11 mars 2025·8 min
Hur man bygger en webbapp för operativ riskspårning
Steg-för-steg-plan för att designa, bygga och lansera en webbapp för operativ riskspårning: krav, datamodell, arbetsflöden, kontroller, rapportering och säkerhet.
Steg-för-steg-plan för att designa, bygga och lansera en webbapp för operativ riskspårning: krav, datamodell, arbetsflöden, kontroller, rapportering och säkerhet.
Innan du designar skärmar eller väljer teknisk plattform, var tydlig med vad “operativ risk” betyder i din organisation. Vissa team använder det för processfel och mänskliga misstag; andra inkluderar IT-avbrott, leverantörsproblem, bedrägeri eller externa händelser. Om definitionen är oklar kommer appen att bli en soptunna — och rapporteringen blir opålitlig.
Skriv en tydlig beskrivning av vad som räknas som operativ risk och vad som inte gör det. Du kan rama in det som fyra fack (process, människor, system, externa händelser) och lägga till 3–5 exempel för varje. Detta minskar framtida tvister och håller datan konsekvent.
Var specifik kring vad appen måste uppnå. Vanliga mål är:
Om du inte kan beskriva resultatet är det troligen en funktionsönskan — inte ett krav.
Lista rollerna som kommer använda appen och vad de behöver mest:
Detta förhindrar att du bygger för “alla” och nöjer ingen.
En praktisk v1 för operativ riskspårning fokuserar vanligtvis på: ett riskregister, grundläggande riskscoring, åtgärdsspårning och enkel rapportering. Spara djupare funktioner (avancerade integrationer, komplex taxonomihantering, anpassade arbetsflödesbyggare) till senare faser.
Välj mätbara signaler som: andel risker med ägare, fullständighet i riskregistret, tid till stängning av åtgärder, andel försenade åtgärder och genomförda granskningar i tid. Dessa mått gör det enklare att avgöra om appen fungerar — och vad som ska förbättras.
Ett riskregister fungerar bara om det matchar hur människor faktiskt identifierar, bedömer och följer upp operativ risk. Innan ni pratar funktioner, tala med de som kommer använda (eller bli bedömda av) resultaten.
Starta med en liten, representativ grupp:
I workshops, kartlägg det verkliga arbetsflödet steg för steg: identifiering av risk → bedömning → åtgärd → övervakning → granskning. Fånga var beslut fattas (vem godkänner vad), vad “klart” betyder och vad som triggar en översyn (tidsbaserat, incidentbaserat eller tröskelbaserat).
Låt intressenter visa nuvarande kalkylblad eller e-postspår. Dokumentera konkreta problem som:
Skriv ned minimala arbetsflöden appen måste stödja:
Enas om outputs tidigt för att undvika omarbete. Vanliga behov inkluderar styrefterföljande sammanfattningar, affärsenhetsvyer, försenade åtgärder och topp-risker efter poäng eller trend.
Lista regler som formar krav — t.ex. lagringsperioder, sekretessbegränsningar för incidentdata, segregation av uppgifter, bevis för godkännande och åtkomstbegränsningar per region eller enhet. Håll det sakligt: du samlar begränsningar, inte påstår automatisk efterlevnad.
Innan ni bygger skärmar eller arbetsflöden, enas om vokabulären appen ska tvinga fram. Tydlig terminologi förhindrar “samma risk, olika ord” och gör rapporteringen pålitlig.
Definiera hur risker ska grupperas och filtreras i riskregistret. Håll det användbart för dagligt arbete såväl som för instrumentpaneler och rapporter.
Typiska taxonominivåer inkluderar kategori → subkategori, mappat till affärsenheter och (där det är hjälpsamt) processer, produkter eller platser. Undvik en taxonomi så detaljerad att användarna inte kan välja konsekvent; finjustera senare när mönster framträder.
Enas om ett konsekvent format för riskuttalandet (t.ex. “På grund av orsak, kan händelse inträffa, vilket leder till påverkan”). Bestäm sedan vad som är obligatoriskt:
Denna struktur knyter kontroller och incidenter till en enda berättelse i stället för spridda anteckningar.
Välj de bedömningsdimensioner ni ska stödja i er poängmodell. Sannolikhet och påverkan är minimum; hastighet och upptäckbarhet kan lägga värde om folk faktiskt kommer att bedöma dem konsekvent.
Bestäm hur ni hanterar inneboende vs. återstående risk. En vanlig metod: inneboende risk poängsätts före kontroller; återstående risk är efter-kontrollpoängen, med kontroller länkade explicit så logiken är förklarlig vid granskningar och revisioner.
Slutligen, enas om en enkel betygsskala (ofta 1–5) och skriv vardagliga definitioner för varje nivå. Om “3 = medel” betyder olika saker för olika team kommer bedömningarna att skapa brus i stället för insikt.
En tydlig datamodell förvandlar ett kalkylbladsliknande register till ett system du kan lita på. Sikta på en liten uppsättning kärnposter, rena relationer och konsekventa referenslistor så rapporteringen förblir tillförlitlig när användningen växer.
Börja med några tabeller som speglar hur folk arbetar:
Modellera kritiska många-till-många-länkar explicit:
Denna struktur stödjer frågor som “Vilka kontroller minskar våra topp-risker?” och “Vilka incidenter drev en poängändring?”
Operativ riskspårning behöver ofta försvarbar ändringshistorik. Lägg till historik-/revisionstabeller för Risks, Controls, Assessments, Incidents och Actions med:
Undvik att bara lagra “senast uppdaterad” om godkännanden och revisioner förväntas.
Använd referenstabeller (inte hårdkodade strängar) för taxonomi, status, svårighets-/sannolikhetsskala, kontrolltyper och åtgärdsstatus. Detta förhindrar att rapportering bryts av stavfel (“High” vs. “HIGH”).
Behandla bevis som första-klassens data: en Attachments-tabell med filmetadata (namn, typ, storlek, uppladdare, länkad post, uppladdningsdatum), plus fält för retentions-/raderingsdatum och åtkomstklassificering. Lagra filer i objektlagring, men behåll styrningsreglerna i databasen.
En riskapp misslyckas snabbt när “vem gör vad” är oklart. Innan du bygger skärmar, definiera arbetsflödesstater, vem som kan flytta objekt mellan stater och vad som måste fångas vid varje steg.
Börja med en liten uppsättning roller och expandera endast vid behov:
Gör behörigheter explicita per objekttyp (risk, kontroll, åtgärd) och per möjlighet (skapa, redigera, godkänna, stänga, återöppna).
Använd en tydlig livscykel med förutsägbara grindar:
Knyt SLA:er till granskningscykler, kontrolltestning och åtgärders förfallodatum. Skicka påminnelser före förfallodatum, eskalera efter missade SLA:er och visa förfallna objekt tydligt (för ägare och deras chefer).
Varje post ska ha en ansvarig ägare plus valfria medarbetare. Stöd delegation och omfördelning, men kräva en orsak (och valfritt ett ikraftträdandedatum) så läsare förstår varför ägarskapet ändrades och när ansvaret övergick.
En riskapp lyckas när människor faktiskt använder den. För icke-tekniska användare är den bästa UX:en förutsägbar, låg tröskel och konsekvent: tydliga etiketter, minimal jargong och tillräcklig vägledning för att undvika vaga “övrigt”-poster.
Ditt intaxformulär ska kännas som en guidad konversation. Lägg in kort hjälptext under fälten (inte långa instruktioner) och markera verkligen obligatoriska fält.
Inkludera det viktigaste: titel, kategori, process/område, ägare, nuvarande status, initial poäng och “varför detta är viktigt” (påverkansberättelse). Om du använder poängsättning, bädda in verktygstips bredvid varje faktor så användare förstår definitionerna utan att lämna sidan.
De flesta användare kommer att leva i listvyn, så gör den snabb att svara på: “Vad behöver uppmärksamhet?”
Erbjud filter och sortering för status, ägare, kategori, poäng, senaste granskningsdatum och förfallna åtgärder. Markera undantag (förfallna granskningar, försenade åtgärder) med subtila badges — inte larmfärger överallt — så uppmärksamheten går till rätt poster.
Detaljskärmen ska läsa som en sammanfattning först, sedan stödjande information. Håll toppen fokuserad: beskrivning, nuvarande poäng, senaste granskning, nästa granskning och ägare.
Under detta, visa länkade kontroller, incidenter och åtgärder som separata sektioner. Lägg till kommentarer för kontext (“varför vi ändrade poängen”) och bilagor för bevis.
Åtgärder behöver tilldelning, förfallodatum, framsteg, bevisuppladdningar och tydliga slutkriterier. Gör avslutande explicit: vem godkänner stängning och vilka bevis som krävs.
Om du behöver en referenslayout, håll navigeringen enkel och konsekvent över skärmar (/risks, /risks/new, /risks/{id}, /actions).
Riskscoring är där appen blir handlingsbar. Målet är inte att “betygsätta” team, utan att standardisera hur ni jämför risker, prioriterar åtgärder och ser till att poster inte blir inaktuella.
Börja med en enkel, förklarbar modell som fungerar över de flesta team. Ett vanligt standardval är en 1–5-skala för Sannolikhet och Påverkan, med en beräknad poäng:
Skriv tydliga definitioner för varje värde (vad “3” innebär, inte bara numret). Placera denna dokumentation vid fälten i UI (verktygstips eller en “Hur poängsättning fungerar”-panel) så användare slipper leta.
Siffror i sig driver inte beteende — trösklar gör det. Definiera gränser för Låg / Medel / Hög (och eventuellt Kritisk) och bestäm vad varje nivå utlöser.
Exempel:
Håll trösklar konfigurerbara, eftersom vad som räknas som “Hög” varierar per affärsenhet.
Operativa riskdiskussioner fastnar ofta när folk pratar förbi varandra. Lös det genom att separera:
I UI, visa båda poängen sida vid sida och visa hur kontroller påverkar återstående risk (t.ex. en kontroll kan minska Sannolikhet med 1 eller Påverkan med 1). Undvik att dölja logik bakom automatiska justeringar som användare inte kan förklara.
Lägg till tidsbaserad granskningslogik så risker inte blir inaktuella. En praktisk baslinje är:
Gör granskningsfrekvens konfigurerbar per affärsenhet och tillåt undantag per risk. Automatisera sedan påminnelser och status “granskning försenad” baserat på senaste granskningsdatum.
Gör beräkningen synlig: visa Sannolikhet, Påverkan, eventuella kontrolljusteringar och slutlig återstående poäng. Användare ska kunna svara “Varför är detta Högt?” vid en titt.
Ett operativt riskverktyg är bara så trovärdigt som dess historia. Om en poäng ändras, en kontroll markeras “testad” eller en incident omklassificeras, behöver du svar på: vem gjorde vad, när och varför.
Starta med en tydlig händelselista så du inte missar viktiga åtgärder eller översvämmer loggen med brus. Vanliga audithändelser inkluderar:
Minst, lagra aktör, tidsstämpel, objekttyp/ID och vilka fält som ändrades (gamla värdet → nytt värde). Lägg till en valfri “orsak till ändring”-anteckning — det förhindrar förvirrande fram- och tillbaka senare.
Håll revisionsloggen append-only. Tillåt inte redigeringar, inte ens av admins; om en korrigering behövs, skapa en ny händelse som refererar den tidigare.
Revisorer och administratörer behöver typiskt en dedikerad, filtrerbar vy: efter datumintervall, objekt, användare och händelsetyp. Gör det enkelt att exportera från denna skärm samtidigt som exporten själv loggas. Om du har ett adminområde, länka det från /admin/audit-log.
Bevisfiler (skärmdumpar, testresultat, policyer) bör versionshanteras. Behandla varje uppladdning som en ny version med egen tidsstämpel och uppladdare, och bevara tidigare filer. Om ersättningar tillåts, kräva en orsak och behåll båda versionerna.
Sätt retentionregler (t.ex. spara audit-händelser i X år; rensa bevis efter Y om inte under juridiskt hold). Begränsa åtkomst till bevis med striktare behörigheter än själva riskposten när de innehåller personuppgifter eller säkerhetsdetaljer.
Säkerhet och sekretess är inte “extras” för en riskapp — de formar hur bekväma människor är med att logga incidenter, bifoga bevis och tilldela ägarskap. Börja med att kartlägga vem som behöver åtkomst, vad de bör se och vad som måste begränsas.
Om din organisation redan använder en identitetsleverantör (Okta, Azure AD, Google Workspace), prioritera Single Sign-On via SAML eller OIDC. Det minskar lösenordsrisk, förenklar onboarding/offboarding och stämmer med företagsrutiner.
Om du bygger för mindre team eller externa användare kan e-post/lösenord fungera — men kombinera det med starka lösenordsregler, säker kontåterställning och (där möjligt) MFA.
Definiera roller som reflekterar verkliga ansvar: admin, riskägare, granskare/godkännare, bidragsgivare, läsbehörig, revisor.
Operativ risk kräver ofta tajtare gränser än ett vanligt internt verktyg. Överväg RBAC som kan begränsa åtkomst:
Håll behörigheter begripliga — folk ska snabbt förstå varför de kan eller inte kan se en post.
Använd kryptering i transit (HTTPS/TLS) överallt och följ principen least privilege för tjänster och databaser. Sessioner ska skyddas med säkra cookies, korta idle-timeouter och server-side invalidation vid utloggning.
Inte alla fält har samma risk. Incidentberättelser, kundpåverkansnoteringar eller medarbetardetaljer kan behöva striktare kontroll. Stöd fältbaserad synlighet (eller åtminstone maskning) så användare kan samarbeta utan att exponera känsligt innehåll brett.
Lägg till praktiska skydd:
Gör detta väl och kontrollera data samtidigt som rapportering och åtgärdsflöden förblir smidiga.
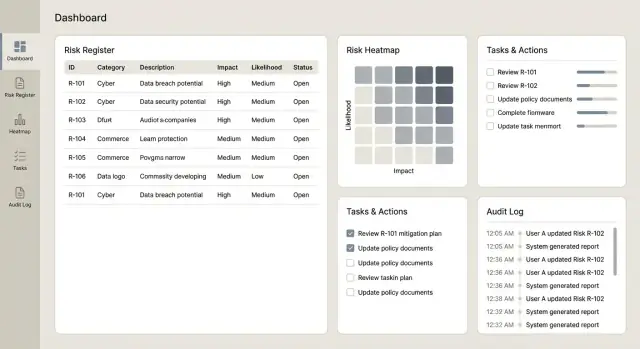
Instrumentpaneler och rapporter är där appen visar sitt värde: de förvandlar ett långt register till tydliga beslut för ägare, chefer och kommittéer. Nyckeln är att göra siffrorna spårbara tillbaka till underliggande regler och poster.
Börja med en liten uppsättning högsignalvyer som snabbt svarar vanliga frågor:
Gör varje ruta klickbar så användare kan borra ner i exakt lista av risker, kontroller, incidenter och åtgärder bakom diagrammet.
Beslutsinstrumentpaneler skiljer sig från operationella vyer. Lägg till skärmar fokuserade på vad som behöver uppmärksamhet den här veckan:
Dessa vyer fungerar bra med påminnelser och uppgiftsansvar så appen känns som ett arbetsflödesverktyg, inte bara en databas.
Planera exporter tidigt, eftersom kommittéer ofta väntar på offline-paket. Stöd CSV för analys och PDF för läsdistribution, med:
Om du redan har en styrningsmall, spegla den så adoptionen blir enkel.
Säkerställ att varje rapportdefinition matchar er poänglogik. Om instrumentpanelen rangordnar “topp-risker” efter återstående poäng måste det stämma överens med samma beräkning på posten och i exporterna.
För stora register, designa för prestanda: pagination på listor, caching för vanliga aggregat och asynkron rapportgenerering (generera i bakgrunden och notifiera när klar). Om ni senare lägger till schemalagda rapporter, spara konfigurationerna internt (t.ex. öppna från /reports).
Integrationer och migration avgör om appen blir systemet för sanning — eller bara en plats folk glömmer uppdatera. Planera tidigt, men implementera stegvis så ni kan hålla kärnprodukten stabil.
De flesta team vill inte ha “ännu en uppgiftslista”. De vill att appen kopplas till där arbetet sker:
En praktisk strategi är att låta riskappen äga riskdatan, medan externa verktyg hanterar exekveringsdetaljer (tickets, assignees, förfallodatum) och matar tillbaka statusuppdateringar.
Många organisationer börjar i Excel. Erbjud en import som accepterar vanliga format, men lägg in skydd:
Visa en förhandsgranskning av vad som kommer skapas, vad som avvisas och varför. Den skärmen kan spara timmar av fram- och tillbaka.
Även om du börjar med en integration, designa API:et som om du kommer ha flera:
Integrationer misslyckas av normala skäl: token går ut, nätverkstidsgränser, raderade ärenden. Bygg för det:
Detta håller förtroendet högt och förhindrar tyst drift mellan registret och exekveringsverktygen.
En riskspårningsapp blir värdefull när folk litar på den och använder den konsekvent. Behandla testning och rollout som en del av produkten, inte en sista kryssruta.
Börja med automatiska tester för delar som måste bete sig likadant varje gång — särskilt poängsättning och behörigheter:
UAT fungerar bäst när det speglar faktiskt arbete. Be varje affärsenhet att bidra med ett litet antal prov-risker, kontroller, incidenter och åtgärder, och kör typiska scenarion:
Fånga inte bara buggar, utan också förvirrande etiketter, saknade statusar och fält som inte matchar teamens språk.
Rulla ut till ett team först (eller en region) i 2–4 veckor. Håll omfånget begränsat: ett arbetsflöde, ett fåtal fält och ett tydligt framgångsmått (t.ex. % riskgranskningar i tid). Använd feedback för att justera:
Tillhandahåll korta how-to-guider och en enkelsidig ordlista: vad varje poäng betyder, när man använder varje status och hur man bifogar bevis. En 30-minuters livesession plus inspelade klipp slår ofta en lång manual.
Om ni vill nå en trovärdig v1 snabbt kan en vibe-coding-plattform som Koder.ai hjälpa er prototypa och iterera arbetsflöden utan lång uppsättningstid. Beskriv skärmar och regler (riskintag, godkännanden, poängsättning, påminnelser, revisionsloggs-vyer) i chatten och förfina sedan den genererade appen medan intressenter reagerar på verkligt UI.
Koder.ai är byggt för end-to-end-leverans: det stödjer webbappar (vanligtvis React), backendtjänster (Go + PostgreSQL) och har praktiska funktioner som källkods-export, deployment/hosting, anpassade domäner och snapshots med rollback — användbart när du ändrar taxonomier, poängskalor eller godkännandeflöden och behöver säker iteration. Team kan börja på en gratisnivå och gå upp till pro, business eller enterprise när styrning och skalningskrav växer.
Planera för löpande drift tidigt: automatiska backuper, enkel övervakning av drifttid/fel och en lätt förändringsprocess för taxonomi och poängskalor så uppdateringar förblir konsekventa och granskbara över tid.
Starta med att skriva en tydlig definition av “operativ risk” för er organisation och vad som ligger utanför.
Ett praktiskt tillvägagångssätt är att använda fyra fack—process, människor, system, externa händelser—och lägga till några exempel för varje så användare kan klassificera poster konsekvent.
Håll v1 inriktad på den minsta uppsättningen arbetsflöden som skapar tillförlitliga data:
Skjut upp komplex taxonomihantering, anpassade arbetsflödesbyggare och djupa integrationer tills ni har konsekvent användning.
Involvera en liten men representativ grupp intressenter:
Detta hjälper dig att designa för verkliga arbetsflöden snarare än hypotetiska funktioner.
Karta det nuvarande arbetsflödet end-to-end (även om det är e-post + kalkylblad): identifiera → bedöma → behandla → övervaka → granska.
För varje steg, dokumentera:
Gör dessa till explicita tillstånd och övergångsregler i appen.
Standardisera ett riskuttalande (t.ex. “På grund av orsak, kan händelse inträffa, vilket leder till påverkan”) och definiera obligatoriska fält.
Minst bör ni kräva:
Använd en enkel, förklarbar modell först (vanligtvis 1–5 Sannolikhet och 1–5 Påverkan, med Score = S × P).
Gör det konsekvent genom att:
Separera punkt-i-tiden-bedömningar från den “aktuella” riskposten.
En minimal schemauppsättning brukar inkludera:
Denna struktur stödjer spårbarhet som “vilka incidenter ledde till en poängändring?” utan att skriva över historiken.
Använd en append-only revisionslogg för viktiga händelser (skapa/uppdatera/radera, godkännanden, ägarbyten, exporter, behörighetsändringar).
Fånga:
Tillhandahåll en filtrerbar, skrivskyddad granskningsloggsvy och möjligheten att exportera från den medan exporten själv loggas.
Behandla bevis som första-klassens data, inte bara filer.
Rekommenderade metoder:
Detta stödjer revisioner och minskar oavsiktlig exponering av känsligt innehåll.
Prioritera SSO (SAML/OIDC) om er organisation redan har en identitetsleverantör, och bygg sedan rollbaserad åtkomstkontroll (RBAC).
Praktiska säkerhetskrav:
Håll behörighetsregler begripliga så användare förstår varför åtkomst ges eller nekas.
Detta förhindrar vaga poster och förbättrar rapporteringskvaliteten.
Om teamen inte kan poängsätta konsekvent, lägg till vägledning innan ni lägger till fler dimensioner.