07 sep. 2025·8 min
Hur du bygger en webbapp för rollback‑beslut
Lär dig designa och bygga en webbapp som centraliserar rollback‑signaler, godkännanden och revisionsspår—så team kan fatta beslut snabbare och minska risken.
Lär dig designa och bygga en webbapp som centraliserar rollback‑signaler, godkännanden och revisionsspår—så team kan fatta beslut snabbare och minska risken.
Ett “rollback‑beslut” är stunden då ett team avgör om man ska ångra en ändring som redan finns i produktion—stänga av en funktionsflagga, återställa en deploy, rulla tillbaka en konfiguration eller dra tillbaka en release. Det låter enkelt tills du står mitt i en incident: signaler motsäger varandra, ägarskapet är oklart och varje minut utan ett beslut kostar.
Team har svårt eftersom inputen är utspridd. Övervakningsgrafer finns i ett verktyg, supportärenden i ett annat, deploy‑historik i CI/CD, funktionsflaggor någon annanstans och själva “beslutet” blir ofta en hastigt påskriven chat‑tråd. Senare, när någon frågar “varför rullade vi tillbaka?”, är bevisen borta—eller svåra att återskapa.
Målet med den här webbappen är att skapa ett ställe där:
Det betyder inte att det ska vara en stor röd knapp som automatiskt rullar tillbaka allt. Som standard är det beslutsstöd: det hjälper människor att gå från “vi är oroliga” till “vi är trygga” med delad kontext och ett tydligt arbetsflöde. Automatisering kan komma senare; första vinsten är att minska förvirring och snabba på samordningen.
Ett rollback‑beslut berör flera roller, så appen bör tjäna olika behov utan att tvinga alla in i samma vy:
När detta fungerar bra rullar ni inte bara tillbaka snabbare. Ni gör färre panikbeslut, behåller ett renare revisionsspår och gör varje produktincident till en mer repeterbar, lugnare beslutsprocess.
En rollback‑beslutsapp fungerar bäst när den speglar hur människor faktiskt svarar på risk: någon upptäcker en signal, någon koordinerar, någon beslutar och någon utför. Börja med att definiera kärnrollerna och designa sedan resor kring vad varje person behöver i stunden.
On‑call‑ingenjör behöver snabbhet och tydlighet: “Vad ändrades, vad går sönder och vad är säkrast just nu?” De ska kunna föreslå en rollback, bifoga bevis och se om godkännanden krävs.
Produktägare behöver användarpåverkan och avvägningar: “Vem påverkas, hur allvarligt är det och vad förlorar vi om vi rullar tillbaka?” De bidrar ofta med kontext (syfte, rollout‑plan, kommunikation) och kan vara godkännare.
Incident‑commander behöver samordning: “Är vi överens om hypotesen, beslutsstatus och nästa steg?” De ska kunna tilldela ägare, sätta beslutstidsfrister och hålla intressenter synkade.
Godkännare (engineering manager, release captain, compliance) behöver förtroende: “Är beslutet motiverat och återställbart, och följer det policy?” De kräver en kortfattad besluts‑sammanfattning plus underlagssignaler.
Definiera fyra tydliga rättigheter: föreslå, godkänna, utföra och visa. Många team tillåter vem som helst på on‑call att föreslå, en liten grupp att godkänna och endast ett begränsat fåtal att utföra i produktion.
De flesta rollback‑beslut går fel på grund av utspridd kontext, oklart ägarskap och saknade loggar/bevis. Din app bör göra ägarskapet explicit, hålla alla input på ett ställe och fånga en varaktig bild av vad som var känt vid beslutstidpunkten.
En rollback‑app lyckas eller misslyckas beroende på om dess datamodell matchar hur ditt team faktiskt levererar mjukvara och hanterar risk. Börja med en liten uppsättning tydliga entiteter, och lägg sedan till struktur (taxonomi och snapshots) som gör beslut förklarliga i efterhand.
Minimalt bör du modellera:
Håll relationer explicita så dashboards snabbt kan svara “vad påverkas?”:
Bestäm tidigt vad som aldrig får ändras:
Lägg till lättviktiga enum‑fält som gör filtrering konsekvent:
Denna struktur stöder snabba incident‑triage‑dashboards och skapar ett revisionsspår som håller i post‑incident‑granskningar.
Innan du bygger arbetsflöden och dashboards, definiera vad ditt team menar med “rollback.” Olika team använder samma ord för mycket olika åtgärder—with olika riskprofiler. Din app bör göra rollback‑typen explicit, inte antagen.
De flesta team behöver tre kärnmekanismer:
I UI:t behandla dessa som distinkta “action‑typer” med egna förutsättningar, förväntad påverkan och verifieringssteg.
Ett rollback‑beslut beror ofta på var problemet uppstår. Modellera omfattningen tydligt:
us-east, eu-west, en specifik kluster eller en procentuell rollout.Appen bör låta en granskare se “stäng av flagg i prod, bara EU” vs “global prod‑rollback”, eftersom det inte är likvärdiga beslut.
Bestäm vad appen får trigga direkt:
Gör åtgärder idempotenta för att undvika konflikt vid flera klick under en incident:
Klara definitioner här håller godkännandeflödet lugnt och incidenttidslinjen ren.
Rollback‑beslut blir enklare när teamet är överens om vad som räknas som “bra bevis”. Din app bör omvandla utspridd telemetri till ett konsekvent besluts‑paket: signaler, trösklar och kontext som förklarar varför siffrorna ändrades.
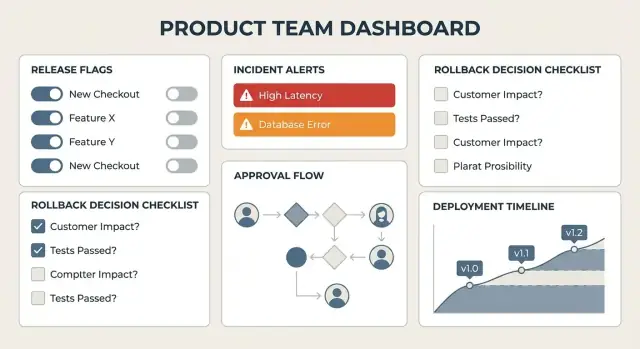
Bygg en checklista som alltid visas för en release eller feature under granskning. Håll den kort men komplett:
Målet är inte att visa varje diagram—utan att bekräfta att samma kärnsignaler kontrollerats varje gång.
Enstaka toppar händer. Beslut bör drivas av ihållande avvikelse och förändringstakt.
Stöd både:
I UI:t visa en liten “trendstrip” bredvid varje mått (sista 60–120 minuterna) så granskare snabb ser om problemet växer, är stabilt eller återhämtar sig.
Siffror utan kontext slösar tid. Lägg till en “Kända ändringar”‑panel som svarar på:
Denna panel bör dra från release notes, funktionsflaggor och deploys, och göra “inget ändrades” till ett uttryckligt påstående—inte en antagande.
När någon behöver detaljer, ge snabba länkar som öppnar rätt vy direkt (dashboards, traces, tickets) via /integrations, utan att förvandla din app till ännu ett övervakningsverktyg.
En rollback‑beslutsapp visar sitt värde när den förvandlar “alla i en chat” till ett tydligt, tidsboxat arbetsflöde. Målet är enkelt: en ansvarig föreslagare, en definierad uppsättning granskare och en slutlig godkännare—utan att bromsa akut åtgärd.
Föreslagaren startar ett Rollback Proposal kopplat till en specifik release/feature. Håll formuläret snabbt men strukturerat:
Förslaget bör omedelbart generera en dela‑länk och notifiera tilldelade granskare.
Granskare uppmanas att lägga till bevis och en ställning:
För att hålla diskussionen produktiv, lagra anteckningar bredvid förslaget (inte utspritt över verktyg), och uppmuntra att länka till tickets eller monitors med relativa referenser som /incidents/123 eller /releases/45.
Definiera en slutgiltig godkännare (ofta on‑call‑lead eller produktägare). Deras godkännande bör:
Rollbacks är tidkänsliga, så baka in deadlines:
Om SLA missas bör appen eskalera—först till en backup‑granskare, sedan till en on‑call‑chef—samtidigt som beslutsdokumentet förblir oförändrat och auditabelt.
Ibland kan man inte vänta. Lägg till en Break‑glass Execute‑väg som tillåter omedelbar åtgärd men kräver:
Utförande ska inte sluta vid “knapp klickad.” Fånga bekräftelsesteg (rollback genomförd, flaggor uppdaterade, övervakning kontrollerad) och stäng posten först när verifiering är signerad.
När en release beter sig illa har människor inte tid att “lära sig verktyget.” UI:t bör minska kognitiv belastning: visa vad som händer, vad som beslutats och vilka säkra nästa steg är—utan att dränka någon i diagram.
Översikt (home dashboard). Detta är triage‑ingången. Den ska besvara tre frågor på sekunder: Vad är för närvarande i riskzonen? Vilka beslut väntar? Vad ändrades nyligen? Ett bra upplägg är en vänster‑till‑höger‑skanning: aktiva incidenter, väntande godkännanden och ett kort “senaste releaser / flaggändringar”‑flöde.
Incident/Decision‑sida. Här konvergerar teamet. Para en narrativ sammanfattning (“Vad vi ser”) med live‑signaler och en tydlig besluts‑panel. Håll beslutskontrollerna på en konsekvent plats (höger kolumn eller sticky footer) så folk inte behöver leta efter “Föreslå rollback”.
Feature‑sida. Behandla detta som ägarvyn: aktuell rollout‑status, senaste incidenter kopplade till feature, associerade flaggor, kända risk‑segment och en historik över beslut.
Release‑tidslinje. En kronologisk vy över deploys, flaggrampningar, konfigändringar och incidenter. Hjälper team att koppla orsak och verkan utan att hoppa mellan verktyg.
Använd framträdande, konsekventa statusbadges:
Undvik subtila färg‑bara signaler. Para färg med etiketter och ikoner, och håll wording konsekvent över alla skärmar.
Ett decision pack är en delbar snapshot som svarar: Varför överväger vi rollback och vilka alternativ finns?
Inkludera:
Denna vy ska vara lätt att klistra in i chat och enkel att exportera för rapportering.
Designa för snabbhet och tydlighet:
Målet är inte flashiga dashboards—utan ett lugnt gränssnitt som gör rätt handling uppenbar.
Integrationer förvandlar en rollback‑app från “ett formulär med åsikter” till ett beslutscockpit. Målet är inte att söka in allt—utan att pålitligt hämta de få signaler och kontroller som låter ett team besluta och agera snabbt.
Börja med fem källor som de flesta team redan använder:
Använd den minst bräckliga metoden som ändå möter era krav på snabbhet:
Olika system beskriver samma sak olika. Normalisera inkommande data till en liten, stabil schema som:
source (deploy/flags/monitoring/ticketing/chat)entity (release, feature, service, incident)timestamp (UTC)environment (prod/staging)severity och metric_valueslinks (relativa referenser som /incidents/123)Detta låter UI:t visa en enda tidslinje och jämföra signaler utan skräddarsydd logik per verktyg.
Integrationer går sönder; appen får inte bli tyst eller vilseledande.
När systemet inte kan verifiera en signal, säg det tydligt—osäkerhet är fortfarande användbar information.
När en rollback är aktuell är beslutet bara halva historien. Den andra halvan är att kunna svara senare: varför gjorde vi detta och vad visste vi då? Ett tydligt revisionsspår minskar ifrågasättanden, snabbar upp granskningar och gör överlämningar mellan team lugnare.
Behandla revisionsspåret som en append‑only‑logg av betydande åtgärder. För varje händelse fånga:
Detta gör auditloggen användbar utan att tvinga in er i en komplex compliance‑berättelse.
Metrik och dashboards ändras minut för minut. För att undvika “rörliga mål” bör du lagra evidens‑snapshots när ett förslag skapas, uppdateras, godkänns eller utförs.
En snapshot kan inkludera: den använda frågan (t.ex. felfrekvens för feature‑kohort), returvärden, diagram/percentiler och referenser till originalkällan. Målet är inte att spegla övervakningsverktyget—utan att bevara de signaler teamet lutade sig mot.
Bestäm retention efter praktik: hur länge incidenter/beslut ska vara sökbara och vad som arkiveras. Erbjud exporter team faktiskt använder:
Lägg till snabb sökning och filter över incidenter och beslut (tjänst, feature, datumintervall, godkännare, utfall, severitet). Grundläggande rapporter kan sammanfatta antal rollbacks, median tid till godkännande och återkommande triggrar—nyttigt för produktoperationer och post‑incident‑granskningar.
En rollback‑beslutsapp är bara användbar om folk litar på den—särskilt när den kan förändra produktion. Säkerhet handlar inte bara om “vem kan logga in”; det handlar om hur du förhindrar förhastade, oavsiktliga eller obehöriga åtgärder samtidigt som ni kan agera snabbt i incidenter.
Erbjud ett litet antal tydliga inloggningsvägar och gör det säkraste till default.
Använd role‑based access control (RBAC) med miljö‑scoping så att behörigheter skiljer sig mellan dev/staging/production.
Ett praktiskt modellförslag:
Miljö‑scoping är viktigt: någon kan vara Operator i staging men endast Viewer i produktion.
Rollbacks kan vara högpåverkande, så lägg till friktion där det förhindrar misstag:
Logga känslig åtkomst (vem tittade på incidentbevis, vem ändrade trösklar, vem utförde rollback) med tidsstämplar och förfrågningsmetadata. Gör loggar append‑only och lätta att exportera för granskning.
Spara hemligheter—API‑token, webhook‑signeringsnycklar—inuti en vault (inte i kod eller som rena databasfält). Rotera dem och återkalla omedelbart när en integration tas bort.
En rollback‑beslutsapp bör kännas lätt att använda, men den koordinerar ändå åtgärder med höga insatser. En tydlig byggplan hjälper er att leverera en MVP snabbt utan att skapa en “mystery box” som ingen litar på senare.
För en MVP, håll kärnarkitekturen tråkig och robust:
Denna form stöder det viktigaste målet: en enda sanning för vad som beslutats och varför, samtidigt som integrationer hanteras asynkront (så ett långsamt tredjeparts‑API inte blockerar UI:t).
Välj vad ni kan drifta tryggt. Typiska kombinationer:
För ett litet team, välj färre rörliga delar. Ett repo och en deploybar tjänst räcker ofta tills användningen kräver mer.
Om du vill skynda fram en första fungerande version utan att tumma på underhållbarheten kan en vibe‑coding‑plattform som Koder.ai vara ett praktiskt startställe: beskriv roller, entiteter och arbetsflöde i chatten, generera en React‑UI med en Go + PostgreSQL‑backend och iterera snabbt på formulär, tidslinjer och RBAC. Det är särskilt användbart för interna verktyg eftersom du kan bygga en MVP, exportera källkoden och sedan hårdna integrationer, auditloggning och deployment över tid.
Fokusera tester på delarna som förhindrar misstag:
Behandla appen som produktionsmjukvara från dag ett:
Planera MVP:n runt beslutsfångst + auditabilitet, och bygg sedan ut rikare integrationer och rapportering när teamen börjar lita på verktyget dagligen.
Ett rollback‑beslut är den punkt där teamet väljer om man ska ångra en förändring i produktion—genom att återställa en deploy, slå av en funktionsflagga, rulla tillbaka en konfiguration eller dra tillbaka en release. Det svåra är inte mekanismen; det svåra är att snabbt komma överens om bevis, ägarskap och nästa steg medan incidenten utvecklas.
Appen är främst till för beslutsstöd: samla signaler, strukturera propose/review/approval‑flödet och bevara ett revisionsspår. Automatisering kan läggas till senare, men det initiala värdet är att minska förvirring och påskynda samstämmighet med delad kontext.
Samma beslutsdokument bör vara begripligt för alla utan att tvinga fram identiska arbetsflöden.
Börja med ett litet antal kärnobjekt:
Gör relationer explicita (t.ex. Feature ↔ Release som många‑till‑många, Decision ↔ Action som ett‑till‑många) så att du snabbt kan svara på “vad påverkas?” under en incident.
Behandla “rollback” som separata action‑typer med olika riskprofiler:
UI:t bör tvinga teamet att välja mekanism uttryckligen och fånga omfattning (env/region/% rollout).
En praktisk checklista inkluderar:
Stöd både statisk tröskel (t.ex. “>2% i 10 minuter”) och (t.ex. “–5% vs samma dag förra veckan”), och visa små trendstickor så granskare ser riktning, inte bara en punkt.
Använd ett enkelt, tidsbegränsat flöde:
Lägg till SLA:er (granskning/godkännande) och eskalering till backupeer så posten förblir tydlig även under tidspress.
Break‑glass bör tillåta omedelbar åtgärd men öka ansvarstagandet:
Det håller teamet snabbt i verkliga nödsituationer samtidigt som det skapar en försvarbar historik i efterhand.
Gör åtgärder idempotenta så upprepade klick inte skapar konflikt:
Det förhindrar dubbla rollbacks och minskar kaos när flera responderar samtidigt.
Prioritera fem integrationspunkter:
Använd där omedelbarhet krävs, där nödvändigt, och behåll en som är tydligt märkt och kräver orsak så degraderad drift förblir pålitlig.