21 sep. 2025·8 min
Eric Brewers CAP-tänkande: varför distribuerade system gör avvägningar
Lär dig Eric Brewers CAP-teorem som en praktisk mental modell: hur konsistens, tillgänglighet och partitioner påverkar beslut i distribuerade system.
Lär dig Eric Brewers CAP-teorem som en praktisk mental modell: hur konsistens, tillgänglighet och partitioner påverkar beslut i distribuerade system.
När du lagrar samma data på mer än en maskin får du snabbhet och feltolerans—men du får också ett nytt problem: oense. Två servrar kan ta emot olika uppdateringar, meddelanden kan komma för sent eller inte alls, och användare kan läsa olika svar beroende på vilken replik de träffar. CAP blev populärt eftersom det ger ingenjörer ett enkelt sätt att prata om den röriga verkligheten utan att vifta bort detaljer.
Eric Brewer, datavetare och medgrundare av Inktomi, introducerade kärnidéen år 2000 som ett praktiskt uttalande om replikerade system under fel. Det spreds snabbt eftersom det matchade vad team redan upplevde i produktion: distribuerade system går inte bara ner genom att stanna; de misslyckas genom att splittras.
CAP är mest användbart när saker går fel—särskilt när nätverket inte beter sig. På en frisk dag kan många system se både tillräckligt konsistenta och tillgängliga ut. Stressprovet är när maskiner inte kan kommunicera tillförlitligt och du måste bestämma vad du gör med läsningar och skrivningar medan systemet är delat.
Denna inramning är anledningen till att CAP blev en go-to tankemodell: den argumenterar inte för bästa praxis; den tvingar fram en konkret fråga—vad kommer vi att offra under en split?
I slutet av den här artikeln bör du kunna:
CAP består eftersom det omvandlar vagt "distribuerat är svårt"-prat till ett beslut du kan fatta—och försvara.
Ett distribuerat system är, enkelt uttryckt, många datorer som försöker agera som en. Du kan ha flera servrar i olika rack, regioner eller molnzoner, men för användaren är det "appen" eller "databasen".
För att få det delade systemet att fungera i verklig skala replikerar vi oftast: vi behåller flera kopior av samma data på olika maskiner.
Replikering är populärt av tre praktiska skäl:
Hittills låter replikering som en självklar fördel. Fällan är att replikering skapar ett nytt jobb: att hålla alla kopior i överensstämmelse.
Om varje replik alltid kunde prata med varje annan replik omedelbart, skulle de kunna koordinera uppdateringar och hålla sig synkade. Men verkliga nätverk är inte perfekta. Meddelanden kan fördröjas, tappas eller routas kring fel.
När kommunikationen är frisk kan repliker vanligtvis utbyta uppdateringar och konvergera mot samma tillstånd. Men när kommunikationen bryts (även tillfälligt) kan du hamna med två giltigt utseende-versioner av ”sanningen.”
Till exempel: en användare ändrar sin leveransadress. Replik A får uppdateringen, replik B gör det inte. Nu måste systemet svara på en till synes enkel fråga: vad är den aktuella adressen?
Detta är skillnaden mellan:
CAP-tänkandet börjar precis här: när replikering finns, är oenighet under kommunikationsfel inte ett undantag—det är det centrala designproblemet.
CAP är en tankemodell för vad användare faktiskt känner när ett system är utspritt över flera maskiner (ofta i flera platser). Det beskriver inte "bra" eller "dåliga" system—bara spänningen du måste hantera.
Konsistens handlar om överenskommelse. Om du uppdaterar något, kommer nästa läsning (var som helst) att återspegla den uppdateringen?
Ur användarens perspektiv är det skillnaden mellan "jag ändrade det precis, och alla ser samma nya värde" och "vissa ser fortfarande det gamla värdet ett tag."
Tillgänglighet betyder att systemet svarar på förfrågningar—läsningar och skrivningar—med ett framgångsresultat. Inte "så snabbt som möjligt", men "det vägrar inte att betjäna dig."
Under problem (en server nere, ett nätverksstörning) fortsätter ett tillgängligt system att ta emot förfrågningar, även om det måste svara med data som kan vara något föråldrad.
En partition är när nätverket splittras: maskinerna körs, men meddelanden mellan några av dem når inte fram (eller anländer för sent för att vara användbara). I distribuerade system kan du inte behandla detta som om det är omöjligt—du måste definiera beteende när det händer.
Föreställ dig två butiker som båda säljer samma produkt och delar "1 i lager." En kund köper den sista varan i Butik A, så Butik A skriver lager = 0. Samtidigt förhindrar en nätverkspartition att Butik B får reda på det.
Om Butik B förblir tillgänglig kan den sälja en vara den inte längre har (acceptera försäljningen under partitionen). Om Butik B istället upprätthåller konsistens kan den neka försäljningen tills den kan bekräfta det senaste lagret (avvisa service under spliten).
En "partition" är inte bara "internet är nere." Det är varje situation där delar av ditt system inte kan prata tillförlitligt med varandra—även om varje del fortfarande kan köras fint.
I ett replikerat system utbyter noder konstant meddelanden: skrivningar, bekräftelser, heartbeat, leader-val, läsförfrågningar. En partition är vad som händer när dessa meddelanden slutar anlända (eller anländer för sent), vilket skapar oenighet om verkligheten: "Hände skrivningen?" "Vem är ledaren?" "Är nod B uppe?"
Kommunikation kan misslyckas på röriga, partiella sätt:
Viktig poäng: partitioner är ofta nedsättning, inte en ren av/på-incident. Ur applikationens synvinkel kan "tillräckligt långsamt" vara omöjligt att skilja från "nere."
När du lägger till fler maskiner, fler nätverk, fler regioner och fler rörliga delar finns det helt enkelt fler möjligheter för kommunikation att bryta tillfälligt. Även om enskilda komponenter är pålitliga upplever det övergripande systemet fel eftersom det har fler beroenden och mer korsnodskoordination.
Du behöver inte anta någon exakt felhastighet för att acceptera verkligheten: om ditt system körs tillräckligt länge och spänner över tillräckligt mycket infrastruktur, kommer partitioner att hända.
Partitionstolerans betyder att ditt system är designat för att fortsätta fungera under en split—även när noder inte kan enas eller inte kan bekräfta vad andra sidan sett. Det tvingar fram ett val: antingen fortsätt serva förfrågningar (riskera inkonsistens) eller stoppa/avvisa vissa förfrågningar (bevara konsistens).
När du har replikering är en partition helt enkelt ett kommunikationsbrott: två delar av ditt system kan inte pålitligt prata med varandra under en tid. Repliker körs fortfarande, användare klickar fortfarande, och din tjänst tar emot förfrågningar—men replikerna kan inte enas om den senaste sanningen.
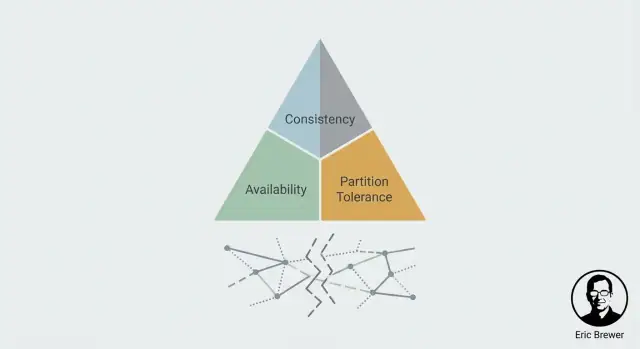
Det är CAP-spänningen i en mening: under en partition måste du välja att prioritera Konsistens (C) eller Tillgänglighet (A). Du får inte båda samtidigt.
Du säger: "Jag vill hellre vara korrekt än responsiv." När systemet inte kan bekräfta att en förfrågan håller alla repliker i synk måste den misslyckas eller vänta.
Praktisk effekt: vissa användare ser fel, timeouter eller "försök igen"-meddelanden—särskilt för operationer som ändrar data. Detta är vanligt när du hellre avvisar en betalning än riskerar att debitera två gånger, eller blockerar en platsbokning än att sälja för mycket.
Du säger: "Jag vill hellre svara än blockera." Varje sida av partitionen fortsätter acceptera förfrågningar, även om den inte kan koordinera.
Praktisk effekt: användare får framgångsresultat, men datan de läser kan vara föråldrad, och samtidiga uppdateringar kan konfliktera. Du förlitar dig då på rekonsiliering senare (merge-regler, last-write-wins, manuell granskning, osv.).
Det här är inte alltid en enda global inställning. Många produkter blandar strategier:
Nyckelögonblicket är att besluta—per operation—vad som är värst: att blockera en användare nu, eller att fixa konflikter senare.
Sloganet "välj två" är minnesvärt, men det vilseleder ofta människor att tro att CAP är en meny med tre funktioner där du bara får behålla två för alltid. CAP handlar om vad som händer när nätverket slutar samarbeta: under en partition (eller något som ser ut som en) måste ett distribuerat system välja mellan att returnera konsistenta svar och att vara tillgängligt för varje förfrågan.
I verkliga distribuerade system är partitioner inget du kan stänga av. Om ditt system spänner över maskiner, rack, zoner eller regioner kan meddelanden fördröjas, tappas, omordnas eller routas konstigt. Det är en partition ur mjukvarans perspektiv: noder kan inte pålitligt enas om vad som händer.
Även om det fysiska nätet är fint skapar fel på andra håll samma effekt—överbelastade noder, GC-pauser, bullriga grannar, DNS-haverier, bristfälliga load balancers. Resultatet är detsamma: vissa delar av systemet kan inte prata tillräckligt väl med andra.
Applikationer upplever inte "partition" som en prydlig, binär händelse. De upplever latenspikar och timeouter. Om en förfrågan timeoutar efter 200 ms spelar det ingen roll om paketet anlände efter 201 ms eller aldrig anlände: appen måste bestämma vad den gör härnäst. Ur appens synvinkel är långsam kommunikation ofta omöjlig att skilja från brutet.
Många verkliga system är mestadels konsistenta eller mestadels tillgängliga, beroende på konfiguration och driftsförhållanden. Timeouter, retry-policyer, kvorumstorlekar och "read your writes"-alternativ kan skifta beteendet.
Under normala förhållanden kan en databas se starkt konsistent ut; under stress eller cross-region-problem kan den börja avvisa förfrågningar (favorisera konsistens) eller returnera äldre data (favorisera tillgänglighet).
CAP handlar mindre om att märka produkter och mer om att förstå den avvägning du gör när oenighet uppstår—särskilt när oenigheten orsakas av vanlig långsamhet.
CAP-diskussioner får ofta konsistens att låta binärt: antingen "perfekt" eller "allt går". Verkliga system erbjuder en meny av garantier, var och en med en annan användarupplevelse när repliker inte är överens eller när en nätverkslänk bryts.
Stark konsistens (ofta "linearizable") betyder att när en skrivning är bekräftad, returnerar varje senare läsning—oavsett replik—den skrivningen.
Vad det kostar: under en partition eller när en minoritet av repliker är otillgängliga kan systemet fördröja eller avvisa läsningar/skrivningar för att undvika konfliktande tillstånd. Användare märker detta som timeouter, "försök igen" eller tillfälligt skrivskydd.
Eventuell konsistens lovar att om inga nya uppdateringar sker kommer alla repliker konvergera. Det lovar inte att två användare som läser just nu ser samma sak.
Vad användare kan märka: en nyligen uppdaterad profilbild som "återgår", räknare som ligger efter, eller ett nyss skickat meddelande som inte syns på en annan enhet under en kort stund.
Du kan ofta få en bättre upplevelse utan att kräva full stark konsistens:
Dessa garantier matchar ofta hur människor tänker ("visa inte mina egna ändringar försvinna") och är enklare att upprätthålla under partiella fel.
Börja med användarlöften, inte jargong:
Konsistens är ett produktval: definiera vad som är "fel" för en användare och välj den svagaste garantin som förhindrar det felaktiga tillståndet.
Tillgänglighet i CAP är inte ett skrytmått ("fem nior")—det är ett löfte du ger användare om vad som händer när systemet inte kan vara säker.
När repliker inte kan enas väljer du ofta mellan:
Användare upplever detta som "appen fungerar" kontra "appen är korrekt." Varken är universellt bättre; rätt val beror på vad "fel" betyder i din produkt. Ett något föråldrat socialt flöde är irriterande. Ett föråldrat kontosaldo kan vara skadligt.
Två vanliga beteenden visar sig vid osäkerhet:
Detta är inte en rent teknisk fråga; det är en policyfråga. Produkten måste definiera vad som är acceptabelt att visa och vad som aldrig får gissas.
Tillgänglighet är sällan allt-eller-inget. Under en split kan du se partiell tillgänglighet: vissa regioner, nät eller användargrupper lyckas medan andra misslyckas. Detta kan vara en avsiktlig design (serva där lokal replik är frisk) eller en oavsiktlig effekt (routing-obalanser, ojämn kvorumåtkomst).
Ett praktiskt mellanting är degraderat läge: fortsätt serva säkra åtgärder medan du begränsar riskabla. Till exempel, tillåt bläddring och sök, men inaktivera tillfälligt "överför pengar", "byt lösenord" eller andra operationer där korrekthet och unikhet är kritisk.
CAP känns abstrakt tills du mappar det till vad dina användare upplever under en nätverkssplit: vill du att systemet fortsätter svara, eller att det stoppar för att undvika konflikt?
Föreställ dig två datacenter som båda accepterar beställningar medan de inte kan prata med varandra.
Om du håller kassan tillgänglig kan varje sida sälja den "sista varan" och du riskerar översäljning. Det kan vara acceptabelt för lågprioriterade varor (du backorderar eller ber om ursäkt), men smärtsamt för begränsade lanseringar.
Om du väljer konsistens-först kan du blockera nya beställningar när du inte kan bekräfta lager globalt. Användare ser "försök igen senare", men du undviker att sälja något du inte kan leverera.
Pengar är det klassiska domen där att ha fel är dyrt. Om två repliker accepterar uttag oberoende under en split kan ett konto bli negativt.
System föredrar ofta konsistens vid kritiska skrivningar: avvisa eller fördröj åtgärder om de inte kan bekräfta senaste saldot. Du byter lite tillgänglighet (tillfälliga betalningsfel) mot korrekthet, revisorbarhet och förtroende.
I chatt och sociala flöden tolererar användare oftast små inkonsekvenser: ett meddelande kommer några sekunder för sent, en gilla-räknare är felaktig, eller en visningsmetrik uppdateras senare.
Här kan design för tillgänglighet vara ett bra produktval, så länge du är tydlig med vilka delar som är "eventuellt korrekta" och kan slå ihop uppdateringar på ett bra sätt.
"Rätt" CAP-val beror på kostnaden av att ha fel: återbetalningar, juridisk exponering, förtroendeförlust eller operationell kaos. Bestäm var du kan acceptera tillfällig föråldring—och var du måste faila closed.
När du bestämt vad du gör under ett nätverksbrott behöver du mekanismer som förverkligar beslutet. Dessa mönster dyker upp i databaser, meddelandesystem och APIer—även om produkten aldrig nämner "CAP".
Ett kvorum är helt enkelt "majoriteten av replikerna håller med." Om du har 5 kopior av någon data är majoriteten 3.
Genom att kräva att läsningar och/eller skrivningar når en majoritet minskar risken att returnera föråldrad eller konfliktande data. Till exempel, om en skrivning måste bekräftas av 3 repliker är det svårare för två isolerade grupper att acceptera olika "sanningar."
Tradeoff: hastighet och räckvidd. Om du inte kan nå en majoritet (på grund av partition eller fel) kan systemet vägra operationen—välj konsistens över tillgänglighet.
Många "tillgänglighets"-problem är inte hårda fel utan långsamma svar. En kort timeout gör systemet kvickt men ökar risken att du behandlar långsamma succéer som misslyckanden.
Retries kan återhämta sig från övergående fel, men aggressiva retries kan överbelasta en redan kämpande tjänst. Backoff (vänta längre mellan retries) och jitter (slumpmässighet) hjälper till att förhindra att retries blir en trafiktopp.
Nyckeln är att alignera dessa inställningar med ditt löfte: "alltid svara" brukar innebära fler retries och fallback, medan "aldrig ljug" innebär tajtare gränser och tydligare fel.
Om du väljer att förbli tillgänglig under partitioner kan repliker acceptera olika uppdateringar och du måste reconcila senare. Vanliga tillvägagångssätt inkluderar:
Retries kan skapa dubbletter: dubbeldebitering eller samma beställning två gånger. Idempotens förhindrar det.
Ett vanligt mönster är en idempotensnyckel (request ID) skickad med varje förfrågan. Servern lagrar det första resultatet och returnerar samma resultat för upprepade försök—så retries ökar tillgänglighet utan att korrupta data.
De flesta team "väljer" en CAP-inställning på en whiteboard—sedan upptäcker i produktion att systemet beter sig annorlunda under stress. Validering innebär att medvetet skapa de förhållanden där CAP-avvägningarna blir tydliga, och kontrollera att systemet reagerar som du designat.
Du behöver inte en verklig kabelavklippning för att lära dig något. Använd kontrollerad felinjektion i staging (och försiktigt i produktion) för att simulera partitioner:
Målet är att besvara konkreta frågor: Blir skrivningar avvisade eller accepterade? Returnerar läsningar föråldrat data? Återhämtar sig systemet automatiskt, och hur lång tid tar rekonsilieringen?
Om du vill validera dessa beteenden tidigt (innan du investerat veckor i att koppla ihop tjänster) kan det hjälpa att snabbt spinna upp en realistisk prototyp. Till exempel börjar team som använder Koder.ai ofta med att generera en liten tjänst (vanligtvis en Go-backend med PostgreSQL plus en React UI) och itererar sedan på beteenden som retries, idempotensnycklar och "degraderat läge" i en sandbox-miljö.
Traditionella uptime-kontroller fångar inte att systemet är "tillgängligt men felaktigt." Spåra:
Operatörer behöver förbestämda åtgärder när en partition inträffar: när frysa skrivningar, när failover, när degradera funktionalitet och hur validera säker åter-merge.
Planera också användar-facing beteende. Om du väljer konsistens kan meddelandet vara "Vi kan inte bekräfta din uppdatering nu—vänligen försök igen." Om du väljer tillgänglighet, var tydlig: "Din uppdatering kan ta några minuter att synas överallt." Tydlig formulering minskar supportbördan och bevarar förtroendet.
När du fattar ett systembeslut är CAP mest användbart som en snabb "vad bryter vid en split?"-revision—inte en teoretisk debatt. Använd denna checklista innan du väljer databasfunktion, cachingstrategi eller replikationsläge.
Ställ dessa i ordning:
Om en nätverkspartition händer bestämmer du vilka av dessa du skyddar först.
Undvik en enda global inställning som "vi är ett AP-system." Bestäm istället per:
Exempel: under en split kan du blockera skrivningar till payments (favorisera konsistens) men hålla läsningar för product_catalog tillgängliga med cachead data.
Skriv ned vad du kan tolerera, med exempel:
Om du inte kan beskriva inkonsistens i klara exempel kommer du ha svårt att testa och förklara incidenter.
Nästa ämnen som passar bra med denna checklista: konsensus, konsistensmodeller och SLOs/error budgets.
CAP är en mental modell för replikerade system under kommunikationsfel. Den är mest användbar när nätverket är långsamt, förlorar paket eller är delat, eftersom det då är när repliker inte kan komma överens och du tvingas välja mellan:
Den hjälper till att göra "distribuerat är svårt" till ett konkret produkt- och ingenjörsbeslut.
Ett verkligt CAP-scenario kräver båda:
Om ditt system är en enda nod eller om du inte replikerar tillstånd, är CAP-avvägningar inte den centrala frågan.
En partition är vilken situation som helst där delar av ditt system inte kan kommunicera pålitligt eller inom krävda tidsgränser—även om varje maskin fortfarande körs.
Praktiskt visar sig "partition" ofta som:
Ur applikationens synvinkel kan "för långsamt" vara samma sak som "nere".
Konsistens (C) innebär att läsningar återger den senaste bekräftade skrivningen var som helst. Användare upplever det som "jag ändrade det, och alla ser det".
Tillgänglighet (A) innebär att varje begäran får ett framgångsrikt svar (inte nödvändigtvis den senaste datan). Användare upplever det som "appen fortsätter fungera", möjligen med föråldrade resultat.
Under en partition kan du vanligtvis inte garantera båda samtidigt för alla operationer.
För att replikerade system ska fungera i verkligheten måste du definiera vad som händer när noder inte kan koordinera. Partitioner är inte valbara—om du replikerar måste du hantera situationer där noder inte kan kommunicera.
Att "tolerera partitioner" innebär oftast att: när kommunikationen bryts så har systemet ändå ett definierat sätt att fungera—antingen genom att förkasta/pausa vissa åtgärder (favorisera konsistens) eller genom att leverera bästa möjliga svar (favorisera tillgänglighet).
Om du favoriserar konsistens brukar du:
Detta är vanligt inom finansiella transaktioner, lagerreservationer och behörighetsändringar—områden där att ha fel är värre än tillfällig otillgänglighet.
Om du prioriterar tillgänglighet brukar du:
Användare ser färre hårda fel, men kan få föråldrad data, dubbleffekter utan idempotens eller konflikter som kräver städning.
Ja. Vanliga mixade strategier inkluderar:
Detta undviker ett enda globalt "vi är AP/CP"-märke som sällan matchar produktens behov.
Användbara alternativ inkluderar:
Validera genom att skapa förhållanden där oenighet blir synlig:
Välj den svagaste garanti som förhindrar användarsynligt fel du inte kan tolerera.
Förbered också runbooks och användarmeddelanden som matchar ditt valda beteende (fail closed vs fail open).