18 aug. 2025·8 min
Chris Lattners LLVM: den tysta motorn bakom moderna verktygskedjor
Lär dig hur Chris Lattners LLVM blev den modulära kompilatorplattformen bakom språk och verktyg—som driver optimeringar, bättre diagnostik och snabba byggen.
Vad LLVM är, på enkelt språk
LLVM ses bäst som ”maskinrummet” som många kompilatorer och utvecklingsverktyg delar.
När du skriver kod i ett språk som C, Swift eller Rust måste något översätta den koden till instruktioner som din CPU kan köra. En traditionell kompilator byggde ofta hela den pipelinen själv. LLVM tar en annan väg: det erbjuder en högkvalitativ, återanvändbar kärna som hanterar de svåra och dyra delarna—optimering, analys och att generera maskinkod för många typer av processorer.
En gemensam grund för många språk
LLVM är sällan en enda kompilator du ”använder direkt”. Det är kompilatorinfrastruktur: byggstenar som språkteam kan sätta ihop till en verktygskedja. Ett team kan fokusera på syntax, semantik och utvecklarvänliga funktioner, och sedan överlämna det tunga arbetet till LLVM.
Denna delade grund är en stor anledning till att moderna språk kan leverera snabba, säkra verktygskedjor utan att uppfinna decennier av kompilatorarbete på nytt.
Varför det spelar roll även om du inte är kompilatorperson
LLVM visar sig i den dagliga utvecklarupplevelsen:
- Hastighet: det kan förvandla högre nivåns kod till effektiv maskinkod över många plattformar.
- Bättre fel och debug: ekosystemet runt LLVM möjliggör rikare diagnostik och bättre verktyg.
- Mer än ”bara kompilering”: statisk analys, sanitizers, kodtäckning och andra utvecklarhjälpmedel bygger ofta på samma underliggande representation och bibliotek.
Vad den här artikeln kommer (och inte kommer) att vara
Detta är en guidad rundtur i de idéer Chris Lattner satte i rörelse: hur LLVM är uppbyggt, varför mellanskiktet är viktigt, och hur det möjliggör optimeringar och stöd för flera plattformar. Det är inte en lärobok—fokus ligger på intuition och verklig påverkan snarare än formell teori.
Chris Lattners ursprungliga vision
Chris Lattner är en datavetare och ingenjör som, som forskarstuderande i början av 2000-talet, startade LLVM utifrån en praktisk frustration: kompilatorteknik var kraftfull men svår att återanvända. Om du ville ha ett nytt programspråk, bättre optimeringar eller stöd för en ny CPU, var du ofta tvungen att pilla på en tätt ihopkopplad ”allt-i-ett” kompilator där varje förändring fick sidokonsekvenser.
Problemet han ville lösa
På den tiden byggdes många kompilatorer som en enda stor maskin: delen som förstod språket, delen som optimerade och delen som genererade maskinkod var djupt sammanflätade. Det gjorde dem effektiva för sitt ursprungliga syfte, men dyra att anpassa.
Lattners mål var inte ”en kompilator för ett språk”. Det var en delad grund som kunde driva många språk och verktyg—utan att alla behövde skriva om samma komplexa delar om och om igen. Gissningen var att om man kunde standardisera mitten av pipelinen, kunde man innovera snabbare vid kanterna.
Varför ”modulär infrastruktur” var en frisk idé
Den centrala förändringen var att betrakta kompilering som en uppsättning separerbara byggstenar med tydliga gränser. I en modulär värld:
- ett språkteam kan fokusera på parsning och utvecklarfunktioner,
- ett optimeringsteam kan förbättra prestanda en gång och dela det brett,
- hårdvarustöd kan läggas till utan att hela upstream-designen måste göras om.
Denna separation låter idag självklar, men motsatte sig hur många produktionskompilatorer hade utvecklats.
Open source, byggt för att användas av andra
LLVM släpptes tidigt som open source, vilket spelade stor roll eftersom en delad infrastruktur bara fungerar om flera grupper kan lita på den, inspektera den och utöka den. Med tiden formade universitet, företag och oberoende bidragsgivare projektet genom att lägga till mål, fixa hörntillstånd, förbättra prestanda och bygga nya verktyg runt det.
Denna community-aspekt var inte bara goodwill—det var en del av designen: gör kärnan allmänt användbar, så blir den värd att underhålla tillsammans.
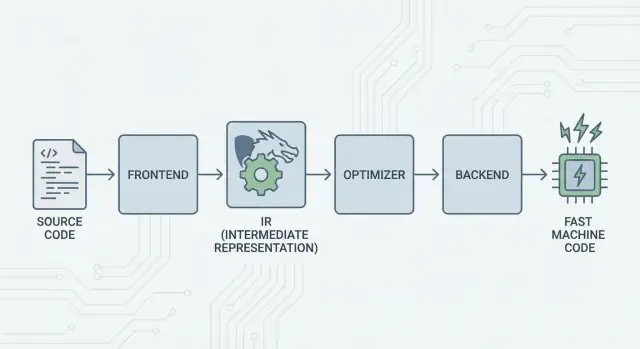
Den stora idén: frontends, en gemensam kärna och backends
LLVMs kärnidé är enkel: dela en kompilator i tre huvudsakliga delar så att många språk kan dela det svåraste arbetet.
1) Frontends: ”Vad menade programmeraren?”
En frontend förstår ett specifikt programspråk. Den läser din källkod, kontrollerar reglerna (syntax och typer) och översätter den till en strukturerad representation.
Viktigt: frontends behöver inte känna till alla CPU-detaljer. Deras jobb är att översätta språkbegrepp—funktioner, loopar, variabler—till något mer universellt.
2) Den delade mitten: en gemensam kärna istället för N×M-arbete
Traditionellt innebar det att bygga en kompilator att göra samma arbete om och om igen:
- Med N språk och M CPU-mål får du N×M kombinationer att stödja.
LLVM minskar det till:
- N frontends som översätter till en delad form
- M backends som översätter från den delade formen till maskinkod
Denna ”delade form” är LLVMs centrum: en gemensam pipeline där optimeringar och analyser lever. Detta är den stora förenklingen. Förbättringar i mitten (som bättre optimeringar eller bättre debug-info) kan gynna många språk samtidigt, istället för att implementeras i varje kompilator.
3) Backends: ”Hur får vi det att gå snabbt på den här CPU:n?”
En backend tar den delade representationen och producerar maskinspecifikt output: instruktioner för x86, ARM med flera. Här spelar detaljer som register, anropskonventioner och instruktionval roll.
En intuitiv bild av pipelinen
Tänk på kompilering som en resrutt:
- Källkod börjar i ett språk-specifikt land (frontend).
- Den korsar en gräns in i ett delat, standardiserat ”mellanspråk” (LLVMs kärnrepresentation och pass).
- Den tar sedan ett lokalt tåg till en specifik slutdestination (backend för din målmaskin).
Resultatet är en modulär verktygskedja: språk kan fokusera på att uttrycka idéer tydligt, medan LLVMs delade kärna fokuserar på att få dessa idéer att köra effektivt över många plattformar.
LLVM IR: mellanskiktet som möjliggör återanvändning
LLVM IR (Intermediate Representation) är det ”gemensamma språket” som sitter mellan ett programspråk och den maskinkod din CPU kör.
En kompilatorfrontend (som Clang för C/C++) översätter din källkod till denna delade form. Sedan arbetar LLVMs optimerare och kodgeneratorer på IR, inte på ursprungsspråket. Slutligen förvandlar en backend IR till instruktioner för ett specifikt mål (x86, ARM med flera).
Ett gemensamt språk mellan verktyg och CPU:er
Tänk på LLVM IR som en väl utformad bro:
- Ovanför: många källspråk kan ansluta (C, C++, Rust, Swift, Julia osv.).
- Nedanför: många CPU:er kan riktas mot.
- I mitten: samma analys- och optimeringsverktyg kan återanvändas.
Detta är varför folk ofta beskriver LLVM som ”kompilatorinfrastruktur” snarare än ”en kompilator”. IR är det delade kontraktet som gör infrastrukturen återanvändbar.
Varför IR möjliggör återanvändning (och sparar tid)
När koden väl är i LLVM IR behöver de flesta optimeringspass inte veta om den började som C++-templates, Rust-iteratorer eller Swift-generics. De bryr sig mest om universella idéer som:
- ”Detta värde är konstant.”
- ”Denna beräkning upprepas; kan vi återanvända resultatet?”
- ”Denna minnesläsning kan flyttas eller tas bort säkert.”
Så språkteam behöver inte bygga (och underhålla) sin egen kompletta optimeringsstack. De kan fokusera på frontenden—parsning, typkontroll, språkregler—och sedan överlåta det tunga arbetet till LLVM.
Hur det ”ser ut” konceptuellt
LLVM IR är tillräckligt låg nivå för att mappas rent till maskinkod, men ändå strukturerad nog för analys. Konceptuellt byggs den av enkla instruktioner (add, compare, load/store), explicit kontrollflöde (grenar) och starkt typade värden—mer lik en prydlig assembler avsedd för kompilatorer än något människor normalt skriver.
Hur optimeringar fungerar (utan matte)
När folk hör ”kompilatoroptimeringar” föreställer de sig ofta mystiska trick. I LLVM är de flesta optimeringar snarare säkra, mekaniska omskrivningar av programmet—transformationer som bevarar vad koden gör men syftar till att göra det snabbare (eller mindre).
Tänk på det som redigering, inte uppfinning
LLVM tar din kod (i LLVM IR) och applicerar upprepade gånger små förbättringar, ungefär som att polera ett utkast:
- Ta bort duplicerat arbete: Om ett värde beräknas två gånger och ingenting ändrats emellan kan LLVM beräkna det en gång och återanvända resultatet.
- Förenkla uppenbar logik: Konstanta uttryck kan vecklas ihop tidigt (t.ex. att ersätta
3 * 4med12), så CPU:n gör mindre vid körning. - Strömlinjeforma loopar: Looprelaterade pass kan minska upprepade kontroller, flytta invariant arbete ut ur loopen eller känna igen mönster som kan köras effektivare.
Dessa förändringar är avsiktligt konservativa. Ett pass utför bara en omskrivning när det kan bevisa att omskrivningen inte ändrar programmets betydelse.
Relaterbara exempel
Om ditt program konceptuellt gör detta:
- Läser samma konfigurationsvärde varje iteration i en loop
- Utför samma beräkning på samma indata på flera ställen
- Kontrollerar ett villkor som alltid är sant/falskt i ett givet sammanhang
…så försöker LLVM göra det till ”gör uppsättningen en gång”, ”återanvänd resultat” och ”ta bort döda grenar”. Det är mindre magi och mer städarbete.
Den verkliga avvägningen: kompileringstid vs. körtid
Optimering är inte gratis: mer analys och fler pass innebär vanligtvis långsammare kompilering, även om det slutliga programmet kör snabbare. Därför erbjuder verktygskedjor nivåer som ”optimera lite” vs. ”optimera aggressivt”.
Profiler kan hjälpa. Med profile-guided optimization (PGO) kör du programmet, samlar verklig användningsdata och kompilerar om så att LLVM fokuserar ansträngningen på de vägar som faktiskt betyder mest—vilket gör avvägningen mer förutsägbar.
Backends: nå många CPU:er utan att skriva om allt
Från bygg till live
Lansera en hostad version utan att manuellt hoppa ihop byggstegen.
En kompilator har två väldigt olika jobb. Först måste den förstå din källkod. Sedan måste den producera maskinkod som en viss CPU kan exekvera. LLVM-backends fokuserar på det andra jobbet.
Vad en backend faktiskt gör
Tänk på LLVM IR som ett ”universellt recept” för vad programmet ska göra. En backend omvandlar det receptet till de exakta instruktionerna för en processorfamilj—x86-64 för de flesta stationära och servrar, ARM64 för många telefoner och nyare laptops, eller specialmål som WebAssembly.
Konkreta ansvar för en backend:
- Instruktionsval: mappa IR-operationer till verkliga CPU-instruktioner
- Registerallokering: välja vilka värden som ligger i snabba CPU-register vs. minne
- Schemaläggning: ordna instruktioner så CPU:n kan köra dem effektivt
- Assembly/objekt-output: skriva ut kod som länkaren och operativsystemet förstår
Varför delad infrastruktur gör hårdvarustöd enklare
Utan en delad kärna skulle varje språk behöva implementera allt detta för varje CPU man vill stödja—en enorm arbetsmängd och ett ständigt underhållsbehov.
LLVM vänder på det: frontends (som Clang) producerar LLVM IR en gång, och backends sköter ”sista milen” per mål. Att lägga till stöd för en ny CPU innebär i allmänhet att skriva en backend (eller utöka en befintlig), inte att skriva om varje kompilator i existens.
Portabilitet för team som levererar på flera plattformar
För projekt som måste köras på Windows/macOS/Linux, på x86 och ARM, eller till och med i webbläsaren, är LLVMs backendmodell en praktisk fördel. Du kan behålla en kodbas och till stor del en byggpipeline, och sedan rikta om genom att välja en annan backend (eller cross-kompilera).
Denna portabilitet är varför LLVM dyker upp överallt: det handlar inte bara om hastighet—det handlar också om att undvika upprepat, plattformsspecifikt kompilatorarbete som bromsar team.
Clang: där många utvecklare först möter LLVM
Clang är C-, C++- och Objective-C-frontend som kopplar in i LLVM. Om LLVM är den delade motorn som kan optimera och generera maskinkod är Clang delen som läser dina källfiler, förstår språkreglerna och förvandlar det du skrev till en form som LLVM kan arbeta med.
Varför Clang blev uppmärksammat
Många utvecklare upptäckte inte LLVM genom att läsa kompilatorartiklar—de stötte på det första gången de bytte kompilator och feedbacken plötsligt hade blivit bättre.
Clangs diagnostik är känd för att vara mer läsbar och mer specifik. Istället för vagt formulerade fel pekar den ofta på exakt token som orsakade problemet, visar den relevanta raden och förklarar vad den förväntade sig. Det spelar roll i det dagliga arbetet eftersom looparna ”kompilera, fixa, upprepa” blir mindre frustrerande.
Clang exponerar också rena, väldokumenterade gränssnitt (särskilt genom libclang och Clang-verktygsekosystemet). Det gjorde det enklare för redigerare, IDE:er och andra utvecklarverktyg att integrera djup språkuppfattning utan att skriva om en C/C++-parser.
Hur det visar sig i dagliga arbetsflöden
När ett verktyg på ett tillförlitligt sätt kan parsa och analysera din kod får du funktioner som känns mindre som textredigering och mer som att arbeta med ett strukturerat program:
- Exakt kodnavigering (”gå till definition”, ”hitta referenser”) även i stora, makrotunga C++-projekt
- Refaktorering som förstår symboler och scopes, inte bara sök-och-ersätt
- Inline-hints och snabba fixar drivna av riktig syntax- och typinformation
Detta är varför Clang ofta är den första ”kontaktpunkten” för LLVM: det är där praktiska förbättringar i utvecklarupplevelsen uppstår. Även om du aldrig tänker på LLVM IR eller backends, drar du nytta när din editorns autokomplettering blir smartare, dina statiska kontroller mer precisa och dina byggfel enklare att åtgärda.
Varför många moderna språk bygger på LLVM
LLVM lockar språkteam av en enkel anledning: det låter dem fokusera på språket istället för att spendera år på att uppfinna en fullfjädrad optimerande kompilator.
Snabbare tid till marknaden
Att bygga ett nytt språk innebär redan parsning, typkontroll, diagnostik, paketverktyg, dokumentation och community-stöd. Om du också måste skapa en produktionsmogen optimizer, kodgenerator och plattformsstöd från grunden fördröjs leveransen—ibland med år.
LLVM erbjuder en färdig kompilator-kärna: registerallokering, instruktionsval, mogna optimeringspass och mål för vanliga CPU:er. Team kan koppla in en frontend som sänker sitt språk till LLVM IR och sedan lita på den befintliga pipelinen för att producera native-kod för macOS, Linux och Windows.
Hög prestanda (utan hjälteinsatser)
LLVMs optimizer och backends är resultatet av långsiktig ingenjörskonst och konstant verklig testning. Det ger stark basprestanda för språk som adopterar det—ofta tillräckligt bra tidigt, och med potential att förbättras i takt med att LLVM förbättras.
Det är en del av varför flera välkända språk byggt runt det:
- Swift använder LLVM för att generera högoptimerade native-binärer över Apple-plattformar.
- Rust förlitar sig på LLVM för kodgenerering och många arkitekturmål.
- Julia använder LLVM för att möjliggöra snabb numerisk kod, inklusive runtime-kompilering för specialiserade arbetslaster.
Inte varje språk behöver LLVM
Att välja LLVM är en avvägning, inte ett krav. Vissa språk prioriterar små binärer, extremt snabb kompilering eller strikt kontroll över hela verktygskedjan. Andra har redan etablerade kompilatorer (som GCC-baserade ekosystem) eller föredrar enklare backends.
LLVM är populärt eftersom det är ett starkt standardval—inte för att det är den enda giltiga vägen.
JIT och runtime-kompilering: snabba feedbackloopar
Återställ snabbt
Ångra en dålig ändring snabbt och fortsätt utan att tappa fart.
”Just-in-time” (JIT) kompilering är lättast att tänka på som kompilera medan du kör. Istället för att översätta all kod i förväg till en slutgiltig körbar fil väntar en JIT-motor tills en kodbit faktiskt behövs, och kompilerar sedan den delen i farten—ofta med verklig runtime-information (som exakta typer och datastorlekar) för att göra bättre val.
Varför JIT kan kännas så snabbt
Eftersom du inte behöver kompilera allt i förväg kan JIT-system leverera snabb återkoppling för interaktivt arbete. Du skriver eller genererar en bit kod, kör den omedelbart, och systemet kompilerar bara det som behövs just nu. Om samma kod körs upprepade gånger kan JIT:en cache:a det kompilerade resultatet eller kompilera ”heta” sektioner mer aggressivt.
Var runtime-kompilering hjälper i praktiken
JIT är bra när arbetslaster är dynamiska eller interaktiva:
- REPLs och notebooks: utvärdera snippet direkt medan du ändå får native-hastighet för tunga loopar.
- Plugins och extensioner: appar kan ladda användarkod vid körning och kompilera den för värd-CPU:n.
- Dynamiska arbetslaster: när indata varierar mycket kan runtime-profilering vägleda vilka vägar som förtjänar optimering.
- Vetenskaplig beräkning: genererade kernels (för en specifik matrisstorlek, modellform eller hårdvarufunktion) kan kompileras vid behov.
LLVMs roll (utan överdrift)
LLVM gör inte magiskt varje program snabbare, och det är inte en komplett JIT i sig. Vad det erbjuder är ett verktygslåda: en väldefinierad IR, ett stort set optimeringspass och kodgenerering för många CPU:er. Projekt kan bygga JIT-motorer ovanpå dessa byggstenar och välja rätt avvägning mellan uppstartstid, toppprestanda och komplexitet.
Prestanda, förutsägbarhet och verkliga avvägningar
LLVM-baserade verktygskedjor kan producera mycket snabb kod—men ”snabb” är inte en enhetlig, stabil egenskap. Det beror på exakt vilken kompilatorversion, mål-CPU, optimeringsinställningar och till och med vilka antaganden du ber kompilatorn göra om programmet.
Varför ”samma källkod, olika resultat” händer
Två kompilatorer kan läsa samma C/C++ (eller Rust, Swift osv.) och fortfarande generera märkbart olika maskinkod. En del är avsiktligt: varje kompilator har sina egna optimeringspass, heuristiker och standardinställningar. Även inom LLVM kan Clang 15 och Clang 18 fatta olika inliner-beslut, vektorisera olika loopar eller schemalägga instruktioner annorlunda.
Det kan också orsakas av undefined behavior och ospecificerat beteende i språket. Om ditt program av misstag förlitar sig på något standarden inte garanterar (som signed overflow i C), kan olika kompilatorer—eller olika flaggor—”optimera” på sätt som ändrar resultat.
Determinism, debug-builds och release-builds
Folk förväntar sig ofta determinism: samma inputs, samma outputs. I praktiken kommer du nära, men inte alltid få identiska binärer över miljöer. Byggvägar, tidsstämplar, länkordning, profile-guided-data och LTO-val kan alla påverka slutartefakten.
Den större, mer praktiska skillnaden är debug vs. release. Debug-bygg brukar stänga av många optimeringar för att bevara steg-för-steg-debuggning och läsbara stacktraces. Release-bygg aktiverar aggressiva transformationer som kan OMORDNA kod, inline:a funktioner och ta bort variabler—bra för prestanda, men ibland svårare att debugga.
Praktisk råd: mät, gissa inte
Behandla prestanda som ett mätproblem:
- Benchmarka på representativ hårdvara och med realistiska dataset.
- Värm upp caches och kör flera iterationer.
- Jämför builds med tydliga flaggor (t.ex. ändra
-O2vs-O3, slå på/av LTO, eller specificera mål med-march).
Små flaggändringar kan flytta prestandan åt båda håll. Det säkraste arbetsflödet är: välj en hypotes, mät den och håll benchmarks nära vad dina användare faktiskt kör.
Verktyg bortom kompilering: analys, debug och säkerhet
Bygg från en chatt
Förvandla en idé till en fungerande app med en enkel chatt — ingen verktygskedjeinstallation behövs.
LLVM beskrivs ofta som ett kompilatorverktyg, men många utvecklare känner dess påverkan genom verktyg som ligger runt kompilering: analysatorer, debuggers och säkerhetskontroller som kan slås på under byggen och tester.
Analys och instrumentering som ”tillägg”
Eftersom LLVM exponerar en väldefinierad IR och en pass-pipeline är det naturligt att bygga extra steg som inspekterar eller omskriver kod för syften som inte är ren hastighet. Ett pass kan till exempel lägga in räknare för profilering, markera misstänkta minnesoperationer eller samla täckningsdata.
Poängen är att dessa funktioner kan integreras utan att varje språkteam behöver uppfinna samma rörmokeri.
Sanitizers: fånga buggar nära källan
Clang och LLVM populariserade en familj runtime-"sanitizers" som instrumenterar program för att upptäcka vanliga buggklasser vid test—tänk utanför-gräns minnesåtkomst, use-after-free, datarace och mönster av undefined behavior. De är inte magiska skydd, och de saktar vanligtvis ner programmet, så de används främst i CI och innan release. Men när de triggar pekar de ofta på en exakt källplats och en begriplig förklaring, vilket är precis vad team behöver när de letar efter intermittenta krascher.
Bättre diagnostik = snabbare introduktion
Verktygskvalitet handlar också om kommunikation. Tydliga varningar, handlingsbara felmeddelanden och konsekvent debug-info minskar ”mysteriefaktorn” för nykomlingar. När verktygskedjan förklarar vad som hände och hur man fixar det spenderar utvecklare mindre tid på att memorera kompilatorquirks och mer tid på att lära sig kodbasen.
LLVM garanterar inte perfekt diagnostik eller säkerhet på egen hand, men det ger en gemensam grund som gör att dessa utvecklarnära verktyg blir praktiska att bygga, underhålla och dela över många projekt.
När man bör använda LLVM (och när inte)
LLVM är bäst att betrakta som en ”bygg-din-egen-kompilator-och-verktygslåda”. Denna flexibilitet är precis anledningen till att den driver så många moderna verktygskedjor—men det är också varför den inte passar alla projekt.
När LLVM är ett utmärkt val
LLVM glänser när du vill återanvända seriös kompilatoringenjörskonst utan att uppfinna den på nytt.
Om ni bygger ett nytt programspråk kan LLVM ge en beprövad optimeringspipeline, mogna kodgeneratorer för många CPU:er och en väg till bra debug-stöd.
Om ni levererar tvärplattformapplikationer minskar LLVMs backend-ekosystem arbetet för att stödja olika arkitekturer. Ni kan fokusera på språk- eller produktlogik istället för att skriva separata kodgeneratorer.
Om målet är utvecklarverktyg—linters, statisk analys, kodnavigering, refaktorering—är LLVM (och det bredare ekosystemet) en stark grund eftersom kompilatorn redan ”förstår” kodstruktur och typer.
När det kan vara överdrivet
LLVM kan vara tungt om ni arbetar med mycket små inbäddade system där byggstorlek, minne och kompileringstid är extremt begränsade.
Det kan också vara olämpligt för mycket specialiserade pipelines där ni inte vill ha generella optimeringar, eller där ert ”språk” är närmare en fast DSL med en rak direct-to-machine-mappning.
En enkel checklista
Ställ dessa tre frågor:
- Behöver vi rikta mot flera plattformar/CPU:er nu eller snart?
- Gynnar vi oss av befintliga optimeringar och debug-info snarare än att bygga egna?
- Vill vi ha en ekosystemväg (verktyg, integrationer, rekrytering) mer än en minimal specialbyggd kompilator?
Om svaret är ”ja” på de flesta är LLVM ofta ett praktiskt val. Om ni främst vill ha den minsta, enklaste kompilatorn för ett smalt problem kan en lättare väg vinna.
Ett praktiskt meddelande för produktteam: LLVMs fördelar utan att bli kompilatorexperter
De flesta team vill inte ”adoptera LLVM” som ett separat projekt. De vill resultat: tvärplattformbyggen, snabba binärer, bra diagnostik och pålitligt verktygsstöd.
Det är en av anledningarna till att plattformar som Koder.ai är intressanta i detta sammanhang. Om ert arbetsflöde i allt högre grad drivs av högre nivåns automation (planering, generera scaffolding, iterera i tät loop) drar ni ändå nytta av LLVM indirekt genom de underliggande verktygskedjorna—oavsett om ni bygger en React-webbapp, en Go-backend med PostgreSQL eller en Flutter-mobilklient. Koder.ai:s chattdrivna ”vibe-coding”-ansats fokuserar på att leverera produkt snabbare, medan modern kompilatorinfrastruktur (LLVM/Clang och vänner, där det är relevant) fortsätter att göra det otrivsamma arbetet med optimering, diagnostik och portabilitet i bakgrunden.