13 nov. 2025·7 min
Hur NoSQL‑databaser uppstod för att lösa skalning och flexibilitet
Lär dig varför NoSQL uppstod: webbens skala, behov av flexibla dataformer och begränsningarna i relationssystem — plus huvudmodeller och avvägningar.
Lär dig varför NoSQL uppstod: webbens skala, behov av flexibla dataformer och begränsningarna i relationssystem — plus huvudmodeller och avvägningar.
NoSQL uppstod när många team stötte på en missmatch mellan vad deras applikationer behövde och vad traditionella relationsdatabaser (SQL‑databaser) var optimerade för. SQL “misslyckades” inte — men i webbskala började vissa team prioritera andra mål.
För det första, skala. Populära konsumentappar började se trafiktoppar, konstant skrivbelastning och enorma mängder användargenererad data. För dessa arbetsmängder blev “köp en större server” dyrt, långsamt att genomföra och till sist begränsat av den största maskin du rimligen kunde driva.
För det andra, förändring. Produktfunktioner utvecklades snabbt och datan bakom dem passade inte alltid snyggt i ett fast antal tabeller. Att lägga till nya attribut i användarprofiler, lagra flera händelstyper eller ta in semistrukturerad JSON från olika källor krävde ofta upprepade schemamigreringar och tvärteam‑koordinering.
Relationsdatabaser är utmärkta för att upprätthålla struktur och möjliggöra komplexa frågor över normaliserade tabeller. Men vissa högskaliga arbetsbelastningar gjorde de styrkorna svårare att utnyttja:
Resultatet: vissa team sökte system som bytte bort vissa garantier och kapabiliteter mot enklare skalning och snabbare iteration.
NoSQL är inte en enskild databas eller design. Det är en paraplyterm för system som betonar en blandning av:
NoSQL var aldrig menat att vara en universell ersättning för SQL. Det är en uppsättning avvägningar: du kan vinna skalbarhet eller schemaflexibilitet, men acceptera svagare konsistensgarantier, färre ad‑hoc‑frågemöjligheter eller mer ansvar i applikationsnivå för datamodellering.
I många år var standardsvaret på en långsam databas enkelt: köp en större server. Lägg till mer CPU, mer RAM, snabbare diskar och behåll samma schema och operativa modell. Denna “scale up”-metod fungerade — tills den slutade vara praktisk.
High‑end‑maskiner blir snabbt dyra och pris/prestanda‑kurvan blir så småningom ogynnsam. Uppgraderingar kräver ofta stora, sällsynta budgetbeslut och underhållsfönster för att flytta data och byta över. Även om du har råd med större hårdvara har en enda server fortfarande en övre gräns: en minnesbuss, ett lagringssubsystem och en primär nod som absorberar skrivbelastningen.
När produkterna växte fick databaser konstant läs‑/skrivtryck istället för sporadiska toppar. Trafiken blev verkligt 24/7 och vissa funktioner skapade ojämna accessmönster. Ett litet antal hårt åtkomna rader eller partitioner kunde dominera trafiken och skapa hot tables (eller hot keys) som sänkte allt annat.
Operativa flaskhalsar blev vanliga:
Många applikationer behövde också vara tillgängliga över regioner, inte bara snabba i ett datacenter. En enda “huvud”databas på ett ställe ökar latensen för avlägsna användare och gör driftstopp mer katastrofala. Frågan försköts från “Hur köper vi en större låda?” till “Hur kör vi databasen över många maskiner och platser?”
Relationsdatabaser glänser när din datamodell är stabil. Men många moderna produkter står inte stilla. En tabellschema är avsiktligt strikt: varje rad följer samma uppsättning kolumner, typer och begränsningar. Den förutsägbarheten är värdefull — tills du itererar snabbt.
I praktiken kan frekventa schemaändringar vara dyra. En till synes liten uppdatering kan kräva migreringar, backfills, indexuppdateringar, koordinerad driftsättning och kompatibilitetsplanering så att äldre kodvågar inte går sönder. På stora tabeller kan även att lägga till en kolumn eller ändra en typ bli en tidskrävande operation med verklig operationell risk.
Denna friktion tvingar team att skjuta upp förändringar, ackumulera nödlösningar eller lagra röriga blobbar i textfält — inget av detta är idealiskt för snabb iteration.
Mycket applikationsdata är naturligt semistrukturerad: nästlade objekt, valfria fält och attribut som utvecklas över tid.
Till exempel kan en “user profile” börja med namn och e‑post, för att sedan växa med preferenser, länkade konton, leveransadresser, notifikationsinställningar och experimentflaggar. Inte alla användare har alla fält, och nya fält dyker upp gradvis. Dokumentstilmodeller kan lagra nästlade och ojämna former direkt utan att tvinga varje post in i samma strikta mall.
Flexibilitet minskar också behovet av komplexa joins för vissa datamönster. När en skärm behöver ett sammansatt objekt (en order med artiklar, leveransinfo och statushistorik) kan relationsdesigner kräva flera tabeller och joins — plus ORM‑lager som försöker dölja komplexiteten men ofta lägger till friktion.
NoSQL‑alternativ gjorde det enklare att modellera data närmare hur applikationen läser och skriver det, vilket hjälpte team att leverera ändringar snabbare.
Webbapplikationer blev inte bara större — de ändrade form. Istället för ett förutsägbart antal interna användare under kontorstid började produkter betjäna miljoner globala användare dygnet runt, med plötsliga toppar drivna av lanseringar, nyheter eller social delning.
Alltid‑på‑förväntningar höjde ribban: driftstopp blev en rubrik, inte ett besvär. Samtidigt ombads team att leverera funktioner snabbare — ofta innan någon visste vad den “slutgiltiga” datamodellen skulle bli.
För att hänga med slutade det räcka att skala upp en enda databasserver. Ju mer trafik du hanterade, desto mer ville du ha kapacitet du kunde lägga till stegvis — lägg till en nod, sprid lasten, isolera fel.
Det pressade arkitekturen mot flotta av maskiner snarare än en “huvud”låda, och förändrade vad team förväntade sig av databaser: inte bara korrekthet, utan förutsägbar prestanda under hög samtidighet och graciellt beteende när delar av systemet är ohälsosamma.
Innan “NoSQL” blev mainstream böjde många team systemen mot webbskålans realiteter:
Dessa tekniker fungerade, men de flyttade komplexitet in i applikationskoden: cache‑invalidation, att hålla duplicerad data konsekvent och bygga pipelines för “ready‑to‑serve” poster.
När dessa mönster blev standard behövde databaser stödja datadistribution över maskiner, tolerera partiella fel, hantera hög skrivvolym och representera utvecklande data på ett rent sätt. NoSQL‑databaser uppstod delvis för att göra vanliga webbskala‑strategier till förstklassiga funktioner istället för ständiga nödlösningar.
När data lever på en maskin känns reglerna enkla: det finns en enda sanningskälla och varje läsning eller skrivning kan kontrolleras omedelbart. När du sprider data över servrar (ofta över regioner) uppstår en ny verklighet: meddelanden kan försenas, noder kan falla och delar av systemet kan tillfälligt sluta kommunicera.
En distribuerad databas måste bestämma vad den gör när den inte kan samordna säkert. Ska den fortsätta svara så att appen förblir “up”, även om resultaten kan vara en aning föråldrade? Eller ska den neka vissa operationer tills repliker kan bekräfta överenskommelse, vilket kan se ut som driftstopp för användare?
Dessa situationer uppstår vid routerfel, överbelastade nätverk, rullande deployment, felkonfigurerade brandväggar och fördröjningar i replikering mellan regioner.
CAP‑teoremet är en förkortning för tre egenskaper du gärna vill ha samtidigt:
Huvudpoängen är inte “välj två för alltid”. Det är: när en nätverkspartition händer måste du välja mellan konsistens och tillgänglighet. I webbskala behandlas partitioner som oundvikliga — särskilt i multi‑region‑upplägg.
Föreställ dig att din app körs i två regioner för motståndskraft. Ett fiberavbrott eller routingfel förhindrar synkronisering.
Olika NoSQL‑system (och olika konfigurationer av samma system) gör olika kompromisser beroende på vad som är viktigast: användarupplevelsen under fel, korrekthetsgarantier, operationell enkelhet eller återhämtningsbeteende.
Skala ut (horisontell skalning) betyder att öka kapaciteten genom att lägga till fler maskiner (noder) snarare än att köpa en enda större server. För många team var detta en ekonomisk och operationell förändring: commodity‑noder kunde läggas till inkrementellt, fel förväntades och tillväxt krävde inte riskfyllda “större låda”‑migrationer.
För att göra många noder användbara lutade NoSQL‑system mot sharding (även kallat partitionering). I stället för att en databas hanterar alla förfrågningar delas data upp i partitioner som distribueras över noder.
Ett enkelt exempel är partitionering efter en nyckel (som user_id):
Läsningar och skrivningar sprids, hot mot enskilda noder minskar och genomströmningen kan växa när du lägger till noder. Partitionsnyckeln blir ett designval: välj en nyckel som stämmer överens med frågemönster, annars kan du oavsiktligt styra för mycket trafik till en shard.
Replikering betyder att hålla flera kopior av samma data på olika noder. Detta förbättrar:
Replikering möjliggör också att sprida data över rack eller regioner för att klara lokala driftstopp.
Sharding och replikering inför löpande operationellt arbete. När data växer eller noder ändras måste systemet rebalansera — flytta partitioner samtidigt som det är online. Hanteras detta dåligt kan rebalansering orsaka latensspikar, ojämn last eller tillfälliga kapacitetsbrister.
Det här är en kärnavvägning: billigare skalning via fler noder i utbyte mot mer komplex distribution, övervakning och felhantering.
När data är distribuerad måste databasen definiera vad “korrekt” betyder när uppdateringar sker samtidigt, nätverk blir långsamma eller noder inte kan kommunicera.
Med stark konsistens, när en skrivning är bekräftad ska varje läsning se den omedelbart. Detta motsvarar “en enda sanningskälla”‑upplevelsen som många förknippar med relationsdatabaser.
Utmaningen är koordination: starka garantier över noder kräver flera meddelanden, väntan på tillräckligt många svar och hantering av fel under pågående operationer. Ju längre ifrån varandra noder befinner sig (eller ju mer belastade de är), desto mer latens kan introduceras — ibland på varje skrivning.
Eventuell konsistens släpper på den garantin: efter en skrivning kan olika noder tillfälligt returnera olika svar, men systemet konvergerar över tid.
Exempel:
För många användarupplevelser är den temporära skillnaden acceptabel om systemet förblir snabbt och tillgängligt.
Om två repliker accepterar uppdateringar nästan samtidigt behöver databasen en sammanslagningsregel.
Vanliga tillvägagångssätt inkluderar:
Stark konsistens är ofta värd kostnaden för penningöverföringar, lagerbegränsningar, unika användarnamn, behörigheter och alla arbetsflöden där “två sanningar för ett ögonblick” kan orsaka verklig skada.
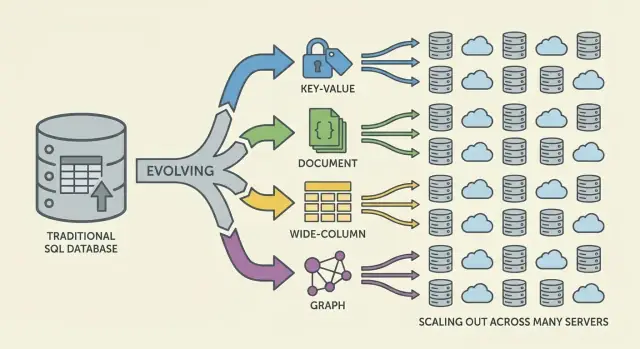
NoSQL är en uppsättning modeller som gör olika avvägningar kring skala, latens och datans form. Att förstå “familjen” hjälper dig förutsäga vad som blir snabbt, vad som blir smärtsamt och varför.
Key‑value‑databaser lagrar ett värde bakom en unik nyckel, som en gigantisk distribuerad hashmap. Eftersom accessmönstret ofta är “get by key” / “set by key” kan de vara extremt snabba och horisontellt skalbara.
De är utmärkta när du redan känner lookup‑nyckeln (sessioner, caching, feature flags), men begränsade för ad‑hoc‑frågor: filtrering över flera fält är ofta inte systemets syfte.
Dokumentdatabaser lagrar JSON‑liknande dokument (ofta grupperade i collections). Varje dokument kan ha en något annan struktur, vilket stödjer schemaflexibilitet när produkter utvecklas.
De är optimerade för att läsa och skriva hela dokument och fråga efter fält inuti dem — utan att tvinga strikta tabeller. Kompromissen: att modellera relationer kan bli knepigt och joins (om de stöds) kan vara mer begränsade än i relationssystem.
Wide‑column‑databaser (inspirerade av Bigtable) organiserar data efter radnycklar, med många kolumner som kan variera per rad. De är utmärkta vid massiva skrivhastigheter och distribuerad lagring, vilket gör dem lämpliga för tidsserier, händelser och loggar.
De premierar noggrann design kring accessmönster: du frågar effektivt efter primärnyckel och klustringsregler, inte godtyckliga filter.
Grafdatabaser behandlar relationer som förstklassig data. Istället för att upprepa joins traverserar de kanter mellan noder, vilket gör frågor om “hur är dessa saker kopplade?” naturliga och snabba (bedrägeri‑nätverk, rekommendationer, beroenden).
Relationsdatabaser uppmuntrar normalisering: dela data i många tabeller och sätt ihop med joins vid frågetid. Många NoSQL‑system tvingar dig att designa runt de viktigaste accessmönstren — ibland på bekostnad av duplicering — för att hålla latensen förutsägbar över noder.
I distribuerade databaser kan en join kräva att hämta data från flera partitioner eller maskiner. Det lägger till nätverkshopp, koordination och oförutsägbar latens. Denormalisering (lagra relaterad data tillsammans) minskar round‑trips och håller en läsning “lokal” så ofta som möjligt.
En praktisk konsekvens: du kan lagra samma kundnamn i en orders‑post även om det också finns i customers, eftersom “visa de senaste 20 beställningarna” är en kärnfråga.
Många NoSQL‑databaser stödjer begränsade joins (eller inga alls), så applikationen tar på sig mer ansvar:
Därför börjar ofta NoSQL‑modellering med: “Vilka skärmar måste vi ladda?” och “Vilka är de viktigaste frågorna vi måste göra snabba?”.
Sekundära index kan möjliggöra nya frågor (“hitta användare efter e‑post”), men de är inte gratis. I distribuerade system kan varje skrivning uppdatera flera indexstrukturer, vilket leder till:
NoSQL antogs inte för att det var “bättre” på alla sätt. Det antogs för att team var villiga att byta vissa bekvämligheter i relationsdatabaser mot hastighet, skala och flexibilitet under webbskale‑press.
Skala‑ut som design. Många NoSQL‑system gjorde det praktiskt att lägga till maskiner (horisontell skalning) i stället för att ständigt uppgradera en server. Sharding och replikering blev kärnfunktioner.
Flexibla scheman. Dokument‑ och key‑value‑system lät applikationer utvecklas utan att varje fältändring gick igenom ett strikt tabell‑definition, vilket minskade friktionen när kraven ändrades ofta.
Hög‑tillgänglighetsmönster. Replikering över noder och regioner gjorde det enklare att hålla tjänster igång under hårdvara‑fel eller underhåll.
Dataduplicering och denormalisering. Att undvika joins innebär ofta duplicerad data. Det förbättrar läsprestanda men ökar lagring och introducerar “uppdatera överallt”‑komplexitet.
Konsistensöverraskningar. Eventuell konsistens kan fungera — tills det inte gör det. Användare kan se föråldrad data eller förvirrande kantfall om inte applikationen är designad för att tolerera eller lösa konflikter.
Svårare analys (ibland). Vissa NoSQL‑lagringssystem är utmärkta för operationella läsningar/skrivningar men gör ad‑hoc‑frågor, rapportering eller komplexa aggregeringar mer omständliga än SQL‑först‑system.
Tidiga NoSQL‑antaganden flyttade ofta insatsen från databasens funktioner till ingenjörsdiciplin: övervaka replikering, hantera partitioner, köra kompaktion, planera backup/restore och load‑testa felscenarier. Team med hög operationell mognad drog störst nytta.
Välj baserat på verkligheten i arbetsbelastningen: förväntad latens, toppgenomströmning, dominerande frågemönster, tolerans för föråldrade läsningar och återställningskrav (RPO/RTO). Rätt NoSQL‑val är oftast det som matchar hur din applikation fallerar, skalar och behöver frågas — inte det med mest imponerande checklist.
NoSQL löste två vanliga påfrestningar:
Det handlade inte om att SQL var “dåligt”, utan om att olika arbetsbelastningar prioriterar olika avvägningar.
Det traditionella “scale up”-svar stöter på praktiska gränser:
NoSQL-lösningar satsade istället på skalning genom att lägga till noder i stället för att hela tiden köpa en större låda.
Relationsscheman är strikt konstruerade, vilket är bra för stabilitet men smärtsamt vid snabb iteration. På stora tabeller kan även “enkla” ändringar kräva:
Dokument‑modeller minskar ofta denna friktion genom att tillåta valfria och utvecklande fält.
Inte nödvändigtvis. Många SQL-databaser kan skalas ut, men det blir ofta operationellt komplext (sharding, cross‑shard joins, distribuerade transaktioner).
NoSQL‑system gjorde distribution (partitionering + replikering) till en förstklassig funktion, optimerad för enklare och förutsägbara accessmönster i stor skala.
Denormalisering lagrar data i formen som läses, ofta med duplicering för att undvika dyra joins över partitioner.
Exempel: spara kundnamn i en orders‑post så att “senaste 20 beställningarna” kan hämtas med en snabb läsning.
Kompromissen är uppdateringskomplexitet: duplicerad data måste hållas konsekvent genom applikationslogik eller pipelines.
I distribuerade system måste databasen bestämma vad som händer vid nätverkspartitioner:
CAP påminner om att under partition kan du inte garantera både perfekt konsistens och full tillgänglighet samtidigt.
Stark konsistens innebär att när en skrivning bekräftats ska alla läsare se den omedelbart; det kräver ofta koordination mellan noder.
Eventuell konsistens betyder att repliker kan skilja sig under en kort tid men konvergerar senare. Det fungerar bra för feeds, räknare och hög‑tillgänglighetsupplevelser om applikationen tål kortvarig föråldring.
En konflikt uppstår när olika repliker accepterar samtidiga uppdateringar. Vanliga strategier:
Valet beror på om det är acceptabelt att förlora mellanliggande uppdateringar för den aktuella datatypen.
En snabb vägledning:
Välj utifrån dina dominerande accessmönster, inte allmän popularitet.
Börja med krav och verifiera med tester:
Många system är hybrida: SQL för kärn‑sanningen (betalningar, lager), NoSQL för högvolyms‑ eller flexibla data (feeds, sessioner, profiler).