Vad “Distributed SQL” betyder (utan hype)
”Distributed SQL” är en databas som känns som en traditionell relationsdatabas—tabeller, rader, joins, transaktioner och SQL—men som är utformad för att köras som ett kluster över många maskiner (och ofta över flera regioner) samtidigt som den beter sig som en logisk databas.
Den kombinationen är viktig eftersom den försöker leverera tre saker samtidigt:
- SQL och relationsmodellering: välkända scheman, constraints och query-verktyg.
- Skalning utåt: lägg till noder för att öka kapaciteten istället för att ”köpa en större server”.
- Stark konsistens: läsningar och skrivningar följer tydliga transaktionsregler, även när data är utspridd.
Mellan klassisk RDBMS och NoSQL
En klassisk RDBMS (som PostgreSQL eller MySQL) är oftast enklast att drifta när allt ligger på en primär nod. Du kan skala läsningar med repliker, men att skala skrivningar och klara regionala avbrott kräver ofta extra arkitektur (sharding, manuell failover och noggrann applikationslogik).
Många NoSQL-system tog motsatt väg: fokus på skalning och hög tillgänglighet först, ibland genom att släppa på konsistensgarantier eller erbjuda enklare frågemodeller.
Distributed SQL siktar på en mellanväg: behåll relationsmodellen och ACID-transaktioner, men distribuera data automatiskt för att hantera tillväxt och fel.
Vad det försöker lösa
Distributed SQL-databaser byggs för problem som:
- Globala applikationer med användare i flera regioner, där både latens och tillgänglighet spelar roll.
- Hög tillgänglighet utan komplexa, manuella failover-procedurer.
- Tillväxt över tid, där du vill expandera kapacitet stegvis och behålla ett enda databassnitt.
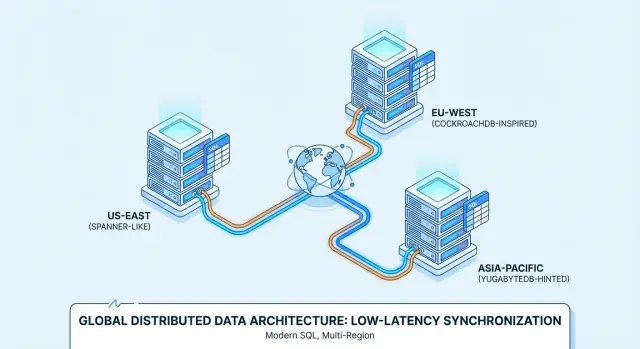
Det är därför produkter som Google Spanner, CockroachDB och YugabyteDB ofta utvärderas för multi-region-implementeringar och alltid-på-tjänster.
Sätt förväntningar (det är inte standarden)
Distributed SQL är inte automatiskt “bättre”. Du accepterar fler rörliga delar och andra prestandarealiteter (nätverkshopp, konsensus, tvärregional latens) i utbyte mot motståndskraft och skalbarhet.
Om din workload får plats på en enda välskött databas med en enkel replikeringsuppsättning kan en konventionell RDBMS vara enklare och billigare. Distributed SQL tjänar sig när alternativet är kundanpassad sharding, komplex failover eller affärskrav som kräver multi-region-konsistens och hög tillgänglighet.
Hur Distributed SQL fungerar under ytan
Distributed SQL ska kännas som en bekant SQL-databas samtidigt som den lagrar data över flera maskiner (och ofta flera regioner). Den svåra delen är att koordinera många datorer så att de beter sig som ett enda pålitligt system.
Replikering + konsensus: hur noder är överens
Varje dataparti kopieras normalt till flera noder (replikering). Om en nod går ner kan en annan kopia fortfarande svara på läsningar och ta emot skrivningar.
För att förhindra att repliker glider isär använder Distributed SQL-system konsensusprotokoll—oftast Raft (CockroachDB, YugabyteDB) eller Paxos (Spanner). På en hög nivå betyder konsensus:
- En replika agerar som ”ledare” för en grupp repliker.
- Skrivningar går till ledaren.
- Ledaren bekräftar skrivningen först efter att en majoritet av replikerna har kvitterat.
Denna ”majoritetsröst” är vad som ger dig stark konsistens: när en transaktion committas kommer andra klienter inte att se en äldre version av datan.
Sharding/partitionering: var data bor
Ingen enskild maskin kan hålla allt, så tabeller delas upp i mindre bitar kallade shards/partitions (Spanner kallar dem splits; CockroachDB kallar dem ranges; YugabyteDB kallar dem tablets).
Varje partition är replikerad (med konsensus) och placerad på specifika noder. Placeringen är inte slumpmässig: du kan påverka den med policies (t.ex. håll EU-kunder i EU-regioner eller placera heta partitioner på snabbare noder). Bra placering minskar tvärnätverkstrafik och håller prestandan mer förutsägbar.
Transaktioner över noder (och varför det lägger till latens)
Med en single-node-databas kan en transaktion ofta committa med lokala diskoperationer. I Distributed SQL kan en transaktion röra flera partitioner—möjligen på olika noder.
Att committa säkert kräver vanligtvis extra koordinering:
- Låsning eller validering av data på de involverade partitionerna
- Replikera skrivningar via konsensus (majoritetsack)
- Slutföra ett commit-beslut så att alla deltagare är överens
Dessa steg introducerar nätverksrundor, vilket är anledningen till att distribuerade transaktioner typiskt ökar latensen—särskilt när data spänner över regioner.
Multi-region-beteende: lokalitetsmedvetna läsningar och skrivningar
När distributionen sträcker sig över regioner försöker systemen hålla operationer ”nära” användarna:
- Lokalitetsmedvetna läsningar kan besvaras från närliggande repliker när det är säkert.
- Lokalitetsmedvetna skrivningar kan routas till ledare i en vald region, eller man placerar ledare nära primära skribenter.
Detta är kärnan i multi-region-balansen: du kan optimera för lokal respons, men stark konsistens över långa avstånd kommer fortfarande att kosta nätverkstid.
När du faktiskt behöver det (och när du inte gör det)
Innan du tar till distributed SQL, kontrollera dina grundläggande behov. Om du har en primär region, förutsägbar belastning och liten ops-budget är en konventionell relationsdatabas (eller en hanterad Postgres/MySQL) oftast det enklaste sättet att snabbt leverera funktioner. Du kan ofta pressa en single-region-uppsättning långt med läs-repliker, caching och noggrann schema/index-optimisering.
Tydliga triggers: när distributed SQL lönar sig
Distributed SQL är värt att överväga seriöst när en eller flera av följande är sanna:
- Du har riktiga användare i flera regioner och vill att databasen ska vara nära dem utan att bygga komplex app-nivå sharding.
- Krav på uppetid är höga (t.ex. överleva zon-/regionfel) och en enda primär region är en oacceptabel risk.
- Datavolym eller skrivgenomströmning överstiger vertikal skalning, och du vill ha horisontell skalning samtidigt som du behåller SQL-semantik.
- Du behöver stark konsistens över noder/regioner för kärntransaktioner (order, saldon, reservationer) utan att sy ihop flera system.
- Efterlevnad kräver geografisk placering (dataresidens) men du vill ändå ha en logisk databas.
Anti-triggers: när det oftast inte är rätt
Distribuerade system ökar komplexitet och kostnader. Var försiktig om:
- Ditt team är litet och inte har tid att lära sig nya felscenar och driftsmönster.
- Trafiken är låg eller sporadisk och du sannolikt inte kommer att växa ur en single-region-databas snart.
- Du har mycket snäva latensbudgetar för enkla nyckelskrivningar och inte kan tolerera koordineringsöverhead från stark konsistens.
- Din workload är analys-tung (stora skanningar, komplexa rapporter). Du kan ofta tjäna på att separera OLTP från analytics.
Snabbt beslutschecklista
Om du kan svara ”ja” på två eller fler, är det troligt värt att utvärdera distributed SQL:
- Behöver du multi-region användare med konsekvent data?
- Behöver du automatisk failover över zoner/regioner?
- Har skalning blivit en återkommande kris?
- Skulle sharding lägga mer ingenjörsarbete än vad databasen gör åt dig?
- Behöver du tillämpa dataresidens med en enda operativ modell?
Konsistens, tillgänglighet och latens: kärntrade-offs
Distributed SQL låter som ”få allt på en gång”, men verkliga system tvingar fram val—särskilt när regioner inte kan prata pålitligt med varandra.
CAP, för produktbeslut
Se en nätverkspartition som ”länken mellan regioner är ostabil eller nere”. I det ögonblicket kan databasen prioritera:
- Konsistens: alla får samma, uppdaterade svar (eller operationen misslyckas).
- Tillgänglighet: appen fortsätter acceptera läsningar/skrivningar i varje region (även om svaren kan skilja sig).
Distributed SQL-system byggs ofta för att föredra konsistens för transaktioner. Det är vad team ofta vill ha—tills en partition gör att vissa operationer måste vänta eller misslyckas.
Stark konsistens (och varför pengar och lager bryr sig)
Stark konsistens betyder att när en transaktion committas kommer efterföljande läsningar att returnera det committade värdet—inga ”det fungerade i en region men inte i en annan”. Detta är avgörande för:
- Betalningar och saldon (undviker dubbeldebitering eller felaktiga totalsummor)
- Inventarie/reservationer (förhindrar översäljning av sista artikeln)
Om ditt produktlöfte är ”när vi bekräftar det, så är det verkligt”, är stark konsistens en funktion, inte en lyx.
Read-your-writes och isolation i riktiga appar
Två praktiska beteenden spelar roll:
- Read-your-writes: efter att en användare uppdaterar sin profil (eller gör en order) måste nästa skärm visa det nya tillståndet, inte en äldre replika.
- Transaktionsisolation: definierar hur samtidiga åtgärder samverkar. Med starkare isolation undviker du subtila buggar som att två kunder framgångsrikt bokar samma plats.
Latenskostnaden för tvärregionalt konsensus
Stark konsistens över regioner kräver vanligtvis konsensus (flera repliker måste vara överens före commit). Om repliker ligger på olika kontinenter blir ljushastigheten en begränsning: varje tvärregional skrivning kan lägga till tiotals till hundratals millisekunder.
Tradeoffen är enkel: mer geografisk säkerhet och korrekthet innebär ofta högre skrivlatens om du inte noggrant väljer var data bor och var transaktioner tillåts committa.
Spanner vs CockroachDB vs YugabyteDB: en praktisk översikt
Google Spanner är en distribuerad SQL-databas som främst erbjuds som en managed service på Google Cloud. Den är designad för multi-region-deployments där du vill ha en logisk databas med data replikerat över noder och regioner. Spanner stöder två SQL-dialekter—GoogleSQL (dess native-dialekt) och en PostgreSQL-kompatibel dialekt—så portabilitet varierar beroende på vilket du väljer och vilka funktioner din app förlitar sig på.
CockroachDB är en distribuerad SQL-databas som vill kännas bekant för team vana vid PostgreSQL. Den använder PostgreSQL-wire-protokollet och stöder en stor del av PostgreSQL-stil SQL, men är inte en byte-för-byte-ersättning för Postgres (vissa extensioner och kantfall skiljer sig). Du kan köra den som en managed service (CockroachDB Cloud) eller self-hosta i din egen infrastruktur.
YugabyteDB är en distribuerad databas med ett PostgreSQL-kompatibelt SQL-API (YSQL) och ett ytterligare Cassandra-kompatibelt API (YCQL). Liksom CockroachDB utvärderas den ofta av team som vill ha Postgres-lik utvecklingsergonomi samtidigt som de skalar över noder och regioner. Den finns både self-hosted och som managed offering (YugabyteDB Managed), med vanliga deployment-mönster från single-region HA till multi-region-setup.
Managed vs self-hosted: vad ändras
Managed-tjänster minskar oftast driftarbete (uppgraderingar, backups, monitoring-integreringar), medan self-hosting ger mer kontroll över nätverk, instanstyper och var data faktiskt körs. Spanner konsumeras oftast som managed på GCP; CockroachDB och YugabyteDB ses ofta i både managed och self-hosted modeller, inklusive multi-cloud och on-prem.
SQL-kompatibilitet i praktiken
Alla tre talar ”SQL”, men daglig kompatibilitet beror på dialektval (Spanner), Postgres-funktionsomfång (CockroachDB/YugabyteDB) och om din app förlitar sig på specifika Postgres-extensioner, funktioner eller transaktionssemantik.
Planering här lönar sig: testa dina queries, migrationer och ORM-beteenden tidigt istället för att anta drop-in-ekvivalens.
Use Case: Global SaaS med regionala användare
Öva failover tidigt
Sätt upp en testmiljö och kör felövningar mot realistisk trafik.
Ett klassiskt match för distributed SQL är en B2B SaaS-produkt med kunder i Nordamerika, Europa och APAC—tänk supportverktyg, HR-plattformar, analysdashboards eller marknadsplatser.
Kravet är enkelt: användarna vill ha ”lokal app”-respons, medan företaget vill ha en logisk databas som alltid är tillgänglig.
Dataresidens och per-tenant-placering
Många SaaS-team hamnar i en blandning av krav:
- EU-kunder förväntar sig att deras data stannar i EU (GDPR, kontraktsåtaganden).
- Vissa kunder kräver lagring i landet (t.ex. Tyskland, Australien, Singapore).
- Andra bryr sig inte men vill ändå låg latens.
Distributed SQL kan modellera detta tydligt med per-tenant-locality: placera varje tenants primära data i en specifik region (eller uppsättning regioner) samtidigt som du behåller schema och query-modell konsekvent över hela systemet. Det låter dig undvika ”en databas per region”-explosionen samtidigt som du uppfyller residenskraven.
Minimera latens: regionala läsningar och skrivplacering
För att hålla appen snabb strävar du oftast efter:
- Regionala läsningar: servera läsintensiva queries från repliker nära användaren.
- Skrivplacering: placera write-ledaren (eller primära repliker) i regionen där tenantens skrivningar oftast kommer från.
Detta är viktigt eftersom tvärregionala rundresor dominerar användarupplevd latens. Även med stark konsistens säkerställer god lokalitetsdesign att de flesta förfrågningar inte betalar interkontinental nätverkskostnad.
Operativa realiteter
De tekniska vinsterna spelar bara roll om driften förblir hanterbar. För global SaaS planera för:
- Online schemaändringar som inte låser tabeller över regioner.
- Tenant-migrationer (flytta en tenant från en region till en annan med minimal nedtid).
- Övervakning och larm för replikeringslagg, hotspots, långsamma queries och regionsspecifika incidenter.
Gör detta väl så får du en enda produktupplevelse som fortfarande känns lokal—utan att splittra ditt ingenjörsteam i ”EU-stack” och ”APAC-stack”.
Use Case: Finansiella arbetsflöden och ledger
Finansiella system är där “eventually consistent” kan bli verkliga pengar förlorade. Om en kund lägger en order, en betalning auktoriseras och ett saldo uppdateras måste dessa steg hålla ihop i en gemensam sanning—omedelbart.
Stark konsistens är viktig eftersom den förhindrar att två olika regioner (eller två olika tjänster) var för sig tar en ”rimlig” beslut som leder till ett felaktigt ledger-tillstånd.
Varför stark konsistens är icke-förhandlingsbar
I ett typiskt arbetsflöde—skapa order → reservera medel → fånga betalning → uppdatera saldo/ledger—vill du garantier som:
- En order kan inte markeras som ”betald” om capture inte skedde.
- Ett saldo kan inte gå negativt eftersom två transaktioner tävlade.
- En återbetalning kan inte appliceras två gånger för att två arbetare retried samma jobb.
Distributed SQL passar här eftersom det ger ACID-transaktioner och constraints över noder (och ofta över regioner), så dina ledger-invarianter håller även vid fel.
Idempotens och ”ingen dubbeldebitering”-mönster
De flesta betalningsintegrationer är retry-tunga: timeouts, webhook-retries och jobbreprocessing är normala. Databasen bör hjälpa dig göra retries säkra.
Ett praktiskt tillvägagångssätt är att para applikationsnivå idempotency-nycklar med databas-enforced unikhet:
- Spara en
idempotency_key per kund/betalningsförsök.
- Lägg en unik constraint på
(account_id, idempotency_key).
- Wrappa “skapa betalningspost + applicera ledger-ändringar” i en enda transaktion.
På så sätt blir andra försöket en harmlös no-op istället för en dubbeldebitering.
Hantera spikar utan att bryta korrektheten
Försäljningshändelser och löneutbetalningar kan skapa plötsliga skrivspikar (auktorisationer, captures, överföringar). Med distributed SQL kan du skala genom att lägga till noder för ökad skrivkapacitet samtidigt som du behåller samma konsistensmodell.
Nyckeln är att planera för hot keys (t.ex. en handlarkonto som tar emot all trafik) och använda schema-mönster som sprider belastningen.
Efterlevnad, revision och retention
Finansiella arbetsflöden kräver ofta oföränderliga audit trails, spårbarhet (vem/vad/när) och förutsägbara retentionpolicys. Anta att du behöver: append-only ledger-entries, tidsstämplade poster, kontrollerad åtkomst och retention/arkiveringsregler som inte kompromissar med auditbarhet.
Use Case: Inventarie, bokning och reservationer
Behåll kontroll över din stack
Behåll kontroll över din stack så att du kan fortsätta i ditt repo när prototypen är klar.
Inventarie och reservationer verkar enkla tills flera regioner serverar samma knappa resurs: sista konsertplatsen, en limiterad drop-produkt eller ett hotellrum för ett visst datum.
Det svåra är inte att läsa tillgänglighet—det är att förhindra att två personer framgångsrikt reserverar samma artikel samtidigt.
Var konflikter kommer från
I en multi-region-setup utan stark konsistens kan varje region tillfälligt tro att lager finns baserat på något föråldrad data. Om två användare checkar ut i olika regioner under det fönstret kan båda transaktionerna accepteras lokalt och senare kollidera vid rekonsiliering.
Så uppstår tvärregional översäljning: inte eftersom systemet är ”fel”, utan eftersom det tillät divergerande sanningar en stund.
Distributed SQL väljs ofta här eftersom det kan säkerställa ett enda auktoritativt utfall för skrivintensiva allocationer—så ”sista platsen” verkligen bara allokeras en gång, även om förfrågningarna kommer från olika kontinenter.
Konkreta exempel
- Sätebokning: Två användare klickar på samma sätesruta. Med stark konsistens committar bara en transaktion; den andra misslyckas omedelbart och UI kan be användaren uppdatera.
- Limiterade drops: 500 artiklar släpps och tusentals försöker checkouta. Du vill ha atomisk decrement-and-allocate, inte ”best effort” med efterföljande återbetalningar.
- Hotellbokningar: Inventariet är inte bara rummet utan rum-natten. Dubbelbokning av ett datumintervall är kostsamt och svårt att rätta till.
Vanliga mönster som passar med Distributed SQL
Hold + confirm: Placera ett temporärt hold (en reservation) i en transaktion, bekräfta betalning i ett andra steg.
Expirationer: Holds bör löpa ut automatiskt (t.ex. efter 10 minuter) för att undvika att inventarie fastnar om användaren lämnar kassan.
Transactionell outbox: När en reservation bekräftas, skriv en "event to send"-rad i samma transaktion och leverera den asynkront till e-post, fulfillment, analys eller ett meddelandebuss—utan risken för "bokad men ingen bekräftelse skickad".
Poängen: om din verksamhet inte tolererar dubbelallokation över regioner blir starka transaktionella garantier en produktfunktion, inte bara teknik.
Use Case: Hög tillgänglighet och katastrofåterställning
Hög tillgänglighet (HA) är en bra match för Distributed SQL när driftstopp är dyrt, oförutsägbara avbrott är oacceptabla och du vill att underhåll ska vara tråkigt.
Målet är inte ”aldrig fel”—det är att möta tydliga SLOs (t.ex. 99.9% eller 99.99% uppetid) även när noder dör, zoner slocknar eller du utför uppgraderingar.
”Always-on” i praktiken: SLOs, underhåll, fel
Börja med att översätta ”always-on” till mätbara förväntningar: maximal månatlig nertid, recovery time objective (RTO) och recovery point objective (RPO).
Distributed SQL-system kan fortsätta serva läsningar/skrivningar genom många vanliga fel, men bara om din topologi matchar dina SLOs och din app hanterar transient-fel (retries, idempotens) snyggt.
Planerat underhåll spelar också roll. Rolling upgrades och nodbyten är enklare när databasen kan flytta ledarskap/repliker bort från påverkade noder utan att ta hela klustret offline.
Multi-zone vs multi-region redundans
Multi-zone-deployment skyddar mot en enskild AZ/zone-incident och många hårdvarufel, ofta med lägre latens och kostnad. De räcker ofta om din efterlevnad och användarbas huvudsakligen ligger i en region.
Multi-region-deployment skyddar mot ett helt regionavbrott och stödjer regional failover. Tradeoffen är högre skrivlatens för starkt konsistenta transaktioner som spänner över regioner, plus mer komplex kapacitetsplanering.
Failover-förväntningar (och testa med game days)
Räkna inte med att failover är omedelbar eller osynlig. Definiera vad “failover” betyder för din tjänst: korta felspikar? read-only-perioder? Några sekunders förhöjd latens?
Kör "game days" för att bevisa det:
- Döda en nod, sedan en zon; verifiera SLO-dashboards och klienters felbudget.
- Simulera nätverkspartitioner och verifiera ledar-/replika-beteende.
- Öva region-evakuering och mät verklig RTO.
Replikering är inte backup
Även med synkron replikering, behåll backups och repetera återställningar. Backups skyddar mot operatörsmisstag (dåliga migrationer, oavsiktliga raderingar), applikationsbuggar och korruption som annars skulle replikeras.
Validera point-in-time-återställning (om stöd finns), återställningshastighet och förmågan att återställa till en ren miljö utan att röra produktion.
Use Case: Dataresidens och compliance-drivna arkitekturer
Krav på dataresidens uppstår när lagar, kontrakt eller interna regler säger att vissa poster måste lagras (och ibland behandlas) inom ett visst land eller region.
Det kan gälla personuppgifter, vårdinformation, betalningsdata, myndighetsarbetslaster eller "kundägd" data där avtalet dikterar var deras data får ligga.
Distributed SQL övervägs ofta här eftersom det kan behålla en logisk databas samtidigt som det fysiskt placerar data i olika regioner—utan att tvinga dig att köra en helt separat applikationsstack per geografi.
Varför residensregler förändrar databasedesignen
Om en regulator eller kund kräver "data stannar i region" räcker det inte med närliggande repliker. Du kan behöva garantera att:
- Den primära kopian (eller alla kopior) av viss data lagras endast i godkända regioner
- Backups och snapshots följer samma regler
- Operatörer och tjänster utanför regionen inte kan nå rådata
Det tvingar team att göra plats till en förstklassig egenskap, inte en eftertanke.
Per-kund-placering och åtkomstkontroller (på hög nivå)
Ett vanligt mönster i SaaS är per-tenant-placering. Exempelvis pins EU-kunders rader/partitioner till EU-regioner, US-kunder till US-regioner.
I stort kombinera du:
- Regler för dataplacering (var en tenants data får bo)
- Identitets- och åtkomstkontroller (vilka tjänster och personer får läsa)
- Kryptering och nyckelhantering (ibland regionbundna nycklar)
Målet är att göra det svårt att oavsiktligt bryta residens via operativ åtkomst, backup-återställningar eller cross-region replikering.
Juridiska krav varierar—ta in juridisk rådgivning
Residens- och compliance-krav skiljer sig mycket mellan länder, branscher och kontrakt. De förändras också över tid.
Behandla databastopologi som en del av ert compliance-program och validera antaganden med kvalificerad juridisk rådgivning (och, när relevant, era revisorer).
Hur multi-region-topologi påverkar rapportering och analytics
Residensvänliga topologier kan komplicera "globala vyer". Om kunddata avsiktligt hålls i separata regioner kan analytics och rapportering:
- Kräva regionala rapporteringspipelines (compute körs där datan bor)
- Använda aggregerade export (endast tillåtna mått lämnar regionen)
- Acceptera högre latens för tvärregionala dashboards, eftersom globala queries kan spänna över regioner eller förlita sig på replikerade/deriverade dataset
I praktiken separerar många team operativa arbetslaster (starkt konsistenta, residensmedvetna) från analytics (regionskoppade warehouses eller noggrant styrda aggregerade dataset) för att hålla compliance hanterbar utan att sakta ner produktrapportering.
Kostnads- och prestandaplanering för Distributed SQL
Designa säkrare retries
Skapa ett idempotent betal- eller provisionsflöde med constraints och transaktioner på några minuter.
Distributed SQL kan rädda dig från smärtsamma avbrott och regionala begränsningar, men det sparar sällan pengar automatiskt. Planering i förväg hjälper dig undvika att betala för försäkring du inte behöver.
Huvuddrivare för kostnad
De flesta budgetar delas upp i fyra delar:
- Noder (compute): Du betalar för att hålla flera repliker online—ofta 3+ per region—plus extra kapacitet för failover. Multi-region-upplägg kräver vanligtvis mer headroom än en single-region Postgres.
- Lagring: Repliker multiplicerar datamängden. En 2 TB dataset med tre repliker blir ~6 TB före backups, index och overhead.
- Inter-region trafik: Cross-region replikering, läsningar och klienttrafik kan bli en betydande post. Det är ofta den första överraskningen när man går active-active.
- Operativ tid: Även managed erbjudanden kräver arbete: schema- och query-tuning, incidenthantering, kapacitetsplanering, uppgraderingstester och styrning (särskilt kring residens/compliance).
Uppskatta latenspåverkan på verkliga användarresor
Distributed SQL-system lägger till koordination—särskilt för starkt konsistenta skrivningar som måste bekräftas av ett kvorum.
Ett praktiskt sätt att uppskatta påverkan:
- Välj 2–3 nyckelresor (checkout, bokning, "spara ändringar").
- Räkna hur många skrivtransaktioner och read-after-write-steg som sker i den kritiska vägen.
- För varje steg, anta en tvärregional rondresa där koordination krävs. Om cross-region RTT är 80–120 ms kan två sekventiella skrivsteg lägga till 160–240 ms före apptiden.
Det betyder inte "gör inte det", men det betyder att du bör designa resor för att minska sekventiella skrivningar (batchning, idempotenta retries, färre pratiga transaktioner).
Komplexitet vs enklare alternativ
Om dina användare mestadels finns i en region är en single-region Postgres med läs-repliker, bra backups och en testad failover-plan ofta billigare, enklare och snabb.
Distributed SQL tjänar sin kostnad när du verkligen behöver multi-region-skrivningar, strikta RPO/RTO eller residensmedveten placering.
Enkel ROI-ram
Behandla utgiften som en tradeoff:
- Risk undviks: färre intäktskritiskska avbrott, mindre dataförlustrisk, färre globala incidenthelger.
- Intäkt skyddas: högre konvertering från lägre latens för regionala användare, starkare enterprise-position (SLA, compliance).
- Kostnad: bas-kluster + replikeringsoverhead + trafik + ingenjörstid.
Om undvikt förlust (nertid + churn + compliance-risk) är större än pågående premie är multi-region-designen motiverad. Om inte, börja enklare—och håll en väg för att utveckla senare.
Adoptions-checklista och nästa steg
Att anta distributed SQL handlar mindre om att lyfta och flytta en databas och mer om att bevisa att din specifika workload beter sig väl när data och konsensus sprids över noder (och eventuellt regioner). En lättviktig plan hjälper dig undvika överraskningar.
Ett fokuserat proof-of-concept (PoC)
Välj en arbetslasta som representerar verklig smärta: t.ex. checkout/booking, konto-provisionering eller ledger-postering.
Definiera framgångsmått i förväg:
- Korrekthet: inga dubbelbokningar, inga förlorade uppdateringar, förutsägbar transaktionsbeteende
- Latens SLOs: p50/p95 för topp 3 queries (inkl. cross-region mål om relevant)
- Genomströmning: uthållig QPS vid peak + säkerhetsmarginal (ofta 2–3×)
- Motståndskraft: beteende vid nodfel och (om relevant) regionförlust
- Driftinsats: tid att upptäcka, diagnostisera och återhämta sig från simulerade incidenter
Om du vill gå snabbare i PoC-stadiet kan det hjälpa att bygga en liten "realistisk" appyta (API + UI) snarare än bara syntetiska benchmarker. Till exempel använder team ibland Koder.ai för att snabbt snurra upp en React + Go + PostgreSQL-bas via chat, och byter sedan databasen till CockroachDB/YugabyteDB (eller kopplar mot Spanner) för att testa transaktionsmönster, retries och felbeteenden end-to-end. Poängen är inte startstacket—utan att förkorta slingan från "idé" till "mätbar arbetslasta".
Designchecklista (det som biter senare)
- Schema: välj primära nycklar som sprider skrivningar; undvik sekventiella "heta" nycklar
- Index: behåll bara det du behöver; förstå skrivamplifiering från sekundära index
- Partitionering/placering: bestäm partition keys (och geo/zone-placering) baserat på accessmönster
- Hot spots: identifiera "celebrity rows" (globala räknare, single-tenant-tabeller) och redesigna tidigt
- Migrationer: planera online schemaändringar och backfills; testa rollback-vägar
Operativa basics att ha från dag ett
Övervakning och runbooks är lika viktiga som SQL:
- Dashboards för latens, retries, contention, replikerings/consensus-hälsa, disk och compactions
- Incident-runbooks: långsamma queries, nodomstarter, felande repliker, ojämn belastning
- Loadtesting som efterliknar produktion (read/write-mix, spikar, långa transaktioner)
- Backups + återställningsövningar (inklusive point-in-time recovery om stöds)
Nästa steg
Börja med en PoC-sprint, budgetera tid för en production readiness-review och en gradvis cutover (dual writes eller shadow reads där möjligt).
Om du behöver hjälp att skatta kostnader eller nivåer, se /pricing. För mer praktiska genomgångar och migrationsmönster, läs /blog.
Om du dokumenterar dina PoC-resultat, arkitekturval eller migrationslärdomar—dela dem gärna internt (och offentligt om möjligt): plattformar som Koder.ai erbjuder ibland sätt att tjäna krediter för att skapa utbildningsinnehåll eller hänvisa andra builders, vilket kan kompensera experimentkostnader medan du utvärderar alternativ.