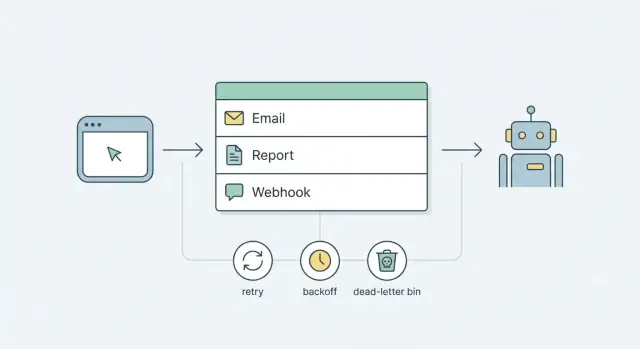
Varför du behöver bakgrundsjobb (och varför det snabbt blir rörigt)
Allt arbete som kan ta längre än en eller två sekunder bör inte köras inne i en användarförfrågan. Att skicka e-post, generera rapporter och leverera webhooks beror ofta på nätverk, tredjepartstjänster eller långa frågor. Ibland pausar de, misslyckas eller tar helt enkelt längre tid än du väntat.
Om du gör det arbetet medan användaren väntar, märker folk det genast. Sidor hänger, "Spara"-knappar snurrar och förfrågningar går i timeout. Omförsök kan också ske på fel ställe. En användare uppdaterar sidan, din load balancer försöker igen eller frontend skickar om, och du får dubbla mejl, dubbla webhook-anrop eller två rapportkörningar som konkurrerar.
Bakgrundsjobb löser detta genom att hålla förfrågningar små och förutsägbara: ta emot åtgärden, skriv en jobbpost för senare, svara snabbt. Jobbet körs utanför förfrågan, med regler du kontrollerar.
Det svåra är tillförlitlighet. När arbetet flyttas ut ur förfrågningsvägen måste du fortfarande svara på frågor som:
- Vad händer om e-postleverantören ligger nere i 3 minuter?
- Vad händer om en webhook-endpoint returnerar 500 eller timear ut?
- Vad händer om jobbet körs två gånger?
- Hur märker du fastnade jobb innan användare klagar?
Många team svarar genom att lägga till "tung infrastruktur": en meddelandebroker, separata worker-flottor, dashboards, alerting och playbooks. De verktygen är användbara när du verkligen behöver dem, men de lägger också till nya rörliga delar och nya felmodeller.
Ett bättre startmål är enklare: tillförlitliga jobb med de delar du redan har. För de flesta produkter betyder det en databasdriven kö plus en liten workerprocess. Lägg till en tydlig strategi för omförsök och backoff, och ett dead-letter-mönster för jobb som fortsätter att misslyckas. Du får förutsägbart beteende utan att binda dig till en komplex plattform från dag ett.
Även om du bygger snabbt med ett chattdrivet verktyg som Koder.ai, är denna separation fortfarande viktig. Användare ska få ett snabbt svar nu, och ditt system ska slutföra långsamt, felbenäget arbete säkert i bakgrunden.
Vad en kö är i enkla termer
En kö är en väntlinje för arbete. Istället för att göra långsamma eller osäkra uppgifter under en användarförfrågan (skicka e-post, skapa en rapport, anropa en webhook), lägger du en liten post i en kö och returnerar snabbt. Senare plockar en separat process upp posten och gör jobbet.
Några ord du ofta ser:
- Job: en enhet arbete, till exempel "skicka välkomstmail till user 123".
- Worker: koden som drar jobben och kör dem.
- Attempt: ett försök att köra ett jobb.
- Schedule: när jobbet ska köras (nu eller senare).
- Queue: där jobben väntar tills en worker tar dem.
Det enklaste flödet ser ut så här:
-
Enqueue: din app sparar en jobbpost (typ, payload, körtid).
-
Claim: en worker hittar nästa tillgängliga jobb och "låser" det så bara en worker kör det.
-
Run: workern utför uppgiften (skicka, generera, leverera).
-
Finish: markera det som klart, eller registrera ett fel och sätt nästa körtid.
Om din jobbvolym är måttlig och du redan har en databas räcker ofta en databasdriven kö. Den är lätt att förstå, lätt att felsöka och passar vanliga behov som e-postjobbshantering och pålitlig webhook-leverans.
Strömmande plattformar börjar bli relevanta när du behöver mycket hög genomströmning, många oberoende konsumenter eller förmågan att spela upp stora händelsehistoriker över många system. Om du kör dussintals tjänster med miljoner händelser per timme kan verktyg som Kafka hjälpa. Fram tills dess täcker en databastabell plus en worker-loop mycket av verklighetens köbehov.
Minsta data du bör spåra för varje jobb
En databasdriven kö förblir hanterbar bara om varje jobbpost snabbt svarar på tre frågor: vad som ska göras, när det ska försökas nästa gång, och vad som hände sist. Får du det rätt blir drift tråkigt (vilket är målet).
Vad att lagra i payloaden (och vad inte)
Spara minsta möjliga input som behövs för att göra jobbet, inte hela det renderade resultatet. Bra payloads är ID:n och ett fåtal parametrar, till exempel { "user_id": 42, "template": "welcome" }.
Undvik att lagra stora blobs (fulla HTML-mejl, stora rapportdata, enorma webhook-bodies). Det gör att databasen växer snabbare och försvårar felsökning. Om jobbet behöver ett stort dokument, spara en referens istället: report_id, export_id eller en filnyckel. Workern kan hämta full data när den körs.
Fälten som betalar sig själva
Minst, gör plats för:
- job_type + payload:
job_type väljer handler (send_email, generate_report, deliver_webhook). payload innehåller små inputs som ID:n och alternativ.
- status: håll det explicit (till exempel:
queued, running, succeeded, failed, dead).
- attempt tracking:
attempt_count och max_attempts så du kan sluta försöka när det uppenbart inte går.
- tidsfält:
created_at och next_run_at (när det blir berättigat). Lägg till started_at och finished_at om du vill ha bättre insyn i långsamma jobb.
- idempotency + last error: en
idempotency_key för att förhindra dubbla effekter, och last_error så du kan se varför det misslyckades utan att rota i en hög loggar.
Idempotens låter fancy, men idén är enkel: om samma jobb körs två gånger ska det andra körningen upptäcka det och inte göra något farligt. Till exempel kan ett webhook-leveransjobb använda en idempotensnyckel som webhook:order:123:event:paid så du inte levererar samma event två gånger om ett omförsök överlappar med en timeout.
Spara också några grundläggande siffror tidigt. Du behöver inte en stor dashboard för att börja, bara frågor som visar: hur många jobb är i kö, hur många misslyckas och åldern på det äldsta jobb i kö.
Steg för steg: en enkel databasdriven kö du kan bygga idag
Om du redan har en databas kan du starta en bakgrundskö utan att lägga till ny infrastruktur. Jobb är rader, och en worker är en process som fortsätter plocka förfallna rader och utföra arbetet.
1) Skapa en jobs-tabell
Håll tabellen liten och tråkig. Du vill ha tillräckligt med fält för att köra, omförsöka och felsöka jobb senare.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Om du bygger på Postgres (vanligt med Go-backends) är jsonb ett praktiskt sätt att lagra jobbdata som { "user_id":123,"template":"welcome" }.
2) Köa säkert (särskilt för användaråtgärder)
När en användaråtgärd ska trigga ett jobb (skicka e-post, skicka en webhook), skriv jobb-raden i samma databas-transaktion som huvudändringen när det är möjligt. Det förhindrar "användare skapad men jobb saknas" om en krasch sker precis efter huvudskrivningen.
Exempel: när en användare registrerar sig, insert-a user-raden och ett send_welcome_email-jobb i en transaktion.
3) Kör en worker-loop som kan skalas
En worker upprepar samma cykel: hitta ett förfallet jobb, claim:a det så ingen annan kan ta det, processa det och sedan markera det klart eller schemalägga ett omförsök.
I praktiken innebär det:
- Plocka ett jobb där
status='queued' och next_run_at <= now().
- Claim:a det atomärt (i Postgres är
SELECT ... FOR UPDATE SKIP LOCKED ett vanligt tillvägagångssätt).
- Sätt
status='running', locked_at=now(), locked_by='worker-1'.
- Processa jobbet.
- Markera det färdigt (till exempel
done/succeeded), eller registrera last_error och schemalägg nästa försök.
Flera workers kan köra samtidigt. Claim-steget förhindrar dubbelplockning.
4) Hantera shutdown utan att bryta jobb
Vid shutdown, sluta ta nya jobb, avsluta det pågående jobbet och avsluta processen. Om en process dör mitt i ett jobb, använd en enkel regel: behandla jobb som fastnat i running längre än en timeout som berättigade att re-queue:as av en periodisk "reaper"-task.
Om du bygger i Koder.ai är detta databas-kö-mönster ett stabilt standardval för e-post, rapporter och webhooks innan du lägger till specialiserade kö-tjänster.
Omförsök och backoff som inte orsakar kaos
Distribuera kö + workers
Distribuera din app och workers tillsammans, och iterera säkert när belastningen växer.
Omförsök är hur en kö förblir lugn när verkligheten är stökig. Utan tydliga regler blir omförsök en bullrig loop som spam:ar användare, hamrar API:er och döljer den verkliga buggen.
Börja med att bestämma vad som ska omförsökas och vad som ska misslyckas snabbt.
Omförsök vid tillfälliga problem: nätverks-timeouter, 502/503, rate limits eller en kort databaskontaktstörning.
Faila snabbt när jobbet inte kommer att lyckas: saknad e-postadress, en 400-respons från en webhook eftersom payload är ogiltig, eller en rapportförfrågan för ett raderat konto.
Backoff är pausen mellan försök. Linjär backoff (5s, 10s, 15s) är enkelt, men det kan fortfarande skapa trafikvågor. Exponentiell backoff (5s, 10s, 20s, 40s) sprider belastningen bättre och är vanligtvis säkrare för webhooks och tredjepartsleverantörer. Lägg till jitter (en liten slumpmässig extra fördröjning) så inte tusentals jobb försöker exakt samtidigt efter ett avbrott.
Regler som brukar bete sig bra i produktion:
- Försök bara om vid klart tillfälliga fel (timeouts, 429, 5xx).
- Använd exponentiell backoff med jitter.
- Begränsa antal försök, markera sedan jobbet som failed.
- Sätt en timeout per försök så workers inte fastnar.
- Gör varje jobb idempotent så omförsök inte skapar dubbletter.
Maxförsök handlar om att begränsa skada. För många team räcker 5 till 8 försök. Efter det, sluta försöka och parkera jobbet för granskning (dead-letter) istället för att loopa för evigt.
Timeouts förhindrar "zombie"-jobb. E-post kan timea ut vid 10–20 sekunder per försök. Webhooks behöver ofta en kortare gräns, som 5–10 sekunder, eftersom mottagaren kan vara nere och du vill gå vidare. Rapportgenerering kan få tillåta minuter, men bör ändå ha en hård stoppgräns.
Om du bygger detta i Koder.ai, behandla should_retry, next_run_at och en idempotensnyckel som förstklassiga fält. De små detaljerna håller systemet tyst när något går fel.
Dead-letter-hantering och enkel drift
Ett dead-letter-tillstånd är där jobb hamnar när omförsök inte längre är säkra eller användbara. Det förvandlar tystnad till något du kan se, söka i och agera på.
Vad att spara på ett dead-letter-jobb
Spara tillräckligt för att förstå vad som hände och för att kunna spela upp jobbet igen utan gissningar, men var försiktig med hemligheter.
Behåll:
- Jobbinsatserna (payload) exakt som användes, plus jobbtyp och version
- Sista felmeddelandet och en kort stacktrace (eller en felkod om du inte har stackar)
- Försökantal, första körningstid, sista körningstid och nästa körningstid (om det var schemalagt)
- Worker-identitet (servicenamn, host) och ett korrelations-ID för loggar
- En dead-letter-orsak (timeout, valideringsfel, 4xx från leverantör, etc.)
Om payloaden innehåller tokens eller personuppgifter, redigera eller kryptera innan du sparar.
Ett enkelt triage-flöde
När ett jobb når dead-letter, fatta ett snabbt beslut: försök igen, fixa eller ignorera.
Försök igen är för externa avbrott och timeouter. Fixa är för felaktiga data (saknad e-post, fel webhook-URL) eller en bugg i din kod. Ignorera bör vara sällsynt, men kan vara giltigt när jobbet inte längre är relevant (till exempel kunden raderade sitt konto). Om du ignorerar, spela in en orsak så det inte ser ut som om jobbet försvann.
Manuell requeue är säkrast när det skapar ett nytt jobb och håller det gamla oföränderligt. Markera dead-letter-jobbet med vem som requeued det, när och varför, och köa sedan en ny kopia med ett nytt ID.
För alerting, övervaka signaler som vanligtvis betyder verklig smärta: snabbt ökande antal dead-letter-jobb, samma fel som upprepas i många jobb, och gamla köade jobb som inte plockas.
Om du använder Koder.ai kan snapshots och rollback hjälpa när en dålig release plötsligt ökar fel, eftersom du snabbt kan backa medan du undersöker.
Slutligen, lägg in säkerhetsventiler för leverantörsavbrott. Rate-begränsa per leverantör och använd en circuit breaker: om en webhook-endpoint misslyckas hårt, pausa nya försök en kort stund så du inte översvämmer deras servrar (och dina egna).
Mönster för e-post, rapporter och webhooks
Lägg till dead-letter-visibility
Bygg en dead-letter-flöde och en enkel adminvy för att inspektera och requeua fel.
En kö fungerar bäst när varje jobtyp har tydliga regler: vad som räknas som framgång, vad som ska omförsökas och vad som aldrig får hända två gånger.
E-post. De flesta e-postfel är tillfälliga: leverantörstimeouter, rate limits eller korta avbrott. Behandla dessa som omförsöksbara med backoff. Den större risken är dubbla utskick, så gör e-postjobb idempotenta. Spara en stabil dedupe-nyckel som user_id + template + event_id och vägra skicka om den nyckeln redan är markerad som skickad.
Det är också värt att spara mallnamn och version (eller en hash av renderad subject/body). Om du någonsin behöver köra om jobb kan du välja att skicka exakt samma innehåll eller regenerera från den senaste mallen. Om leverantören returnerar ett meddelande-ID, spara det så support kan spåra vad som hände.
Rapporter. Rapporter misslyckas på andra sätt. De kan köra i minuter, träffa pagineringsgränser eller få slut på minne om du gör allt i ett svep. Dela upp arbetet i mindre delar. Ett vanligt mönster är: ett "report request"-jobb skapar många "page"- eller "chunk"-jobb, där varje jobb bearbetar en skiva av data.
Spara resultat för senare nedladdning istället för att hålla användaren väntande. Det kan vara en databastabell keyed by report_run_id, eller en filreferens plus metadata (status, radantal, created_at). Lägg till progress-fält så UI kan visa "processing" vs "ready" utan att gissa.
Webhooks. Webhooks handlar om leveranssäkerhet, inte hastighet. Signera varje förfrågan (till exempel HMAC med en delad hemlighet) och inkludera en tidsstämpel för att förhindra replay. Försök bara om mottagaren kan lyckas senare.
En enkel regelsats:
- Försök igen vid timeouter och 5xx-svar, med backoff och ett maxförsöksantal.
- Behandla de flesta 4xx-responser som permanenta fel och sluta försöka.
- Spara sista statuskod och en kort response-body för felsökning.
- Använd en idempotensnyckel så mottagaren kan ignorera dubbletter.
- Begränsa payload-storlek och logga vad du faktiskt skickade.
Ordning och prioritet. De flesta jobb behöver inte strikt ordning. När ordning betyder något gör det oftast per nyckel (per användare, per faktura, per webhook-endpoint). Lägg till en group_key och kör bara ett jobb per nyckel i taget.
För prioritet, separera brådskande arbete från långsamt arbete. En stor rapportkö ska inte fördröja lösenordsåterställningsmejl.
Exempel: efter ett köp köar du (1) ett orderbekräftelsemail, (2) en partner-webhook och (3) ett rapportuppdateringsjobb. Mailet kan omförsökas snabbt, webhooken omförsökas längre med backoff, och rapporten körs senare med låg prioritet.
Ett realistiskt exempel: signup-flöde plus webhook plus nattlig rapport
Generera en Go worker-loop
Be Koder.ai generera en Go-worker med säker jobb-claiming och timeouts.
En användare registrerar sig för din app. Tre saker ska hända, men ingen av dem ska få signup-sidan att bli långsam: skicka ett välkomstmail, meddela ditt CRM med en webhook, och inkludera användaren i en nattlig aktivitetsrapport.
Vad som köas vid signup
Direkt efter att du skapat user-raden skriver du tre jobb-rader till din databas-kö. Varje rad har en typ, en payload (som user_id), en status, ett försökantal och en next_run_at-timestamp.
En typisk livscykel ser ut så här:
queued: skapad och väntar på en workerrunning: en worker har claim:at densucceeded: klart, inget mer arbetefailed: misslyckades, schemalagd för senare eller slut på omförsökdead: misslyckades för många gånger och behöver mänsklig granskning
Välkomstmailet inkluderar en idempotensnyckel som welcome_email:user:123. Innan du skickar kontrollerar workern en tabell med färdiga idempotensnycklar (eller tvingar en unik constraint). Om jobbet körs två gånger på grund av en krasch ser den andra körningen nyckeln och hoppar över utskicket. Inga dubbla välkomstmail.
Ett fel och hur det återhämtar sig
CRM-webhook-endpointen ligger nere. Webhook-jobbet misslyckas med timeout. Din worker schemalägger ett omförsök med backoff (till exempel: 1 minut, 5 minuter, 30 minuter, 2 timmar) plus lite jitter så många jobb inte försöker exakt samtidigt.
Efter maxförsök blir jobbet dead. Användaren registrerades ändå, fick välkomstmailet, och nattliga rapportjobbet kan köra som normalt. Endast CRM-notifikationen sitter fast, och det är synligt.
Nästa morgon kan support eller den som är på vakt hantera det utan att rota i loggar i timmar:
- Filtrera dead-jobb efter typ (till exempel
webhook.crm).
- Läs sista felmeddelandet och bekräfta att payload ser rätt ut.
- Verifiera att CRM är uppe igen.
- Requeuea jobbet (dead -> queued, återställ attempts) eller inaktivera destinationen tillfälligt.
Om du bygger appar på en plattform som Koder.ai gäller samma mönster: håll användarflödet snabbt, skjut sidoeffekter till jobb, och gör fel enkla att inspektera och köra om.
Vanliga misstag som gör köer opålitliga
Det snabbaste sättet att bryta en kö är att behandla den som valfri. Team börjar ofta med "skicka e-post i förfrågan den här gången" för att det känns enklare. Sedan sprider det sig: lösenordsåterställningar, kvitton, webhooks, rapportexporter. Snart känns appen långsam, timeouter ökar och varje tredjepartshicka blir din outage.
En annan fälla är att skippa idempotens. Om ett jobb kan köras två gånger måste det inte skapa två resultat. Utan idempotens blir omförsök dubbletter av e-post, upprepade webhook-events eller värre.
Ett tredje problem är synlighet. Om du bara får reda på fel från supportärenden skadar kön redan användarna. Även en grundläggande intern vy som visar jobbräkningar per status plus sökbar last_error sparar tid.
Reliability killers att se upp för
Några problem som dyker upp tidigt, även i enkla köer:
- Omförsök direkt vid fel. Om en leverantör är nere skapar snabba omförsök din egen trafikvåg.
- Blanda långsamma jobb med brådskande jobb. En 10-minuters rapport kan blockera ett "verifiera din e-post"-meddelande.
- Behandla fel som tillfälliga för alltid. Jobb som aldrig kommer lyckas fortsätter att cykla och döljer verkliga problem.
- Ingen ansvarsfördelning för payload-versioner. Om du ändrar jobbets form kan gamla jobb börja misslyckas.
- Ignorera rate limits. Köer kan överbelasta leverantörer som throttlar.
Backoff förhindrar självskapade outage-scenarier. Även ett grundschema som 1 minut, 5 minuter, 30 minuter, 2 timmar gör fel säkrare. Sätt också ett maxförsöksantal så ett trasigt jobb stannar och blir synligt.
Om du bygger på en plattform som Koder.ai är det bra att leverera dessa grunder tillsammans med funktionen, inte veckor senare som ett städprojekt.