12 okt. 2025·6 min
Hur fullstack-ramverk suddar ut frontend- och backendrollerna
Fullstack-ramverk blandar UI, data och serverlogik på samma ställe. Lär dig vad som förändras, varför det hjälper och vad teamen måste hålla utkik efter.
Vad “frontend” och “backend” brukade betyda
Före fullstack-ramverken fanns en ganska tydlig linje mellan “frontend” och “backend”: webbläsaren på ena sidan och servern på andra. Den separationen formade teamroller, repo-gränser och hur man talade om “appen”.
Frontend (traditionellt)
Frontend var delen som kördes i användarens webbläsare. Fokus låg på vad användaren ser och interagerar med: layout, styling, klientbeteende och att anropa API:er.
I praktiken innebar frontendarbete ofta HTML/CSS/JavaScript plus ett UI-ramverk, som sedan skickade förfrågningar till ett backend-API för att läsa och skriva data.
Backend (traditionellt)
Backenden levde på servrar och fokuserade på data och regler: databasfrågor, affärslogik, autentisering, auktorisation och integrationer (betalningar, e-post, CRM). Den exponerade endpoints—ofta REST eller GraphQL—that frontend konsumerade.
En användbar mental modell var: frontenden frågar; backenden beslutar.
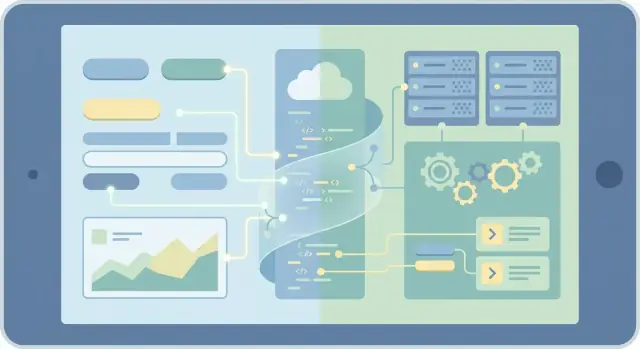
Så vad är ett “fullstack-ramverk”?
Ett fullstack-ramverk är ett webb-ramverk som medvetet spänner över båda sidorna inom ett och samma projekt. Det kan rendera sidor, definiera routes, hämta data och köra serverkod—samtidigt som det producerar ett UI för webbläsaren.
Vanliga exempel är Next.js, Remix, Nuxt och SvelteKit. Poängen är inte att de alltid är “bättre”, utan att de gör det vanligt att UI-kod och serverkod ligger närmare varandra.
Vad den här artikeln är (och inte är)
Det här är inte ett påstående om att “du inte längre behöver en backend”. Databaser, bakgrundsjobb och integrationer finns fortfarande. Skiftet handlar om delat ansvar: frontendutvecklare rör sig mer i serverfrågor, och backendutvecklare rör sig mer i rendering och användarupplevelse—eftersom ramverket uppmuntrar samarbete över gränsen.
Varför fullstack-ramverk dök upp
Fullstack-ramverk dök inte upp för att team glömde hur man bygger separata frontends och backends. De uppstod eftersom koordinationskostnaden för att hålla dem åtskilda i många produkter blev mer märkbart än fördelarna.
Krafter som trycker koden närmare varandra
Moderna team optimerar för snabbare leverans och smidigare iteration. När UI, datahämtning och “limkod” ligger i olika repo och arbetsflöden blir varje feature ett stafettlopp: definiera ett API, implementera det, dokumentera det, koppla ihop det, fixa missmatchande antaganden, och upprepa.
Fullstack-ramverk minskar dessa överlämningar genom att låta en ändring spänna över sida, data och serverlogik i en enda pull request.
Utvecklarupplevelse (DX) spelar också roll. Om ett ramverk ger routing, dataladdning, caching-primitiver och deploy-standarder tillsammans, lägger du mindre tid på att sätta ihop bibliotek och mer tid på att bygga.
Varför webbläsare och servrar nu delar mer verktyg
JavaScript och TypeScript blev det gemensamma språket för klient och server, och bundlers gjorde det praktiskt att paketera kod för båda miljöerna. När din server pålitligt kan köra JS/TS blir det enklare att återanvända validering, formatering och typer över gränsen.
“Isomorf” kod är inte alltid målet—men delade verktyg minskar friktionen för att kolokalisera bekymmer.
Från “sidor + API:er” till end-to-end-funktioner
Istället för att tänka i två leverabler (en sida och ett API) uppmuntrar fullstack-ramverk att leverera en enda funktion: route, UI, server-side dataåtkomst och mutationer tillsammans.
Det stämmer bättre överens med hur produktarbete ofta avgränsas: “Bygg checkout” istället för “Bygg checkout-UI” och “Bygg checkout-endpoints”.
Tradeoffen
Denna enkelhet är en stor fördel för små team: färre tjänster, färre kontrakt, färre rörliga delar.
I större skala kan samma närhet öka koppling, sudda ut ägandeskap och skapa prestanda- eller säkerhetsfällor—så bekvämligheten behöver styrs när kodbasen växer.
Renderingslägen drar in backend-tänk i UI-lagret
Fullstack-ramverk gör “rendering” till ett produktbeslut som också påverkar servrar, databaser och kostnad. När du väljer ett renderingsläge bestämmer du inte bara hur snabbt en sida känns—du väljer var arbetet sker och hur ofta.
SSR, SSG och hybrid—på enkelt språk
Server-Side Rendering (SSR) betyder att servern bygger HTML för varje förfrågan. Du får färskt innehåll, men servern gör mer arbete varje gång någon besöker.
Static Site Generation (SSG) betyder att HTML byggs i förväg (vid byggtid). Sidor är mycket billiga att servera, men uppdateringar kräver ombyggnad eller revalidering.
Hybrid rendering blandar tillvägagångssätt: vissa sidor är statiska, andra server-renderade, och vissa uppdateras delvis (t.ex. regenerering var N:e minut).
Renderingsval förändrar både UI och serverarbete
Med SSR kan en “frontend”-ändring som att lägga till ett personligt widget bli backend-frågor: sessionuppslag, databasläsningar och långsammare responstider under belastning.
Med SSG kan en “backend”-ändring som uppdaterad prissättning kräva planering för byggfrekvens eller inkrementell regenerering.
Ramverkskonventioner döljer mycket komplexitet: du vänder en konfigurationsflagg, exporterar en funktion eller placerar en fil i en särskild mapp—och plötsligt har du definierat cache-beteende, serverexekvering och vad som körs vid byggtid kontra requesttid.
Caching är en del av renderingen, inte bara ops
Caching är inte längre bara en CDN-inställning. Rendering inkluderar ofta:
- Per-route cache-regler (cacha för alltid, cacha i 60 sekunder eller aldrig)
- Data-nivå caching (cacha ett databasfrågeresultat)
- Revalidering (servera cachad HTML tills den uppdateras)
Det är därför renderingslägen drar backend-tänk in i UI-lagret: utvecklare bestämmer färskhet, prestanda och kostnad samtidigt som de designar sidan.
Routes som hanterar både sidor och API:er
Fullstack-ramverk behandlar allt oftare “en route” som mer än en URL som renderar en sida. En enda route kan också innehålla serverkod som laddar data, hanterar formulärinlämningar och returnerar API-svar.
I praktiken betyder det att du får en slags backend inne i frontend-repot—utan att skapa en separat tjänst.
Loaders, actions och API-rutter: en mental modell
Beroende på ramverk ser du termer som loaders (hämta data för sidan), actions (hantera mutationer som formulärpost) eller explicita API-rutter (endpoints som returnerar JSON).
Även om de känns “frontend” eftersom de ligger intill UI-filer gör de klassiskt backend-arbete: läsa requestparametrar, anropa databaser/tjänster och forma ett svar.
Denna route-baserade kolokalisering känns naturlig eftersom koden du behöver för att förstå en skärm ligger nära: sidkomponenten, dess databehov och dess skrivoperationer sitter ofta i samma mapp. Istället för att leta i ett separat API-projekt följer du route:en.
Request-hantering blir UI-nära
När routes äger både rendering och serverbeteende blir backendfrågor en del av UI-arbetsflödet:
- Validering sker nära formuläret eller komponenten som samlar input.
- Fel kan returneras i en form som UI direkt kan visa (fältfel, banners, omdirigeringar).
- Auktorisationskontroller lever ofta i samma route-modul som bestämmer vad som ska renderas.
Denna täta loop kan minska duplication, men den ökar också risken: “lätt att koppla ihop” kan bli “lätt att samla logik på fel ställe.”
Dölj inte affärslogik i route-handlers
Route-handlare är ett utmärkt ställe för orkestrering—parsa input, anropa en domänfunktion och översätta resultat till HTTP-svar. De är ett dåligt ställe att låta komplex affärslogik växa.
Om för mycket logik samlas i loaders/actions/API-rutter blir den svårare att testa, återanvända och dela över routes.
En praktisk gräns: håll routes tunna och flytta kärnregler till separata moduler (t.ex. ett domän- eller servicelag) som routes anropar.
Datahämtning flyttar intill komponenter
Fullstack-ramverk uppmuntrar ofta att kolokalisera datahämtning med det UI som använder den. Istället för att definiera queries i ett separat lager och skicka props genom flera filer kan en sida eller komponent hämta exakt vad den behöver precis där den renderas.
För team betyder det ofta färre kontextbyten: du läser UI:t, ser queryn och förstår datans form—utan att hoppa mellan mappar.
Server-endast åtkomst vs klient-säker data
När hämtning sitter intill komponenter blir den avgörande frågan: var körs den här koden? Många ramverk låter en komponent köra på servern som standard (eller välja server-exekvering), vilket är idealiskt för direkt databas- eller intern tjänsteåtkomst.
Klientside-komponenter får däremot bara röra klient-säker data. Allt som hämtas i webbläsaren kan inspekteras i DevTools, avlyssnas på nätverket eller cachas av tredjepartsverktyg.
Ett praktiskt tillvägagångssätt är att betrakta serverkod som “betrodd” och klientkod som “publik”. Om klienten behöver data, exponera den medvetet via en serverfunktion, API-route eller ramverkets loader.
Serialisering, integritet och oavsiktliga läckor
Data som går från server till webbläsare måste serialiseras (vanligtvis JSON). Denna gräns är där känsliga fält kan glida ut av misstag—tänk passwordHash, interna anteckningar, prissättningsregler eller PII.
Guardrails som hjälper:
- Returnera view models (endast de fält UI behöver), inte råa databasposter.
- Default till “deny” för känsliga egenskaper; lägg till fält med avsikt.
- Var försiktig med nästlade objekt; en enda
user-inkludering kan bära dolda attribut.
Snabbchecklista: server vs webbläsare
- Server: databasfrågor, interna tjänsteanrop, hemligheter, adminlogik, permission-kontroller.
- Webbläsare: rendering, användarinteraktioner, optimistisk UI, klientendast tillstånd, anropa publika endpoints.
När datahämtning flyttar intill komponenter spelar tydlighet om den gränsen lika stor roll som bekvämligheten.
Delade typer och scheman minskar kontraktsgapet
Lägg till en mobilklient
Utöka din webbapp till en Flutter-mobilapp från samma produktidé.
En anledning till att fullstack-ramverk känns “blandade” är att gränsen mellan UI och API kan bli ett delat uppsättning typer.
Delade typer är typdefinitioner (ofta TypeScript-gränssnitt eller härledda typer) som både frontend och backend importerar, så båda sidor är överens om hur en User, Order eller CheckoutRequest ser ut.
Varför TypeScript gör delade typer attraktiva
TypeScript förvandlar “API-kontraktet” från en PDF eller wiki till något din editor kan upprätthålla. Om backend ändrar ett fältnamn eller gör en property valfri kan frontenden misslyckas tidigt i byggsteget istället för att krascha i runtime.
Detta är särskilt attraktivt i monorepos, där det är enkelt att publicera ett litet @shared/types-paket (eller bara importera en mapp) och hålla allt synkat.
Scheman och DTOs minskar UI/API-missmatch
Typer ensamma kan driva ifrån verkligheten om de skrivs för hand. Där hjälper scheman och DTOs (Data Transfer Objects):
- Ett schema (t.ex. ett valideringsschema) kan definiera sanningskällan för vad API:t accepterar och returnerar.
- DTOs gör det tydligt att API-formen inte är samma som din databasmodell eller ORM-entitet.
Med schema-first eller schema-inferred tillvägagångssätt kan du validera input på servern och återanvända samma definitioner för att typa klientanrop—vilket minskar “det funkade på min maskin”-missmatch.
Den dolda risken: hård koppling
Att dela modeller överallt kan också limma ihop lager. När UI-komponenter beror direkt på domänobjekt (eller, ännu värre, databasformade typer) blir backend-refaktorer frontend-refaktorer och små ändringar sprider sig över appen.
Hålla gränser klara
En praktisk medelväg är:
- Kontrakt: definiera stabila request/response-typer per route (DTOs), inte “globala” modeller.
- Adapters: mappa domän-entiteter till DTOs i kanten (API-route eller server action).
- Stabila gränssnitt: versionera eller deprecated kontrakt med eftertanke, även i ett enda repo.
På så sätt får du farten av delade typer utan att varje intern ändring blir ett tvär-teams-koordinationsärende.
Server Actions får backend-anrop att kännas som funktionsanrop
Server Actions (namnen varierar mellan ramverk) låter dig anropa serverkod från en UI-händelse som om du kallade en lokal funktion. Ett formulärinlämning eller knappklick kan anropa createOrder() direkt, och ramverket sköter serialisering av input, skickar förfrågan, kör koden på servern och returnerar resultatet.
Ergonomi vs REST/GraphQL
Med REST eller GraphQL tänker du ofta i endpoints och payloads: definiera en route, forma en förfrågan, hantera statuskoder och parsa ett svar.
Server Actions flyttar den mentala modellen mot “anropa en funktion med argument”.
Ingen av metoderna är i sig bättre. REST/GraphQL kan vara tydligare när du vill ha explicita, stabila gränser för flera klienter. Server Actions känns smidigare när den primära konsumenten är samma app som renderar UI:t, eftersom anropsstället kan ligga precis intill komponenten som triggar det.
Validering och auktorisation är fortfarande obligatoriskt
Känslan av ett “lokalt funktionsanrop” kan vara vilseledande: Server Actions är fortfarande server-entrépunkter.
Du måste validera input (typer, intervall, obligatoriska fält) och verkställa auktorisation (vem får göra vad) inne i actionen själv, inte bara i UI:t. Behandla varje action som om det vore ett publikt API-handler.
Nätverket finns fortfarande
Även om anropet ser ut som await createOrder(data) så korsar det fortfarande nätverket. Det innebär latens, intermittenta fel och retry-behov.
Du behöver fortfarande laddningsstater, felhantering, idempotens för säkra omformuleringar och noggrann hantering av partiella fel—bara med ett mer bekvämt sätt att koppla ihop delarna.
Autentisering och auktorisation blir “fullstack” som standard
Fullstack-ramverk tenderar att sprida “auth-arbetet” över hela appen, eftersom förfrågningar, rendering och dataåtkomst ofta händer i samma projekt—och ibland i samma fil.
Istället för en ren överlämning till ett separat backend-team blir autentisering och auktorisation delade frågor som berör middleware, routes och UI-kod.
En inloggning, många kontroller
Ett typiskt flöde spänner flera lager:
- Middleware / edge-logik kontrollerar om en request har en giltig cookie eller token innan vissa vägar tillåts.
- Route-handlers (sidor och API:er) laddar aktuell användare, förnyar sessioner eller avvisar icke-autentiserade förfrågningar.
- UI-skydd döljer eller inaktiverar knappar, omdirigerar användare från skyddade sidor och visar “logga in”-uppmaningar.
Dessa lager kompletterar varandra. UI-skydd förbättrar användarupplevelsen, men de är inte säkerhet.
Cookies, sessioner och tokens (på hög nivå)
De flesta appar väljer en av dessa strategier:
- Cookie-baserade sessioner: webbläsaren skickar automatiskt en sessionscookie; servern slår upp den och avgör vem du är.
- Signerade cookies / JWTs: cookien eller headern innehåller en signerad token; servern verifierar den och extraherar identitet/roller.
- Hybridupplägg: kortlivade tokens som förnyas via en säker cookie.
Fullstack-ramverk gör det enkelt att läsa cookies under server-rendering och att fästa identitet till server-side datahämtning—bra för bekvämlighet, men det innebär också att misstag kan ske på fler platser.
Auktorisation hör hemma nära dataåtkomst
Auktorisation (vad du får göra) bör verkställas där data läses eller muteras: i server actions, API-handlers eller databasåtkomstfunktioner.
Om du bara verkställer den i UI:t kan en användare kringgå gränssnittet och anropa endpoints direkt.
Vanliga fallgropar att undvika
- Exponera “admin”-routes eller actions utan server-sidiga permission-kontroller.
- Lita på klient-input (t.ex.
role:"admin"elleruserId` i request-body). - Förlita dig på dolda UI-element istället för att verkställa regler i data-lagret.
- Glöm inte att server-renderade sidor också behöver auktorisationskontroller, inte bara API-rutter.
Deploy-modeller förändrar vad “backend” betyder
Förvandla en idé till en kodbas
Starta från en enkel chattprompt och låt Koder.ai generera en fungerande fullstack-appskelett.
Fullstack-ramverk ändrar inte bara hur du skriver kod—de ändrar var din “backend” faktiskt körs.
Mycket förvirring om roller kommer från distribution: samma app kan bete sig som en traditionell server en dag och som en uppsättning små funktioner nästa.
Edge, serverless och långkörande servrar (enkelt)
En långkörande server är den klassiska modellen: du kör en process som alltid är igång, håller minne och servar förfrågningar kontinuerligt.
Serverless kör din kod som on-demand-funktioner. De startar när en förfrågan kommer och kan stänga ner när de är inaktiva.
Edge pushar kod närmare användarna (ofta i många regioner). Det är bra för låg latens, men runtime kan vara mer begränsad än en full server.
Vad ditt ramverksval ändrar: cold starts, streaming, caching
Med serverless och edge spelar cold starts roll: den första förfrågan efter inaktivitet kan vara långsammare medan funktionen startar upp. Ramverksfunktioner som server-side rendering, middleware och tunga beroenden kan öka den uppstartskostnaden.
Å andra sidan stödjer många ramverk streaming—att skicka delar av en sida när de blir klara—så användare ser något snabbt även om data fortfarande laddas.
Caching blir också ett delat ansvar. Sida-nivå caching, fetch-caching och CDN-caching kan alla interagera. Ett “frontend”-beslut som “rendera detta på servern” kan plötsligt påverka backend-liknande frågor: cache-invalidering, föråldrade data och regional konsistens.
Gemensamma bekymmer: hemligheter och observability
Miljövariabler och hemligheter (API-nycklar, databas-URL:er) är inte längre bara “backend”. Du behöver tydliga regler för vad som är säkert för webbläsaren kontra server-only, plus ett konsekvent sätt att hantera hemligheter över miljöer.
Observability måste omfatta båda lagren: centraliserade loggar, distribuerade spår och enhetlig felrapportering så att en långsam sidrendering kan kopplas till ett misslyckat API-anrop—även om de körs på olika platser.
Teamstruktur och ägarskap när gränser suddas ut
Fullstack-ramverk ändrar inte bara kodstruktur—de ändrar vem som “äger” vad.
När UI-komponenter kan köras på servern, definiera routes och anropa databaser (direkt eller indirekt) kan den gamla överlämningsmodellen mellan frontend- och backendteam bli rörig.
Feature-team vs separata frontend/backend-team
Många organisationer går mot feature-team: ett team äger en användar-facing del (t.ex. “Checkout” eller “Onboarding”) end-to-end. Detta passar ramverk där en route kan inkludera sidan, serveractionen och dataåtkomsten på samma plats.
Separata frontend/backend-team kan fortfarande fungera, men ni behöver tydligare gränssnitt och granskningsrutiner—annars samlas backendlogik tyst i UI-nära kod utan ordinarie granskning.
BFF-mönstret, uppmuntrat av moderna ramverk
En vanlig mellanväg är BFF (Backend for Frontend): webbappen inkluderar ett tunt backend-lager skräddarsytt för sitt UI (ofta i samma repo).
Fullstack-ramverk puttar dig ofta dit genom att göra det enkelt att lägga till API-rutter, serveractions och auth-kontroller intill sidorna som använder dem. Det är kraftfullt—behandla det som en riktig backend.
Arbetsöverenskommelser som förhindrar förvirring
- CODEOWNERS och review-regler för server-only-mappar, auth-logik och dataåtkomst.
- API- och schema-granskning (även om “det bara är en server action”): validera input, definiera felformat och tänk på versionering.
- Säkerhetskontroller: threat modeling för nya routes, hantering av hemligheter, auktorisationstester och logg-/monitoreringskrav.
Dokumentera “vad lever var”
Skapa ett kort repo-dokument (t.ex. /docs/architecture/boundaries) som anger vad som hör hemma i komponenter vs route-handlers vs delade bibliotek, med några exempel.
Målet är konsekvens: alla ska veta var man placerar kod—och var man inte gör det.
Fördelar och risker att hålla utkik efter
Klargör gränser med Planning Mode
Kartlägg UI, routes, tjänster och dataåtkomst innan du genererar eller ändrar kod.
Fullstack-ramverk kan kännas som en superkraft: du bygger UI, dataåtkomst och serverbeteende i ett sammanhängande arbetsflöde. Det kan vara en verklig fördel—men det förändrar också var komplexiteten bor.
Fördelar du snabbt märker
Den största vinsten är hastighet. När sidor, API-rutter och datahämtningmönster lever tillsammans, levererar team ofta funktioner snabbare eftersom det är mindre koordinationsarbete och färre överlämningar.
Du ser också färre integrationsbuggar. Delade verktyg (linting, formattering, typkontroll, testrunners) och delade typer minskar mismatch mellan vad frontenden förväntar sig och vad backenden returnerar.
Med en monorepo-lik setup blir refaktorer ofta säkrare eftersom ändringar sprider sig genom stacken i en pull request.
Kostnader som visar sig senare
Bekvämlighet kan dölja komplexitet. En komponent kan renderas på servern, rehydreras på klienten och sedan trigga servermutationer—felsökning kan kräva spårning över flera körmiljöer, caches och nätverksgränser.
Det finns också en kopplingsrisk: djup adoption av ett ramverks konventioner (routing, serveractions, datacache) kan göra verktygsbyte dyrt. Även om du inte planerar migrering kan ramverksuppgraderingar bli höginsats.
Prestandarisker att hantera
Blandade stackar kan uppmuntra överhämtning ("hämta bara allt i serverkomponenten") eller skapa kaskadförfrågningar när data-dependenser upptäcks sekventiellt.
Tungt serverarbete i request-tid-rendering kan öka latenstid och infrastrukturkostnad—särskilt vid trafiktoppar.
Säkerhet och compliance-implikationer
När UI-kod kan exekvera på servern kan åtkomst till hemligheter, databaser och interna API:er ligga närmare presentationslagret. Det är inte nödvändigtvis dåligt, men det kräver ofta djupare säkerhetsgranskningar.
Permission-kontroller, audit-logging, dataresidens och compliance-krav måste vara explicita och testbara—inte antas för att koden “ser ut som frontend”.
Praktiska mönster för tydliga gränser i fullstack-appar
Fullstack-ramverk gör det enkelt att kolokalisera allt, men “enkelt” kan bli trassligt.
Målet är inte att återskapa gamla silos—det är att hålla ansvar läsbara så att funktioner förblir säkra att ändra.
1) Lägg domänlogik i ett servicelag
Behandla affärsregler som en egen modul, oberoende av rendering och routing.
En bra tumregel: om det avgör vad som ska hända (prissättningsregler, behörighet, state-transitioner) hör det hemma i services/.
Det håller UI:t tunt och route-handlers tråkiga—båda är bra utfall.
2) Dela upp UI, serverhandlers och dataåtkomst
Även om ramverket låter dig importera vad som helst var som helst, använd en enkel trepartsstruktur:
- Ren UI: komponenter som tar emot data och callbacks; inga databasklienter, inga request-objekt.
- Serverhandlers: route-handlers/server actions som översätter HTTP-/session-kontekst till servicestyrda anrop.
- Dataåtkomst: repositories/queries som vet hur man pratar med databasen eller externa API:er.
En praktisk guardrail: UI importerar bara services/ och ui/; serverhandlers kan importera services/; endast repositories importerar DB-klienten.
3) Testa där gränsen spelar roll
Matcha tester med lager:
- Unittester för services (snabba, inget nätverk, inget ramverk).
- Integrationstester för repositories och serverhandlers (riktig DB i CI eller testcontainer).
- E2E-tester för kritiska användarresor (inloggning, checkout, inställningsändringar).
Tydliga gränser gör tester billigare eftersom du kan isolera vad du validerar: affärsregler vs infrastruktur vs UI-flöde.
4) Gör gränser synliga i kodgranskning
Lägg till lätta konventioner: mappregler, lint-restriktioner och “ingen DB i komponenter”-kontroller.
De flesta team behöver inte tung process—bara konsekventa standarder som förhindrar oavsiktlig koppling.
Var Koder.ai passar in när stacken suddas ut
När fullstack-ramverk smälter ihop UI- och serverbekymmer i en kodbas flyttas ofta flaskhalsen från “kan vi koppla ihop detta?” till “kan vi hålla gränserna tydliga samtidigt som vi levererar snabbt?”
Koder.ai är designat för den verkligheten: det är en vibe-coding-plattform där du kan skapa webb-, server- och mobilapplikationer via ett chattgränssnitt—samtidigt som du får riktig, exportbar källkod. I praktiken betyder det att du kan iterera på end-to-end-funktioner (routes, UI, serveractions/API-rutter och dataåtkomst) i ett arbetsflöde, och ändå upprätthålla de gränsmönster som beskrivs ovan i det genererade projektet.
Om du bygger en typisk fullstack-app så mappar Koder.ai:s standardstack (React för webben, Go + PostgreSQL för backend, Flutter för mobil) tydligt på separationen “UI / handlers / services / data access”. Funktioner som planning mode, snapshots och rollback hjälper också när ramverksnivå-ändringar (renderingsläge, cache-strategi, auth-tilvägagång) får konsekvenser i appen.
Oavsett om du handkodar allt eller snabbar upp leverans med en plattform som Koder.ai kvarstår lärdomen: fullstack-ramverk gör det enklare att kolokalisera bekymmer—så du behöver avsiktliga konventioner för att hålla systemet begripligt, säkert och snabbt att utveckla vidare.
Vanliga frågor
What do “frontend” and “backend” mean in the traditional model?
Traditionellt betydde frontend kod som körs i webbläsaren (HTML/CSS/JS, UI-beteende, anrop till API:er), och backend var kod som körs på servrar (affärslogik, databaser, autentisering, integrationer).
Fullstack-ramverk spänner avsiktligt över båda: de renderar UI och kör serverkod i samma projekt, så gränsen blir ett designval (vad som körs var) snarare än separata kodbaser.
What is a “full-stack framework” in plain English?
Ett fullstack-ramverk är ett webb-ramverk som stödjer både UI-rendering och serverbeteende (routing, dataladdning, mutationer, autentisering) i en och samma app.
Exempel är Next.js, Remix, Nuxt och SvelteKit. Den viktiga förändringen är att routes och sidor ofta ligger intill den serverkod de beror på.
Why did full-stack frameworks emerge if separate frontends/backends already worked?
De minskar koordinationskostnader. Istället för att bygga en sida i ett repo och ett API i ett annat kan du leverera en end-to-end-funktion (route + UI + data + mutation) i en enda förändring.
Det förbättrar ofta iterationstakten och minskar integrationsbuggar som uppstår när frontend och backend antar olika saker.
How do SSR, SSG, and hybrid rendering blur the frontend/backend line?
De gör rendering till ett produktbeslut med backend-konsekvenser:
- SSR: servern bygger HTML per förfrågan (färskt men mer serverarbete).
- SSG: HTML byggs i förväg (billigt att servera, uppdateringar kräver byggen/revalidering).
- Hybrid: en blandning av SSR/SSG med revalidering.
Valet påverkar latenstid, serverbelastning, cache-strategi och kostnad—så “frontend”-arbete innefattar nu även backend-style tradeoffs.
Why is caching now considered part of rendering (not just ops)?
Caching blir en del av hur sidan byggs och hålls uppdaterad, inte bara en CDN-inställning:
- Per-route cache-regler (ingen cache vs 60s vs alltid)
- Data-nivå caching (cacha frågeresultat)
- Revalidering (servera cachad output tills den uppdateras)
Eftersom dessa val ofta lever intill route-/sidkoden, fattar UI-utvecklare beslut som påverkar färskhet, prestanda och driftkostnad samtidigt.
What are loaders/actions/API routes, and why do they feel “backend-ish”?
Många ramverk låter en route innehålla:
- UI för sidan
- En loader (hämta data)
- En action (hantera mutationer som formulärpost)
- Eller en API-route (returnera JSON)
Denna kolokalisering är bekväm, men behandla route-handlare som riktiga backend-entrépunkter: validera input, kontrollera auth och låt komplex affärslogik ligga i en service-/domänlager.
When data fetching moves next to components, what security pitfalls should I watch for?
Eftersom kod kan köras på olika platser gäller:
- Serverkod kan säkert nå databaser, hemligheter och interna tjänster.
- Klientkod är i praktiken publik: användare kan inspektera data i DevTools och avlyssna nätverksanrop.
Praktisk tumregel: skicka view models (endast de fält UI behöver), inte råa DB-poster, för att undvika oavsiktliga läckor som passwordHash, interna anteckningar eller PII.
Are shared TypeScript types always a good idea in full-stack apps?
Delade TypeScript-typer minskar kontraktsdrift: om servern ändrar ett fält bryter klienten redan i byggsteget.
Men att dela domän-/DB-formade modeller överallt ökar kopplingen. En säkrare mellanväg:
- Definiera per-route DTOs (request/response-typer)
- Mappa domän-entiteter till DTOs i kanten (handler/action)
- Undvik att importera ORM-entitets-typer i UI-komponenter
What are Server Actions, and what do developers often forget about them?
De får ett backend-anrop att kännas som ett lokalt funktionsanrop (t.ex. await createOrder(data)), medan ramverket sköter serialisering och transport.
Behandla dem fortfarande som publika server-entrépunkter:
- Validera input på servern
- Verkställ auktorisation i action
- Hantera latens/fel med laddnings- och felstater
- Designa för idempotens vid omförsök/om-inklick
How should authentication and authorization be handled when boundaries blur?
Fullstack-ramverk sprider ofta auth-ansvaret över hela appen:
- Middleware/edge-logik kan kontrollera cookies/tokens för åtkomst
- Route-handlers laddar aktuell användare, förnyar sessioner eller avvisar icke-autentiserade anrop
- UI-skydd döljer/avaktiverar knappar och visar inloggningsuppmaningar
UI-skydd förbättrar UX men är inte säkerhet. Verkställ alltid auktorisation nära dataåtkomst och lita aldrig på klient-supplied roller/userId.