07 aug. 2025·8 min
Från GPT‑1 till GPT‑4: Historien om OpenAIs GPT‑modeller
Utforska historien om OpenAIs GPT‑modeller, från GPT‑1 till GPT‑4o, och se hur varje generation förbättrade språkförståelse, användbarhet och säkerhet.
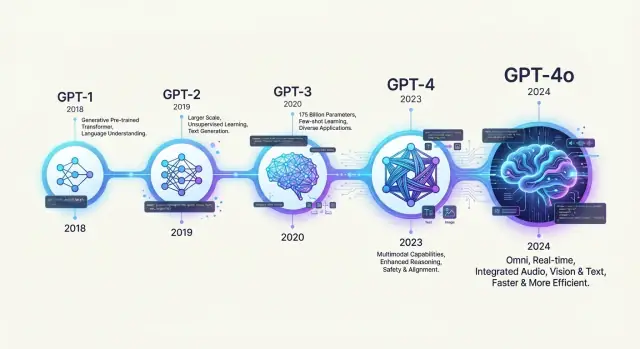
Varför historien om GPT‑modeller spelar roll
GPT‑modeller är en familj av stora språkmodeller byggda för att förutsäga nästa ord i en textsekvens. De läser enorma mängder text, lär sig mönster i hur språk används och använder sedan dessa mönster för att generera ny text, svara på frågor, skriva kod, sammanfatta dokument och mycket mer.
Akronymen i sig förklarar huvudidén:
- Generative – de skapar ny text, inte bara klassificerar befintlig text.
- Pre‑trained – de förtränas på breda data först och anpassas sedan till specifika uppgifter.
- Transformer – de använder transformer‑arkitekturen, som är mycket bra på att modellera långsiktiga beroenden i språk.
Att förstå hur dessa modeller utvecklats hjälper till att förklara vad de kan och inte kan göra, och varför varje generation känns som ett så stort hopp i kapacitet. Varje version speglar specifika tekniska val och avvägningar kring modellstorlek, träningsdata, målsättningar och säkerhetsarbete.
- GPT‑1 introducerade den grundläggande formeln: förtränas på generell text, sedan finjusteras.
- GPT‑2 skalade upp receptet och väckte de första offentliga debatterna om kraftfulla textgeneratorer.
- GPT‑3 visade stark few‑shot och in‑context‑inlärning, levererad främst via en API.
- GPT‑3.5 förvandlade forskningsförmågan till något folk kunde använda varje dag.
- GPT‑4 förbättrade resonemang och lade till multimodala förmågor (text plus bilder).
- GPT‑4o och GPT‑4o mini fokuserade på effektivitet, kostnad och realtidsinteraktion.
Denna artikel följer en kronologisk, översiktlig genomgång: från tidiga språkmodeller och GPT‑1, via GPT‑2 och GPT‑3, till instruction tuning och ChatGPT, och slutligen GPT‑3.5, GPT‑4 och GPT‑4o‑familjen. Längs vägen tittar vi på de viktigaste tekniska trenderna, hur användningsmönster förändrades och vad dessa skiften antyder om framtiden för stora språkmodeller.
Grundvalar: från tidiga språkmodeller till GPT
Innan GPT var språkmodeller redan en central del av NLP‑forskningen. Tidiga system var n‑gram‑modeller, som förutsade nästa ord utifrån ett fast fönster av tidigare ord med hjälp av enkla räkningar. De drev stavningskorrigering och enkel autokomplettering men hade svårt med långa kontexter och data‑sparsitet.
Nästa stora steg var neuronala språkmodeller. Feed‑forward‑nätverk och senare recurrent neural networks (RNNs), särskilt LSTM och GRU, lärde sig distribuerade ordrepresentationer och kunde i princip hantera längre sekvenser. Samtidigt populariserade modeller som word2vec och GloVe ord‑embeddings, vilket visade att osuperviserad inlärning från rå text kunde fånga rik semantisk struktur.
RNNs var dock långsamma att träna, svåra att parallellisera och kämpade fortfarande med mycket långa kontexter. Genombrottet kom med 2017‑artikeln “Attention Is All You Need”, som introducerade transformer‑arkitekturen. Transformers ersatte rekurrens med självuppmärksamhet, vilket gjorde att modellen kunde koppla ihop vilka två positioner som helst i en sekvens direkt och gjorde träningen mycket mer parallell.
Detta öppnade dörren för att skala språkmodeller långt bortom vad RNNs klarade. Forskare insåg att en enda, stor transformer tränad för att förutsäga nästa token på massiva textkorpusar kunde lära sig syntax, semantik och till och med vissa resonemangsfärdigheter utan uppgiftspecifik övervakning.
OpenAIs nyckelidé var att formalisera detta som generativ förträningsmetodik: förtränas först som en stor endast‑dekoder‑transformer på ett internet‑skaligt korpus för att modellera text, och anpassa sedan samma modell till nedströmsuppgifter med minimal ytterligare träning. Detta lovade en enda allmän modell istället för många snäva modeller.
Denna konceptuella förskjutning — från små, uppgiftsspecifika system till en stor, generativt förtränad transformer — lade grunden för den första GPT‑modellen och hela GPT‑serien som följde.
GPT‑1: den första generativt förtränade transformern
GPT‑1 markerade OpenAIs första steg mot den GPT‑serie vi känner idag. Släppt 2018 hade den 117 miljoner parametrar och byggde på transformerarkitekturen från Vaswani et al. 2017. Trots att den var liten jämfört med senare modeller, konkretiserade den den kärnrecept som alla senare GPT‑modeller följde.
Den centrala träningsidén
GPT‑1 tränades med en enkel men kraftfull idé:
- Generativ förträningsfas på ett stort, allmänt textkorpus.
- Uppgiftsspecifik finjustering på mindre annoterade dataset.
För förträning lärde sig GPT‑1 att förutsäga nästa token i text hämtad främst från BooksCorpus och Wikipedia‑liknande källor. Detta mål — nästa‑ord‑prediktion — krävde inga mänskliga etiketter, vilket gjorde att modellen kunde absorbera bred kunskap om språk, stil och fakta.
Efter förträning finjusterades samma modell med övervakad inlärning på klassiska NLP‑benchmarks: sentimentanalys, frågesvar, textuell härledning med mera. Ett litet klassifierhuvud lades på toppen och hela modellen (eller större delen av den) tränades end‑to‑end på varje märkta dataset.
Den metodologiska poängen var att samma förtränade modell kunde anpassas lätt till många uppgifter istället för att träna en separat modell för varje uppgift från början.
Forskningsinsikter från en modest skala
Trots sin relativt lilla storlek gav GPT‑1 flera inflytelserika insikter:
- Förträning som allmänt NLP‑lärande: Studien visade att en generativ modell, tränad på rå text, kunde matcha eller slå uppgiftsspecifika arkitekturer på flera benchmarks efter finjustering.
- Transformers fungerar väl för språk: Tidigare toppmodeller använde ofta rekurrenta eller konvolutionella nätverk. GPT‑1 hjälpte till att validera rena Transformer‑dekodrar som stark arkitektur för språkmodellering.
- Skalningshintar: Resultaten antydde att prestanda fortsatte förbättras med modellstorlek och mer data, vilket pekade mot att mycket större modeller kunde låsa upp nya förmågor.
- Enhetlig arkitektur, många uppgifter: GPT‑1 använde i huvudsak en arkitektur och ett objektiv för många nedströmsproblem, vilket förebådade idén om ”foundation models”.
GPT‑1 visade redan tidiga spår av zero‑shot och few‑shot‑generalisation, även om detta ännu inte var centralt. De flesta utvärderingar förlitade sig fortfarande på finjustering för varje uppgift.
Varför GPT‑1 förblev en forskningsprototyp
GPT‑1 var aldrig avsedd för konsumentdrift eller en bred utvecklar‑API. Flera faktorer höll den inom forskningen:
- Skalgränser: 117M parametrar var små nog att kvalitet och faktamässig korrekthet var tydligt begränsad.
- Snävt utvärderingsfokus: Arbetet centrerade kring NLP‑benchmarks, inte interaktiva assistenter eller produktionsfall.
- Säkerhet och tillförlitlighet inte i förgrunden: Det fanns lite diskussion om missbruk, hallucinationer eller alignment; dessa frågor växte med senare modeller.
- Ingen publik tjänst: OpenAI publicerade papper och kod, men inte en hanterad tjänst eller gränssnitt.
Ändå etablerade GPT‑1 mallen: generativ förträning på stora textkorpusar, följt av enkel uppgiftsspecifik finjustering. Varje senare GPT‑modell kan ses som en skalad, förfinad och alltmer kapabel efterföljare till denna första modell.
GPT‑2: uppskalning och de första offentliga debatterna
GPT‑2, släppt 2019, var den första GPT‑modellen som verkligen fick global uppmärksamhet. Den skalade GPT‑1‑arkitekturen från 117 miljoner parametrar till 1,5 miljarder och visade hur långt enkel uppskalning av en transformer‑språkmodell kunde ta.
Uppskalning: 1,5 miljarder parametrar och vad som förändrades
Arkitektoniskt var GPT‑2 mycket lik GPT‑1: en endast‑dekoder‑transformer tränad med nästa‑token‑prediktion på ett stort webbkorpus. Den stora skillnaden var skalan:
- Parametrar: 117M → 1,5B
- Data: Mycket större och mer diversifierad webbtext
Detta hopp i storlek förbättrade flyt, koherens över längre avsnitt och förmågan att följa prompts utan uppgiftsspecifik träning.
Zero‑shot och few‑shot‑överraskningar
GPT‑2 fick många forskare att omvärdera vad ”bara” nästa‑token‑prediktion kunde göra.
Utan något finjustering kunde GPT‑2 utföra zero‑shot‑uppgifter som:
- Svara på faktabaserade frågor från en prompt
- Översätta korta meningar mellan språk
- Generera sammanfattningar från ett enstaka inmatningsavsnitt
Med några exempel i prompten (few‑shot) förbättrades ofta prestandan ytterligare. Detta antydde att stora språkmodeller kunde representera en bred uppsättning uppgifter internt och använda in‑context‑exempel som ett slags implicit programmeringsgränssnitt.
Gradvis publicering och rädsla för missbruk
Den imponerande genereringskvaliteten utlöste några av de första större offentliga debatterna runt stora språkmodeller. OpenAI höll initialt tillbaka hela 1,5B‑modellen med hänvisning till oro över:
- Fejkade nyheter och desinformation i skala
- Spam och lågkvalitativt innehåll som översvämmar plattformar
- Impersonation och vilseledande chattliknande agenter
I stället antog OpenAI en stegvis publiceringsstrategi:
- Publikt släpp av en mindre 117M‑modell
- Gradvis släpp av 345M och 774M‑varianter
- Full 1,5B‑modell släppt senare 2019
Detta inkrementella tillvägagångssätt var ett av de tidigaste exemplen på en uttrycklig AI‑utrullningspolicy centrerad kring riskbedömning och övervakning.
Gemenskapens experimenterande och förändrade uppfattningar
Även de mindre GPT‑2‑kontakterna ledde till en våg av open‑source‑projekt. Utvecklare finjusterade modeller för kreativt skrivande, kodautokomplettering och experimentella chatbotar. Forskare granskade bias, faktabrister och felaktigheter.
Dessa experiment förändrade hur många såg på stora språkmodeller: från nischade forskningsartefakter till allmänna textmotorer. GPT‑2:s påverkan satte förväntningar — och väckte oro — som formade mottagandet av GPT‑3, ChatGPT och senare GPT‑4‑klass modeller i den fortlöpande utvecklingen av OpenAIs GPT‑familj.
GPT‑3: in‑context‑lärande och API‑eran
GPT‑3 kom 2020 med det iögonfallande antalet 175 miljarder parametrar, över 100× större än GPT‑2. Den siffran fick mycket uppmärksamhet: den antydde rå memoriseringskraft, men viktigare var att den låste upp beteenden som inte setts i skala tidigare.
In‑context‑lärande och promptingenjörskonstens uppkomst
Den definierande upptäckten med GPT‑3 var in‑context‑lärande. Istället för att finjustera modellen på nya uppgifter kunde man klistra in några exempel i prompten:
- Visa ett par engelska–franska meningsexempel så översatte den.
- Ge några Q&A‑par så svarade den på nya frågor.
- Demonstrera en skrivstil så imiterade den den stilen.
Modellen uppdaterade inte sina vikter; den använde prompten som ett slags temporärt träningsset. Detta ledde till begrepp som zero‑shot, one‑shot och few‑shot prompting och startade den första vågen av promptengineering: att noggrant utforma instruktioner, exempel och formatering för att få bättre beteende utan att röra själva modellen.
Från forskningsresultat till kommersiell API
Till skillnad från GPT‑2, som hade nedladdningsbara vikter, gjordes GPT‑3 tillgänglig främst via en kommersiell API. OpenAI lanserade en privat beta av OpenAI API 2020 och positionerade GPT‑3 som en allmän textmotor som utvecklare kunde anropa över HTTP.
Detta skiftade stora språkmodeller från nischade forskningsartefakter till en bred plattform. Istället för att träna egna modeller kunde startups och företag prototypa idéer med en enda API‑nyckel och betala per token.
Tidiga nyttaområden
Tidiga användare utforskade snabbt mönster som senare blev standard:
- Kodhjälp: generera kodsnuttar, regexer eller förslag på refaktorering.
- Skrivstöd: utkast till mejl, bloggposter, marknadsföringstexter och sammanfattningar.
- Prototyping: bygga chatbotar, semantisk sökning och no‑code/low‑code‑verktyg.
GPT‑3 visade att en enda, generell modell — tillgänglig via en API — kunde driva en mängd olika applikationer och banade väg för ChatGPT och senare GPT‑3.5 och GPT‑4‑system.
Instruction tuning, alignment och ChatGPT:s framväxt
Dela Koder.ai med ett team
Bjud in vänner med din referral-länk och få belöningar när de börjar bygga.
Varför instruction tuning behövdes
Bas‑GPT‑3 tränades enbart för att förutsäga nästa token på internet‑skalig text. Det gjorde den bra på att fortsätta mönster, men inte nödvändigtvis på att göra det användaren bad om. Användare behövde ofta formulera prompts noggrant, och modellen kunde:
- Ignorera instruktioner eller byta ämne
- Generera osäkert, biasat eller faktamässigt felaktigt innehåll utan varning
- Framföra nonsens med falsk säkerhet
Forskare kallade detta gap mellan vad användare vill ha och vad modellen gör för alignment‑problemet: modellens beteende var inte pålitligt i linje med mänskliga intentioner, värderingar eller säkerhetsförväntningar.
InstructGPT: lära sig följa instruktioner
OpenAIs InstructGPT (2021–2022) var ett viktigt genombrott. Istället för att bara träna på rå text lade man till två nyckelsteg ovanpå GPT‑3:
- Supervised fine‑tuning (SFT): Mänskliga bedömare skrev idealiska svar på många prompts (t.ex. ”Förklara kvantberäkning enkelt”). Modellen finjusterades för att imitera dessa exempel.
- Reinforcement learning from human feedback (RLHF): Bedömare rangordnade flera modelloutputs för samma prompt. En ”belöningsmodell” lärde sig dessa preferenser, och basmodellen optimerades (via policy gradients) för att producera högre rankade svar.
Detta gav modeller som:
- Följer tydliga instruktioner mer pålitligt
- Vägrar farliga förfrågningar oftare
- Är i allmänhet hjälpsammare och hövligare som standard
I användarstudier föredrog man ofta mindre InstructGPT‑modeller framför mycket större bas‑GPT‑3‑modeller, vilket visade att alignment och gränssnitts‑kvalitet kan vara viktigare än rå skala.
Från InstructGPT till ChatGPT
ChatGPT (slutet av 2022) byggde vidare på InstructGPT‑tanken och anpassade den för flerspårig dialog. Det var i grunden en GPT‑3.5‑klass modell finjusterad med SFT och RLHF på konversationsdata i stället för enstaka instruktioner.
Istället för ett API eller en utvecklarinriktad lekplats lanserade OpenAI ett enkelt chattgränssnitt:
- Användare kunde prata med modellen som i en meddelandeapp
- Kontext över flera turer gjorde det konversationellt och ihållande
- Folk kunde korrigera modellen, förfina frågor och utforska idéer iterativt
Detta sänkte tröskeln för icke‑tekniska användare. Ingen promptengineering‑expertis, ingen kod — skriv bara och få svar.
Resultatet blev ett mainstream‑genombrott: teknik som byggts upp under årtionden av transformer‑forskning och alignment‑arbete blev plötsligt tillgänglig för vem som helst med en webbläsare. Instruction tuning och RLHF gjorde systemet tillräckligt samarbetsvilligt och säkert för brett släpp, medan chattgränssnittet förvandlade en forskningsmodell till en global produkt och vardagsverktyg.
GPT‑3.5: från forskningssystem till vardagsverktyg
GPT‑3.5 markerade ögonblicket då stora språkmodeller slutade vara mestadels en forskningsnyfikenhet och började kännas som vardagstjänster. Den låg mellan GPT‑3 och GPT‑4 i kapacitet, men dess verkliga betydelse låg i hur tillgänglig och praktisk den blev.
En brygga mellan GPT‑3 och GPT‑4
Tekniskt förfinade GPT‑3.5 kärnarkitekturen hos GPT‑3 med bättre träningsdata, uppdaterad optimering och omfattande instruction tuning. Modeller i serien — inklusive text-davinci-003 och senare gpt-3.5-turbo — tränades för att bättre följa naturliga språk‑instruktioner, svara säkrare och upprätthålla koherent flerspårig konversation.
Det gjorde GPT‑3.5 till en naturlig språngbräda mot GPT‑4. Den förhandsvisade mönster som skulle definiera nästa generation: starkare resonemang i vardagliga uppgifter, bättre hantering av längre prompts och stabilare dialogbeteende, utan hela hoppet i kostnad och komplexitet som GPT‑4 innebar.
ChatGPT och konversations‑AI:s uppsving
Den första publika utgåvan av ChatGPT i slutet av 2022 drevs av en GPT‑3.5‑klass modell finjusterad med RLHF. Detta förbättrade dramatiskt hur modellen:
- Höll sig till ämnet över flera turer
- Bad om förtydliganden i stället för att gissa
- Följde instruktioner formulerade i vardagligt språk
För många var ChatGPT deras första praktiska möte med en stor språkmodell, och den satte förväntningar på hur ”AI‑chatt” skulle kännas.
gpt‑3.5‑turbo och varför den blev standard
När OpenAI släppte gpt-3.5-turbo via API erbjöd den en attraktiv kombination av pris, hastighet och kapacitet. Den var billigare och snabbare än tidigare GPT‑3‑modeller och gav samtidigt bättre instruktionefterlevnad och dialogkvalitet.
Denna balans gjorde gpt-3.5-turbo till standardvalet för många applikationer:
- Startups använde den för kundsupport, innehållsgenerering och interna verktyg.
- Utvecklare använde den för kodförklaringar, inline‑dokumentation och enkel kodsyntes.
- Produktteam integrerade den i produktivitetsappar för funktioner som autocompletion, sammanfattning och utkast.
GPT‑3.5 spelade alltså en avgörande transitiroll: tillräckligt kraftfull för verkliga produkter i skala, ekonomisk nog att användas brett och tillräckligt anpassad till mänskliga instruktioner för att kännas användbar i vardagliga arbetsflöden.
GPT‑4: multimodala modeller och starkare resonemang
Skicka det du precis designade
Driftsätt och hosta din app när du är redo att dela den.
GPT‑4, släppt av OpenAI 2023, markerade ett skifte från ”stor textmodell” till en allmän assistent med starkare resonemangsförmåga och multimodala ingångar.
Från GPT‑3 till GPT‑4: vad ändrades i praktiken
Jämfört med GPT‑3 och GPT‑3.5 fokuserade GPT‑4 mindre på ren parameterstorlek och mer på:
- Resonemang och tillförlitlighet: Bättre resultat på prov och benchmarks (juridiska prov, olympiadliknande problem, kodutmaningar) och färre uppenbara logiska fel.
- Styrbarhet: Systemmeddelanden lät utvecklare ange stil, roll och begränsningar mer direkt.
- Längre kontext: Vissa GPT‑4‑varianter hanterar mycket längre prompts, vilket möjliggör analys på dokumentnivå och flerstegsarbetsflöden.
Flaggskeppsfamiljen inkluderade gpt‑4 och senare gpt‑4‑turbo, som syftade till att leverera liknande eller bättre kvalitet till lägre kostnad och latens.
Multimodalitet: förstå mer än text
En av huvudfunktionerna i GPT‑4 var dess multimodala förmåga: utöver textinput kunde den ta emot bilder. Användare kunde:
- Ställa frågor om diagram, grafer eller handskrivna anteckningar
- Få beskrivningar av skärmbilder från användargränssnitt
- Använda bilder för att styra kod, design eller datautdrag
Detta gjorde att GPT‑4 kändes mindre som enbart en textmodell och mer som ett allmänt resonemangsverktyg som kommunicerar via språk.
Säkerhet, alignment och kontroll
GPT‑4 tränades och finjusterades också med större fokus på säkerhet och alignment:
- Utökad RLHF för att minska skadliga eller vilseledande utsagor
- Mer förfinade innehållspolicys och vägran‑beteenden
- Bättre verktyg för att kontrollera ton, ordrikedom och persona via systempromptar och API‑inställningar
Modeller som gpt‑4 och gpt‑4‑turbo blev standardval för allvarliga produktionsanvändningar: kundsupportautomation, kodassistenter, utbildningsverktyg och kunskapssökning. GPT‑4 banade väg för senare varianter som GPT‑4o och GPT‑4o mini, som drev effektivitet och realtidsinteraktion vidare samtidigt som de ärvde mycket av GPT‑4:s resonemangs‑ och säkerhetsframsteg.
GPT‑4o och GPT‑4o mini: effektivitet och realtidsanvändning
GPT‑4o ("omni") markerar ett skifte från ”mest kapabel till vilket pris som helst” mot ”snabbt, prisvärt och alltid tillgängligt”. Den är designad för att leverera GPT‑4‑nivå kvalitet samtidigt som den är långt billigare att köra och tillräckligt snabb för live, interaktiva upplevelser.
Vad GPT‑4o är optimerad för
GPT‑4o förenar text, vision och ljud i en enda modell. Istället för att koppla ihop separata komponenter hanterar den inbyggt:
- Textchatt och kodning
- Bildförståelse (skärmbilder, foton, diagram)
- Realtidsljud in och ut
Denna integration minskar latens och komplexitet. GPT‑4o kan svara i nära realtid, strömma svar medan den tänker och sömlöst växla mellan modaliteter i en konversation.
Hastighet, kostnad och vardaglig åtkomst
Ett viktigt designmål för GPT‑4o var effektivitet: bättre prestanda per krona och lägre latens per förfrågan. Det tillåter utvecklare och tjänster att:
- Erbjuda billigare eller gratis nivåer samtidigt som kvaliteten hålls hög
- Driva högvolymsprodukter (chatt, support, utbildning) utan fördyrande kostnader
- Köra mer interaktiva funktioner som strömmande svar och live‑korrigeringar
Resultatet är att funktioner som tidigare reserverats för dyra API:er nu blir tillgängliga för studenter, hobbyister, små startups och team som testar AI för första gången.
GPT‑4o mini: liten, snabb och överallt
GPT‑4o mini skjuter tillgängligheten ännu längre genom att byta bort en del toppkapacitet för hastighet och extremt låg kostnad. Den passar bra för:
- Alltid‑på‑assistenter och bakgrundsagenter
- Enkla chatbotar, dirigeringsflöden och sammanfattningstjänster
- Lättviktsverktyg som behöver snabba, billiga svar
Eftersom 4o mini är ekonomisk kan utvecklare bädda in den i många fler platser — i appar, kundportaler, interna verktyg eller till och med på lågbudgettjänster — utan att oroa sig lika mycket för användningskostnader.
Tillsammans utvidgar GPT‑4o och GPT‑4o mini avancerade GPT‑funktioner till realtids-, konversations‑ och multimodala användningsfall och breddar vem som praktiskt kan bygga med — och dra nytta av — toppmoderna modeller.
Tekniska trender som format GPT‑utvecklingen
Flera tekniska strömningar löper genom varje generation av GPT‑modeller: skala, feedback, säkerhet och specialisering. Tillsammans förklarar de varför varje nytt släpp känns kvalitativt annorlunda, inte bara större.
Skalningslagar och mönstret “mer data, mer beräkning, bättre modeller”
En viktig upptäckt bakom GPT‑framsteg är skalningslagar: när du ökar modellparametrar, datasetstorlek och beräkning i balanserad takt tenderar prestandan förbättras jämnt över många uppgifter.
Tidiga modeller visade att:
- Större transformers tränade på mer diversifierad, högkvalitativ text generaliserar bättre.
- Många förmågor (översättning, kodning, resonemangsliknande beteenden) uppstår när skalan passerar vissa trösklar, även utan uppgiftsspecifik träning.
Detta ledde till en systematisk strategi:
- Planera modellstorlek och datasetstorlek tillsammans, baserat på empiriska skalningskurvor.
- Använd allt större, deduplicerade och filtrerade korpusar som blandar webbdata, böcker, kod och proprietära data.
- Optimera träningseffektivitet (bättre parallellism, kärnor, hårdvaruanvändning) för att göra varje steg i uppskalningen ekonomiskt genomförbar.
Reinforcement learning from human feedback (RLHF)
Råa GPT‑modeller är kraftfulla men likgiltiga inför användarens förväntningar. RLHF formar dem till hjälpsamma assistenter:
- Samla mänskligt skrivna eller mänskligt betygsatta svar på prompts.
- Träna en belöningsmodell som förutsäger vilka svar människor föredrar.
- Använd förstärkningsinlärning (ofta Proximal Policy Optimization) så att basmodellen lär sig generera hög‑belöning svar.
Över tiden utvecklade detta sig till instruction tuning + RLHF: först finjustera på många instruktion–svar‑par, sedan tillämpa RLHF för att förfina beteendet. Denna kombination ligger bakom ChatGPT‑stil interaktioner.
Säkerhetsutvärderingar och innehållsfilter
När kapaciteterna växte ökade också behovet av systematiska säkerhetsutvärderingar och policy‑egenskaper.
Tekniska mönster inkluderar:
- Dedikerad red‑teaming och automatiserade tester för missbruks‑scenarier (t.ex. farliga råd, otillåtna innehåll).
- Säkerhets‑tunade varianter av modellen, optimerade för att vägra eller omdirigera riskfyllda förfrågningar.
- Innehållsfilter som körs parallellt med modellen: klassificerare och heuristiker som kontrollerar prompts och outputs mot säkerhetspolicys innan leverans.
Dessa mekanismer itereras upprepade gånger: nya utvärderingar upptäcker felmodeller, vilket återförs till träningsdata, belöningsmodeller och filter.
Från en gigantisk modell till anpassade modellfamiljer
Tidigare släpp centrerade kring en enda ”flaggskeppsmodell” med ett fåtal mindre varianter. Med tiden försköts trenden mot familjer av modeller optimerade för olika begränsningar och användningsfall:
- High‑end‑modeller för komplexa resonemang och multimodala uppgifter.
- Lättare, billigare modeller (såsom ”mini”‑varianter) för realtidsinteraktion, storskalig drift eller edge‑användning.
- Specialiserade modeller finjusterade för kodning, moderering eller företagsarbetsflöden.
Under ytan reflekterar detta en mogen stack: delade basarkitekturer och träningspipeline, följt av målinriktad finjustering och säkerhetslager för att producera en portfölj snarare än en monolit. Denna multi‑modellstrategi är nu en definierande teknisk och produkttrend i GPT‑utvecklingen.
Hur GPT‑modeller förändrat AI‑användning och tillämpningar
Gå live på din domän
Publicera ditt projekt på en egen domän för en mer professionell lansering.
GPT‑modeller förvandlade språkbaserad AI från ett nischat forskningsverktyg till infrastruktur som många människor och organisationer bygger på.
Nya byggklossar för utvecklare
För utvecklare fungerar GPT‑modeller som en flexibel ”språkmotor”. Istället för att hårdkoda regler skickar man naturliga språkpromptar och får tillbaka text, kod eller strukturerade outputs.
Detta har förändrat hur mjukvara designas:
- Prototyper kan byggas på timmar med enkla API‑anrop.
- Appar lägger ut komplexa uppgifter som sammanfattning, översättning och kodgenerering till modellen.
- Nya mönster som agenter, verktygsanvändning (function calling) och retrieval‑augmented generation har uppstått.
Som ett resultat förlitar sig många produkter numera på GPT som en kärnkomponent snarare än en tilläggsfunktion.
Hur företag integrerar GPT
Företag använder GPT‑modeller både internt och i kundnära produkter.
Internt automatiserar team triage för support, utkastar mejl och rapporter, hjälper till med programmering och QA samt analyserar dokument och loggar. Externt driver GPT chatbotar, AI‑co‑piloter i produktivitetsverktyg, kodassistenter, innehålls‑ och marknadsföringsverktyg samt domänspecifika co‑piloter för finans, juridik, vård med mera.
API:er och hostade produkter gör det möjligt att lägga till avancerade språkfunktioner utan att hantera infrastruktur eller träna modeller från grunden, vilket sänker tröskeln för små och medelstora organisationer.
Effekter på forskning, utbildning och kreativt arbete
Forskare använder GPT för att generera idéer, skapa kod för experiment, utarbeta manus och utforska tankar i naturligt språk. Lärare och studenter använder GPT för förklaringar, träningsfrågor, handledning och språkhjälp.
Skribenter, designers och kreatörer använder GPT för disposition, idégenerering, världsskapande och finslipning av utkast. Modellen fungerar snarare som en medarbetare som snabbar upp utforskande än som en ersättning.
Bekymmer och avvägningar
Spridningen av GPT‑modeller väcker också allvarliga frågor. Automatisering kan förändra eller ersätta vissa jobb samtidigt som efterfrågan på nya kompetenser ökar.
Eftersom GPT tränas på mänskliga data kan den återspegla och förstärka sociala bias om den inte begränsas omsorgsfullt. Den kan också generera trovärdig men felaktig information eller missbrukas för att producera spam, propaganda eller annat vilseledande innehåll i skala.
Dessa risker har lett till arbete med alignment‑tekniker, användningspolicyer, övervakning och verktyg för upptäckt och proveniens. Att balansera kraftfulla nya applikationer med säkerhet, rättvisa och förtroende förblir en öppen utmaning i takt med att GPT‑modeller fortsätter utvecklas.
Framtida riktningar och öppna frågor för GPT‑modeller
När GPT‑modeller blir mer kapabla flyttas kärnfrågorna från kan vi bygga dem? till hur bör vi bygga, driftsätta och styra dem?
Tekniska fronter
Effektivitet och åtkomst. GPT‑4o och GPT‑4o mini antyder en framtid där högkvalitativa modeller körs billigt, på mindre servrar och så småningom på personliga enheter. Nyckelfrågor:
- Hur långt kan vi krympa modeller utan att förlora resonemangskvalitet?
- Kan träning och inferens bli tillräckligt energieffektiva för hållbar skalning?
Personalisation utan överanpassning. Användare vill ha modeller som kommer ihåg preferenser, stil och arbetsflöden utan att läcka data eller bli partiska mot en persons åsikter. Öppna frågor inkluderar:
- Hur separerar vi kärnmodellkunskap från användarspecifik anpassning?
- Hur personaliserar vi säkert över många enheter och appar?
Tillförlitlighet och resonemang. Även toppmodeller hallucinerar, misslyckas tyst eller beter sig oförutsägbart vid distributionell förskjutning. Forskning undersöker:
- Metoder för verifierbart resonemang och verktygsstött kontroll
- Sätt att representera osäkerhet och säga "jag vet inte" på lämpligt sätt
Samhälleliga och styrningsutmaningar
Säkerhet och alignment i skala. När modeller får verktyg och automation ökar behovet av att alignera dem med mänskliga värderingar — och att behålla alignment över kontinuerliga uppdateringar. Detta inkluderar kulturell pluralism: vems värderingar och normer kodas, och hur hanteras oenigheter?
Reglering och standarder. Regeringar och branschgrupper utarbetar regler för transparens, dataanvändning, watermarking och incidentrapportering. Frågor som kvarstår:
- Vad bör vara obligatoriskt (revisioner, red‑teaming, säkerhetsutvärderingar)?
- Hur harmoniserar vi regler över jurisdiktioner så att både innovation och säkerhet gynnas?
En balanserad utsikt
Framtida GPT‑system kommer sannolikt att bli mer effektiva, mer personaliserade och mer tätt integrerade i verktyg och organisationer. Parallellt kan vi förvänta oss mer formella säkerhetsrutiner, oberoende utvärdering och tydligare användarkontroller. Historien från GPT‑1 till GPT‑4 visar på stadig teknisk framgång, men också att tekniska framsteg måste gå i takt med styrning, samhällelig input och noggrann mätning av verkliga effekter.
Vanliga frågor
Vad är en GPT‑modell i enkla ord?
GPT (Generative Pre-trained Transformer) är stora neurala nätverk som tränas för att förutsäga nästa ord i en textsekvens. Genom att göra detta i stor skala på massiva textkorpusar lär de sig grammatik, stil, fakta och resonemangsmönster. När de väl är tränade kan de:
- Generera ny text (berättelser, mejl, kod)
- Svara på frågor och förklara koncept
- Sammanfatta och översätta dokument
- Fungera som konversationsassistenter eller co‑piloter i appar
Varför är historien om GPT‑modeller viktig för dagens användare?
Att känna till historiken förtydligar:
- Varför kapaciteterna ökade mellan versionerna (t.ex. GPT‑2 → GPT‑3 → GPT‑4)
- Vad varje modell är bra respektive dålig på (resonemang, kontextlängd, multimodalitet)
- Hur säkerhet och anpassning utvecklades (från rå textgenerering till ChatGPT‑stil assistenter)
- Varför dagens verktyg ser ut som de gör, från API:er till chattgränssnitt och ”mini”‑modeller
Det hjälper också att skapa realistiska förväntningar: GPT är kraftfulla mönsterlärande system, inte ofelbara orakel.
Vilka är de stora milstolparna från GPT‑1 till GPT‑4o?
Viktiga milstolpar inkluderar:
Hur förändrar instruction tuning och RLHF GPT‑beteende?
Instruction tuning och RLHF gör modeller mer i linje med vad människor faktiskt vill ha.
- Instruction tuning (SFT): Finjusterar modellen på många prompt–svar‑par skrivna av människor så att den lär sig följa instruktioner tydligare.
- RLHF: Tränar en belöningsmodell utifrån mänskliga rangordningar av olika outputs och optimerar sedan GPT‑modellen för att generera högre rankade svar.
Tillsammans:
Vad förändrades egentligen från GPT‑3.5 till GPT‑4?
GPT‑4 skiljer sig på flera sätt:
- Resonemang: Bättre på prov, koduppgifter och komplexa instruktioner.
- Styrbarhet: Systemmeddelanden låter utvecklare ange ton, roll och begränsningar.
- Kontextlängd: Vissa varianter hanterar mycket längre ingångar för dokument‑skaliga uppgifter.
- Multimodalitet: Kan ta emot bilder som input, vilket möjliggör uppgifter som diagramanalys eller granskning av UI‑skärmbilder.
Dessa förändringar driver GPT‑4 från att vara en textgenerator mot en allmän assistent.
Vad passar GPT‑4o och GPT‑4o mini bäst för?
GPT‑4o och GPT‑4o mini är optimerade för hastighet, kostnad och realtidsanvändning snarare än maximal toppförmåga.
- GPT‑4o: En enhetlig modell som hanterar text, bild och ljud, med låg latens lämplig för livechatt, röstassistenter och interaktiva verktyg.
- GPT‑4o mini: Mindre och billigare, idealisk för:
Hur integrerar utvecklare och företag GPT‑modeller i produkter?
Utvecklare använder GPT‑modeller för att:
- Bygga chatbots och co‑piloter (support, försäljning, interna verktyg)
- Skapa och sammanfatta mejl, rapporter, ärenden och dokumentation
- Generera och förklara kod, tester och dataomvandlingar
- Implementera översättning, sentimentanalys och klassificering utan skräddarsydd ML
- Prototypa komplexa arbetsflöden via verktygsanrop och retrieval‑augmented generation
API‑åtkomst gör det möjligt att integrera dessa funktioner utan att träna eller drifta egna stora modeller.
Vilka är de viktigaste begränsningarna och riskerna med dagens GPT‑modeller?
Dagens GPT‑modeller har viktiga begränsningar:
- Hallucinationer: De kan producera övertygande men felaktig eller fabricerad information.
- Bias: Träningsdata kan innehålla sociala och kulturella bias som återkommer i utslagen.
- Kontextkänslighet: Prestandan kan försämras på mycket långa, röriga eller out‑of‑distribution‑ingångar.
- Brist på verkligen förståelse: De modellerar mönster i text snarare än förankrad världskunskap.
Vilka framtida riktningar för GPT‑modeller lyfter artikeln fram?
Flera trender kommer sannolikt att forma framtida GPT‑system:
- Effektivitet: Mindre, billigare modeller med nästan GPT‑4‑kvalitet, kanske körbara på personliga eller edge‑enheter.
- Personalisation: Säkrare sätt att anpassa modeller efter individuella preferenser utan att läcka eller överanpassa privata data.
- Pålitlighet: Bättre hantering av osäkerhet, verifierbart resonemang och att uttrycka ”jag vet inte” när det är lämpligt.
Hur bör team tänka kring att använda GPT‑modeller säkert och effektivt?
Artikeln ger praktiska riktlinjer:
- Välj rätt nivå: Använd högpresterande modeller (t.ex. GPT‑4‑klass) för komplexa resonemang; använd 4o mini‑liknande modeller för högvolyms, enkla uppgifter.
- Lägg lager för säkerhet: Kombinera anpassade modeller med innehållsfilter, användningspolicyer och mänsklig granskning där insatserna är höga.
- Behandla outputs som utkast eller förslag, inte sanning; lägg till retrieval och kontrollsteg för kritisk information.