21 maj 2025·8 min
Skapa en webbapp för centraliserad SLA‑rapportering
Lär dig planera, bygga och lansera en multi‑kunds webbapp som samlar SLA‑data, normaliserar mätvärden och levererar dashboards, varningar och exportbara rapporter.
Lär dig planera, bygga och lansera en multi‑kunds webbapp som samlar SLA‑data, normaliserar mätvärden och levererar dashboards, varningar och exportbara rapporter.
Centraliserad SLA‑rapportering finns för att bevis för SLA sällan ligger på ett ställe. Uppetid kan finnas i ett övervakningsverktyg, incidenter i en status‑sida, tickets i ett helpdesk‑system och eskalationsanteckningar i e‑post eller chatt. När varje kund har en något annorlunda stack (eller olika namngivningskonventioner) blir månadsrapportering manuellt kalkylbladsarbete — och tvister om “vad som egentligen hände” blir vanliga.
En bra SLA‑rapporteringstjänst betjänar flera målgrupper med olika mål:
Appen bör presentera samma underliggande sanning på olika detaljnivåer beroende på roll.
En centraliserad SLA‑dashboard bör leverera:
I praktiken bör varje SLA‑siffra kunna spåras till råa händelser (larm, tickets, incidenttidslinjer) med tidsstämplar och ansvarig.
Innan ni bygger något, definiera vad som är in scope och out of scope. Till exempel:
Tydliga gränser förhindrar debatter senare och håller rapporteringen konsekvent över kunder.
Minst bör centraliserad SLA‑rapportering stödja fem arbetsflöden:
Designa runt dessa arbetsflöden från dag ett så håller resten av systemet (datamodell, integrationer och UX) sig i linje med verkliga rapporteringsbehov.
Innan du bygger skärmar eller pipelines, bestäm vad din app ska mäta och hur dessa siffror ska tolkas. Målet är konsekvens: två personer som läser samma rapport ska dra samma slutsats.
Börja med en liten uppsättning som de flesta kunder känner igen:
Var tydlig med vad varje mått mäter och vad det inte gör. En kort definitionspanel i UI (och en länk till /help/sla-definitions) förebygger missförstånd senare.
Regler är där SLA‑rapportering vanligtvis går sönder. Dokumentera dem i meningar som din kund kan validera, och översätt dem sedan till logik.
Täcka det väsentliga:
Välj standardperioder (månatliga och kvartalsvisa är vanliga) och om ni ska stödja anpassade intervall. Klargör vilken tidszon som används för avgränsningar.
För överträdelser, definiera:
För varje mått, lista nödvändiga ingångar (övervakningshändelser, incidentposter, ticket‑tidsstämplar, underhållsfönster). Detta blir din ritning för integrationer och datakvalitetskontroller.
Innan du designar dashboards eller KPI:er, var tydlig med var SLA‑bevis faktiskt ligger. De flesta team upptäcker att deras “SLA‑data” är splittrad över verktyg, ägd av olika grupper och registrerad med något olika betydelser.
Börja med en enkel lista per kund (och per tjänst):
För varje system, notera ägare, retentionstid, API‑begränsningar, tidsupplösning (sekunder vs minuter) och om data är kundavgränsad eller delad.
De flesta SLA‑appar använder en kombination:
En praktisk regel: använd webhooks där färskhet spelar roll, och API‑pulls där fullständighet spelar roll.
Olika verktyg beskriver samma sak på olika sätt. Normalisera till en liten uppsättning events din app kan lita på, till exempel:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedInkludera konsekventa fält: client_id, service_id, source_system, external_id, severity och tidsstämplar.
Spara alla tidsstämplar i UTC, och konvertera vid visning baserat på kundens föredragna tidszon (särskilt för månatliga cutoff‑regler).
Planera för luckor också: vissa kunder har ingen status‑sida, vissa tjänster övervakas inte 24/7 och vissa verktyg kan förlora events. Gör “partiell täckning” synligt i rapporter (t.ex. “övervakningsdata saknas i 3 timmar”) så att SLA‑resultat inte blir missvisande.
Om din app rapporterar SLA:er för flera kunder avgör arkitekturval om du kan skala säkert utan dataläckage mellan kunder.
Börja med att namnge lager du behöver stödja. En “kund” kan vara:
Skriv ner dem tidigt, eftersom de påverkar behörigheter, filter och hur du lagrar konfiguration.
De flesta SLA‑appar väljer en av dessa:
tenant_id. Kostnadseffektivt och enklare att drifta, men kräver strikt frågedisciplin.Ett vanligt kompromissmönster är delad DB för de flesta tenants och dedikerade DB för “enterprise”‑kunder.
Isolation måste gälla över:
tenant_id så resultat inte kan skrivas till fel tenantAnvänd skydd som row‑level security, obligatoriska query‑scopes och automatiserade tester för tenant‑gränser.
Olika kunder har olika mål och definitioner. Planera för per‑tenant‑inställningar som:
Interna användare behöver ofta “impersonera” en kundvy. Implementera en avsiktlig switch (inte ett fritt filter), visa aktiv tenant tydligt, logga byten för revision och förhindra länkar som kan kringgå tenant‑kontroller.
En centraliserad SLA‑app lever eller dör på sin datamodell. Om du endast modellerar “SLA % per månad” kommer du ha svårt att förklara resultat, hantera tvister eller uppdatera beräkningar senare. Om du bara modellerar råa events blir rapportering långsam och dyr. Målet är att stödja båda: spårbart råbevis och snabba, kundklara rollups.
Håll en tydlig separation mellan vem som rapporteras om, vad som mäts och hur det beräknas:
Designa tabeller (eller collections) för:
SLA‑logik förändras: affärstider uppdateras, exklusioner förtydligas, avrundningsregler utvecklas. Addera en calculation_version (och helst en referens till ett regelsätt) till varje beräknat resultat. Då kan gamla rapporter reproduceras exakt även efter förbättringar.
Inkludera auditfält där de betyder något:
Kunder frågar ofta “visa varför”. Planera ett schema för bevis:
Denna struktur håller appen förklarbar, reproducerbar och snabb — utan att förlora underliggande bevis.
Om dina inputs är röriga blir även SLA‑dashboarden det. En pålitlig pipeline omvandlar incident‑ och ticketdata från flera verktyg till konsekventa, auditerbara SLA‑resultat — utan dubbelräkning, luckor eller tysta fel.
Behandla ingestion, normalisering och rollups som separata steg. Kör dem som bakgrundsjobb så UI förblir snabbt och du kan retryna säkert.
Denna separation hjälper också när en kunds källa är nere: ingestion kan misslyckas utan att korrupta befintliga beräkningar.
Externa API:er time‑outar. Webhooks kan levereras två gånger. Din pipeline måste vara idempotent: att bearbeta samma input flera gånger ska inte ändra utfall.
Vanliga angreppssätt:
Över kunder och verktyg kan “P1”, “Critical” och “Urgent” betyda samma prioritet — eller inte. Bygg ett normaliseringslager som standardiserar:
Spara både ursprungligt värde och normaliserat värde för spårbarhet.
Lägg till valideringsregler (saknade tidsstämplar, negativa durationer, omöjliga statusövergångar). Droppa inte dåliga data tyst — routa dem till en quarantine‑kö med orsak och ett “åtgärda eller mappa”‑arbetsflöde.
För varje kund och källa, beräkna “senaste lyckade sync”, “äldsta oprocesserade event” och “rollup uppdaterad t.o.m.”. Visa detta som en enkel data‑färskhetsindikator så att kunder litar på siffrorna och ditt team snabbt upptäcker problem.
Om kunder använder din portal för att granska SLA‑prestanda måste autentisering och behörigheter designas lika noggrant som SLA‑matematiken. Målet är enkelt: varje användare ska se endast det hen får — och du ska kunna bevisa det senare.
Börja med ett litet, tydligt set roller och expandera bara vid goda skäl:
Håll least privilege som standard: nya konton bör hamna i viewer‑läge om inte uttryckligen befordrade.
För interna team minskar SSO kontoöverblomstring och offboarding‑risk. Stöd OIDC (vanligt med Google Workspace/Azure AD/Okta) och, där det krävs, SAML.
För kunder, erbjud SSO som uppgradering men tillåt e‑post/lösenord med MFA för mindre organisationer.
Genomdriv tenant‑gränser på varje lager:
Logga åtkomst till känsliga sidor och nedladdningar: vem, vad, när och varifrån. Det hjälper med regelefterlevnad och kundförtroende.
Bygg ett onboardingflöde där admins eller kundeditors kan bjuda in användare, sätta roller, kräva e‑postverifiering och återkalla åtkomst omgående när någon slutar.
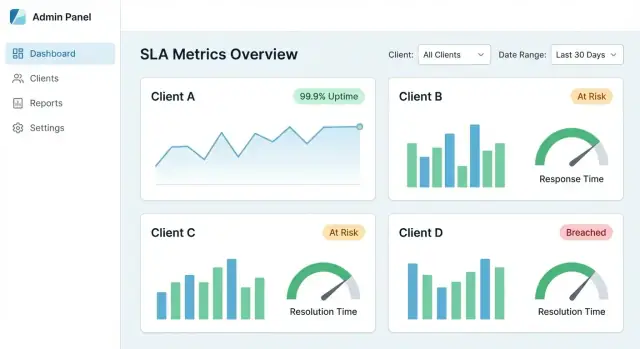
En centraliserad SLA‑dashboard lyckas när en kund kan svara tre frågor under en minut: Möter vi SLA:erna? Vad ändrades? Vad orsakade missarna? Din UX ska guida dem från högnivå till bevis — utan att tvinga dem lära sig din interna datamodell.
Börja med ett litet set kort och diagram som matchar vanliga SLA‑samtal:
Gör varje kort klickbart så det blir en dörr till detaljer, inte en återvändsgränd.
Filter bör vara konsekventa över alla sidor och “sitta kvar” när användare navigerar.
Rekommenderade standarder:
Visa aktiva filter som chips högst upp så användare alltid förstår vad de ser.
Varje metrik bör ha en väg till “varför”. Ett starkt drill‑down‑flöde:
Om en siffra inte kan förklaras med bevis kommer den att ifrågasättas — särskilt under QBR.
Lägg till tooltips eller en “info”‑panel för varje KPI: hur den beräknas, exklusioner, tidszon och datafärskhet. Inkludera exempel som “Underhållsfönster exkluderade” eller “Uptime mätt vid API‑gateway”.
Gör filtrerade vyer delbara via stabila URL:er (t.ex. /reports/sla?client=acme&service=api&range=30d). Detta gör din centraliserade SLA‑dashboard till en klientklar rapportportal som stödjer återkommande uppföljningar och revisionsspår.
En centraliserad SLA‑dashboard är användbar dagligen, men kunder vill ofta ha något de kan vidarebefordra internt: en PDF för ledningen, en CSV för analytiker och en länk som går att bokmärka.
Stöd tre utdataformat från samma underliggande SLA‑resultat:
För länkbaserade rapporter, gör filtren explicita (datumintervall, tjänst, svårighetsgrad) så kunden vet exakt vad siffrorna representerar.
Lägg till schemaläggning så varje kund kan få rapporter automatiskt — veckovis, månadsvis eller kvartalsvis — skickade till en kundspecifik lista eller en delad inkorg. Håll scheman tenant‑scopade och auditerbara (vem skapade det, senast skickat, nästa körning).
Om du behöver en enkel startpunkt, lansera med en “månatlig sammanfattning” plus en enkel nedladdning från /reports.
Bygg mallar som läses som QBR/MBR‑slides i skriftlig form:
Verkliga SLA:er innehåller undantag (underhållsfönster, tredjepartsavbrott). Låt användare bifoga compliance notes och flagga undantag som kräver godkännande, med ett approvals‑spår.
Exporter måste respektera tenant‑isolation och rollbehörigheter. En användare bör endast exportera de kunder, tjänster och perioder de har rätt att se — och exporten ska matcha portalvyn exakt (inga extra kolumner som läcker dolt data).
Aviseringar är där en SLA‑rapporteringstjänst går från “intressant dashboard” till ett operationellt verktyg. Målet är inte att skicka fler meddelanden — utan att hjälpa rätt personer reagera tidigt, dokumentera vad som hände och hålla kunder informerade.
Börja med tre kategorier:
Knyt varje alert till en klar definition (metrik, tidsfönster, tröskel, kundscope) så mottagare kan lita på den.
Erbjud flera leveransalternativ så team kan använda de kanaler kunder redan arbetar i:
För multi‑kundsrapportering, routa notifikationer med tenant‑regler (t.ex. “Kund A‑överträdelser går till Kanal A; interna överträdelser går till on‑call”). Undvik att skicka kundspecifika detaljer till delade kanaler.
Alert fatigue dödar adoption. Implementera:
Varje alert bör stödja:
Detta skapar ett lättvikts audit‑spår som kan återanvändas i klientklara sammanfattningar.
Ge en grundläggande reglereditor för per‑kunds trösklar och routing (utan att exponera komplex query‑logik). Skyddsåtgärder hjälper: standarder, validering och förhandsgranskning (“denna regel skulle ha triggat 3 gånger förra månaden”).
En centraliserad SLA‑app blir snabbt mission‑kritisk eftersom kunder använder den för att bedöma tjänstekvalitet. Det gör hastighet, säkerhet och bevis (för revisioner) lika viktiga som diagrammen själva.
Stora kunder kan generera miljontals tickets, incidenter och övervakningshändelser. För att hålla sidor responsiva:
Råa events är värdefulla för utredningar, men att behålla allt för evigt ökar kostnad och risk.
Sätt klara regler som:
För en kundportal, anta känsligt innehåll: kundnamn, tidsstämplar, ticket‑anteckningar och ibland PII.
Även om ni inte siktar på en specifik standard bygger bra driftbevis förtroende.
Underhåll:
Att lansera en SLA‑app handlar mindre om en stor release och mer om att bevisa noggrannhet och sedan skala repeterbart. En stark lanseringsplan minskar tvister genom att göra resultat lätta att verifiera och reproducera.
Välj en kund med en hanterbar uppsättning tjänster och datakällor. Kör appens SLA‑beräkningar parallellt med deras befintliga kalkylblad, ticke‑exporter eller leverantörsportalrapporter.
Fokusera på vanliga mismatch‑områden:
Dokumentera skillnader och bestäm om appen ska matcha kundens nuvarande tillvägagångssätt eller ersätta det med en klarare standard.
Skapa en repeterbar onboarding‑checklista så varje ny kundupplevelse blir förutsägbar:
En checklista hjälper också att uppskatta insats och stöd för diskussioner om /pricing.
SLA‑dashboards är bara trovärdiga om de är färska och fullständiga. Lägg till monitoring för:
Skicka interna alertar först; när stabilt kan du introducera kundsynliga statusnotiser.
Samla feedback på var förvirring uppstår: definitioner, tvister (“varför är detta en överträdelse?”) och “vad ändrades” sedan förra månaden. Prioritera små UX‑förbättringar som tooltips, ändringsloggar och tydliga fotnoter om exklusioner.
Om du vill skicka en intern MVP snabbt (tenant‑modell, integrationer, dashboards, exporter) utan veckor av boilerplate kan en vibe‑coding‑metod hjälpa. Till exempel låter Koder.ai team skissa och iterera på en multi‑tenant webapp via chatt — och sedan exportera källkoden och driftsätta. Det passar väl för SLA‑produkter där kärnkomplexiteten är domänregler och datanormalisering snarare än engångs UI‑scaffolding.
Du kan använda Koder.ai:s planning‑läge för att lägga ut entiteter (tenants, services, SLA‑definitions, events, rollups), och sedan generera en React‑UI och en Go/PostgreSQL‑backend som bas att bygga vidare på.
Håll ett levande dokument med nästa steg: nya integrationer, exportformat och revisionsspår. Koppla till relaterade guider på /blog så kunder och medarbetare kan självserva detaljer.
Centraliserad SLA-rapportering bör skapa en enda sanningskälla genom att samla uppetid, incidenter och ticket-tidslinjer i en enda, spårbar vy.
I praktiken bör den:
Börja med en liten uppsättning som de flesta kunder känner igen, och utöka bara när du kan förklara och granska dem.
Vanliga startmetrik:
Dokumentera för varje metrik vad den mäter, vad den exkluderar och vilka datakällor som krävs.
Skriv reglerna i enkelt språk först, och konvertera dem sedan till logik.
Du behöver vanligtvis definiera:
Om två personer inte kan enas om meningstexten kommer kodversionen att ifrågasättas senare.
Spara alla tidsstämplar i UTC och konvertera för visning med tenantens rapporteringstidzon.
Bestäm också i förväg:
Var tydlig i UI (t.ex. “Rapportperiodens avgränsningar är i America/New_York”).
Använd en mix av integrationsmetoder beroende på behov av färskhet kontra fullständighet:
Praktisk regel: använd webhooks där färskhet är viktig, API-pulls där fullständighet är viktig.
Definiera en liten kanonisk uppsättning normaliserade events så att olika verktyg mappas till samma begrepp.
Exempel:
incident_opened / incident_closedVälj en multi‑tenancy‑modell och genomdriv isolering utanför bara UI.
Viktiga skydd:
tenant_idAnta att exportjobb och bakgrundsjobb är de lättaste ställena att av misstag läcka data om man inte designar för tenant‑kontext.
Spara både råa events och härledda resultat så att du kan vara både snabb och förklarande.
Praktisk uppdelning:
Gör pipeline-stegen tydliga och idempotenta:
För tillförlitlighet:
Inkludera tre varselkategorier så att systemet är operationellt, inte bara en dashboard:
Minska brus med deduplicering, tysta timmar och eskalering, och gör varje alert handlingsbar med bekräftelse och resolutionsanteckningar.
downtime_started / downtime_endedticket_created / first_response / resolvedInkludera konsekventa fält som tenant_id, service_id, source_system, external_id, severity och UTC-tidsstämplar.
Lägg till en calculation_version så att gamla rapporter kan reproduceras exakt efter regeländringar.