05 maj 2025·8 min
Datadog och plattformsskiftet: Telemetri, integrationer, arbetsflöden
Se hur Datadog blir en plattform när telemetri, integrationer och arbetsflöden blir produkten — och få praktiska idéer du kan använda i din stack.
Se hur Datadog blir en plattform när telemetri, integrationer och arbetsflöden blir produkten — och få praktiska idéer du kan använda i din stack.
Ett observability-verktyg hjälper dig att besvara specifika frågor om ett system—vanligtvis genom att visa diagram, loggar eller ett sökresultat. Det är något du "använder" när det uppstår ett problem.
En observability-plattform är bredare: den standardiserar hur telemetri samlas in, hur team utforskar den och hur incidenter hanteras från början till slut. Den blir något din organisation "driver" varje dag, över många tjänster och team.
De flesta team börjar med dashboards: CPU-diagram, felrater, kanske några loggsökningar. Det är användbart, men det verkliga målet är inte snyggare diagram—det är snabbare upptäckt och snabbare åtgärd.
Ett plattformsskifte sker när ni slutar fråga "Kan vi grafera detta?" och börjar fråga:
Det är resultatfokuserade frågor, och de kräver mer än visualisering. De kräver delade datastandarder, konsekventa integrationer och arbetsflöden som kopplar telemetri till handling.
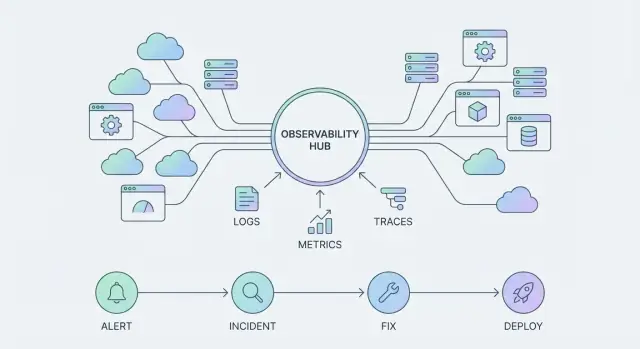
När plattformar som Datadog utvecklas är "produktytan" inte bara dashboards. Det är tre sammanlänkade pelare:
En enskild dashboard kan hjälpa ett enskilt team. En plattform blir starkare för varje tjänst som ansluts, varje integration som läggs till och varje arbetsflöde som standardiseras. Över tid komprimeras detta till färre blinda fläckar, mindre duplicerat verktyg och kortare incidenter—eftersom varje förbättring blir återanvändbar, inte engångs.
När observabilitet skiftar från "ett verktyg vi frågar" till "en plattform vi bygger på", slutar telemetri vara råspill och börjar fungera som produktytan. Vad du väljer att emitera—och hur konsekvent du emiterar det—avgör vad dina team kan se, automatisera och lita på.
De flesta team standardiserar runt några signaler:
Var för sig är varje signal användbar. Tillsammans blir de ett enda gränssnitt mot era system—det du ser i dashboards, aviseringar, incidenttidslinjer och postmortems.
Ett vanligt misslyckandemönster är att samla in "allt" men namnge det inkonsekvent. Om en tjänst använder userId, en annan uid och en tredje inte loggar något alls, kan du inte pålitligt skära data, slå ihop signaler eller bygga återanvändbara monitorer.
Team får mer värde av att enas om några konventioner—servicenamn, env-taggar, request IDs och ett standardset attribut—än av att dubbla ingångsvolymen.
Hög kardinalitet är attribut med många möjliga värden (som user_id, order_id eller session_id). De är kraftfulla för felsökning där "bara en kund" drabbas, men de kan öka kostnad och göra frågor långsammare om de används överallt.
Plattformsansatsen är avsiktlig: behåll hög kardinalitet där den ger tydligt undersökningsvärde och undvik den där globala aggregat behövs.
Vinsten är hastighet. När metrik, loggar, spår, händelser och profiler delar samma kontext (service, version, region, request ID) spenderar ingenjörer mindre tid på att sätta ihop bevis och mer tid på att laga problemet. Istället för att hoppa mellan verktyg och gissa följer du en tråd från symptom till rotorsak.
De flesta team börjar observabilitet med att "få in data." Det är nödvändigt, men det är inte en strategi. En telemetri-strategi är vad som håller onboarding snabb och gör din data tillräckligt konsekvent för att driva delade dashboards, pålitliga aviseringar och meningsfulla SLOs.
Datadog tar vanligtvis emot telemetri via några praktiska vägar:
I början vinner hastighet: team installerar en agent, slår på några integrationer och ser omedelbart värde. Risken är att varje team uppfinner sina egna taggar, servicenamn och loggformat—vilket gör tvärtjänstvyers utsnitt röriga och aviseringar opålitliga.
En enkel regel: tillåt "quick start"-onboarding, men kräv "standardisering inom 30 dagar." Det ger team momentum utan att låsa in kaos.
Du behöver ingen enorm taxonomi. Börja med ett litet set som varje signal (loggar, metrik, spår) måste bära:
service: kort, stabilt, gemener (t.ex. checkout-api)env: prod, staging, devteam: ägarteamets identifierare (t.ex. payments)version: deploy-version eller git SHAVill du ha en till som snabbt ger nytta, lägg till tier (frontend, backend, data) för att förenkla filtrering.
Kostnadsproblem kommer ofta från för generösa standarder:
Målet är inte att samla mindre—det är att samla rätt data konsekvent, så ni kan skala användningen utan överraskningar.
De flesta tror att observability-verktyg är "något man installerar." I praktiken sprider de sig i en organisation som bra kopplingar gör: en integration i taget.
En integration är inte bara ett datapipes. Den har vanligtvis tre delar:
Den sista delen är vad som förvandlar integrationer till distribution. Om verktyget bara läser är det en dashboarddestination. Om det också skriver blir det en del av det dagliga arbetet.
Bra integrationer minskar uppsättningstiden eftersom de levereras med vettiga standarder: förbyggda dashboards, rekommenderade monitorer, parsing-regler och vanliga taggar. Istället för att varje team uppfinner sin egen "CPU-dashboard" eller "Postgres-larm" får ni en standardstartpunkt som matchar best practices.
Team anpassar fortfarande—men de anpassar från en delad baslinje. Denna standardisering är viktig när ni konsoliderar verktyg: integrationer skapar upprepbara mönster som nya tjänster kan kopiera, vilket håller tillväxt hanterbar.
När ni utvärderar alternativ, fråga: kan den ta emot signaler och utföra åtgärder? Exempel inkluderar att öppna incidenter i ert ticketing-system, uppdatera incidentkanaler eller bifoga en trace-länk tillbaka i en PR eller deploy-vy. Tvåvägsupplägg är där arbetsflöden börjar kännas "native."
Börja smått och förutsägbart:
Som tumregel: prioritera integrationer som omedelbart förbättrar incidentrespons, inte de som bara lägger till fler diagram.
Standardvyer är där en observability-plattform blir användbar i det dagliga arbetet. När team delar samma mentala modell—vad en "service" är, vad "hälsosam" betyder och var man klickar först—går felsökning snabbare och överlämningar blir renare.
Välj ett litet set "golden signals" och mappa varje till en konkret, återanvändbar dashboard. För de flesta tjänster är det:
Nyckeln är konsekvens: en dashboard-layout som fungerar över tjänster slår tio specialanpassade dashboards.
En servicekatalog (även en lättviktig) förvandlar "någon borde titta" till "det här teamet äger det." När tjänster taggas med ägare, env och beroenden kan plattformen svara på enkla frågor direkt: Vilka monitorer gäller för denna tjänst? Vilka dashboards ska jag öppna? Vem får ett page?
Den tydligheten minskar Slack-pingpong under incidenter och hjälper nya ingenjörer att self-serva.
Behandla dessa som standardartefakter, inte valfria extras:
Vanity-dashboards (snygga diagram utan beslut bakom), engångsvarningar (skapade hastigt och aldrig justerade) och odokumenterade queries (endast en person förstår filtermagi) skapar plattformsbrus. Om en query är viktig, spara den, namnge den och fäst den vid en servicevy andra kan hitta.
Observability blir bara "verklig" för verksamheten när den förkortar tiden mellan problem och ett säkert åtgärdande. Det sker genom arbetsflöden—upprepbara vägar som tar dig från signal till handling, och från handling till lärande.
Ett skalbart arbetsflöde är mer än att paginera någon.
En alert bör öppna en fokuserad triage-loop: bekräfta påverkan, identifiera drabbad tjänst och hämta mest relevant kontext (senaste deploys, beroendehälsa, felspikar, saturation-signaler). Därifrån förvandlas kommunikation ett tekniskt event till en koordinerad respons—vem äger incidenten, vad ser användarna och när kommer nästa uppdatering.
Mildring är där du vill ha "säkra åtgärder" nära till hands: feature flags, traffic shifting, rollback, rate limits eller en känd workaround. Slutligen stänger lärandet loopen med en lättviktig granskning som fångar vad som ändrades, vad som fungerade och vad som bör automatiseras nästa gång.
Plattformar som Datadog adderar värde när de stödjer delat arbete: incidentkanaler, statusuppdateringar, överlämningar och konsekventa tidslinjer. ChatOps-integrationer kan förvandla alerts till strukturerade konversationer—skapa en incident, tilldela roller och posta nyckeldiagram och queries direkt i tråden så alla ser samma bevis.
En användbar runbook är kort, åsiktsfull och säker. Den bör innehålla: målet (återställa tjänst), tydliga ägare/on-call-rotationer, steg-för-steg-kontroller, länkar till rätt dashboards/monitorer och "säkra åtgärder" som minskar risk (med rollback-steg). Om den inte är säker att köra kl. 03:00, är den inte klar.
Rotorsaken hittas snabbare när incidenter automatiskt korreleras med deploys, konfigändringar och feature flag-flippar. Gör "vad ändrades?" till en förstklassig vy så triage börjar med bevis, inte gissningar.
Ett SLO (Service Level Objective) är ett enkelt löfte om användarupplevelsen över ett tidsfönster—till exempel "99.9% av förfrågningar lyckas över 30 dagar" eller "p95 sidladdningar är under 2 sekunder."
Det slår en "grön dashboard" eftersom dashboards ofta visar systemhälsa (CPU, minne, ködjup) snarare än kundpåverkan. En tjänst kan se grön ut men ändå misslyckas för användare (t.ex. ett beroende tajmar ut eller fel är koncentrerade i en region). SLOs tvingar teamet att mäta vad användarna faktiskt upplever.
En error budget är mängden otillförlitlighet ni accepterar enligt ert SLO. Om ni lovar 99.9% över 30 dagar är ni "tillåtna" ungefär 43 minuter fel i det fönstret.
Detta skapar ett praktiskt operativsystem för beslut:
Istället för att debattera åsikter i ett releasemöte, debatterar ni ett nummer alla kan se.
SLO-avisering fungerar bäst när ni larmar på burn rate (hur snabbt ni förbrukar error-budgeten), inte på råa felräkningar. Det minskar brus:
Många team använder två fönster: ett snabbt burn (page snabbt) och ett långsamt burn (ticket/notifiering).
Börja smått—två till fyra SLOs ni faktiskt använder:
När dessa är stabila kan ni expandera—annars bygger ni bara en annan vägg av dashboards. För mer, se /blog/slo-monitoring-basics.
Avisering är där många observability-program fastnar: datan finns, dashboards ser bra ut, men on-call-upplevelsen blir brusig och opålitlig. Om folk lär sig ignorera aviseringar förlorar plattformen sin förmåga att skydda verksamheten.
De vanligaste orsakerna är förvånansvärt konsekventa:
I Datadog-termer uppstår duplicerade signaler ofta när monitorer skapas från olika "ytor" (metrics, loggar, traces) utan att besluta vilken som är den kanoniska pagingen.
Att skala avisering börjar med routing-regler som är logiska för människor:
En användbar default är: larma på symptom, inte varje metrikförändring. Paga på saker användare märker (felrate, misslyckade köp, utdragen latens, SLO-burn), inte på "inputs" (CPU, pod-count) om de inte pålitligt förutsäger påverkan.
Gör larmhygien till en operationsvana: månatlig monitor-pruning och tuning. Ta bort monitorer som aldrig triggar, justera trösklar som triggar för ofta och slå ihop dubbletter så varje incident har en primär page plus stödjande kontext.
Görs det väl blir avisering ett arbetsflöde folk litar på—inte ett bakgrundsbrus.
Att kalla observabilitet en "plattform" handlar inte bara om att ha loggar, metrik, spår och många integrationer på ett ställe. Det innebär också styrning: de konsistenser och skydd som håller systemet användbart när antalet team, tjänster, dashboards och monitorer multipliceras.
Utan styrning kan Datadog (eller vilken observability-plattform som helst) glida in i ett brusigt scrapbook—hundratals snarlika dashboards, inkonsekventa taggar, otydligt ägarskap och larm ingen litar på.
Bra styrning klargör vem som bestämmer vad och vem som ansvarar när plattformen blir rörig:
Några lätta kontroller gör mer än långa policydokument:
service, env, team, tier) plus tydliga regler för valfria taggar. Verkställ i CI där det går.Det snabbaste sättet att skala kvalitet är att dela det som fungerar:
Vill ni att detta ska hålla måste den styrda vägen vara den enkla vägen—färre klick, snabbare uppsättning och tydligare ägarskap.
När observabilitet börjar fungera som en plattform följer den plattforms-ekonomi: ju fler team som antar den, desto mer telemetri produceras och desto nyttigare blir den.
Det skapar en svänghjulseffekt:
Fällan är att samma loop också ökar kostnad. Fler hosts, containrar, loggar, traces, syntetiska tester och anpassade metrik kan växa snabbare än budgeten om ni inte hanterar det medvetet.
Ni behöver inte "stänga av allt." Börja med att forma datan:
Mät ett litet set mått som visar om plattformen betalar tillbaka:
Gör det till en produktgranskning, inte en revision. Ha med plattformsägare, några service-team och finans. Granska:
Målet är delat ägarskap: kostnad blir en input till bättre instrumenteringsbeslut, inte en anledning att sluta observera.
Om observabilitet blir en plattform slutar er "verktygsstack" vara en samling punktlösningar och börjar fungera som delad infrastruktur. Den förändringen gör tool-sprawl till mer än ett irritationsmoment: den skapar duplicerad instrumentering, inkonsekventa definitioner (vad räknas som ett fel?) och högre on-call-belastning eftersom signaler inte linjerar över loggar, metrik, spår och incidenter.
Konsolidering betyder inte automatiskt "en leverantör för allt." Det betyder färre system-of-record för telemetri och respons, tydligare ägarskap och ett mindre antal ställen folk behöver titta på under ett outage.
Tool-sprawl döljer ofta kostnader på tre ställen: tid som går åt att hoppa mellan UI:er, bräckliga integrationer ni måste underhålla och fragmenterad styrning (namn, taggar, retention, åtkomst).
En mer konsoliderad plattformsansats kan minska kontextbyten, standardisera servicevyer och göra incidentarbetsflöden upprepbara.
När ni utvärderar er stack (inklusive Datadog eller alternativ) pressa på dessa:
Välj en eller två tjänster med verklig trafik. Definiera ett enda framgångsmått som "tid till hitta rotorsak minskar från 30 minuter till 10" eller "minska bullriga larm med 40%." Instrumentera bara det ni behöver och granska resultat efter två veckor.
Håll interna dokument centraliserade så lärande kan byggas på—länka pilotens runbook, taggregler och dashboards från ett ställe, till exempel /blog/observability-basics som en intern startpunkt.
Du "rullar inte ut Datadog" på en gång. Du börjar smått, sätter standarder tidigt och skalar sedan det som fungerar.
Dagar 0–30: Onboarda (bevisa värde snabbt)
Välj 1–2 kritiska tjänster och en kundvänd resa. Instrumentera loggar, metrik och spår konsekvent och koppla de integrationer ni redan litar på (cloud, Kubernetes, CI/CD, on-call).
Dagar 31–60: Standardisera (gör det upprepbart)
Gör om vad ni lärde er till defaults: servicenamn, taggning, dashboardmallar, namngivning av monitorer och ägarskap. Skapa "golden signals"-vyer (latens, trafik, fel, saturation) och ett minimalt SLO-set för de viktigaste endpoints.
Dagar 61–90: Skala (expandera utan kaos)
Onboarda fler team med samma mallar. Inför styrning (taggregler, obligatorisk metadata, granskningsprocess för nya monitorer) och börja spåra kostnad vs användning så plattformen håller sig hälsosam.
När ni betraktar observability som en plattform kommer ni ofta vilja ha små "lim"-appar runt den: ett servicekatalog-UI, ett runbook-nav, en incidenttidslinje-sida eller en intern portal som länkar ägare → dashboards → SLOs → playbooks.
Det här är den typ av lättviktiga interna verktyg ni snabbt kan bygga på Koder.ai—en vibe-coding-plattform som låter er generera webbappar via chat (vanligtvis React i frontend, Go + PostgreSQL i backend), med export av källkod och stöd för deployment/hosting. I praktiken använder team det för att prototypa och leverera de operationella ytor som underlättar styrning och arbetsflöden utan att dra bort ett helt produktteam från roadmap.
Kör två 45-minuterssessioner: (1) "Hur vi frågar här" med delade query-mönster (per service, env, region, version), och (2) "Felsöknings-playbook" med ett enkelt flöde: bekräfta påverkan → kolla deploy-markörer → avgränsa till tjänst → inspektera traces → bekräfta beroendehälsa → besluta rollback/mildring.
En observability tool är något du konsulterar vid ett problem (dashboards, loggsök, en fråga). En observability platform är något du kör kontinuerligt: den standardiserar telemetri, integrationer, åtkomst, ägarskap, aviseringar och incidentarbetsflöden över team så att utfallen förbättras (snabbare upptäckt och lösning).
Där de största vinsterna finns handlar om resultat, inte bara visuella element:
Diagram hjälper, men ni behöver delade standarder och arbetsflöden för att konsekvent minska MTTD/MTTR.
Börja med ett baspaket som varje signal måste bära:
serviceenv (prod, staging, )Fält med hög kardinalitet (som user_id, order_id, session_id) är utmärkta för felsökning när "bara en kund" drabbas, men de kan öka kostnad och göra förfrågningar långsammare om de används överallt.
Använd dem med avsikt:
De flesta team standardiserar på:
En praktisk standard är:
Välj den väg som matchar era kontrollbehov och tvinga samma namn-/taggregler över alla.
Gör båda:
Detta förhindrar att varje team uppfinner sitt eget schema samtidigt som det bevarar adoptionsmomentum.
För att integrationskanalen ska fungera behöver integrationer mer än bara dataflöde — de innehåller:
Prioritera tvåvägs-integrationer som både tar emot signaler och kan trigga/registrera åtgärder, så blir observability en del av det dagliga arbetet — inte bara en destinations-UI.
Fokusera på konsekvens och återanvändning:
Undvik vanity-dashboards och engångsvarningar. Om en fråga är viktig, spara den, namnge den och länka den till en servicevy som andra hittar.
Larma på burn rate (hur snabbt ni förbrukar error-budgeten), inte på varje övergående topp. Ett vanligt mönster:
Håll startuppsättningen liten (2–4 SLOs per tjänst) och bygg ut först när teamen faktiskt använder dem. För grunderna, se /blog/slo-monitoring-basics.
devteamversion (deploy-version eller git SHA)Lägg till tier (frontend, backend, data) om ni vill ha ett enkelt extra filter som snabbt ger avkastning.
Nyckeln är att få dessa att dela samma kontext (service/env/version/request ID) så korrelation blir snabb.