20 mars 2025·8 min
Hur du bygger en webbapp för kundsupport med ärenden och SLA:er
Planera, designa och bygg en webbapp för kundsupport med ärendearbetsflöden, SLA-övervakning och en sökbar kunskapsdatabas—plus roller, analys och integrationer.
Definiera mål, användare och omfattning
Ett ärendehanteringssystem blir rörigt när det byggs kring funktioner istället för resultat. Innan du designar fält, köer eller automationer, enas om vem appen är för, vilken smärta den löser och vad som räknas som “bra”.
Identifiera dina användare (och deras dagliga arbetsuppgifter)
Börja med att lista rollerna och vad var och en måste åstadkomma under en normal vecka:
- Agenter: triage, svara, lösa och dokumentera lösningar snabbt.
- Teamledare: omfördela arbetsbelastning, upptäcka fastnade ärenden, upprätthålla SLA:er, coacha agenter.
- Administratörer: konfigurera kanaler, kategorier, automationer, behörigheter och mallar.
- Kunder (valfritt): skicka in förfrågningar, följa status, lägga till detaljer, hitta svar i en portal.
Om du hoppar över det här steget optimerar du av misstag för administratörer medan agenter kämpar i kön.
Skriv ner problemen du löser
Håll det konkret och kopplat till beteenden du kan observera:
- Missade SLA:er: ärenden åldras tyst; eskalationer sker för sent.
- Röriga köer: oklart ägandeskap, duplicerat arbete och förvirring kring “vart hör detta hemma?”.
- Upprepade frågor: samma svar skrivs om och om igen, vilket saktar ner lösningar.
Bestäm var appen ska användas
Var tydlig: är det ett internt verktyg endast, eller kommer du också att leverera en kundvändig portal? Portaler ändrar kraven (autentisering, behörigheter, innehåll, varumärke, notiser).
Välj framgångsmetrik tidigt
Välj ett litet antal mått du kommer att följa från dag ett:
- Tid till första svar
- Lösningstid
- Avledningsgrad (problem lösta via kunskapsdatabasen istället för ärenden)
Skapa en enkel v1-omfattningsbeskrivning
Skriv 5–10 meningar som beskriver vad som ingår i v1 (måste-ha-arbetsflöden) och vad som kommer senare (trevligt att ha som avancerad routing, AI-förslag eller djup rapportering). Detta blir din styrning när förfrågningar hopar sig.
Designa ärendemodellen och livscykeln
Din ärendemodell är “sanningskällan” för allt annat: köer, SLA:er, rapportering och vad agenter ser på skärmen. Få detta rätt tidigt så undviker du smärtsamma migreringar senare.
Kartlägg en livscykel du kan förklara i en mening
Börja med en tydlig uppsättning tillstånd och definiera vad varje innebär operationellt:
- Nytt: skapat, inte ännu triagerat
- Tilldelat: ägs av en agent eller ett team
- Pågående: aktivt under arbete
- Väntar: blockerad (kundsvar, tredje part, engineering)
- Löst: agenten anser att det är löst (triggar ofta en notis)
- Stängt: slutligt tillstånd (låst eller begränsade redigeringar)
Lägg till regler för tillståndsövergångar. Till exempel: endast Tilldelat/Pågående-ärenden kan sättas till Löst, och ett Stängt ärende kan inte återöppnas utan att skapa ett uppföljningsärende.
Bestäm hur ärenden kommer in i systemet
Lista varje intagsväg du stödjer nu (och vad du lägger till senare): webbformulär, inkommande e-post, chatt och API. Varje kanal bör skapa samma ärendeobjekt, med några kanal-specifika fält (som e-posthuvuden eller chatttranskript-ID:n). Konsistens håller automation och rapportering hanterbar.
Välj nödvändiga fält (och håll dem minimala)
Som minimum krävs:
- Ämne och beskrivning
- Begärande part (kundens identitet)
- Prioritet (hur brådskande)
- Kategori (vilken typ av problem)
Allt annat kan vara valfritt eller härlett. Ett överlastat formulär minskar kvaliteten på ifyllandet och gör agenter långsammare.
Planera taggar och anpassade fält för verkliga team
Använd taggar för lättviktsfiltrering (t.ex. “fakturering”, “bugg”, “vip”), och anpassade fält när du behöver strukturerad rapportering eller routing (t.ex. “Produktområde”, “Order-ID”, “Region”). Se till att fält kan vara team-scopade så att en avdelning inte stökas ner av en annan.
Definiera samarbete inuti ett ärende
Agenter behöver en säker plats att samordna sig:
- Interna anteckningar (inte synliga för kunder)
- @omnämnanden och följare/CC-listor
- Länkade ärenden (dubbletter, förälder/barn-incidenter)
Ditt agentgränssnitt bör göra dessa element ett klick bort från huvudtidslinjen.
Bygg ärendeköer och tilldelningsarbetsflöden
Köer och tilldelningar är där ett ärendehanteringssystem slutar vara en delad inkorg och börjar fungera som ett driftverktyg. Målet är enkelt: varje ärende ska ha en uppenbar “nästa bästa åtgärd”, och varje agent ska veta vad de ska arbeta med nu.
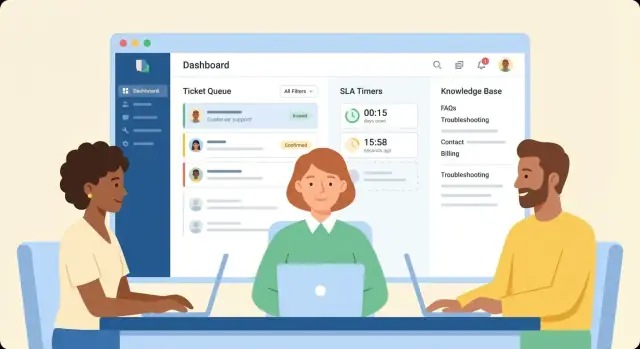
Designa en agentkö som svarar "vad är nästa?"
Skapa en kövy som standard visar det mest tidssensitiva arbetet. Vanliga sorteringsalternativ som agenter faktiskt kommer att använda är:
- Prioritet (t.ex. P1–P4)
- SLA-förfallotid (snart först)
- Senast uppdaterad (för att fånga fastnade konversationer)
Lägg till snabba filter (team, kanal, produkt, kundnivå) och en snabb sökfunktion. Håll listan kompakt: ämne, begärande part, prioritet, status, SLA-nedräkning och tilldelad agent är vanligtvis tillräckligt.
Tilldelningsregler: automatisera när det går, manuellt när det behövs
Stöd ett par tilldelningsvägar så team kan utvecklas utan att byta verktyg:
- Manuell tilldelning för edge-case och träningsfällen
- Round-robin för jämn fördelning
- Kompetensbaserad routing (språk, produktområde, fakturering vs tekniskt)
- Teambaserad routing (t.ex. “Betalningar”, “Enterprise”, “Returer”)
Gör regelbesluten synliga (“Tilldelad av: Kompetens → Franska + Fakturering”) så att agenter litar på systemet.
Statusar och mallar som håller arbetet igång
Statusar som Väntar på kund och Väntar på tredje part förhindrar att ärenden ser “inaktiva” ut när de är blockerade, och gör rapporteringen mer ärlig.
För att snabba upp svar, inkludera snabbsvar och svarsmallar med säkra variabler (namn, ordernummer, SLA-datum). Mallar bör vara sökbara och redigerbara av auktoriserade ledare.
Förhindra kollisioner (två agenter, ett ärende)
Lägg till kollisionshantering: när en agent öppnar ett ärende, placera ett kortlivat “visa/redigera-lås” eller en banner “hanteras för närvarande av”. Om någon annan försöker svara, varna dem och kräva en bekräftelse för att skicka (eller blockera sändning) för att undvika dubbletter och motstridiga svar.
Implementera SLA-regler, timers och eskalationer
SLA:er hjälper bara om alla är överens om vad som mäts och appen upprätthåller det konsekvent. Börja med att omvandla “vi svarar snabbt” till policys som ditt system kan beräkna.
Definiera SLA-policys (vad ni kommer att mäta)
De flesta team börjar med två timers per ärende:
- Tid till första svar: tid från ärendets skapande till första agentsvar (eller första icke-automatiska publika svar).
- Lösningstid: tid från ärendets skapande till “Löst/Stängt.”
Håll policys konfigurerbara efter prioritet, kanal eller kundnivå (till exempel: VIP får 1 timmes första svar, Standard får 8 arbetstimmar).
Bestäm när SLA-klockor startar och stoppar
Skriv reglerna innan du kodar, eftersom kantfall snabbt hopar sig:
- Arbetstider vs. 24/7: definiera en kalender (tidszon, veckodagar, helgdagar).
- Pausade tillstånd: stoppa klockan när ärendet är i “Väntar på kund” eller “Väntar på extern leverantör.”
- Återuppta villkor: återstarta när kunden svarar eller tillståndet ändras tillbaka till “Öppet/Pågående.”
Spara SLA-händelser (startad, pausad, återupptagen, överträdelse) så att du senare kan förklara varför något överträdde.
Gör SLA-status uppenbar i UI
Agenter ska inte behöva öppna ett ärende för att upptäcka att det snart kommer att överträda. Lägg till:
- En nedräkningstimer (återstående tid)
- Förtida- och överskridningsflagga med tydlig allvarlighetsgrad (varning vs. överträdd)
- Valfria aviseringar (i-app, e-post eller chat) när en tröskel närmar sig
Bygg eskalationsvägar
Eskalering ska vara automatisk och förutsägbar:
- Informera en teamledare vid 80 % av tillåten tid
- Omtilldela till en jourkö om det överträds
- Öka prioritet eller lägg till en “Eskalerad”-tagg
Planera SLA-rapportering
Som minimum, följ antal överträdelser, överträdelsegrad och trend över tid. Logga också orsaker till överträdelser (pausad för länge, fel prioritet, underbemannad kö) så att rapporter leder till åtgärder, inte skuldbeläggning.
Skapa en kunskapsdatabas som minskar upprepade ärenden
En bra kunskapsdatabas (KB) är inte bara en mapp av FAQ:er – det är en produktfunktion som ska minska upprepade frågor och snabba upp lösningar mäkbart. Designa den som en del av ditt ärendehanteringsflöde, inte som en separat “dokumentationssajt.”
Struktur: gör innehållet lätt att underhålla
Börja med en enkel informationsmodell som skalar:
- Kategorier → sektioner → artiklar (lätt navigering för kunder och agenter)
- Taggar för tvärgående ämnen (fakturering, inloggning, integrationer) utan att duplicera artiklar
- Tydligt ägarskap (vem granskar vad) så innehållet hålls aktuellt
Håll artikelmallar konsekventa: problembeskrivning, steg-för-steg-fix, skärmdumpar valfritt, och “Om detta inte hjälpte…” med vägledning som leder till rätt ärendeformulär eller kanal.
Sökmotor som faktiskt hittar svar
De flesta KB-misslyckanden är sökfel. Implementera sök med:
- Relevansinställning (titel/rubrik-boost, färskhetsboost)
- Synonymer (t.ex. “invoice” ↔ “bill”, “2FA” ↔ “authentication code”)
- Felavkänslighet och stamning (plural/singular)
Indexera också anonymiserade ärendeämnen för att lära dig kundernas ordval och mata din synonymlista.
Utkast, granskningar och publiceringsgodkännanden
Lägg till ett lättviktigt arbetsflöde: utkast → granskning → publicerat, med valbar schemalagd publicering. Spara versionshistorik och inkludera metadata för “senast uppdaterad”. Para ihop detta med roller (författare, granskare, publicerare) så inte varje agent kan redigera offentliga dokument.
Mät vad som minskar ärenden
Spåra mer än sidvisningar. Användbara mått inkluderar:
- Hjälpsamma röster (ja/nej) och “vad saknades?”-feedback
- Avledningsindikatorer: sökning → artikel visad → inget ärende skapat inom X timmar
- Toppsökningar utan bra resultat (innehållsgap)
Länka artiklar till ärenden där arbetet sker
I agentens svarskomponent, visa föreslagna artiklar baserat på ärendets ämne, taggar och upptäckt av avsikt. Ett klick ska infoga en publik länk (t.ex. /help/account/reset-password) eller ett internt utdrag för snabbare svar.
Gör KB:n till din första försvarslinje: kunder löser problem själva, och agenter hanterar färre upprepade ärenden med högre konsekvens.
Ställ in roller, behörigheter och revisionsspårbarhet
Behåll full kontroll
Exportera källkoden när som helst så att ditt team kan vidareutveckla och äga projektet.
Behörigheter är där ett ärendehanteringsverktyg antingen förblir säkert och förutsägbart—eller blir rörigt snabbt. Vänta inte tills efter lansering med att “låsa ner” systemet. Modellera åtkomst tidigt så team kan röra sig snabbt utan att exponera känsliga ärenden eller låta fel personer ändra systemregler.
Separera roller (och håll dem enkla)
Börja med några tydliga roller och lägg till nyanser bara när du ser ett verkligt behov:
- Agent: arbetar med ärenden, lägger till anteckningar, svarar, uppdaterar fält.
- Ledare: allt en agent kan göra, plus omfördelning, köhantering och coachningsarbetsflöden.
- Admin: systemomfattande inställningar som kanaler, användarhantering och konfiguration.
- Innehållsredaktör: skapar och publicerar kunskapsdatabasartiklar.
- Endast läsning: revision, ekonomi, juridik eller intressenter som behöver insyn utan att göra ändringar.
Definiera behörigheter efter förmåga
Undvik “allt-eller-inget”-åtkomst. Behandla större åtgärder som explicita behörigheter:
- Visa vs redigera ärenden (inklusive privata anteckningar)
- Hantera makron/snabbmallar
- Redigera SLA-regler, timers och eskaleringspolicys
- Publicera/avpublicera kunskapsinnehåll
Detta gör det enklare att ge minsta möjliga behörighet och att stödja tillväxt (nya team, nya regioner, kontraktörer).
Teambaserad åtkomst för känsliga köer
Vissa köer bör vara begränsade som standard—fakturering, säkerhet, VIP eller HR-relaterade förfrågningar. Använd teammedlemskap för att kontrollera:
- Vilka köer som syns
- Vem som kan omfördela eller slå ihop ärenden
- Om kunddatafält ska maskeras
Revisionsloggar du faktiskt kommer att använda
Logga viktiga åtgärder med vem, vad, när och före/efter-värden: tilldelningsändringar, raderingar, SLA-/policyändringar, rolländringar och KB-publiceringar. Gör loggar sökbara och exportera så utredningar inte kräver databasåtkomst.
Planera multi-brand eller multi-inkorg tidigt
Om du stödjer flera varumärken eller inkorgar, bestäm om användare kan byta kontext eller om åtkomst partitioneras. Detta påverkar behörighetskontroller och rapportering och bör vara konsekvent från dag ett.
Designa agent- och administratörsanvändarupplevelsen
Ett ärendehanteringssystem vinner eller förlorar på hur snabbt agenter kan förstå en situation och ta nästa åtgärd. Behandla agentarbetsytan som din “startskärm”: den ska omedelbart svara på tre frågor—vad hände, vem är den här kunden, och vad bör jag göra härnäst.
Layout för agentarbetsytan
Börja med en delad vy som håller kontexten synlig medan agenter arbetar:
- Konversationstråd (e-post/chatt/meddelanden) med tydliga tidsstämplar, bilagor och citeringar.
- Kundpanel med identitet, plan/konto-nivå, organisation, tidigare ärenden och nyckelanteckningar.
- Ärendefält (status, prioritet, kö, ansvarig, taggar, SLA-timers) grupperade logiskt, inte utspridda.
Håll tråden läsbar: skilj kund vs agent vs systemhändelser, och gör interna anteckningar visuellt distinkta så de aldrig skickas av misstag.
Enklicksåtgärder som tar bort friktion
Placera vanliga åtgärder där markören redan är—nära senaste meddelandet och högst upp i ärendet:
- Tilldela / omfördela
- Byt status (inklusive “väntar på kund”)
- Lägg till intern anteckning
- Använd makro (förifyllt svar + fältuppdateringar)
Sträva efter “ett klick + valfri kommentar”-flöden. Om en åtgärd kräver en modal, gör den kort och tangentbordsvänlig.
Hastighetsfunktioner för högvolymteam
Höggenomströmmande support behöver genvägar som känns förutsägbara:
- Tangentbordsgenvägar för svar, anteckning, tilldela till mig, stäng och nästa ärende
- Massåtgärder i listvyer (tagga, tilldela, stänga, slå ihop)
- Ett snabbt kommandopalett för kraftanvändare
Tillgänglighet och UI-säkerhet
Bygg tillgänglighet från dag ett: tillräcklig kontrast, synliga fokusindikatorer, full tabb-navigering och skärmläsarlabels för kontroller och timers. Förhindra kostsamma misstag med små skydd: bekräfta destruktiva åtgärder, märk tydligt “publikt svar” vs “intern anteckning”, och visa vad som kommer att skickas innan sändning.
Admin- och kundportal-UX
Admin behöver enkla, vägledande skärmar för köer, fält, automationer och mallar—undvik att gömma det viktiga bakom invecklade inställningar.
Om kunder kan skicka in och följa ärenden, designa en lätt portal: skapa ärende, se status, lägg till uppdateringar och se föreslagna artiklar innan inskick. Håll den konsekvent med ditt publika varumärke och länka från /help.
Planera integrationer, API:er och omnikanal-intag
Planera arbetsflödet först
Använd Planning Mode för att kartlägga tillstånd, fält och SLA:er innan du genererar kod.
En ärendeapp blir användbar när den kopplas till de platser kunder redan pratar med dig—och de verktyg ditt team förlitar sig på för att lösa problem.
Börja med systemen du måste koppla
Lista dina “dag ett”-integrationer och vilken data du behöver från varje:
- E-post (delade inkorgar, vidarebefordringsregler, utgående SMTP)
- Chatt (webbwidget, WhatsApp, verktyg i Intercom-stil)
- CRM (kontekontext, ägare, plannivå)
- Fakturering (prenumerationsstatus, fakturor, återbetalningar)
- Identitetsleverantör (SSO via Google/Microsoft, SCIM-user provisioning)
Skriv vilken riktning datan flödar (read-only vs skriv tillbaka) och vem som äger varje integration internt.
Designa ditt API och webhooks tidigt
Även om du levererar integrationer senare, definiera stabila primitiva nu:
- API-endpoints för ärende create, update, search, plus kommentarer/meddelanden och statusändringar.
- Webhooks för nyckelhändelser (ticket.created, ticket.updated, message.received, sla.breached) så externa system kan reagera.
Håll autentisering förutsägbar (API-nycklar för servrar; OAuth för användarinstallerade appar), och versionera API:t för att undvika att bryta kunder.
Förhindra duplicerade ärenden med solid e-posttrådning
E-post är där röriga kantfall visar sig först. Planera hur du kommer att:
- Tråda svar med Message-ID / In-Reply-To / References-huvuden
- Parsade vidarebefordrade meddelanden och vanliga signaturer säkert
- Deduplikation genom att upptäcka upprepade inkommande payloads (särskilt från mail-leverantörer)
En liten investering här undviker “varje svar skapar ett nytt ärende”-katastrofer.
Hantera bilagor säkert
Stöd bilagor, men med skydd: filtyp-/storleksgränser, säker lagring och hooks för virusgenomsökning (eller en skanningstjänst). Överväg att strippa farliga format och rendera aldrig otillförlitlig HTML inline.
Dokumentera setup som en produktfunktion
Skapa en kort integrationsguide: nödvändiga behörigheter, steg-för-steg-konfiguration, felsökning och teststeg. Om du underhåller docs, hänvisa till din integrationshub på /docs så administratörer inte behöver ingenjörshjälp för att koppla system.
Lägg till analys och rapportering för supportprestanda
Analys är där ditt ärendehanteringssystem går från “en plats att jobba i” till “ett sätt att förbättra”. Nyckeln är att fånga rätt händelser, beräkna ett par konsekventa mått och presentera dem för olika målgrupper utan att exponera känslig data.
Börja med ett händelsspår (inte bara aktuellt ärendetillstånd)
Spara de ögonblick som förklarar varför ett ärende ser ut som det gör. Minst, spåra: statusändringar, kund- och agentsvar, tilldelningar och omfördelningar, prioritet/kategori-uppdateringar och SLA-timerevent (start/stop, pauser och överträdelser). Detta låter dig svara på frågor som “Överträddes vi för att vi var underbemannade, eller för att vi väntade på kunden?”
Håll händelser append-only där det är möjligt; det gör revision och rapportering mer trovärdig.
Instrumentpaneler för teamledare
Ledare behöver vanligtvis operativa vyer de kan agera på idag:
- Backlog per kö, prioritet och kategori
- Åldrande ärenden (t.ex. äldsta öppna, äldsta väntande kund)
- SLA-risk (ärenden som sannolikt överträder inom X timmar)
- Agentbelastning (antal tilldelade, aktivt arbete, tid sedan senaste uppdatering)
Gör dessa instrumentpaneler filtrerbara efter tidsintervall, kanal och team—utan att tvinga chefer till kalkylblad.
Rapporter för ledningen
Ledningen bryr sig mindre om enskilda ärenden och mer om trender:
- Volym per kategori/kanal, inklusive toppdagar och -timmar
- Första svar och löstrend (median och 90:e percentil)
- CSAT-trender (och svarsfrekvens, så poängen inte blir missvisande)
Om du kopplar utfall till kategorier kan du motivera bemanning, utbildning eller produktfixar.
Filter, export och åtkomstkontroller
Lägg till CSV-export för vanliga vyer, men skydda den med behörigheter (och helst fält-nivåkontroller) för att undvika läckage av e-post, meddelandetexter eller kundidentifierare. Logga vem som exporterade vad och när.
Dataretention utan riskfyllda löften
Definiera hur länge du behåller ärendehändelser, meddelandeinnehåll, bilagor och analysaggregeringar. Föredra konfigurerbara retention-inställningar och dokumentera vad du faktiskt raderar vs anonymiserar så du inte lovar garantier du inte kan verifiera.
Välj en praktisk arkitektur och techstack
Ett ärendesystem behöver inte en komplex arkitektur för att vara effektiv. För de flesta team är en enkel setup snabbare att leverera, enklare att underhålla och skalar fortfarande bra.
Börja med ett tydligt systemdiagram
En praktisk baslinje ser ut så här:
- Webbfrontend: agent-/admin-UI plus kundformulär och portal
- API-backend: affärsregler för ärenden, SLA:er, användare och kunskapsdatabas
- Databas: sanningskälla för ärenden, användare, händelser och inställningar
- Bakgrundsjobb: allt tidsbaserat eller långt körande arbete
Denna “modulära monolit”-ansats (en backend, tydliga moduler) håller v1 hanterbar samtidigt som det lämnar utrymme att dela upp tjänster senare vid behov.
Om du vill snabba på en v1-byggnation utan att uppfinna hela leveranspipen kan en vibe-coding-plattform som Koder.ai hjälpa dig att prototypa agentpanelen, ärendelivscykeln och adminskärmar via chat—för att sedan exportera källkod när du är redo att ta full kontroll.
Veta vad som måste köras i bakgrunden
Ärendesystem känns realtidsbetonade, men mycket arbete är asynkront. Planera bakgrundsjobb tidigt för:
- SLA-timers och eskalationer (t.ex. “första svar ska ske inom 30 minuter”)
- Aviseringar (e-post, in-app, webhooks)
- Sökindeksering (ärenden och kunskapsartiklar)
- Inkommande e-postprocessning (parsning, bilagor, trådning)
Om bakgrundsprocessning är en eftertanke blir SLA:er opålitliga och agenter tappar förtroende.
Spara data för korrekthet, sök för hastighet
Använd en relationsdatabas (PostgreSQL/MySQL) för kärnposter: ärenden, kommentarer, statusar, tilldelningar, SLA-policys och en revisions-/händelsetabell.
För snabb sökning och relevans, ha en separat sökindex (Elasticsearch/OpenSearch eller en managed motsvarighet). Försök inte få din relationsdatabas att göra fulltextsökning i skala om din produkt är beroende av det.
Bestäm bygga vs köpa (och varför)
Tre områden sparar ofta månader om de köps:
- Autentisering: använd en beprövad leverantör (SSO, MFA, lösenordspolicy)
- E-postleverans: transaktionstjänst för leveransbarhet och bounce-hantering
- Sök: hanterad sökning om ni saknar intern expertis
Bygg de saker som differentierar dig: arbetsflödesregler, SLA-beteende, routinglogik och agentupplevelsen.
Planera milstolpar med en tydlig v1-lista
Skatta arbete efter milstolpar, inte funktioner. En solid v1-milstolpslista är: ärende-CRUD + kommentarer, grundläggande tilldelning, SLA-timers (kärna), e-postaviseringar, minimal rapportering. Håll “trevligt att ha” (avancerad automation, komplexa roller, djup analys) uttryckligen utanför scope tills v1-användning visar vad som verkligen betyder något.
Täcka grundläggande säkerhet, integritet och tillförlitlighet
Från specifikation till fungerande app
Förvandla din ärendemodell och livscykel till fungerande React-skärmar och en Go-API.
Säkerhets- och tillförlitlighetsbeslut är enklare (och billigare) när du bygger in dem tidigt. En supportapp hanterar känsliga konversationer, bilagor och kontouppgifter—så behandla den som ett kärnsystem, inte ett sidoutil.
Skydda kunddata som standard
Börja med kryptering i transit överallt (HTTPS/TLS), inklusive interna service-till-service-anrop om du har flera tjänster. För data i vila: kryptera databaser och objektlagring (bilagor), och lagra hemligheter i en hanterad vault.
Använd minsta möjliga åtkomst: agenter ska bara se de ärenden de får hantera, och administratörer bör ha höjda rättigheter bara när det behövs. Lägg till åtkomstloggning så du kan svara på “vem visade/exporterade vad, och när?” utan gissningar.
Välj autentisering som matchar din publik
Autentisering är inte en-size-fits-all. För små team räcker e-post + lösenord. Om du säljer till större organisationer kan SSO (SAML/OIDC) vara ett krav. För lätta kundportaler kan magiska länkar minska friktion.
Oavsett val, se till att sessioner är säkra (kortlivade tokens, refresh-strategi, säkra cookies) och lägg till MFA för adminkonton.
Förhindra vanliga attacker innan de börjar
Sätt rate limiting på inloggning, ärendeskapande och sök-endpoints för att bromsa brute-force och spam. Validera och sanera input för att förhindra injection-problem och osäker HTML i kommentarer.
Om du använder cookies, lägg till CSRF-skydd. För API:er, applicera strikta CORS-regler. För filuppladdningar, skanna efter skadlig kod och begränsa typer och storlekar.
Backup, återställning och mätbara mål
Definiera RPO/RTO-mål (hur mycket data ni kan förlora, hur snabbt ni måste vara tillbaka). Automatisera backups för databaser och fil-lagring, och—viktigt—testa återställningar regelbundet. En backup du inte kan återställa är ingen backup.
Integritetsgrunder användare kommer att fråga om
Supportappar omfattas ofta av integritetsbegäranden. Ge ett sätt att exportera och radera kunddata, och dokumentera vad som tas bort vs behålls för juridiska/revisionsskäl. Håll revisionsspår och åtlogsningar tillgängliga för administratörer (se /security) så du snabbt kan utreda incidenter.
Testa, lansera och förbättra med riktiga supportteam
Att leverera en kundsupportwebbapp är inte mållinjen—det är början på att lära sig hur riktiga agenter arbetar under verklig press. Målet med testning och utrullning är att skydda daglig support samtidigt som du verifierar att ditt ärendehanteringssystem och SLA-hantering fungerar korrekt.
Skriv end-to-end-testscenarier som matchar verkligt arbete
Utöver enhetstester, dokumentera (och automatisera där möjligt) ett litet antal end-to-end-scenarier som speglar era högst riskfyllda flöden:
- Ärendeskapande: e-post/webbformulär/API-intag skapar ett ärende med rätt fält, kundidentitet och initial status.
- Svar och trådning: kundsvar bifogas rätt ärende, agentsvar notifierar kunden, interna anteckningar förblir interna.
- SLA-överträdelse: timers startar/stannar korrekt (t.ex. paus på “Väntar på kund”), överträdelser triggar rätt eskalation och revisionsspåret registrerar vad som hände.
- Kunskapsbas-sökning: agenter hittar snabbt relevanta artiklar från ärendevyn, och kunder ser hjälpsamma förslag innan inskick.
Om ni har en stagingmiljö, fyll den med realistiska data (kunder, taggar, köer, arbetstider) så tester inte bara passerar “i teorin”.
Kör en pilot och samla feedback veckovis
Börja med en liten supportgrupp (eller en enda kö) i 2–4 veckor. Ha en veckovis feedbackritual: 30 minuter för att granska vad som saktade ner dem, vad som förvirrade kunder och vilka regler som orsakade överraskningar.
Håll feedback strukturerad: “Vilken uppgift?”, “Vad förväntade du dig?”, “Vad hände?” och “Hur ofta inträffar detta?” Detta hjälper er prioritera fixar som påverkar genomströmning och SLA-efterlevnad.
Skapa en onboarding-checklista för admin och agenter
Gör onboarding repeterbar så utrullningen inte hänger på en person.
Inkludera essentials som: logga in, kövyer, svara vs interna anteckningar, tilldela/omnämna, byta status, använda makron, läsa SLA-indikatorer och hitta/skapa KB-artiklar. För admins: hantera roller, arbetstider, taggar, automationer och grundläggande rapportering.
Planera en stegrad utrullning (med rollback-alternativ)
Rulla ut per team, kanal eller ärendetyp. Definiera en rollback-väg i förväg: hur ni temporärt kommer att återgå intag, vilken data som kan behöva synkas om och vem tar beslutet.
Team som bygger på Koder.ai lutar sig ofta mot snapshots och rollback under tidiga piloter för att säkert iterera på arbetsflöden (köer, SLA:er och portalformulär) utan att störa live-driften.
Sätt en iterativ roadmap
När piloten stabiliserats, planera förbättringar i vågor:
- Bättre automatiseringsregler (makron, triggers, auto-tagging)
- Avancerad routing (kompetensbaserad tilldelning, load balancing)
- Rikare KB-arbetsflöden (artikelgranskningar, feedback-loopar, avledningsmetrik)
Behandla varje våg som en liten release: testa, pilota, mät och expandera.