07 maj 2025·8 min
Hur databasshardning fungerar — och varför det är svårt att överblicka
Sharding ökar databaskapacitet genom att dela data över noder, men lägger till routing, ombalansering och nya fel‑lägen som gör system svårare att överblicka.
Sharding ökar databaskapacitet genom att dela data över noder, men lägger till routing, ombalansering och nya fel‑lägen som gör system svårare att överblicka.
Sharding (kallas också horisontell partitionering) innebär att det som ser ut som en databas för din applikation delas upp över flera maskiner, kallade shards. Varje shard innehåller bara en delmängd av raderna, men tillsammans representerar de hela datasetet.
En användbar mental modell är skillnaden mellan logisk struktur och fysisk placering.
Ur applikationens synvinkel vill du köra frågor som om det vore en tabell. Under huven måste systemet bestämma vilken eller vilka shards som ska kontaktas.
Sharding skiljer sig från replikering. Replikering skapar kopior av samma data på flera noder, främst för hög tillgänglighet och läs‑skalning. Sharding delar upp data så varje nod håller olika poster.
Det skiljer sig också från vertikal skalning, där du behåller en databas men flyttar den till en större maskin (mer CPU/RAM/snabbare diskar). Vertikal skalning kan vara enklare, men har praktiska gränser och blir snabbt dyrt.
Sharding ökar kapacitet, men gör inte automatiskt din databas “enkel” eller att varje fråga blir snabbare.
Så sharding bör ses som ett sätt att skala lagring och genomströmning—inte en gratis förbättring av alla databass beteenden.
Sharding är sällan någons första val. Team når oftast dit efter att systemet träffat fysiska begränsningar—eller efter att operativ smärta blivit för frekvent för att ignorera. Motivationen är mindre “vi vill sharda” och mer “vi behöver växa utan att en databas blir en single point of failure och kostnad.”
En enda databasknute kan få slut på utrymme på flera sätt:
När dessa problem dyker upp regelbundet är det ofta inte en enda dålig fråga—det är att en maskin bär för mycket ansvar.
Databasshardning sprider data och trafik över flera noder så kapacitet växer genom att lägga till maskiner istället för att uppgradera en. Gjort rätt kan det också isolera arbetsbelastningar (så att en tenants peak inte saboterar latens för andra) och kontrollera kostnader genom att undvika allt större premium‑instanser.
Återkommande mönster inkluderar stadigt stigande p95/p99‑latens under peak, längre replikeringslagg, backuper/restore som överskrider acceptabla fönster och ”små” schemaändringar som blir stora events.
Innan man bestämmer sig försöker team normalt enklare alternativ: indexering och frågefixar, caching, read replicas, partitionering inom en enda databas, arkivering av gammal data och hårdvaruuppgraderingar. Sharding kan lösa skala, men lägger också till koordination, operationell komplexitet och nya fel‑lägen—så ribban bör vara hög.
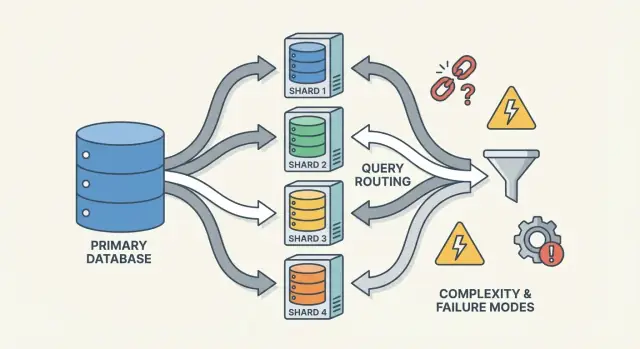
En sharded databas är inte en sak—det är ett litet system av samverkande delar. Anledningen till att sharding kan kännas “svårt att överblicka” är att korrekthet och prestanda beror på hur dessa delar interagerar, inte bara på databasmotorn.
En shard är en delmängd av datan, vanligtvis lagrad på sin egen server eller kluster. Varje shard har typiskt:
Ur applikationens synvinkel försöker ett sharded upplägg ofta se ut som en logisk databas. Men under huven kan en fråga som vore “en index‑uppslagning” på en enskild nod bli “hitta rätt shard, sedan gör uppslagningen.”
En router (ibland kallad koordinator, query router eller proxy) är trafikpolisen. Den svarar på den praktiska frågan: givet den här förfrågan, vilken shard ska hantera den?
Det finns två vanliga mönster:
Routrar minskar komplexitet i appen, men de kan också bli en flaskhals eller en ny felpunkt om de inte är designade noggrant.
Sharding bygger på metadata—en sanningens källa som beskriver:
Denna information lever ofta i en konfigurationsservice (eller en liten “control plane”‑databas). Om metadata är föråldrad eller inkonsekvent kan routrar skicka trafik till fel plats—även om varje shard är fullt frisk.
Slutligen förlitar sig sharding på bakgrundsprocesser som håller systemet hanterbart över tid:
Dessa jobb är lätta att ignorera tidigt, men det är där många produktionsöverraskningar händer—eftersom de ändrar systemets form medan det fortfarande servar trafik.
En shard‑nyckel är fältet (eller kombinationen av fält) ditt system använder för att bestämma vilken shard som ska lagra en rad/dokument. Det enkla valet påverkar i tysthet prestanda, kostnad och vilka funktioner som blir “lättare” senare—eftersom det styr om förfrågningar kan routas till en shard eller måste spridas.
En bra nyckel tenderar att ha:
Ett vanligt exempel är att sharda på tenant_id i en multi‑tenant‑app: de flesta läsningar och skrivningar för en tenant stannar på en shard, och tenants är tillräckligt många för att sprida lasten.
Vissa nycklar nästan garanterar problem:
Även om en lågkardinal nyckel verkar bekväm för filtrering, tenderar den att göra rutinfrågor till scatter‑gather eftersom matchande rader finns överallt.
Den bästa shard‑nyckeln för lastbalansering är inte alltid den bästa för produktfrågor.
user_id), och vissa “globala” frågor (t.ex. admin‑rapporter) blir långsammare eller kräver separata pipelines.region), och du riskerar hotspots och ojämn kapacitet.De flesta team designar runt denna avvägning: optimera shard‑nyckeln för de vanligaste, latency‑känsliga operationerna—hantera resten med index, denormalisering, repliker eller dedikerade analys‑tabeller.
Det finns inget enda “bästa” sätt att sharda en databas. Strategin du väljer formar hur lätt det är att routa frågor, hur jämnt datan fördelas och vilka åtkomstmönster som blir problematiska.
Med range sharding äger varje shard ett sammanhängande segment av ett nyckelrum—till exempel:
Routing är enkel: titta på nyckeln, välj sharden.
Nackdelen är hotspots. Om nya användare alltid får stigande ID:n blir den “sista” sharden skrivflaskhalsen. Range sharding är också känslig för ojämn tillväxt (en range blir populär, en annan förblir tyst). Fördelen: range‑frågor (”alla order från 1–31 okt”) kan vara effektiva eftersom data är fysiskt grupperad.
Hash sharding kör shard‑nyckeln genom en hashfunktion och använder resultatet för att välja en shard. Detta sprider vanligtvis data jämnare och hjälper undvika att allt går till den senaste sharden.
Avvägningen: range‑frågor blir svåra. En fråga som “customers med ID mellan X och Y” mappar inte längre till ett litet antal shards; den kan röra vid många.
Ett praktiskt detaljer som ofta underskattas är konsekvent hashing. Istället för att mappa direkt till antalet shards (vilket omfördelar allt när du lägger till shards) använder många system en hash‑ring med “virtuella noder” så att tillägg av kapacitet flyttar endast en del av nycklarna.
Directory sharding lagrar en explicit mappning (en lookup‑tabell/tjänst) från nyckel → shard‑plats. Detta är mest flexibelt: du kan placera specifika tenants på dedikerade shards, flytta en kund utan att flytta alla andra och stödja ojämna shard‑storlekar.
Nackdelen är ett extra beroende. Om directoryn är långsam, föråldrad eller otillgänglig påverkas routingen—även om shards är friska.
Verkliga system blandar ofta angreppssätt. En komposit shard‑nyckel (t.ex. tenant_id + user_id) håller tenants isolerade samtidigt som den sprider lasten inom en tenant. Sub‑sharding är liknande: först routea efter tenant, sedan hash inom den tenantens shard‑grupp för att undvika att en “stor tenant” dominerar en shard.
En sharded databas har två mycket olika “frågestigar.” Att förstå vilken stig du är på förklarar de flesta överraskningar i prestanda—och varför sharding kan kännas oförutsägbar.
Det ideala är att routa en fråga till exakt en shard. Om förfrågan inkluderar shard‑nyckeln (eller något som routern kan mappa) kan systemet skicka den direkt till rätt ställe.
Därför fokuserar team på att göra vanliga läsningar “shard‑nyckel‑medvetna.” En shard betyder färre nätverkshopp, enklare exekvering, färre lås och mycket mindre koordination. Latensen är mestadels databasen som gör jobbet, inte klustret som argumenterar om vem som ska göra det.
När en fråga inte kan routas precist (t.ex. filtrerar på ett icke‑shard‑nyckelfält) kan systemet broadcasta den till många eller alla shards. Varje shard kör frågan lokalt, sedan slår routern (eller en koordinator) ihop resultaten—sorterar, deduplicerar, applicerar limits och kombinerar partiella aggregat.
Denna fan‑out amplifierar tail‑latensen: även om 9 shards svarar snabbt kan en långsam shard hålla hela förfrågan som gisslan. Det multiplicerar också belastningen: en användarförfrågan kan bli N shard‑förfrågningar.
Joins över shards är dyra eftersom data som tidigare möttes “inom” databasen nu måste resa mellan shards (eller till en koordinator). Även enkla aggregationer (COUNT, SUM, GROUP BY) kan kräva en två‑fasplan: beräkna delresultat på varje shard, sedan slå ihop dem.
De flesta system använder lokala index: varje shard indexerar bara sin egen data. De är billiga att underhålla, men hjälper inte routing—så frågor kan fortfarande spridas.
Globala index kan möjliggöra riktad routing på icke‑shard‑nyckelfält, men de ger skriv‑overhead, extra koordination och egna skalnings‑ och konsistensproblem.
Skrivningar är där sharding slutar kännas som “bara skalning” och börjar förändra hur du designar funktioner. En skrivning som berör en shard kan vara snabb och enkel. En skrivning som spänner över shards kan vara långsam, felbenägen och överraskande svår att göra korrekt.
Om varje begäran kan routas till exakt en shard (typiskt via en shard‑nyckel) kan databasen använda sin normala transaktionsmekanik. Du får atomicitet och isolation inom den sharden, och de flesta operationella problem ser ut som bekanta en‑nodsproblem—bara upprepade N gånger.
När du behöver uppdatera data på två shards i en “logisk handling” (t.ex. överföra pengar, flytta en order mellan kunder, uppdatera ett aggregat lagrat någon annanstans) är du i distribuerade transaktioners territorium.
Distribuerade transaktioner är svåra eftersom de kräver koordination mellan maskiner som kan vara långsamma, partitionerade eller startas om när som helst. Två‑fas‑commit‑liknande protokoll lägger till extra rundresor, kan blockera vid timeouts och gör fel tvetydiga: applicerade shard B ändringen innan koordinatorn dog? Om klienten gör om försöket, appliceras skrivningen dubbelt? Om du inte gör om, förlorar du den?
Få vanliga taktiker minskar hur ofta du behöver multi‑shard‑transaktioner:
I sharded system är retries oundvikliga. Gör skrivningar idempotenta genom att använda stabila operations‑ID (t.ex. en idempotensnyckel) och låta databasen lagra ”redan applicerat”‑markörer. Då blir en timeout + retry en no‑op istället för dubbla debiteringar, dubbletter eller inkonsekventa räknare.
Sharding delar din data över maskiner, men tar inte bort behovet av redundans. Replikering är vad som håller en shard tillgänglig när en nod dör—och det är också det som gör "vad är sant just nu?" svårare att svara på.
De flesta system replikerar inom varje shard: en primär (leader) accepterar skrivningar och en eller flera repliker kopierar ändringarna. Om primären fallerar promoverar systemet en replika (failover). Repliker kan också servera läsningar för att minska belastning.
Avvägningen är timing. En read‑replica kan vara några millisekunder—eller sekunder—efter. Denna glipa är normal, men den spelar roll när användare förväntar sig “jag uppdaterade det nyss, jag borde se det”.
I sharded uppsättningar landar du ofta i stark konsistens inom en shard och svagare garantier över shards, särskilt när multi‑shard‑operationer är inblandade.
Med sharding betyder ofta ”single source of truth”: för varje datadel finns en auktoritativ plats att skriva till (vanligtvis shardens leader). Men globalt finns ingen maskin som omedelbart kan bekräfta senaste tillståndet för allt. Du har många lokala sanningar som måste hållas synkade via replikering.
Constraints är knepiga när datan som ska kontrolleras ligger på olika shards:
Dessa val är inte bara implementationstekniska—de definierar vad “korrekt” betyder för din produkt.
Rebalansering är vad som håller en sharded databas användbar när verkligheten förändras. Data växer ojämnt, en tidigare balanserad shard‑nyckel driver mot skevhet, du lägger till noder för kapacitet eller behöver pensionera hårdvara. Något av det kan göra en shard till flaskhals—även om ursprungsdesignen såg perfekt ut.
Till skillnad från en enskild databas bakar sharding in data‑platsen i routinglogiken. När du flyttar data kopierar du inte bara bytes—du ändrar var förfrågningar måste gå. Det betyder att rebalansering handlar lika mycket om metadata och klienter som om lagring.
De flesta team eftersträvar ett online‑arbetsflöde som undviker ett stort "stop the world"‑fönster:
En ändring i shard‑kartan är händelsebrytande om klienter cachar routingbeslut. Bra system behandlar routing‑metadata som konfiguration: versionera den, uppdatera ofta och var tydlig med vad som händer när en klient träffar en flyttad nyckel (redirect, retry eller proxy).
Rebalansering orsakar ofta tillfälliga prestandadippar (extra skrivningar, cache‑churn, bakgrundskopieringslast). Partiella flyttar är vanliga—vissa intervall migrerar före andra—så du behöver tydlig observability och en rollback‑plan (t.ex. vänd kartan tillbaka och töm dual‑writes) innan cutover.
Sharding antar att arbete sprids. Överraskningen är att ett kluster kan se “jämnt” ut på papper (samma antal rader per shard) men bete sig mycket ojämnt i produktion.
En hotspot uppstår när en liten del av nyckelrummet får mest trafik—tänk en känd profils konto, en populär produkt, en tenant som kör ett tungt batchjobb eller en tidsbaserad nyckel där “idag” drar all skrivning. Om dessa nycklar mappar till en shard blir den sharden flaskhalsen även om andra shards är inaktiva.
”Skevhet” är inte en sak:
De matchar inte alltid. En shard med mindre data kan ändå vara het om den äger de mest efterfrågade nycklarna.
Du behöver inte avancerad tracing för att upptäcka skevhet. Börja med per‑shard‑dashboards:
Om en shards latens stiger med dess QPS medan andra är stabila har du sannolikt en hotspot.
Fixar byter ofta enkelhet mot balans:
Sharding lägger inte bara till fler servrar—det lägger till fler sätt för saker att gå fel och fler platser att leta på när det händer. Många incidenter är inte “databasen är nere”, utan “en shard är nere” eller “systemet kan inte komma överens om var datan finns.”
Flera mönster uppträder ofta:
I en en‑nodsdatabas tailar du en logg och kollar ett metriksätt. I ett sharded system behöver du observability som följer en förfrågan över shards.
Använd korrelations‑ID:n i varje förfrågan och propagéra dem från API‑lagret genom routrar till varje shard. Kombinera det med distribuerad tracing så en scatter‑gather‑fråga visar vilken shard som var långsam eller misslyckades. Metrik bör brytas ner per shard (latens, ködjup, felfrekvens), annars döljs en het shard i fleet‑medelvärden.
Sharding‑fel visar sig ofta som korrekthetsbuggar:
”Återställ databasen” blir “återställ många delar i rätt ordning.” Du kan behöva återställa metadata först, sedan varje shard, och verifiera att shard‑gränser och routingregler matchar den återställda tidpunkten. DR‑planer bör innehålla övningar som bevisar att du kan sätta ihop ett konsekvent kluster—inte bara återställa enskilda maskiner.
Sharding behandlas ofta som "skala‑brytaren", men det är också en permanent ökning av systemkomplexitet. Om du kan nå dina prestanda‑ och tillförlitlighetsmål utan att dela data över noder får du vanligtvis en enklare arkitektur, lättare felsökning och färre operations‑edge‑cases.
Innan du bestämmer dig för sharding, testa alternativ som bevarar en logisk databas:
Ett praktiskt sätt att minska risk är att prototypa plumbingen (routinggränser, idempotens, migrations‑workflows och observability) innan du binder din produktionsdatabas till den.
Till exempel kan du med Koder.ai snabbt spinna upp en liten, realistisk tjänst från chatten—ofta ett React‑admin‑UI plus en Go‑backend med PostgreSQL—och experimentera med shard‑nyckel‑medvetna API:er, idempotensnycklar och “cutover”‑beteenden i en säker sandbox. Eftersom Koder.ai stödjer planning mode, snapshots/rollback och export av källkod kan du iterera på sharding‑designbeslut (som routing och metadatastruktur) och sedan föra med dig koden och runbooks in i din huvudstack när du är trygg.
Sharding (horisontell partitionering) delar upp en enda logisk dataset över flera maskiner (”shards”), där varje shard lagrar olika rader.
Replikering, däremot, behåller kopior av samma data på flera noder—främst för tillgänglighet och läs‑skalning.
Vertikal skalning betyder att uppgradera en databasserver (mer CPU/RAM/snabbare diskar). Det är enklare operativt, men du når så småningom hårda gränser (eller mycket hög kostnad).
Sharding skalar ut genom att lägga till fler maskiner, men inför routing, ombalansering och utmaningar för korrekthet över shards.
Team shardar när en nod blir en återkommande flaskhals, till exempel:
Sharding sprider data och trafik så kapacitet ökar genom att lägga till noder.
Ett typiskt sharded system inkluderar:
Prestanda och korrekthet beror på att dessa delar hålls konsekventa.
En shard‑nyckel är fältet/fälten som används för att bestämma var en rad placeras. Den avgör i hög grad om förfrågningar träffar en shard (snabbt) eller många shards (långsamt).
Bra shard‑nycklar har ofta hög kardinalitet, jämn fördelning och matchar dina vanliga åtkomstmönster (t.ex. tenant_id eller user_id).
Vanliga “dåliga” shard‑nycklar inkluderar:
Dessa leder ofta till hotspots eller till att rutinfrågor måste spridas (scatter‑gather).
Tre vanliga strategier är:
Om en förfrågan innehåller shard‑nyckeln (eller något som mappar till den) kan routern skicka den till en shard—det snabba spåret.
Om den inte kan routas precist kan den fanas ut till många/alla shards (scatter‑gather). En långsam shard kan bestämma hela latensen, och varje användarförfrågan blir N shard‑förfrågningar.
Enkel‑shard‑skrivningar använder normal transaktionslogik på den sharden.
Skrivningar över flera shards kräver distribuerad koordination (ofta två‑fas‑commit‑liknande), vilket ökar latens och gör felhantering svårare. Praktiska åtgärder inkluderar:
Innan du shardar, försök alternativ som behåller en logisk databas:
Sharding passar bättre när du överskridit en nods gränser och de viktigaste frågorna kan routas av en shard‑nyckel med minimal tvär‑shard‑trafik.