14 nov. 2025·8 min
Craig McLuckie och cloud-native: När plattformstänkande vinner
En praktisk genomgång av Craig McLuckies roll i cloud-native-adoptionen och hur plattformstänkande hjälpte containrar att bli tillförlitlig produktionsinfrastruktur.
Varför den här historien spelar roll för team som kör mjukvara
Team kämpar inte för att de inte kan starta en container. De kämpar för att de måste köra hundratals av dem säkert, uppdatera utan driftstopp, återhämta sig när något går sönder och ändå leverera funktioner enligt schema.
Craig McLuckies "cloud-native"-historia spelar roll eftersom det inte är en självgod hyllning med blanka demoexempel. Det är en redogörelse för hur containrar blev operabla i verkliga miljöer—där incidenter händer, efterlevnad krävs och företaget behöver förutsägbar leverans.
Cloud-native, enkelt uttryckt
"Cloud-native" är inte bara att "köra i molnet". Det är ett sätt att bygga och drifta mjukvara så att den kan distribueras ofta, skalas när efterfrågan ändras och repareras snabbt när delar fallerar.
I praktiken betyder det ofta:
- Applikationer paketerade och levererade konsekvent (ofta med containrar)
- System designade som mindre tjänster, inte ett enda jätteutsläpp
- Automation för distributioner, skalning och återställning
- Standardiserade sätt att observera, säkra och styra det som körs
Temat: plattformstänkande förvandlar verktyg till infrastruktur
Tidiga adoptioner av containrar såg ofta ut som en verktygslåda: team tog Docker, satte ihop skript och hoppades att drift skulle hålla jämna steg. Plattformstänkande vänder på det. Istället för att varje team uppfinner sin egen väg till produktion bygger ni delade "paved roads"—en plattform som gör det säkra, efterlevnadsanpassade och observerbara sättet också till det enkla sättet.
Den förändringen är bron från "vi kan köra containrar" till "vi kan driva en affär på dem".
Vem den här artikeln är för
Det här är för dem som ansvarar för resultat, inte bara arkitekturritningar:
- Tekniska chefer som balanserar snabbhet och tillförlitlighet
- Produktteam som vill iterera snabbare utan driftstopp
- Plattform-, DevOps- och SRE-personal som försöker minska repetitivt arbete och friktion
- Utvecklare som helst vill att distributioner ska vara tråkiga och repeterbara
Om ditt mål är pålitlig leverans i skala har den här historien praktiska lärdomar.
Vem är Craig McLuckie (och varför nämner folk honom)
Craig McLuckie är ett av de mest kända namnen kopplade till den tidiga cloud-native-rörelsen. Du ser honom ofta nämnd i samtal om Kubernetes, Cloud Native Computing Foundation (CNCF) och idén att infrastruktur bör behandlas som en produkt—inte en hög med tickets och tribal kunskap.
Inte "uppfinnaren", men en nyckelbyggare
Det är värt att vara precis. McLuckie uppfann inte cloud-native ensam, och Kubernetes var aldrig ett enmansprojekt. Kubernetes skapades av ett team på Google, och McLuckie var en del av den tidiga insatsen.
Vad folk ofta krediterar honom för är att hjälpa till att förvandla ett ingenjörskoncept till något som hela branschen faktiskt kunde anta: starkare community-byggande, tydligare paket och en push mot repeterbara driftpraxis.
Ett konsekvent tema: tillförlitlighet genom repeterbarhet
Genom Kubernetes- och CNCF-eran har McLuckies budskap handlat mindre om trendiga arkitekturer och mer om att göra produktion förutsägbar. Det innebär:
- Standardiserade sätt att distribuera och rulla tillbaka
- Konsekventa miljöer från laptop till produktion
- Operativa skyddsräcken som minskar överraskningar
Om du hört termer som "paved roads", "golden paths" eller "platform as a product" kretsar du runt samma idé: minska den kognitiva belastningen för team genom att göra rätt sak till den enkla saken.
Varför artikeln nämner honom
Det här inlägget är ingen biografi. McLuckie är en användbar referenspunkt eftersom hans arbete sitter i skärningspunkten av tre krafter som förändrade leverans av mjukvara: containrar, orkestrering och ekosystembyggande. Lärdomarna här handlar inte om personlighet—de handlar om varför plattformstänkande blev nyckeln till att köra containrar i verklig produktion.
Före cloud-native: containrar fanns, produktion var svårt
Containrar var en spännande idé långt innan "cloud-native" blev ett vanligt begrepp. I vardagliga termer är en container ett sätt att paketera en applikation tillsammans med filer och bibliotek den behöver så att den kan köras likadant på olika maskiner—som att skicka en produkt i en förseglad låda med alla delar inkluderade.
Varför tidig containeranvändning förblev experimentell
Tidigt använde många team containrar för sidoprojekt, demoexempel och utvecklarflöden. De var utmärkta för att testa nya tjänster snabbt, starta upp testmiljöer och undvika "det funkar på min laptop"-överraskningar vid överlämning.
Men att gå från ett fåtal containrar till ett produktionssystem som körs dygnet runt är en annan uppgift. Verktygen fanns, men den operativa historien var ofullständig.
Produktionshinder team stötte på
Vanliga problem dök snabbt upp:
- Uppgraderingar och rollback: Hur uppdaterar du dussintals (eller hundratals) körande containrar säkert, utan driftstopp? Och hur backar du när något går söder?
- Nätverk: Containrar måste hitta varandra pålitligt. Service discovery, trafikstyrning, load balancing och "vem får prata med vem" var inte standardiserat.
- Säkerhet: Bildproveniens, hantering av hemligheter, åtkomstkontroller och patchning av sårbarheter blev ett löpande arbete—inte en engångsinställning.
- Övervakning och felsökning: När en container startas om kan loggar försvinna. Metrics, tracing och alerting måste designas för en värld där processer är kortlivade.
Från "fungerar på min maskin" till "körs varje dag i skala"
Containrar gjorde mjukvara portabel, men portabilitet garanterade inte tillförlitlighet. Team behövde fortfarande konsekventa distributionsrutiner, tydligt ägarskap och operativa skyddsräcken—så att containeriserade appar inte bara kördes en gång, utan kördes förutsägbart varje dag.
Plattformstänkande: förvandla infrastruktur till en produkt
Plattformstänkande är ögonblicket när ett företag slutar se infrastruktur som ett engångsprojekt och börjar behandla det som en intern produkt. "Kunderna" är era utvecklare, datateam och alla som levererar mjukvara. Produktmålet är inte fler servrar eller mer YAML—det är en smidigare väg från idé till produktion.
En plattform är en produkt, inte en hög med verktyg
En riktig plattform har ett tydligt löfte: "Om du bygger och distribuerar med dessa vägar får du tillförlitlighet, säkerhet och förutsägbar leverans." Det löftet kräver produktvanor—dokumentation, support, versionering och feedbackloopar. Det kräver också en genomtänkt användarupplevelse: vettiga standardinställningar, paved roads och en nödlösning när team verkligen behöver den.
Varför standardisering snabbar upp leverans (och minskar risk)
Standardisering tar bort beslutströtthet och förhindrar oavsiktlig komplexitet. När team delar samma distributionsmönster, loggning och åtkomstkontroller blir problem repeterbara—och därmed lösbara. On-call-rotationer förbättras eftersom incidenter ser bekanta ut. Säkerhetsgranskningar går snabbare eftersom plattformen redan har inbyggda skyddsräcken i stället för att förlita sig på att varje team uppfinner dem.
Det handlar inte om att tvinga alla in i samma box. Det handlar om att enas om de 80% som borde vara tråkiga, så team kan lägga energi på de 20% som skiljer affären åt.
Från handbyggda servrar till repeterbara mönster
Innan plattformsmetoderna slog igenom berodde infrastrukturen ofta på speciell kunskap: några få visste vilka servrar som var patchade, vilka inställningar som var säkra och vilka skript som var "de bra". Plattformstänkande ersätter det med repeterbara mönster: mallar, automatiserad provisionering och konsekventa miljöer från dev till produktion.
Styrning utan byråkrati
Gjort rätt skapar plattformar bättre styrning med mindre pappersarbete. Policys blir automatiska kontroller, godkännanden blir revisionsbara flöden och efterlevnadsbevis genereras när team distribuerar—så organisationen får kontroll utan att bromsa alla.
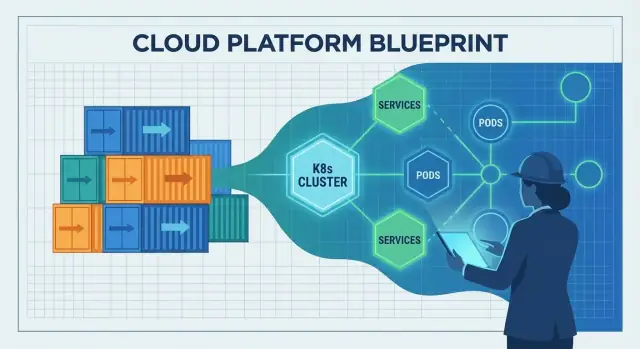
Kubernetes som bron från containrar till drift
Containrar gjorde det enkelt att paketera och leverera en app. Den svåra delen var vad som hände efter att du levererat den: välja var den ska köras, hålla den frisk och anpassa när trafik eller infrastruktur förändras.
Det är gapet Kubernetes fyllde. Det förvandlade "en hög av containrar" till något du kan drifta dag efter dag, även när servrar fallerar, releaser sker och efterfrågan ökar.
Vad orkestrering faktiskt löser
Kubernetes beskrivs ofta som "containerorkestrering", men de praktiska problemen är mer specifika:
- Schemaläggning: avgöra vilken maskin som ska köra varje container, baserat på tillgänglig CPU/minne och placeringsregler.
- Självläkning: starta om kraschar, schemalägga om om en nod dör och hålla önskat antal instanser igång.
- Skalning: öka eller minska repliker baserat på efterfrågan och rulla ut nya versioner utan att ta allt ner.
Utan en orkestrator slutar team med att skripta dessa beteenden och hantera undantag för hand—tills skripten inte längre speglar verkligheten.
Ett gemensamt control plane
Kubernetes populariserade idén om ett delat control plane: en plats där du deklarerar vad du vill ("kör 3 kopior av den här tjänsten") och plattformen kontinuerligt arbetar för att få den verkliga världen att matcha den avsikten.
Det är ett stort ansvarsskifte:
- Utvecklare distribuerar: bygger en image, applicerar en deployment, sätter resursförfrågningar och definierar health checks.
- Plattformen håller den igång: placerar arbetslaster, ersätter felande instanser, balanserar rollout och upprätthåller service discovery.
Byggt utifrån verkliga driftsmönster
Kubernetes dök inte upp för att containrar var trendiga. Det växte fram ur lärdomar från att drifta stora flotta: betrakta infrastruktur som ett system med återkopplingsslingor, inte som en uppsättning enstaka serveruppgifter. Denna operativa inställning är varför det blev bron från "vi kan köra containrar" till "vi kan köra dem pålitligt i produktion".
Vad cloud-native förändrade i vardaglig leverans
Tjäna krediter medan du lär
Tjäna krediter för innehåll eller rekommendationer medan du utforskar Koder.ai.
Cloud-native introducerade inte bara nya verktyg—det förändrade rytmen i att skicka mjukvara. Team gick från "handbyggda servrar och manuella runbooks" till system designade för att drivas via API:er, automation och deklarativ konfiguration.
Från tickets och SSH till API:er och automation
En cloud-native-setup förutsätter att infrastruktur är programmerbar. Behöver du en databas, en load balancer eller en ny miljö? I stället för att vänta på manuell setup beskriver team vad de vill ha och låter automation skapa det.
Den avgörande förändringen är deklarativ konfiguration: du definierar önskat tillstånd ("kör 3 kopior av denna tjänst, exponera den på denna port, begränsa minne till X") och plattformen arbetar kontinuerligt för att matcha det tillståndet. Det gör ändringar granskbara, repeterbara och enklare att rulla tillbaka.
Immutabla distributioner minskar driftavvikelse
Traditionell leverans involverade ofta patchning av live-servrar. Med tiden blev varje maskin lite annorlunda—konfigurationsdrift som bara visar sig under en incident.
Cloud-native-leverans pressade team mot immutabla distributioner: bygg en artefakt en gång (ofta en containerimage), distribuera den, och om du behöver en ändring deployar du en ny version i stället för att modifiera det som redan körs. Kombinerat med automatiserade rollouter och health checks tenderar detta att minska "mystiska driftstopp" orsakade av ad-hoc-ändringar.
Mikrotjänster och containrar: en förstärkande loop (med kompromisser)
Containrar gjorde det enklare att paketera och köra många små tjänster konsekvent, vilket uppmuntrade mikrotjänstarkitekturer. Mikrotjänster ökade i sin tur behovet av konsekvent distribution, skalning och service discovery—områden där containerorkestrering utmärker sig.
Kompromissen: fler tjänster betyder mer driftarbete (övervakning, nätverk, versionering, incidenthantering). Cloud-native hjälper till att hantera den komplexiteten, men tar inte bort den.
Portabilitet: verklig, men inte magisk
Portabiliteten förbättrades eftersom team standardiserade på gemensamma distributionsprimitiver och API:er. Fortfarande kräver "kör varsomhelst" oftast arbete—skillnader i säkerhet, lagring, nätverk och managed services spelar roll. Cloud-native är bäst förstått som att minska låsning och friktion, inte att eliminera dem.
CNCF och ekosystemeffekten: varför det accelererade adoption
Kubernetes spreds inte bara för att det var kraftfullt. Det spreds därför att det fick ett neutralt hem, tydlig styrning och en plats där konkurrerande företag kunde samarbeta utan att en leverantör "ägde" reglerna.
En neutral fond gör samarbete säkrare
Cloud Native Computing Foundation (CNCF) skapade delad styrning: öppet beslutsfattande, förutsägbara projektprocesser och offentliga roadmappar. Det spelar roll för team som satsar på kärninfrastruktur. När reglerna är transparenta och inte knutna till en enskild företags affärsmodell känns adoption mindre riskfylld—och bidrag blir mer attraktiva.
CNCF:s roll: mer än en logga
Genom att hosta Kubernetes och relaterade projekt hjälpte CNCF att förvandla "ett populärt open source-verktyg" till en långsiktig plattform med institutionellt stöd. Den gav:
- Ett konsekvent sätt att hantera maintainers, releaser och säkerhetspraxis
- En arena för koordinering över företag
- En signal till marknaden: det här projektet är tänkt att överleva vilken leverantör som helst
Öppna standarder och breda bidragsgivare
Med många bidragsgivare (molnleverantörer, startups, företag och oberoende ingenjörer) utvecklades Kubernetes snabbare och i mer verkliga riktningar: nätverk, lagring, säkerhet och day-2-operationer. Öppna API:er och standarder gjorde det enklare för verktyg att integrera, vilket minskade låsning och ökade förtroendet för produktionsanvändning.
Ekosystemeffekten (och kompromissen)
CNCF accelererade också en explosion av ekosystemet: service meshes, ingress-kontrollers, CI/CD-verktyg, policymotorer, observability-stacks med mera. Denna överflöd är en styrka—men skapar också överlapp.
För de flesta team kommer framgång från att välja en liten uppsättning välunderstödda komponenter, favorisera interoperabilitet och vara tydlig med ägarskap. Ett "bäst av allt"-angreppssätt leder ofta till underhållsbyrda snarare än bättre leverans.
Från verktyg till tillförlitlighet: det saknade operativa lagret
Distribuera ett snabbt miljö
Hosta och distribuera din app från Koder.ai när du behöver ett snabbt miljö.
Containrar och Kubernetes löste en stor del av frågan "hur ska vi köra mjukvara?". De löste inte automatiskt den svårare frågan: "hur håller vi den igång när riktiga användare dyker upp?" Det saknade lagret är operativ tillförlitlighet—tydliga förväntningar, delade praxis och ett system som gör rätt beteenden till standard.
Definiera produktionsbaslinjen
Ett team kan leverera snabbt och ändå vara ett dåligt deploy från kaos om produktionsbaslinjen är odefinierad. Minst behöver du:
- Observabilitet: förmågan att se vad som händer och varför (inte bara om det är "uppe").
- Incidenthantering: roller, on-call-rotation, eskalationsvägar och efterhandsgranskningar.
- Kapacitetsplanering: förstå last, gränser och hur systemet beter sig under stress.
Utan denna baslinje hittar varje tjänst på sina egna regler och tillförlitlighet blir en fråga om tur.
Praxis ersätter inte plattformar—de kompletterar dem
DevOps och SRE introducerade viktiga vanor: ägarskap, automation, mätbar tillförlitlighet och lärande från incidenter. Men vanor skalas inte över dussintals team och hundratals tjänster.
Plattformar gör dessa praxis repeterbara. SRE sätter mål (som SLOs) och feedbackloopar; plattformen erbjuder paved roads för att nå dem.
"Bordsspel"-komponenterna för tillförlitlighet
Pålitlig leverans kräver oftast en konsekvent uppsättning kapabiliteter:
- Loggning, metrics, tracing (så du kan felsöka och förbättra)
- Alerting kopplat till användarpåverkan (så on-call inte är brus)
- Säkra rollbacks och progressiva distributionsmönster (så fel inte blir katastrofala)
Hur plattformar kodar in förväntningar
En bra plattform bakar in dessa standarder i mallar, pipelines och runtime-policys: standard dashboards, gemensamma larmregler, distributionsskydd och rollback-mekanismer. Så börjar tillförlitlighet vara ett förutsägbart utfall av att skicka mjukvara.
Plattformengineering: göra cloud-native användbart för de flesta team
Cloud-native-verktyg kan vara kraftfulla och ändå kännas som "för mycket" för de flesta produktteam. Plattformengineering finns för att stänga det gapet. Uppdraget är enkelt: minska kognitiv belastning för applikationsteam så att de kan leverera funktioner utan att bli deltidsinfrastrukturexperter.
Plattformteamets uppdrag: gör rätt väg till den enkla vägen
Ett bra plattformsteam behandlar intern infrastruktur som en produkt. Det betyder tydliga användare (utvecklare), tydliga resultat (säker, repeterbar leverans) och en feedbackloop. I stället för att lämna över en hög Kubernetes-primitiver erbjuder plattformen åsiktsstyrda sätt att bygga, distribuera och drifta tjänster.
En praktisk fråga att ställa är: "Kan en utvecklare gå från idé till en körande tjänst utan att öppna ett dussin tickets?" Verktyg som komprimerar det arbetsflödet—samtidigt som de bevarar skyddsräcken—är i linje med cloud-native plattformsmålet.
Byggstenar som gör cloud-native praktiskt
De flesta plattformar är en uppsättning återanvändbara "paved roads" som team kan välja som standard:
- Mallverktyg och scaffold för nya tjänster (repo-struktur, CI, grundläggande observabilitet)
- Självbetjäningsflöden (skapa en miljö, begär en databas, rotera hemligheter)
- Standarddistributionsmönster (ingress, autoscaling, health checks, canary-releaser)
Målet är inte att dölja Kubernetes—utan att paketera det i rimliga standarder som förhindrar oavsiktlig komplexitet.
I den anda kan Koder.ai användas som ett "DX-accelerator"-lager för team som vill spawna interna verktyg eller produktfunktioner snabbt via chat, och sedan exportera källkod när det är dags att integrera med en mer formell plattform. För plattformsteam kan dess planning mode och inbyggda snapshots/rollback också spegla samma tillförlitlighetsprioriterade hållning du vill ha i produktionsarbetsflöden.
Kompromisser: flexibilitet vs. konsekvens
Varje paved road är en avvägning: mer konsekvens och säkrare drift, men färre enstaka alternativ. Plattformsteam gör bäst när de erbjuder:
- en golden path för 80% av tjänsterna
- en nödlucka för legitima edgefall (med uttryckligt ägarskap)
Tecken på att det fungerar
Du ser plattformsframgång i mätbara termer: snabbare onboardning för nya ingenjörer, färre specialskripta distributionsskript, färre "snowflake"-kluster och tydligare ägarskap vid incidenter. Om team kan svara på "vem äger den här tjänsten och hur deployar vi?" utan ett möte, gör plattformen sitt jobb.
Vad som går fel: fallgropar som bromsar cloud-native-framsteg
Cloud-native kan göra leverans snabbare och drift lugnare—men bara när team är tydliga med vad de försöker förbättra. Många fördröjningar sker när Kubernetes och dess ekosystem behandlas som målet, inte medlet.
1) Kubernetes-first, resultat-senare
Ett vanligt misstag är att adoptera Kubernetes eftersom det är "vad moderna team gör", utan ett konkret mål som kortare lead time, färre incidenter eller bättre miljökonsistens. Resultatet blir mycket migrationsarbete utan synlig nytta.
Om framgångskriterier inte definieras i förväg blir varje beslut subjektivt: vilket verktyg att välja, hur mycket att standardisera och när plattformen är "klar".
2) Komplexitetskryp från ekosystemet
Kubernetes är en grund, inte en full plattform. Team lägger ofta snabbt till tillägg—service mesh, flera ingress-kontrollers, custom operators, policymotorer—utan tydliga gränser eller ägarskap.
Överanpassning är en annan fälla: skräddarsydda YAML-mönster, hemmagjorda mallar och engångsundantag som bara ursprungsförfattarna förstår. Komplexiteten stiger, onboardingen saktar och uppgraderingar blir riskfyllda.
3) Kostnad, spridning och säkerhetsblinda fläckar
Cloud-native gör det lätt att skapa resurser—och lätt att glömma dem. Kluster-spridning, oanvända namespaces och överallokerade arbetslaster driver tyst upp kostnader.
Säkerhetsfällor är lika vanliga:
- Behörigheter som växer över tid (bred RBAC, delade servicekonton)
- Supply chain-risk (ovaliderade images, för många tredjepartscharts)
- Inkonsekventa policys över kluster och miljöer
4) Hur man mildrar (utan att stoppa framsteg)
Starta litet med en eller två väldefinierade tjänster. Definiera standarder tidigt (golden paths, godkända basimages, uppgraderingsregler) och håll plattformens yta medvetet begränsad.
Mät utfall som distributionsfrekvens, MTTR och utvecklarnas tid till första deploy—och betrakta allt som inte flyttar dessa siffror som valfritt.
En praktisk playbook för att tillämpa dessa lärdomar
Kickstarta en platform-MVP
Starta en fungerande webapp, backend och PostgreSQL-bas i en session.
Du "adopterar inte cloud-native" i ett enda steg. De team som lyckas följer samma centrala idé som associeras med McLuckies era: bygg en plattform som gör rätt väg till den enkla vägen.
En enkel adoptionsväg
Börja litet, kodifiera det som fungerar.
- Pilot: Välj en tjänst som är tillräckligt smärtsam för att motivera förändring, men inte affärskritisk. Containerisera den, automatisera builds och distribuera upprepade gånger tills det känns rutin.
- Plattform-MVP: Förvandla pilotens lärdomar till en tunn intern plattform: standardmallar, en paved deployment-väg, grundläggande observabilitet och ett tydligt ägarskapsmodell.
- Expandera: Onboarda fler team och tjänster med samma standarder. Prioritera konsekvens framför anpassning.
- Optimera: Lägg till policy, kostnadskontroller, incidentflöden och självservicefunktioner när grunderna är stabila.
Om ni experimenterar med nya arbetsflöden är ett användbart mönster att prototypa hela "golden path"-upplevelsen innan ni standardiserar den. Till exempel kan team använda Koder.ai för att snabbt generera en fungerande webapp (React), backend (Go) och databas (PostgreSQL) via chat, och sedan använda den resulterande kodbasen som utgångspunkt för plattformens mallar och CI/CD-konventioner.
Beslutsfrågor för att vara ärlig mot er själva
Innan ni lägger till verktyg, fråga:
- Varför containrar? Vilken friktion tar ni bort (miljödrift, paketering, portabilitet) och vilket nytt arbete accepterar ni?
- Varför orkestrering? Behöver ni verkligen automatisk skalning, rollouter och tjänsteresiliens—eller räcker enklare automation?
- Varför nu? Drivs detta av leveranssmärta, tillförlitlighetsrisk eller ett tydligt produktmål (inte bara trender)?
Metriker som visar verklig framgång
Mät utfall, inte verktygsanvändning:
- Distribueringsfrekvens och lead time (leveranshastighet)
- Tillförlitlighet (SLO-uppfyllnad, incidentfrekvens, MTTR)
- Utvecklarnöjdhet (korta enkäter, onboardingtid, "tid till första deploy")
Om du vill ha exempel på vad bra "plattform-MVP"-paket kan se ut, se /blog. För budgetering och utrullningsplanering kan du också referera till /pricing.
Nästa kapitel för cloud-native (och hur du förbereder dig)
Den stora lärdomen från det senaste decenniet är enkel: containrar "vann" inte för att de var smart paketering. De vann för att plattformstänkande gjorde dem pålitliga—repeterbara distributioner, säkra rollouter, konsekventa säkerhetskontroller och förutsägbara driftmönster.
Nästa kapitel handlar inte om ett enda genombrottsverktyg. Det handlar om att göra cloud-native tråkigt på bästa sätt: färre överraskningar, färre ad-hoc-fixar och en smidigare väg från kod till produktion.
Vad du bör hålla koll på
Policy-as-code blir standard. I stället för att granska varje distribution manuellt kodifierar team regler för säkerhet, nätverk och efterlevnad så att skyddsräcken blir automatiska och revisionsbara.
Utvecklarupplevelse (DX) behandlas som en produkt. Räkna med mer fokus på paved roads: mallar, självservice-miljöer och tydliga golden paths som minskar kognitiv belastning utan att begränsa autonomi.
Enklare drift, inte fler dashboards. De bästa plattformarna gömmer komplexitet: åsiktsstyrda standarder, färre rörliga delar och inbyggda tillförlitlighetsmönster i stället för eftermonterade lösningar.
Undvik "verktygssamlaren"-fällan
Cloud-native-framsteg bromsas när team jagar funktioner i stället för resultat. Om du inte kan förklara hur ett nytt verktyg minskar lead time, sänker incidentfrekvensen eller förbättrar säkerhet, är det troligen inte prioritet.
Ett tydligt nästa steg
Utvärdera era nuvarande leveranssmärtpunkter och mappa dem till plattformsbehov:
- Var misslyckas eller bromsas distributioner oftast?
- Vilka godkännanden och kontroller bör bli automatiserade skyddsräcken?
- Vad bygger utvecklare upp om och om igen (som kan standardiseras)?
Behandla svaren som er plattformsbacklogg—och mät framgång på de förbättringar era team känner varje vecka.
Vanliga frågor
Vad betyder “cloud-native” (förutom “körs i molnet”)?
Cloud-native är ett sätt att bygga och drifta mjukvara så att du kan distribuera ofta, skala när efterfrågan förändras och återhämta dig snabbt från fel.
I praktiken inkluderar det ofta containrar, automation, mindre tjänster och standardiserade sätt att observera, säkra och styra det som körs.
Varför räckte inte containrarna ensamma för produktion i skala?
En container hjälper dig att skicka mjukvara konsekvent, men löser inte alla svåra produktionsproblem av sig själv—som säkra uppgraderingar, service discovery, säkerhetskontroller och beständig observabilitet.
Klyftan syns när du går från ett fåtal containrar till hundratals som körs dygnet runt.
Vad är “plattformstänkande”, och hur skiljer det sig från en verktygslåda med DevOps-skript?
“Plattformstänkande” innebär att behandla intern infrastruktur som en intern produkt med tydliga användare (utvecklare) och ett tydligt löfte (säker, repeterbar leverans).
Istället för att varje team sätter ihop sin egen väg till produktion bygger organisationen delade paved roads (golden paths) med rimliga standardval och support.
Vad löser Kubernetes egentligen för team som kör containrar?
Kubernetes tillhandahåller det operativa lagret som gör att “en hög av containrar” blir ett system du kan driva dag efter dag:
- Schemaläggning: placera arbetslaster på maskiner med rätt resurser
- Självläkning: starta om och schemalägga om när något fallerar
- Scaling och rollouter: ändra repliker och införa nya versioner på ett säkert sätt
Det introducerar också ett delat där du deklarerar önskat tillstånd och systemet arbetar för att uppfylla det.
Vad är “deklarativ konfiguration” och varför spelar det roll i leverans?
Deklarativ konfiguration betyder att du beskriver vad du vill ha (önskat tillstånd) i stället för att skriva steg-för-steg-instruktioner.
Praktiska fördelar:
- Ändringar blir granskningsbara (Git-flöden)
- Distributioner blir repeterbara över miljöer
- Rollbacks blir oftast eftersom du kan återställa konfiguration eller rulla ut en tidigare artefakt
Vad är immutabla distributioner, och hur minskar de “mystiska driftstopp”?
Immutabla distributioner innebär att du inte patchar live-servrar på plats. Du bygger en artefakt en gång (ofta en containerimage) och distribuerar just den artefakten.
För att ändra något skickar du en ny version i stället för att modifiera det som redan körs. Det minskar konfigurationsdrift och gör incidenter lättare att reproducera och återställa.
Varför spelade CNCF roll för Kubernetes-adoptionen?
CNCF gav Kubernetes och närliggande projekt ett neutralt styrt hem, vilket minskade risken att satsa på kärninfrastruktur.
Det hjälpte med:
- Förutsägbara processer för releaser och säkerhet
- Samarbete över företag
- Ett starkare ekosystem av interopererande verktyg byggda på öppna API:er
Vad är en “produktionsbaslinje”, och vad bör den innehålla?
En produktionsbaslinje är minimisatsen av kapabiliteter och rutiner som gör tillförlitlighet förutsägbar, till exempel:
- Observabilitet (loggar, metrics, tracing som förklarar varför)
- Incidenthantering (roller, on-call, eskalering, efterhandsgranskningar)
- Kapacitetsplanering (gränser, lastförväntningar, beteende under belastning)
Utan detta hittar varje tjänst på sina egna regler och tillförlitlighet blir en fråga om tur.
Vad bygger ett plattformsteam typiskt för att göra cloud-native användbart?
Plattformengineering syftar till att minska utvecklarnas kognitiva belastning genom att paketera cloud-native-primitiver till opinionsstyrda standarder:
- Mallar och scaffold för tjänster (repo, CI, grundläggande observabilitet)
- Självbetjäningsflöden (miljöer, rotation av hemligheter)
- Standarddistributionmönster (health checks, autoscaling, canaries)
Målet är inte att gömma Kubernetes—utan att göra den säkra vägen till den enklaste vägen.
Vilka är de vanligaste fallgroparna vid cloud-native-adoption, och hur kan team undvika dem?
Vanliga fallgropar är:
- Kubernetes-first, resultat-senare: adoptera verktyg utan mål
- Ekosystem-spridning: för många tillägg utan tydligt ägarskap
- Säkerhets- och kostnadsdrift: bred RBAC, ovärderade images, glömda resurser
Hur man undviker dem: