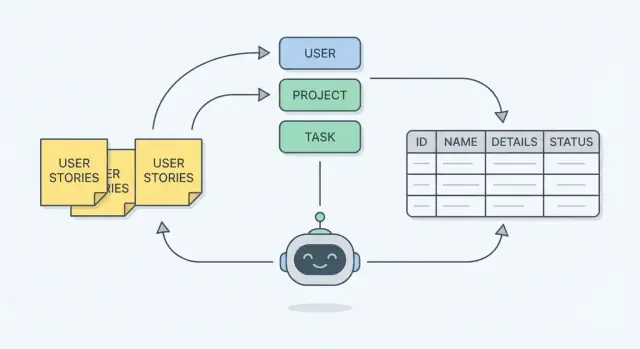
Vad du bygger: ett schema som matchar verkligt arbete
Ett databasschema är planen för hur din app kommer ihåg saker. I praktiska termer är det:
- Tabeller: informations"hinkarna" (Customers, Orders, Tickets)
- Fält (kolumner): detaljerna du sparar om varje sak (customer_name, order_date)
- Relationer: hur hinkarna kopplas ihop (en Order tillhör en Customer; en Customer kan ha många Orders)
När schemat speglar verkligt arbete återspeglar det vad människor faktiskt gör—skapar, granskar, godkänner, planerar, tilldelar, avbokar—istället för vad som låter prydligt på en whiteboard.
Varför börja från användarberättelser?
Användarberättelser och acceptanskriterier beskriver verkliga behov med enkelt språk: vem gör vad och vad som räknas som “klart”. Om du använder dem som källa är det mindre sannolikt att schemat missar viktiga detaljer (t.ex. “vi måste spåra vem som godkände återbetalningen” eller “en bokning kan ombokas flera gånger”).
Att börja från berättelser håller dig också ärlig om omfattningen. Om det inte finns i berättelserna (eller arbetsflödet), behandla det som valfritt istället för att tyst bygga en komplicerad modell “ifall”.
Vad AI kan och inte kan göra här
AI kan hjälpa dig gå snabbare genom att:
- Plocka ut kandidat‑entiteter (de viktiga “sakerna” i berättelserna)
- Föreslå fält som antyds av acceptanskriterier (tidsstämplar, statusar, referenser)
- Upptäcka sannolika relationer och luckor (“du nämner godkännanden men sparar inte vem som godkände”)
AI kan inte pålitligt:
- Känna till dina dolda affärsregler eller kantfall som du inte skrev ner
- Välja rätt detaljnivå utan avvägningar (enkelt vs flexibelt)
- Garanti att schemat uppfyller dina rapport‑, säkerhets‑ eller efterlevnadsbehov
Behandla AI som en stark assistent, inte beslutsfattaren.
Om du vill omvandla den assistenten till momentum kan en vibe‑coding‑plattform som Koder.ai hjälpa dig gå från schema‑beslut till en fungerande React + Go + PostgreSQL‑app snabbare—samtidigt som du behåller kontroll över modellen, begränsningarna och migrationerna.
Sätt förväntningar: iterativt, inte engångs
Schema‑design är en loop: draft → testa mot berättelser → hitta saknad data → förfina. Målet är inte ett perfekt första utkast; det är en modell du kan härleda tillbaka till varje användarberättelse och med säkerhet säga: “Ja, vi kan lagra allt detta arbetsflöde behöver—och vi kan förklara varför varje tabell finns.”
Innan du förvandlar krav till tabeller, var tydlig med vad du modellerar. Ett bra schema börjar sällan från ett blankt papper—det börjar från konkreta uppgifter människor utför och den bevisning du behöver senare (skärmar, utskrifter och kantfall).
User stories är rubriken, men de räcker inte ensamma. Samla:
- Användarberättelser + roller (vem gör vad och varför)
- Acceptanskriterier (”måste vara sant”-reglerna)
- Formulär/skärmar (fält användare skriver in, väljer eller ser)
- Rapporter/exporter (vad som behöver summeras, grupperas, filtreras)
- Verkliga exempel (exempelbeställningar, fakturor, ärenden, kalendrar—allt representativt)
Om du använder AI håller dessa inputs modellen jordad. AI kan föreslå entiteter och fält snabbt, men behöver verkliga artefakter för att undvika att uppfinna struktur som inte stämmer med produkten.
Acceptanskriterier: den dolda källan till begränsningar
Acceptanskriterier innehåller ofta de viktigaste databasreglerna, även när de inte nämner data uttryckligen. Leta efter formuleringar som:
- “E‑post måste vara unik” (unikhet)
- “Status kan vara Draft, Submitted, Approved” (tillåtna värden)
- “Endast chefer kan godkänna” (behörigheter, eventuellt audit‑fält)
- “Kan inte radera en faktura med betalningar” (referentiella regler)
Vanliga fallgropar att fixa tidigt
Vaga berättelser (“Som en användare kan jag hantera projekt”) döljer ofta flera entiteter och arbetsflöden. Ett annat vanligt gap är saknade kantfall som avbokningar, omförsök, delåterbetalningar eller omfördelning.
Snabb checklista för berättelsekvalitet (innan modellering)
- Aktören/rollen är tydlig.
- Objektet är specifikt (inte “data” eller “saker”).
- Minst ett verkligt exempel finns.
- Acceptanskriterier inkluderar valideringar och gränser.
- Fel‑ och “vad händer om”-fall nämns (eller uttryckligen skjuts upp).
Innan du tänker på tabeller eller diagram, läs användarberättelserna och markera substantiven. I kravskrivning pekar substantiv ofta på de “saker” systemet måste komma ihåg—de blir ofta entiteter i ditt schema.
En enkel mental modell: substantiv blir entiteter, medan verb blir åtgärder eller arbetsflöden. Om en berättelse säger “En chef tilldelar en tekniker till ett jobb”, är troliga entiteter chef, tekniker och jobb—och “tilldelar” antyder en relation du modellerar senare.
Hur avgör du om ett substantiv är en riktig entitet
Inte varje substantiv förtjänar sin egen tabell. Ett substantiv är en stark kandidat för en entitet när det:
- Har egen identitet: du kan peka på ett specifikt exempel (Jobb #1042, Kund A).
- Förändras över tid: det har en livscykel (ett jobb går från schemalagt → avslutat).
- Används på flera ställen: flera berättelser refererar till det, eller flera arbetsflöden berör det.
Om ett substantiv bara dyker upp en gång eller bara beskriver något annat (“röd knapp”, “fredag”), kanske det inte är en entitet.
Attribut vs separat entitet ("Adress" och "Tag" testet)
Ett vanligt misstag är att göra varje detalj till en tabell. Använd denna tumregel:
- Om det är ett värde som beskriver en sak, är det vanligtvis ett attribut (t.ex. Customer.phone_number).
- Om det är upprepningsbart, delat eller strukturerat, är det ofta en separat entitet.
Två klassiska exempel:
- Adress: Om du sparar leverans‑ och fakturaadresser, behåller historik eller återanvänder adresser mellan kunder/plats, är Address sannolikt en egen entitet. Om du bara behöver en enda postadress och aldrig återanvänder den, kan den stanna som attribut.
- Tag: Tags är nästan alltid egna entiteter eftersom de är upprepningsbara och många‑till‑många (ett Jobb har många Tags; en Tag gäller många Jobs).
Använd AI för att föreslå kandidat‑entiteter (med försiktighet)
AI kan snabba upp entity discovery genom att skanna berättelser och returnera en utkastlista med kandidat‑substantiv grupperade efter tema (personer, arbetsobjekt, dokument, platser). En användbar prompt är: “Extrahera substantiv som representerar data vi måste lagra, och gruppera dubbletter/synonymer.”
Behandla resultatet som en startpunkt, inte svaret. Ställ följdfrågor som:
- “Vilka av dessa har en livscykel eller behöver egen ID?”
- “Vilka är egentligen statusar, kategorier eller attribut?”
- “Är några synonymer (t.ex. ‘client’ vs ‘customer’)?”
Målet med Steg 1 är en kort, ren lista över entiteter du kan försvara genom att peka tillbaka på verkliga berättelser.
Steg 2 — Förvandla detaljer till fält (det du måste spara)
När du namngivit entiteterna (som Order, Customer, Ticket) är nästa jobb att fånga de detaljer du behöver senare. I en databas är de detaljerna fält (även kallade attribut)—påminnelserna systemet inte får glömma.
Hur välja fält (utan att gissa)
Börja med användarberättelsen och läs acceptanskriterierna som en checklista över vad som måste sparas.
Om ett krav säger “Användare kan filtrera beställningar efter leveransdatum”, så är delivery_date inte valfritt—det måste finnas som ett fält (eller kunna härledas pålitligt av annan sparad data). Om det står “Visa vem som godkände begäran och när”, behöver du troligen approved_by och approved_at.
Ett praktiskt test: Behöver någon detta för att visa, söka, sortera, granska eller räkna ut något? Om ja, hör det sannolikt hemma som ett fält.
Enkla regler för rena fält
- Håll värden atomära: spara “Förnamn” och “Efternamn” separat om du ska söka eller sortera på dem. Undvik att packa flera värden i ett fält (t.ex. “röd, blå”).
- Använd konsekventa typer: datum som datum, pengar som decimaler, boolean som true/false—inte blandade format som “$10”, “10 USD” och “10”.
- Undvik duplicerad text: kopiera inte kundens adress i varje orderrad. Spara den en gång på rätt plats och referera till den.
Kontrollerade vokabulärer: statusar, typer och kategorier
Många berättelser innehåller ord som “status”, “typ” eller “prioritet.” Behandla dessa som kontrollerade vokabulärer—ett begränsat uppsättning tillåtna värden.
Om uppsättningen är liten och stabil kan ett enkelt enum‑fält fungera. Om den kan växa, behöver etiketter eller behörigheter (t.ex. admin‑styrda kategorier), använd en separat uppslags‑tabell (t.ex. status_codes) och lagra en referens.
Så här blir berättelser till fält du kan lita på—sökbara, rapporterbara och svåra att mata in felaktigt.
Steg 3 — Koppla entiteter med relationer
När du listat entiteterna (User, Order, Invoice, Comment, osv.) och skissat deras fält är nästa steg att koppla ihop dem. Relationer är lagret “hur dessa saker interagerar” som berättelserna antyder.
En‑till‑en (1:1) betyder “en sak har exakt en annan sak.”
- Berättelsefras: “Varje användare har en profil.”
- Modellidé:
User ↔ Profile (ofta kan dessa slås ihop om det inte finns skäl att separera).
En‑till‑många (1:N) betyder “en sak kan ha många av en annan sak.” Detta är vanligast.
- Berättelsefras: “En användare kan ha många beställningar.”
- Modellidé:
User → Order (lagra user_id på Order).
Många‑till‑många (M:N) betyder “många saker kan relatera till många saker.” Detta kräver en extra tabell.
- Berättelsefras: “En beställning kan innehålla många produkter, och en produkt kan finnas i många beställningar.”
M:N: join‑tabellstricket
Databaser kan inte lagra “en lista med produkt‑ID:n” snyggt inne i Order utan problem senare (sökning, uppdatering, rapportering). Skapa istället en join‑tabell som representerar relationen.
Exempel:
OrderProductOrderItem (join‑tabell)
OrderItem brukar innehålla:
order_idproduct_id- extra detaljer från berättelsen som
quantity, unit_price, discount
Notera hur berättelsens detaljer (“quantity”) ofta hör hemma på relationen, inte på någon av entiteterna.
Obligatoriskt vs valfritt (utan facktermer)
Berättelser säger också om en koppling är nödvändig eller ibland saknas.
- “En order måste tillhöra en användare” → varje
Order behöver en user_id (får inte vara tom).
- “En användare kan ha ett telefonnummer” →
phone kan vara tomt.
- “En order kan ha en leveransadress (om fysiska varor)” →
shipping_address_id kan vara tom för digitala varor.
En snabb kontroll: om berättelsen antyder att du inte kan skapa posten utan länken, behandla den som obligatorisk. Om berättelsen säger “kan”, “får” eller ger undantag, behandla den som valfri.
Skriv om berättelsesatser till relationssatser
När du läser en berättelse, skriv om den som en enkel parning:
- “En användare kan lämna många kommentarer” →
User 1:N Comment
- “En kommentar tillhör en användare” →
Comment N:1 User
Gör detta för varje interaktion i dina berättelser. I slutändan har du en sammanhängande modell som matchar hur arbetet faktiskt sker—innan du öppnar ett ER‑diagramverktyg.
Steg 4 — Använd arbetsflöden för att hitta tillstånd, händelser och luckor
Få ett schemadraft snabbt
Skissa tabeller, fält och relationer från dina acceptanskriterier och förfina snabbt.
Användarberättelser berättar vad folk vill. Arbetsflöden visar hur jobbet faktiskt rör sig, steg för steg. Att översätta ett arbetsflöde till data är ett av de snabbaste sätten att fånga “vi glömde att spara det”-problem—innan du bygger något.
Börja med ett enkelt arbetsflöde
Skriv arbetsflödet som en sekvens av åtgärder och tillståndsbyten. Exempel:
- Skapa begäran → Draft
- Skicka in begäran → Submitted
- Chef granskar → Approved eller Rejected
- Om godkänd, planeras arbetet → In progress
- Avslutad → Done
De markerade orden blir ofta ett status‑fält (eller en liten “state”‑tabell) med tydliga tillåtna värden.
Arbetsflöden avslöjar saknade fält
När du går igenom varje steg, fråga: “Vad måste vi kunna veta senare?” Arbetsflöden avslöjar ofta fält som:
- tidsstämplar:
submitted_at, approved_at, completed_at
- ägarskap:
created_by, assigned_to, approved_by
- orsak/context:
rejection_reason, approval_note
- ordning:
sequence för flerstegsprocesser
Om ditt arbetsflöde inkluderar väntan, eskalering eller överlämningar behöver du vanligtvis åtminstone en tidsstämpel och ett “vem har det nu”‑fält.
Arbetsflöden avslöjar saknade tabeller
Vissa arbetsflödessteg är inte bara fält—de är separata datastrukturer:
- Audit logg / historik för “vem ändrade status när”
- Godkännanden för flervals‑ eller villkorliga godkännanden
- Bilagor när användare laddar upp filer under ett steg
- Kommentarer när diskussion är en del av processen
Använd AI för att krysschecka luckor
Ge AI både: (1) användarberättelserna och acceptanskriterierna, och (2) arbetsflödets steg. Be den lista varje steg och identifiera vilken data som krävs för varje (status, aktör, tidsstämplar, outputs), och markera krav som inte kan stödjas av nuvarande fält/tabeller.
I plattformar som Koder.ai blir denna “gap check” särskilt praktisk eftersom du snabbt kan iterera: justera schemaantaganden, regenerera scaffolding och fortsätta utan långa manuella omvägar.
Nycklar, unikhet och grundläggande begränsningar (utan jargong)
När du förvandlar användarberättelser till tabeller bestämmer du också hur data förblir identifierbar och konsekvent över tid.
Primärnycklar: ett stabilt “ID‑kort” för varje rad
En primärnyckel identifierar unikt en post—tänk på den som radens permanenta ID‑kort.
Varför varje rad behöver en: berättelser antyder uppdateringar, referenser och historik. Om en berättelse säger “Support kan se en order och ge en återbetalning” behöver du ett stabilt sätt att peka på den ordern—även om kunden byter e‑post, adressen redigeras eller orderstatus ändras.
I praktiken är det ofta ett internt id (nummer eller UUID) som aldrig ändras.
Främmande nycklar: pekare mellan tabeller
En foreign key är hur en tabell säkert pekar på en annan. Om orders.customer_id refererar customers.id kan databasen försäkra att varje order tillhör en verklig kund.
Detta matchar berättelser som “Som en användare kan jag se mina fakturor.” Fakturan flyter inte fritt; den är kopplad till en kund (och ofta till en order eller prenumeration).
Unika regler: gör “måste vara unik” till enforcement
Användarberättelser innehåller ofta dolda unikhetskrav:
- “Användare registrerar sig med e‑post” → upprätthåll unik e‑post (eller unik per tenant om du stödjer flera konton).
- “Ekonomi söker på fakturanummer” → upprätthåll unik invoice_number.
Dessa regler förhindrar förvirrande duplikat som annars dyker upp månader senare som “databugs”.
Indexering (översikt): gör vanliga uppslag snabba
Index gör uppslagningar snabba, som “hitta kund via e‑post” eller “lista ordrar per kund”. Börja med index som speglar dina vanligaste frågor och unikhetsregler.
Vad som kan vänta: tung indexering för sällsynta rapporter eller spekulativa filter. Dokumentera dessa behov i berättelserna, validera schemat först och optimera sedan baserat på verklig användning och långsamma frågor.
Håll data konsekvent: en praktisk normaliseringschecklista
Bygg från dina användarberättelser
Förvandla användarberättelser till en fungerande React, Go och PostgreSQL-app med Koder.ai.
Normalisering har ett enkelt mål: förhindra konflikterande dubbletter. Om samma fakta kan sparas på två ställen kommer den förr eller senare att avvika (två stavningar, två priser, två “aktuella” adresser). Ett normaliserat schema lagrar varje fakta en gång och refererar till den.
En snabb checklista du kan köra på varje utkast till schema
1) Se upp för upprepade grupper
Om du ser mönster som “Phone1, Phone2, Phone3” eller “ItemA, ItemB, ItemC” är det en signal för en separat tabell (t.ex. CustomerPhones, OrderItems). Upprepade grupper gör det svårt att söka, validera och skala.
2) Kopiera inte samma namn/detaljer i flera tabeller
Om CustomerName förekommer i Orders, Invoices och Shipments har du flera sanningskällor. Håll kunddetaljer i Customers och spara endast customer_id på andra ställen.
3) Undvik “flera kolumner för samma sak”
Kolumner som billing_address, shipping_address, home_address kan vara okej om de verkligen är olika begrepp. Men om du modellerar “många adresser av olika typer”, använd en Addresses‑tabell med ett type‑fält.
4) Separera lookup från fri text
Om användare väljer från en känd uppsättning (status, kategori, roll), modellera det konsekvent: antingen ett begränsat enum eller en uppslags‑tabell. Detta förhindrar “Pending” vs “pending” vs “PENDING”.
5) Kontrollera att varje icke‑ID‑fält beror på rätt sak
Ett hjälpsamt tumtest: i en tabell, om en kolumn beskriver något annat än tabellens huvudentitet, hör den sannolikt hemma någon annanstans. Exempel: Orders bör inte lagra product_price om det inte betyder “pris vid beställningstid” (en historisk snapshot).
När denormalisering är acceptabelt (som senare val)
Ibland lagrar du medvetet dubbletter:
- Rapportering/prestanda: föraggregerade totalsummor eller sammanfattningstabeller.
- Caching: ett beräknat värde lagrat för att undvika tung omräkning.
- Audit/historik: kopiera “namn vid köpstillfället” för att bevara tidigare verklighet.
Nyckeln är att det är avsiktligt: dokumentera vilket fält som är sanningens källa och hur kopior uppdateras.
Var AI hjälper—och var människor bestämmer
AI kan flagga misstänkt duplication (upprepade kolumner, liknande fältnamn, inkonsekventa “status”fält) och föreslå uppdelningar till tabeller. Människor väljer fortfarande avvägningen—enkelhet vs flexibilitet vs prestanda—baserat på hur produkten faktiskt kommer användas.
Sparat vs beräknat: vad hör hemma i databasen
En användbar regel: spara fakta du inte pålitligt kan återskapa senare; beräkna allt annat.
Sparat vs beräknat (härlett) data
Sparad data är sanningskällan: individuella radposter, tidsstämplar, statusändringar, vem gjorde vad. Beräknad data produceras från dessa fakta: totalsummor, räknare, flaggor som “är försenad” och summeringar som “aktuellt lager”.
Om två värden kan beräknas från samma underliggande fakta, föredra att spara fakta och beräkna resten. Annars riskerar du motstridigheter.
Varför sparade härledda värden orsakar mismatch
Härledda värden ändras när deras input ändras. Om du sparar både input och resultat måste de hållas synkade i varje arbetsflöde och kantfall (ändringar, återbetalningar, partiella leveranser, bakdaterade ändringar). Ett missat uppdateringssteg och databasen börjar berätta två olika historier.
Exempel: spara order_total samtidigt som du sparar order_items. Om någon ändrar en kvantitet eller applicerar en rabatt och totalen inte uppdateras perfekt ser ekonomi ett tal medan kundvagnen visar ett annat.
Använd arbetsflöden för att avgöra vad som måste sparas (historik och snapshots)
Arbetsflöden visar när du behöver historisk sanning, inte bara “nuvarande sanning”. Om användare behöver veta vilket värde var vid tidpunkten, spara en snapshot.
För en order kan du spara:
- Radposter och priser (fakta)
- En fångad
order_total vid checkout (snapshot), eftersom skatt, rabatter och prissättningsregler kan ändras senare
För lager beräknas ofta “lagernivå” från rörelser (inköp, försäljning, justeringar). Men om du behöver revisionsspår sparar du rörelser och eventuellt periodiska snapshots för rapporteringshastighet.
För inloggningsspårning, spara last_login_at som en faktahändelse (tidsstämpel). “Är aktiv de senaste 30 dagarna?” förblir beräknat.
Genomgångsexempel: från 5 användarberättelser till en ER‑modell
Låt oss använda en bekant supportticket‑app. Vi går från fem användarberättelser till en enkel ER‑modell (entiteter + fält + relationer), och sedan kontrollerar vi den mot ett arbetsflöde.
5 användarberättelser → substantiv → entiteter
- Som kund kan jag skapa ett supportärende med ämne, beskrivning och kategori.
- Som agent kan jag tilldela ett ärende till mig själv eller en annan agent.
- Som agent kan jag lägga till interna anteckningar och publika svar på ett ärende.
- Som kund kan jag se när mitt ärende uppdateras och när det stängs.
- Som chef kan jag följa hur länge ärenden är öppna och vem som stängde dem.
Från dessa substantiv får vi kärnentiteter:
- User (customers, agents, managers)
- Ticket
- Message (publika svar + interna anteckningar)
- Category
- TicketEvent (audit/historik)
Fält och relationer (en kompakt ER‑modell)
- User: id, name, email, role
- Category: id, name
- Ticket: id, subject, description, status, created_at, updated_at, closed_at
- relationer: Ticket.category_id → Category.id
- relationer: Ticket.requester_id → User.id (customer)
- relationer: Ticket.assignee_id → User.id (agent, nullable)
- Message: id, ticket_id, author_id, body, is_internal, created_at
- relationer: Message.ticket_id → Ticket.id
- relationer: Message.author_id → User.id
- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
Arbetsflödes‑karta: skapa → uppdatera → stäng
- Skapa: insert Ticket (status = “open”, created_at), insert TicketEvent(type = “created”).
- Uppdatera (tilldela, svara): insert Message eller uppdatera Ticket.assignee_id, och insert TicketEvent(type = “assigned”/“replied”, updated_at).
- Stäng: uppdatera Ticket.status = “closed”, sätt closed_at, insert TicketEvent(type = “closed”, actor_id = closer).
“Före och efter”: AI fångar en saknad begränsning
Före (vanligt miss): Ticket har assignee_id, men vi glömde säkerställa att bara agenter kan vara assignees.
Efter: AI flaggar detta och du lägger till en praktisk regel: assignee måste vara en User med role = “agent” (implementeras via applikationsvalidering eller en databasconstraint/policy beroende på stack). Det förhindrar “tilldelad till kund”‑data som senare bryter rapporter.
Validera schemat: spåra tillbaka till varje berättelse
Prototypa datamodellen
Testa ditt schema mot verkliga arbetsflöden genom att snurra upp en liten app på några minuter.
Ett schema är bara “klart” när varje användarberättelse kan besvaras med data du faktiskt kan spara och fråga. Det enklaste valideringssteget är att plocka upp varje berättelse och fråga: “Kan vi svara på detta från databasen, pålitligt, i alla fall?” Om svaret är “kanske” har din modell en lucka.
Gör varje berättelse till en databashövdfråga
Skriv om varje användarberättelse till ett eller flera testfrågor—saker du förväntar dig att en rapport, skärm eller API ska fråga. Exempel:
- Rapporter: “Visa alla öppna ordrar per kund, med totalsummor för de senaste 30 dagarna.”
- Behörigheter: “Vilka användare får godkänna återbetalningar för denna butik?”
- Kantfall: “Kan en order finnas utan leveransadress? Vad gäller digitala varor?”
- Borttagningar: “Om vi raderar en kund, vad händer med orders, fakturor och anteckningar?”
Om du inte kan uttrycka en berättelse som en tydlig fråga är berättelsen otydlig. Om du kan uttrycka den—men inte kan svara med ditt schema—saknas ett fält, en relation, en status/händelse eller en constraint.
Använd exempeldata som snabb sanity‑check
Skapa en liten dataset (5–20 rader per nyckeltabell) som innehåller normala fall och besvärliga fall (duplikat, saknade värden, avbokningar). “Spela igenom” berättelserna med dessa data. Du ser snabbt problem som “vi kan inte avgöra vilken adress som användes vid köpet” eller “vi har ingenstans att spara vem som godkände ändringen”.
Låt AI hjälpa dig hitta ohanterade fall
Be AI generera valideringsfrågor per berättelse (inklusive kantfall och raderingsscenarier) och lista vilken data som krävs för att svara på dem. Jämför listan med ditt schema: varje mismatch är en konkret åtgärdspunkt, inte en vag känsla av att “något är fel”.
Använd AI säkert och håll schemat hållbart
AI kan snabba upp datamodellering, men ökar också risken för att känslig information läcker eller att dåliga antaganden hårdkodas. Behandla det som en mycket snabb assistent: användbar, men behöver styrning.
Vad du kan dela med AI (och vad du ska undvika)
Dela inputs som är realistiska nog för att modellera, men sanerade för att vara säkra:
- Sanerade användarberättelser (byt namn på kunder, produkter, platser)
- Acceptanskriterier och kantfall (“återbetalning inom 14 dagar”, “en aktiv prenumeration per konto”)
- Exempelfält med falska data (t.ex.
invoice_total: 129.50, status: "paid")
- Nuvarande CSV‑huvuden / befintliga tabeller (struktur är oftast säker; innehåll ofta inte)
Undvik allt som kan identifiera personer eller röja konfidentiell drift:
- Riktiga namn, e‑post, telefonnummer, adresser
- Verkliga orderhistoriker, supportärenden, interna anteckningar
- API‑nycklar, databasuppgifter, skärmdumpar med privat data
Om du behöver realism, generera syntetiska provdata som matchar format och intervall—kopiera aldrig produktionsrader.
Sätt antaganden bredvid schemat
Scheman misslyckas oftast eftersom “alla antog” olika saker. Bredvid ditt ER‑diagram (eller i samma repo) håll en kort beslutslogg:
- Definitioner (“Vad räknas som ett ‘aktivt’ konto?”)
- Constraints (“En användare kan tillhöra flera organisationer”)
- Avvägningar (“Vi sparar valutakod på varje faktura för revisioner”)
Detta förvandlar AI‑output till teamkunnande istället för en engångsartifact.
Planera för förändring: versionering och migrationer
Ditt schema kommer att utvecklas med nya berättelser. Skydda det genom att:
- Versionera schemaändringar (migrationsfiler i Git)
- Skriva reversibla migrationer där det är möjligt
- Uppdatera seeds och exempelqueries så ändringar är testbara
- Granska AI‑genererade migrationer som vilken annan kod som helst
Om du använder en plattform som Koder.ai, dra nytta av guardrails som snapshots och rollback när du itererar på schemaändringar, och exportera källkoden när du behöver djupare anpassning eller traditionell granskning.
Ett enkelt upprepbart arbetsflöde
- Sanera berättelser + skapa 5–10 syntetiska exempel.
- Be AI föreslå entiteter, fält, relationer och constraints.
- Granska med teamet; skriv ner antaganden.
- Implementera migrationer; kör ett litet “story trace”‑test (varje berättelse kan besvaras av modellen).
- Upprepa när berättelser ändras; håll schema och anteckningar synkade.