19 dec. 2025·8 min
Hur MySQL skalade den tidiga webben — och fortfarande körs i stor skala
Hur MySQL växte från tidiga LAMP-sajter till dagens högvolymsproduktion: viktiga designval, InnoDB, replikation, sharding och praktiska skalningsmönster.
Hur MySQL växte från tidiga LAMP-sajter till dagens högvolymsproduktion: viktiga designval, InnoDB, replikation, sharding och praktiska skalningsmönster.
MySQL blev den tidiga webbens go-to-databas av en enkel anledning: den kunde det webbplatser behövde då—lagra och hämta strukturerad data snabbt, köras på modest hårdvara och vara enkel för små team att driva.
Den var lättillgänglig. Du kunde installera den snabbt, ansluta från vanliga programspråk och få en sajt att fungera utan att anställa en dedikerad databashanterare. Kombinationen av “tillräckligt bra prestanda” och låg driftkostnad gjorde den till ett standardval för startups, hobbyprojekt och växande företag.
När folk säger att MySQL “skalade” menar de vanligtvis en blandning av:
Tidiga webbbolag behövde inte bara hastighet; de behövde förutsägbar prestanda och upptid samtidigt som de höll infrastrukturomkostnaderna under kontroll.
MySQLs skalningsberättelse är egentligen en berättelse om praktiska avvägningar och upprepbara mönster:
Det här är en rundtur i mönstren team använde för att hålla MySQL presterande under verklig webbtrafik—inte en fullständig MySQL-handbok. Målet är att förklara hur databasen passade webbens behov, och varför samma idéer fortfarande dyker upp i massiva produktionssystem idag.
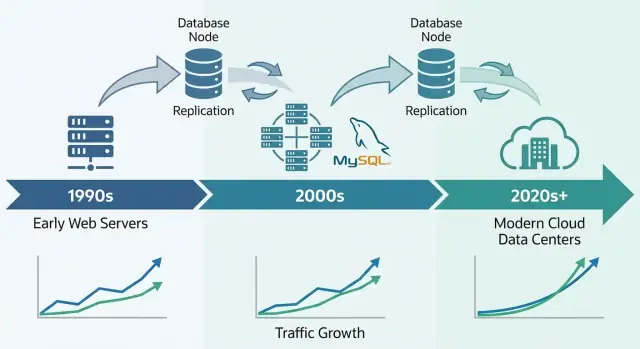
MySQLs genombrott var tätt kopplat till uppkomsten av delad hosting och små team som snabbt byggde webbappar. Det var inte bara att MySQL var “good enough”—det passade hur den tidiga webben deployades, hanterades och betalades.
LAMP (Linux, Apache, MySQL, PHP/Perl/Python) fungerade eftersom det stämde överens med standardservern de flesta hade råd med: en enda Linux-låda som kör en webserver och en databas sida vid sida.
Hosting-leverantörer kunde templa den här uppsättningen, automatisera installationer och erbjuda den billigt. Utvecklare kunde anta samma basmiljö nästan överallt, vilket minskade överraskningar när man flyttade från lokal utveckling till produktion.
MySQL var enkel att installera, starta och ansluta till. Den talade bekant SQL, hade en enkel CLI-klient och integrerades väl med populära språk och ramverk vid tiden.
Lika viktigt var att driftmodellen var tillgänglig: en huvudprocess, några konfigurationsfiler och tydliga felbeteenden. Det gjorde det realistiskt för generalist-sysadmins (och ofta utvecklare) att köra en databas utan specialutbildning.
Att vara open-source tog bort licenshinder. Ett studentprojekt, ett hobbyforum och en småföretagssajt kunde alla använda samma motor som större företag.
Dokumentation, mailinglistor och senare online-handledningar skapade momentum: fler användare gav fler exempel, fler verktyg och snabbare felsökning.
De flesta tidiga sajter var lästunga och ganska enkla: forum, bloggar, CMS-sidor och små e-handelskataloger. Dessa appar behövde ofta snabba uppslag efter ID, senaste inlägg, användarkonton och enkel sökning eller filtrering—exakt den typ av arbetsbelastning MySQL kunde hantera effektivt på modest hårdvara.
Tidiga MySQL-distributioner började ofta som “en server, en databas, en app.” Det fungerade bra för ett hobbyforum eller en liten företagsajt—tills appen blev populär. Sidvisningar blev sessioner, sessioner blev konstant trafik och databasen slutade vara en tyst bakgrundskomponent.
De flesta webbappar var (och är fortfarande) lästunga. En startsida, produktlista eller profilsida kan visas tusentals gånger för varje uppdatering. Denna obalans formade tidiga skalningsbeslut: om du kunde göra läsningar snabbare—eller undvika att träffa databasen för läsningar helt—kunde du betjäna långt fler användare utan att skriva om allt.
Men även lästunga appar har kritiska skrivningar. Registreringar, köp, kommentarer och admin-uppdateringar kan inte tappas. När trafiken växer måste systemet hantera både en flod av läsningar och “måste lyckas”-skrivningar samtidigt.
Vid högre trafik blev problemen synliga i enkla termer:
Team lärde sig att dela upp ansvar: appen hanterar affärslogiken, en cache absorberar upprepade läsningar, och databasen fokuserar på korrekt lagring och nödvändiga frågor. Denna mentala modell banade väg för senare steg som frågtuning, bättre indexering och horisontell skalning med repliker.
En unik sak med MySQL är att det inte är “en databasmotor” under huven. Det är en databasserver som kan lagra och hämta data med olika lagringsmotorer.
På en hög nivå bestämmer en lagringsmotor hur rader skrivs till disk, hur index underhålls, hur lås fungerar och vad som händer efter en krasch. Din SQL kan se identisk ut, men motorn avgör om databasen beter sig mer som en snabb anteckningsbok—eller som en bankbok.
Under lång tid använde många MySQL-installationer MyISAM. Den var enkel och ofta snabb för lästunga sajter, men hade kompromisser:
InnoDB vände på de antagandena:
När webbappar gick från mestadels läsning till att hantera inloggningar, kundvagnar, betalningar och meddelanden, blev korrekthet och återställning lika viktiga som hastighet. InnoDB gjorde det realistiskt att skala utan att frukta att en omstart eller trafikspik skulle korrupta data eller stoppa hela tabellen.
Det praktiska slutsatsen: val av motor påverkar både prestanda och säkerhet. Det är inte bara en kryssruta—ditt låsmodell, felbeteende och appgarantier beror på det.
Innan sharding, läsrepliker eller avancerad caching kom många tidiga MySQL-vinster från en konsekvent förändring: göra frågor förutsägbara. Index och frågedesign var den första “multiplikatorn” eftersom de minskade hur mycket data MySQL behövde röra vid per förfrågan.
De flesta MySQL-index är B-tree-baserade. Tänk på dem som en ordnad katalog: MySQL kan hoppa till rätt plats och läsa en liten, sammanhängande del av data. Utan rätt index faller servern ofta tillbaka på att skanna rader en och en. Vid låg belastning är det bara långsamt; i skala blir det en trafikförstärkare—mer CPU, mer disk-I/O, mer låstid och högre latens för allt annat.
Några mönster orsakade återkommande "fungerade i staging"-fel:
SELECT *: hämtar onödiga kolumner, ökar I/O och kan slå ut fördelarna med covering-index.WHERE name LIKE '%shoe' kan inte använda ett vanligt B-tree-index effektivt.WHERE DATE(created_at) = '2025-01-01' hindrar ofta indexanvändning; föredra range-filter som created_at >= ... AND created_at < ....Två vanor skalade bättre än något enskilt smart trick:
EXPLAIN för att verifiera att du använder tänkt index och inte skannar.Designa index runt hur produkten beter sig:
(user_id, created_at) gör "senaste objekt" snabba.Bra indexering är inte "fler index"—det är de få rätta som matchar kritiska läs-/skrivvägar.
När en MySQL-baserad produkt börjar bli långsam är det stora beslutet om du ska skala upp (vertikalt) eller ut (horisontellt). De löser olika problem—och förändrar din operativa vardag på mycket olika sätt.
Vertikal skalning betyder att ge MySQL mer resurser på en maskin: snabbare CPU, mer RAM, bättre lagring.
Det fungerar ofta överraskande bra eftersom många flaskhalsar är lokala:
Vertikal skalning är vanligtvis snabbast: färre rörliga delar, enklare felbeteenden och mindre applikationsändring. Nackdelen är att det alltid finns en gräns (och uppgraderingar kan kräva driftstopp eller riskfyllda migreringar).
Horisontell skalning lägger till maskiner. För MySQL betyder det typiskt:
Det är svårare eftersom du introducerar koordineringsproblem: replikationsfördröjning, failover-beteende, konsistensavvägningar och mer driftverktyg. Din applikation behöver också veta vilken server den ska prata med (eller så behöver du ett proxy-lager).
De flesta team behöver inte sharding som första steg. Börja med att bekräfta var tiden går (CPU vs I/O vs låskonflikter), fixa långsamma frågor och index, och anpassa minne och lagring. Horisontell skalning lönar sig när en enda maskin inte kan möta din skrivfrekvens, lagringsbehov eller tillgänglighetskrav—även efter god tuning.
Replikation är en av de mest praktiska metoderna MySQL-system använde för tillväxt: istället för att låta en databas göra allt, kopierar du dess data till andra servrar och sprider arbetet.
Tänk på en primär (ibland kallad “master”) som databasen som tar emot ändringar—INSERT, UPDATE, DELETE. En eller flera repliker kontinuerligt drar dessa ändringar och applicerar dem, och håller en nära realtidskopia.
Din applikation kan då:
Detta mönster blev vanligt eftersom webbtrafik ofta växer "mer i läsningar" snabbare än i skrivningar.
Läsrepliker handlade inte bara om att servera sidvisningar snabbare. De hjälpte också till att isolera jobb som annars skulle sakta ner huvuddatabasen:
Replikation är ingen gratislunch. Det vanligaste problemet är replikationsfördröjning—repliker kan ligga sekunder (eller mer) efter primären vid spikar.
Det leder till en app-nivå fråga: read-your-writes-konsistens. Om en användare uppdaterar en profil och du omedelbart läser från en replika, kan hen se gammal data. Många team löser detta genom att läsa från primären för färska vyer eller använda ett kort “läs från primären efter skrivning”-fönster.
Replikation kopierar data; det håller dig inte automatiskt uppe vid fel. Failover—att promota en replika, dirigera om trafik och säkerställa att appen reconnectar säkert—är en separat kapabilitet som kräver verktyg, tester och tydliga driftsrutiner.
Hög tillgänglighet (HA) är praxis som håller din app igång när en databasserver kraschar, en nätlänk går ner eller du behöver göra underhåll. Målen är enkla: minska driftstopp, göra underhåll säkert och se till att återhämtning är förutsägbar istället för improviserad.
Tidiga MySQL-distributioner började ofta med en primär databas. HA lade vanligtvis till en andra maskin så att ett fel inte betydde långt avbrott.
Automatisering hjälper, men höjer också ribban: ditt team måste lita på detektionslogiken och undvika "split brain" (två servrar som tror de är primära).
Två mått gör HA-beslut mer mätbara:
HA är inte bara topologi—det är praxis.
Backups måste vara rutin, men nyckeln är återställningstester: kan du verkligen återställa till en ny server, snabbt och under press?
Schemaändringar spelar också roll. Stora tabelländringar kan låsa skrivningar eller sakta frågor. Säkrare metoder inkluderar att göra ändringar under lågtrafik, använda online schema-change-verktyg och alltid ha en rollback-plan.
Görs det väl blir fel inte nödsituationer utan planerade, övade händelser.
Caching var ett av de enklaste sätten tidiga webbteam höll MySQL responsiv när trafiken steg. Idén är enkel: svara upprepade förfrågningar från något snabbare än databasen, och slå bara mot MySQL när det behövs. Gjort rätt sänker caching läsbelastningen dramatiskt och gör plötsliga spikar hanterbara.
Applikations-/objektcache lagrar "bitar" av data som din kod ofta frågar efter—användarprofiler, produktdetaljer, behörighetskontroller. Istället för att köra samma SELECT hundratals gånger per minut läser appen ett förberäknat objekt via en nyckel.
Sida- eller fragmentcache lagrar renderad HTML (hela sidor eller delar som en sidospalt). Detta är särskilt effektivt för innehållstunga sajter där många besökare ser samma sidor.
Frågeresultat-cache sparar resultatet av en specifik fråga (eller en normaliserad version av den). Även om du inte cacher på SQL-nivå kan du cacha "resultatet av denna endpoint" med en nyckel som representerar förfrågan.
Konceptuellt använder team in-memory key/value-butiker, HTTP-cacher eller inbyggd caching i ramverk. Verktyget spelar mindre roll än konsekventa nycklar, TTL:er och tydligt ägandeskap.
Caching byter färskhet mot hastighet. Viss data kan vara lite föråldrad (nyhetssidor, visningsräkningar). Annan data kan inte vara det (checkout-summor, behörigheter). Vanligtvis väljer man mellan:
Om invalidiering misslyckas kan användare se föråldrat innehåll. Om den är för aggressiv förlorar du fördelarna och MySQL blir överbelastad igen.
När trafiken spikar absorberar cacher upprepade läsningar medan MySQL fokuserar på “riktigt arbete” (skrivningar, cache-missar, komplexa frågor). Detta minskar köbildning, förhindrar att långsamhet sprider sig och ger tid att skala säkert.
Det finns en punkt där "större hårdvara" och noggrann frågetuning inte längre räcker. Om en enda MySQL-server inte kan hantera skrivfrekvens, datamängd eller underhållsfönster börjar du fundera på att dela data.
Partitionering delar en tabell i mindre delar inne i samma MySQL-instans (t.ex. efter datum). Det kan göra borttagningar, arkivering och vissa frågor snabbare, men det låter dig inte överskrida CPU-, RAM- och I/O-gränserna för den servern.
Sharding delar data över flera MySQL-servrar. Varje shard håller en delmängd av raderna, och din applikation (eller ett routingskikt) bestämmer vart varje förfrågan går.
Sharding dyker oftast upp när:
En bra shard-nyckel sprider trafiken jämnt och håller de flesta förfrågningar på en enda shard:
Sharding byter enkelhet mot skala:
Börja med caching och läsrepliker för att avlasta primären. Isolera sedan de tyngsta tabellerna eller arbetsflödena (ibland genom att dela per funktion eller tjänst). Först därefter gå till sharding—helst på ett sätt som låter dig lägga till shards gradvis istället för att göra om allt på en gång.
Att köra MySQL för en trafikerad produkt handlar mindre om smarta funktioner och mer om disciplinerad drift. De flesta avbrott börjar inte med ett dramatiskt fel—de börjar med små signaler som ingen kopplade ihop i tid.
I skala tenderar de “fyra stora” signalerna att förutsäga problem tidigt:
Bra dashboards ger kontext: trafik, felräntor, anslutningsantal, buffer pool hit rate och toppfrågor. Målet är att se förändring—inte memorera “normalt”.
Många frågor ser fine ut i staging och till och med i produktion under lugna timmar. Under belastning beter sig databasen annorlunda: cacher hjälper inte, samtidiga förfrågningar förstärker låskonflikter och en något ineffektiv fråga kan trigga fler läsningar, fler temporära tabeller eller större sorteringsarbete.
Därför förlitar sig team på slow query-logg, frågesammanfattningar och verkliga produktionshistogram snarare än enstaka benchmark-tester.
Säkra ändringsrutiner är avsiktligt tråkiga: kör migrationer i små satser, lägg till index med minimal låsning när möjligt, verifiera med explain-planer och håll rollback realistiska (ibland är rollback att stoppa rollout och failover). Ändringar bör vara mätbara: före/efter latens, lock-waits och replikationslagg.
Under en incident: bekräfta påverkan, identifiera huvudorsaken (en fråga, en host, en tabell), och mildra—throttla trafik, döda runaway-queries, lägg till ett temporärt index eller flytta läsningar/skrivningar. Efteråt, dokumentera vad som hände, lägg till larm för tidiga signaler och göra fixen upprepbar så samma fel inte återkommer nästa vecka.
MySQL förblir ett standardval för många moderna system eftersom det matchar formen för vardaglig applikationsdata: många små läsningar och skrivningar, tydliga transaktionsgränser och förutsägbara frågor. Därför passar det fortfarande OLTP-tunga produkter som SaaS-appar, e-handel, marknadsplatser och multi-tenant-plattformar—särskilt om du modellerar data kring verkliga affärsobjekt och håller transaktioner fokuserade.
Dagens MySQL-ekosystem drar nytta av år av lärdomar inbakade i bättre defaults och säkrare driftsvanor. I praktiken förlitar sig team på:
Många företag kör nu MySQL via managed services, där leverantören sköter rutinärenden som patchning, automatiska backups, kryptering, punkt-i-tid-återställning och vanliga skalsteg (större instanser, läsrepliker, lagringstillväxt). Du äger fortfarande schema, frågor och åtkomstmönster—but du spenderar mindre tid på underhållsfönster och återställningsövningar.
En anledning till att "MySQL-skalningsplaybooken" fortfarande är relevant är att det sällan bara är ett databashot. Val som read/write-separation, cache-nycklar och invalidiering, säkra migrationer och rollback-planer fungerar bäst när de designas tillsammans med produkten, inte som snabba lösningar under incidenter.
Om du bygger nya tjänster och vill koda in dessa beslut tidigt kan en vibe-coding-workflow hjälpa. Till exempel kan Koder.ai ta ett ren-text-spec (entiteter, trafikförväntningar, konsistensbehov) och hjälpa till att generera ett app-skelett—vanligtvis React för webben och Go-tjänster—samtidigt som du behåller kontroll över datalagsdesignen. Dess Planning Mode, snapshots och rollback är särskilt användbara när du itererar på scheman och deploy-ändringar utan att varje migration blir hög risk.
Om du vill utforska Koder.ai-planer (Free, Pro, Business, Enterprise), se prisplaner.
Välj MySQL när du behöver: starka transaktioner, en relationell modell, mogna verktyg, förutsägbar prestanda och en stor arbetsmarknad. Överväg alternativ när du behöver: massiv write fan-out med flexibel schema (vissa NoSQL-system), globalt konsekventa multi-region-skrivningar (specialiserade distribuerade databaser), eller analysfokuserade arbetslaster (kolumnlager).
Praktisk slutsats: börja från kraven (latens, konsistens, datamodell, tillväxttakt, teamets färdigheter), välj det enklaste systemet som möter dem—och MySQL gör det ofta.
MySQL träffade en balans som passade tidiga webbplatser: snabbt att installera, enkelt att koppla till vanliga språk och “tillräckligt bra” prestanda på begränsad hårdvara. I kombination med öppen källkod och att LAMP-stackens närvaro på delad hosting var vanlig, blev det standardvalet för många små team och växande sajter.
I det här sammanhanget betyder “skala” oftast att klara av:
Det handlar inte bara om rå hastighet—utan om förutsägbar prestanda och upptid under verklig belastning.
LAMP gjorde distributionen förutsägbar: en enda Linux-maskin kunde köra Apache + PHP + MySQL billigt, och hosting-leverantörer kunde standardisera och automatisera uppsättningen. Denna konsistens minskade friktionen vid övergång från lokal utveckling till produktion och hjälpte MySQL spridas som en "allmänt tillgänglig" databas.
Tidiga webbjobb var ofta lästunga och enkla: användarkonton, senaste inlägg, produktkataloger och grundläggande filtrering. MySQL fungerade bra för snabba uppslag (ofta med primärnyckel) och vanliga mönster som “senaste objekt”, särskilt när index matchade åtkomstmönstren.
Vanliga tidiga problem var:
Dessa problem syntes ofta först när trafiken ökade och gjorde små ineffektiviteter till stora fördröjningar.
En lagringsmotor styr hur MySQL skriver data, upprätthåller index, låser rader/tabeller och återhämtar sig efter krascher. Valet av motor påverkar både prestanda och korrekthet—två installationer kan köra samma SQL men bete sig mycket olika vid samtidighet och fel.
MyISAM var vanligt tidigt eftersom det kunde vara enkelt och snabbt för läsningar, men det förlitar sig på table-level locks, saknar transaktioner och är svagare vid återhämtning efter krasch. InnoDB införde row-level locking, transaktioner och bättre hållbarhet—vilket gjorde det till ett bättre standardval när applikationer behövde säkrare skrivningar (inloggningar, varukorgar, betalningar) i skala.
Index gör att MySQL kan hitta rader snabbt istället för att skanna hela tabeller. Praktiska vanor som betyder mycket:
SELECT *; hämta bara nödvändiga kolumnerLIKE och funktioner på indexerade kolumnerEXPLAIN för att bekräfta indexanvändningVertikal skalning ("större maskin") lägger till CPU/RAM/snabbare lagring till en server—ofta snabbast och med färre rörliga delar. Horisontell skalning ("fler maskiner") lägger till repliker och/eller shardar, men ger koordineringskomplexitet (replikationsfördröjning, routing, failover). De flesta team bör först åtgärda frågor, index och rätta resurser innan de shardar.
Läsrepliker hjälper genom att leda många läsningar (och ofta rapportering/backup-jobb) till sekundära servrar medan skrivningar hålls på primären. Huvudproblemet är replikationsfördröjning—repliker kan ligga efter med några sekunder eller mer, vilket kan bryta "read-your-writes"-förväntningar. Ofta läser appar från primären direkt efter en skrivning eller använder ett kort "läs från primär efter skriv"-fönster.
Målet är förutsägbara kostnader per fråga under belastning.