03 okt. 2025·7 min
Data utanför vs inuti – Pat Hellands lärdomar för appar
Lär dig Pat Hellands idé om "data utanför vs inuti" för att sätta tydliga gränser, designa idempotenta anrop och återställa tillstånd när nätverk fallerar.
Lär dig Pat Hellands idé om "data utanför vs inuti" för att sätta tydliga gränser, designa idempotenta anrop och återställa tillstånd när nätverk fallerar.
När du bygger en app är det lätt att föreställa sig att förfrågningar kommer in prydligt, en i taget, i rätt ordning. Riktiga nätverk beter sig inte så. En användare trycker “Betala” två gånger för att skärmen frös. En mobilanslutning bryts precis efter ett knapptryck. En webhook kommer sent, eller kommer två gånger. Ibland kommer den aldrig alls.
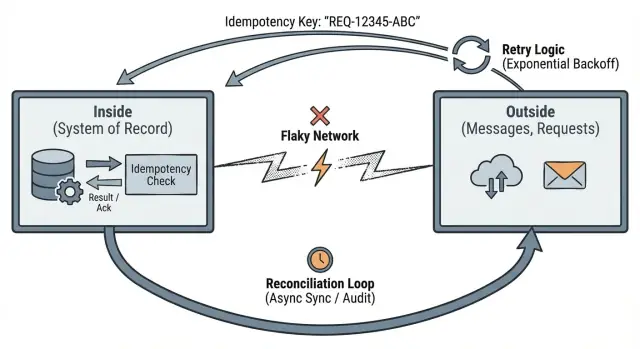
Pat Hellands idé om data utanför vs inuti är ett tydligt sätt att tänka kring det kaoset.
”Utsidan” är allt ditt system inte kontrollerar. Det är där du pratar med andra människor och system, och där leverans är osäker: HTTP‑förfrågningar från webbläsare och mobila appar, meddelanden från köer, tredjeparts‑webhooks (betalningar, e‑post, frakt) och omförsök som triggas av klienter, proxys eller bakgrundsjobb.
På utsidan, anta att meddelanden kan försenas, dupliceras eller komma i fel ordning. Även om något är “vanligtvis pålitligt”, designa för den dag det inte är det.
”Insidan” är vad ditt system kan göra pålitligt. Det är det durabla tillstånd du lagrar, de regler du upprätthåller och de fakta du kan bevisa senare:
Insidan är där du skyddar invariabler. Om du lovar “en betalning per order” måste löftet upprätthållas inuti, eftersom utsidan inte kan litas på.
Mindset‑skiftet är enkelt: anta inte perfekt leverans eller perfekt timing. Behandla varje interaktion från utsidan som ett opålitligt förslag som kan upprepas, och låt insidan reagera säkert.
Detta spelar roll även för små team och enkla appar. Första gången ett nätverksfel skapar en dubbelavgift eller en fast order blir det inte längre teori — det blir en återbetalning, ett supportärende och förlorat förtroende.
Ett konkret exempel: en användare trycker “Lägg order”, appen skickar en förfrågan och anslutningen bryts. Användaren försöker igen. Om din insida inte kan känna igen “detta är samma försök” kan du skapa två ordrar, reservera lager två gånger eller skicka två bekräftelser.
Hellands poäng är rak: utsidan är osäker, men insidan av ditt system måste förbli konsekvent. Nätverk tappar paket, telefoner tappar signal, klockor glider isär och användare trycker på uppdatera. Din app kan inte styra något av det. Vad den kan styra är vad den accepterar som “sant” när data passerar en tydlig gräns.
Föreställ dig någon som beställer kaffe på telefonen medan de går genom en byggnad med dåligt Wi‑Fi. De trycker “Betala”. Spinnaren snurrar. Nätverket bryts. De trycker igen.
Kanske nådde första förfrågan din server, men svaret kom aldrig tillbaka. Eller så nådde ingen av förfrågningarna fram. Ur användarens perspektiv ser båda möjligheterna likadana ut.
Det är tid och osäkerhet: du vet inte vad som hände än, och du kan få veta senare. Ditt system måste bete sig förnuftigt medan det väntar.
När du accepterar att utsidan är opålitlig blir några “konstiga” beteenden normala:
Utsidesdata är ett påstående, inte en bekräftad sanning. “Jag betalade” är bara ett uttalande skickat över en opålitlig kanal. Det blir en sanning först när du registrerar det inuti ditt system på ett hållbart och konsekvent sätt.
Detta leder till tre praktiska vanor: definiera tydliga gränser, gör omförsök säkra med idempotens, och planera för avstämning när verkligheten inte stämmer.
Idén “utanför vs inuti” börjar med en praktisk fråga: var börjar och slutar ditt systems sanning?
Inuti gränsen kan du ge starka garantier eftersom du kontrollerar data och regler. Utanför gränsen gör du bästa‑försök och antar att meddelanden kan tappas, dupliceras, försenas eller komma i fel ordning.
I riktiga appar dyker den gränsen ofta upp vid platser som:
När du drar den linjen, bestäm vilka invariabler som är icke‑förhandlingsbara inuti. Exempel:
Gränsen behöver också ett klart språk för “var vi är”. Många fel bor i glappet mellan “vi hörde dig” och “vi blev klara”. Ett hjälpsamt mönster är att separera tre betydelser:
När team hoppar över detta får de buggar som bara dyker upp under belastning eller delvisa driftstopp. Ett system använder “betald” för att mena pengar inkasserade; ett annat använder det för ett påbörjat betalningsförsök. Den mismatchen skapar dubbletter, fastnade ordrar och supportärenden ingen kan reproducera.
Idempotens betyder: om samma förfrågan skickas två gånger behandlar systemet den som en och returnerar samma utfall.
Omförsök är normalt. Timeouter händer. Klienter upprepar sig. Om utsidan kan upprepa måste din insida omvandla det till stabila tillståndsändringar.
Ett enkelt exempel: en mobilapp skickar “betala 20 kr” och anslutningen bryts. Appen gör omförsök. Utan idempotens kan kunden debiteras två gånger. Med idempotens returnerar den andra förfrågan samma resultat som den första.
De flesta team använder ett av dessa mönster (ibland en blandning):
Idempotency-Key: ...). Servern sparar nyckeln och slutsvaret.När en dubblett kommer är bästa beteendet oftast inte “409 conflict” eller ett generiskt fel. Det är att returnera samma resultat som du gav första gången, inklusive samma resurs‑ID och status. Det gör omförsök säkra för klienter och bakgrundsjobb.
Idempotensposten måste ligga innanför din boundary i uthållig lagring, inte i minnet. Om din API startar om och glömmer försvinner garantin.
Behåll poster tillräckligt länge för realistiska omförsök och fördröjda leveranser. Tiden beror på affärsrisk: minuter till timmar för lågrisk‑creates, dagar för betalningar/e‑post/frakt där dubbletter är kostsamma, och längre om partners kan göra omförsök under lång tid.
Distribuerade transaktioner låter lugnande: en stor commit över tjänster, köer och databaser. I praktiken är de ofta otillgängliga, långsamma eller för sköra att förlita sig på. När ett nätverkshopp är involverat kan du inte anta att allt committas tillsammans.
En vanlig fälla är att bygga ett arbetsflöde som bara fungerar om varje steg lyckas nu: spara order, ta betalt, reservera lager, skicka bekräftelse. Om steg 3 får timeout, misslyckades det eller lyckades det? Om du retryar, debiterar du dubbelt eller reserverar du två gånger?
Två praktiska angreppssätt undviker detta:
Välj en stil per workflow och håll fast vid den. Att blanda “ibland använder vi outbox” med “ibland antar vi synkront lyckat” skapar kantfall som är svåra att testa.
En enkel regel hjälper: om du inte kan atomiskt committa över gränser, designa för omförsök, dubbletter och fördröjningar.
Avstämning är att medge en grundläggande sanning: när din app pratar med andra system över nätet kommer ni ibland att vara oense om vad som hände. Förfrågningar går timeout, callbacks kommer sent och människor gör omförsök. Avstämning är hur du upptäcker mismatcher och åtgärdar dem över tid.
Behandla externa system som oberoende sanningskällor. Din app håller sin egen interna post, men behöver ett sätt att jämföra den posten med vad partners, leverantörer och användare faktiskt gjorde.
De flesta team använder en ganska tråkig uppsättning verktyg (tråkigt är bra): en worker som gör om försök för väntande åtgärder och kollar extern status, en schemalagd sökning efter inkonsekvenser, och en liten administrativ reparationsåtgärd för support att retrya, avboka eller markera som granskad.
Avstämning fungerar bara om du vet vad du ska jämföra: intern ledger vs leverantörs‑ledger (betalningar), orderstatus vs fraktstatus (fulfillment), prenumerationsstatus vs faktureringsstatus.
Gör tillstånd reparerbara. Istället för att hoppa direkt från “skapat” till “komplett”, använd hållningssteg som pending, on hold eller needs review. Det gör det säkert att säga “vi är inte säkra än” och ger avstämningen en tydlig plats att landa.
Spara ett litet revisionsspår för viktiga ändringar:
Exempel: om din app begär en fraktetikett och nätverket brister kan du få “ingen etikett” internt medan fraktbolaget faktiskt skapade en. En recon‑worker kan söka på korrelations‑ID, upptäcka att etiketten finns och flytta ordern framåt (eller markera för granskning om detaljerna inte stämmer).
När du antar att nätverket kommer att misslyckas ändras målet. Du försöker inte få varje steg att lyckas i ett försök. Du försöker göra varje steg säkert att upprepa och lätt att reparera.
Skriv en en‑meningars gränsbeskrivning. Var tydlig med vad ditt system äger (sanningskällan), vad det speglar och vad det bara begär från andra.
Lista felmoderna innan happy path. Minst: timeouter (du vet inte om det fungerade), dubbletter, partiell framgång (ett steg hände, nästa inte) och händelser i fel ordning.
Välj en idempotensstrategi för varje input. För synkrona API:er är det ofta en idempotency‑nyckel plus ett sparat resultat. För meddelanden/event är det vanligtvis ett unikt meddelande‑ID och en “har jag bearbetat detta?”‑post.
Persist intent, sedan agera. Spara först något varaktigt som PaymentAttempt: pending eller ShipmentRequest: queued, gör sedan det externa anropet och spela därefter in utfall. Returnera ett stabilt referens‑ID så att omförsök pekar på samma intent istället för att skapa en ny.
Bygg avstämning och en reparationsväg, och gör dem synliga. Avstämning kan vara ett jobb som skannar “pending too long”‑poster och kontrollerar extern status igen. Reparationsvägen kan vara en säker admin‑åtgärd som “retry”, “cancel” eller “mark resolved” med en revisionsanteckning. Lägg till grundläggande observerbarhet: korrelations‑ID, tydliga statusfält och några räknare (pending, retries, failures).
Exempel: om checkout får timeout precis efter att du kallade en betalningsleverantör, gissa inte. Spara försöket, returnera attempt‑ID, och låt användaren försöka igen med samma idempotency‑nyckel. Senare kan avstämning bekräfta om leverantören debiterade eller inte och uppdatera försöket utan att dubbeldebiteras.
En kund trycker “Lägg order”. Din tjänst skickar en betalningsförfrågan till en leverantör, men nätverket är ostadigt. Leverantören har sin egen sanning, och din databas har sin. De kommer att glida isär om du inte designar för det.
Ur ditt perspektiv är utsidan en ström av meddelanden som kan vara sena, upprepade eller saknas:
Ingen av dessa steg garanterar “exactly once”. De garanterar bara “maybe”.
Inom din gräns, spara hållbara fakta och det minsta som behövs för att koppla externa händelser till de fakta.
När kunden först lägger ordern, skapa en order‑post i ett tydligt tillstånd som pending_payment. Skapa också en payment_attempt‑post med en unik leverantörsreferens plus en idempotency_key kopplad till kundens handling.
Om klienten får timeout och försöker igen bör din API inte skapa en andra order. Den ska slå upp idempotency_key och returnera samma order_id och nuvarande status. Det enda valet förhindrar dubbletter när nätverk fallerar.
Nu kommer webhooken två gånger. Den första callbacken uppdaterar payment_attempt till authorized och flyttar ordern till paid. Den andra callbacken når samma handler, men du upptäcker att du redan behandlat den leverantörshändelsen (genom att spara leverantörens event‑ID eller genom att kontrollera nuvarande status) och gör ingenting. Du kan fortfarande svara 200 OK, eftersom resultatet redan är sant.
Slutligen hanterar avstämning de röriga fallen. Om ordern fortfarande är pending_payment efter en fördröjning, frågar ett bakgrundsjobb leverantören med den sparade referensen. Om leverantören säger “authorized” men du missade webhooken uppdaterar du dina poster. Om leverantören säger “failed” men du markerade den som betald flaggar du den för granskning eller triggar en kompensation som en återbetalning.
De flesta dubblettposter och “stuck” workflows kommer från att blanda ihop vad som hände utanför ditt system (en förfrågan anlände, ett meddelande togs emot) med vad du säkert committade inuti ditt system.
Ett klassiskt fel: en klient skickar “lägg order”, din server börjar arbeta, nätverket bryts och klienten gör om. Om du behandlar varje omförsök som helt ny sanning får du dubbla avgifter, dubblettorder eller flera e‑post.
Vanliga orsaker är:
Ett problem gör allt värre: inget revisionsspår. Om du skriver över fält och bara behåller senaste tillstånd förlorar du bevis för att kunna avstämma senare.
En bra sanity‑check är: “Om jag kör denna handler två gånger, får jag samma resultat?” Om svaret är nej, är dubbletter inte ett sällsynt kantfall. De är garanterade.
Om du minns en sak: din app måste förbli korrekt även när meddelanden kommer sent, kommer två gånger eller aldrig kommer alls.
Använd den här checklistan för att hitta svaga punkter innan de blir dubblettposter, saknade uppdateringar eller fastnade workflows:
Om du inte snabbt kan svara på ett av dessa är det användbart — det betyder oftast att en gräns är suddig eller att en tillståndsövergång saknas.
Praktiska nästa steg:
Skissa gränser och tillstånd först. Definiera ett litet set tillstånd per workflow (t.ex.: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Lägg till idempotens där det betyder mest. Börja med högst risk‑skrivningar: skapa order, ta betalt, utfärda återbetalning. Spara idempotensnycklar i PostgreSQL med en unik constraint så dubbletter avvisas säkert.
Behandla avstämning som en normal funktion. Schemalägg ett jobb som söker efter “pending too long”‑poster, kontrollerar externa system igen och reparerar lokalt tillstånd.
Iterera säkert. Justera övergångar och retry‑regler, och testa genom att medvetet skicka om samma förfrågan och bearbeta samma event igen.
Om du bygger snabbt på en chattdriven plattform som Koder.ai (koder.ai), är det fortfarande värt att baka in dessa regler tidigt: snabbheten kommer från automation, men tillförlitligheten kommer från tydliga gränser, idempotenta handlers och avstämning.
“Utsidan” är allt du inte kontrollerar: webbläsare, mobila nätverk, köer, tredjeparts‑webhooks, omförsök och timeouter. Anta att meddelanden kan försenas, dupliceras, tappas bort eller komma i fel ordning.
“Insidan” är det du faktiskt kontrollerar: ditt lagrade tillstånd, dina regler och de fakta du kan bevisa senare (vanligtvis i din databas).
Därför att nätverket kan ljuga för dig.
En klient som får timeout betyder inte att din server inte behandlade förfrågan. En webhook som kommer två gånger betyder inte att leverantören gjorde åtgärden två gånger. Om du behandlar varje meddelande som helt ny sanning kommer du att få dubblett‑order, dubbla avgifter och workflow‑problem som är svåra att reproducera.
En tydlig gräns är den punkt där ett opålitligt meddelande blir ett varaktigt faktum.
Vanliga gränser är:
När data korsat gränsen upprätthåller du invariabler inuti (t.ex. “order kan endast betalas en gång”).
Använd idempotens. Regeln är: samma intent ska ge samma resultat även om den skickas flera gånger.
Praktiska mönster:
Spara det inte bara i minnet. Lägg det innanför din gräns (t.ex. PostgreSQL) så att omstart inte tar bort skyddet.
Bevarandetid – tumregel:
Behåll poster tillräckligt länge för realistiska omförsök och fördröjda callbacks.
Använd tillstånd som medger osäkerhet.
Ett enkelt, praktiskt set:
pending_* (vi accepterade intenten men känner inte till utfall än)succeeded / failed (vi har registrerat ett slutligt utfall)needs_review (vi upptäckte en mismatch som kräver mänsklig åtgärd)För att du inte kan atomiskt committa över flera system över ett nätverk.
Om du gör “spara order → ta betalt → reservera lager” synkront och steg 2 får timeout vet du inte om det lyckades. Att retrya kan skapa dubbletter; att inte retrya kan lämna arbetet ofullständigt.
Designa för partiell framgång: persist intent först, utför externa åtgärder, och spela in utfall.
Outbox/inbox‑mönstret gör meddelandeutbyte robust utan att låtsas att nätverket är perfekt.
Avstämning är hur du återhämtar dig när dina poster och ett externt systems poster skiljer sig åt.
Bra default:
needs_reviewDet är nödvändigt för betalningar, leverans, prenumerationer eller allt som använder webhooks.
Ja. Snabb utveckling tar dig inte förbi nätverksfel—det bara gör problemen synliga snabbare.
Om du genererar tjänster med Koder.ai, baka in dessa defaulter tidigt:
Då blir omförsök och dubbla callbacks tråkiga istället för dyra.
Detta förhindrar gissningar vid timeouter och gör avstämning enklare.