15 maj 2025·8 min
Hur man bygger en webbapp för berikning av kunddata
Lär dig bygga en webbapp som berikar kundposter: arkitektur, integrationer, matchning, validering, sekretess, övervakning och tips för utrullning.
Definiera mål, användare och berikningsomfång
Innan ni väljer verktyg eller ritar arkitekturbilder, var tydliga med vad “berikning” betyder för er organisation. Team blandar ofta flera typer av berikning och får sedan svårt att mäta framsteg — eller börjar argumentera om vad som räknas som färdigt.
Vad räknas som berikning?
Börja med att namnge de fälttyper ni vill förbättra och varför:
- Firmografiska: företagets storlek, bransch, huvudkontorets plats, finansieringsfas
- Kontakt: jobbtitel, verifierad e-post/telefon, senioritet, roll
- Beteende: produktsignaler, intent, engagemangspoäng
- Egna fält: intern territorium, kontonivå, ICP-fit-poäng
Skriv ner vilka fält som är obligatoriska, vilka som är trevliga att ha, och vilka som aldrig ska berikas (t.ex. känsliga attribut).
Vem kommer använda appen — och till vad?
Identifiera era primära användare och deras viktigaste uppgifter:
- Sales ops: minska dubbletter, standardisera konton, förbättra routing
- Marketing ops: berika leads för segmentering och bättre målgruppsarbete
- Support: visa kontekontext vid ärenden
- Analytiker: pålitliga dataset för rapportering
Varje användargrupp behöver ofta olika arbetsflöden (bulkbehandling vs. enskild postgranskning), så fånga dessa behov tidigt.
Definiera utfall, avgränsningar och framgångsmått
Lista utfall i mätbara termer: högre matchningsgrad, färre dubbletter, snabbare routing av leads/konton eller bättre segmenteringsprestanda.
Sätt tydliga gränser: vilka system som ingår i omfånget (CRM, fakturering, produktanalys, supportsystem) och vilka som inte gör det — åtminstone för första releasen.
Slutligen, kom överens om framgångsmått och acceptabla felgrader (t.ex. berikningstäckning, verifieringsgrad, dubblettrate och regler för “säkert fel” när berikning är osäker). Det blir er ledstjärna för resten av bygget.
Modellera er kunddata och identifiera luckor
Innan ni berikar något, var tydliga med vad “en kund” betyder i ert system — och vad ni redan vet om dem. Det hindrar er från att betala för berikning ni inte kan lagra och undviker förvirrande sammanslagningar senare.
Inventera era nuvarande fält och källor
Börja med en enkel katalog över fält (t.ex. namn, e-post, företag, domän, telefon, adress, jobbtitel, bransch). För varje fält, notera var det härstammar: användarinmatning, CRM-import, faktureringssystem, supportsystem, produktregistreringsformulär eller en berikningsleverantör.
Få också med hur det samlas in (obligatoriskt vs. frivilligt) och hur ofta det ändras. Till exempel förändras jobbtitel och företagsstorlek över tid, medan ett internt kund-ID aldrig bör ändras.
Definiera er identitetsmodell: person, företag, konto
De flesta berikningsflöden involverar minst två entiteter:
- Person (kontakt/lead): en individ med e-post, telefon, roller
- Företag (organisation): ett företag med domän, plats och firmografiska uppgifter
Avgör om ni även behöver ett Konto (en kommersiell relation) som kan länka flera personer till ett företag med attribut som plan, kontraktsdatum och status.
Skriv ned vilka relationer ni stödjer (t.ex. många personer → ett företag; en person → flera företag över tid).
Dokumentera vanliga dataproblem
Lista de problem ni ser upprepade gånger: saknade värden, inkonsekventa format ("US" vs "United States"), dubbletter skapade vid importer, åldrade poster och motstridiga källor (fakturadress vs CRM-adress).
Välj kravnycklar och sätt förtroendenivåer
Välj de identifierare ni kommer använda för matchning och uppdateringar — vanligtvis e-post, domän, telefon och ett internt kund-ID.
Tilldela varje nyckel en förtroendenivå: vilka som är auktoritativa, vilka som är “bäst ansträngning” och vilka som aldrig får skrivas över.
Klargör ägarskap och redigeringsrättigheter
Kom överens om vem som äger vilka fält (Sales ops, Support, Marketing, Customer Success) och definiera redigeringsregler: vad en människa kan ändra, vad automation får ändra och vad som kräver godkännande.
Denna styrning sparar tid när berikningsresultat kolliderar med befintliga data.
Välj berikningskällor och datakontrakt
Innan ni skriver integrationskod, bestäm var berikningsdata kommer ifrån och vad ni får göra med den. Det förhindrar ett vanligt fel: att leverera en funktion som fungerar tekniskt men som spräcker kostnader, tillförlitlighet eller efterlevnad.
Typiska berikningskällor
Ni kommer vanligtvis kombinera flera insatser:
- Interna system: CRM, fakturering, supportärenden, produktanalys, e-postplattform, datalager
- Tredjeparts-API:er: firmografi, kontaktvalidering, branschkoder, teknografier, risksignaler
- Uppladdade listor: CSV från försäljning, event, partners eller dataleverantörer
- Webhooks: realtidsuppdateringar från verktyg som redan observerar förändringar (t.ex. e-postverifiering, identitetsleverantörer)
Hur man utvärderar källor
För varje källa, poängsätt den efter täckning (hur ofta den returnerar något användbart), färskhet (hur snabbt den uppdateras), kostnad (per anrop/per post), rate limits och användarvillkor (vad ni får lagra, hur länge och för vilket syfte).
Kontrollera också om leverantören returnerar tillitsvärden och tydlig proveniens (varifrån ett fält kommer).
Definiera ett datakontrakt
Behandla varje källa som ett kontrakt som specificerar fältnamn och format, obligatoriska vs valfria fält, uppdateringsfrekvens, förväntad latens, felkoder och betydelsen av confidence-score.
Inkludera en tydlig mappning (”leverantörsfält → er kanoniska fält”) plus regler för null-värden och konflikthantering.
Fallback- och lagringsbeslut
Planera vad som händer när en källa är otillgänglig eller returnerar låg förtroendegrad: retry med backoff, köa för senare, eller falla tillbaka på sekundär källa.
Avgör vad ni lagrar (stabila attribut som behövs för sökning/rapportering) kontra vad ni beräknar på begäran (dyra eller tidskänsliga uppslag).
Dokumentera slutligen begränsningar för att lagra känsliga attribut (t.ex. personliga identifierare, härledda demografiska data) och sätt retentionregler därefter.
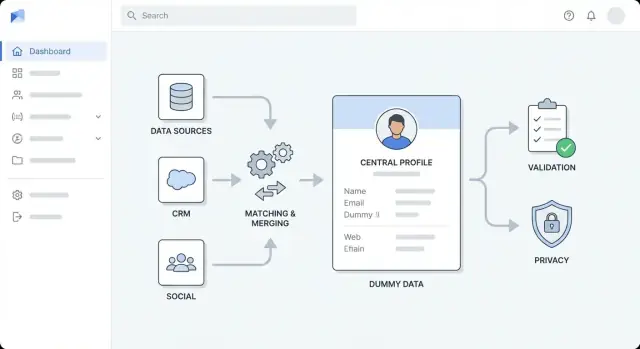
Designa hög-nivåarkitekturen
Innan ni väljer verktyg, bestäm hur appen ska formas. En tydlig hög-nivåarkitektur håller berikningsarbetet förutsägbart, förhindrar att “snabba lösningar” blir permanent skräp och hjälper teamet att estimera arbete.
Välj en arkitekturstil som passar ert team
För de flesta team: starta med en modulär monolit — en deploybar app som internt är uppdelad i välavgränsade moduler (ingestion, matchning, berikning, UI). Det är enklare att bygga, testa och felsöka.
Gå över till separerade tjänster när ni har en tydlig anledning — t.ex. hög genomströmning, behov av oberoende skalning eller skilda teamansvar. En vanlig uppdelning är:
- API-tjänst (synchronous requests, auth, CRUD för poster)
- Worker-tjänst (asynkron berikning, retries)
- UI (granskning, godkännanden, bulkåtgärder)
Separera ansvar i lager
Håll gränserna explicita så att förändringar inte sprider sig överallt:
- Ingestionslager: importer från CRM/filer och normalisering
- Berikningslager: anropar leverantörer/interna källor och lagrar resultat
- Valideringslager: tillämpar datakvalitetsregler och flaggar undantag
- Lagringslager: kundprofiler, råa leverantörspayloads, revisionshistorik
- Presentationslager: UI-vyer, granskningsköer, godkännanden
Designa för asynkron berikning från dag ett
Berikning är långsam och felbenägen (rate limits, timeouts, partiella data). Behandla berikning som jobb:
- API skapar ett jobb och svarar snabbt
- Workers bearbetar jobb via en kö (med retries och backoff)
- UI visar jobbstatus och tillåter omkörning vid behov
Planera miljöer och konfiguration
Sätt upp dev/staging/prod tidigt. Håll leverantörsnycklar, trösklar och feature-flaggor i konfiguration (inte i kod) och gör det enkelt att byta leverantörer per miljö.
Samordna med en enkel översiktsdiagram
Skissa en enkel diagram: UI → API → databas, plus kö → workers → berikningsleverantörer. Använd den i granskningar så alla är överens om ansvar innan implementation.
Snabbprototyp (valfritt)
Om målet är att validera arbetsflöden och granskningsskärmar innan ni investerar i full engineering-cykel kan en plattform som Koder.ai hjälpa er att snabbt prototypa kärnappen: ett React-baserat UI för granskning/godkännanden, ett Go-API-lager och PostgreSQL som lagring.
Detta kan vara särskilt användbart för att bevisa jobbmodellen (asynkron berikning med retries), revisionshistorik och rollbaserad åtkomst, och sedan exportera källkoden när ni är redo att produktionssätta.
Sätt upp lagring, köer och stödjande tjänster
Innan ni börjar koppla berikningsleverantörer, få "rören" på plats. Lagrings- och bakgrundsprocessbeslut är svåra att ändra senare och påverkar pålitlighet, kostnad och auditerbarhet direkt.
Primär databas: profiler + historia
Välj en primär databas för kundprofiler som stödjer strukturerad data och flexibla attribut. Postgres är ett vanligt val eftersom den kan lagra kärnfält (namn, domän, bransch) tillsammans med semistrukturerade berikningsfält (JSON).
Lika viktigt: lagra ändringshistorik. Istället för att skriva över värden tyst, fånga vem/vad som ändrade ett fält, när och varför (t.ex. “vendor_refresh”, “manual_approval”). Det gör godkännanden enklare och säkrar er vid återställningar.
Kö: berikning och retries
Berikning är i grunden asynkront: API:er har rate-limits, nätverk fallerar och vissa leverantörer svarar långsamt. Lägg till en jobbkö för bakgrundsarbete:
- Berikningsförfrågningar (enskilda poster och bulk)
- Retries med backoff
- Schemalagd refresh (t.ex. var 30/90 dag)
- Dead-letter-hantering för jobb som fortsätter misslyckas
Detta håller ert UI responsivt och förhindrar att leverantörsproblem tar ner appen.
Cache: snabba uppslag och rate-limit-spårning
En liten cache (ofta Redis) hjälper vid frekventa uppslag (t.ex. “företag per domän”) och för att spåra leverantörers rate limits och cooldown-fönster. Den är också användbar för idempotensnycklar så upprepade importer inte triggar dubbletter.
Filsystem och retention
Planera objektlagring för CSV-importer/exporter, felrapporter och "diff"-filer som används i granskningsflöden.
Definiera retentionregler tidigt: behåll råa leverantörspayloads bara så länge det behövs för debugging och revisioner, och ta bort loggar enligt er policy.
Bygg ingest- och normaliseringspipeliner
Matcha nivå till omfattning
Börja på gratis, sedan uppgradera till Pro, Business eller Enterprise när er utrullning växer.
Er berikningsapp är bara så bra som data ni matar in. Ingestion är där ni bestämmer hur information kommer in i systemet, och normalisering är där ni gör den konsekvent nog för att matcha, berika och rapportera.
Bestäm hur data kommer in
De flesta team behöver en mix av ingångspunkter:
- API-endpoints för er produkt eller interna verktyg att skicka nya/uppdaterade kunder
- Webhooks från CRM eller faktureringssystem för nära realtidsändringar
- Schemalagda pullar (nattliga synkroniseringar) för system som inte pushar
- CSV-importer för backfills och engångsuppladdningar
Oavsett vad ni stödjer, håll "rå-ingest" lättviktig: acceptera data, autentisera, logga metadata och köa arbete för bearbetning.
Normalisera och standardisera tidigt
Skapa ett normaliseringslager som förvandlar röriga indata till ett konsekvent internt format:
- Namn: trimma blanksteg, dela upp fullständiga namn när möjligt, hantera versalisering
- Telefon: konvertera till E.164-format och lagra landsantaganden explicit
- Adresser: standardisera fält (gata, ort, region, postnummer) och behåll originaltexten
- Domäner/e-post: gör till gemener, ta bort spårningsparametrar i URL:er, validera syntax
Validera, karantänsera och var idempotent
Definiera obligatoriska fält per posttyp och avvisa eller karantänsera poster som misslyckas (t.ex. saknad e-post/domän för företagsmatchning). Karantänsatta objekt ska vara synliga och möjliga att åtgärda i UI.
Lägg till idempotensnycklar för att förhindra dubbla processer vid retries (vanligt med webhooks och ostadiga nätverk). En enkel approach är att hasha (source_system, external_id, event_type, event_timestamp).
Spåra härkomst per fält
Lagra proveniens för varje post och, gärna, för varje fält: källa, ingestionstid och transformationsversion. Då blir det möjligt att svara på frågor som: “Varför ändrades detta telefonnummer?” och “Vilken import skapade detta värde?”
Implementera matchning, deduplicering och sammanfogning
Att få berikningen rätt bygger på att ni kan identifiera vem som är vem. Appen behöver tydliga matchningsregler, förutsägbart merge-beteende och en säkerhetsmekanism när systemet är osäkert.
Definiera matchningsregler (och förtroendetrösklar)
Börja med deterministiska identifierare:
- Exakta nycklar: e-post (normaliserad till gemener), kund-ID, skatte-/VAT-ID eller verifierad domän
Lägg sedan till probabilistisk matchning när exakta nycklar saknas:
- Fuzzy-matcher: namn + företagsdomän, namn + plats, telefonlikhet
Tilldela en matchningspoäng och sätt trösklar, till exempel:
- Automerga endast över en hög tröskel
- Kö för manuell granskning i “kanske”-intervallet
- Avvisa under den lägre tröskeln
Planera deduplicerings- och merge-logik
När två poster representerar samma kund, bestäm hur fält väljs:
- Fältprioritering: “verifierad e-post slår overifierad”, “nyare tidsstämpel vinner”, “CRM skriver över berikning för kontaktansvarig”
- Källförtroendescore: rangordna källor (CRM, fakturering, berikningsleverantörer) för att lösa konflikter
- Konflikthantering: behåll båda värden när möjligt (t.ex. flera telefonnummer) eller spara det förlorade värdet i historiken
Revisionsspår och granskningsflöde
Varje merge bör skapa en audit-händelse: vem/vad som initierade den, före/efter-värden, matchningspoäng och involverade post-ID:n.
För tvetydiga matcher, erbjuda en granskningsvy med sida-vid-sida-jämförelse och alternativ: “merge / avbryt merge / be om mer data”.
Skydd mot oavsiktliga massmerges
Kräv extra bekräftelse för bulkmerges, begränsa merges per jobb och stöd “dry run”-förhandsvisningar.
Lägg också till en ångra-väg (eller merge-omvändning) med hjälp av revisionshistoriken så misstag inte blir permanenta.
Integrera beriknings-API:er och hantera tillförlitlighet
Berikning är där appen möter omvärlden — flera leverantörer, inkonsekventa svar och oförutsägbar tillgänglighet.
Behandla varje leverantör som en plug-and-play-"connector" så ni kan lägga till, byta eller stänga av källor utan att röra resten av pipelinen.
Bygg connectorer för leverantörer (auth, retries, felmappning)
Skapa en connector per berikningsleverantör med ett konsekvent gränssnitt (t.ex. enrichPerson(), enrichCompany()). Håll leverantörsspecifik logik inne i connectorn:
- Autentisering (API-nycklar, OAuth-tokens, token-refresh)
- Standardiserade retries för transienta fel
- Felmappning (konvertera leverantörsfel till era egna kategorier som
invalid_request,not_found,rate_limited,provider_down)
Detta förenklar downstream-logic: de hanterar era feltyper, inte varje leverantörs egenheter.
Hantera rate limits med throttling och backoff
De flesta beriknings-API:er har kvoter. Lägg på throttling per leverantör (och ibland per endpoint) för att hålla förfrågningarna under gränserna.
När ni träffar en gräns, använd exponentiell backoff med jitter och respektera Retry-After-headers om de finns.
Planera även för “långsamt fel”: timeouts och partiella svar ska fångas som retrybara händelser, inte tyst släppas bort.
Lagra förtroende och bevis (inom policy)
Berikningsresultat är sällan absoluta. Spara leverantörens confidence-scores när de finns, plus er egen poäng baserad på matchkvalitet och fältkompletthet.
Där kontrakt och sekretesspolicy tillåter, lagra råa bevis (käll-URL:er, identifierare, tidsstämplar) för att stödja revision och användarförtroende.
Multi-leverantörsstrategi: “bäst tillgängligt”
Stöd flera leverantörer genom att definiera urvalsregler: billigast först, högst tillit eller fält-för-fält “bäst tillgängligt”.
Spåra vilken leverantör som levererat varje attribut så ni kan förklara förändringar och backa vid behov.
Schemalagda refresh-regler
Berikning blir gammal. Implementera refresh-regler som “re-berika var 90:e dag”, “refresh vid nyckelfältsändring” eller “refresh bara om förtroendet sjunker”.
Gör scheman konfigurerbara per kund och per datatyp för att styra kostnad och brus.
Lägg in datakvalitetsregler och validering
Sätt den framför användare
Distribuera och hosta er nya app, och lägg till en egen domän när den är produktionsklar.
Berikning hjälper bara om nya värden är tillförlitliga. Behandla validering som en förstklassig funktion: den skyddar era användare från röriga importer, opålitliga tredjepartssvar och oavsiktlig korruption vid merges.
Definiera fältnivå-valideringsregler
Börja med en enkel "regelkatolog" per fält, delad av UI-formulär, ingestpipelines och publika API:er.
Vanliga regler inkluderar formatkontroller (e-post, telefon, postnummer), tillåtna värden (landskoder, branschlistor), intervallkontroller (antal anställda, intäktsband) och beroenden (om country = US så krävs state).
Håll reglerna versionerade så ni kan ändra dem säkert över tid.
Lägg till kvalitetskontroller som speglar verkligt användande
Utöver grundläggande validering, kör datakvalitetskontroller som svarar på affärsfrågor:
- Fullständighet: Har vi minimifälten för att använda posten?
- Unikhet: Är ”unika” identifierare (domän, skatte-ID) duplicerade?
- Konsistens: Stämmer relaterade fält överens (land vs telefonprefix)?
- Aktualitet: Hur gammalt är ett värde och bör det uppdateras?
Poängsätt poster och källor
Konvertera kontroller till ett scorecard: per post (samlad hälsa) och per källa (hur ofta den levererar giltiga, uppdaterade värden).
Använd poängen för att styra automation — t.ex. applicera bara berikningar automatiskt ovanför en tröskel.
Rutin för felhantering
När en post misslyckas validering, ta inte bort den.
Skicka den till en "data-quality"-kö för retry (transienta problem) eller manuell granskning (felaktig indata). Spara den misslyckade payloaden, regelbrott och föreslagna åtgärder.
Gör fel begripliga
Returnera tydliga, handlingsbara meddelanden för importer och API-klienter: vilket fält som misslyckades, varför och ett exempel på ett giltigt värde.
Det minskar supportbelastning och snabbar upp saneringsarbete.
Skapa UI för granskning, godkännanden och bulkarbete
Ert berikningspipeline levererar värde först när människor kan granska vad som ändrats och tryggt föra uppdateringar vidare till system nedströms.
UI:t ska göra “vad hände, varför, och vad gör jag härnäst?” uppenbart.
Kärnskärmar att designa
Kundprofilen är basen. Visa nyckelidentifierare (e-post, domän, företagsnamn), aktuella fältvärden och en berikningsstatus-badge (t.ex. Inte berikad, Pågår, Behöver granskning, Godkänd, Avvisad).
Lägg till en ändringshistorik-tidslinje som förklarar uppdateringar i vardagligt språk: “Företagsstorlek uppdaterad från 11–50 till 51–200.” Gör varje post klickbar för att se detaljer.
Ge merge-förslag när dubbletter upptäcks. Visa de två (eller fler) kandidatposterna sida-vid-sida med rekommenderad "survivor"-post och en förhandsvisning av det sammanslagna resultatet.
Bulkarbete som matchar verkliga operationer
De flesta team arbetar i partier. Inkludera bulkåtgärder som:
- Berika valda poster (eller köa för nattlig behandling)
- Godkänn/avvisa föreslagna merges
- Exportera resultat (CSV) för revision eller offlinegranskning
Använd ett tydligt bekräftelsesteg för destruktiva åtgärder (merge, skriv över) med ett "ångra"-fönster när det är möjligt.
Snabb sökning, filter och fälthistorik
Lägg till global sökning och filter efter e-post, domän, företag, status och kvalitetspoäng.
Låt användare spara vyer som “Behöver granskning” eller “Låg förtroende-uppdateringar”.
För varje berikat fält, visa proveniens: källa, tidsstämpel och förtroende.
En enkel “Varför detta värde?”-panel bygger förtroende och minskar onödig kommunikation.
Vägledda arbetsflöden för icke-tekniska användare
Håll beslut binära och vägledda: “Acceptera föreslaget värde”, “Behåll befintligt” eller “Redigera manuellt.” Om ni behöver djupare kontroll, göm det bakom en “Avancerat”-väljare istället för att göra det till standard.
Säkerhet, integritet och grundläggande efterlevnad
Validera det asynkrona jobmodellen
Ställ upp jobbköer, retries och statusvyer utan att behöva sy ihop flera verktyg först.
Kundberikningsappar hanterar identifierare (e-post, telefon, företagsuppgifter) och drar ofta data från tredjepart. Behandla säkerhet och integritet som kärnfunktioner, inte som senare uppgifter.
Rollbaserad åtkomstkontroll (RBAC)
Börja med tydliga roller och minst privilegium som standard:
- Admin: hantera användare, roller, connectorer, retentionpolicyer
- Ops: köra berikningsjobb, lösa konflikter, godkänna merges
- Viewer: read-only för rapportering och support
Håll behörigheter granulära (t.ex. “exportera data”, “se PII”, “godkänn merges”) och separera miljöer så produktionsdata inte är tillgänglig i dev.
Skydda känsliga data
Använd TLS för all trafik och kryptering i vila för databaser och objektlagring.
Spara API-nycklar i en secrets manager (inte i env-filer i källkod), rotera dem regelbundet och ge dem begränsade rättigheter per miljö.
Om ni visar PII i UI, använd säkra standarder som maskning (t.ex. visa sista 2–4 siffrorna) och kräva explicit behörighet för att avslöja hela värdet.
Samtycke och begränsningar i databruk
Om berikning beror på samtycke eller kontraktsvillkor, koda in dessa begränsningar i ert arbetsflöde:
- Spåra datakälla, syfte och tillåtna användningar per fält
- Dokumentera vad ni sparar och varför (en kort intern policy-sida som /privacy eller /docs/data-handling hjälper)
- Undvik att samla fält ni inte behöver — mindre data minskar risk
Revision, retention och radering
Skapa en audit-trail för både åtkomst och ändringar:
- Logga vem som visade/exporterade poster
- Logga vem ändrade vad och när (före/efter-värden, jobb-ID, berikningsleverantör)
Slutligen, stöd sekretessförfrågningar med praktiska verktyg: retention-scheman, postradering och “glömd”-arbetsflöden som också rensar kopior i loggar, cache och backup där det är möjligt (eller markerar dem för utgång).
Övervakning, analys och operativa kontroller
Övervakning är inte bara för drifttid — det är hur ni håller berikningen pålitlig när volymer, leverantörer och regler ändras.
Behandla varje berikningskörning som ett mätbart jobb med tydliga signaler ni kan trenda över tid.
Mätvärden som faktiskt hjälper
Börja med en liten uppsättning operativa mätvärden kopplade till utfall:
- Jobgennemströmning (poster/min) och tid-till-färdig per körning
- Framgångsgrad vs felgrad, uppdelat på feltyp (validering, matchning, leverantör)
- Leverantörslatens (p50/p95) och timeouts per berikningskälla
- Matchningsgrad (hur ofta ni med förtroende fäster berikning)
- Förhindrade dubbletter (hur många merges som skulle skett felaktigt utan kontroller)
Dessa siffror svarar snabbt på: “Förbättrar vi datan, eller flyttar vi bara runt den?”
Larm och skyddsåtgärder
Lägg till larm som triggas på förändring, inte brus:
- Spikar i fel eller karantänsatta poster
- Köbacklogs eller långsamma konsumenter (signal för fast pipeline)
- Leverantörsfelspikar (429/5xx), förhöjd latens eller ökade timeouts
Knyt larm till konkreta åtgärder, som att pausa en leverantör, sänka samtidighet eller byta till cache/stale-data.
Adminpanel för operatörer
Erbjud en adminvy för senaste körningar: status, räknare, retries och en lista över karantänsatta poster med orsaker.
Inkludera “replay”-kontroller och säkra bulkåtgärder (retry för leverantörstimeouts, kör matchning igen).
Spårbarhet med loggar
Använd strukturerade loggar och ett korrelations-ID som följer en post end-to-end (ingestion → match → berikning → merge).
Det gör support och incidentfelsökning avsevärt snabbare.
Incident-playbooks och rollback
Skriv korta playbooks: vad gör ni när en leverantör degraderas, när matchningsgraden faller, eller när dubbletter slinker igenom.
Behåll en rollback-option (t.ex. återställ merges under ett tidsfönster) och dokumentera den i /runbooks.
Testning, utrullning och iterativ plan
Testning och utrullning är där en berikningsapp blir säker att lita på. Målet är inte "fler tester" — det är förtroende för att matchning, merge och validering beter sig förutsägbart under röriga verkliga data.
Testa de riskfyllda delarna först
Prioritera tester runt logik som tyst kan skada poster:
- Matchningsregler: enhetstester för exakta, fuzzy och sammansatta matcher (t.ex. e-post + företagsdomän). Inkludera närbesläktade dubbletter och utbytta fält.
- Merge-utfall: testa fältprioriteringar (källa-prioritet), konflikthantering och "skriv inte över"-regler.
- Valideringskantfall: felaktiga e-postadresser, internationella telefonformat, saknat land, duplicerade identifierare och "okänt"-värden.
Använd syntetiska dataset (genererade namn, domäner, adresser) för att validera noggrannhet utan att exponera riktig kunddata.
Behåll en versionerad “golden set” med förväntade match-/merge-utgångar så regressioner blir uppenbara.
Stega ut utrullningen för att minska blast radius
Börja litet, expandera sedan:
- Pilotomfång: ett team eller ett segment (t.ex. SMB-leads)
- Begränsade åtgärder: starta med “föreslagna uppdateringar” som kräver godkännande innan skrivning tillbaka till CRM
- Skala upp: öka volymen och tillåt automatiska skrivningar för lågriskfält
Definiera framgångsmått innan ni börjar (matchprecision, godkännandegrad, minskning av manuella redigeringar och tid-till-berikning).
Dokumentera arbetsflöden och integrationschecklista
Skapa korta dokument för användare och integratörer (länka från er produktarea eller /pricing om ni vill styra åtkomst). Inkludera en integrationschecklista:
- API-authmetod, rate limits och retry-beteende
- Obligatoriska fält för berikningsförfrågningar
- Webhook-/event-payloads (och versionering)
- Felkoder och regler för “delvis berikning”
- Förväntningar kring auditloggar och dataretention
För kontinuerlig förbättring, schemalägg en lättviktig granskning: analysera misslyckade valideringar, frekventa manuella åsidosättningar och mismatchade poster, uppdatera regler och lägg till tester.
En praktisk referens för att spetsa reglerna: /blog/data-quality-checklist.
Bygga vs accelerera: en praktisk notering
Om ni redan vet era arbetsflöden men vill korta tiden från specifikation → fungerande app, överväg att använda Koder.ai för att generera en initial implementation (React UI, Go-tjänster, PostgreSQL-lagring) från en strukturerad chatbaserad plan.
Team använder ofta detta för att snabbt få upp gransknings-UI, jobbprocessning och revisionshistorik — och sedan iterera med planning mode, snapshots och rollback när kraven utvecklas. När ni behöver full kontroll kan ni exportera källkoden och fortsätta i er befintliga pipeline. Koder.ai erbjuder free, pro, business och enterprise-nivåer som hjälper er matcha experiment mot produktionsbehov.