12 nov. 2025·8 min
Från ideell forskningslabb till AI‑ledare: OpenAIs historia
Utforska OpenAIs historia, från dess ideella ursprung och viktiga forskningsgenombrott till lanseringen av ChatGPT, GPT‑4 och hur uppdraget utvecklats.
Utforska OpenAIs historia, från dess ideella ursprung och viktiga forskningsgenombrott till lanseringen av ChatGPT, GPT‑4 och hur uppdraget utvecklats.
OpenAI är ett företag för AI‑forskning och -drift vars arbete påverkat hur allmänheten och experter tänker om artificiell intelligens, från tidiga forskningsartiklar till produkter som ChatGPT. Att förstå hur OpenAI utvecklades — från ett litet ideellt labb 2015 till en central aktör inom AI — hjälper till att förklara varför dagens AI ser ut som det gör.
OpenAIs historia är inte bara en rad modellsläpp. Den är ett fallstudie i hur mission, incitament, tekniska genombrott och offentlig press samverkar. Organisationen började med starkt fokus på öppen forskning och bred nytta, omstrukturerades för att locka kapital, bildade ett djupt partnerskap med Microsoft och lanserade produkter som används av hundratals miljoner människor.
Att följa OpenAIs utveckling belyser flera bredare trender inom AI:
Mission och värderingar: OpenAI grundades med målet att säkerställa att artificiell generell intelligens (AGI) gynnar hela mänskligheten. Hur det målet tolkats och reviderats över tid visar på spänningen mellan idealistiska ambitioner och kommersiella realiteter.
Forskningsgenombrott: Förflyttningen från tidiga projekt till system som GPT‑3, GPT‑4, DALL·E och Codex speglar en bredare förskjutning mot storskaliga foundational models som driver många av dagens AI‑applikationer.
Styrning och struktur: Flytten från ren ideell verksamhet till en capped‑profit‑enhet och skapandet av komplexa styrningsmekanismer visar hur nya organisatoriska former prövas för att hantera kraftfull teknik.
Offentlig påverkan och granskning: Med ChatGPT och andra lanseringar gick OpenAI från att vara ett forskningslabb som mest var känt inom AI‑kretsar till ett namn i var mans mun, vilket riktade uppmärksamhet mot säkerhet, alignment och regleringsdebatter som nu påverkar politiska diskussioner världen över.
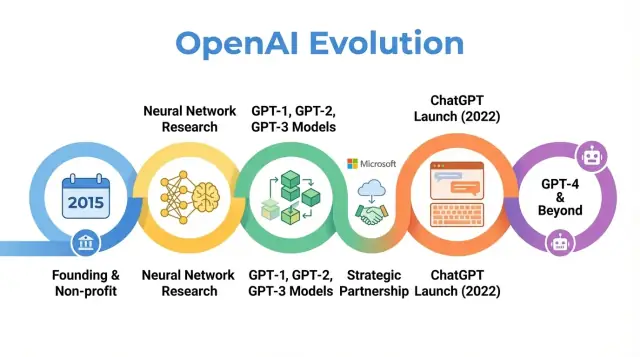
Denna artikel följer OpenAIs resa från 2015 till de senaste händelserna och visar hur varje fas speglar bredare skift inom AI‑forskning, ekonomi och styrning — och vad det kan innebära för framtiden.
OpenAI grundades i december 2015, vid en tidpunkt då maskininlärning — särskilt deep learning — snabbt förbättrades men fortfarande långt ifrån allmän intelligens. Bildigenkänningsbenchmarkar sjönk, taligenkänning blev bättre och företag som Google, Facebook och Baidu satsade stort på AI.
En växande oro bland forskare och tech‑ledare var att avancerad AI kunde hamna under kontroll av ett fåtal mäktiga företag eller stater. OpenAI föddes som en motvikt: en forskningsorganisation inriktad på långsiktig säkerhet och bred fördelning av AI:s nyttor, snarare än snävt kommersiellt övertag.
Från dag ett definierade OpenAI sitt uppdrag i termer av artificiell generell intelligens (AGI), inte bara inkrementella steg inom maskininlärning. Kärnuttalandet var att OpenAI skulle arbeta för att säkerställa att AGI, om den skapas, "gynnar hela mänskligheten."
Detta mission medförde flera konkreta följder:
Tidiga offentliga blogginlägg och grundarstadgan betonade både öppenhet och försiktighet: OpenAI skulle publicera mycket av sitt arbete, men också överväga samhälleliga konsekvenser av att frigöra kraftfulla kapaciteter.
OpenAI började som ett ideellt forskningslabb. De initiala finansieringslöftena kommunicerades till cirka 1 miljard dollar i åtaganden, även om detta var ett långsiktigt löfte snarare än kontanta medel på bordet. Viktiga tidiga finansiärer inkluderade Elon Musk, Sam Altman, Reid Hoffman, Peter Thiel, Jessica Livingston och YC Research, tillsammans med stöd från företag som Amazon Web Services och Infosys.
Det tidiga ledningsteamet kombinerade erfarenhet från startups, forskning och drift:
Denna blandning av Silicon Valley‑entreprenörskap och topptung AI‑forskning formade OpenAIs tidiga kultur: mycket ambitiöst kring att driva AI‑fronten, men organiserat som en missionsdriven ideell aktör med sikte på långsiktig global påverkan snarare än kortsiktig kommersialisering.
När OpenAI startade som ett ideellt forskningslabb 2015 var löftet enkelt men ambitiöst: driva AI‑forskning framåt samtidigt som så mycket som möjligt delades med det bredare samhället.
De tidiga åren präglades av en "open by default"‑filosofi. Forskningsartiklar publicerades snabbt, kod släpptes ofta och interna verktyg blev publika projekt. Idén var att påskynda bred vetenskaplig framsteg — och granskning — skulle vara säkrare och mer fördelaktigt än att koncentrera kapaciteter i ett enda företag.
Samtidigt var säkerhet redan en del av diskussionen. Teamet samtalade om när öppenhet kunde öka risken för missbruk och började skissa på idéer för stegvis release och policygranskningar, även om dessa idéer då var mer informella jämfört med senare styrningsprocesser.
OpenAIs tidiga vetenskapliga fokus sträckte sig över flera kärnområden:
Dessa projekt handlade mer om att testa vad som var möjligt med deep learning, beräkningskraft och smarta träningsregimer än om polerade produkter.
Två av de mest inflytelserika produkterna från denna era var OpenAI Gym och Universe.
Båda projekten reflekterade ett åtagande för delad infrastruktur snarare än proprietär fördel.
Under den ideella perioden porträtterades OpenAI ofta som en missionsdriven motvikt till stora techföretags AI‑labb. Kolleger värderade kvaliteten på forskningen, tillgången på kod och miljöer samt viljan att föra safety‑diskussioner.
Mediabevakningen betonade den ovanliga kombinationen av högprofilerade finansiärer, en icke‑kommersiell struktur och ett löfte om öppen publicering. Det ryktet — som ett inflytelserikt, öppet forskningslabb med fokus på långsiktiga konsekvenser — satte förväntningar som senare färgade reaktioner på varje strategiskt skifte i organisationen.
Vändpunkten i OpenAIs historia var beslutet att fokusera på stora transformer‑baserade språkmodeller. Detta skifte förvandlade OpenAI från ett främst forskningsfokuserat ideellt labb till en aktör känd för foundational models som andra bygger på.
GPT‑1 var blygsam i senare mått — 117 miljoner parametrar, tränad på BookCorpus — men gav ett viktigt konceptbevis.
Istället för att träna separata modeller för varje NLP‑uppgift visade GPT‑1 att en enda transformer‑modell, tränad med ett enkelt mål (förutsäga nästa ord), kunde anpassas med minimal finjustering till uppgifter som frågesvar, sentimentanalys och textual entailment.
För OpenAIs interna roadmap bekräftade GPT‑1 tre idéer:
GPT‑2 tog samma recept mycket längre: 1,5 miljarder parametrar och en mycket större webb‑deriverad dataset. Dess utsagor var ofta förbluffande koherenta: flerparagrafsartiklar, fiktiva berättelser och sammanfattningar som vid en första anblick såg ut att vara skrivna av människor.
Dessa kapaciteter väckte larm om potentiellt missbruk: automatiserad propaganda, spam, trakasserier och fejknyheter i stor skala. Istället för att omedelbart släppa fullmodell valde OpenAI en stegvis release‑strategi:
Detta var ett av de första högprofilerade exemplen på att OpenAI uttryckligen kopplade distributionsbeslut till säkerhet och samhällspåverkan, och det formade hur organisationen tänkte kring öppenhet och ansvar.
GPT‑3 skalade upp igen — denna gång till 175 miljarder parametrar. Istället för att förlita sig huvudsakligen på fine‑tuning för varje uppgift visade GPT‑3 upp "few‑shot" och till och med "zero‑shot"‑inlärning: modellen kunde ofta utföra en ny uppgift enbart utifrån instruktioner och några exempel i prompten.
Denna generalitet förändrade hur både OpenAI och branschen tänkte om AI‑system. Istället för att bygga många smala modeller kunde en stor modell fungera som en allmän motor för:
Avgörande var att OpenAI valde att inte open‑sourca GPT‑3. Åtkomst erbjöds via en kommersiell API. Detta markerade ett strategiskt skifte:
GPT‑1, GPT‑2 och GPT‑3 visar en tydlig båge i OpenAIs historia: skalning av transformrar, upptäckt av emergenta kapabiliteter, kamp med säkerhet och missbruk samt själva grunden för kommersialisering som senare skulle stödja produkter som ChatGPT och utvecklingen av GPT‑4.
Redan 2018 var OpenAIs ledare övertygade om att förbli ett litet, donationfinansierat labb inte skulle räcka för att bygga och säkert styra mycket stora AI‑system. Träning av gränsmodeller krävde redan tiotals miljoner dollar i beräkningskostnader och talang, med kostnadskurvor som tydligt pekade uppåt. För att konkurrera om toppforskare, skala experiment och säkerställa långsiktig åtkomst till molninfrastruktur behövde OpenAI en struktur som kunde attrahera betydande kapital utan att överge sitt ursprungliga uppdrag.
2019 lanserade OpenAI OpenAI LP, ett nytt "capped‑profit" kommanditbolag. Målet var att frigöra stor extern investering samtidigt som den ideella organisationens mission — att säkerställa att AGI gynnar hela mänskligheten — skulle ligga överst i beslutsfattandet.
Traditionella riskkapitaldrivna startups ansvarar slutligen inför aktieägare som söker obegränsad avkastning. OpenAIs grundare oroade sig för att detta skulle skapa starka drivkrafter att prioritera vinst framför säkerhet, öppenhet eller försiktig distribution. LP‑strukturen var en kompromiss: den kunde ge equity‑liknande intressen och resa kapital i stor skala, men under andra regler.
I den capped‑profit‑modellen kan investerare och anställda tjäna avkastning på sina andelar, men bara upp till en fast multipel av deras ursprungliga investering (för tidiga investerare ofta angivet upp till 100x, med lägre tak i senare omgångar). När den gränsen nås ska ytterligare värde tillfalla den ideella huvudorganisationen för användning i linje med dess mission.
Detta står i skarp kontrast mot vanliga startups, där aktievärdet teoretiskt sett kan växa utan gräns och där maximal aktieägarvärde är den rättsliga och kulturella normen.
OpenAI Nonprofit förblir den styrande enheten. Dess styrelse övervakar OpenAI LP och är stadgad att prioritera mänsklighetens intressen framför något specifikt investerarintresse.
Formellt:
Denna design syftar till att ge OpenAI flexibiliteten hos en kommersiell organisation för finansiering och rekrytering, samtidigt som en mission‑först kontroll bevaras.
Omstruktureringen väckte debatt internt och externt. Förespråkare menade att det var det enda praktiska sättet att säkra de miljardbelopp som krävs för banbrytande AI‑forskning samtidigt som man begränsade vinstincitamenten. Kritiker undrade om någon struktur som erbjuder stora avkastningar verkligen kan stå emot kommersiella påtryckningar, och om taknivåerna var tillräckligt låga eller tydligt verkställda.
I praktiken öppnade OpenAI LP dörren för stora strategiska investeringar, mest framträdande från Microsoft, och gjorde det möjligt att erbjuda konkurrenskraftiga ersättningspaket kopplade till potentiell uppsida. Det möjliggjorde i sin tur en skalning av forskarteam, fler träningskörningar för modeller som GPT‑3 och GPT‑4 och byggandet av infrastrukturen som krävdes för att driftsätta system som ChatGPT globalt — samtidigt som en formell styrningslänk till ideella rötter behölls.
2019 tillkännagav OpenAI och Microsoft ett flerårigt partnerskap som omformade båda företagens roller inom AI. Microsoft investerade rapporterat 1 miljard dollar, i form av kontanter och Azure‑molnkrediter, i utbyte mot att bli OpenAIs föredragna kommersiella partner.
Affären svarade mot OpenAIs behov av enorma beräkningsresurser för att träna allt större modeller, samtidigt som Microsoft fick tillgång till banbrytande AI som kunde differentiera dess produkter och molnplattform. Under de följande åren fördjupades relationen genom ytterligare finansiering och tekniskt samarbete.
OpenAI valde Microsoft Azure som primär molnplattform av flera skäl:
Detta gjorde Azure till standardmiljön för träning och drift av modeller som GPT‑3, Codex och senare GPT‑4.
Partnerskapet ledde till en av världens största AI‑superdatorlösningar, byggd på Azure för OpenAIs arbetsbelastningar. Microsoft betonade dessa kluster som flaggskeppsfall för Azures AI‑kapaciteter, medan OpenAI förlitade sig på dem för att pusha modellstorlek, träningsdata och experimenthastighet.
Detta gemensamma infrastrukturarbete suddade ut gränsen mellan "kund" och "partner": OpenAI påverkade effektivt Azures AI‑färdplan, och Azure optimerades efter OpenAIs behov.
Microsoft erhöll exklusiva licensrättigheter till vissa OpenAI‑teknologier, särskilt GPT‑3. Det gjorde det möjligt för Microsoft att integrera OpenAI‑modeller i sina produkter — Bing, Office, GitHub Copilot, Azure OpenAI Service — medan andra företag fick åtkomst via OpenAIs egna API:er.
Denna exklusivitet väckte debatt: förespråkare menade att det gav finansiering och distribution som behövdes för att skala kraftfull AI säkert; kritiker oroade sig för att det koncentrerade inflytande över gränsmodeller till ett stort techföretag.
Samtidigt gav partnerskapet OpenAI mainstream‑synlighet. Microsofts varumärke, produktintegrationer och företagskanaler hjälpte till att föra OpenAIs system från forskningsdemoer in i vardagsverktyg som används av miljarder, vilket formade den offentliga bilden av OpenAI både som ett självständigt labb och som en kärnpartner till Microsoft.
När OpenAIs modeller blev bättre på att förstå och generera språk drev teamet arbetet in i nya modaliteter: bilder och kod. Detta breddade OpenAIs påverkan från skrivande och dialog till visuell kreativitet och mjukvaruutveckling.
CLIP (Contrastive Language–Image Pretraining), presenterat tidigt 2021, var ett viktigt steg mot modeller som förstår världen mer likt människor.
I stället för att bara träna på etiketterade bilder lärde sig CLIP från hundratals miljoner bild‑text‑par hämtade från webben. Det tränades för att matcha bilder med deras mest sannolika textbeskrivningar och skilja dem från felaktiga alternativ.
Detta gav CLIP förvånansvärt generella förmågor:
CLIP blev en grund för senare generativt bildarbete hos OpenAI.
DALL·E (2021) applicerade GPT‑stilarkitekturer på bilder och genererade bilder direkt från textpromptar: "en fåtölj i form av en avokado" eller "en butiksfasadskylt som säger 'openai'". Den visade att språkmodeller kunde utvidgas för att producera sammanhängande, ofta lekfulla bilder.
DALL·E 2 (2022) förbättrade upplösning, realism och kontrollsignaler avsevärt. Det introducerade funktioner som:
Dessa system förändrade hur designers, marknadsförare, konstnärer och hobbyister prototypade idéer, och flyttade en del kreativt arbete från manuella skisser till iterativ promptdriven utforskning.
Codex (2021) tog GPT‑3‑familjen och anpassade den till källkod, tränad på stora öppna kodbaser. Den kan översätta naturligt språk till fungerande kodsnuttar för språk som Python, JavaScript och många fler.
GitHub Copilot, byggt på Codex, förde detta in i vardagliga utvecklingsverktyg. Programmerare började få hela funktioner, tester och boilerplate som förslag, med naturliga språkkommentarer som vägledning.
För mjukvaruutveckling antydde Codex en gradvis förskjutning:
Tillsammans visade CLIP, DALL·E och Codex att OpenAIs angreppssätt kunde sträcka sig bortom text till syn och kod, och därigenom bredda forskningens inverkan över design, konst och teknik.
OpenAI lanserade ChatGPT som en gratis "research preview" den 30 november 2022, med ett kort blogginlägg och en tweet snarare än en storskalig produktkampanj. Modellen byggde på GPT‑3.5 och var optimerad för dialog, med skyddsåtgärder för att neka vissa skadliga eller osäkra förfrågningar.
Användningen ökade nästan omedelbart. Miljoner människor registrerade sig inom dagar, och ChatGPT blev en av de snabbast växande konsumentapplikationerna någonsin. Skärmbilder på konversationer fyllde sociala medier när användare testade dess förmåga att skriva uppsatser, felsöka kod, formulera mejl och förklara komplexa ämnen på ett enkelt sätt.
ChatGPTs attraktionskraft låg i dess mångsidighet snarare än ett snävt användningsfall.
I utbildning använde studenter det för att sammanfatta texter, generera övningsfrågor, översätta eller förenkla akademiska artiklar och få steg‑för‑steg‑förklaringar i matematik eller naturvetenskap. Lärare experimenterade med det för att utforma kursplaner, skapa bedömningsmallar och differentierade undervisningsmaterial, samtidigt som skolor diskuterade om och hur det bör tillåtas.
På jobbet bad yrkespersoner ChatGPT att skriva mejl, marknadsföringstexter och rapporter, skissa presentationer, generera kodsnuttar, skriva testfall och fungera som en brainstorming‑partner för produktidéer eller strategier. Frilansare och småföretag använde det särskilt som en lågkostnadshjälp för innehåll och analyser.
I vardagsproblem vände sig människor till ChatGPT för reseplaner, matidéer utifrån vad som fanns i kylskåpet, grundläggande juridiska och medicinska förklaringar (vanligtvis med uppmaning att söka professionell hjälp) och hjälp med att lära sig nya färdigheter eller språk.
Den inledande research‑previewen var gratis för att sänka tröskeln och samla in feedback på fel, missbruk och saknade funktioner. När användningen ökade stod OpenAI inför både höga infrastrukturkostnader och efterfrågan på mer tillförlitlig åtkomst.
I februari 2023 introducerade OpenAI ChatGPT Plus, en prenumerationsplan som erbjöd snabbare svar, prioriterad åtkomst under toppar och tidig tillgång till nya funktioner och modeller som GPT‑4. Detta skapade återkommande intäkter samtidigt som en gratis nivå behölls för bred åtkomst.
Med tiden lade OpenAI till mer företagsinriktade alternativ: API‑åtkomst till samma konverserande modeller, verktyg för integration i produkter och arbetsflöden och erbjudanden som ChatGPT Enterprise och teamplaner för organisationer som behöver högre säkerhet, administrationskontroller och efterlevnadsfunktioner.
ChatGPTs plötsliga synlighet intensifierade redan långvariga debatter om AI.
Regulatorer och beslutsfattare oroade sig för integritet, dataskydd och efterlevnad av befintliga lagar, särskilt i regioner som EU. Vissa myndigheter tillfälligt begränsade eller utredde ChatGPT medan de bedömde om datainsamling och bearbetning uppfyllde rättsliga standarder.
Utbildningsväsendet konfronterades med plagiat‑ och akademisk integritetsproblematik eftersom studenter kunde generera uppsatser och läxor som var svåra att upptäcka. Detta ledde till förbud eller strikta policyer i vissa skolor, medan andra förändrade uppgifter för att betona process, muntliga prov eller arbete i klass.
Etiker och forskare varnade för desinformation, överberoende på AI i kritiska beslut, bias i svar och potentiella effekter på kreativa och kunskapsintensiva jobb. Det uppstod också frågor om träningsdata, upphovsrätt och rättigheter för konstnärer och skribenter vars verk kan ha påverkat modellernas beteende.
För OpenAI markerade ChatGPT en vändpunkt: organisationen gick från att vara ett mestadels forskningsfokuserat labb till att stå i centrum för globala diskussioner om hur kraftfulla språkmodeller bör driftsättas, styras och integreras i vardagen.
OpenAI släppte GPT‑4 i mars 2023 som ett stort steg bortom GPT‑3.5, den modell som ursprungligen drev ChatGPT. GPT‑4 förbättrade resonemang, följandet av komplexa instruktioner och bibehållandet av koherens över längre konversationer. Den blev också betydligt bättre på att hantera nyanserade prompts, som att förklara juridiska klausuler, sammanfatta tekniska artiklar eller skriva kod från otydliga krav.
Jämfört med GPT‑3.5 minskade GPT‑4 många uppenbara felmoder: den var mindre benägen att hitta på källor när den ombads ange referenser, hanterade kantfall i matematik och logik mer tillförlitligt och producerade mer konsekventa utsagor över upprepade förfrågningar.
GPT‑4 introducerade multimodala förmågor: utöver text kan den i vissa konfigurationer ta emot bilder som indata. Det möjliggör användningsfall som att beskriva diagram, läsa handskrivna anteckningar, tolka skärmdumpar av användargränssnitt eller analysera foton för att extrahera strukturerad information.
På standardiserade benchmarkar överträffade GPT‑4 tidigare modeller avsevärt. Den nådde nära topp‑percentilresultat på simulerade professionella prov som advokatexamen, SAT och olika avancerade prov, och förbättrades även i kodnings‑ och resonemangstest.
GPT‑4 blev snabbt kärnan i OpenAIs API och drev en ny våg av tredjepartsprodukter: AI‑co‑piloter i produktivitetspaket, kodassistenter, kundtjänstverktyg, utbildningsplattformar och vertikalspecifika applikationer inom områden som juridik, finans och vård.
Trots dessa framsteg hallucinerar GPT‑4 fortfarande, kan manipuleras till osäkra eller partiska svar och saknar äkta förståelse eller helt uppdaterad faktakunskap. OpenAI satsade tungt på alignment‑forskning för GPT‑4 — med tekniker som reinforcement learning from human feedback, red‑teaming och systemnivåregler — men framhåller att noggrann distribution, övervakning och fortsatt forskning krävs för att hantera risker och missbruk.
Från de tidiga åren har OpenAI ramat in säkerhet och alignment som centrala för sitt uppdrag, inte något som kommer i efterhand till produktlanseringar. Organisationen har konsekvent uttalat att målet är att bygga mycket kapabla AI‑system som är i linje med mänskliga värderingar och driftsätts så att de gagnar alla, inte bara aktieägare eller tidiga partners.
2018 publicerade OpenAI OpenAI Charter, som formaliserade dess prioriteringar:
Chartern fungerar som en styrkompass och formar beslut om forskningsriktning, distributionshastighet och externa partnerskap.
När modellerna blev mer kapabla byggde OpenAI dedikerade funktioner för säkerhet och styrning bredvid kärnforskningsgrupperna:
Dessa grupper påverkar lanseringsbeslut, åtkomstnivåer och användningspolicyer för modeller som GPT‑4 och DALL·E.
En definierande teknisk metod har varit reinforcement learning from human feedback (RLHF). Människor granskar modellens utsagor, rankar dem och tränar en belöningsmodell. Huvudmodellen optimeras sedan för att producera svar som ligger närmare mänskliga preferenser, vilket minskar toxiska, partiska eller osäkra utslag.
Med tiden har OpenAI lagrat RLHF med ytterligare tekniker: systemnivåregler, innehållsfilter, domänspecifik finjustering och övervakningsverktyg som kan begränsa eller flagga högriskanvändning.
OpenAI har deltagit i offentliga säkerhetsramverk, till exempel frivilliga åtaganden med regeringar, modelrapportering och standarder för frontier‑modelsäkerhet. De har samarbetat med akademiker, civilsamhällets organisationer och säkerhetsforskare kring utvärderingar, red‑teaming och revisioner.
Dessa samarbeten, tillsammans med formella dokument som chartern och utvecklande användarpolicyer, utgör ryggraden i OpenAIs angreppssätt för att styra allt kraftfullare AI‑system.
OpenAIs snabba uppgång har skuggats av kritik och intern påfrestning, mycket av det centrerat kring hur väl organisationen fortfarande lever upp till sitt ursprungliga uppdrag om bred, säker nytta.
Tidigt betonade OpenAI öppen publicering och delning. Med tiden, i takt med att modeller som GPT‑2, GPT‑3 och GPT‑4 blev mer kapabla, rörde sig företaget mot begränsade utgåvor, API‑endast‑åtkomst och färre tekniska detaljer.
Kritiker menade att detta stred mot löftet i namnet "OpenAI" och den tidiga ideella retoriken. Förespråkare inom företaget har argumenterat att att hålla tillbaka fullständiga modellvikter och träningsdetaljer är nödvändigt för att hantera missbruksrisker och säkerhetsproblem.
OpenAI har svarat genom att publicera säkerhetsutvärderingar, systemkort och policydokument, samtidigt som kärnmodellvikter hålls proprietära. De presenterar detta som en balans mellan öppenhet, säkerhet och konkurrenstryck.
När OpenAI fördjupade sitt partnerskap med Microsoft — och integrerade modeller i Azure och produkter som Copilot — uppstod oro kring koncentration av beräkningskraft, data och beslutsfattande.
Kritiker fruktar att ett litet antal företag nu kontrollerar de mest avancerade allmänna modellerna och den omfattande infrastruktur som ligger bakom dem. Andra menar att aggressiv kommersialisering (ChatGPT Plus, företagsprodukter och exklusiva licenser) avviker från det ursprungliga ideella uppdraget om bred fördel.
OpenAIs ledning har ramat in intäkter som nödvändiga för att finansiera dyr forskning, samtidigt som man påpekar den capped‑profit‑struktur och en charter som prioriterar mänsklighetens intressen framför aktieägare. De har också lanserat program som gratis åtkomstnivåer, forskningspartnerskap och vissa open‑source‑verktyg för att visa offentliga fördelar.
Interna oenigheter om hur snabbt man ska röra sig, hur öppet man ska vara och hur säkerhet ska prioriteras har dykt upp upprepade gånger.
Dario Amodei och andra lämnade 2020 för att starta Anthropic, med hänvisning till skillnader i syn på säkerhet och styrning. Senare avgångar från nyckelpersoner inom säkerhet, inklusive Jan Leike 2024, belyste offentligt oro över att kortsiktiga produktmål prioriterades framför långsiktig säkerhetsforskning.
Den mest synliga brytningen skedde i november 2023 när styrelsen kortvarigt avsatte VD Sam Altman med hänvisning till förlorat förtroende. Efter kraftig medarbetarprotest och förhandlingar med Microsoft och andra intressenter återinsattes Altman, styrelsen byttes ut och OpenAI lovade styrningsreformer, inklusive en ny Safety and Security Committee.
Dessa händelser underströk att organisationen fortfarande kämpar med hur man förenar snabb distribution, kommersiell framgång och det uttalade ansvaret för säkerhet och bred nytta.
OpenAI har skiftat från ett litet forskningslabb till en central plattformsleverantör för AI, och påverkar hur nya verktyg byggs, regleras och förstås.
I stället för att bara publicera modeller driver OpenAI nu en hel plattform som används av startups, företag och enskilda utvecklare. Genom API:er för modeller som GPT‑4, DALL·E och framtida system har OpenAI blivit:
Denna plattformsroll innebär att OpenAI inte bara avancerar forskning — det sätter standarder för hur miljontals människor först upplever kraftfull AI.
OpenAIs arbete pressar konkurrenter och open‑source‑gemenskaper att svara med nya modeller, träningsmetoder och säkerhetsansatser. Den konkurrensen accelererar framsteg samtidigt som den skärper debatter om öppenhet, centralisering och kommersialisering av AI.
Regeringar och regelgivare ser i allt högre grad till OpenAIs praxis, transparensrapporter och alignment‑forskning när de utformar regler för AI‑distribuering, säkerhetsutvärderingar och ansvarig användning. Offentliga samtal om ChatGPT, GPT‑4 och framtida system påverkar i hög grad hur samhället föreställer sig både risker och fördelar med AI.
När modeller blir mer kapabla blir obesvarade frågor om OpenAIs roll viktigare:
Dessa frågor kommer att avgöra om framtida AI‑system förstärker existerande ojämlikheter eller hjälper till att minska dem.
Utvecklare och företag kan:
Individer kan:
OpenAIs framtida inflytande kommer att bero inte bara på interna beslut, utan på hur regeringar, konkurrenter, civilsamhället och vardagsanvändare väljer att engagera sig, kritisera och kräva ansvar av de system som byggs.
OpenAI grundades 2015 som ett ideellt forskningslabb med uppdraget att säkerställa att artificiell generell intelligens (AGI), om den skapas, kommer hela mänskligheten till del.
Flera faktorer formade bildandet:
Denna ursprungshistoria påverkar fortfarande OpenAIs struktur, partnerskap och offentliga åtaganden i dag.
AGI (artificiell generell intelligens) avser AI‑system som kan utföra ett brett spektrum kognitiva uppgifter på eller över mänsklig nivå, istället för att vara smala verktyg optimerade för en enda uppgift.
OpenAIs mission är att:
Detta mission formaliseras i OpenAI Charter och påverkar viktiga beslut om forskningsriktningar och distribution.
OpenAI övergick från en ren ideell verksamhet till en "capped‑profit" limited partnership (OpenAI LP) för att kunna ta in de stora kapitalmängder som krävs för banbrytande AI‑forskning, samtidigt som organisationens mission skulle bevaras högst upp i hierarkin.
Viktiga punkter:
Det är ett experiment i styrning och dess effektivitet är föremål för debatt.
Microsoft tillhandahåller enorma molnresurser via Azure och har investerat miljarder i företaget.
Partnerskapet inkluderar:
I gengäld får OpenAI de resurser som behövs för att träna och driftsätta frontlinjemodeller i global skala, medan Microsoft får differentierade AI‑möjligheter för sitt ekosystem.
GPT‑serien visar en progression i skala, kapabilitet och strategi för distribution:
OpenAI började med en "open by default"‑strategi — publicerade artiklar, kod och verktyg som OpenAI Gym brett. När modeller blev kraftfullare rörde sig organisationen mot:
OpenAI hävdar att detta är nödvändigt för att minska missbruksrisker och hantera säkerhet. Kritiker menar att det undergräver det ursprungliga löftet som namnet "OpenAI" antyder och koncentrerar makt i ett företag.
OpenAI använder en kombination av organisatoriska åtgärder och tekniska metoder för att hantera säkerhet och missbruk:
Dessa åtgärder minskar risker men eliminerar inte problem som hallucinationer, bias och potentiellt missbruk — vilket fortfarande är aktiva forsknings‑ och styrningsutmaningar.
ChatGPT, som lanserades i slutet av 2022, gjorde stora språkmodeller lättillgängliga för allmänheten via ett enkelt chattgränssnitt.
Det förändrade AI‑adoption på flera sätt:
Den offentliga synligheten intensifierade också granskningen av OpenAIs styrning, affärsmodell och säkerhetspraxis.
OpenAIs modeller, särskilt Codex och GPT‑4, påverkar redan delar av kunskapsarbete och kreativt arbete.
Möjliga fördelar:
Risker och utmaningar:
Du kan engagera dig i OpenAI‑ekosystemet på flera sätt:
I alla fall är det bra att vara informerad om hur modeller tränas och styrs och att kräva transparens, ansvarstagande och rättvis åtkomst när systemen blir mer kapabla.
Varje steg knuffade de tekniska gränserna samtidigt som nya beslut om säkerhet, åtkomst och kommersialisering krävdes.
Nettoeffekten beror i hög grad på politik, organisatoriska val och hur individer och företag väljer att integrera AI i sina arbetsflöden.