21 sep. 2025·8 min
Hur C och C++ fortfarande driver operativsystem, databaser och spelmotorer
Se hur C och C++ fortfarande utgör kärnan i operativsystem, databaser och spelmotorer — genom minneskontroll, snabbhet och låg-nivåtillgång.
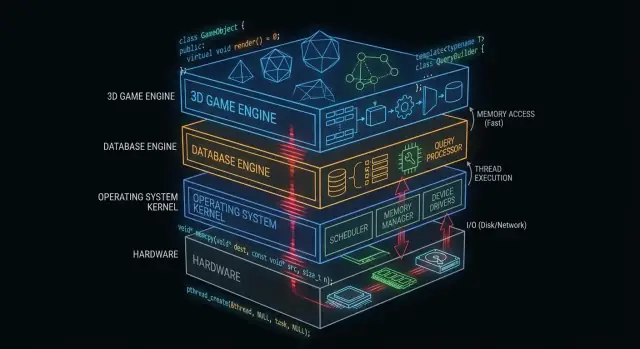
Varför C och C++ fortfarande är viktiga bakom kulisserna
"Under huven" är allt din app är beroende av men sällan rör vid direkt: operativsystemskärnor, enhetsdrivrutiner, databaslagringsmotorer, nätverksstackar, runtime-miljöer och prestandakritiska bibliotek.
Till vardags ser många applikationsutvecklare ytan: ramverk, API:er, hanterade runtime-miljöer, paketverktyg och molntjänster. Dessa lager är byggda för att vara säkra och produktiva — även när de medvetet döljer komplexitet.
Varför vissa lager måste ligga nära hårdvaran
Vissa mjukvarukomponenter har krav som är svåra att uppfylla utan direkt kontroll:
- Förutsägbar prestanda och latens (t.ex. schemalägga CPU-tid, hantera avbrott, streama assets)
- Precisionsstyrning över minnet (layout, justering, cachebeteende, undvika pauser)
- Direkt hårdvaruåtkomst (register, DMA, drivrutiner, filsystem och blockenheter)
- Små, portabla binärer som kan köras tidigt i boot eller i begränsade miljöer
C och C++ är fortfarande vanliga här eftersom de kompileras till native-kod med minimal runtime-överhead och ger ingenjörer finstyrlig kontroll över minne och systemanrop.
Var C och C++ är vanligast idag
På en hög nivå hittar du C och C++ som drivkraft i:
- Operativsystemskärnor och låg-nivåbibliotek
- Drivrutiner och inbyggd firmware
- Databasmotorer (främst frågaexekvering, lagring, indexering)
- Spelmotorer och realtidsdelar (rendering, fysik, ljud)
- Kompilatorer, verktygskedjor och språkramverk som andra språk bygger på
Vad detta inlägg kommer (och inte kommer) att täcka
Den här artikeln fokuserar på mekaniken: vad dessa komponenter gör, varför de gynnas av native-kod och vilka kompromisser som följer med den kraften.
Den påstår inte att C/C++ alltid är bästa valet, och den ska inte bli ett språkbråk. Målet är praktisk förståelse för var dessa språk fortfarande förtjänar sin plats — och varför moderna mjukvarustackar fortsätter bygga på dem.
Vad gör C och C++ lämpade för systemsprogramvara
C och C++ används ofta för systemsprogramvara eftersom de möjliggör "nära metallen"-program: små, snabba och tätt integrerade med OS och hårdvara.
Kompileras till native-kod (på enkelt sätt)
När C/C++-kod kompileras blir den maskininstruktioner som CPU:n kan köra direkt. Det finns ingen nödvändig runtime som översätter instruktionerna medan programmet körs.
Det spelar roll för infrastrukturella komponenter — kärnor, databasmotorer, spelmotorer — där även små overheads kan adderas under belastning.
Förutsägbar prestanda för kärninfrastruktur
Systemsprogramvara behöver ofta konstant timing, inte bara bra genomsnittlig hastighet. Till exempel:
- Ett operativsystems schemaläggare måste reagera snabbt under belastning.
- En databas måste hålla latensen stabil när många användare frågar samtidigt.
- En spelmotor måste nå ett ram-budget (t.ex. ~16 ms för 60 FPS).
C/C++ ger kontroll över CPU-användning, minneslayout och datastrukturer, vilket hjälper ingenjörer att sikta på förutsägbar prestanda.
Direkt minnes- och pointeråtkomst
Pointerar låter dig arbeta med minnesadresser direkt. Denna kraft kan låta skrämmande, men den låser upp kapaciteter som många högre nivåers språk abstraherar bort:
- Anpassade allocatorer anpassade till specifika arbetslaster
- Kompakta in-memory-format (användbart i databaser och cache)
- Zero-copy I/O-mönster där data inte dupliceras onödigt
Används med omsorg kan denna kontroll ge dramatiska effektivitetsvinster.
Kompromisser: säkerhet, komplexitet och utvecklingstid
Samma frihet är också risken. Vanliga kompromisser inkluderar:
- Säkerhet: misstag kan orsaka krascher, datakorruption eller sårbarheter.
- Komplexitet: manuell minneshantering och undefined behavior kräver disciplin.
- Utvecklingstid: testning, granskning och verktyg blir oundvikliga för tillförlitlighet.
En vanlig strategi är att hålla den prestandakritiska kärnan i C/C++ och omge den med säkrare språk för produktfunktioner och UX.
C/C++ i operativsystemskärnor
Operativsystemskärnan sitter allra närmast hårdvaran. När din laptop vaknar, din webbläsare öppnas eller ett program begär mer RAM, samordnar kärnan dessa förfrågningar och bestämmer vad som händer.
Vad en kernel faktiskt gör
Praktiskt hanterar kärnor några kärnuppgifter:
- Schemaläggning: bestämmer vilket program (och vilken tråd) som får CPU-tid och hur länge.
- Minneshantering: tilldelar minne till processer, håller dem isolerade och återtar minne säkert.
- Enhetshantering: pratar med hårdvara genom drivrutiner (disk, nätverk, tangentbord, GPU, etc.).
- Säkerhetsgränser: upprätthåller behörigheter så att ett program inte kan läsa eller förstöra ett annat programs data.
Eftersom dessa ansvar ligger i systemets mitt är kernelkod både prestandakänslig och korrekthetskänslig.
Varför strikt kontroll gynnar C (och ibland C++)
Kernelutvecklare behöver precis kontroll över:
- Minneslayout: fasta strukturer, alignment och förutsägbar tilldelningsbeteende.
- CPU-instruktioner och calling conventions: interaktion med avbrott, context switches och låg-nivå synkronisering.
- Hårdvaruregister: läsa/skriva specifika adresser och hantera särskilda CPU-lägen.
C förblir ett vanligt "kernel-språk" eftersom det kartlägger rent mot maskin-koncept samtidigt som det är läsbart och portabelt över arkitekturer. Många kärnor förlitar sig också på assembly för de minsta, mest hårdvaruspecifika delarna, medan C tar hand om huvuddelen.
C++ kan förekomma i kärnor, men vanligtvis i en begränsad stil (få runtime-funktioner, restriktiva undantagspolicys och noggranna regler för allokering). När det används är det ofta för att förbättra abstraktion utan att ge upp kontroll.
Kernel-nära kod skrivs ofta i C/C++
Även när kärnan själv är konservativ, är många närliggande komponenter C/C++:
- Enhetsdrivrutiner (speciellt prestandakritiska)
- Standardbibliotek och runtime-delar (delar av libc, låg-nivåtrådar)
- Bootloaders och tidig uppstarts-kod
- Systemtjänster som behöver native-hastighet (t.ex. nätverks- eller lagringshjälpare)
För mer om hur drivrutiner bygger en bro mellan mjukvara och hårdvara, se /blog/device-drivers-and-hardware-access.
Enhetsdrivrutiner och hårdvaruåtkomst
Enhetsdrivrutiner översätter mellan ett operativsystem och fysisk hårdvara — nätverkskort, GPU:er, SSD-kontrollers, ljudenheter och mer. När du klickar "play", kopierar en fil eller ansluter till Wi‑Fi är det ofta en drivrutin som först måste svara.
Eftersom drivrutiner ligger på den heta vägen för I/O är de extremt prestandakänsliga. Några extra mikrosekunder per paket eller per diskanrop kan snabbt adderas på upptagna system. C och C++ är vanliga här eftersom de kan anropa kärn-API:er direkt, kontrollera minneslayout exakt och köras med minimal overhead.
Avbrott, DMA och varför låg-nivå-API:er spelar roll
Hårdvara väntar inte artigt på sin tur. Enheter signalerar CPU:n via avbrott — brådskande notifieringar att något hänt (ett paket anlände, en överföring avslutades). Drivrutinskod måste hantera dessa händelser snabbt och korrekt, ofta under strikta timing- och trådningsbegränsningar.
För hög genomströmning förlitar sig drivrutiner också på DMA (Direct Memory Access), där enheter läser/skriver systemminne utan att CPU:n kopierar varje byte. Att ställa in DMA involverar typiskt:
- Förbereda buffrar i rätt format och alignment
- Ge enheten fysiska adresser eller mappade descriptors
- Synkronisera ägandeskap av minne mellan enhet och CPU
Dessa uppgifter kräver låg-nivå-gränssnitt: memory-mapped registers, bitflaggor och noggrann ordning i läs-/skrivoperationer. C/C++ gör det praktiskt att uttrycka denna "nära metallen"-logik samtidigt som det kan vara portabelt över kompilatorer och plattformar.
Stabilitet är icke-förhandlingsbar
Till skillnad från en vanlig app kan en drivrutinsbugg krascha hela systemet, korrupta data eller öppna säkerhetshål. Den risken formar hur drivrutinskod skrivs och granskas.
Team minskar faran genom strikta kodstandarder, defensiva kontroller och lager av granskningar. Vanliga metoder inkluderar att begränsa osäker pointeranvändning, validera indata från hårdvara/firmware och köra statisk analys i CI.
Minneshantering: kraft och fallgropar
Get more build credits
Tjäna krediter genom att skapa innehåll om Koder.ai eller bjuda in andra med din referral-länk.
Minneshantering är en av de största anledningarna till att C och C++ fortfarande dominerar delar av operativsystem, databaser och spelmotorer. Det är också ett av de lättaste ställena att skapa subtila buggar.
Vad "minneshantering" innebär
I praktiken inkluderar minneshantering:
- Allokera minne (skaffa en bit för att lagra data)
- Frigöra det (lämna tillbaka när du är klar)
- Hantera fragmentering (överskottsutrymmen som gör framtida allokeringar långsammare eller svårare)
I C görs detta ofta explicit (malloc/free). I C++ kan det vara explicit (new/delete) eller paketerat i säkrare mönster.
Varför manuell kontroll kan vara en fördel
I prestandakritiska komponenter kan manuell kontroll vara en funktion:
- Du kan undvika oförutsägbara pauser från garbage collection.
- Du kan välja var och hur minne allokeras (t.ex. pooler eller arena-allocatorer), vilket förbättrar konsekvens.
- Du kan anpassa allokeringsmönster till verkliga arbetslaster (många små objekt vs stora sammanhängande buffrar).
Detta är viktigt när en databas måste bibehålla stabil latens eller en spelmotor måste hålla ram-tidsbudget.
Vanliga feltyper (och varför de är allvarliga)
Samma frihet skapar klassiska problem:
- Minnesläckor: glömma frigöra minne, vilket gör att användningen växer tills prestandan försämras eller processen kraschar.
- Buffer overflow: skriva förbi slutet av en array, korrupta data eller möjliggöra exploateringar.
- Use-after-free: använda en pointer efter att den frigjorts, vilket leder till krascher som är svåra att reproducera.
Dessa buggar kan vara subtila eftersom programmet kan "verka bra" tills en specifik arbetslast utlöser felet.
Hur moderna metoder hjälper
Modern C++ minskar risken utan att ge upp kontroll:
- RAII (Resource Acquisition Is Initialization) knyter resursers livstid till scope så att städning sker automatiskt.
- Smart pointers (som
std::unique_ptrochstd::shared_ptr) gör ägarskap explicit och förhindrar många läckor. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) och statisk analys hittar problem tidigt, ofta i CI.
Används väl håller dessa verktyg C/C++ snabba samtidigt som de minskar sannolikheten att minnesbuggar når produktion.
Konkurrens och flerkärnprestanda
Moderna CPU:er blir inte dramatiskt snabbare per kärna — de får fler kärnor. Det flyttar prestandafrågan från "Hur snabb är min kod?" till "Hur bra kan min kod köras parallellt utan att gå i vägen för sig själv?" C och C++ är populära här eftersom de tillåter låg-nivåkontroll över trådar, synkronisering och minnesbeteende med mycket liten overhead.
Trådar, kärnor och schemaläggning
En tråd är en enhet din kod använder för arbete; en CPU-kärna är där arbetet körs. OS-schemaläggaren mappar runnable trådar till tillgängliga kärnor och gör hela tiden avvägningar.
Små schemaläggningsdetaljer spelar roll i prestandakritisk kod: att pausa en tråd vid fel ögonblick kan stalla en pipeline, skapa kö-backlogs eller ge ryckigt beteende. För CPU-bundet arbete minskar ofta att hålla aktiva trådar ungefär i nivå med kärnantalet thrashing.
Låsning: mutexar, atomics och contention
- Mutexar är lätta att resonera om, men tung delning skapar contention — tid som spenderas väntande istället för att arbeta.
- Atomics kan vara snabbare för små uppdateringar av delat tillstånd, men kräver omsorgsfull design för att undvika subtila korrekthetsfel.
Det praktiska målet är inte "aldig låsa" utan: lås mindre, lås smartare — håll kritiska sektioner små, undvik globala lås och minska delat muterbart tillstånd.
Varför latensspikar spelar roll
Databaser och spelmotorer bryr sig inte bara om genomsnittlig hastighet — de bryr sig om värsta fallets pauser. En låskonvoj, page fault eller avstannad worker kan ge synbart hack, inmatningsfördröjning eller en långsam fråga som bryter ett SLA.
Vanliga C/C++-mönster
Många högpresterande system förlitar sig på:
- Trådpooler för att återanvända workers och hålla schemaläggningen förutsägbar.
- Work-stealing-köer för att balansera belastning över kärnor.
- Låsfri köer (i utvalda heta vägar) för att minska blockering — använd med försiktighet eftersom korrekthet är svårare att bevisa.
Dessa mönster siktar på stadig genomströmning och konsekvent latens under tryck.
Databasmotorer: där C/C++ ger hastighet
En databasmotor är inte bara "lagra rader." Det är en tight loop av CPU- och I/O-arbete som körs miljoner gånger per sekund, där små ineffektiviteter snabbt adderas. Därför är så många motorer och kärnkomponenter fortfarande skrivna till stor del i C eller C++.
Motorens huvuduppgift: parse, plan, exekvera
När du skickar SQL gör motorn:
- Parsar den (omvandlar text till en strukturerad representation)
- Planerar den (väljer ett effektivt sätt att svara på frågan)
- Exekverar den (skannar, indexuppslag, joins, sorteringar, aggregeringar och returnerar rader)
Varje steg gynnas av noggrann kontroll över minne och CPU-tid. C/C++ möjliggör snabba parserar, färre allokationer under planering och en slimmad exekverings-hotpath — ofta med anpassade datastrukturer för arbetslasten.
Lagringsmotorer: sidor, index, buffring
Under SQL-lagret hanterar lagringsmotorn de oansenliga men viktiga detaljerna:
- Sidor: data läses och skrivs i fasta block, inte rad-för-rad.
- Index: B-träd, LSM-träd och relaterade strukturer måste uppdateras effektivt.
- Buffring: en buffer pool bestämmer vad som stannar i minnet, vad som evikteras och hur läsningar/skrivningar batches.
C/C++ passar bra här eftersom dessa komponenter bygger på förutsägbar minneslayout och direkt kontroll över I/O-gränser.
Cachevänliga datastrukturer (varför det spelar roll)
Modern prestanda beror ofta mer på CPU-cacher än rå CPU-hastighet. Med C/C++ kan utvecklare packa ofta använda fält tillsammans, lagra kolumner i sammanhängande arrayer och minimera pointer-chasing — mönster som håller data nära CPU:n och minskar stalls.
Var högre nivå-språk fortfarande visar sig
Även i C/C++-tunga databaser driver högre nivå-språk ofta adminverktyg, backup, övervakning, migreringar och orkestrering. Den prestandakritiska kärnan förblir native; omgivningen prioriterar iterationshastighet och användbarhet.
Lagring, caching och I/O i databaser
Build the mobile surface
Skapa en Flutter-mobilapp och håll produktiteration åtskild från låg-nivåoptimeringar.
Databaser känns omedelbara eftersom de arbetar hårt för att undvika disk. Även på snabba SSD:er är läsning från lagring flera storleksordningar långsammare än att läsa från RAM. En databasmotor skriven i C eller C++ kan kontrollera varje steg av den väntetiden — och ofta undvika den.
Buffer pool och page cache enkel förklaring
Tänk på data på disk som lådor i ett lager. Att hämta en låda (diskläsning) tar tid, så du håller de mest använda sakerna på ett skrivbord (RAM).
- Buffer pool: databasens eget "skrivbord" som håller nyligen använda sidor (fasta chunkar av tabeller och index).
- Page cache: operativsystemets "skrivbord" som cache:ar nyligen läst fildata.
Många databaser har sin egen buffer pool för att förutsäga vad som bör hållas het och undvika kamp om minnet med OS:et.
Varför disk är långsamt — och hur caching döljer det
Lagring är inte bara långsam; den är också oförutsägbar. Latensspikar, köer och slumpmässig åtkomst lägger till fördröjning. Caching mildrar detta genom att:
- Servera läsningar från RAM i de flesta fall
- Batcha skrivningar till färre, större I/O-operationer
- Prefetcha sidor som sannolikt behövs nästa (t.ex. vid indexskanning)
Designval som gynnas av låg-nivåkontroll
C/C++ låter databasmotorer tune detaljer som spelar roll vid hög genomströmning: alignerade läsningar, direct I/O vs buffered I/O, egna eviction-policyer och noggrant strukturerade in-memory-layouts för index och loggbuffrar. Dessa val kan minska kopior, undvika contention och hålla CPU-cacherna matade med relevant data.
Komprimering och checksummor kan bli CPU-bundna
Caching minskar I/O men ökar CPU-arbete. Dekomprimering av sidor, beräkning av checksummor, kryptering av loggar och validering av poster kan bli flaskhalsar. Eftersom C och C++ ger kontroll över minnesåtkomstmönster och SIMD-vänliga loopar används de ofta för att pressa mer arbete ur varje kärna.
Spelmotorer: realtidskrav
Spelmotorer arbetar under strikta realtidsförväntningar: spelaren rör kameran, trycker på en knapp och världen måste svara omedelbart. Detta mäts i ram-tid, inte genomsnittlig genomströmning.
Ram-budgetar: varför millisekunder spelar roll
Vid 60 FPS får du cirka 16.7 ms för att producera en frame: simulering, animation, fysik, ljudmixning, culling, rendering submission och ofta streamning av assets. Vid 120 FPS sjunker budgeten till 8.3 ms. Missa budgeten och spelaren uppfattar det som hack, input-lag eller ojämn takt.
Det är därför C-programmering och C++-programmering fortfarande är vanliga i motorers kärna: förutsägbar prestanda, låg overhead och fin kontroll över minne och CPU-användning.
Kärnsubsystem som ofta skrivs i C/C++
De flesta motorer använder native-kod för det tunga arbetet:
- Rendering (scen-traversal, byggande av draw-calls, GPU-resurshantering)
- Fysik (kollisionstestning, constraints, rigid bodies)
- Animation (skeletal blending, IK, pose-evaluering)
- Audio (realtidsmixning, spatialisering)
Dessa system körs varje frame, så små ineffektiviteter multipliceras snabbt.
Tighta loopar och minneslayout
Mycket av spelprestandan handlar om tighta loopar: iterera entiteter, uppdatera transforms, testa kollisioner, skinna vertices. C/C++ gör det enklare att strukturera minnet för cache-effektivitet (sammanhängande arrayer, färre allokeringar, färre virtuella indirectioner). Datastrukturernas layout kan vara lika viktig som algoritmval.
Var skript passar in (och var de inte gör det)
Många studios använder skriptspråk för gameplay-logik — quests, UI-regler, triggers — eftersom iterationshastighet är viktig. Motorkärnan förblir native, och skript anropar C/C++-system via bindings. Ett vanligt mönster: skript orkestrerar; C/C++ exekverar de kostsamma delarna.
Kompilatorer, verktygskedjor och interop
Keep native code isolated
Prototypa en FFI-gräns och koppla din app till befintlig C- eller C++-kod.
C och C++ blir inte bara "körda" — de byggs till native-binarier som matchar en viss CPU och operativsystem. Denna byggpipeline är en stor anledning till att språken förblir centrala för operativsystem, databaser och spelmotorer.
Vad som händer under en build
En typisk build har några steg:
- Kompilator: förvandlar C/C++-källkod till maskinspecifika objektfiler.
- Linker: sammanfogar objekt med bibliotek för att skapa en körbar fil eller delat bibliotek.
- Binärt utdata: artefakten som OS kan ladda direkt (ofta med separata debug-symboler).
Linker-steget är där många verkliga problem dyker upp: saknade symboler, felaktiga biblioteksversioner eller inkompatibla build-inställningar.
Varför verktygskedjor och plattformsstöd spelar roll
En verktygskedja är hela paketet: kompilator, linker, standardbibliotek och byggverktyg. För systemsprogramvara kan plattformsstöd vara avgörande:
- Konsol- och mobil-SDK:er kan kräva specifika kompilatorer och linkers.
- Databaser och backend-mjukvara behöver stabila builds över Linux-distributioner och CPU-typer.
- OS- och drivrutinsarbete kan kräva cross-kompilatorer, strikta flaggor och ABI-disciplin.
Team väljer ofta C/C++ delvis eftersom verktygskedjorna är mogna och finns över miljöer — från inbyggda enheter till servrar.
Interfacing med andra språk (FFI)
C behandlas ofta som "universell adapter." Många språk kan anropa C-funktioner via FFI, så team lägger ofta prestandakritisk logik i ett C/C++-bibliotek och exponerar en liten API till högre nivåers kod. Det är därför Python, Rust, Java och andra ofta wrapp:ar befintliga C/C++-komponenter istället för att skriva om dem.
Debugging och profilering: vad team mäter
C/C++-team mäter typiskt:
- CPU-tid (heta funktioner, call stacks)
- Minnesanvändning (allokationer, läckor, fragmentering)
- Latens (frame time i spel, frågetid i databaser)
- I/O-beteende (cache-missar, diskläsningar, systemanrop)
Arbetsflödet är konsekvent: hitta flaskhalsen, bekräfta med data, optimera sedan den minsta del som verkligen spelar roll.
Att välja C/C++ idag: praktisk beslutsguide
C och C++ är fortfarande utmärkta verktyg — när du bygger mjukvara där några millisekunder, några byte eller en specifik CPU-instruktion verkligen betyder något. De är inte automatiskt bästa valet för varje funktion eller team.
När C/C++ är rätt val
Välj C/C++ när komponenten är prestandakritisk, behöver tät minneskontroll eller måste integrera nära med OS eller hårdvara.
Typiska passningar inkluderar:
- Heta vägar där latens är synlig (parsing, kompression, rendering, frågaexekvering)
- Låg-nivåmoduler som måste vara förutsägbara (allocatorer, schemaläggare, nätverksprimitiver)
- Plattformoberoende bibliotek där native-kod är produkten (SDK:er, motorer, inbäddat)
- Situationer där portabilitet över kompilatorer/verktygskedjor är ett hårt krav
När andra språk föredras
Välj ett högre nivå-språk när prioriteten är säkerhet, iterationshastighet eller underhållbarhet i stor skala.
Det är ofta smartare att använda Rust, Go, Java, C#, Python eller TypeScript när:
- Teamet är stort och personalomsättning förväntas (färre "foot-guns" spelar roll)
- Funktionen ändras ofta och korrekthet väger tyngre än att pressa cykler
- Du behöver starka minnessäkerhetsgarantier
- Utvecklarproduktivitet och rekryteringsbas är viktigare än rå prestanda
I praktiken är de flesta produkter en blandning: native-bibliotek för den kritiska vägen, och högre nivåers tjänster och UI för allt annat.
Ett praktiskt meddelande för app-team (var Koder.ai passar in)
Om du främst bygger webb-, backend- eller mobilfunktioner behöver du ofta inte skriva C/C++ för att dra nytta av det — du konsumerar det via ditt OS, databas, runtime och beroenden. Plattformar som Koder.ai lut ar sig mot den uppdelningen: du kan snabbt producera React-webbappar, Go + PostgreSQL-backends eller Flutter-mobilappar via en chattdriven workflow, samtidigt som du integrerar native-komponenter när det behövs (t.ex. anropa ett befintligt C/C++-bibliotek via en FFI-gräns). På så sätt håller du större delen av produkten i snabb-itererande kod utan att ignorera var native-kod är rätt verktyg.
Praktisk checklista (komponent för komponent)
Ställ dessa frågor innan du bestämmer dig:
- Är detta på den kritiska vägen? Mät först; gissa inte.
- Vilka är felmoderna? Minneskorruption i C/C++ kan vara katastrofal.
- Vad är gränssnittets boundary? Kan du isolera native-kod bakom ett litet API?
- Har ni kompetensen? Granskning, testning och profilering är oundvikliga.
- Vad är distributionsmålet? Konsoler, inbäddat, kernels och drivrutiner favoriserar ofta C/C++.
- Hur ska ni testa och profilera det? Planera verktyg och CI från dag ett.
Föreslagna nästa läsningar
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing