensam statusdefinition och börja med ett linjärt set:
Se till att varje status svarar på "vad händer härnäst?" och "vem äger nästa steg?". Om "Planned" ibland betyder "kanske", dela upp eller byt namn så rapporteringen förblir tillförlitlig.
Definiera dubbletter som "samma underliggande problem/önskemål", inte bara liknande text.
Ett vanligt arbetsflöde:
Det förhindrar fragmenterat arbete samtidigt som efterfrågan bevaras.
Håll automation enkel och granskbar:
Visa alltid "Routed because…" så människor kan lita på och korrigera regler. Börja med förslag eller standarder innan du tvingar igenom hård automatisk routing.
Behandla varje workspace som en hård gräns:
workspace_id på varje kärnpostworkspace_idDefiniera sedan roller baserat på handlingar (view/edit/merge/export/send replies), inte på skärmar. Lägg till en tidigt för statusändringar, merges, tilldelningar och svar.
Börja som en modulär monolit med tydliga gränser (auth/orgs, feedback, workflow, messaging, analytics). Använd en relationsdatabas för transaktionell workflow‑data.
Lägg bakgrundsjobb tidigt för:
Det håller UI:t snabbt och gör fel återkörbara utan att binda er till mikrotjänster för tidigt.
Spara lätta referenser i stället för att spegla hela issue‑trackern:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (och valfri external_url)När kopplat arbete går till , trigga ett flöde som notifierar alla kunder knutna till de relaterade feedback‑posterna med mallar och spårningsstatus. Om ni har offentliga anteckningar, länka dem relativt (t.ex. ).
Använd events‑tidslinjen för auditspårning så att huvud‑feedback‑posten förblir lättviktig.
/releases