21 sep. 2025·7 min
Disruptor-mönstret för låg latenstid: förutsägbar realtidsdesign
Lär dig Disruptor-mönstret för låg latenstid och hur du designar realtidssystem med förutsägbara svarstider med köer, minne och arkitekturval.
Lär dig Disruptor-mönstret för låg latenstid och hur du designar realtidssystem med förutsägbara svarstider med köer, minne och arkitekturval.
Hastighet har två sidor: genomströmning och latenstid. Genomströmning är hur mycket arbete du avslutar per sekund (förfrågningar, meddelanden, frames). Latenstid är hur lång tid en enskild arbetsenhet tar från start till slut.
Ett system kan ha bra genomströmning men ändå kännas segt om vissa förfrågningar tar mycket längre tid än andra. Därför lurar medelvärden. Om 99 åtgärder tar 5 ms och en åtgärd tar 80 ms ser snittet bra ut, men den som fick 80 ms upplever stutter. I realtidssystem är dessa sällsynta toppar hela historien eftersom de bryter rytmen.
Förutsägbar latenstid betyder att du inte bara siktar på ett lågt medelvärde. Du siktar på konsistens, så att de flesta operationer slutförs inom ett snävt intervall. Därför tittar team på svansen (p95, p99). Det är där pauserna gömmer sig.
En 50 ms-spik kan spela roll i tillämpningar som röst och video (ljudstörningar), multiplayer-spel (rubber-banding), realtidshandel (missade priser), industriell övervakning (försenade larm) och live-dashboards (siffror hoppar, varningar känns opålitliga).
Ett enkelt exempel: en chattapp levererar oftast meddelanden snabbt. Men om en bakgrundspaus gör att ett meddelande anländer 60 ms för sent, flimrar skrivindikatorer och konversationen känns trög även om servern ser "snabb" ut i snitt.
Om du vill att realtid ska kännas verkligen realtid behöver du färre överraskningar, inte bara snabbare kod.
De flesta realtidssystem är inte långsamma för att CPU:n kämpar. De känns långsamma för att arbete tillbringar största delen av sin tid i väntan: väntan på att bli schemalagt, väntan i en kö, väntan på nätverk eller väntan på lagring.
End-to-end-latenstid är hela tiden från "något hände" till "användaren ser resultatet." Även om din handler körs på 2 ms kan förfrågan ändå ta 80 ms om den pausar på fem olika ställen.
Ett användbart sätt att dela upp vägen är:
Dessa väntetider adderas. Några millisekunder här och där gör en "snabb" kodväg till en seg upplevelse.
Tail-latency är där användare börjar klaga. Medelvärdet kan se bra ut, men p95 eller p99 betyder de långsammaste 5% eller 1% av förfrågningarna. Outliers kommer ofta från sällsynta pauser: en GC-cykel, en bullrig granne på hosten, kort låskontention, en cache-uppfyllning eller en burst som skapar en kö.
Konktret exempel: en prisuppdatering anländer över nätverket på 5 ms, väntar 10 ms på en upptagen worker, spenderar 15 ms bakom andra events och träffar sedan ett databasstopp i 30 ms. Din kod kördes fortfarande på 2 ms, men användaren väntade 62 ms. Målet är att göra varje steg förutsägbart, inte bara beräkningen snabb.
Ett snabbt algoritmval kan ändå kännas segt om tiden per förfrågan svänger. Användare lägger märke till toppar, inte medelvärdet. Denna svängning är jitter, och ofta kommer den från saker din kod inte helt kontrollerar.
CPU-cachar och minnesbeteende är dolda kostnader. Om het data inte får plats i cachen stannar CPU:n medan den väntar på RAM. Objekt-tunga strukturer, utspritt minne och "bara en lookup till" kan bli upprepade cache-missar.
Minnesallokering lägger till sin egen slump. Att allokera många kortlivade objekt ökar trycket på heapen, vilket senare visar sig som pauser (garbage collection) eller allocator-konflikter. Även utan GC kan frekventa allokeringar fragmentera minnet och försämra lokalitet.
Trådschemaläggning är en annan vanlig källa. När en tråd deschemaläggs betalar du context switch-overhead och förlorar cache-varmhet. På en upptagen maskin kan din "realtidstråd" få vänta bakom orelaterat arbete.
Låskontention är där förutsägbara system ofta fallerar. Ett lås som "vanligtvis är fritt" kan bli en konvoj: trådar vaknar, kämpar om låset och sätter varandra i sömn igen. Arbetet blir gjort, men tail-latenstiden drar ut.
I/O-väntan kan överträffa allt annat. Ett enda systemanrop, en full nätverksbuffert, en TLS-handshake, en diskflush eller en långsam DNS-lookup kan skapa en kraftig spik som ingen mikrooptimering fixar.
Om du jagar jitter, börja med att leta efter cache-missar (ofta orsakade av pekar-tunga strukturer och slumpmässig åtkomst), frekventa allokeringar, context switches från för många trådar eller bullriga grannar, låskontention och all blockerande I/O (nätverk, disk, loggning, synkrona anrop).
Exempel: en price-ticker-tjänst kan räkna uppdateringar på mikrosekunder, men ett synkroniserat logg-anrop eller ett kontenderat metrics-lås kan intermittenta lägga till tiotals millisekunder.
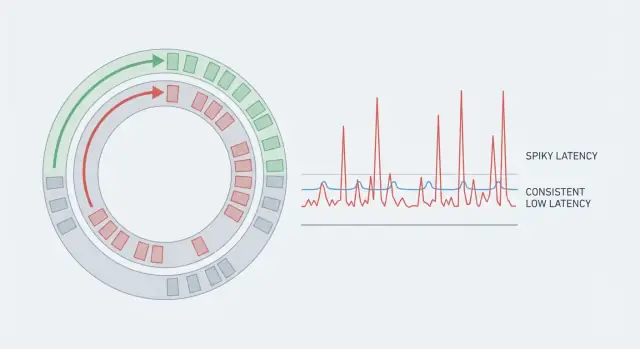
Martin Thompson är känd inom låg-latenstidsteknik för att fokusera på hur system beter sig under tryck: inte bara genomsnittlig hastighet, utan förutsägbar hastighet. Tillsammans med LMAX-teamet hjälpte han till att popularisera Disruptor-mönstret, en referensmetod för att föra händelser genom ett system med små och konsekventa fördröjningar.
Disruptor-tanken är ett svar på vad som gör många "snabba" appar oförutsägbara: kontention och koordination. Typiska köer förlitar sig ofta på lås eller tunga atomics, väcker trådar upp och ner, och skapar väntelaster när producenter och konsumenter slåss om delade strukturer.
Istället för en kö använder Disruptor en ringbuffer: en faststor cirkulär array som håller händelser i slots. Producenter tar nästa slot, skriver data och publicerar ett sekvensnummer. Konsumenter läser i ordning genom att följa den sekvensen. Eftersom bufferten är förallokerad undviker du frekventa allokeringar och minskar trycket på garbage collectorn.
En nyckelidé är en-skrivare-principen: håll en komponent ansvarig för ett visst delat tillstånd (t.ex. kursorn som avancerar genom ringen). Färre skrivare betyder färre "vem går nästa?"-ögonblick.
Backpressure är explicit. När konsumenter hamnar efter når producenter så småningom en slot som fortfarande är i bruk. Då måste systemet vänta, droppa eller sakta ner, men det gör det på ett kontrollerat, synligt sätt istället för att gömma problemet i en växande kö.
Vad som gör Disruptor-liknande designer snabba är inte en smart mikrooptimering. Det är att ta bort de oförutsägbara pauser som händer när ett system kämpar med sina egna rörliga delar: allokeringar, cache-missar, låskontention och långsamt arbete blandat i hot-path.
En användbar mental modell är en monteringslinje. Händelser rör sig genom en fast rutt med tydliga överlämningar. Det minskar delat tillstånd och gör varje steg enklare att hålla enkelt och mätbart.
Snabba system undviker överraskande allokeringar. Om du förallokerar buffrar och återanvänder meddelandeobjekt minskar du "ibland"-spikar orsakade av garbage collection, heap-tillväxt och allocator-lås.
Det hjälper också att hålla meddelanden små och stabila. När datan du berör per händelse får plats i CPU-cachen spenderar du mindre tid på att vänta på minne.
I praktiken är vanorna som brukar spela störst roll: återanvänd objekt istället för att skapa nya per händelse, håll eventdata kompakt, föredra en enda skrivare för delat tillstånd och batcha försiktigt så du betalar koordinationskostnader mer sällan.
Realtidsappar behöver ofta extras som loggning, metrics, retries eller databas-skrivningar. Disruptor-tänkandet är att isolera dessa från kärnloopen så att de inte kan blockera den.
I ett live-prisflöde kan hot-path bara validera en tick och publicera nästa pris-snapshot. Allt som kan stanna (disk, nätverksanrop, tung serialisering) flyttas till en separat konsument eller sidokanäl, så att den förutsägbara vägen förblir förutsägbar.
Förutsägbar latenstid är mest ett arkitekturproblem. Du kan ha snabb kod och ändå få spikar om för många trådar slåss om samma data eller om meddelanden studsar över nätverket utan anledning.
Börja med att bestämma hur många skrivare och läsare som rör samma kö eller buffert. En enda producent är lättare att hålla jämn eftersom den undviker koordination. Multi-producent-upplägg kan öka genomströmningen men ofta lägga till kontention och göra worst-case-tider mindre förutsägbara. Om du behöver flera producenter, minska delade skrivningar genom att sharda händelser efter nyckel (t.ex. userId eller instrumentId) så varje shard har sin egen hot-path.
På konsumentsidan ger en enda konsument mest stabil timing när ordering är viktigt, eftersom tillstånd hålls lokalt i en tråd. Worker-pooler hjälper när uppgifter är verkligt oberoende, men de lägger till schemaläggningsförseningar och kan förändra ordningen om du inte är försiktig.
Batchning är en annan tradeoff. Små batcher minskar overhead (färre wakeups, färre cache-missar), men batchning kan också lägga till väntetid om du håller händelser för att fylla en batch. Om du batchar i ett realtidssystem, sätt en gräns för väntetid (t.ex. "upp till 16 händelser eller 200 mikrosekunder, vad som än kommer först").
Tjänstegränser spelar också roll. In-process-meddelanden är oftast bäst när du behöver tät latenstid. Nätverkshopp kan vara värda det för skalning, men varje hopp lägger till köer, retries och variabel fördröjning. Om du behöver ett hopp, håll protokollet enkelt och undvik fan-out i hot-path.
En praktisk regelsamling: håll en single-writer path per shard när du kan, skala genom sharding-nycklar istället för att dela en het kö, batcha endast med strikt tidsgräns, lägg till worker-pooler endast för parallellt och oberoende arbete, och behandla varje nätverkshopp som en potentiell jitter-källa tills du mätt den.
Börja med en skriftlig latenstidsbudget innan du rör koden. Välj ett mål (vad som "känns bra") och ett p99 (vad du måste hålla dig under). Dela upp det numret över stadier som indata, validering, matchning, persistens och utgående uppdateringar. Om ett stadium inte har någon budget har det ingen gräns.
Rita sedan hela dataflödet och markera varje överlämning: trådgränser, köer, nätverkshopp och lagringsanrop. Varje överlämning är en plats där jitter gömmer sig. När du kan se dem kan du minska dem.
Ett arbetsflöde som håller designen ärlig:
Bestäm sedan vad som kan vara asynkront utan att bryta användarupplevelsen. En enkel regel: allt som ändrar vad användaren ser "nu" stannar på den kritiska vägen. Allt annat flyttas ut.
Analytics, revisionsloggar och sekundär indexering kan ofta skjutas bort från hot-path. Validering, ordering och steg som behövs för att producera nästa tillstånd kan vanligtvis inte det.
Snabb kod kan ändå kännas seg när runtime eller OS pausar ditt arbete vid fel ögonblick. Målet är inte bara hög genomströmning. Det är färre överraskningar i de långsammaste 1% av förfrågningarna.
Garbage-collected runtimes (JVM, Go, .NET) kan vara bra för produktivitet, men de kan introducera pauser när minnet behöver städas. Moderna collectors är mycket bättre än förr, men tail-latency kan ändå hoppa om du skapar många kortlivade objekt under last. I icke-GC-språk (Rust, C, C++) undviker du GC-pauser, men skjuter kostnaden till manuell ägarskap och allokeringsdisciplin. Hur som helst spelar minnesbeteende lika stor roll som CPU-hastighet.
Den praktiska vanan är enkel: hitta var allokeringar händer och gör dem tråkiga. Återanvänd objekt, förstor buffrar i förväg och undvik att förvandla hot-path-data till temporära strängar eller kartor.
Trådval visar sig också som jitter. Varje extra kö, async-hopp eller trådpool-övergång lägger till väntan och ökar variansen. Föredra ett litet antal långlivade trådar, håll producent-konsument-gränser tydliga och undvik blockerande anrop på hot-path.
Några OS- och containerinställningar avgör ofta om din svans är ren eller spikig. CPU-throttling från strikta gränser, bullriga grannar på delade hosts och illa placerad loggning eller metrics kan alla skapa plötsliga fördröjningar. Om du bara ändrar en sak, börja med att mäta allokeringshastighet och context switches under latenstidsspikar.
Många latenstidsspikar är inte "långsam kod." De är väntetider du inte planerat för: ett databaslås, en retry-storm, ett cross-service-anrop som hänger eller en cache-miss som blir en full rundresa.
Håll den kritiska vägen kort. Varje extra hopp lägger till schemaläggning, serialisering, nätverksköer och fler ställen att blockera. Om du kan svara från en process och en datakälla, gör det först. Dela upp i fler tjänster bara när varje anrop är valfritt eller strikt avgränsat.
Begränsad väntan är skillnaden mellan snabba medelvärden och förutsägbar latenstid. Sätt hårda timeouts på fjärranrop och faila snabbt när en beroende är ohälsosam. Circuit breakers handlar inte bara om att rädda servrar. De sätter en gräns för hur länge användare kan ligga fast.
När dataåtkomst blockerar, separera vägarna. Läsningar vill ofta ha indexerade, denormaliserade, cache-vänliga former. Skrivningar vill ofta ha hållbarhet och ordering. Att separera dem kan ta bort kontention och minska låstiden. Om dina konsistensbehov tillåter det, beter sig append-only-loggar (en eventlogg) ofta mer förutsägbart än in-place-uppdateringar som triggar hot-row-lås eller bakgrundsunderhåll.
En enkel regel för realtidsappar: persistens bör inte sitta på den kritiska vägen om du inte verkligen behöver det för korrekthet. Ofta är en bättre form: uppdatera i minnet, svara, och persist -asynkront- med en replay-mekanism (som en outbox eller write-ahead-log).
I många ringbuffer-pipelines slutar detta som: publicera till en minnesbuffer, uppdatera tillstånd, svara, och låt en separat konsument batcha skrivningar till PostgreSQL.
Föreställ dig en live-samarbetsapp (eller ett litet multiplayer-spel) som pushar uppdateringar var 16 ms (ungefär 60 gånger per sekund). Målet är inte "snabbt i snitt." Det är "vanligtvis under 16 ms," även när en användares anslutning är dålig.
Ett enkelt Disruptor-liknande flöde ser ut så här: användarinmatning blir en liten event, den publiceras i en förallokerad ringbuffer, bearbetas av en fast uppsättning handlers i ordning (validate -> apply -> prepare outbound messages), och broadcastas sedan till klienter.
Batchning kan hjälpa i kanterna. Till exempel, batcha utgående skrivningar per klient en gång per tick så du anropar nätverkslagret färre gånger. Men batcha inte inne i hot-path på ett sätt som väntar "bara lite längre" för fler events. Att vänta är hur du missar tick.
När något blir långsamt, behandla det som ett inkapslingsproblem. Om en handler blir långsam, isolera den bakom sin egen buffer och publicera istället ett lättviktsarbete så huvudloopen inte blockeras. Om en klient är långsam, låt den inte backa upp broadcastern; ge varje klient en liten sändkö och droppa eller coalescera gamla uppdateringar så du behåller senaste tillståndet. Om bufferdjupet växer, applicera backpressure i kanten (sluta acceptera extra input för den ticken eller degradera funktioner).
Du vet att det fungerar när siffrorna förblir tråkiga: backlog-djup ligger nära noll, droppade/coalescerade events är sällsynta och förklarliga, och p99 håller sig under din tick-budget under realistisk belastning.
De flesta latenstidsspikar är självförvållade. Koden kan vara snabb, men systemet pausar när det väntar på andra trådar, OS eller något utanför CPU-cachen.
Några upprepade misstag:
Ett snabbt sätt att minska spikar är att göra väntan synlig och begränsad. Flytta långsamt arbete till en separat väg, kapa köer och bestäm vad som händer när du är full (droppa, shedda eller degradera funktioner).
Behandla förutsägbar latenstid som en produktfunktion, inte en olycka. Innan du finjusterar kod, se till att systemet har tydliga mål och skydd.
Ett enkelt test: simulera en burst (10x normal trafik i 30 sekunder). Om p99 exploderar, fråga var väntan sker: växande köer, en långsam konsument, en GC-paus eller en delad resurs.
Behandla Disruptor-mönstret som ett arbetsflöde, inte ett bibliotekval. Bevisa förutsägbar latenstid med en tunn slice innan du lägger till funktioner.
Välj en användaråtgärd som måste kännas omedelbar (t.ex. "nytt pris anländer, UI uppdateras"). Skriv ner end-to-end-budgeten och mät p50, p95 och p99 från dag ett.
En sekvens som brukar fungera:
Om du bygger på Koder.ai (koder.ai), kan det hjälpa att först kartlägga event-flödet i Planning Mode så köer, lås och tjänstegränser inte dyker upp av misstag. Snapshots och rollback gör det också enklare att köra upprepade latenstidsexperiment och backa ut ändringar som förbättrar genomströmning men försämrar p99.
Håll mätningarna ärliga. Använd ett fast testskript, värm upp systemet och registrera både genomströmning och latenstid. När p99 hoppar med belastning, börja inte med att "optimera koden." Leta efter pauser från GC, bullriga grannar, loggburstar, trådschemaläggning eller dolda blockerande anrop.
Medelvärden döljer sällsynta pauser. Om de flesta åtgärder är snabba men några få tar mycket längre tid, uppfattar användaren det som stutter eller "lagg", särskilt i realtidsflöden där rytm spelar roll.
Mät tail-latency (t.ex. p95/p99) eftersom det är där de märkbara pauserna bor.
Genomströmning är hur mycket arbete du klarar av per sekund. Latenstid är hur lång tid en enskild handling tar från början till slut.
Du kan ha hög genomströmning men ändå få enstaka långa väntetider, och dessa väntetider är vad som gör realtidsappar långsamma i upplevd mening.
Tail-latency (p95/p99) mäter de långsammaste förfrågningarna, inte de typiska. p99 betyder att 1% av operationerna tar längre tid än det värdet.
I realtidsappar visar sig den här 1% ofta som synligt jitter: ljudstörningar, rubber-banding, blinkande indikatorer eller missade ticks.
Det mesta av tiden tillbringas ofta i väntan, inte i beräkning:
En handler på 2 ms kan ändå ge 60–80 ms end-to-end om den väntar på flera platser.
Vanliga källor till jitter inkluderar:
För att debugga, korrelera spikar med allokeringshastighet, context switches och ködjup.
Disruptor är ett mönster för att föra händelser genom en pipeline med små, konsekventa fördröjningar. Det använder en förallokerad ringbuffer och sekvensnummer istället för en typisk delad kö.
Målet är att minska oförutsägbara pauser från kontention, allokering och wakeups—så latenstiden blir "tråkig", inte bara snabb i genomsnitt.
Förallokera och återanvänd objekt/buffrar i hot-loop: detta minskar
Håll även eventdata kompakt så att CPU:n berör mindre minne per händelse (bättre cachebeteende).
Börja med en single-writer-path per shard när det går (lättare att resonera om, mindre kontention). Skala genom att sharda efter nyckel (t.ex. userId eller instrumentId) istället för att ha många producenter som kämpar om samma kö.
Använd worker pools endast för verkligt oberoende arbete; annars byter du ofta till högre tail-latency och svårare felsökning.
Batchning minskar overhead men kan lägga till väntetid om du håller händelser för att fylla en batch.
En praktisk regel är att begränsa batchning både efter storlek och tid (t.ex. "upp till N händelser eller upp till T mikrosekunder, vad som än kommer först") så batchning inte tyst bryter din latenstidsbudget.
Skriv först en latenstidsbudget (target och p99), dela upp den över stadier. Kartlägg varje handoff (köer, trådbass, nätverkshopp, lagringsanrop) och gör väntan synlig med metrik som ködjup och per-stadie-tid.
Håll blockerande I/O utanför kritiska vägen, använd begränsade köer och bestäm överbelastningsbeteende i förväg (droppa, shed, coalescera eller backpressure).