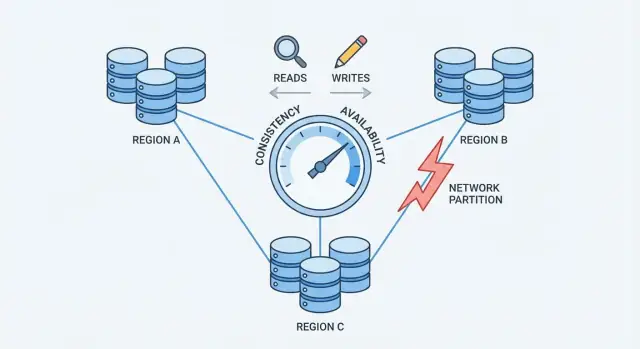
Vad konsistens och tillgänglighet betyder i praktiken
När en databas är spridd över flera maskiner (repliker) får du snabbhet och motståndskraft—men du inför också perioder där maskinerna inte är helt överens eller inte kan prata pålitligt med varandra.
Konsistens (i vardaglig bemärkelse)
Konsistens betyder: efter en lyckad skrivning läser alla samma värde. Om du uppdaterar din profil-e-post, så returnerar nästa läsning—oavsett vilken replika som svarar—den nya e-posten.
I praktiken kan system som prioriterar konsistens fördröja eller avvisa vissa förfrågningar under fel för att undvika motsägande svar.
Tillgänglighet (i vardaglig bemärkelse)
Tillgänglighet betyder: systemet svarar på varje förfrågan, även om vissa servrar är nere eller frånkopplade. Du kanske inte får den senaste datan, men du får ett svar.
I praktiken kan system som prioriterar tillgänglighet acceptera skrivningar och svara på läsningar även när repliker inte är överens, och sedan förena skillnader i efterhand.
Vad avvägningen innebär för riktiga applikationer
En avvägning betyder att du inte kan maximera båda målen samtidigt i varje felscenario. Om repliker inte kan koordinera måste databasen antingen:
- Vänta/misslyckas med några förfrågningar för att skydda en enda, överenskommen sanning (föredra konsistens), eller
- Fortsätta svara användare även om risken för föråldrade eller motsägande data ökar (föredra tillgänglighet)
Ett enkelt exempel: kundvagn vs banköverföring
- Kundvagn: Om antalet varor i din kundvagn tillfälligt är fel på en annan enhet är det irriterande men oftast acceptabelt. Många team föredrar högre tillgänglighet och reparerar senare.
- Banköverföring: Om du flyttar 500 $ och saldot tillfälligt visar två olika värden är det allvarligt. Här är starkare konsistens ofta värd de tillfälliga “försök igen”-felen.
Ingen universell bästa lösning
Rätt balans beror på vilka fel du kan tolerera: ett kort avbrott eller en kort period med felaktig/gammal data. De flesta verkliga system väljer en mellanväg—och gör avvägningen uttalad.
Varför distribution ändrar reglerna
En databas är “distribuerad” när den lagrar och serverar data från flera maskiner (noder) som koordinerar över ett nätverk. För en applikation kan det fortfarande se ut som en enda databas—men under huven kan förfrågningar hanteras av olika noder på olika platser.
Replikering: varför team lägger till noder
De flesta distribuerade databaser replikerar data: samma post lagras på flera noder. Team gör detta för att:
- hålla tjänsten igång om en maskin dör
- minska latensen genom att serva användare från en närliggande nod
- skala läsningar (och ibland skrivningar) över mer hårdvara
Replikering är kraftfullt, men det väcker omedelbart en fråga: om två noder båda har en kopia av samma data, hur garanterar du att de alltid är överens?
Partiella fel är norm, inte undantag
På en enda server är “nere” oftast uppenbart: maskinen är igång eller den är det inte. I ett distribuerat system är fel ofta partiella. En nod kan vara levande men långsam. En nätverkslänk kan tappa paket. Ett helt rack kan förlora anslutning medan resten av klustret fortsätter köra.
Detta spelar roll eftersom noder inte kan veta omedelbart om en annan nod verkligen är nere, tillfälligt otillgänglig eller bara försenad. Medan de väntar måste de bestämma vad de gör med inkommande läsningar och skrivningar.
Garantier ändras när kommunikation inte är garanterad
Med en server finns det en källa till sanning: varje läsning ser den senaste lyckade skrivningen.
Med flera noder beror “senaste” på koordinering. Om en skrivning lyckas på nod A men nod B inte kan nås, bör databasen:
- blockera skrivningen tills B bekräftar den (skydda konsistensen), eller
- acceptera skrivningen ändå (skydda tillgängligheten)?
Den spänningen—gjord verklig av ofullkomliga nätverk—är varför distribution ändrar reglerna.
Nätverkspartitioner: kärnproblemet
En nätverkspartition är ett avbrott i kommunikationen mellan noder som ska fungera som en databas. Noderna kan fortfarande köras och vara friska, men de kan inte pålitligt utbyta meddelanden—på grund av en trasig switch, en överbelastad länk, en felkonfigurerad routing, en felaktig brandväggsregel eller till och med en högljudd granne i ett moln.
Varför partitioner är oundvikliga i stor skala
När ett system sprids över flera maskiner (ofta över rack, zoner eller regioner) kontrollerar du inte längre varje hopp mellan dem. Nätverk tappar paket, introducerar fördröjningar och kan ibland delas i “öar”. I liten skala är dessa händelser ovanliga; i stor skala blir de rutin. Även en kort störning räcker, eftersom databaser behöver konstant koordinering för att vara överens om vad som hänt.
Hur partitioner skapar motsägande “senaste” data
Under en partition fortsätter båda sidor att ta emot förfrågningar. Om användare kan skriva på båda sidor kan varje sida acceptera uppdateringar som den andra sidan inte ser.
Exempel: Nod A uppdaterar en användares adress till “New Street.” Samtidigt uppdaterar Nod B den till “Old Street Apt 2.” Var sida tror att dess skrivning är den senaste—eftersom det inte finns något sätt att jämföra i realtid.
Användarsynliga symptom
Partitioner syns inte som snygga felmeddelanden; de syns som förvirrande beteenden:
- Timeouts: databasen väntar på att en annan nod ska bekräfta en skrivning eller läsning.
- Föråldrade läsningar: du uppdaterar och ser fortfarande gammal data eftersom du träffade en replika som missade uppdateringar.
- Split-brain-beteende: olika användare ser olika “sanningar” beroende på vilken sida de når.
Detta är tryckpunkten som tvingar fram ett val: när nätverket inte kan garantera kommunikation måste en distribuerad databas bestämma om den prioriterar konsistens eller tillgänglighet.
CAP-teoremet utan jargongen
CAP är ett kompakt sätt att beskriva vad som händer när en databas är spridd över flera maskiner.
De tre termerna (enkelt språk)
- Konsistens (C): efter att du skrivit ett värde returnerar varje senare läsning samma värde.
- Tillgänglighet (A): varje förfrågan får ett icke-fel-svar, även om vissa servrar har problem.
- Partionstolerans (P): systemet fortsätter fungera även om nätverket delas och servrar inte kan prata pålitligt.
Huvudpoängen
När det inte finns någon partition kan många system se både konsistenta och tillgängliga ut.
När det finns en partition måste du välja vad du prioriterar:
- Välj konsistens: avvisa eller fördröj vissa förfrågningar tills servrar kan bli överens.
- Välj tillgänglighet: acceptera förfrågningar på varje sida av delningen, även om svaren tillfälligt kan skilja sig.
Ett enkelt tidsschema att föreställa sig
- 10:00 Klient skriver
balance = 100 till Server A.
- 10:01 Nätverkspartition: Server A når inte Server B.
- 10:02 Klient läser från Server B.
- Om du prioriterar konsistens, måste Server B vägra eller vänta.
- Om du prioriterar tillgänglighet, svarar Server B, men det kan fortfarande visa
balance = 80.
Vanligt missförstånd
CAP betyder inte permanent “välj bara två”. Det betyder under en partition kan du inte garantera både konsistens och tillgänglighet samtidigt. Utanför partitioner kan du ofta komma mycket nära båda—tills nätverket beter sig oväntat.
Att välja konsistens: vad du vinner och vad du förlorar
Att välja konsistens innebär att databasen prioriterar “alla ser samma sanning” framför “svara alltid”. I praktiken pekar det ofta mot stark konsistens, ofta beskrivet som lineariserbar beteende: när en skrivning är bekräftad returnerar varje senare läsning (från var som helst) det värdet, som om det fanns en enda uppdaterad kopia.
Vad som händer under en partition
När nätverket splittras och repliker inte kan prata, kan ett system med stark konsistens inte säkert acceptera oberoende uppdateringar på båda sidor. För att skydda korrektheten brukar det:
- Blockera förfrågningar medan det väntar på koordinering, eller
- Avvisa förfrågningar (returnera fel/timeouts) om det inte når de nödvändiga replikerna/ledaren.
Ur användarens perspektiv kan detta se ut som ett avbrott även om vissa maskiner fortfarande kör.
Vad du vinner
Huvudfördelen är enklare resonemang. Applikationskod kan bete sig som om den pratar med en enda databas, inte flera repliker som kan vara oense. Det minskar “konstiga stunder” såsom:
- Att läsa äldre data direkt efter en lyckad uppdatering
- Att se två olika värden för samma post beroende på vilken replika du träffar
- Att tappa invarians (t.ex. översälja lager) på grund av samtidiga, motsägande skrivningar
Du får också renare mentala modeller för revision, fakturering och allt som måste vara korrekt första gången.
Vad du förlorar
Konsistens har verkliga kostnader:
- Högre latens: många operationer måste vänta på koordinering (ofta över maskiner eller regioner).
- Fler fel under fel: partitioner, långsamma repliker eller ledarproblem kan bli timeouts eller “försök igen senare”.
Om din produkt inte tål misslyckade förfrågningar under partiella avbrott kan stark konsistens kännas dyrt—även när det är rätt val för korrektheten.
Att välja tillgänglighet: vad du vinner och vad du förlorar
Designa säkra återförsök snabbt
Skapa en idempotent skriv-endpoint och ett klientflöde säkert för återförsök utan att bygga om stacken.
Att välja tillgänglighet innebär att du optimerar för ett enkelt löfte: systemet svarar, även när delar av infrastrukturen är ohälsosam. I praktiken är “hög tillgänglighet” inte “inga fel någonsin”—det betyder att de flesta förfrågningar fortfarande får ett svar vid nodfel, överbelastade repliker eller brutna nätlänkar.
Vad som händer under en nätverkspartition
När nätverket splittras kan repliker inte pålitligt prata med varandra. En tillgänglighetsfokuserad databas håller vanligtvis att serva trafik från den nåbara sidan:
- Läsningar besvaras lokalt från den data repliken för närvarande har.
- Skrivningar accepteras lokalt och köas/replikeras senare när anslutningen återvänder.
Det håller applikationer igång, men innebär också att olika repliker tillfälligt kan acceptera olika sanningar.
Vad du vinner
Du får bättre drifttid: användare kan fortfarande bläddra, lägga saker i kundvagnen, posta kommentarer eller logga händelser även om en region är isolerad.
Du får också en smidigare användarupplevelse under stress. Istället för timeouts kan din app fortsätta med rimligt beteende (“din uppdatering är sparad”) och synka senare. För många konsument- och analysarbetsflöden är den avvägningen värd det.
Vad du förlorar
Priset är att databasen kan returnera föråldrade läsningar. En användare kan uppdatera en profil på en replika och sedan omedelbart läsa från en annan replika och se det gamla värdet.
Du riskerar också skrivkonflikter. Två användare (eller samma användare på två platser) kan uppdatera samma post på olika sidor av en partition. När partitionen läker måste systemet rekonciliera skilda historiker. Beroende på regler kan en skrivning “vinna”, fält kan slås ihop eller konflikten kan kräva applikationslogik.
Design för tillgänglighet handlar om att acceptera temporära oenigheter så produkten fortsätter svara—och sedan investera i hur du upptäcker och reparerar oenigheterna senare.
Quorum och röstning: en mellangata
Quorum är en praktisk “röstnings”-teknik som många replikerade databaser använder för att balansera konsistens och tillgänglighet. Istället för att lita på en enda replika frågar systemet tillräckligt många repliker för att få enighet.
Idén (N, R, W)
Du ser ofta quorums beskrivet med tre siffror:
- N: hur många repliker som finns för ett dataobjekt
- W: hur många repliker som måste bekräfta en skrivning innan den anses lyckad
- R: hur många repliker som konsulteras för en läsning
En vanlig tumregel är: om R + W > N, så överlappar varje läsning med den senaste lyckade skrivningen på åtminstone en replika, vilket minskar sannolikheten för att läsa föråldrad data.
Intuitiva exempel
Om du har N=3 repliker:
- Enkel-replika (R=1, W=1): Snabbt och mycket tillgängligt, men du kan lätt läsa en föråldrad replika.
- Majoritetsröstning (R=2, W=2): En skrivning måste nå 2 repliker och en läsning konsulterar 2 repliker. Det ökar chansen att du ser det senaste värdet eftersom läs- och skrivmängderna överlappar.
Vissa system går längre med W=3 (alla repliker) för starkare konsistens, men det kan orsaka fler skrivfel när någon replika är långsam eller nere.
Vad quorums gör under partitioner
Quorums tar inte bort partitionproblem—de definierar vem som får göra framsteg. Om nätverket splittras 2–1 kan sidan med 2 repliker fortfarande uppfylla R=2 och W=2, medan den isolerade enkla repliken inte kan det. Det minskar konflikter, men betyder att vissa klienter kommer se fel eller timeouts.
Avvägningarna
Quorums innebär oftast högre latens (fler noder att kontakta), högre kostnad (mer trafik mellan noder) och mer nyanserat felbeteende (timeouts kan se ut som otillgänglighet). Fördelen är en ställbar mellanväg: du kan justera R och W mot färskare läsningar eller högre skrivframgång beroende på vad som är viktigast.
Eventuell konsistens och vanliga anomalier
Eventuell konsistens betyder att repliker får vara temporärt osynkade, så länge de konvergerar till samma värde senare.
En konkret analogi
Tänk på en kedja kaféer som uppdaterar en delad “slutsåld”-skylt för ett bakverk. En butik markerar det som slutsålt, men uppdateringen når andra butiker några minuter senare. Under det fönstret kan en annan butik fortfarande visa “finns” och sälja den sista. Ingen system är “trasigt”—uppdateringarna kommer bara efter.
Vanliga anomalier du märker
När data fortfarande sprids kan klienter se beteenden som känns överraskande:
- Föråldrade läsningar: du läser gammal data från en replika som inte fått senaste skrivningen.
- Read-your-writes-gap: du skriver en uppdatering och läser direkt från en annan replika (eller efter failover) och ser inte din egen ändring.
- Uppdateringar i fel ordning: två uppdateringar anländer i olika ordning på olika repliker och ger tillfälligt inkonsistenta vyer.
Tekniker som hjälper repliker konvergera
Eventuellt konsistenta system lägger ofta till bakgrunds-mekanismer för att minska inkonsistensfönstren:
- Read repair: om en läsning upptäcker att repliker skiljer sig uppdaterar systemet de gamla replikerna i bakgrunden.
- Hinted handoff: om en replika är nere lagrar en annan nod tillfälligt “hints” av skrivningar att skicka när den kommer tillbaka.
- Anti-entropy (sync): periodisk reconciliering (ofta via merkle-träd eller checksummor) för att hitta och rätta avvikelser.
När eventual konsistens fungerar bra
Det passar när tillgänglighet är viktigare än att vara helt aktuell: aktivitetsflöden, visningsräknare, rekommendationer, cachade profiler, loggar/telemetri och annan icke-kritisk data där “rätt om en stund” är acceptabelt.
Konfliktlösning: hur divergerande skrivningar förenas
Testa läs- och skrivlägen
Starta en React-app och ett Go-API för att testa strikta skrivningar och avslappnade läsningar.
När en databas accepterar skrivningar på flera repliker kan den få konflikter: två (eller fler) uppdateringar av samma objekt som skett oberoende på olika repliker innan de hunnit synka.
Ett klassiskt exempel är en användare som uppdaterar sin leveransadress på en enhet samtidigt som hen ändrar telefonnumret på en annan. Om varje uppdatering hamnar på olika repliker under en tillfällig frånkoppling måste systemet avgöra vad den “sanna” posten är när replikerna utbyter data igen.
Last-write-wins (LWW): enkelt men riskfyllt
Många system börjar med last-write-wins: den uppdatering som har den senaste tidsstämpeln skriver över de andra.
Det är attraktivt eftersom det är enkelt att implementera och snabbt att beräkna. Nackdelen är att det kan tyst radera data. Om “nyast” vinner kan en äldre men viktig ändring försvinna—även om uppdateringarna berörde olika fält.
Det förutsätter också att tidsstämplarna är pålitliga. Klockskiftningar mellan maskiner (eller klienter) kan göra att fel uppdatering vinner.
Att bevara historik: versionsvektorer och liknande
Säkrare konfliktlösning kräver ofta spårning av kausal historia.
Konceptuellt fäster versionsvektorer (och enklare varianter) ett litet metadata till varje post som sammanfattar “vilken replika har sett vilka uppdateringar”. När repliker utbyter versioner kan databasen upptäcka om en version inkluderar en annan (ingen konflikt) eller om de har divergerat (konflikt som behöver lösas).
Vissa system använder logiska tidsstämplar (t.ex. Lamport-klockor) eller hybrid logiska klockor för att minska beroendet av väggklockan samtidigt som de ger en ordningshint.
Slå ihop istället för skriva över
När en konflikt upptäcks har du val:
- Appnivå-sammanslagningar: din applikation bestämmer hur fält ska kombineras, fråga användare eller behåll båda versionerna för granskning.
- CRDTs (Conflict-Free Replicated Data Types): datastrukturer designade för att automatiskt och deterministiskt slå ihop (bra för räknare, mängder, kollaborativ text osv.). De undviker ofta “vinnaren tar allt”-beteende och behåller hög tillgänglighet.
Det bästa tillvägagångssättet beror på vad “korrekt” betyder för din data—ibland är det acceptabelt att tappa en skrivning, och ibland är det ett kritiskt fel.
Hur du väljer för ditt användningsfall
Att välja konsistens/tillgänglighetsinriktning är inte en filosofisk debatt—det är ett produktbeslut. Börja med att fråga: vad kostar det att ha fel en stund, och vad kostar det att säga “försök igen senare”?
Karta affärsrisk till konsistensbehov
Vissa domäner behöver ett enda auktoritativt svar vid skrivtid eftersom “nästan rätt” fortfarande är fel:
- Pengar och fakturering: dubbeldebiteringar, övertrasseringar och återbetalningar kräver oftast stark konsistens.
- Identitet och behörigheter: inloggning, återställning av lösenord, åtkomstkontroll och rolländringar bör undvika split-brain.
- Lager och kapacitet: om översäljning är oacceptabelt (biljetter, begränsad lager), luta mot konsistens—eller bygg uttryckliga reservationer.
Om konsekvensen av en temporär missanpassning är låg eller reversibel kan du oftast luta mer mot tillgänglighet.
Bestäm hur mycket föråldrad data du tolererar
Många användarupplevelser fungerar bra med något gamla läsningar:
- Flöden och tidslinjer: ett inlägg som dyker upp några sekunder senare är ofta acceptabelt.
- Analys och dashboards: batchade eller fördröjda siffror är vanliga och förväntade.
- Cachar och sökindex: användare accepterar “inte uppdaterat än” om det är snabbt och stabilt.
Var tydlig med hur gammalt som är okej: sekunder, minuter eller timmar. Den tidsbudget som definieras styr dina replikerings- och quorumval.
Välj det felläge användarna hatar minst
När repliker inte kan bli överens slutar du oftast med ett av tre UX-utfall:
- Spinner / väntan (prioritera korrekthet, kan upplevas långsamt)
- Fel / återförsök (ärligt, men störande)
- Föråldrat resultat (smidigt, men ibland överraskande)
Välj det minst skadliga per funktion, inte globalt.
Snabbchecklista
Luta mot C (konsistens) om: felaktiga resultat skapar finansiell/juridisk risk, säkerhetsproblem eller irreversibla åtgärder.
Luta mot A (tillgänglighet) om: användare värderar snabb respons, föråldrad data är hanterbar och konflikter kan lösas säkert senare.
Om du är osäker, dela systemet: håll kritiska poster starkt konsistenta och låt avledda vyer (flöden, cachar, analys) optimera för tillgänglighet.
Designmönster för att minska smärta från avvägningen
Instrumentera för trade-offen
Lägg till latens-, fel- och föråldradhets-metrik i din app och iterera på trösklar.
Du behöver sällan välja en enda “konsistensinställning” för hela systemet. Många moderna distribuerade databaser låter dig välja konsistens per operation—och smarta applikationer utnyttjar det för att hålla användarupplevelsen smidig utan att låtsas att avvägningen inte finns.
Använd per-operation-konsistensnivåer
Behandla konsistens som en ratt du vrider beroende på vad användaren gör:
- Kritiska uppdateringar (betalningar, minskning av lager, lösenordsändringar): använd starkare konsistens (t.ex. quorum/lineariserbara skrivningar).
- Icke-kritiska läsningar (flöden, dashboards, “senast sedd”): tillåt svagare läsningar (lokal/en replika/eventuell) för snabbhet och motståndskraft.
Detta undviker att betala kostnaden för starkast konsistens överallt, samtidigt som de operationer som verkligen behöver skyddas får det.
Blanda starkt och svagt i ett flöde
Ett vanligt mönster är starkt för skrivningar, svagare för läsningar:
- Skriv med en strikt nivå så systemet har en auktoritativ post.
- Läs med en lösare nivå, och om du upptäcker något “knasigt” (saknad post, föråldrad räknare) uppdatera med en starkare läsning eller visa en “uppdateras” indikation.
I vissa fall fungerar motsatsen: snabba skrivningar (köade/eventuella) plus starka läsningar när du bekräftar ett resultat (“Lades min order?”).
Designa för återförsök: idempotens
När nätverk svajar gör klienter om försök. Gör återförsök säkra med idempotency-nycklar så att “skicka order” två gånger inte skapar två order. Spara och återanvänd första resultatet när samma nyckel ses igen.
Långa arbetsflöden: sagor och kompensation
För flerstegsaktioner mellan tjänster, använd en saga: varje steg har en motsvarande kompenserande åtgärd (återbetalning, släpp reservation, avbryt leverans). Detta gör systemet återhämtningsbart även när delar tillfälligt är oense eller fallerar.
Testning och observerbarhet för konsistens vs tillgänglighet
Du kan inte hantera konsistens/tillgänglighets-avvägningen om du inte ser den. Produktionsproblem ser ofta ut som “slumpmässiga fel” tills du lägger till rätt mätvärden och tester.
Vad att mäta (och varför)
Börja med en liten uppsättning mätvärden som mappar direkt till användarpåverkan:
- Latens (p50/p95/p99): håll koll på toppar under failovers, ledarbyten eller quorum-omförsök.
- Felrate: separera “hårda” fel (timeouts, 5xx) från “mjuka” fel (returnerat fallback, partiella resultat).
- Andel föråldrade läsningar: procent av läsningar som returnerar data äldre än ditt mål (t.ex. äldre än 2 sekunder).
- Konfliktrate: hur ofta samtidiga skrivningar kräver rekonsiliering (inklusive LWW-överskrivningar).
Om möjligt tagga mätvärden efter konsistensläge (quorum vs lokal) och region/zon för att se var beteendet avviker.
Testa partitioner medvetet
Vänta inte på verkligt avbrott. I staging, kör chaos-experiment som simulerar:
- tappade paket och hög latens mellan repliker
- en region som blir otillgänglig
- partiella partitioner där bara vissa noder kan prata
Verifiera inte bara “systemet håller sig uppe”, utan vilka garantier som håller: förblir läsningar färska, blockeras skrivningar, får klienter tydliga fel?
Alerting som fångar avvägningen tidigt
Lägg till alerting för:
- replikeringslag som överstiger din tolerans för föråldring
- quorum-fel (kan inte nå tillräckligt många repliker) och ökande antal omförsök
- ökande skrivkonflikter eller backlogg för rekonsiliering
Slutligen, gör garantierna explicita: dokumentera vad ditt system lovar under normal drift och under partitioner, och utbilda produkt- och supportteam i vad användare kan se och hur de ska svara.
Prototypa CAP-val snabbare (utan att bygga om allt)
Om du utforskar dessa avvägningar i en ny produkt är det hjälpsamt att validera antaganden tidigt—särskilt kring felbeteenden, återförsök och hur “föråldrat” ser ut i UI:n.
Ett praktiskt tillvägagångssätt är att prototypa en liten version av arbetsflödet (skrivväg, läsväg, återförsök/idempotens och en rekonsilieringsjobb) innan du bestämmer dig för full arkitektur. Med Koder.ai kan team snabbt snurra upp webbappar och backends via ett chattstyrt arbetsflöde, iterera på datamodeller och API:er och testa olika konsistensmönster (t.ex. strikta skrivningar + avslappnade läsningar) utan overhead från en traditionell byggkedja. När prototypen matchar önskat beteende kan du exportera källkoden och vidareutveckla den till produktion.