29 mars 2025·8 min
Bygga en webbapp för innehållsmoderering
Lär dig hur du designar och bygger en webbapp för innehållsmoderering: köer, roller, policyer, eskalering, revisionsloggar, analys och säkra integrationer.
Lär dig hur du designar och bygger en webbapp för innehållsmoderering: köer, roller, policyer, eskalering, revisionsloggar, analys och säkra integrationer.
Innan du designar ett modereringsarbetsflöde, bestäm vad du faktiskt modererar och vad “bra” betyder. En tydlig omfattning förhindrar att din moderationskö fylls med kantfall, dubbletter och ärenden som inte hör hemma där.
Skriv ner varje innehållstyp som kan skapa risk eller skada för användare. Vanliga exempel är användargenererad text (kommentarer, inlägg, recensioner), bilder, video, livestreams, profilfält (namn, biografier, avatarer), privata meddelanden, community-grupper och marknadsplatser (titlar, beskrivningar, bilder, prissättning).
Notera också källor: användarinlämningar, automatiska importer, redigeringar av befintliga objekt och rapporter från andra användare. Detta undviker att bygga ett system som bara fungerar för “nya inlägg” men missar redigeringar, återuppladdningar eller DM-missbruk.
De flesta team balanserar fyra mål:
Var tydlig med vilket mål som är primärt i varje område. Till exempel kan högseveritetmissbruk prioritera hastighet över perfekt konsistens.
Lista hela uppsättningen av utfall din produkt kräver: godkänn, avvisa/ta bort, redigera/retuschera, etikett/åldersspärra, begränsa synlighet, sätta under granskning, eskalera till en lead, och kontoåtgärder som varningar, tillfälliga låsningar eller avstängningar.
Definiera mätbara mål: median- och 95:e percentil för granskningstid, backlog-storlek, andel omvända beslut vid överklagande, policynogahet från QA-sampling och andelen högseveritetsärenden som hanteras inom en SLA.
Ta med moderatorer, teamledare, policy, support, teknik och juridik. Missanpassning här orsakar omarbete senare—särskilt kring vad “eskalering” betyder och vem som äger slutgiltiga beslut.
Innan du bygger skärmar och köer, skissa hela livscykeln för ett enskilt innehållsobjekt. Ett tydligt arbetsflöde förhindrar “mystiska tillstånd” som förvirrar granskare, bryter notiser och gör revisioner smärtsamma.
Börja med en enkel end-to-end state-modell du kan lägga i ett diagram och i din databas:
Submitted → Queued → In review → Decided → Notified → Archived
Håll tillstånden ömsesidigt uteslutande och definiera vilka övergångar som är tillåtna (och av vem). Till exempel: “Queued” kan gå till “In review” endast när det är tilldelat, och “Decided” bör vara oföränderligt utom via ett överklagandeflöde.
Automatiska klassificerare, nyckelordsmatchningar, rate limits och användarrapporter bör behandlas som signaler, inte beslut. En “människa-i-slingan”-design håller systemet ärligt:
Denna separation gör det också lättare att förbättra modeller senare utan att skriva om policylogiken.
Beslut kommer att ifrågasättas. Lägg till förstklassiga flöden för:
Modellera överklaganden som nya granskningshändelser istället för att redigera historiken. Då kan du berätta hela historien om vad som hände.
För revisioner och tvister, definiera vilka steg som måste spelas in med tidsstämplar och aktörer:
Om du inte kan förklara ett beslut senare, anta att det inte hände.
Ett modereringsverktyg lever eller dör på åtkomstkontroll. Om alla kan göra allt får du inkonsekventa beslut, oavsiktlig dataexponering och ingen tydlig ansvarighet. Börja med att definiera roller som matchar hur ditt trust & safety-team faktiskt arbetar, och översätt dem sedan till behörigheter som din app kan upprätthålla.
De flesta team behöver ett litet set tydliga roller:
Denna separation hjälper till att undvika “policyändringar av misstag” och håller policystyrning åtskild från den dagliga verkställigheten.
Implementera rollbaserad åtkomstkontroll så att varje roll bara får det den behöver:
can_apply_outcome, can_override, can_export_data) snarare än per sida.Om du senare lägger till nya funktioner (exporter, automations, tredjepartsintegrationer) kan du fästa dem vid behörigheter utan att omdefiniera hela organisationsstrukturen.
Planera för flera team tidigt: språkpodar, regionbaserade grupper eller separata linjer för olika produkter. Modellera team explicit och skala sedan köer, innehållssynlighet och tilldelningar per team. Detta förhindrar att ärenden granskas i fel region och håller arbetsbelastningen mätbar per grupp.
Admins behöver ibland impersonera användare för att felsöka åtkomst eller reproducera en granskares problem. Behandla impersonation som en känslig åtgärd:
För irreversibla eller högriskåtgärder, lägg till admin-godkännande (eller två-personersgranskning). Denna lilla friktion skyddar mot både misstag och insidermissbruk, samtidigt som rutingränssnittet förblir snabbt.
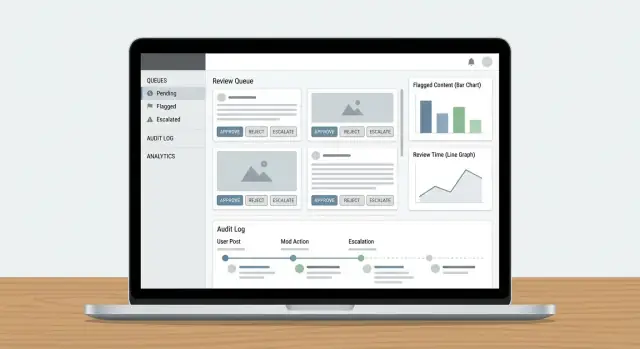
Köer är där modereringsarbetet blir hanterbart. Istället för en enda oändlig lista, dela upp arbetet i köer som speglar risk, brådska och intent—och gör det svårt för items att falla mellan stolarna.
Börja med ett litet set köer som matchar hur ditt team faktiskt arbetar:
Håll köerna ömsesidigt uteslutande när det är möjligt (ett item bör ha ett “hem”), och använd taggar för sekundära attribut.
Inom varje kö, definiera poängregler som avgör vad som kommer högst:
Gör prioriteringarna förklarliga i UI (“Varför ser jag detta?”) så att granskarna litar på ordningen.
Använd claiming/locking: när en granskare öppnar ett item tilldelas det dem och döljs för andra. Lägg till en timeout (t.ex. 10–20 minuter) så att övergivna items återgår till kön. Logga alltid claim-, release- och completion-händelser.
Om systemet belönar hastighet kan granskare välja snabba ärenden och hoppa över svåra. Motverka detta genom att:
Målet är konsekvent täckning, inte bara hög genomströmning.
En modereringspolicy som bara finns i en PDF kommer att tolkas olika av varje granskare. För att göra beslut konsekventa (och granskningsbara), översätt policytext till strukturerade data och UI-val som ditt arbetsflöde kan upprätthålla.
Börja med att bryta ned policyn till ett gemensamt vokabulär granskarna kan välja från. En användbar taxonomi innehåller vanligtvis:
Denna taxonomi blir grunden för köer, eskalering och analys senare.
Istället för att be granskarna skriva ett beslut från början varje gång, ge beslutsmallar kopplade till taxonomiposter. En mall kan förifylla:
Mallarna gör “happy path” snabb, samtidigt som de tillåter avvikelser.
Policyer förändras. Spara policyer som versionerade poster med ikraftträdandedatum, och spela in vilken version som användes för varje beslut. Detta förhindrar förvirring när äldre ärenden överklagas och säkerställer att du kan förklara utfall månader senare.
Fritext är svårt att analysera och lätt att glömma. Kräv att granskarna väljer en eller flera strukturerade orsaker (från din taxonomi) och valfritt lägger till anteckningar. Strukturerade orsaker förbättrar hantering av överklaganden, QA-sampling och trendrapportering—utan att tvinga granskarna skriva långa texter.
En granskardashboard lyckas när den minimerar “letande” efter information och maximerar självsäkra, repeterbara beslut. Granskare ska kunna förstå vad som hänt, varför det är viktigt och vad de ska göra härnäst—utan att öppna fem flikar.
Visa inte ett isolerat inlägg och förvänta dig konsekventa utfall. Presentera en kompakt kontextpanel som svarar på vanliga frågor direkt:
Håll standardvyn koncis, med expanderingsval för djupare dykar. Granskare ska sällan behöva lämna dashboarden för att fatta ett beslut.
Din åtgärdsrad bör matcha policyutfall, inte generiska CRUD-knappar. Vanliga mönster inkluderar:
Gör åtgärder synliga och gör irreversibla steg explicita (bekräftelse endast när det behövs). Fånga en kort orsakskod plus valfria anteckningar för senare revisioner.
Volymarbete kräver låg friktion. Lägg till kortkommandon för toppåtgärder (godkänn, avvisa, nästa item, lägg till etikett). Visa en snabböversikt över kortkommandon i UI.
För köer med repetitivt arbete (t.ex. uppenbar spam), stöd massval med skydd: visa en förhandsgranskningsräkning, kräva orsakskod och logga massåtgärden.
Moderering kan utsätta människor för skadligt material. Lägg in säkerhetsstandarder:
Dessa val skyddar granskarna samtidigt som besluten förblir korrekta och konsekventa.
Revisionsloggar är din “sanna källa” när någon frågar: Varför togs detta inlägg bort? Vem godkände överklagandet? Var det modellen eller en människa som fattade slutgiltigt beslut? Utan spårbarhet blir utredningar gissningslek och granskarnas förtroende sjunker snabbt.
För varje modereringsåtgärd, logga vem gjorde det, vad som ändrades, när det hände och varför (policyorsak + fritextanteckningar). Lika viktigt: spara före/efter-snapshots av relevanta objekt—innehållstext, mediahashar, detekterade signaler, etiketter och slutligt utfall. Om ett item kan ändras (redigeringar, borttagningar) förhindrar snapshots att “posten” driver bort.
Ett praktiskt mönster är en append-only händelsepost:
{
"event": "DECISION_APPLIED",
"actor_id": "u_4821",
"subject_id": "post_99102",
"queue": "hate_speech",
"decision": "remove",
"policy_code": "HS.2",
"reason": "slur used as insult",
"before": {"status": "pending"},
"after": {"status": "removed"},
"created_at": "2025-12-26T10:14:22Z"
}
Utöver beslut, logga arbetsflödets mekanik: claimed, released, timed out, reassigned, escalated och auto-routed. Dessa händelser förklarar “varför det tog 6 timmar” eller “varför detta item studsade mellan team” och är väsentliga för att upptäcka missbruk (t.ex. granskare som plockar de lätta ärendena).
Ge utredare filter på användare, innehålls-ID, policykod, tidsintervall, kö och åtgärdstyp. Inkludera export till en ärendefil med oföränderliga tidsstämplar och referenser till relaterade items (dubbletter, återuppladdningar, överklaganden).
Sätt tydliga retentionfönster för audit-händelser, snapshots och granskningsanteckningar. Håll policyn explicit (t.ex. 90 dagar för rutinloggar, längre för juridiska hållningar) och dokumentera hur redigering eller raderingsförfrågningar påverkar lagrade bevis.
Ett modereringsverktyg är bara användbart om det stänger loopen: rapporter blir granskningar, beslut når rätt personer och åtgärder på användarnivå utförs konsekvent. Här brister många system—någon tömmer kön men inget annat förändras.
Behandla användarrapporter, automatiska flaggor (spam/CSAM/hashmatchningar/toxicitetsignaler) och interna eskalationer (support, community managers, juridik) som samma kärnobjekt: en rapport som kan skapa ett eller flera granskningsuppdrag.
Använd en gemensam rapportrouter som:
Om support-eskalationer är en del av flödet, länka dem direkt (t.ex. /support/tickets/1234) så att granskarna inte behöver växla kontext.
Moderationsbeslut bör generera templaterade notifikationer: innehåll borttaget, varning utfärdad, ingen åtgärd eller kontoåtgärd utförd. Håll budskapet konsekvent och kort—förklara utfall, referera till relevant policy och ge instruktioner för överklagande.
Operationellt, skicka notifikationer via en händelse som moderation.decision.finalized, så att e‑post/in-app/push kan prenumerera utan att sakta ner granskarflödet.
Beslut kräver ofta åtgärder bortom ett enskilt innehållsobjekt:
Gör dessa åtgärder explicita och reversibla, med tydliga varaktigheter och skäl. Länka varje åtgärd tillbaka till beslutet och underliggande rapport för spårbarhet, och ge en snabb väg till överklaganden så att beslut kan omprövas utan manuella detektivuppgifter.
Din datamodell är “sanningskällan” för vad som hände med varje item: vad som granskades, av vem, under vilken policy och vad resultatet blev. Får du detta lager rätt blir allt annat—köer, dashboards, revisioner och analys—enklare.
Undvik att lagra allt i en och samma post. Ett praktiskt mönster är att hålla:
HARASSMENT.H1 eller NUDITY.N3, lagrade som referenser så att policyer kan utvecklas utan att skriva om historiken.Detta håller policyverkställandet konsekvent och gör rapportering tydligare (t.ex. “topp överträdda policykoder denna vecka”).
Lägg inte stora bilder/videor direkt i databasen. Använd objektlagring och spara endast objektnycklar + metadata i ditt innehållstabell.
För granskare, generera kortlivade signerade URL:er så att media är åtkomligt utan att vara offentligt. Signerade URL:er låter dig också styra utgång och återkalla åtkomst vid behov.
Köer och utredningar kräver snabba uppslag. Lägg till index för:
Modellera moderering som explicita tillstånd (t.ex. NEW → TRIAGED → IN_REVIEW → DECIDED → APPEALED). Spara tillståndsövergångshändelser (med tidsstämplar och aktör) så att du kan detektera items som inte gått framåt.
Ett enkelt skydd: ett fält last_state_change_at plus varningar för items som överstiger en SLA, och ett reparationsjobb som återsätter items som legat i IN_REVIEW efter en timeout.
Trust & Safety-verktyg hanterar ofta den känsligaste datan i din produkt: användargenererat innehåll, rapporter, kontouppgifter och ibland rättsliga förfrågningar. Behandla modereringsappen som ett högrisksystem och bygg säkerhet och integritet inifrån från dag ett.
Börja med stark autentisering och strikta sessionregler. För de flesta team betyder det:
Kombinera detta med rollbaserad åtkomstkontroll så att granskarna bara ser det de behöver (t.ex. en kö, en region eller en innehållstyp).
Kryptera data i transit (HTTPS överallt) och i vila (hanterad databas-/lagringskryptering). Fokusera sedan på att minimera exponering:
Om du hanterar samtycke eller särskilda datakategorier, gör dessa flaggor synliga för granskarna och tvinga dem i UI (t.ex. begränsad visning eller retentionregler).
Rapporterings- och överklagandeendpoints är vanliga mål för spam och trakasserier. Lägg till:
Slutligen, gör varje känslig åtgärd spårbar med en revisionslogg så att du kan utreda granskarmedelar, komprometterade konton eller samordnat missbruk.
Ett modereringsarbetsflöde blir bara bättre om du kan mäta det. Analys bör tala om huruvida din ködesign, eskaleringsregler och policyverkställning ger konsekventa beslut—utan att bränna ut granskare eller låta skadligt innehåll ligga kvar.
Börja med ett litet set mått kopplade till utfall:
Visa dessa i en SLA-dashboard så att ops-ansvariga ser vilka köer som halkar efter och om flaskhalsen är bemanning, oklara regler eller en anstormning av rapporter.
Oenighet är inte alltid dåligt—det kan peka på kantfall. Spåra:
Använd din audit-logg för att koppla varje provat beslut till granskaren, tillämpad regel och bevis. Detta ger förklarbarhet vid coaching av granskare och när du bedömer om UI:t får folk att göra inkonsekventa val.
Moderationsanalys bör hjälpa dig svara: “Vad ser vi som vår policy inte täcker väl?” Leta efter kluster som:
Omvandla dessa signaler till konkreta åtgärder: skriv om policyexempel, lägg till beslutsträd i granskarens dashboard eller uppdatera verkställningspreset (t.ex. standardtidsgränser vs. varningar).
Behandla analys som en del av en människa-i-slingan-lösning. Dela queue‑nivåprestanda öppet inom teamet, men hantera individuella mått varsamt för att undvika att uppmuntra hastighet framför kvalitet. Kombinera kvantitativa KPI:er med regelbundna kalibreringssessioner och små, frekventa policyuppdateringar—så att verktygen och människorna förbättras tillsammans.
Ett modereringsverktyg faller oftast på kanterna: konstiga inlägg, sällsynta eskaleringar och ögonblick när flera personer rör samma ärende. Behandla testning och utrullning som en del av produkten, inte som en slutlig checkbox.
Bygg ett litet “scenario‑paket” som speglar verkligt arbete. Inkludera:
Använd produktionsliknande datavolymer i en stagingmiljö så att du kan upptäcka kö‑nedgångar och paginerings-/sökrestriktioner tidigt.
Ett säkrare utrullningsmönster är:
Shadow mode är särskilt användbart för att validera policyregler och automation utan att riskera falska positiver.
Skriv korta, uppgiftsbaserade playbooks: “Hur man hanterar en rapport”, “När man eskalerar”, “Hur man hanterar överklaganden” och “Vad man gör när systemet är osäkert.” Träna sedan med samma scenario‑paket så att granskarna övar de exakta flöden de kommer att använda.
Planera underhåll som kontinuerligt arbete: nya innehållstyper, uppdaterade eskaleringsregler, periodisk QA‑sampling och kapacitetsplanering vid kötoppar. Ha en tydlig releaseprocess för policyändringar så att granskarna ser vad som ändrats och när—och så att du kan korrelera förändringar med modereringsanalys.
Om du implementerar detta som en webbapplikation är en stor del av arbetet repetitivt: RBAC, köer, state‑övergångar, revisionsloggar, dashboards och den händelsedrivna limmet mellan beslut och notifikationer. Koder.ai kan snabba upp bygget genom att låta dig beskriva modereringsarbetsflödet i en chattgränssnitt och generera en fungerande grund du kan iterera på—vanligtvis med en React‑frontend och en Go + PostgreSQL‑backend.
Två praktiska sätt att använda det för trust & safety‑verktyg:
När basen är på plats kan du exportera källkoden, koppla dina befintliga modell‑signaler som “inputs” och behålla granskarens beslut som slutgiltig auktoritet—vilket matchar den människa‑i‑slingan‑arkitektur som beskrivs ovan.
Börja med att lista varje innehållstyp ni kommer hantera (inlägg, kommentarer, meddelanden, profiler, annonser, media) samt varje källa (nya inskick, redigeringar, importer, användarrapporter, automatiska flaggor). Definiera sedan vad som är utom räckhåll (t.ex. interna adminanteckningar eller systemgenererat innehåll) så att din kö inte blir en soptipp.
En praktisk kontroll: om du inte kan namnge innehållstypen, källan och ansvarigt team, ska det troligen inte skapa en modereringsuppgift ännu.
Välj ett litet set operativa KPI:er som speglar både hastighet och kvalitet:
Sätt mål per kö (t.ex. hög-risk vs. backlog) så att du inte av misstag optimerar lågprioriterat arbete medan skadligt innehåll väntar.
Använd en enkel, uttrycklig state-modell och enhetliga tillåtna övergångar, till exempel:
SUBMITTED → QUEUED → IN_REVIEW → DECIDED → NOTIFIED → ARCHIVEDGör tillstånden ömsesidigt uteslutande, och behandla “Decided” som oföränderligt förutom via ett överklagande/omgranskning-flöde. Det förhindrar “mystiska tillstånd”, brutna notiser och svårgranskade ändringar.
Behandla automatiserade system som signaler, inte slutgiltiga utfall:
Detta håller policytillämpningen förklarlig och gör det enklare att förbättra modeller senare utan att skriva om beslutslogiken.
Bygg överklaganden som förstklassiga objekt kopplade till det ursprungliga beslutet:
Börja med ett litet, tydligt RBAC-set:
Använd flera köer med tydligt ägarskap:
Prioritera inom en kö med förklarliga signaler som severitet, räckvidd, unika rapportörer och SLA-timers. I UI, visa “Varför ser jag detta?” så att granskarna litar på ordningen och du kan upptäcka manipulation.
Implementera claiming/locking med timeouts:
Det minskar dubbelarbete och ger data för att diagnostisera flaskhalsar och selektivt plockande av lätta ärenden.
Gör din policy till en strukturerad taxonomi och använd beslutsmallar:
Det ökar konsekvensen, gör analys fungerande och förenklar revisioner och överklaganden.
Logga allt som krävs för att återskapa historiken:
Gör loggar sökbara efter aktör, innehålls-ID, policykod, kö och tidsintervall, och definiera retentionregler (inklusive rättsliga hållningar och hur raderingsförfrågningar påverkar lagrade bevis).
Spela alltid in vilken policyversion som användes ursprungligen och vilken som gäller vid överklagandet.
Lägg sedan till minst-privilegium-behörigheter per kapacitet (t.ex. can_export_data, can_apply_account_penalty) så att nya funktioner inte spränger accessmodellen.