Definiera omfattning och användarbehov
Innan du börjar designa skärmar eller välja en filparsers, bli specifik kring vem som flyttar data in och ut ur produkten och varför. En dataimport-webbapp byggd för interna operatörer kommer se annorlunda ut än ett självbetjäningsverktyg för Excel som kunderna använder.
Vilka är användarna?
Börja med att lista roller som kommer hantera importer/exporter:
- Admins som konfigurerar kartläggningar, regler och behörigheter
- Operatörer som kör importer regelbundet och hanterar undantag
- Kunder som laddar upp sina egna CSV/Excel-filer och förväntar sig tydlig vägledning
För varje roll, definiera förväntad nivå och tolerans för komplexitet. Kunder behöver vanligen färre valmöjligheter och mycket bättre inprodukt-förklaringar.
Kärnscenarier (och vad “klart” betyder)
Skriv ner dina viktigaste scenarier och prioritera dem. Vanliga är:
- Initial bulk-load vid onboarding (stor volym, stökig data)
- Periodisk synk (veckovis/månadsvis uppdatering där konsistens är viktigt)
- Engångsexport för rapportering, migrering eller backup
Definiera sedan framgångsmått du kan mäta. Exempel: färre misslyckade importer, snabbare tid till lösning för fel, och färre supportärenden om ”min fil går inte att ladda upp”. Dessa hjälper dig prioritera (t.ex. tydligare felrapportering vs. fler filformat).
Var tydlig med vad ni stöder från start:
- Filformat: CSV, Excel (XLSX), JSON
- Max filstorlek och radbegränsningar (och vad som händer vid överskridande)
- Kodningsförväntningar (t.ex. UTF-8) och tidszonsregler för datum
Identifiera även compliance-behov tidigt: om filer innehåller PII, lagringskrav (hur länge ni sparar uppladdningar) och revisionskrav (vem importerade vad, när och vad som ändrades). Dessa val påverkar lagring, loggning och behörigheter i hela systemet.
Välj arkitektur och teknisk stack
Innan du tänker på en avancerad kolumnkartläggnings-UI eller avancerade valideringsregler, välj en arkitektur som teamet kan leverera och drifta tryggt. Importer och exporter är ofta ”tråkig” infrastruktur—här slår itereringstakt och felsökningsbarhet nyhetsspel.
Börja med en stack ni redan kan
Vilken mainstream webstack som helst kan driva en dataimport-webbapp. Välj efter befintliga kunskaper och möjligheten att anställa:
- React + Node (TypeScript) om ni vill ha ett en-språks fullstack och ett starkt ekosystem för bakgrundsjobb.
- Django om ni vill ha ett batteries-included admin, mogen ORM och snabb leverans.
- Rails om ni värderar konventioner, snabb CRUD och väletablerade bakgrundsjobbmönster.
Nyckeln är konsistens: stacken ska göra det enkelt att lägga till nya importtyper, nya datavalideringsregler och nya exportformat utan omskrivningar.
Om ni vill snabba upp scaffolding utan att låsa er i en engångsprototyp kan en vibe-coding-plattform som Koder.ai vara användbar: beskriv importflödet (upload → preview → mapping → validation → background processing → history) i chatten, generera en React-UI med Go + PostgreSQL-backend och iterera snabbt med planning mode och snapshots/rollback.
Lagring: separera “rå fil” från “normaliserade poster”
Använd en relationsdatabas (Postgres/MySQL) för strukturerade poster, upserts och revisionsloggar för dataändringar.
Spara ursprungliga uppladdningar (CSV/Excel) i objektlagring (S3/GCS/Azure Blob). Att behålla råa filer är ovärderligt för support: du kan reproducera parser-problem, köra om jobb och förklara felhanteringsbeslut.
Bestäm hur importer körs
Små filer kan köras synkront (upload → validate → apply) för en snabb UX. För större filer, flytta arbetet till bakgrundsjobb:
- upload → enqueue job → visa progress/history → notifiera vid slutförande
Detta förbereder också för retries och rate-limited writes.
Multitenant vs single-tenant
Om ni bygger SaaS, bestäm tidigt hur ni separerar tenant-data (radnivåscoping, separata scheman eller separata databaser). Detta påverkar ert dataexport-API, behörigheter och prestanda.
Icke-funktionella krav att dokumentera nu
Skriv ner mål för uppetid, max filstorlek, förväntade rader per import, tid-till-slutförande och kostnadsgränser. Dessa siffror styr val av jobbkö, batchstrategi och indexering—långa innan UI blir snyggt.
Bygg intake-flödet för import
Intake-flödet sätter tonen för varje import. Om det känns förutsägbart och förlåtande kommer användare försöka igen när något går fel—och supportärenden minskar.
Ingångspunkter: UI-uppladdning och API
Erbjud en drag-and-drop-zon plus en klassisk filväljare i webb-UI:t. Drag-and-drop är snabbare för power users, medan filväljaren är mer tillgänglig och bekant.
Om era kunder importerar från andra system, lägg till en API-endpoint också. Den kan acceptera multipart uploads (fil + metadata) eller ett pre-signerat URL-flöde för större filer.
Vid uppladdning gör lättviktig parsning för att skapa en “preview” utan att begå data än:
- Upptäck headers och visa ett sample av rader (t.ex. första 20–100)
- Hantera vanliga kodningar (UTF‑8, UTF‑16) och avgränsare (komma, tab, semikolon)
- Normalisera nya rader och trimma uppenbara formateringsproblem
Denna preview driver senare steg som kolumnkartläggning och validering.
Spara originalfilen för replay
Spara alltid originalfilen säkert (objektlagring är typiskt). Håll den oföränderlig så att du kan:
- Köra om importen när valideringsregler ändras
- Undersöka buggar med exakt input
- Erbjuda “ladda ner original” från importhistoriken
Behandla varje uppladdning som en förstaklasspost. Spara metadata som uppladdare, tidsstämpel, källsystem, filnamn och checksum (för att upptäcka dubbletter och säkerställa integritet). Detta blir ovärderligt för audit och felsökning.
Förkontroller innan användaren investerar tid
Kör snabba förkontroller omedelbart och faila tidigt när det behövs:
- Filtyp och storleksgränser
- Grundläggande läsbarhet (kan vi parsa?)
- Obligatoriska kolumner finns (beroende på importtyp)
Om en förkontroll misslyckas, returnera ett tydligt meddelande och visa vad som behöver åtgärdas. Målet är att blockera riktigt dåliga filer snabbt—utan att stoppa giltig men ofullständig data som kan mappas och rengöras senare.
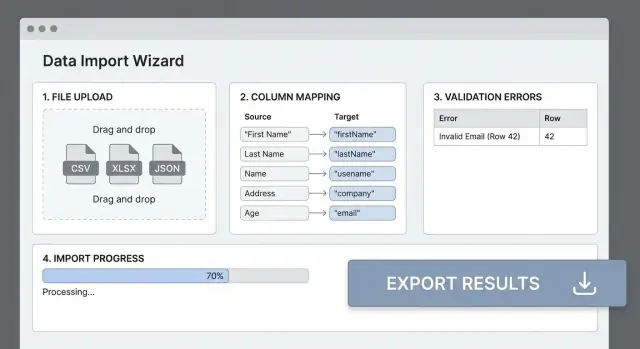
De flesta importfel beror på att filens headers inte matchar appens fält. Ett tydligt kartläggningssteg förvandlar “stökig CSV” till förutsägbar input och sparar användare från trial-and-error.
Ett kartläggnings-UI folk förstår
Visa en enkel tabell: Källkolumn → Målfält. Autodetektera sannolika matchningar (skiftlägesoberoende header-matchning, synonymer som “E-mail” → email), men låt alltid användare åsidosätta.
Inkludera några användbarhetsförbättringar:
- Flagga obligatoriska målfält och visa om de är kartlagda
- Tillåt “Ignorera den här kolumnen” för irrelevant data
- Markera omappade kolumner så användare inte missar något
Sparade mallar (per kund eller dataset)
Om kunder importerar samma format varje vecka, gör det till ett klick. Låt dem spara mallar scopeade till:
- ett kundkonto
- en datasettyp (t.ex. Contacts vs. Invoices)
- valfritt, ett specifikt integrations- eller källsystem
När en ny fil laddas upp, föreslå en mall baserat på kolöverensstämmelse. Stöd även versionering så användare kan uppdatera en mall utan att bryta äldre körningar.
Lägg till lätta transformationer som kan appliceras per mappat fält:
- trimma blanksteg; konvertera tomma strängar till null
- datumparsning (MM/DD/YYYY vs. DD.MM.YYYY) med tidszonsval
- valuta-normalisering (t.ex. “$1,200.00” → 1200.00 + valuta)
- enums (t.ex. “Active”, “enabled”, “1” →
ACTIVE)
- splitta/sammanslå fält (Full Name → First/Last, eller tvärtom)
Håll transformationerna explicita i UI:t (“Applied: Trim → Parse Date”) så resultatet är förklarligt.
Förhandsgranska innan commit
Före full-processning, visa en förhandsgranskning av mappade resultat för (säg) 20 rader. Visa ursprungligt värde, transformerat värde och varningar (som “Kunde inte parsa datum”). Här fångar användare problem tidigt.
Upptäck dubbletter och nyckelfält
Be användaren välja en nyckelfält (email, external_id, SKU) och förklara vad som händer vid dubbletter. Även om ni hanterar upserts senare, sätter detta förväntningar: varna för dubblett-nycklar i filen och föreslå vilken rad som “vinner” (första, sista eller fel).
Designa valideringssystemet
Validering är skillnaden mellan en “filuppladdare” och en importfunktion folk kan lita på. Målet är inte att vara strikt för sakens skull—utan att förhindra att dåliga data sprids samtidigt som användaren får tydlig, åtgärdbar feedback.
Separera validering i lager
Behandla validering som tre olika kontroller, med olika syften:
- Schema-validering (typer & obligatoriska fält): “Är
email en sträng?”, “Är amount ett tal?”, “Finns customer_id?” Detta är snabbt och kan köras direkt efter parsning.
- Affärsregler: “Amount måste vara positivt”, “Status måste vara en av Active/Paused”, “Startdatum får inte ligga i det förflutna.” Dessa speglar produktens logik.
- Korsfält och relationsregler: “Om
country=US krävs state”, “end_date måste vara efter start_date”, “Plan-namnet måste finnas i detta workspace.” Dessa kräver ofta kontext (andra kolumner eller databasuppslag).
Att hålla lagren separata gör systemet lättare att bygga ut och att förklara i UI:t.
Strikt vs förlåtande läge (och varför det spelar roll)
Bestäm tidigt om en import ska:
- Faila hela filen (strikt): bäst för finansiella data, behörigheter eller allt där partiella uppdateringar är riskfyllda.
- Acceptera delvis giltiga rader (förlåtande): bäst för stora listor där användare förväntar sig att bara åtgärda de problematiska raderna.
Ni kan också stödja båda: strikt som default, med en “Allow partial import”-option för admins.
Människovänliga fel (med rad-/kolumnreferenser)
Varje fel ska svara: vad hände, var och hur åtgärdar jag det.\n
Exempel: “Rad 42, kolumn ‘Start Date’: måste vara ett giltigt datum i YYYY-MM-DD-format.”
Differentiera:
- Fel: stoppar processning för den raden (eller hela filen i strikt läge)
- Varningar: tillåts men markeras (t.ex. “Okänt avdelning; lämnas tom”)
Möjliggör “fixa och ladda upp igen”-loopar
Användare åtgärdar sällan allt i en passning. Gör re-uppladdningar smidiga genom att binda valideringsresultat till ett importförsök och tillåta användaren att ladda upp en korrigerad fil. Para detta med nedladdningsbara felrapporter så de kan fixa i bulk.
Ett praktiskt tillvägagångssätt är hybrid:
- Konfigurerbara regler för tenant-specifika krav (t.ex. “Employee ID måste vara unik inom workspace”).
- Koddefinierade regler för kärnproduktinvarianter (t.ex. behörighetsgränser, obligatoriska relationer) för att undvika felkonfiguration.
Detta håller valideringen flexibel utan att göra den till en svårdebbuggad “inställningslabyrint”.
Implementera pålitlig processning och retries
Ställ in roller och åtkomst
Modellera multitenant-behörigheter tidigt och generera de adminytor du behöver.
Importer brukar misslyckas av tråkiga skäl: långsamma databaser, filspikar vid peak, eller en enstaka “dålig” rad som blockerar hela batchen. Pålitlighet handlar mest om att flytta tungt arbete bort från request/response-vägen och göra varje steg säkert att köra igen.
Använd bakgrundsjobb för stora filer
Kör parsning, validering och skrivningar i bakgrundsjobb (köer/worker) så uploads inte stöter på webtimeouts. Det låter dig också skala workers oberoende när kunder börjar importera större kalkylblad.
Ett praktiskt mönster är att dela arbetet i chunkar (t.ex. 1 000 rader per jobb). Ett “parent”-importjobb schemalägger chunk-jobb, aggregerar resultat och uppdaterar progress.
Spåra tydliga tillstånd och övergångar
Modellera importen som en state machine så UI och ops-team alltid vet vad som händer:
- queued → running → completed
- queued/running → failed (med orsak)
- queued/running → canceled (av användare eller system)
Spara tidsstämplar och försökantal per övergång så du kan svara “när startade det?” och “hur många retries?” utan att gräva i loggar.
Progress som användare kan lita på
Visa mätbar progress: rader processade, rader kvar och hittade fel hittills. Om du kan uppskatta genomströmning, lägg till en grov ETA—men föredra “~3 min” framför exakt nedräkning.
Gör processningen idempotent (retry-säker)
Retries ska aldrig skapa dubbletter eller dubbelapplicera uppdateringar. Vanliga tekniker:
- Använd ett
import_id plus row_number (eller row-hash) som stabil idempotensnyckel.
- Upserta med en naturlig nyckel (som
external_id) istället för att alltid göra insert.
- Skriv i transaktioner per chunk så partiella fel inte korruptar tillstånd.
Throttla för att skydda alla
Rate-limita samtidiga importer per workspace och throttla skrivintensiva steg (t.ex. max N rader/sek) för att undvika att överbelasta databasen och försämra upplevelsen för andra användare.
Felrapportering och importhistorik
Om folk inte förstår vad som gick fel kommer de ladda upp samma fil tills det går igenom. Behandla varje import som en förstaklass “körning” med tydlig pappersspårning och åtgärdbara fel.
Skapa en import run-post
Börja med att skapa en import run-entitet i samma stund som en fil skickas in. Denna post bör fånga det väsentliga:
- Vem initierade den (användare + organisation)
- Vad som importerades (källfilens namn, storlek, checksum, entitetstyp)
- När det hände (start/slut-tidsstämplar)
- Hur den tolkades (använd kartläggningskonfiguration, transform-version)
- Utfall (success/failed/partial, rader processade, rader avvisade)
Detta blir din importhistorikskärm: en enkel lista över körningar med status, räkningar och en “view details”-sida.
Spara radnivåfel (inte bara loggar)
Apploggar är bra för ingenjörer, men användare behöver querybara fel. Spara fel som strukturerade poster knutna till import-run, helst på båda nivåerna:
- Radnivå: radnummer, primär identifierare (om upptäckt), snapshot av råa värden
- Fältnivå: kolumnnamn, felkod (t.ex. REQUIRED, INVALID_DATE), människomeddelande, svårighetsgrad
Med denna struktur kan du erbjuda snabba filter och aggregerade insikter som “Top 3 feltyper denna vecka”.
Gör fel usable: UI + nedladdningsbar rapport
På run-detaljsidan, erbjud filter efter typ, kolumn och svårighetsgrad, plus en sökruta (t.ex. “email”). Sedan erbjud en nedladdningsbar CSV-felrapport som inkluderar originalraden plus extra kolumner som error_columns och error_message, med tydlig vägledning som “Åtgärda datumformat till YYYY-MM-DD.”
Lägg till ett dry run-läge
Ett “dry run” validerar allt med samma mapping och regler, men skriver inte data. Det är idealiskt för första imports och låter användare iterera säkert innan de committar ändringar.
Datamodell, upserts och auditabilitet
Planera innan du kodar
Kartlägg tillstånd, jobb och kantfall först, låt sedan Koder.ai generera koden.
Importer känns “klara” när rader landar i databasen—men långsiktig kostnad uppstår ofta i stökiga uppdateringar, dubbletter och oklar ändringshistorik. Detta handlar om att designa datamodellen så importer blir förutsägbara, reversibla och förklarliga.
Bestäm: skapa, uppdatera eller båda
Börja med att definiera hur en importerad rad mappar till din domänmodell. För varje entitet, bestäm om importen kan:
- Enbart skapa nya poster
- Enbart uppdatera befintliga poster
- Göra båda (vanligt i SaaS)
Detta val ska vara tydligt i importkonfigurationen och sparas med importjobbet så beteendet är reproducerbart.
Välj upsert-nycklar och hantering av kollideringar
Om ni stödjer “create or update” behöver ni stabila upsert-nycklar—fält som identifierar samma post varje gång. Vanliga val:
external_id (bäst när det kommer från ett annat system)- Email (fungerar för användare/kontakter, men kan ändras)
- Kompositnycklar (t.ex.
account_id + sku)
Definiera kollisionsregler: vad händer om två rader delar samma nyckel, eller om en nyckel matchar flera poster? Bra default är “fail the row med ett tydligt fel” eller “sista raden vinner”, men välj med omsorg.
Transaktioner utan att låsa världen
Använd transaktioner där de skyddar konsistens (t.ex. skapa parent + dess barn). Undvik en jättetransaktion för en fil med 200k rader; det kan låsa tabeller och göra retries smärtsamma. Föredra chunkade skrivningar (t.ex. 500–2 000 rader per batch) med idempotenta upserts.
Skydda referentiell integritet
Importer bör respektera relationer: om en rad refererar till en parent (som Company), kräva att den finns eller skapa den i ett kontrollerat steg. Att faila tidigt med “saknad parent”-fel förhindrar halvkopplad data.
Audita allt importer ändrar
Lägg till revisionsloggar för importdrivna ändringar: vem startade importen, när, källfil och en per-post-sammanfattning av vad som ändrades (gammalt vs nytt). Detta förenklar support, bygger förtroende och gör rollback enklare.
Bygg exporter som skalar
Exporter verkar enkla tills kunder försöker ladda ner “allt” precis innan en deadline. Ett skalbart exportsystem ska hantera stora dataset utan att sakta ner appen eller producera inkonsekventa filer.
Erbjud rätt exporttyper
Börja med tre alternativ:
- Full export: allt användaren kan komma åt.
- Filtrerad export: respekterar samma filter/sök som i UI (status, datumintervall, ägare osv.).
- Inkrementell export: “ändringar sedan X” för sync-jobb och rapporteringspipelines.
Inkrementella exporter är särskilt användbara för integrationer och minskar belastningen jämfört med upprepade fulla dumps.
- CSV är standard för kalkylblad och bulk-analys.
- JSON är bäst för ett data export API och automation.
- Excel endast när det behövs (flera blad, rik formatering eller icke-tekniska arbetsflöden).
Oavsett val, behåll konsistenta headers och stabil kolumnordning så downstream-processer inte går sönder.
Streama och paginera för att undvika minnesspikar
Stora exporter bör inte ladda alla rader i minnet. Använd pagination/streaming för att skriva rader medan du hämtar dem. Detta förhindrar timeouts och håller webappen responsiv.
Generera stora exporter asynkront
För stora dataset, generera exporter i ett bakgrundsjobb och notifiera användaren när de är klara. Ett vanligt mönster är:
- Användaren begär export.
- Appen köar ett jobb.
- Jobbet skriver filen till objektlagring.
- UI visar en nedladdningslänk och behåller den i exporthistoriken.
Detta passar väl med era bakgrundsjobb för importer och samma “run history + nedladdningsbart artefakt”-mönster som ni använder för felrapporter.
Exporterna granskas ofta. Inkludera alltid:
- En tydlig tidszonpolicy (t.ex. spara i UTC, exportera i användarens tidszon).
- Konsekvent datumformat (ISO-8601 för JSON; explicita format för CSV/Excel).
- En “genererad vid”-tidsstämpel och, för inkrementella exporter, cutoff-tiden som användes.
Dessa detaljer minskar förvirring och stödjer tillförlitlig avstämning.
Säkerhet, behörigheter och datasekretess
Importer och exporter är kraftfulla eftersom de kan flytta mycket data snabbt. Det gör dem också vanliga källor till säkerhetsbuggar: en för vid roll, en läckt fil-URL eller en loggrad som av misstag innehåller personuppgifter.
Autentisering: välj vad som matchar hur folk använder produkten
Börja med samma autentisering ni använder i resten av appen—skapa inte en “specialväg” bara för importer.
Om era användare arbetar i en browser passar sessionsbaserad auth (plus valfritt SSO/SAML). Om importer/exporter är automatiserade (nattjobb, integrationspartners) överväg API-nycklar eller OAuth-tokens med tydlig scope och rotation.
Ett praktiskt regel: import-UI och import-API ska båda upprätthålla samma behörigheter, även om de används av olika målgrupper.
Rollbaserad åtkomst: definiera vem som kan göra vad
Behandla import/export-funktioner som explicita privilegier. Vanliga roller:
- Can import (ladda upp filer, köra importer)
- Can export (generera och ladda ner exporter)
- Can view history (se importkörningar, fel, räkningar)
- Can download files (originaluppladdningar, felrapporter)
Gör “ladda ner filer” till en separat behörighet. Många känsliga läckor sker när någon kan se en importkörning och systemet felaktigt antar att de också kan ladda ner originalfilen.
Tänk också på radnivå- eller tenant-gränser: en användare bör bara importera/exportera data för det konto eller workspace de tillhör.
Skydda känslig data end-to-end
För sparade filer (uppladdningar, genererade fel-CSVs, exportarkiv), använd privat objektlagring och kortlivade nedladdningslänkar. Kryptera i vila när det krävs av compliance, och var konsekvent: originaluppladdning, processad staging-fil och alla genererade rapporter bör följa samma regler.
Var försiktig med loggar. Redigera känsliga fält (emails, telefonnummer, ID:n, adresser) och logga aldrig råa rader som standard. När debugging krävs, lås upp “verbose row logging” bakom admin-inställningar och se till att det förfaller.
Validera och skanna uppladdningar innan processning
Behandla varje uppladdning som otillförlitlig input:\n
- Tvinga filtypkontroller (lita inte enbart på filnamnet)\n- Sätt storleksgränser för att förhindra DoS och oavsiktliga stora uploads\n- Överväg malware-scanning om er riskprofil eller bransch kräver det
Validera även struktur tidigt: avvisa uppenbart malformed-filer innan de når bakgrundsjobb och ge användaren ett tydligt felmeddelande.
Audits för säkerhetsrelevanta händelser
Logga händelser du vill ha vid en utredning: vem laddade upp en fil, vem startade en import, vem laddade ner en export, ändringar av behörigheter och misslyckade åtkomstförsök.
Auditposter bör inkludera aktör, tidsstämpel, workspace/tenant och objektet (import run ID, export ID), utan att spara känsliga raddata. Detta kompletterar importhistorik-UI:t och hjälper dig svara “vem ändrade vad och när?” snabbt.
Testning, övervakning och driftbarhet
Behåll ägandeskap över källan
När du är redo, exportera källkoden och fortsätt i din vanliga workflow.
Om importer och exporter berör kunddata kommer du förr eller senare få edge-cases: konstiga kodningar, sammanslagna celler, halvfyllda rader, dubbletter och “det fungerade igår”-mysterier. Driftbarhet är vad som förhindrar att dessa blir supportkatastrofer.
Tester som speglar verkliga filer
Börja med fokuserade tester kring de mest felbenägna delarna: parsning, kartläggning och validering.
- Parsningstester: Använd ett litet set representativa CSV/XLSX-fixtures (olika avgränsare, datumformat, tomma kolumner, stora tal, UTF‑8 vs Windows-1252). Assert radantal och att nyckelfält parsas konsekvent.
- Kartläggning + transformationstester: Givet en uppsättning inputkolumner, verifiera att appen mappar till rätt interna fält och applicerar transformationer (trim, case-normalisering, valuta-/procentkonvertering).
- Valideringsregeltester: För varje regel (required, unique, range, foreign-key existence), inkludera “bra” och “dåliga” rader och assert exakta felkoder/meddelanden.
Lägg sedan till minst ett end-to-end-test för hela flödet: upload → background processing → rapportgenerering. Dessa fångar kontraktsmismatch mellan UI, API och workers.
Övervakning som svarar på “vad gick sönder?”
Spåra signaler som reflekterar användarpåverkan:\n
- Job failures (antal och rate)\n- Processing time (p50/p95)\n- Valideringsfel-rate (plötsliga spikar kan betyda template-ändring)\n- Kö-depth och worker-throughput
Koppla alerts till symptom (ökade failures, växande ködjup) snarare än varje undantag.
Adminverktyg och användarhjälp
Ge interna team en liten adminyta för att köra om jobb, avbryta fastnade importer och inspektera fel (inputfilens metadata, använd mapping, felöversikt och länk till logs/traces).
För användare, minska förekommande fel med inline-tips, nedladdningsbara mallar och tydliga nästa steg i felsidor. Ha en central hjälpsida och länka till den från import-UI:t (t.ex. /docs).
Deployment, rollout och framtida förbättringar
Att leverera ett import/export-system är inte bara “pusha till produktion”. Behandla det som en produktfunktion med säkra defaults, tydliga återställningsvägar och utrymme att utveckla.
Miljöer: dev, staging, prod
Sätt upp separata dev/staging/prod-miljöer med isolerade databaser och separata objektlagringsbuckets (eller prefixes) för uppladdade filer och genererade exporter. Använd olika krypteringsnycklar och credentials per miljö, och se till att bakgrundsjobbar pekar på rätt köer.
Staging bör spegla produktion: samma jobbkönkurrent, timeouts och filstorleksgränser. Där validerar ni prestanda och behörigheter utan att riskera riktig kunddata.
Migrationer och versionerade mallar
Importer lever ofta ”för alltid” eftersom kunder sparar gamla kalkylblad. Använd databas-migrationer som vanligt, men versionera även importmallar (och mapping-presets) så ett schemabyte inte bryter förra kvartalets CSV.
Ett praktiskt tillvägagångssätt är att spara template_version med varje import run och behålla kompatibilitetskods för äldre versioner tills ni kan avveckla dem.
Rollout-strategi med feature flags
Använd feature flags för att rulla ut förändringar säkert:\n
- Nya valideringsregler (varna först, sen error)\n- Nya exportformat (t.ex. lägga till JSON bredvid CSV)\n- Nya kartläggningsalternativ (t.ex. dela “Full name”)
Flags låter er testa med interna användare eller en liten kundgrupp innan ni aktiverar bredare.
Supportflöden och diagnos
Dokumentera hur support ska undersöka fel med hjälp av importhistorik, job IDs och loggar. En enkel checklista hjälper: bekräfta template-version, granska första felande rad, kontrollera storage-access, och inspektera worker-logs. Länka detta i ert interna runbook och, där lämpligt, i admin-UI:t (t.ex. /admin/imports).
Nästa steg: integrationer
När kärnflödet är stabilt, bygg ut bortom uploads:\n
- API-baserade importer för automatiserade pipelines\n- Webhooks för “import finished” eller “export ready”-händelser\n- Connectors för vanliga verktyg (Google Sheets, S3, Snowflake)
Dessa reducerar manuellt arbete och gör er dataimport-webbapp kännas som en naturlig del i kundernas befintliga processer.
Om ni bygger detta som en produktfunktion och vill korta ner tiden till en första användbar version, överväg att använda Koder.ai för att prototypa importwizards, jobstatus-sidor och run-history end-to-end, och sedan exportera källkoden för vidare utveckling i ett konventionellt engineering-workflow. Denna strategi är särskilt praktisk när målet är pålitlighet och snabb iteration (inte pixelperfekt UI dag ett).