10 juni 2025·8 min
Cachelager minskar belastningen — men tillför dold komplexitet
Cachelager minskar latenstiden och belastningen på backend, men tillför feltyper och driftkostnader. Lär dig vanliga lager, risker och sätt att hantera komplexiteten.
Cachelager minskar latenstiden och belastningen på backend, men tillför feltyper och driftkostnader. Lär dig vanliga lager, risker och sätt att hantera komplexiteten.
Caching håller en kopia av data nära där den behövs så att förfrågningar kan besvaras snabbare, med färre turer till kärnsystemen. Vinsten är oftast en kombination av hastighet (lägre latenstid), kostnad (färre dyra databasläsningar eller upstream-anrop) och stabilitet (origin-tjänster klarar trafiktoppar bättre).
När en cache kan svara på en förfrågan gör din “origin” (appservrar, databaser, tredjeparts-API:er) mindre. Den minskningen kan vara dramatisk: färre frågor, färre CPU-cykler, färre nätverkshopp och färre möjligheter till timeouts.
Caching jämnar också ut burstar—hjälper system som är dimensionerade för medelbelastning att hantera toppar utan att omedelbart skala (eller falla omkull).
Caching tar inte bort arbete; det flyttar det in i design och drift. Du får nya frågor:
Varje cachelager lägger på konfiguration, övervakning och specialfall. En cache som gör 99 % av förfrågningarna snabbare kan ändå orsaka smärtsamma incidenter i den sista procenten: synkroniserade utgångar, inkonsekventa användarupplevelser eller plötsliga flöden mot origin.
En enkel cache är ett enskilt lagringsställe (t.ex. en minnes-cache bredvid din applikation). Ett cachelager är en separat checkpoint i request-vägen—CDN, webbläsarcache, applikationscache, databascache—var och en med egna regler och feltyper.
Det här inlägget fokuserar på den praktiska komplexitet som flera lager inför: korrekthet, invalidering och drift (inte lågnivå-cachealgoritmer eller leverantörsspecifik tuning).
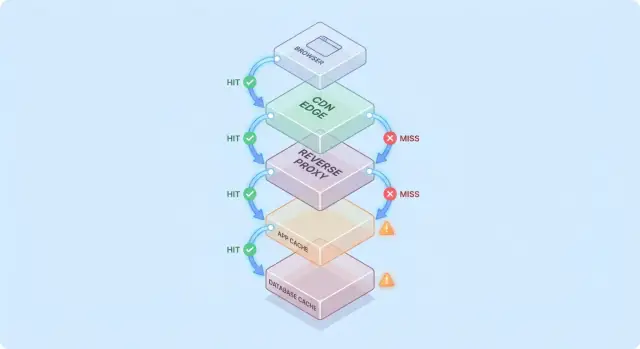
Caching blir lättare att resonera om när du föreställer dig en förfrågan som reser genom en stapel av “kanske har jag det redan”-kontrollpunkter.
En vanlig väg ser ut så här:
Vid varje hopp kan systemet antingen returnera ett cacheat svar (hit) eller vidarebefordra förfrågan till nästa lager (miss). Ju tidigare en hit sker (t.ex. i edge), desto mer belastning undviker du längre ner i stacken.
Hits får dashboards att se bra ut. Missar är där komplexiteten dyker upp: de triggar verkligt arbete (applogik, databasfrågor) och lägger på overhead (cacheuppslag, serialisering, cache-skrivningar).
En användbar mental modell är: varje miss betalar för cachen två gånger—du gör fortfarande det ursprungliga arbetet, plus cachearbetet runt omkring.
Att lägga till ett cachelager eliminerar sällan flaskhalsar; det flyttar dem oftare:
Antag att din produktsida cachas i CDN i 5 minuter, och appen också cachar produktdetaljer i Redis i 30 minuter.
Om ett pris ändras kan CDN uppdateras snabbt medan Redis fortsätter servera det gamla priset. Nu beror “sanningen” på vilket lager som svarade—en tidig bild av varför cachelager minskar belastning men ökar systemkomplexiteten.
Caching är inte en enda funktion—det är en stapel av platser där data kan sparas och återanvändas. Varje lager kan minska belastningen, men alla har olika regler för färskhet, invalidering och synlighet.
Webbläsare cachear bilder, skript, CSS och ibland API-svar baserat på HTTP-headers (som Cache-Control och ETag). Detta kan eliminera upprepade nedladdningar helt—utmärkt för prestanda och för att minska CDN/origin-trafik.
Problemet: när ett svar väl är cacheat klient-side har du inte full kontroll över revalidiseringstidpunkten. Vissa användare kan behålla äldre assets längre (eller rensa cache oväntat), så versionssatta URL:er (t.ex. app.3f2c.js) är ett vanligt skydd.
En CDN cachear innehåll nära användarna. Den glänser för statiska filer, publika sidor och “mest stabila” svar som produktbilder, dokumentation eller rate-limited API-endpoints.
CDN:er kan också cachea semi-statiskt HTML om du är försiktig med variation (cookies, headers, geo, device). Felaktigt konfigurerade variationsregler är en vanlig källa till att visa fel innehåll för fel användare.
Reverse proxies (som NGINX eller Varnish) sitter framför din applikation och kan cachea hela svar. Detta är användbart när du vill ha central kontroll, förutsägbar eviction och snabb skydd för origin-servrar vid trafikspikar.
Det är vanligtvis mindre globalt distribuerat än en CDN, men enklare att skräddarsy för dina routes och headers.
Denna cache riktar sig mot objekt, beräknade resultat och dyra anrop (t.ex. “user profile by id” eller “pricing rules for region”). Den är flexibel och kan göras medveten om affärslogik.
Den inför också fler beslutspunkter: nyckeldesign, TTL-val, invalideringslogik och driftbehov som dimensionering och failover.
De flesta databaser cachear sidor, index och queryplaner automatiskt; vissa stöder result-caching. Detta kan snabba upp upprepade queries utan att ändra applikationskod.
Bäst att se som en bonus, inte en garanti: databas-cachar är oftast minst förutsägbara under diversifierade querymönster, och de tar inte bort kostnaden för skrivningar, lås eller contentions på samma sätt som upstream-cachar kan.
Caching lönar sig mest när den förvandlar upprepade, dyra backend-operationer till en billig uppslagning. Tricket är att matcha cachen till arbetslaster där förfrågningar är tillräckligt lika—och tillräckligt stabila—för att återanvändning ska vara hög.
Om ditt system levererar betydligt fler läsningar än skrivningar kan caching ta bort en stor del av databas- och applikationsarbetet. Produktsidor, publika profiler, hjälpcente-artiklar och sök-/filterresultat efterfrågas ofta upprepade gånger med samma parametrar.
Caching hjälper också med “dyra” jobb som inte strikt är databasbundna: generera PDF:er, ändra storlek på bilder, rendera templates eller beräkna aggregat. Även en kortlivad cache (sekunder till minuter) kan slå ihop upprepade beräkningar under intensiva perioder.
Caching är särskilt effektivt när trafiken är ojämn. Om ett marknadsföringsmail, en nyhetsomnämning eller ett inlägg sprider sig och skickar en ström av användare till samma få URL:er kan en CDN eller edge-cache absorbera det mesta av den vågen.
Det här minskar belastning bortom “snabbare svar”: det kan förhindra autoscaling-thrash, undvika uttömning av databasanslutningar och köpa tid för rate limits och backpressure att verka.
Om din backend är långt från dina användare—antingen bokstavligt (cross-region) eller logiskt (en långsam beroende)—kan caching minska både belastning och upplevd långsamhet. Att leverera innehåll från en CDN-cache nära användaren undviker upprepade långdistansresor till origin.
Intern caching hjälper också när flaskhalsen är en hög-latenslagrad tjänst (en fjärrdatabas, ett tredjeparts-API eller en delad tjänst). Att skära ner antalet anrop minskar samtidighetsbelastning och förbättrar tail-latency.
Caching ger mindre fördel när svar är starkt personaliserade (per-användardata, känsliga kontouppgifter) eller när underliggande data ändras konstant (live-dashboards, snabbt uppdaterande lager). Då är träfffrekvensen låg, kostnaden för invalidering stiger och den sparade backendarbetet kan vara marginellt.
En praktisk regel: caching är mest värdefullt när många användare frågar efter samma sak inom ett fönster där “samma sak” förblir giltigt. Om den överlappningen inte finns kan ytterligare ett cachelager lägga på komplexitet utan att minska belastningen märkbart.
Caching är enkelt när data aldrig ändras. I det ögonblick den gör det ärv du det svåraste: bestämma när cachedata slutar vara tillförlitligt och hur varje cachelager får reda på att det ändrats.
Time-to-live (TTL) är lockande eftersom det är ett enda nummer och ingen koordinering. Problemet är att en “korrekt” TTL beror på hur datan används.
Om du sätter en 5-minuters TTL på ett produktpris kommer vissa användare att se ett gammalt pris efter en ändring—potentiellt ett juridiskt eller support-problem. Om du sätter 5 sekunder kanske du inte minskar belastningen mycket alls. Än värre, olika fält i samma svar ändras i olika takt (lager vs beskrivning), så en enda TTL tvingar fram en kompromiss.
Event-driven invalidering säger: när sanningskällan ändras, publicera ett event och rensa/uppdatera alla påverkade cachenycklar. Detta kan vara mycket korrekt, men det skapar nytt arbete:
Den mappningen är där “de två svåra sakerna: namngivning och invalidering” blir praktiskt plågsam. Om du cachear /users/123 och också cachear “top contributors”-listor påverkar ett användarnamn flera nycklar. Om du inte spårar relationer kommer du att servera blandad verklighet.
Cache-aside (appen läser/skriver DB, fyller cache) är vanligt, men invalidering ligger på dig.
Write-through (skriv cache och DB tillsammans) minskar risken för föråldring, men lägger till latens och felhanteringskomplexitet.
Write-back (skriv cache först, flusha senare) ger snabbhet, men gör korrekthet och återhämtning mycket svårare.
Stale-while-revalidate serverar lite gammal data medan den uppdateras i bakgrunden. Det jämnar ut toppar och skyddar origin, men är också ett produktbeslut: du väljer uttryckligen “snabbt och i stort sett aktuellt” över “alltid senaste”.
Caching förändrar vad “korrekt” betyder. Utan cache ser användare oftast den senaste committade datan (med normala databasbeteenden). Med cacher kan användare se data som ligger något efter—eller inkonsekvent mellan vyer—ibland utan något uppenbart felmeddelande.
Stark konsistens strävar efter “read-after-write”: om en användare uppdaterar sin leveransadress bör nästa sidladdning visa den nya adressen överallt. Detta känns intuitivt, men kan bli dyrt om varje skrivning måste omedelbart rensa eller uppdatera flera cacher.
Eventual konsistens tillåter kortvarig föråldring: uppdateringen syns snart, men inte omedelbart. Användare tolererar detta för lågprioriterat innehåll (som visningsräkningar), men inte för pengar, behörigheter eller något som påverkar vad de kan göra härnäst.
Ett vanligt fallgropsscenario är en skrivning samtidigt som cache återfylls:
Nu innehåller cachen gammal data under hela sin TTL, trots att databasen är korrekt.
Med flera cachelager kan olika delar av systemet vara oense:
Användare tolkar detta som “systemet är trasigt”, inte “systemet är eventual-consistent”.
Versionshantering minskar tvetydighet:
user:123:v7) låter dig gå framåt säkert: en skrivning bump:ar versionen och läsningar skiftar naturligt till den nya nyckeln utan att kräva perfekt tajmade deletioner.Nyckelbeslutet är inte “är föråldrad data dålig?” utan var den är dålig.
Sätt explicita föråldringsbudgetar per funktion (sekunder/minuter/timmar) och anpassa dem till användarnas förväntningar. Sökningsresultat kan få ligga efter en minut; kontobalanser och accesskontroller bör inte göra det. Detta gör “cachekorrekthet” till ett produktkrav som kan testas och övervakas.
Caching faller ofta i sätt som ser ut som “allt var fint, sedan bröts allt på en gång.” Dessa fel betyder inte att caching är dåligt—de betyder att cacher koncentrerar trafikmönster, så små förändringar kan trigga stora effekter.
Efter en deploy, autoscale-händelse eller cacheflush kan du ha en i stort sett tom cache. Nästa trafikvåg tvingar många requests att träffa databasen eller upstream-API:er direkt.
Detta är särskilt smärtsamt när trafiken ökar snabbt, eftersom cachen inte haft tid att värmas med populära objekt. Om deploys sammanfaller med hög belastning kan du av misstag skapa ditt eget loadtest.
En stampede uppstår när många användare ber om samma objekt precis när det går ut (eller inte finns). Istället för att en request återbygger värdet gör hundratals eller tusentals det—vilket överväldigar origin.
Vanliga mitigeringar inkluderar:
Om korrekthetskraven tillåter det kan stale-while-revalidate också jämna ut toppar.
Vissa nycklar blir oproportionerligt populära (en homepage-payload, en trendande produkt, en global konfiguration). Hot keys skapar ojämn belastning: en cache-node eller en backendväg får hård press medan andra står stilla.
Mitigeringar inkluderar att dela upp stora “globala” nycklar i mindre, införa sharding/partitionering eller cacha på ett annat lager (t.ex. flytta verkligen publikt innehåll närmare användarna via en CDN).
Cacheavbrott kan vara värre än ingen cache, eftersom applikationer kan vara skrivna för att bero på den. Bestäm i förväg:
Oavsett val, använd rate limits och circuit breakers för att undvika att ett cachefel blir ett ursprungsfel.
Caching kan minska belastningen på dina origin-system, men det ökar antalet tjänster du driver dagligen. Även “managed” cacher kräver planering, tuning och incidenthantering.
Ett nytt cachelager är ofta en ny kluster (eller åtminstone ett nytt lager) med egna kapacitetsgränser. Team måste bestämma minnesstorlek, eviction-policy och vad som händer under tryck. Om cachen är för liten churnar den: hit rate sjunker, latens stiger och origin blir överbelastad ändå.
Caching lever sällan på ett ställe. Du kan ha en CDN-cache, en applikationscache och databas-caching—alla tolkar regler olika.
Små mismatchar samlas på hög:
Med tiden blir “varför är den här requesten cachead?” ett arkeologiskt projekt.
Cachar skapar återkommande arbete: värma kritiska nycklar efter deploys, rensa eller revalidera vid dataändringar, resharding när noder läggs till/ tas bort, och öva vad som händer efter en full flush.
När användare rapporterar föråldrade data eller plötslig långsamhet har svarsteamet nu flera misstänkta: CDN, cacheklustret, appens cacheklient och origin. Debugging innebär ofta att kolla hit rates, eviction-spikar och timeouts över lager—och sedan bestämma om man ska kringgå, purge:a eller skala upp.
Caching är bara en vinst om den både minskar ursprungsarbete och förbättrar användarupplevd hastighet. Eftersom förfrågningar kan besvaras av flera lager (edge/CDN, applikationscache, databascache) behöver du observabilitet som svarar på:
En hög hit-ratio låter bra, men kan dölja problem (som långsamma cacheläsningar eller konstant churn). Spåra en liten uppsättning mätvärden per lager:
Om hit-ratio stiger men total latens inte förbättras kan cachen vara långsam, för serialiserad eller returnera för stora payloads.
Distribuerad tracing bör visa om en request serverades i edge, av app-cachen eller av databasen. Lägg till konsekventa taggar som cache.layer=cdn|app|db och cache.result=hit|miss|stale så du kan filtrera traces och jämföra hit-path vs miss-path timing.
Logga cache-nycklar försiktigt: undvik råa användaridentifierare, e-post, tokens eller fulla URL:er med querystrings. Föredra normaliserade eller hashade nycklar och logga bara en kort prefix.
Larma vid abnorma miss-rate-spikar, plötsliga latenshoppar på misses och stampede-signaler (många samtidiga misses för samma nyckelmönster). Separera dashboards i edge, app och database-vyer, plus en end-to-end panel som knyter ihop dem.
Caching är utmärkt för att repetera svar snabbt—men det kan också repetera fel svar till fel person. Caching-relaterade säkerhetsincidenter är ofta tysta: allt ser snabbt och friskt ut samtidigt som data läcker.
En vanlig miss är att personaliserat eller konfidentiellt innehåll (kontouppgifter, fakturor, supportärenden, admin-sidor) cacheas. Detta kan hända i vilket lager som helst—CDN, reverse proxy eller applikationscache—särskilt med breda “cache everything”-regler.
En annan subtil läcka: att cachea svar som innehåller sessionsstate (t.ex. en Set-Cookie-header) och sedan servera det cachade svaret till andra användare.
En klassisk bugg är att cachea HTML/JSON för Användare A och senare servera den till Användare B eftersom cache-nyckeln inte inkluderade användarkontext. I multi-tenant system måste tenant-identity vara en del av nyckeln.
Tumregel: om svaret beror på autentisering, roller, geografi, prissättning eller feature-flaggor måste din cache-nyckel (eller bypass-logik) spegla det beroendet.
HTTP-caching styrs i hög grad av headers:
Cache-Control: förhindra oavsiktlig lagring med private / no-store där det behövsVary: se till att caches separerar svar efter relevanta request-headers (t.ex. Authorization, Accept-Language)Set-Cookie: ofta en signal att svaret inte bör cacheas publiktOm compliance- eller risknivån är hög—PII, hälso-/finansiell data, juridiska dokument—föredra Cache-Control: no-store och optimera server-side istället. För blandade sidor, cacha bara icke-känsliga fragment eller statiska assets och håll personaliserad data utanför delade cacher.
Cachelager kan minska origin-belastning, men det är sällan “gratis prestanda”. Behandla varje nytt cachelager som en investering: du köper lägre latens och mindre ursprungsarbete i utbyte mot pengar, ingenjörstid och en större korrekthetsyta.
Extra infrastrukturkostnad vs reducerad originkostnad. En CDN kan minska egress och databasläsningar, men du betalar för CDN-förfrågningar, cache-lagring och ibland invalideringsanrop. En applikationscache (Redis/Memcached) lägger till klusterkostnader, uppgraderingar och on-call-börda. Besparingar kan synas som färre databasreplicas, mindre instanstyper eller fördröjd skalning.
Latensvinster vs färskhetskostnader. Varje cache inför en “hur föråldrat är acceptabelt?”-beslut. Strikt färskhet kräver mer invalideringsplumbing (och fler misses). Tolererad föråldring sparar beräkning men kan kosta användarförtroende—särskilt för priser, tillgänglighet eller behörigheter.
Ingenjörstid: featurefart vs driftsarbete. Ett nytt lager innebär ofta extra kodvägar, mer testning och fler incidentklasser att förebygga (stampedes, hot keys, partiell invalidering). Budgetera för löpande underhåll, inte bara initial implementering.
Innan du rullar ut brett, kör ett begränsat försök:
Lägg till ett nytt cachelager endast om:
Caching betalar av sig snabbast när du behandlar det som en produktfunktion: det behöver en ägare, tydliga regler och ett säkert sätt att stänga av det.
Lägg till ett cachelager i taget (t.ex. CDN eller applikationscache först) och tilldela ett ansvarigt team/person.
Definiera vem som äger:
De flesta cachebuggar är egentligen “nyckelbuggar.” Använd en dokumenterad konvention som inkluderar de inputs som ändrar svaret: tenant/user-scope, locale, device-class och relevanta feature-flaggor.
Lägg till tydlig nyckelversionering (t.ex. product:v3:...) så du säkert kan invalidera genom att bumpa en version istället för att försöka ta bort miljontals poster.
Att försöka hålla allt perfekt färskt skjuter komplexitet in i varje skrivväg.
Bestäm istället vad “acceptabelt föråldrat” betyder per endpoint (sekunder, minuter eller “tills nästa uppdatering”), och koda det med:
Anta att cachen kommer vara långsam, felaktig eller nere.
Använd timeouts och circuit breakers så cache-anrop inte kan ta ner request-vägen. Gör graciös degradering explicit: om cachen misslyckas, falla tillbaka på origin med rate limits, eller servera ett minimalt svar.
Skicka caching bakom en canary eller procentbaserad rollout och behåll en bypass-switch (per route eller header) för snabb felsökning.
Dokumentera runbooks: hur man purge:ar, hur man bump:ar nyckelversioner, hur man tillfälligt stänger av caching och vad man ska kolla i metrik. Länka dem från intern runbook-sida så on-call kan agera snabbt.
Cachingarbete stannar ofta eftersom ändringar rör flera lager (headers, applogik, datamodeller, rollback-planer). Ett sätt att minska iterationskostnaden är att prototypa hela requestvägen i en kontrollerad miljö.
Med Koder.ai kan team snabbt spinna upp en realistisk appstack (React på webben, Go-backends med PostgreSQL, och till och med Flutter-mobilklienter) från ett chatstyrt arbetsflöde, och testa cachingbeslut (TTL, nyckeldesign, stale-while-revalidate) end-to-end. Funktioner som planning mode hjälper till att dokumentera tänkt cachebeteende innan implementation, och snapshots/rollback gör det säkrare att experimentera med cachekonfiguration eller invalideringslogik. När du är redo kan du exportera källkod eller deploya/hosta med egna domäner—användbart för prestandatester som behöver spegla produktion.
Om du använder en plattform som denna, behandla den som ett komplement till produktions-klass observabilitet: målet är snabbare iteration på cache-design samtidigt som korrekthetskrav och rollback-procedurer hålls explicita.
Caching minskar belastningen genom att svara på upprepade förfrågningar utan att nå ursprunget (appservrar, databaser, tredjeparts-API:er). De största vinsterna kommer ofta från:
Ju tidigare i request-vägen en cache träffar (webbläsare/CDN vs app), desto mer arbete undviker du för ursprunget.
En enskild cache är ett lagringsställe (t.ex. en in-memory-cache intill appen). Ett cachelager är en checkpoint i request-vägen (webbläsarcache, CDN, reverse proxy, app-cache, databascache).
Flera lager minskar belastningen bredare, men de inför också fler regler, fler felmodeller och fler sätt att leverera inkonsekventa data när lagren inte är i synk.
Missar triggar verkligt arbete plus cache-omkostnader. Vid en miss betalar du typiskt för:
Så en miss kan vara långsammare än “ingen cache” om inte cachen är väl designad och träfffrekvensen är hög på de viktiga endpoints.
TTL är enkelt eftersom det inte kräver koordinering, men det tvingar fram en gissning om färskhet. Om TTL är för lång serverar du föråldrade data; för kort och du minskar inte belastningen märkbart.
Ett praktiskt tillvägagångssätt är att sätta TTL per funktion baserat på användarpåverkan (t.ex. minuter för dokumentationssidor, sekunder eller ingen cache för saldon/priser) och sedan revidera dem utifrån verkliga hit/miss- och incidentdata.
Använd event-driven invalidering när föråldring är kostsamt och du tillförlitligt kan koppla skrivningar till de påverkade cachenycklarna. Det fungerar bäst när:
Om du inte kan garantera detta, föredra begränsad föråldring (TTL + revalidation) framför en “perfekt” invalidering som kan misslyckas tyst.
Flerlager-caching kan få olika delar av systemet att motstrida varandra. Exempel: CDN serverar gammal HTML medan appcachen returnerar nyare JSON, vilket skapar ett blandat UI.
För att minska detta:
product:v3:...) så läsningar naturligt går framåtEn stampede (thundering herd) uppstår när många förfrågningar återbygger samma nyckel samtidigt (ofta precis vid utgång), vilket överbelastar ursprunget.
Vanliga åtgärder:
Bestäm fallback-beteende i förväg:
Lägg också in timeouts, circuit breakers och rate limits så en cachestörning inte kaskadar till ett ursprungsavbrott.
Fokusera på mätvärden som förklarar utfall, inte bara träfffrekvens:
I tracing/loggar, tagga requests med cache.layer och så du kan jämföra "hit-path" vs "miss-path" och snabbt upptäcka regressioner.
Vanligaste risken är att personaliserade eller konfidentiella svar cachas i delade lager (CDN/reverse proxy) på grund av saknade nyckelvariationer eller felaktiga headers.
Säkerhetsåtgärder:
Varycache.resultCache-Control: private eller no-store för känsliga svarVary (t.ex. Authorization, Accept-Language) när svar skiljer sigSet-Cookie på ett svar som en stark signal att undvika publik caching