06 aug. 2025·8 min
Hur du bygger en webbapp för centraliserad notifikationskontroll
Lär dig designa och bygga en webbapp som centraliserar notifikationer över kanaler, med routingregler, mallar, användarpreferenser och leveransspårning.
Lär dig designa och bygga en webbapp som centraliserar notifikationer över kanaler, med routingregler, mallar, användarpreferenser och leveransspårning.
Centraliserad notifikationshantering betyder att behandla varje meddelande ditt produkt skickar—e-post, SMS, push, i-app-banners, Slack/Teams, webhook-callbacks—som del av ett koordinerat system.
Istället för att varje feature-team bygger sin egen "skicka ett meddelande"-logik skapar du en enda plats där events kommer in, regler bestämmer vad som händer, och leveranser spåras från början till slut.
När notifikationer är utspridda över tjänster och kodbaser återkommer samma problem:
Centralisering ersätter ad-hoc-sändning med ett konsekvent arbetsflöde: skapa ett event, applicera preferenser och regler, välj mallar, leverera via kanaler och registrera utfallen.
Ett notifikationsnav brukar tjäna:
Du vet att tillvägagångssättet fungerar när:
Innan du skissar arkitektur, specificera vad "centraliserad notifikationskontroll" betyder för din organisation. Klara krav håller första versionen fokuserad och förhindrar att navet blir en halvfärdig CRM.
Börja med att lista kategorierna du kommer stödja, eftersom de styr regler, mallar och efterlevnad:
Var tydlig med vilken kategori varje meddelande tillhör—det förhindrar senare "marknadsföring som maskeras till transaktionellt".
Välj en liten uppsättning du kan drifta pålitligt från dag ett, och dokumentera "senare"-kanaler så din datamodell inte blockerar dem.
Stöd nu (typisk MVP): e-post + en realtidskanal (push eller i-app) eller SMS om din produkt är beroende av det.
Stöd senare: chattverktyg (Slack/Teams), WhatsApp, röst, post, partner-webhooks.
Skriv också ner kanalbegränsningar: rate limits, leveranskrav, avsändaridentiteter (domäner, telefonnummer) och kostnad per sändning.
Centraliserad notifikationshantering är inte samma som "allt kundrelaterat". Vanliga icke-mål:
Fånga regler tidigt så du slipper retrofitta senare:
Om du redan har policyer, referera till dem internt (t.ex. /security, /privacy) och behandla dem som acceptanskriterier för MVP:n.
Ett notifikationsnav är lättast att förstå som en pipeline: events kommer in, meddelanden kommer ut, och varje steg är observerbart. Att separera ansvar gör det enklare att lägga till kanaler senare (SMS, WhatsApp, push) utan att skriva om allt.
1) Event-intag (API + connectors). Din app, tjänster eller externa partners skickar "något hände"-events till en ingångspunkt. Vanliga intagspunkter är REST-endpoint, webhooks eller direkta SDK-anrop.
2) Routingmotor. Navet bestämmer vem som ska notifieras, genom vilka kanaler och när. Det här lagret läser mottagardata och preferenser, utvärderar regler och skapar en leveransplan.
3) Templating + personalisering. Givet en leveransplan renderar navet kanalspecifika meddelanden (email HTML, SMS-text, push-payload) med mallar och variabler.
4) Leveransworkrar. Dessa integrerar med leverantörer (SendGrid, Twilio, Slack osv.), hanterar retries och respekterar rate limits.
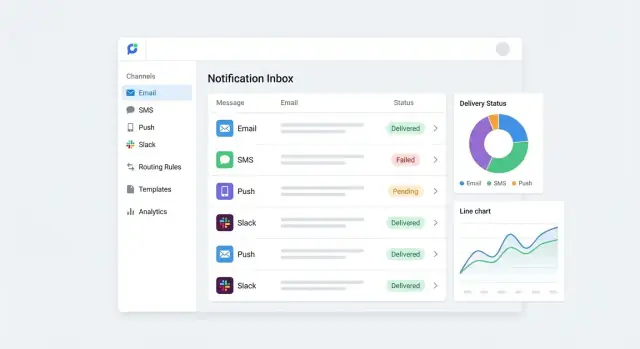
5) Spårning + rapportering. Varje försök registreras: accepterat, skickat, levererat, misslyckat, öppnat/klickat (när tillgängligt). Detta driver admin-dashboards och revisionsspår.
Använd synkront endast för lättviktig intake (t.ex. validera och returnera 202 Accepted). För de flesta system, routa och leverera asynkront:
Planera för dev/staging/prod tidigt. Spara leverantörscredentials, rate limits och feature flags i miljöspecifik konfiguration (inte i mallar). Håll mallar versionshanterade så du kan testa ändringar i staging innan produktion påverkas.
En praktisk uppdelning är:
Denna arkitektur ger en stabil ryggrad samtidigt som dagliga meddelandeändringar hålls utanför deploycykler.
Ett centraliserat notifikationssystem lever eller dör med kvaliteten på sina events. Om olika delar av produkten beskriver samma sak på olika sätt kommer navet spendera tiden på att översätta, gissa och gå sönder.
Börja med ett litet, explicit kontrakt som varje producent kan följa. En praktisk baslinje ser ut så här:
invoice.paid, comment.mentioned)Denna struktur håller event-driven notifikationer begripliga och stödjer routingregler, mallar och leveransspårning.
###Versionssätt dina kontrakt (var inte rädd för förändring)
Events utvecklas. Förhindra breakage genom att versionssätta dem, till exempel med schema_version: 1. När du behöver en brytande ändring publicera en ny version (eller ett nytt event-namn) och stöd båda under en övergångsperiod. Detta är viktigast när flera producenter (backend-tjänster, webhooks, schemalagda jobb) matar ett nav.
Behandla inkommande events som otrustad input, även från dina egna system:
idempotency_key: invoice_123_paid) så retries inte skapar dubbla utskick över flerkanaals-notifikationer.Starka datakontrakt minskar supportärenden, snabbar upp integrationer och gör rapportering och revisionsloggar mycket mer pålitliga.
Ett notifikationsnav fungerar bara om det vet vem någon är, hur nå dem och vad de gått med på att få. Behandla identitet, kontaktdata och preferenser som förstklassiga objekt—inte som incidental information i en användarpost.
Separera en User (ett konto som loggar in) från en Recipient (en enhet som kan ta emot meddelanden):
För varje kontaktpunkt, spara: value (t.ex. e-post), channel-typ, label, ägare och verifieringsstatus (unverified/verified/blocked). Behåll också metadata som senaste verifieringstid och verifieringsmetod (länk, kod, OAuth).
Preferenser bör vara uttrycksfulla men förutsägbara:
Modellera detta med lager av default: organisation → team → user → recipient, där lägre nivåer överskriver högre. Det låter administratörer sätta rimliga baser samtidigt som individer kontrollerar personlig leverans.
Samtycke är inte bara en checkbox. Spara:
Gör ändringar i samtycke revisionsbara och enkla att exportera från en central plats (t.ex. /settings/notifications), eftersom support behöver det när användare frågar "varför fick jag detta?" eller "varför fick jag inte detta?".
Routingregler är navets "hjärna": de bestämmer vilka mottagare som ska notifieras, genom vilka kanaler och under vilka villkor. Bra routing minskar brus utan att missa kritiska larm.
Definiera de inputs dina regler kan utvärdera. Håll första versionen liten men uttrycksfull:
invoice.overdue, deployment.failed, comment.mentioned)Dessa inputs bör härledas från ditt eventkontrakt, inte skrivas manuellt av administratörer per notifikation.
Åtgärder specificerar leveransbeteendet:
Definiera en tydlig prioritet och fallback-ordning per regel. Exempel: försök push först, sedan SMS om push misslyckas, sedan email som sista utväg.
Koppla fallback till verkliga leveranssignaler (bounced, provider error, device unreachable) och stoppa retry-loopar med tydliga tak.
Regler ska vara redigerbara via en vägledd UI (dropdowns, förhandsvisningar och varningar), med:
Mallar är där centraliserad notifikationshantering förvandlar "en massa meddelanden" till en sammanhållen produktupplevelse. Ett bra mallsystem håller tonen konsekvent över team, minskar fel och gör flerkanalig leverans (email, SMS, push, i-app) mer genomtänkt än improviserad.
Behandla en mall som en strukturerad tillgång, inte rå text. Minst bör du spara:
{{first_name}}, {{order_id}}, {{amount}})Behåll variabler explicita med ett schema så systemet kan validera att ett event-payload innehåller allt som krävs. Detta förhindrar halvrenderade meddelanden som "Hej {{name}}".
Definiera hur mottagarens locale väljs: användarpreferens först, sedan konto/org-inställning, sedan en default (ofta en). För varje mall, spara översättningar per locale med en tydlig fallback-policy:
fr-CA saknas, fall tillbaka till fr.fr saknas, fall tillbaka till mallens default-locale.Detta gör att saknade översättningar syns i rapporteringen istället för att tyst degradera.
Erbjud en mallförhandsvisning där en administratör kan välja:
Rendera slutliga meddelandet exakt som pipelinen kommer skicka det, inklusive länk-omskrivning och trunkeringsregler. Lägg till en test-sändning som riktas mot en säker “sandbox-mottagarlista” för att undvika att av misstag skicka till kunder.
Mallar bör versionshanteras som kod: varje ändring skapar en ny oföränderlig version. Använd statusar som Draft → In review → Approved → Active, med rollbaserade godkännanden vid behov. Återställningar ska vara ett klick.
För revisionsbarhet, registrera vem som ändrade vad, när och varför, och länka det till leveransutfall så du kan korrelera feltoppar med malländringar (se också blog/audit-logs-for-notifications).
Ett notifikationsnav är bara så pålitligt som sin "sista mil": kanal-leverantörerna som faktiskt levererar email, SMS och push. Målet är att få varje leverantör att kännas som ett "plug-in", samtidigt som leveransbeteendet är konsekvent över kanaler.
Börja med en välstödd leverantör för varje kanal—t.ex. SMTP eller en e-post-API, en SMS-gateway och en push-tjänst (APNs/FCM via en vendor). Håll integrationer bakom ett gemensamt gränssnitt så du kan byta eller lägga till leverantörer senare utan att skriva om affärslogiken.
Varje integration bör hantera:
Behandla "skicka notifikation" som en pipeline med tydliga steg: enqueue → prepare → send → record. Även om din app är liten förhindrar en köbaserad worker-modell att långsamma leverantörsanrop blockerar webbappen och ger en plats att implementera retries säkert.
Ett praktiskt tillvägagångssätt:
Leverantörer returnerar väldigt olika svar. Normalisera dem till en intern statusmodell som: queued, sent, delivered, failed, bounced, suppressed, throttled.
Spara rå leverantörspayload för felsökning, men basera dashboards och larm på den normaliserade statusen.
Implementera retries med exponential backoff och ett maximalt försökstak. Retry bara temporära fel (timeouts, 5xx, throttling), inte permanenta fel (ogiltigt nummer, hård bounce).
Respektera leverantörernas rate limits genom per-leverantör throttling. För högvolym-händelser, batcha där leverantören stödjer det (t.ex. bulk e-post-API) för att minska kostnad och förbättra genomströmning.
Ett notifikationsnav är bara så trovärdigt som dess synlighet. När en kund säger "jag fick aldrig det mailet" behöver du ett snabbt sätt att svara: vad skickades, genom vilken kanal och vad hände sedan.
Standardisera en liten uppsättning leveransstater över kanaler så rapportering förblir konsekvent. En praktisk baseline är:
Behandla dessa som en tidslinje, inte ett enda värde—varje meddelandeförsök kan avge flera statusuppdateringar.
Skapa en meddelandelogg som är enkel för support och drift att använda. Minst bör den vara sökbar på:
invoice.paid, password.reset)Inkludera nyckeldetaljer: kanal, mallnamn/version, locale, leverantör, felkoder och retry-count. Gör den säker som standard: maskera känsliga fält (t.ex. delvis rött e-post/telefon) och begränsa åtkomst via roller.
Lägg till trace IDs för att koppla varje notifikation tillbaka till utlösande åtgärd (kassa, admin-uppdatering, webhook). Använd samma trace ID i:
Detta förvandlar "vad hände?" till en enda filtrerad vy istället för en jakt över flera system.
Fokusera dashboards på beslut, inte vanity-metrics:
Lägg till drill-down från diagramen in i underliggande meddelandelogg så varje metric kan förklaras.
Ett notifikationsnav hanterar kunddata, leverantörscredentials och meddelandeinnehåll—så säkerhet måste designas in, inte klistras på i efterhand. Målet är enkelt: bara rätt personer kan ändra beteende, hemligheter förblir hemliga och varje ändring är spårbar.
Börja med en liten uppsättning roller och mappa dem till de handlingar som betyder något:
Använd minst-privilegium som standard: nya användare ska aldrig kunna redigera regler eller credentials förrän det uttryckligen beviljats.
Leverantörsnycklar, webhook-signeringshemligheter och API-tokens måste behandlas som hemligheter end-to-end:
Varje konfigurationsändring bör skriva ett oföränderligt audit-event: vem ändrade vad, när, varifrån (IP/enhet) och före/efter-värden (med hemliga fält maskerade). Spåra ändringar i routingregler, mallar, leverantörsnycklar och behörighetsassigneringar. Erbjud enkel export (CSV/JSON) för efterlevnadsgranskningar.
Definiera retention per datatyp (events, leveransförsök, innehåll, auditlogs) och dokumentera det i UI:n. Vid behov, stöd raderingsförfrågningar genom att ta bort eller anonymisera mottagaridentifierare samtidigt som aggregerade leveransmetrik och maskerade auditposter behålls.
Ett notifikationsnav lyckas eller misslyckas på användbarhet. De flesta team kommer inte "hantera notifikationer" dagligen—förrän något går sönder eller en incident inträffar. Designa UI:t för snabb överblick, säkra ändringar och tydliga utfall.
Regler bör läsa som policyer, inte kod. Använd en tabell med "IF event… THEN send…"-formulering, plus chips för kanaler (Email/SMS/Push/Slack) och mottagare. Inkludera en simulator: välj ett event och se exakt vem som skulle få vad, var och när.
Mallar vinner på en sida-vid-sida-editor och förhandsgranskning. Låt administratörer växla locale, kanal och exempeldata. Ge versionshantering med en "publish"-steg och en ett-klicks rollback.
Mottagare bör stödja både individer och grupper (team, roller, segment). Visa medlemskap tydligt ("varför är Alex i On-call?") och visa var en recipient refereras av regler.
Leverantörshälsa behöver en överblick: leveranslatens, felrate, ködjup och senaste incident. Länka varje problem till en mänsklig förklaring och nästa steg (t.ex. "Twilio auth failed—kolla API-nyckelrättigheter").
Håll preferenser lätta: kanalopt-ins, tysta tider och ämnes-/kategoriväxlar (t.ex. "Billing", "Security", "Produktuppdateringar"). Visa en plattformsförklaring högst upp ("Du får säkerhetslarm via SMS, när som helst").
Inkludera avprenumerationsflöden som är respektfulla och efterlevnadsmässiga: en-klick för marknadsföring, och tydlig information när kritiska larm inte kan stängas av ("Krävs för kontosäkerhet"). Om en användare inaktiverar en kanal, bekräfta vilka förändringar det medför ("Inga fler SMS; e-post förblir aktiverat").
Operatorer behöver verktyg som är säkra under press:
Tomma tillstånd bör vägleda setup ("Inga regler ännu—skapa din första routingregel") och peka på nästa steg (t.ex. /rules/new). Felmeddelanden ska inkludera vad som hände, vad det påverkade och vad man kan göra härnäst—utan intern jargong. När möjligt, erbjud en snabbfix ("Återanslut leverantör") och en "kopiera detaljer"-knapp för supportärenden.
Ett centraliserat notifikationsnav kan växa till en stor plattform, men det bör börja litet. Målet med MVP:n är att bevisa end-to-end-flödet (event → routing → template → send → track) med så få rörliga delar som möjligt, och sedan utöka säkert.
Om du vill snabba upp första fungerande versionen kan en vibe-coding-plattform som Koder.ai hjälpa dig att snabbt sätta upp adminkonsolen och kärn-API:et: bygg ett React-UI, en Go-backend med PostgreSQL, och iterera i en chattdriven workflow—använd sedan planning mode, snapshots och rollback för att hålla ändringar säkra när du finslipar regler, mallar och revisionsloggar.
Håll första releasen avsiktligt smal:
Denna MVP ska svara på: "Kan vi pålitligt skicka rätt meddelande till rätt mottagare och se vad som hände?"
Notifikationer är användarvända och tidskritiska, så automatiska tester ger snabbt avkastning. Fokusera på tre områden:
Lägg till ett litet set end-to-end-tester som skickar till ett sandbox-leverantörskonto i CI.
Använd stagad deployment:
När stabilt, expandera i tydliga steg: lägg till kanaler (SMS, push, i-app), rikare routing, förbättrade mallverktyg och djupare analys (leveransgrader, tid-till-leverans, opt-out-trender).
Centraliserad notifikationshantering är ett enda system som tar emot events (t.ex. invoice.paid), tillämpar preferenser och routingregler, renderar mallar per kanal, levererar via leverantörer (email/SMS/push/osv.) och registrerar resultatet i hela flödet.
Det ersätter ad-hoc "skicka ett mail här"-logik med en konsekvent pipeline som du kan driva och granska.
Vanliga tidiga signaler inkluderar:
Om detta upprepas så tjänar ett nav sig ofta snabbt in.
Börja med en liten uppsättning kanaler som du kan drifta tillförlitligt:
Dokumentera “senare” kanaler (Slack/Teams, webhooks, WhatsApp) så att din datamodell kan utökas utan brytande ändringar, men undvik att integrera dem i MVP:n.
Ett praktiskt MVP bevisar hela loopen (event → route → template → deliver → track) med minimal komplexitet:
queued/sent/failedMålet är tillförlitlighet och observabilitet, inte funktionsbredd.
Använd ett litet, explicit eventkontrakt så routing och mallar inte behöver gissa:
event_name (stabil)actor (vem som utlöste det)recipient (vem det gäller)Idempotens förhindrar dubbletter när producenter retryar eller när navet retryar.
Praktiskt tillvägagångssätt:
idempotency_key per event (t.ex. invoice_123_paid)Detta är särskilt viktigt för flerkanaliga och retry-tunga flöden.
Separera identitet från kontaktpunkter:
Spåra verifieringsstatus per recipient (unverified/verified/blocked) och använd lager av defaultinställningar för preferenser (org → team → user → recipient).
Modellera samtycke per kanal och notifikationstyp och gör det revisionsbart:
Behåll en exportbar vy av samtyckeshistoriken så support kan svara på “varför fick jag detta?” på ett tillförlitligt sätt.
Normalisera leverantörsspecifika utfall till en konsekvent intern statusmaskin:
queued, sent, delivered, failed, bounced, suppressed, throttledAnvänd säkra arbetsmönster och skyddsåtgärder:
Logga allt oföränderligt vem som ändrade vad och när.
payloadmetadata (tenant, timestamp, source, locale hints)Lägg till schema_version och en idempotency-nyckel så retries inte skapar dubbletter.
Spara råa leverantörssvar för felsökning, men basera dashboards och larm på de normaliserade statusarna. Behandla status som en tidslinje (flera uppdateringar per försök), inte ett enda värde.