03 apr. 2025·8 min
Hantera tillstånd mellan frontend och backend i AI-appar
Lär dig hur UI-, sessions- och data-tillstånd rör sig mellan frontend och backend i AI-appar, med praktiska mönster för synkronisering, persistens, caching och säkerhet.
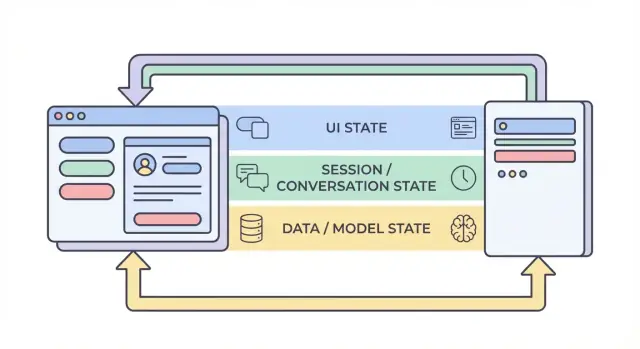
Vad tillstånd betyder i en AI-baserad applikation
"Tillstånd" är allt din app behöver komma ihåg för att bete sig korrekt från ett ögonblick till nästa.
Om en användare klickar på Skicka i ett chattgränssnitt ska appen inte glömma vad hen skrev, vad assistenten redan svarat, om en förfrågan fortfarande körs eller vilka inställningar (ton, modell, verktyg) är aktiva. Allt det är tillstånd.
Tillstånd, enkelt förklarat
Ett användbart sätt att tänka på tillstånd är: den aktuella sanningen i appen — värden som påverkar vad användaren ser och vad systemet gör härnäst. Det inkluderar uppenbara saker som formulärfält, men också "osynliga" fakta som:
- Vilken konversation användaren är i
- Om det sista svaret strömmas eller är klart
- Listan över meddelanden och deras ordning
- Anrop till verktyg och verktygsresultat (sökresultat, databasuppslag, filutdrag)
- Fel, retry-försök och rate-limit backoff
Varför AI-appar har fler rörliga delar
Traditionella appar läser ofta data, visar den och sparar uppdateringar. AI-appar lägger till extra steg och mellanliggande output:
- En enda användaråtgärd kan trigga flera backend-operationer (LLM-anrop, verktygsanrop, ytterligare LLM-anrop).
- Svar kan komma inkrementellt (strömmande tokens), så UI:t måste hantera partiellt tillstånd.
- Kontext spelar roll: systemet kan behöva hålla ihop konversationsminne, verktygsresultat och modellinställningar över förfrågningar.
Den här extra rörelsen är anledningen till att tillståndshantering ofta är den dolda komplexiteten i AI-applikationer.
Vad den här guiden täcker
I avsnitten nedan delar vi upp tillstånd i praktiska kategorier (UI-tillstånd, sessionstillstånd, persisterade data och modell/runtime-tillstånd) och visar var varje del bör bo (frontend vs backend). Vi tar också upp synkronisering, cache, långkörande jobb, strömmande uppdateringar och säkerhet — eftersom tillstånd bara är användbart om det är korrekt och skyddat.
Snabbt exempel
Föreställ dig en chattapp där en användare ber: "Sammanfatta förra månadens fakturor och markera avvikelser." Backend kan (1) hämta fakturor, (2) köra ett analysverktyg, (3) strömma en sammanfattning tillbaka till UI:t och (4) spara slutrapporten.
För att det ska kännas sömlöst måste appen hålla reda på meddelanden, verktygsresultat, progress och det sparade resultatet — utan att blanda ihop konversationer eller läcka data mellan användare.
Fyra lager av tillstånd: UI, session, data och modell
När folk säger "tillstånd" i en AI-app blandar de ofta ihop väldigt olika saker. Att dela upp tillstånd i fyra lager — UI, session, data och modell/runtime — gör det lättare att bestämma var något ska leva, vem som kan ändra det och hur det ska lagras.
1) UI-tillstånd (vad användaren gör just nu)
UI-tillstånd är det levande, ögonblickliga tillståndet i webbläsaren eller mobilappen: textfält, toggle-knappar, valda objekt, vilken flik som är öppen och om en knapp är inaktiverad.
AI-appar lägger till några UI-specifika detaljer:
- Laddningsindikatorer och "tänker"-tillstånd
- Strömmade tokens (delvis text som dyker upp medan den genereras)
- Lokala utkast (innan de skickas)
UI-tillstånd ska vara enkelt att återställa och säkert att förlora. Om användaren uppdaterar sidan kan du tappa det — och det är ofta OK.
2) Session / konversations-tillstånd (delad kontext för en användares flöde)
Sessionstillstånd binder en användare till en pågående interaktion: användaridentitet, en konversations-ID och en konsekvent vy av meddelandehistoriken.
I AI-appar innehåller detta ofta:
- Meddelandehistorik (eller referenser till den)
- Verktygsspår (vilka funktioner/verktyg som kallades och med vilka resultat)
- "Arbetsuppsättning"-val som nuvarande projekt/dokument, vald modell eller workspace
Det här lagret sträcker sig ofta över frontend och backend: frontend håller lätta identifierare, medan backend är auktoriteten för sessionskontinuitet och åtkomstkontroll.
3) Data-tillstånd (beständiga poster i lagring)
Data-tillstånd är det du avsiktligt lagrar i en databas: projekt, dokument, embeddings, preferenser, revisionsloggar, faktureringshändelser och sparade konversationer.
Till skillnad från UI och session bör data-tillstånd vara:
- Beständigt (överlever omstart)
- Sökbart (du kan filtrera och söka)
- Granskningsbart (du kan förstå vad som hände senare)
4) Modell / runtime-tillstånd (hur AI:n är konfigurerad just nu)
Modell/runtime-tillstånd är den operativa setup som används för att producera svar: systemprompts, vilka verktyg som är aktiverade, temperatur/max tokens, säkerhetsinställningar, rate limits och tillfälliga cachear.
En del är konfiguration (stabila standarder); annat är flyktigt (kortlivade cachear eller per-förfrågan token-budgetar). Det mesta hör hemma på backend så det kan kontrolleras konsekvent och inte exponeras i onödan.
Varför separation minskar buggar
När dessa lager suddas ut får du klassiska fel: UI visar text som inte sparats, backend använder andra promptinställningar än frontend förväntar sig, eller konversationsminne läcker mellan användare. Klara gränser skapar tydligare sanningskällor — och gör det uppenbart vad som måste bestå, vad som kan återskapas och vad som måste skyddas.
Vad som bor i frontend vs backend (och varför)
Ett pålitligt sätt att minska buggar i AI-appar är att bestämma, för varje bit tillstånd, var den ska bo: i webbläsaren (frontend), på servern (backend) eller i båda. Detta påverkar pålitlighet, säkerhet och hur "överraskande" appen känns när användare uppdaterar, öppnar en ny flik eller tappar nätverk.
Frontend-tillstånd: snabbt, temporärt och användardrivet
Frontend-tillstånd passar bäst för saker som ändras snabbt och inte behöver överleva en uppdatering. Att hålla det lokalt gör UI:t responsivt och undviker onödiga API-anrop.
Vanliga frontend-exempel:
- Utkast till meddelandetext som användaren skriver
- Lokala filter och sorteringsordning i en tabell
- Modal öppet/stängt, vald flik, hover-tillstånd
Om du förlorar detta vid uppdatering är det vanligtvis acceptabelt.
Backend-tillstånd: auktoritativt, känsligt och delat
Backend bör hålla allt som måste vara betrott, granskningsbart eller konsekvent upprätthållet. Detta inkluderar tillstånd som andra enheter/flikar behöver se, eller som måste förbli korrekt även om klienten manipuleras.
Vanliga backend-exempel:
- Behörigheter och roller
- Fakturering/abonnemang och användningsgränser
- Långkörande jobb (dokumentindexering, stora exporter, fine-tune-körningar) och deras status
Bra tumregel: om felaktigt tillstånd kan kosta pengar, läcka data eller bryta åtkomstkontroll, hör det hemma på backend.
Delat tillstånd: koordinerat men med en sanningskälla
Vissa tillstånd är naturligt delade:
- Konversationstitel
- Valda kunskapskällor för en chatt
- Användarprofilfält som används över enheter
Även när det är delat, välj en "sanningskälla." Typiskt är backend auktoritativ och frontend cachar en kopia för hastighet.
Tumregel (och ett vanligt antipattern)
Håll tillstånd nära där det behövs, men persist det som måste överleva uppdateringar, enhetsbyten eller avbrott.
Undvik antipatternen att lagra känsligt eller auktoritativt tillstånd endast i webbläsaren (t.ex. en klient-side isAdmin-flagga, plan-nivå eller jobbstatus som sanning). UI:t kan visa dessa värden, men backend måste verifiera dem.
En typisk AI-förfrågnings livscykel: från klick till färdigt
En AI-funktion känns som "en handling", men är egentligen en kedja av tillståndsövergångar delade mellan webbläsare och server. Att förstå livscykeln gör det enklare att undvika mismatch i UI, saknad kontext och duplicerade kostnader.
1) Användaråtgärd → frontend förbereder intent
En användare klickar på Skicka. UI:t uppdaterar omedelbart lokalt tillstånd: det kan lägga till en "pending" meddelandebubbla, inaktivera skicka-knappen och fånga aktuella inputs (text, bilagor, valda verktyg).
Vid denna punkt bör frontend generera eller bifoga korrelationsidentifierare:
conversation_id: vilken tråd detta hör tillmessage_id: klientens ID för det nya användarmeddelandetrequest_id: unikt per försök (användbart för retries)
Dessa IDs låter båda sidor referera till samma händelse även när svar kommer sent eller dubbelt.
2) API-anrop → server validerar och persisterar
Frontenden skickar en API-förfrågan med användarmeddelandet plus IDs. Servern validerar behörigheter, rate limits och payloadens form, och persisterar sedan användarmeddelandet (eller åtminstone en oföränderlig loggpost) nycklad på conversation_id och message_id.
Detta persistenssteg förhindrar "fantomhistorik" om användaren uppdaterar mitt i en förfrågan.
3) Servern bygger upp kontext
För att anropa modellen bygger servern upp kontext från sin sanningskälla:
- Hämta senaste meddelanden för
conversation_id - Dra in relaterade poster (dokument, preferenser, verktygsresultat)
- Applicera konversationspolicyer (systemprompts, minnesregler, trunkering)
Nyckelidén: lita inte på att klienten skickar full historik. Klienten kan vara föråldrad.
4) Modell/verktygsexekvering → mellanliggande tillstånd
Servern kan kalla verktyg (sök, databasuppslag) före eller under modellgenereringen. Varje verktygsanrop producerar mellanliggande tillstånd som bör spåras mot request_id så att det kan granskas och återköras säkert.
5) Svar (strömmande eller ej) → UI slutför
Vid streaming skickar servern partiella tokens/händelser. UI:t uppdaterar successivt det väntande assistentmeddelandet, men ser det fortfarande som "pågående" tills en slutlig händelse markerar slutförande.
6) Felpunkter att planera för
Retries, dubbelinskickningar och felordnade svar händer. Använd request_id för att deduplicera på servern och message_id för att försonas i UI:t (ignorera sena chunkar som inte matchar den aktiva förfrågan). Visa alltid ett tydligt "misslyckades"-tillstånd med en säker retry som inte skapar dubbletter.
Sessioner och konversationsminne: behåll kontext utan kaos
Skicka med rollback-säkerhet
Iterera på tillståndsändringar tryggt med snapshots och rollback i Koder.ai.
En session är tråden som binder användarens åtgärder: vilken workspace de är i, vad de senast sökte efter, vilket utkast de redigerade och vilken konversation ett AI-svar ska fortsätta. Bra sessionstillstånd gör att appen känns kontinuerlig över sidor — och helst över enheter — utan att backend blir en dumpningsplats för allt användaren någonsin sagt.
Mål för sessionstillstånd
Sikta på: (1) kontinuitet (en användare kan lämna och komma tillbaka), (2) korrekthet (AI:n använder rätt kontext för rätt konversation) och (3) isolering (en session får inte läcka till en annan). Om du stödjer flera enheter, behandla sessioner som användar- plus enhetsskopade: "samma konto" betyder inte alltid "samma öppna arbetsvy".
Cookies vs tokens vs serversessioner
Du väljer vanligtvis ett av dessa sätt att identifiera sessionen:
- Cookies: enklast för webb eftersom webbläsaren skickar dem automatiskt. Bra för traditionella sessioner, men sätt säkra flaggor (
HttpOnly,Secure,SameSite) och hantera CSRF. - Tokens (t.ex. JWT): bra för API:er och mobilappar eftersom klienten fäster dem uttryckligen. De skalar väl, men återkallande och rotation kräver design (och du bör inte stoppa känsligt tillstånd i token).
- Serversessioner: servern lagrar sessiondata (ofta i Redis) och klienten håller bara ett ogenomskinligt session-ID. Lättast att återkalla och uppdatera, men du måste köra och skala sessionlagret.
Strategier för konversationsminne
"Minne" är bara tillstånd du väljer att skicka tillbaka in i modellen.
- Full historik: mest korrekt, men dyrt och kan exponera gammalt känsligt innehåll.
- Sammanfattat minne: behåll en löpande sammanfattning plus några senaste turer; billigare och ofta tillräckligt.
- Fönsterkontext: bara de senaste N meddelandena; enklast, men kan missa viktiga tidigare beslut.
Ett praktiskt mönster är summary + window: förutsägbart och hjälper undvika överraskande modellbeteende.
Verktygsanrop: upprepbara och granskbara
Om AI:n använder verktyg (sök, databasfrågor, filläsningar), lagra varje verktygsanrop med: inputs, tidsstämplar, verktygs-version och returnerat output (eller en referens). Det här låter dig förklara "varför AI:n sa det", replaya körningar för debugging och upptäcka när resultat ändrats på grund av verktygets datasetändring.
Integritets-garderober
Spara inte långtidsminne som standard. Behåll bara vad som behövs för kontinuitet (konversations-ID, sammanfattningar och verktygsspår), sätt retention-gränser och undvik att persistera rå användartext utan klart produktbehov och användarsamtycke.
Synkronisering av tillstånd säkert: sanningskällor och konfliktlösning
Tillstånd blir riskabelt när samma "sak" kan redigeras på mer än ett ställe — ditt UI, en andra flik eller en bakgrundsprocess. Lösningen handlar mindre om smart kod och mer om tydligt ägande.
Definiera sanningskällor
Bestäm vilket system som är auktoritativt för varje bit tillstånd. I de flesta AI-applikationer bör backend äga den kanoniska posten för allt som måste vara korrekt: konversationsinställningar, verktygsbehörigheter, meddelandehistorik, faktureringsgränser och jobbstatus. Frontend kan cachea och härleda tillstånd för hastighet, men bör anta att backend har rätt vid mismatch.
Praktisk regel: om du skulle bli upprörd över att förlora det vid uppdatering, hör det troligen hemma i backend.
Optimistiska UI-uppdateringar (använd med omsorg)
Optimistiska uppdateringar får appen att kännas omedelbar: toggla en inställning, uppdatera UI direkt och bekräfta sedan med servern. Det fungerar bra för låg-stakes, återkännbara handlingar (t.ex. markera en konversation som favorit).
Det skapar förvirring när servern kan avvisa eller transformera ändringen (behörighetskontroller, kvotbegränsningar, validering eller serversidiga defaults). I sådana fall visa ett "sparar..."-tillstånd och uppdatera UI först efter bekräftelse.
Hantera konflikter (två flikar, en konversation)
Konflikter uppstår när två klienter uppdaterar samma post utifrån olika startversioner. Vanligt exempel: Flik A och Flik B ändrar modellens temperatur samtidigt.
Använd lättviktsversionering så backend kan upptäcka föråldrade skrivningar:
updated_attidsstämplar (enkelt och mänskligt debuggbart)- ETags /
If-Matchheaders (HTTP-native) - Inkrementella revisionsnummer (explicit konfliktupptäckt)
Om versionen inte matchar, returnera en konflikt (ofta HTTP 409) och skicka tillbaka det senaste serverobjektet.
Designa API:er för att minska mismatch
Efter varje skrivning, låt API:t returnera det sparade objektet som persisterats (inklusive serverskapade defaults, normaliserade fält och ny version). Detta låter frontend ersätta sin cachade kopia omedelbart — en uppdatering av sanningskällan istället för att gissa vad som ändrats.
Caching och prestanda: snabba upp utan föråldrat tillstånd
Caching är ett av de snabbaste sätten att få en AI-app att kännas omedelbar, men det skapar också en andra kopia av tillstånd. Cachar du fel sak — eller cachar den på fel ställe — får du ett UI som känns snabbt men förvirrande.
Vad du bör cachea på klienten
Klient-side caches bör fokusera på upplevelsen, inte auktoriteten. Bra kandidater är senaste konversationsförhandsvisningar (titlar, sista meddelandesnitt), UI-preferenser (tema, vald modell, sidofältsstatus) och optimistiska UI-tillstånd (meddelanden som "skickas").
Håll klientcachen liten och förgänglig: om den rensas ska appen fortfarande fungera genom att hämta om från servern.
Vad du bör cachea på servern
Servercachar bör fokusera på dyr eller ofta upprepad arbete:
- Verktygsresultat som är säkra att återanvända (t.ex. väderuppslag för samma stad inom 5 minuter)
- Embedding-uppslag och vektor-sökresultat för upprepade frågor (ofta med korta TTL)
- Rate-limit state och throttling-räknare (för att skydda din API och kostnader)
Här kan du också cachea härlett tillstånd som token-räkningar, moderationsbeslut eller dokumentparsningsresultat — allt deterministiskt och dyrt.
Grundläggande cache-invalidation (utan att göra det komplicerat)
Tre praktiska regler:
- Använd tydliga cache-nycklar som kodar in inputs (
user_id, modell, verktygsparametrar, dokumentversion). - Sätt TTL baserat på hur snabbt underliggande data förändras. Kort TTL slår smart logik.
- Bypass cache när korrekthet är viktigare än hastighet: efter att användaren uppdaterat ett dokument, ändrat behörigheter eller begärt en refresh.
Om du inte kan förklara när en cachepost blir fel, cachea den inte.
Cachning av hemligheter och personlig data
Undvik att lägga API-nycklar, auth-tokens, råa prompts med känslig text eller användarspecifikt innehåll i delade lager som CDN-cachar. Om du måste cachea användardata, isolera per användare och kryptera i vila — eller håll det i din primära databas istället.
Mät påverkan: hastighet vs föråldrat UI
Caching bör bevisas, inte antas. Mät p95-latens före/efter, cache-hit rate och användar-synliga fel som "meddelande uppdaterat efter rendering." Ett snabbt svar som senare motsäger UI:t är ofta sämre än ett något långsammare, konsekvent svar.
Persistens och långkörande arbete: jobb, köer och status-tillstånd
Prototypa web och mobil
Skapa Flutter-mobiler och React-webbklienter som delar samma backend-tillstånd.
Vissa AI-funktioner blir klara på en sekund. Andra tar minuter: ladda upp och parsa en PDF, embedding och indexering av en knowledge base eller köra ett flerstegs verktygsworkflow. För dessa överlever tillstånd inte bara i skärmen — det måste överleva uppdateringar, retries och tid.
Vad att persistera (och varför)
Persist endast det som ger verkligt produktvärde.
Konversationshistorik är uppenbart: meddelanden, tidsstämplar, användaridentitet och ofta vilken modell/verktygsstack som användes. Det möjliggör "återuppta senare", revisionsspår och bättre support.
Användar- och workspace-inställningar bör ligga i databasen: föredragen modell, temperatur-standarder, feature toggles, systemprompts och UI-preferenser som följer användaren över enheter.
Filer och artefakter (uppladdningar, extraherad text, genererade rapporter) lagras ofta i objektlagring med databaspunkter som pekar på dem. Databasen håller metadata (ägare, storlek, content-type, processing state), medan blob-lagret håller bytesserna.
Bakgrundsjobb för långa uppgifter
Om en förfrågan inte kan slutföras inom en normal HTTP-timeout, flytta arbetet till en kö.
Ett typiskt mönster:
- Frontend anropar ett API som
POST /jobsmed inputs (file id, conversation id, parametrar). - Backend lägger jobb i kö (extraktion, indexering, batch-verktygskörningar) och returnerar omedelbart ett
job_id. - Workers processar jobben asynkront och skriver resultat tillbaka till beständig lagring.
Detta håller UI:t responsivt och gör retries säkrare.
Status-tillstånd som UI:t kan lita på
Gör jobbstatus explicit och frågbar: queued → running → succeeded/failed (valfritt canceled). Spara dessa övergångar serverside med tidsstämplar och felinformation.
På frontend, återspegla status tydligt:
Queued/running: visa spinner och inaktivera dubbletthandlingar.Failed: visa ett kort felmeddelande och en Retry-knapp.Succeeded: ladda artefakten eller uppdatera konversationen.
Exponera GET /jobs/{id} (polling) eller strömuppdateringar (SSE/WebSocket) så UI:t aldrig behöver gissa.
Idempotency-nycklar: retries utan dubbla skrivningar
Nätverks-timeouter händer. Om frontenden retry:ar POST /jobs vill du inte ha två identiska jobb (och dubbla kostnader).
Kräv en Idempotency-Key per logisk handling. Backend lagrar nyckeln med resulterande job_id/response och returnerar samma resultat för upprepade förfrågningar.
Rensa och expireringspolicyer
Långkörande AI-appar samlar snabbt data. Definiera retention-regler tidigt:
- Ta bort gamla konversationer efter N dagar (eller låt användaren konfigurera).
- Radera härledda artefakter när källan tas bort.
- Rensa periodiskt misslyckade jobb och mellanfiler.
Behandla cleanup som en del av tillståndshantering: det minskar risk, kostnad och förvirring.
Strömmande svar och realtidsuppdateringar: hantera partiellt tillstånd
Streaming gör tillstånd svårare eftersom "svaret" inte längre är ett enda blob. Du arbetar med partiella tokens (text som kommer ord för ord) och ibland partiellt verktygsarbete (en sökning startar och blir klar senare). Det betyder att UI:t och backend måste vara överens om vad som räknas som tillfälligt respektive slutligt tillstånd.
Backend: streama typade händelser, inte bara text
Ett rent mönster är att strömma en sekvens små händelser, var och en med en typ och en payload. Exempel:
token: inkrementell text (eller en liten chunk)tool_start: ett verktygsanrop har börjat (t.ex. "Söker...", med ett id)tool_result: verktygets output är klart (samma id)done: assistentmeddelandet är kompletterror: något gick fel (inkludera ett användarsäkert meddelande och en debug-id)
Denna event-ström är lättare att versionera och debugga än rå textströmning, eftersom frontend kan rendera progress exakt (och visa verktygsstatus) utan att gissa.
Frontend: append-only uppdateringar, sedan en slutlig commit
På klienten behandla streaming som append-only: skapa ett "utkast" till assistentmeddelande och fortsätt lägga till medan token-händelser kommer. När du får done, gör en commit: markera meddelandet som slutligt, persist det (om du lagrar lokalt) och lås upp åtgärder som kopiera, betygsätta eller regenerera.
Detta undviker att skriva om historiken mitt i streamen och håller UI:t förutsägbart.
Hantera avbrott (cancel, droppar, timeouter)
Streaming ökar risken för halvfärdigt arbete:
- Användaren avbryter: skicka en cancel-signal; sluta rendera tokens; behåll utkastet synligt som avbrutet.
- Nätverksavbrott: stoppa streamen; visa "återansluter..." och anta inte att det är klart.
- Server-timeouter/fel: finalisera utkastet som misslyckat och erbjuda retry som startar en ny förfrågan (syll inte tyst ihop streams).
Rehydrering: ladda om och återskapa stabilt tillstånd
Om sidan laddas om mitt i en stream, rekonstruera från senaste stabila tillstånd: de senaste commitade meddelandena plus eventuella lagrade utkastmetadata (message id, ackumulerad text, verktygsstatus). Om du inte kan återuppta streamen, visa utkastet som avbrutet och låt användaren försöka igen i stället för att låtsas att det slutfördes.
Säkerhet och integritet: skydda tillstånd end-to-end
Tjäna krediter medan du bygger
Dela vad du bygger med Koder.ai eller bjud in kollegor för att få extra krediter.
Tillstånd är inte bara data du lagrar — det är användarens prompts, uppladdningar, preferenser, genererade output och metadata som binder ihop allt. I AI-appar kan detta vara ovanligt känsligt (personuppgifter, proprietära dokument, interna beslut), så säkerhet måste designas in i varje lager.
Håll hemligheter på servern
Allt som skulle låta en klient imitera din app måste stanna serverside: API-nycklar, privata connectors (Slack/Drive/DB-credentials) och interna systemprompts eller routinglogik. Frontend kan be om en åtgärd ("sammanfatta den här filen"), men backend bör besluta hur det körs och med vilka credentials.
Auktorisera varje skrivning (och de flesta läsningar)
Behandla varje tillståndsmutation som en privilegierad operation. När klienten försöker skapa ett meddelande, byta namn på en konversation eller bifoga en fil, bör backend verifiera:
- Användaren är autentiserad.
- Användaren äger resursen (konversation, workspace, projekt).
- Användaren får utföra åtgärden (roll, planbegränsningar, org-policy).
Detta förhindrar ID-gissningsattacker där någon byter conversation_id och får åtkomst till en annans historik.
Lita aldrig på webbläsaren: validera och sanera
Anta att alla klient-levererade tillstånd är otillförlitlig input. Validera schema och begränsningar (typer, längder, tillåtna enums) och sanera för destinationen (SQL/NoSQL, loggar, HTML-rendering). Om du accepterar "tillståndsuppdateringar" (t.ex. inställningar, verktygsparametrar), whitelista tillåtna fält i stället för att slå samman godtycklig JSON.
Revisionsloggar för kritiska åtgärder
För åtgärder som ändrar beständigt tillstånd — dela, exportera, radera, koppla connectors — spela in vem som gjorde vad och när. En lättvikts audit-logg hjälper vid incidenthantering, support och compliance.
Dataminimering och kryptering
Spara bara det du behöver för funktionen. Om du inte behöver fulla prompts för evigt, överväg retention-window eller redigering. Kryptera känsligt tillstånd i vila när det är lämpligt (tokens, connector-credentials, uppladdade dokument) och använd TLS i transit. Separera operationell metadata från content så du kan begränsa åtkomst strängare.
Praktisk referensarkitektur och en bygg-checklista
En användbar standard för AI-appar är enkel: backend är sanningskällan och frontend är en snabb, optimistisk cache. UI:t kan kännas omedelbart, men allt du skulle bli ledsen över att förlora (meddelanden, jobbstatus, verktygsresultat, faktureringshändelser) bör bekräftas och sparas serverside.
Om du bygger med en snabb iterations-workflow — där stora delar av produktytan genereras snabbt — blir tillståndsmodellen ännu viktigare. Plattformar som Koder.ai kan hjälpa team att leverera fulla webb-, backend- och mobilappar från chatt, men samma regel gäller: snabb iteration är säkrast när sanningskällor, IDs och statusövergångar designas i förväg.
Referensarkitektur (en du kan skicka)
Frontend (browser/mobile)
- UI-tillstånd: öppna paneler, utkaststext, vald modell, temporära "byter"-indikatorer.
- Cachat server-tillstånd: senaste konversationer, senaste jobbstatus, partiell stream-buffer.
- En enda request-pipeline som alltid bifogar:
session_id,conversation_idoch en nyrequest_id.
Backend (API + workers)
- API-service: validerar input, skapar poster, ger strömmande svar.
- Beständig lagring (SQL/NoSQL): konversationer, meddelanden, verktygsanrop, jobbstatus.
- Kö + workers: långkörande uppgifter (RAG-indexering, filparsing, bildgenerering).
- Cache (valfritt): heta reads (konversationssammanfattningar, embeddings-metadata), alltid nycklade med versioner/tidsstämplar.
Notera: ett praktiskt sätt att hålla detta konsekvent är att standardisera backend-stack tidigt. Till exempel använder Koder.ai-genererade backends ofta Go med PostgreSQL (och React i frontend), vilket gör det enkelt att centralisera "auktoritativt" tillstånd i SQL medan klientcachen är förgänglig.
Designa din tillståndsmodell först
Innan du bygger skärmar, definiera fälten du kommer lita på i varje lager:
IDs och ägarskap:user_id,org_id,conversation_id,message_id,request_id.Tidsstämplar och ordning:created_at,updated_atoch en explicitsequenceför meddelanden.Statusfält:queued | running | streaming | succeeded | failed | canceled(för jobb och verktygsanrop).Versionering:etagellerversionför konflikt-säkra uppdateringar.
Detta förhindrar klassiska buggar där UI:t "ser rätt ut" men inte kan försonas vid retries, uppdateringar eller samtidiga redigeringar.
Använd konsekventa API-former
Håll endpoints förutsägbara över funktioner:
GET /conversations(lista)GET /conversations/{id}(hämta)POST /conversations(skapa)POST /conversations/{id}/messages(lägg till)PATCH /jobs/{id}(uppdatera status)GET /streams/{request_id}ellerPOST .../stream(stream)
Returnera samma envelopestil överallt (inklusive fel) så frontend kan uppdatera tillstånd enhetligt.
Lägg till observabilitet där tillstånd kan gå fel
Logga och returnera ett request_id för varje AI-anrop. Spela in verktygsanrops inputs/outputs (med redigering), latens, retries och slutlig status. Gör det enkelt att svara på: "Vad såg modellen, vilka verktyg kördes och vilket tillstånd persisterade vi?"
Bygg-checklista (för att undvika vanliga tillståndsbuggar)
- Backend är sanningskällan; frontend-cachen är tydligt märkbar och förgänglig.
- Varje skrivning är idempotent (säkert att retrya) med
request_id(och/eller en Idempotency-Key). - Statustransitioner är explicita och validerade (inga tysta hopp från
queuedtillsucceeded). - Streaminguppdateringar slås samman via IDs/sekvens, inte genom "senaste meddelandet vinner".
- Konflikter hanteras via
version/etageller serverside merge-regler. - PII och hemligheter lagras aldrig i klienttillstånd; redigera loggar som standard.
- En dashboard för debugging finns: förfrågningar, verktygsanrop, jobbstatus och fel.
När du antar snabbare byggcykler (inklusive AI-assisterad generation), överväg att lägga in guardrails som automatiskt uppfyller dessa checklist-punkter — schema-validering, idempotens och eventad streaming — så att "snabbt" inte blir till tillståndsdrift. I praktiken är det här en end-to-end-plattform som Koder.ai kan vara användbar: den snabbar upp leverans samtidigt som du kan exportera koden och behålla konsekventa tillståndsmönster över web, backend och mobil.