01 sep. 2025·8 min
Från idé till driftsatt app i ett AI‑assisterat arbetsflöde
En praktisk slut‑till‑slut‑berättelse som visar hur du går från app‑idé till driftsatt produkt med ett AI‑assisterat arbetsflöde — steg, promptar och kontroller.
En praktisk slut‑till‑slut‑berättelse som visar hur du går från app‑idé till driftsatt produkt med ett AI‑assisterat arbetsflöde — steg, promptar och kontroller.
Föreställ dig en liten, användbar appidé: en "Queue Buddy" som låter en kafémedarbetare trycka på en knapp för att lägga till en kund i en väntelista och automatiskt skicka ett SMS när bordet är klart. Framgångsmetriska är enkel och mätbar: minska genomsnittliga väntetids‑förvirrings‑samtal med 50 % på två veckor, samtidigt som introduktionen för personalen hålls under 10 minuter.
Det här är andan i den här artikeln: välj en tydlig, avgränsad idé, definiera vad som är "bra", och gå sedan från koncept till live‑driftsättning utan att konstant byta verktyg, dokument och mentala modeller.
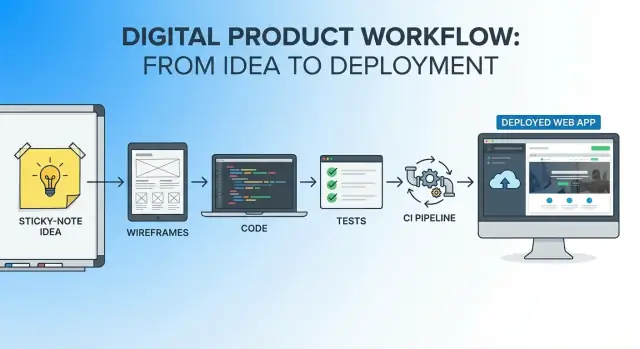
Ett enda arbetsflöde är en kontinuerlig tråd från första meningen om idén till första produktionsreleasen:
Du kommer fortfarande använda flera verktyg (editor, repo, CI, hosting), men du behöver inte "starta om" projektet i varje fas. Samma berättelse och begränsningar följer med.
AI är mest värdefull när den:
Men den äger inte produktbesluten. Du gör det. Arbetsflödet är utformat så att du alltid verifierar: Flyttar denna ändring metriska? Är det säkert att släppa?
I de följande sektionerna går du steg för steg:
I slutet bör du ha ett upprepbart sätt att gå från "idé" till "live‑app" samtidigt som du håller scope, kvalitet och lärande tätt samman.
Innan du ber AI om skärmar, API:er eller databas‑tabeller behöver du ett klart mål. En liten tydlighet här sparar timmar av "nästan rätt"‑svar senare.
Du bygger en app eftersom en specifik grupp människor gång på gång stöter på samma friktion: de kan inte slutföra en viktig uppgift snabbt, pålitligt eller med förtroende med de verktyg de har. Målet med version 1 är att ta bort ett smärtsamt steg i det arbetsflödet — utan att försöka automatisera allt — så att användare kan gå från "jag behöver göra X" till "X är gjort" på några minuter, med en tydlig logg över vad som hände.
Välj en primär användare. Sekundära användare kan vänta.
Antaganden är där bra idéer tyst misslyckas — gör dem synliga.
Version 1 ska vara en liten vinst du kan leverera.
Ett lättviktigt kravdokument (tänk: en sida) är bron mellan "cool idé" och "byggbar plan". Det håller dig fokuserad, ger din AI‑assistent rätt kontext och hindrar att första versionen växer till ett månadslångt projekt.
Håll det kort och lätt att skumma. En enkel mall:
Skriv max 5–10 funktioner, formulerade som utfall. Rangordna dem:
Den här rankningen styr också AI‑genererade planer och kod: "Implementera bara måste‑ha först."
För de 3–5 viktigaste funktionerna, lägg till 2–4 acceptanskriterier vardera. Använd enkelt språk och testbara uttalanden.
Exempel:
Avsluta med en kort "Öppna frågor"‑lista — saker du kan svara på med en chatt, ett kundsamtal eller en snabb sökning.
Exempel: "Behöver användare Google‑login?" "Vad är minsta data vi måste lagra?" "Behöver vi admin‑godkännande?"
Detta dokument är inte pappersarbete; det är en gemensam sanningskälla du uppdaterar under byggets gång.
Innan du ber AI generera skärmar, få produktens berättelse rak: vad användaren försöker göra, vad "framgång" ser ut som och var det kan gå fel. En snabb reseskiss håller alla i fas: vad användaren gör, vad som krävs för värde och riskområden.
Börja med happy path: den enklaste sekvensen som levererar huvudvärdet.
Exempelflöde (generiskt):
Lägg sedan till några edge cases som är troliga och kostsamma om de hanteras fel:
Du behöver inte en stor diagram. En numrerad lista plus anteckningar räcker för att styra prototyp och kodgenerering.
Skriv en kort "jobb att göra" för varje skärm. Håll det resultatfokuserat snarare än UI‑fokuserat.
Om du arbetar med AI blir den här listan utmärkt promptmaterial: "Generera en Dashboard som stödjer X, Y, Z och inkluderar tom‑/laddnings‑/fel‑tillstånd."
Håll detta på "servett‑schema"‑nivå — tillräckligt för att stödja skärmar och flöden.
Notera relationer (User → Projects → Tasks) och allt som påverkar behörigheter.
Markera punkter där misstag bryter förtroendet:
Detta handlar inte om över‑engineering — det handlar om att undvika överraskningar som förvandlar en "fungerande demo" till ett support‑problem efter lansering.
Version 1‑arkitektur ska göra en sak bra: låta dig leverera den minsta användbara produkten utan att låsa fast dig. En bra regel är "ett repo, en deploybar backend, en deploybar frontend, en databas" — och lägg till extra delar bara när ett krav kräver det.
För en typisk webbapp är en rimlig standard:
Håll antalet tjänster lågt. För v1 är en "modulär monolit" (välorganiserad kodbas, men en backend‑tjänst) oftast enklare än mikrotjänster.
Om du föredrar en AI‑först‑miljö där arkitektur, uppgifter och genererad kod hålls tätt ihop kan plattformar som Koder.ai passa bra: beskriv v1‑omfånget i chatten, iterera i "planning mode" och generera sedan ett React‑frontend med en Go + PostgreSQL‑backend — samtidigt som du behåller granskning och kontroll.
Innan du genererar kod, skriv en liten API‑tabell så att du och AI har samma mål. Exempelformat:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }Lägg till anteckningar för statuskoder, feleformat (t.ex. { error: { code, message } }) och eventuell paginering.
Om v1 kan vara offentlig eller enkla användare, hoppa över auth och skicka snabbare. Om du behöver konton, använd en hanterad leverantör (e‑post magic link eller OAuth) och håll behörigheterna enkla: "user owns their records." Undvik komplexa roller tills verklig användning kräver det.
Dokumentera några praktiska begränsningar:
Dessa anteckningar styr AI‑assisterad kodgenerering mot något deploybart, inte bara funktionellt.
Den snabbaste sättet att döda momentum är att diskutera verktyg i en vecka och ändå inte ha körbar kod. Målet här är enkelt: nå en "hello app" som startar lokalt, har en synlig skärm och kan ta emot en förfrågan — samtidigt som det är tillräckligt litet för att varje ändring ska vara lätt att granska.
Ge AI en snäv prompt: ramverk, grundläggande sidor, ett stub‑API och vilka filer du förväntar dig. Du söker förutsägbara konventioner, inte smarta lösningar.
En bra första passning är en struktur som:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Om du använder ett singel‑repo, be om grundläggande routes (t.ex. / och /settings) och ett API‑endpoint (t.ex. GET /health eller GET /api/status). Det räcker för att bevisa att rördragningen fungerar.
Om du använder Koder.ai är detta också en naturlig startpunkt: be om ett minimalt "web + api + database‑redo" skelett, och exportera källan när du är nöjd med struktur och konventioner.
Håll UI:et avsiktligt tråkigt: en sida, en knapp, ett anrop.
Exempelbeteende:
Detta ger en omedelbar feedback‑loop: om UI laddar men anropet misslyckas vet du exakt var du ska leta (CORS, port, routing, nätverksfel). Motstå att lägga till auth, databaser eller komplex state här — det kommer efter att skelettet är stabilt.
Skapa en .env.example dag ett. Det förhindrar "funkar på min maskin"‑problem och gör onboardingen smärtfri.
Exempel:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Gör sedan README körbar på under en minut:
.env.example till .envBehandla denna fas som att lägga rena grundlinjer. Comitta efter varje litet framsteg: "init repo", "lägg till web shell", "lägg till api health endpoint", "koppla web till api." Små commits gör AI‑assisterad iteration säkrare: om en genererad ändring går fel kan du återställa utan att förlora en dags arbete.
När skelettet körs end‑to‑end, motstå frestelsen att "göra allt klart". Bygg istället en smal vertikal skiva som berör databasen, API och UI (om relevant), och repetera. Tunna skivor håller granskningar snabba, buggar små och AI‑assistansen lättare att verifiera.
Välj den modell appen inte kan fungera utan — ofta "tingen" användaren skapar eller hanterar. Definiera den tydligt (fält, obligatoriskt vs valfritt, defaults), och lägg till migrationer om du använder relationsdatabas. Håll första versionen tråkig: undvik smart normalisering och prematur flexibilitet.
Om du använder AI för att skissa modellen, be den motivera varje fält och default. Allt den inte kan förklara i en mening bör troligen inte vara med i v1.
Skapa bara de endpoints som krävs för första användarresan: vanligtvis create, read och en minimal update. Placera validering nära gränsen (request DTO/schema), och gör reglerna explicita:
Validering är en del av funktionen, inte polish — det förhindrar smutsiga data som bromsar dig senare.
Behandla felmeddelanden som UX för debugging och support. Returnera klara, handlingsbara meddelanden (vad gick fel och hur åtgärdar man det) samtidigt som tekniska detaljer hålls undan från klienten. Logga teknisk kontext server‑side med en request‑ID så att du kan spåra incidenter utan gissningar.
Be AI föreslå inkrementella PR‑stora ändringar: en migration + en endpoint + ett test i taget. Granska diffar som om det vore en kollegas arbete: kolla namngivning, edge cases, säkerhetsantaganden och om ändringen faktiskt stödjer användarens "lilla vinst". Om den lägger till extra funktioner, skär bort dem och fortsätt.
Version 1 behöver inte företagsnivå‑säkerhet — men den måste undvika förutsägbara fel som förvandlar en lovande app till ett support‑maraton. Målet här är "tillräckligt säkert": förhindra felinmatning, begränsa åtkomst som standard och lämna en spårbarhet när något går fel.
Behandla varje gräns som otrustad: formulärfält, API‑payloads, query‑parametrar och interna webhooks. Validera typ, längd och tillåtna värden, och normalisera data (trimma strängar, konvertera case) innan lagring.
Några praktiska default:
Be AI att inkludera valideringsregler explicit (t.ex. "max 140 tecken" eller "måste vara en av: …") istället för att bara skriva "validera input".
En enkel behörighetsmodell räcker ofta för V1:
Gör ownership‑kontroller centrala och återanvändbara (middleware/policy‑funktioner) så att du inte sprider "if userId == …" över hela kodbasen.
Bra loggar svarar: vad hände, för vem och var? Inkludera:
update_project, project_id)Logga händelser, inte hemligheter: skriv aldrig lösenord, tokens eller fullständiga betalningsuppgifter.
Innan du ropar appen "tillräckligt säker", kontrollera:
Testning handlar inte om att jaga perfekt täckning — det handlar om att förhindra fel som skadar användare, bryter förtroende eller skapar dyra brandkårsutryckningar. I ett AI‑assisterat arbetsflöde fungerar tester också som ett "kontrakt" som håller genererad kod i linje med vad du faktiskt menade.
Innan du lägger till mycket täckning, identifiera var misstag skulle bli kostsamma. Vanliga högriskområden inkluderar pengar/krediter, behörigheter, datatransformationer och edge‑case‑validering. Skriv enhetstester för dessa först. Håll dem små och specifika: givet input X förväntas output Y (eller ett fel). Om en funktion har för många grenar att testa rent, är det en signal att den bör förenklas.
Enhetstester fångar logikfel; integrationstester fångar "kopplings"‑fel — routes, databas‑anrop, auth‑kontroller och UI‑flödet som fungerar tillsammans.
Välj det kärn‑journey‑som‑levererar‑värde (happy path) och automatisera:
Ett par stabila integrationstester förhindrar ofta fler incidenter än dussintals små tester.
AI är bra på att generera test‑stommar och lista edge cases du kan missa. Be om:
Granska sedan varje genererad assertion. Tester ska verifiera beteende, inte implementation. Om ett test fortfarande passerar efter en bugg gör det inte sitt jobb.
Välj ett modest mål (t.ex. 60–70 % på kärnmoduler) och använd det som ett skydd, inte ett trofé. Fokusera på stabila, repetitiva tester som kör snabbt i CI och felar av rätt anledningar. Fladdriga tester urholkar förtroendet — och när folk slutar lita på sviten slutar den skydda dig.
Automatisering är där ett AI‑assisterat arbetsflöde slutar vara "fungerar på min laptop" och blir något du kan leverera med förtroende. Målet är inte fint verktyg — det är repeterbarhet.
Välj ett kommando som ger samma resultat lokalt och i CI. För Node kan det vara npm run build; för Python en make build; för mobil en specifik Gradle/Xcode‑steg.
Separera också utvecklings‑ och produktionskonfig tidigt. En enkel regel: dev‑defaults är bekväma; produktions‑defaults är säkra.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
En linter fångar riskabla mönster (unused variables, osäkra async‑anrop). En formatterare förhindrar "stildebatter" från att bli skräniga diffar i granskningar. Håll reglerna måttliga för v1, men verkställ dem konsekvent.
En praktisk gate‑ordning:
Din första CI‑workflow kan vara liten: installera beroenden, kör gates och faila snabbt. Det här hindrar trasig kod från att tyst landa.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Bestäm var hemligheter lever: CI:s secret store, en lösenordshanterare eller din driftsplattform. Commita aldrig hemligheter — lägg till .env i .gitignore, och inkludera en .env.example med säkra platshållare.
Om du vill ha ett rent nästa steg, koppla dessa gates till din driftsprocess i nästa avsnitt, så att "grön CI" är enda vägen till produktion.
Att skicka är inte en engångsknapp — det är en repeterbar rutin. Målet för v1 är enkelt: välj en driftsplats som matchar din stack, driftsätt i små inkrement och ha alltid en väg tillbaka.
Välj en plattform som passar hur din app körs:
Att optimera för "lätt att driftsätta om" brukar slå "maximal kontroll" i detta skede.
Om din prioritet är att minimera verktygsskiften, överväg plattformar som bundlar build + hosting + rollback‑primitiv. Till exempel stöder Koder.ai driftsättning och hosting tillsammans med snapshots och rollback, så du kan betrakta releaser som reversibla steg.
Skriv checklista en gång och återanvänd för varje release. Håll den kort så människor faktiskt följer den:
Om du lagrar den i repot (t.ex. i /docs/deploy.md) håller den sig nära koden.
Skapa ett lättviktsendpoint som svarar: "Är appen uppe och kan nå beroenden?" Vanliga mönster:
GET /health för lastbalanserare och uptime‑monitorerGET /status som returnerar grundläggande app‑version + beroende‑kontrollerHåll svarsnät snabba, cache‑fria och säkra (inga hemligheter eller interna detaljer).
En rollback‑plan ska vara explicit:
När driftsättning är reversibel blir releaser rutin — och du kan skicka oftare med mindre stress.
Lansering är starten på den mest användbara fasen: lära vad riktiga användare gör, var appen brister och vilka små ändringar som rör din framgångsmetrik. Målet är att hålla samma AI‑assisterade arbetsflöde du använde för att bygga — nu riktat mot evidens istället för antaganden.
Börja med en minimal stack som svarar tre frågor: Är den uppe? Faller den? Är den långsam?
Uptime‑checks kan vara enkla (periodisk träff mot health‑endpoint). Felspårning bör fånga stacktraces och request‑kontext (utan att samla känslig data). Prestandaövervakning kan börja med svarstider för nyckelendpoints och front‑page load‑mått.
Be AI hjälpa till med att generera:
Spåra inte allt — spåra det som bevisar att appen fungerar. Definiera en primär framgångsmetrik (t.ex. "genomfört köp", "skapade första projektet" eller "bjöd in en kollega"). Instrumentera ett litet funnel: entry → nyckelhandling → framgång.
Be AI föreslå event‑namn och properties, och granska dem sedan för integritet och tydlighet. Håll events stabila; att byta namn varje vecka gör trender meningslösa.
Skapa ett enkelt intake: en in‑app feedback‑knapp, en kort e‑postalias och en lätt bug‑mall. Triagera veckovis: gruppera feedback i teman, koppla teman till analys och bestäm 1–2 förbättringar för nästa sprint.
Behandla övervakningslarm, analysdippar och feedback‑teman som nya "krav." Mata dem in i samma process: uppdatera dokumentet, generera ett litet ändringsförslag, implementera i tunna skivor, lägg till ett riktat test och driftsätt via samma reversibla release‑process. För team håller en delad "Learning Log"‑sida (länkad från /blog eller interna docs) beslut synliga och upprepbara.
Ett "single workflow" är en enda kontinuerlig tråd från idé till produktion där:
Du kan fortfarande använda flera verktyg, men undviker att "starta om" projektet i varje fas.
Använd AI för att generera alternativ och utkast — sedan väljer och verifierar du:
Håll beslutsregeln tydlig: "Flyttar detta metriska måttet, och är det säkert att skicka?"
Definiera ett mätbart framgångsmål och en snäv v1‑"definition of done". Exempel:
Om en funktion inte stödjer dessa utfall är den ett icke‑mål för v1.
Håll det till ett överblickbart, en‑sida PRD som inkluderar:
Lägg sedan till 5–10 kärnfunktioner max, rankade Must/Should/Nice. Använd den rankningen för att begränsa AI‑genererade planer och kod.
För dina topp 3–5 funktioner, lägg till 2–4 testbara uttalanden vardera. Bra acceptanskriterier är:
Exempel: valideringsregler, förväntade omdirigeringar, felmeddelanden och behörighetsbeteende (t.ex. "obehöriga användare ser ett klart fel och inga data läcker").
Börja med ett numrerat happy path och lista sedan ett par sannolika, kostsamma fel:
En enkel lista räcker; målet är att styra UI‑tillstånd, API‑svar och tester.
Default till en "modulär monolit" för v1:
Lägg till tjänster först när ett krav tvingar det. Det minskar koordinationskostnader och gör AI‑assisterad iteration enklare att granska och återställa.
Skriv en liten "API‑kontrakt"‑tabell före kodgenerering:
{ error: { code, message } })Detta förhindrar mismatch mellan UI och backend och ger tester ett stabilt mål.
Sikta på en "hello app" som bevisar att rördragningen fungerar:
/health).env.example och en README som startar på under en minutCommita små milstolpar tidigt så att du säkert kan återställa om en genererad ändring går fel.
Prioritera tester som förhindrar dyra fel:
I CI, verkställ enkla portar i denna ordning:
Håll tester stabila och snabba; fladdriga testsviter slutar skydda dig.