27 juli 2025·8 min
Hur språk, databaser och ramverk fungerar som ett system
Lär dig hur språk, databaser och ramverk fungerar som ett system. Jämför avvägningar, integrationspunkter och praktiska sätt att välja en sammanhållen stack.
Lär dig hur språk, databaser och ramverk fungerar som ett system. Jämför avvägningar, integrationspunkter och praktiska sätt att välja en sammanhållen stack.
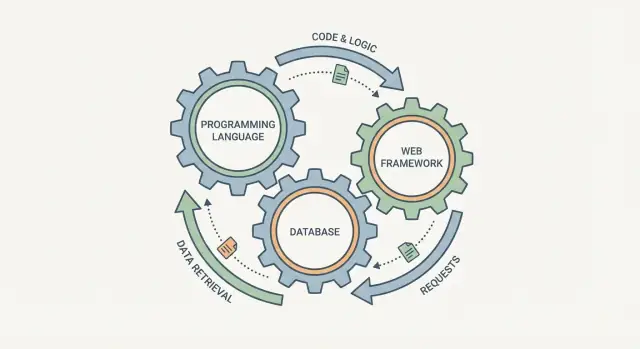
Det är frestande att bocka av ett programmeringsspråk, en databas och ett webbramverk som tre oberoende val. I praktiken beter de sig mer som sammankopplade kugghjul: ändra ett, och de andra märker det.
Ett webbramverk formar hur förfrågningar hanteras, hur data valideras och hur fel visas. Databasen bestämmer vad som är “enkelt att lagra”, hur du frågar information och vilka garantier du får när flera användare agerar samtidigt. Språket sitter i mitten: det avgör hur säkert du kan uttrycka regler, hur du hanterar konkurrent körning och vilka bibliotek och verktyg du kan lita på.
Att behandla stacken som ett enda system innebär att du inte optimerar varje del isolerat. Du väljer en kombination som:
Den här artikeln håller sig praktisk och medvetet icke-teknisk. Du behöver inte memorera databasteori eller språkets internals—se bara hur val påverkar hela applikationen.
Ett snabbt exempel: att använda en schemalös databas för mycket strukturerade, rapporttunga affärsdata leder ofta till spridda ”regler” i applikationskoden och förvirrande analys senare. Ett bättre val kan vara att para samma domän med en relationsdatabas och ett ramverk som uppmuntrar konsekvent validering och migrationer, så din data förblir sammanhängande när produkten utvecklas.
När du planerar stacken tillsammans designar du en uppsättning avvägningar—inte tre separata satsningar.
Ett hjälpsamt sätt att tänka på en “stack” är som en enda pipeline: en användarförfrågan går in i systemet, och ett svar (plus sparad data) kommer ut. Programmeringsspråket, webbramverket och databasen är inte oberoende val—de är tre delar av samma resa.
Föreställ dig att en kund uppdaterar sin leveransadress.
/account/address). Validering kontrollerar att indata är kompletta och rimliga.När dessa tre stämmer överens flyter en förfrågan smidigt. När de inte gör det får du friktion: klumpig dataåtkomst, läckande validering och subtila konsistensbuggar.
De flesta “stack”-debatter börjar med språk- eller databasmärke. En bättre utgångspunkt är din datamodell—eftersom den tyst dikterar vad som kommer kännas naturligt (eller smärtsamt) överallt annars: validering, frågor, API:er, migrationer och till och med teamets arbetsflöde.
Applikationer jonglerar vanligtvis fyra former samtidigt:
En bra passform är när du slipper översätta mellan former hela dagarna. Om din kärndata är mycket sammankopplad (users ↔ orders ↔ products) kan rader och joins hålla logiken enkel. Om din data mest är “en blob per entitet” med varierande fält kan dokument minska ceremonin—tills du behöver tvär-entitetsrapportering.
När databasen har ett starkt schema kan många regler leva nära datan: typer, begränsningar, foreign keys, unikhet. Det minskar ofta duplicerade kontroller över tjänster.
Med flexibla strukturer flyttas regler upp i applikationen: valideringskod, versionerade payloads, backfills och noggrann läslogik (“om fält finns, då…”). Det kan fungera väl när produktkrav ändras veckovis, men ökar bördan för ramverket och testningen.
Din modell avgör om din kod mest är:
Det påverkar i sin tur språk- och ramverksbehov: stark typning kan förhindra subtil drift i JSON-fält, medan mogna migrationsverktyg är viktigare när scheman utvecklas ofta.
Välj modellen först; det “rätta” ramverket och databasalternativet blir ofta tydligare efter det.
Transaktioner är de “allt-eller-inget”-garantier din app tyst förlitar sig på. När ett köp lyckas förväntar du dig att orderposten, betalningsstatusen och lageruppdateringen antingen alla sker—eller inga sker. Utan den garantin får du de svåraste buggarna: sällsynta, dyra och svåra att reproducera.
En transaktion grupperar flera databasoperationer till en enda arbetsenhet. Om något misslyckas mitt i (valideringsfel, timeout, kraschat process) kan databasen rulla tillbaka till ett tidigare säkert tillstånd.
Detta är viktigt bortom pengar: kontoskapande (user-rad + profilrad), publicering av innehåll (post + tags + sökindexpekare), eller vilket arbetsflöde som helst som berör mer än en tabell.
Konsistens betyder “läsningar matchar verkligheten.” Snabbhet betyder “returnera något snabbt.” Många system gör avvägningar här:
Ett vanligt felmönster är att välja eventual consistency och sedan koda som om systemet var starkt konsistent.
Ramverk och ORM:er startar inte automatiskt transaktioner bara för att du kallade flera “save”-metoder. Vissa kräver explicita transaktionsblock; andra startar en transaktion per förfrågan, vilket kan dölja prestandaproblem.
Retries är också kluriga: ORM:er kan göra omförsök vid deadlocks eller tillfälliga fel, men din kod måste vara säker att köra två gånger.
Partiella skrivningar händer när du uppdaterar A och sedan misslyckas innan B uppdateras. Dubbla åtgärder uppstår när en förfrågan görs om efter timeout—särskilt om du debiterar ett kort eller skickar ett mail innan transaktionen har committats.
En enkel regel hjälper: gör sidoeffekter (mail, webhooks) efter databascommit, och gör åtgärder idempotenta genom unika begränsningar eller idempotensnycklar.
Detta är “översättningslagret” mellan applikationskoden och databasen. Valen här påverkar ofta vardagen mer än själva databasmärket.
En ORM (Object-Relational Mapper) låter dig behandla tabeller som objekt: skapa en User, uppdatera en Post, och ORM:en genererar SQL bakom kulisserna. Det kan vara produktivt eftersom det standardiserar vanliga uppgifter och döljer repetitivt arbete.
En query builder är mer explicit: du bygger en SQL-liknande fråga i kod (kedjor eller funktioner). Du tänker fortfarande i “joins, filters, groups”, men får parametrarsäkerhet och komposabilitet.
Ren SQL är att skriva själva SQL:en själv. Det är mest direkt och ofta tydligast för komplexa rapportfrågor—på bekostnad av mer manuellt arbete och konventioner.
Språk med stark typning (TypeScript, Kotlin, Rust) tenderar att driva mot verktyg som kan validera frågor och resultatformar tidigt. Det minskar runtime-överraskningar, men pressar också team att centralisera dataåtkomst så typer inte glider isär.
Språk med flexibel metaprogrammering (Ruby, Python) gör ofta att ORM:er känns naturliga och snabba att iterera med—tills dolda frågor eller implicit beteende blir svårt att förstå.
Migrationer är versionsstyrda ändringsskript för ditt schema: lägg till en kolumn, skapa ett index, backfilla data. Målet är enkelt: vem som helst ska kunna deploya appen och få samma databasstruktur. Behandla migrationer som kod du granskar, testar och rullar tillbaka vid behov.
ORM:er kan tyst generera N+1-frågor, hämta stora rader du inte behöver, eller göra joins klumpiga. Query builders kan bli oläsliga “kedjor”. Ren SQL kan dupliceras och bli inkonsekvent.
En bra regel: använd det enklaste verktyget som håller avsikten uppenbar—och för kritiska vägar, inspektera SQL:en som faktiskt körs.
Folk skyller ofta på “databasen” när en sida känns långsam. Men synlig latens är summan av flera små väntetider över hela förfrågningsvägen.
En enda förfrågan betalar vanligtvis för:
Även om din databas kan svara på 5 ms, blir en app som gör 20 frågor per förfrågan, blockerar på I/O och spenderar 30 ms på att serialisera ett stort svar fortfarande trög.
Att öppna en ny databasanslutning är dyrt och kan överväldiga databasen under belastning. En anslutningspool återanvänder befintliga anslutningar så förfrågningar inte betalar den kostnaden varje gång.
Men: rätt poolstorlek beror på din runtime-modell. En högkonkurrerande async-server kan skapa massiv samtidig efterfrågan; utan poolgränser får du köbildning, timeouts och bullriga fel. Med för snäva poolgränser blir appen själv flaskhalsen.
Caching kan ligga i webbläsaren, en CDN, en in-process-cache eller en delad cache (som Redis). Det hjälper när många förfrågningar behöver samma resultat.
Men caching räddar inte:
Din programmeringsspråks runtime formar genomströmningen. Tråd-per-förfrågan-modeller kan slösa resurser medan de väntar på I/O; async-modeller kan öka samtidigheten, men gör också backpressure (som poolbegränsningar) nödvändigt. Därför är prestandatuning ett stack-beslut, inte ett databasbeslut.
Säkerhet är inte något du “lägger till” med ett ramverksplugin eller en databasinställning. Det är en överenskommelse mellan språk/runtime, webbramverk och databas om vad som måste vara sant—även när en utvecklare gör fel eller en ny endpoint läggs till.
Autentisering (vem är detta?) brukar leva vid ramverkets kant: sessions, JWTs, OAuth-callbacks, middleware. Auktorisering (vad får de göra?) måste upprätthållas konsekvent i både applikationslogik och databasregler.
Ett vanligt mönster: appen bestämmer intent (“användaren får redigera det här projektet”), och databasen försvarar gränser (tenant IDs, ägarskapsbegränsningar och—där det passar—radnivåpolicies). Om auktorisering bara finns i controllers kan bakgrundsjobb och interna skript av misstag kringgå den.
Ramverksvalidering ger snabb återkoppling och tydliga felmeddelanden. Databasbegränsningar ger ett slutgiltigt säkerhetsnät.
Använd båda när det spelar roll:
Det minskar “omöjliga tillstånd” som annars uppstår när två förfrågningar tävlar eller en ny tjänst skriver data annorlunda.
Hemligheter bör hanteras av runtime och deploy-workflow (env-vars, secret managers), inte hårdkodas i kod eller migrationer. Kryptering kan ske i appen (fält-kryptering) och/eller i databasen (at-rest-kryptering, KMS), men du behöver klarhet i vem som roterar nycklar och hur återställning fungerar.
Revision är också delat ansvar: appen bör emitera meningsfulla events; databasen bör hålla immutabla loggar där det passar (t.ex. append-only audit-tabeller med begränsad åtkomst).
Att överlåta för mycket till applikationslogik är klassiskt: saknade begränsningar, tysta nulls, “admin”-flagor utan kontroller. Åtgärden är enkel: anta att buggar kommer hända och designa stacken så databasen kan neka osäkra skrivningar—även från er egen kod.
Skalning misslyckas sällan för att “databasen inte klarar det.” Den misslyckas för att hela stacken reagerar dåligt när belastningens form förändras: en endpoint blir populär, en fråga blir het, ett arbetsflöde börjar försöka om.
De flesta team stöter på samma tidiga flaskhalsar:
Om du kan reagera snabbt beror på hur väl ditt ramverk och databasverktyg exponerar frågeplaner, migrationer, connection pooling och säkra cache-mönster.
Vanliga skalningssteg brukar komma i denna ordning:
En skalbar stack behöver förstaklass-stöd för bakgrundsuppgifter, schemaläggning och säkra omförsök.
Om ditt jobbsystem inte kan upprätthålla idempotency (samma jobb körs två gånger utan dubbeldebitering eller dubbelutskick) kommer du att “skala” in i datakorruption. Tidiga val—som att förlita sig på implicita transaktioner, svaga unikhetsbegränsningar eller ogenomskinliga ORM-beteenden—kan blockera införandet av köer, outbox-mönster eller ungefär-exakt-en-gång-arbetsflöden senare.
Tidigt samspel lönar sig: välj en databas som matchar dina konsistensbehov och ett ramverks-ekosystem som gör nästa skalsteg (replicering, köer, partitionering) till en stödd väg snarare än en omskrivning.
En stack känns “lätt” när utveckling och drift delar samma antaganden: hur du startar appen, hur data förändras, hur tester körs och hur du tar reda på vad som hände när något går fel. Om dessa bitar inte stämmer slösar team tid på limkod, sköra skript och manuella runbooks.
Snabb lokal setup är en funktion. Föredra ett arbetsflöde där en ny kollega kan clone:a, installera, köra migrationer och ha realistiska testdata på minuter—inte timmar.
Det betyder ofta:
Om ramverkets migrationsverktyg kämpar med ditt databasval blir varje schemaändring ett litet projekt.
Din stack bör göra det naturligt att skriva:
Ett vanligt fel: team lutar sig mot enbart unit tester för att integrationstester är långsamma eller svåra att sätta upp. Det är ofta ett stack-/ops-mismatch—testdatabasprovisionering, migrationer och fixtures är inte strömlinjeformade.
När latens skjuter i höjden måste du följa en förfrågan genom ramverket och in i databasen.
Sikta på konsekventa strukturerade logs, grundläggande metrics (förfrågningstakt, fel, DB-tid) och traces som inkluderar frågetider. Även ett enkelt korrelations-ID som finns i app- och databasloggar kan förvandla “gissning” till “hitta”.
Drift är inte separerat från utveckling; det är dess fortsättning.
Välj verktyg som stöder:
Om du inte kan öva att återställa eller köra migrationer lokalt kommer du inte göra det väl under press.
Att välja en stack handlar mindre om att plocka “bästa” verktyg och mer om att välja verktyg som fungerar tillsammans under dina verkliga begränsningar. Använd denna checklista för att tvinga fram tidig samsyn.
Tidsboxa till 2–5 dagar. Bygg en tunn vertikal snutt: ett kärnarbetsflöde, ett bakgrundsjobb, en rapportliknande fråga och grundläggande auth. Mät utvecklarfriktion, migrations-ergonomi, frågeklarhet och hur lätt det är att testa.
Om du vill snabba på det här steget kan ett vibe-coding-verktyg som Koder.ai vara användbart för att snabbt generera en fungerande vertikal snutt (UI, API och databas) från en chatbaserad specifikation—sedan iterera med snapshots/rollback och exportera källkoden när du är redo att binda dig.
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Även starka team hamnar i stack-mismatch—val som ser bra ut isolerat men skapar friktion när systemet byggs. Goda nyheter: de flesta är förutsägbara och undvikbara med några kontroller.
Ett klassiskt dofttecken är att välja en databas eller ett ramverk för att det är trendigt medan din verkliga datamodell fortfarande är oklar. Ett annat är prematur skalning: optimera för miljoner användare innan ni kan hantera hundratals, vilket ofta leder till mer infrastruktur och fler felmoder.
Se också upp för stackar där teamet inte kan förklara varför varje huvudkomponent finns. Om svaret mest är “alla använder det” ackumulerar du risk.
Många problem visar sig i skarvarna:
Detta är inte “databasproblem” eller “ramverksproblem”—det är systemproblem.
Föredra färre rörliga delar och en tydlig väg för vanliga uppgifter: en migrationsmetod, en frågestil för de flesta funktioner och konsekventa konventioner över tjänster. Om ramverket uppmuntrar ett mönster (request-livscykel, dependency injection, job-pipeline), luta er mot det istället för att blanda stilar.
Återbesök val när ni ser återkommande produktionsincidenter, bestående utvecklarfriktion eller när nya produktkrav fundamentalt förändrar åtkomstmönstren.
Byt säkert genom att isolera skarven: inför en adapter-layer, migrera inkrementellt (dual-write eller backfill vid behov) och bevisa paritet med automatiska tester innan ni skickar om trafiken.
Att välja ett programmeringsspråk, ett webbramverk och en databas är inte tre oberoende beslut—det är ett systemdesignbeslut uttryckt på tre ställen. Det “bästa” alternativet är den kombination som stämmer med din datamodell, dina konsistensbehov, teamets arbetsflöde och hur du förväntar dig att produkten växer.
Skriv ner orsakerna bakom era val: förväntade trafikmönster, accepterbar latenstid, regler för datalagring, felmoder ni kan tolerera och vad ni explicit inte optimerar för just nu. Det gör avvägningar synliga, hjälper nya kollegor förstå “varför” och förhindrar oavsiktlig arkitekturdrift när krav förändras.
Gå igenom er nuvarande setup med checklistan och notera var val inte stämmer överens (t.ex. ett schema som strider mot ORM, eller ett ramverk som gör bakgrundsarbete besvärligt).
Om ni utforskar en ny riktning kan verktyg som Koder.ai hjälpa er jämföra stackantaganden snabbt genom att generera en basapplikation (vanligtvis React för webben, Go-tjänster med PostgreSQL och Flutter för mobil) som ni kan inspektera, exportera och vidareutveckla—utan att binda er till en lång byggcykel i förväg.
För djupare uppföljning: bläddra i relaterade guider på /blog, sök implementationdetaljer i /docs eller jämför support- och driftsalternativ på /pricing.
Behandla dem som en enda pipeline för varje förfrågan: ramverk → kod (språk) → databas → svar. Om en del uppmuntrar mönster som de andra kämpar emot (t.ex. schema-lös lagring + tung rapportering) spenderar du tid på limkod, duplicerade regler och svårfelsökta konsistensproblem.
Börja med din kärndatamodell och de operationer ni kommer göra oftast:
När modellen är tydlig blir de naturliga valen av databas och ramverk oftast uppenbara.
Om databasen har ett starkt schema kan många regler ligga nära datan:
NOT NULL, unikhetCHECK-begränsningar för giltiga intervall/tillståndMed flexibla strukturer flyttar fler regler upp i applikationen (validering, versionerade payloads, backfills). Det kan snabba på tidig iteration men ökar testbördan och risken för drift mellan tjänster.
Använd transaktioner när flera skrivningar måste lyckas eller misslyckas tillsammans (t.ex. order + betalningsstatus + lagerändring). Utan transaktioner riskerar du:
Gör även sidoeffekter (e-post/webhooks) efter commit och gör operationer idempotenta (säkra att köra om).
Välj det enklaste verktyget som gör avsikten tydlig:
För kritiska endpoints: inspektera alltid den SQL som faktiskt körs.
Håll schema och kod synkroniserade med migrationer som behandlas som produktionskod:
Om migrationer är manuella eller bristfälliga glider miljöer isär och deploys blir riskfyllda.
Profilera hela förfrågningsvägen, inte bara databasen:
En databas som svarar på 5 ms hjälper inte om appen gör 20 frågor eller blockeras på I/O.
Använd en anslutningspool för att undvika att betala anslutningskostnaden per förfrågan och för att skydda databasen under belastning.
Praktiska riktlinjer:
Felaktigt dimensionerade pooler visar sig ofta som timeouts och bullriga fel vid trafiktoppar.
Använd båda lagren:
NOT NULL, CHECK)Detta förhindrar “omöjliga tillstånd” när förfrågningar tävlar, bakgrundsjobb skriver data eller en ny endpoint glömmer en kontroll.
Tidsboxa en liten proof of concept (2–5 dagar) som testar de verkliga skarvarna:
Skriv sedan en enkel en-sida beslutslogg så framtida förändringar blir avsiktliga (se relaterade guider i /docs och /blog).