23 apr. 2025·8 min
Hur vektordatabaser möjliggör semantisk sökning för AI‑appar
Lär dig hur vektordatabaser lagrar inbäddningar, utför snabba likhetssökningar och stöder semantisk sökning, RAG‑chatbotar, rekommendationer och andra AI‑appar.
Vad semantisk sökning betyder (utan jargong)
Semantisk sökning fokuserar på vad du menar, inte bara de exakta orden du skriver.
Om du någonsin sökt efter något och tänkt "svaret är klart här—varför hittar den det inte?", så har du stött på gränserna för nyckelordsökning. Traditionell sökning matchar termer. Det fungerar när formuleringen i din fråga och innehållet överlappar.
Varför nyckelordsökning ofta missar poängen
Nyckelordsökning har svårt med:
- Synonymer och formuleringar: “cancel” vs “close” vs “terminate” en prenumeration.
- Intention: “how do I stop being billed?” handlar egentligen om att avsluta en prenumeration.
- Kontekst: “apple charger” (märke) vs “apple tree charger” (nonsens, men du förstår poängen).
Den kan också överskatta upprepade ord och returnera resultat som ser relevanta ut på ytan, medan sidan som faktiskt svarar på frågan med andra ord hamnar lägre.
Ett enkelt exempel
Föreställ dig ett help‑center med en artikel med titeln “Pause or cancel your subscription.” En användare söker:
"stop my payments next month"
Ett nyckelordssystem kanske inte placerar den artikeln högt om den inte innehåller "stop" eller "payments". Semantisk sökning är utformad för att förstå att "stop my payments" är nära besläktat med "cancel subscription" och lyfta upp den artikeln—eftersom betydelsen stämmer överens.
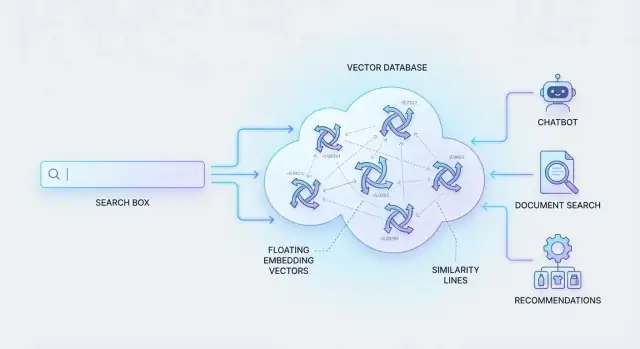
Var vektordatabaser kommer in
För att få det att fungera representerar system innehåll och frågor som "menings‑fingeravtryck" (tal som fångar likhet). Sedan måste de kunna söka bland miljoner sådana fingeravtryck snabbt.
Det är vad vektordatabaser är byggda för: att lagra dessa numeriska representationer och hämta de mest liknande matcherna effektivt, så att semantisk sökning känns omedelbar även i stor skala.
Inbäddningar: att omvandla innehåll till meningsfulla vektorer
En inbäddning är en numerisk representation av betydelse. Istället för att beskriva ett dokument med nyckelord representerar du det som en lista med siffror (en "vektor") som fångar vad innehållet handlar om. Två innehåll som betyder liknande saker får vektorer som ligger nära varandra i det numeriska rummet.
Hur en inbäddning faktiskt ser ut
Tänk på en inbäddning som en koordinat på en mycket högdimensionell karta. Du kommer vanligtvis inte läsa siffrorna direkt—de är inte avsedda att vara mänskligt vänliga. Deras värde ligger i hur de beter sig: om "cancel my subscription" och "how do I stop my plan?" ger vektorer som ligger nära varandra, kan systemet behandla dem som relaterade även när de delar få (eller inga) ord.
Text, bilder och ljud kan alla bli vektorer
Inbäddningar är inte begränsade till text.
- Textinbäddningar representerar mening i meningar, stycken, supportärenden, produktbeskrivningar med mera.
- Imagebäddningar representerar visuell likhet och koncept (t.ex. “röda löparskor”).
- Audiobäddningar kan representera talare, ton eller betydelsen av talad text när de paras med talmodeller.
Detta är hur en enda vektordatabas kan stödja “sök med bild”, “hitta liknande låtar” eller “rekommendera produkter som denna”.
Genererade av modeller—inte skrivna för hand
Vektorer skapas inte genom manuella taggar. De produceras av maskininlärningsmodeller som tränats för att komprimera betydelse till siffror. Du skickar innehåll till en embeddings‑modell (hostad av dig eller en leverantör), och den returnerar en vektor. Din applikation lagrar den vektorn tillsammans med originalinnehållet och metadata.
Varför val av inbäddning påverkar kvalitet och kostnad
Den inbäddningsmodell du väljer påverkar resultaten mycket. Större eller mer specialiserade modeller förbättrar ofta relevansen men kostar mer (och kan vara långsammare). Mindre modeller kan vara billigare och snabbare, men kan missa nyanser—särskilt för branschspecifikt språk, flera språk eller korta frågor. Många team testar några modeller tidigt för att hitta bästa kompromissen innan de skalar.
Hur vektordatabaser lagrar data
En vektordatabas bygger på en enkel idé: lagra “mening” (en vektor) tillsammans med informationen du behöver för att identifiera, filtrera och visa resultat.
Den grundläggande datamodellen
De flesta poster ser ut så här:
- ID: ett unikt identifierare du kontrollerar (t.ex.
doc_18492eller en UUID) - Vektor (inbäddning): en array med tal som representerar innehållets betydelse
- Metadata: nyckel–värde‑fält som title, URL, tags, author, language, created_at, eller tenant_id
Till exempel kan en help‑center‑artikel lagra:
- ID:
kb_123 - Vektor: 768 flyttal (för en vanlig embedding‑modell)
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
Vektorn är vad som driver semantisk likhet. ID och metadata gör resultaten användbara.
Varför metadata spelar roll (mer än man tror)
Metadata gör två saker:
- Filtrering före/efter vektorsök: “Visa bara resultat från produkt X”, “Endast engelska”, “Endast dokument användaren har åtkomst till” eller “Endast objekt nyare än 90 dagar.” Detta är avgörande för relevans och åtkomstkontroll.
- Visning och åtgärder: När du visar ett resultat vill inte användaren ha en vektor—de vill ha en titel, ett utdrag och en länk (URL). Metadata ger de detaljer som UI behöver.
Utan bra metadata kan du hämta rätt mening men ändå visa fel kontext.
Vanliga vektorstorlekar och lagringskonsekvenser
Storleken på inbäddningen beror på modellen: 384, 768, 1024 och 1536 dimensioner är vanliga. Fler dimensioner kan fånga mer nyans, men ökar också:
- Lagring (varje post lagrar fler tal)
- Minnesbelastning för snabb sökning
- Indexbyggtid (särskilt med ANN‑indexering)
Som tumregel: att dubblera dimensioner ökar ofta kostnad och latens om du inte kompenserar med indexval eller kompression.
Uppdateringsmönster: insättningar, ändringar och raderingar
Riktiga dataset förändras, så vektordatabaser brukar stödja:
- Insert: lägg till nytt innehåll med dess inbäddning och metadata
- Update: ändra metadata (t.ex. tags) eller ersätt vektorn om innehållet ändrats
- Delete: ta bort föråldrat eller återkallat innehåll
- Re‑embed: beräkna om vektorer när du byter modell, ändrar chunkning eller redigerar text
Att planera för uppdateringar tidigt förhindrar ett "stale knowledge"‑problem där sökningen returnerar innehåll som inte längre stämmer.
Likhetssök: hitta "närmast betydelse" snabbt
När din text, bilder eller produkter har blivit inbäddade (vektorer) blir sökning ett geometriskt problem: "Vilka vektorer är närmast denna frågavektor?" Detta kallas närmsta‑grannar‑sökning. Istället för att matcha nyckelord jämför systemet mening genom att mäta hur nära två vektorer är.
Närmsta grannar på enkelt språk
Föreställ dig varje innehåll som en punkt i ett enormt flerdimensionellt rum. När en användare söker omvandlas frågan till en annan punkt. Likhetssök returnerar de objekt vars punkter ligger närmast—dina "närmsta grannar." De grannar som hittas delar sannolikt intention, ämne eller kontext, även om de inte delar exakta ord.
Vanliga likhetsmått
Vektordatabaser stöder ofta några standardmetoder för att mäta "närhet":
- Cosine similarity: jämför vinkeln mellan vektorer (bra när riktning/betydelse är viktigare än magnitud).
- Dot product: besläktat med cosinus men påverkas också av vektorlängd; används ofta med normaliserade inbäddningar.
- Euclidean distance: rak linje mellan punkter (användbart i vissa modeller och domäner).
Olika modeller tränas med en viss metrik i åtanke, så använd den modellen rekommenderar.
Exact search vs approximativ (ANN)
En exact sökning jämför varje vektor för att hitta de verkliga närmaste grannarna. Det kan vara korrekt, men blir långsamt och dyrt vid miljontals objekt.
De flesta system använder approximate nearest neighbor (ANN) sökning. ANN använder smarta indexstrukturer för att begränsa sökningen till de mest lovande kandidaterna. Du får vanligtvis resultat som är "tillräckligt nära" de verkligt bästa matcherna—mycket snabbare.
Latens vs recall‑avvägningen
ANN är populärt eftersom du kan justera enligt dina behov:
- Lägre latens (snabbare svar) genom att söka färre kandidater.
- Högre recall (hitta fler av de verkligt bästa matcherna) genom att söka fler.
Denna justerbarhet är anledningen till att vektorsök fungerar bra i verkliga appar: du kan hålla svarsnivån snabb samtidigt som du returnerar relevanta resultat.
Det semantiska sökflödet end‑to‑end
Semantisk sökning är enklast att förstå som en enkel pipeline: du omvandlar text till mening, letar upp liknande meningar, och presenterar de mest användbara matcherna.
1) Embedda frågan
En användare skriver en fråga (t.ex. “How do I cancel my plan without losing data?”). Systemet kör den texten genom en embedding‑modell och producerar en vektor—en array siffror som representerar frågans mening snarare än dess exakta ord.
2) Sök i vektordatabasen
Denna frågavektor skickas till vektordatabasen, som utför likhetssök för att hitta de "närmast" liggande vektorerna bland ditt lagrade innehåll.
De flesta system returnerar top‑K matchningar: de K mest lika chunkarna/dokumenten.
- Varför K är konfigurerbart: ett mindre K är snabbare och ofta tillräckligt (t.ex. K=5).
- Ett större K ökar recall (du är mindre benägen att missa rätt svar), men kan inkludera fler "nära‑men‑fel" resultat (t.ex. K=50).
3) (Valfritt) Omsortera för precision
Likhetssök optimeras för hastighet, så initiala top‑K kan innehålla nära‑missar. En reranker är en andra modell som tittar på frågan och varje kandidat tillsammans och omordnar dem efter relevans.
Tänk så här: vektorsökning ger en stark kortlista; rerankern plockar ut bästa ordningen.
4) Returnera resultat (eller mata downstream)
Slutligen returnerar du de bästa matcherna till användaren (som sökresultat), eller skickar dem vidare till en AI‑assistent (t.ex. ett RAG‑system) som den "grundande" kontexten.
Om du bygger detta i en app kan plattformar som Koder.ai hjälpa dig prototypa snabbt: du beskriver den semantiska sök‑ eller RAG‑upplevelsen i ett chattgränssnitt och itererar på React‑frontend och Go/PostgreSQL‑backend medan du håller återhämtningspipen (embed → vektorsök → valfri rerank → svar) som en första‑klass del av produkten.
Ett snabbt "nyckelord vs semantik"‑exempel
Om din help‑artikel säger “terminate subscription” och användaren söker “cancel my plan”, kan keyword‑sök missa den eftersom “cancel” och “terminate” inte matchar.
Semantisk sökning kommer normalt att hämta den eftersom inbäddningen fångar att båda fraserna uttrycker samma intention. Lägg till reranking så blir toppresultaten inte bara "liknande", utan direkt användbara för användarens fråga.
Hybrid‑sök och metadatafilter för bättre resultat
Lansera bättre supportsökning
Förvandla ditt help‑center‑innehåll till en sökupplevelse med filter och omrankning.
Ren vektorsök är fantastisk på "betydelse", men användare söker inte alltid efter betydelse. Ibland behöver de en exakt matchning: ett personnamn, ett SKU, ett fakturanummer eller en felkod från en logg. Hybrid‑sök löser detta genom att kombinera semantiska signaler (vektorer) med lexikala signaler (traditionell nyckelordsök som BM25).
Vad "hybrid‑sök" faktiskt gör
En hybridfråga kör typiskt två sökvägar parallellt:
- Vektorsök: hittar konceptuellt liknande innehåll även om ordalydelsen skiljer sig.
- Keyword/BM25‑sök: hittar innehåll som delar samma token och belönar exakta termer och ovanliga ord.
Systemet slår sedan ihop kandidatresultaten till en rankad lista.
När hybrid är bättre som default
Hybrid‑sök fungerar särskilt bra när din data innehåller "måste‑matcha" strängar:
- Produktnamn med specifika modifierare (t.ex. "Pro Max", "Gen 2")
- ID:n (ordernummer, ticket‑ID, artikelnummer)
- Felkoder ("E0421", "ORA‑00933") och kommandoflaggor
- Sällsynta domäntermer där synonymer är riskabla
Semantisk sökning ensam kan returnera brett relaterade sidor; keyword‑sök ensam kan missa relevanta svar som är omformulerade. Hybrid täcker båda fallgroparna.
Använda metadatafilter för att begränsa sökutrymmet
Metadatafilter begränsar återvinningen före rankning (eller parallellt), vilket förbättrar relevans och hastighet. Vanliga filter inkluderar:
- Språk (returnera endast engelska dokument)
- Datumintervall (senaste policyn, senaste release notes)
- Kategori eller källa (docs vs tickets; "billing" vs "security")
- Åtkomsttaggar (endast det användaren får se)
Hur poängsättning fungerar (högnivå)
De flesta system använder en praktisk blandning: kör båda söktyperna, normalisera poäng så de blir jämförbara, och applicera vikter (t.ex. "lita mer på nyckelord för ID:n"). Vissa produkter rerankar också den sammanslagna kortlistan med en lättviktsmodell eller regler, medan filter säkerställer att du rankar rätt delmängd från början.
RAG: använda vektordatabaser för att grunda LLM‑svar
Retrieval‑Augmented Generation (RAG) är ett praktiskt mönster för att få mer tillförlitliga svar från en LLM: hämta först relevant information, generera sen ett svar som är bundet till det hämtade innehållet.
RAG‑idén i en mening
Istället för att be modellen "kom ihåg" era företagsdokument, lagrar du de dokumenten (som inbäddningar) i en vektordatabas, hämtar de mest relevanta chunkarna vid frågetillfället och skickar dem in i LLM:en som stödjande kontext.
Varför en vektordatabas hjälper till att minska hallucinationer
LLM:er är utmärkta på att formulera text, men de fyller gärna i luckor när de saknar fakta. En vektordatabas gör det enkelt att hämta närmast‑betydelse passager från din kunskapsbas och förse prompten med dem.
Denna grundning får modellen att gå från "hitta på ett svar" till "sammanfatta och förklara dessa källor." Det gör också svaren lättare att granska eftersom du kan spåra vilka chunkar som hämtades och visa citat.
Chunkningens grunder (så att återvinning faktiskt fungerar)
RAG‑kvaliteten beror ofta mer på chunkningen än på modellen.
- Chunk‑storlek: Sikta på chunkar som innehåller en fullständig tanke (ofta en kort sektion). För små tappar kontext; för stora drar in brus.
- Överlappning: Lägg till liten överlappning så viktiga detaljer vid gränser inte splittras bort.
- Behåll kontext: Spara titlar, rubriker och identifierare (doknamn, sektion, datum) som metadata så att resultaten blir begripliga och filtrerbara.
En enkel RAG‑pipeline (beskrivning)
Föreställ dig detta flöde:
Användarfråga → Embedda fråga → VektorDB hämtar top‑k chunkar (+ valfria metadatafilter) → Bygg prompt med hämtade chunkar → LLM genererar svar → Returnera svar (och källor).
Vektordatabasen sitter i mitten som ett "snabbt minne" som levererar den mest relevanta evidensen för varje förfrågan.
Vanliga AI‑användningsfall som drivs av vektordatabaser
Planera pipelinen först
Karta över ingestion, uppdelning och uppdateringar innan du skriver en rad kod.
Vektordatabaser gör inte bara sökning "smartare"—de möjliggör produktupplevelser där användare kan beskriva vad de vill ha i naturligt språk och ändå få relevanta resultat. Nedan några praktiska användningsfall som återkommer.
Kundsupport: hitta svar bortom nyckelord
Supportteam har ofta en kunskapsbas, gamla tickets, chattloggar och release notes—men nyckelordsök kämpar med synonymer, parafraser och vaga problemformuleringar.
Med semantisk sökning kan en agent (eller chatbot) hämta tidigare tickets som betyder samma sak även om formuleringen skiljer sig. Det snabbar upp lösningen, minskar duplicerat arbete och hjälper nya agenter att komma in fortare. Kombinera vektorsök med metadatafilter (produktlinje, språk, ärendetyp, datumintervall) för att hålla resultaten fokuserade.
Produktupptäckt: sök kataloger som människor pratar
Shoppare känner sällan exakta produktnamn. De söker efter intentioner som "liten ryggsäck som rymmer en laptop och ser professionell ut." Inbäddningar fångar dessa preferenser—stil, funktion, begränsningar—så resultaten känns mer som en mänsklig säljare.
Detta fungerar för detaljhandel, reselistor, fastighetsannonser, jobbtavlor och marknadsplatser. Du kan även blanda semantisk relevans med strukturerade begränsningar som pris, storlek, tillgänglighet eller plats.
Rekommendationer: “liknande artiklar” och innehållsupptäckt
En klassisk funktion är "hitta saker som detta." Om en användare tittar på en produkt, läser en artikel eller ser en video kan du hämta annat innehåll med liknande betydelse eller attribut—även när kategorierna inte överensstämmer perfekt.
Det är användbart för:
- "Mer som detta"‑moduler
- Relaterade artiklar och knowledge base‑förslag
- Duplicate eller near‑duplicate‑detektion (moderation eller städning)
Intern sökning med behörigheter: policyer, dokument, mötesanteckningar
Inom företag är information utspridd i dokument, wikis, PDF:er och mötesanteckningar. Semantisk sökning hjälper anställda att ställa naturliga frågor ("Vad är vår ersättningspolicy för konferenser?") och hitta rätt källa.
Det icke förhandlingsbara är åtkomstkontroll. Resultat måste respektera behörigheter—vanligtvis genom att filtrera på team, dokumentägare, konfidentialitetsnivå eller en ACL‑lista—så användare bara hämtar det de får se.
Om du vill ta det längre är samma återvinningslager det som driver grundade Q&A‑system (se RAG‑sektionen).
Datapipelines: ingestion, chunkning och uppdateringar
Ett semantiskt söksystem är bara så bra som pipelinen som matar det. Om dokument anländer inkonsekvent, chunkas dåligt eller aldrig re‑embeddas efter redigering, glider resultaten ifrån vad användare förväntar sig.
Ett enkelt ingest‑flöde (som fungerar)
De flesta team följer en repeterbar sekvens:
- Samla data (dokument, PDF:er, tickets, chattloggar, wiki‑sidor, produktdata).
- Rensa (ta bort boilerplate, fixa enkodning, normalisera whitespace, extrahera huvudtext).
- Chunka (dela i korta passager användare faktiskt vill återfinna).
- Embedda (generera vektorer med vald modell).
- Upsert (skriv vektorer + metadata till vektordatabasen, ersätt vid behov).
"Chunk"‑steget är där många pipelines vinner eller förlorar. Chunkar som är för stora späds ut i mening; för små tappar kontext. Ett praktiskt tillvägagångssätt är att chunka efter naturlig struktur (rubriker, stycken, Q&A‑par) och behålla liten överlappning för kontinuitet.
Hålla inbäddningar uppdaterade
Innehåll ändras ständigt—policyer uppdateras, priser ändras, artiklar skrivs om. Behandla inbäddningar som härledda data som måste regenereras.
Vanliga taktiker:
- Spara ett source document ID, chunk ID och en content hash. Om hashen ändras, re‑embedda den chunk som ändrats.
- Använd soft deletes (markera gamla chunkar inaktiva) för att undvika spökresultat.
- Bygg om selektivt istället för att re‑embedda allt.
Batch vs streaming‑uppdateringar
- Batch passar stora backfills, nattliga synkar och förutsägbart innehåll (dokumentation, knowledge bases).
- Streaming passar snabbt föränderliga källor (supporttickets, användargenererat innehåll, inventarier). Det minskar föråldring men kräver mer övervakning och kostnadskontroll.
Flera språk och flera modeller
Om du tjänar flera språk kan du använda en multilingual embedding‑modell (enklare) eller per‑språk‑modeller (ibland högre kvalitet). Versionera dina inbäddningar (t.ex. embedding_model=v3) så du kan göra A/B‑tester och backa utan att bryta sökningen.
Hur man utvärderar kvalitet och prestanda
Semantisk sökning kan kännas "bra" i en demo men ändå misslyckas i produktion. Skillnaden är mätning: du behöver tydliga relevansmått och hastighetsmål, utvärderade på frågor som liknar verkliga användare.
Relevansmått som speglar användartillfredsställelse
Börja med en liten uppsättning mått och håll fast vid dem över tid:
- Precision / Recall: Precision visar hur många returnerade resultat som verkligen är relevanta; recall visar hur många relevanta objekt du lyckades hämta. Använd när du har en tydlig definition av "relevant".
- MRR (Mean Reciprocal Rank): Bra när användare förväntar sig ett enkelt "bästa" svar. Belönar att rätt dokument ligger högt.
- nDCG: Användbart när flera resultat kan vara relevanta i olika grad (mycket relevant vs något relevant).
- Latens (p50/p95): Följ både median och tail‑latens. Ett snabbt p50 men ett långsamt p95 känns fortfarande segt för användare.
Bygg ett testsätt du kan lita på
Skapa en utvärderingsuppsättning från:
- Verkliga frågor från sökloggar eller supporttickets (anonymiserade).
- Förväntade dokument (gold labels) överenskomna av ämnesexperter.
- Edge cases: korta frågor ("refund"), långa frågor, tvetydiga termer, sällsynta produktnamn och "no‑result"‑frågor där korrekt beteende är att säga "inga träffar".
Versionera testsättet så du kan jämföra över releaser.
A/B‑testning och feedbackloopar
Offline‑mått fångar inte allt. Kör A/B‑tester och samla lätta signaler:
- Tumme upp/ner på resultat
- Klickfrekvens och tid på sida
- "Finslipa sökning"‑händelser
Använd denna feedback för att uppdatera relevansdomar och hitta felmönster.
Övervaka drift över tid
Prestanda kan förändras när:
- Du byter inbäddningsmodell eller ändrar chunkningslogik.
- Ditt korpus skiftar (nya produkter, policyändringar, säsongsbetonade termer).
Kör om testsuiten efter varje förändring, övervaka mått veckovis och sätt larm för plötsliga droppar i MRR/nDCG eller toppar i p95‑latens.
Säkerhet, integritet och åtkomstkontroll
Få källkoden
Behåll full kontroll med export av källkod när du är redo att gå bortom prototyper.
Vektorsök ändrar hur data hämtas, men det ska inte ändra vem som får se den. Om ditt semantiska sök‑ eller RAG‑system kan "hitta" rätt chunk, kan det också av misstag returnera chunkar användaren inte är auktoriserad att se—om du inte designar behörigheter och sekretess in i återvinningssteget.
Åtkomstkontroll: verkställ vid hämtning
Den säkraste regeln är enkel: en användare ska bara kunna hämta innehåll de får läsa. Lita inte på appen att "dölja" resultat efter att vektordatabasen returnerat dem—då har innehållet redan lämnat din lagringsgräns.
Praktiska angreppssätt inkluderar:
- Per‑dokument (eller per‑chunk) ACL:er: lagra behörighetsfält tillsammans med varje vektor så varje fråga kan verkställa dem.
- Tenant‑isolation: för multi‑tenant appar, separera data per tenant (logiska partitioner, namespaces eller separata index) för att undvika korsläckage.
Metadatafilter för behörigheter
Många vektordatabaser stödjer metadata‑filter (t.ex. tenant_id, department, project_id, visibility) som körs tillsammans med likhetssökningen. Använd rätt fungerar detta bra för att applicera behörigheter under hämtningen.
En viktig detalj: se till att filtret är obligatoriskt och server‑side, inte valfri klientlogik. Var också försiktig med "role explosion" (för många kombinationer). Om din behörighetsmodell är komplex, överväg att förberäkna "effektiva accessgrupper" eller använda en dedikerad authorization‑tjänst för att skapa query‑tid filter‑token.
PII och känslig data: bestäm vad som aldrig ska embedda
Inbäddningar kan koda betydelse från originaltexten. Det avslöjar inte automatiskt rå PII, men det kan öka risk (t.ex. känsliga fakta som blir lättare att återfinna).
Riktlinjer som fungerar bra:
- Undvik att embedda mycket känsliga fält (personnummer, betalningsdetaljer, medicinska identifierare) när det är möjligt.
- Redigera innan embedding om texten måste vara sökbar (ersätt exakta värden med platshållare).
- Lagra original separat och återta dem först efter behörighetskontroller.
Operationella behov: backups, retention och revision
Behandla ditt vektorindex som produktionsdata:
- Backup och återställning: index kan vara dyra att bygga om; planera snapshots eller en återuppbyggnadsväg från källdata.
- Retention policies: radera vektorer när källdokument går ut eller användare begär borttagning.
- Revisionsloggning: logga vem som frågade vad (åtminstone frågekontekst och returnerade dokument‑ID:n) för att stödja utredningar och efterlevnad.
Görs rätt känns semantisk sökning magisk för användare—utan att bli en säkerhetsöverraskning senare.
Fallgropar, kostnader och en praktisk checklista för val
Vektordatabaser kan kännas "plug‑and‑play", men de flesta besvikelser kommer från omgivande val: hur du chunkar data, vilken inbäddningsmodell du väljer och hur tillförlitligt du håller allt uppdaterat.
Vanliga felkällor (och hur se dem)
Dålig chunkning är den största orsaken till irrelevanta resultat. Chunkar som är för stora späds ut; för små tappar kontext. Om användare ofta säger "den hittade rätt dokument men fel passage" behöver du justera chunkningen.
Fel inbäddningsmodell visar sig som konsekvent semantisk mismatch—resultaten är flytande men off‑topic. Det händer när modellen inte passar din domän (juridik, medicin, supporttickets) eller din innehållstyp (tabeller, kod, flerspråkig text).
Gamla data skapar snabbt förtroendeproblem: användare söker senaste policyn men får förra kvartalets version. Om din källdata ändras måste inbäddningar och metadata också uppdateras (och raderingar måste verkligen ta bort data).
Cold‑start och hantering av tomma resultat
I början kan du ha för lite innehåll, för få frågor eller för lite feedback för att ställa in återvinningen. Planera för:
- Fallbacks: nyckelordsök eller kuraterade "toppsvar" när semantiska resultat är svaga.
- UX för tomt resultat: visa relaterade kategorier, ställ förtydligande frågor eller vidga filter.
- Uppvärmningsfrågor: test med en liten uppsättning representativa frågor före lansering.
Kostnadsdrivare att budgetera för
Kostnader kommer oftast från fyra håll:
- Embedding‑beräkning (engångs‑backfill + löpande uppdateringar)
- Lagring (vektorer, metadata och index)
- Frågevolym (reads, nätverk, samtidighet)
- Reranking (valfritt men kraftfullt; kan lägga till modellkostnad per fråga)
Om du jämför leverantörer, be om en enkel månatlig uppskattning baserad på ditt dokumentantal, genomsnittlig chunkstorlek och peak QPS. Många överraskningar dyker upp efter indexering och under trafiktoppar.
En praktisk checklista för val av vektordatabas
Använd denna korta checklista för att välja en lösning som passar:
- Sök‑kvalitet: Stöder den hybrid‑sök (nyckelord + vektorer) och metadatafilter? Kan du lägga till reranking?
- Prestanda: ANN‑indexalternativ, förutsägbar latens vid peak och enkel skalning.
- Data‑operationer: Upserts, deletes, re‑indexering, versionering och backfills utan driftstopp.
- Observability: Sökloggar, recall/latens‑mått och verktyg för att felsöka "varför detta resultat".
- Säkerhet: Kryptering, tenant‑isolation, rollbaserad åtkomst och filter‑per‑behörighetmönster.
- Integration: SDK:er, supportspråk och connectors för din lagring (S3, databaser, docs).
- Total kostnad: Transparent prissättning för lagring, skrivningar, läsningar och eventuell hanterad beräkning.
Att välja rätt handlar mindre om att jaga den senaste index‑typen och mer om tillförlitlighet: kan du hålla data färsk, kontrollera åtkomst och bibehålla kvalitet när ditt innehåll och din trafik växer?
Vanliga frågor
Vad är semantisk sökning, enkelt uttryckt?
Keyword‑sökning matchar exakta token. Semantisk sökning matchar betydelse genom att jämföra inbäddningar (vektorer), så den kan returnera relevanta resultat även när frågan formuleras annorlunda (t.ex. “stoppa betalningar” → “avsluta prenumeration”).
Vad gör en vektordatabas egentligen i ett semantiskt söksystem?
En vektordatabas lagrar inbäddningar (talserier) tillsammans med ID och metadata, och utför snabba närmsta‑grannar‑uppslag för att hitta poster med närmast liknande betydelse som en fråga. Den är optimerad för likhetssökning i stor skala (ofta miljontals vektorer).
Vad är en inbäddning, och varför är den viktig?
En inbäddning är ett modellgenererat numeriskt “fingeravtryck” av innehåll. Du tolkar inte siffrorna direkt; du använder dem för att mäta likhet.
I praktiken:
- Konvertera dokument (eller chunkar) till inbäddningar
- Konvertera användarens fråga till en inbäddning
- Hämta de mest liknande inbäddningarna som resultat
Vilka data bör jag lagra för varje objekt i en vektordatabas?
De flesta poster innehåller:
- (du kontrollerar det)
Varför är metadata så viktigt för relevans och säkerhet?
Metadata möjliggör två kritiska funktioner:
- Filtrering: begränsa resultat till rätt del (språk, produkt, datumintervall, behörigheter)
- Presentation: visa titel/utdrag/länk istället för bara ett internt ID
Utan metadata kan du få rätt betydelse men visa fel kontext eller läcka begränsat innehåll.
Vilken likhetsmetrik bör jag använda (cosine, dot product, Euclidean)?
Vanliga alternativ:
- Cosinuslikhet (jämför vinkeln mellan vektorer; bra när riktning/betydelse är viktigare än magnitud)
- Dot‑product (besläktat med cosinus; påverkas även av vektorns längd)
- Euklidiskt avstånd (rak linje mellan punkter)
Använd gärna den metrik som inbäddningsmodellen tränades för; fel metrik kan märkbart försämra rangordningen.
Vad är skillnaden mellan exact search och ANN (approximate) search?
Exact search jämför en fråga mot alla vektorer, vilket blir långsamt och dyrt i stor skala. ANN (approximate nearest neighbor) använder index för att söka i ett mindre kandidatset.
Handeln du kan göra:
- Snabbare svar (lägre latens)
- Bättre täckning av de verkligt bästa matcherna (högre recall)
När bör jag använda hybrid‑sök istället för ren vektorsök?
Hybrid‑sök kombinerar:
- Vektorsök för betydelse och parafraser
- Keyword/BM25‑sök för exakta token (ID:n, felkoder, SKU:er)
Det är ofta bästa standardvalet när ditt material innehåller “måste‑matcha”‑strängar och naturligt språkfrågor.
Hur stödjer en vektordatabas RAG för LLM‑appar?
RAG (Retrieval‑Augmented Generation) hämtar relevanta chunkar från din kunskapsbas och ger dem som kontext till en LLM.
Ett typiskt flöde:
- Embedda användarfrågan
- Hämta top‑K chunkar från vektorDB (med metadatafilter)
- Bygg prompt med de hämtade chunkarna
- LLM genererar ett svar som är förankrat i källorna
Vilka är de vanligaste fallgroparna när man bygger semantisk sökning med vektordatabaser?
Tre vanliga fallgropar:
- Dålig chunkning: för stora chunkar ger brus; för små tappar kontext
- Gamla inbäddningar: innehåll uppdateras utan att re‑embeddas → föråldrade resultat
- Ingen permission‑filtrering vid hämtning: kan returnera begränsade chunkar innan appen hinner dölja dem
Motåtgärder: chunkning efter struktur, versionera inbäddningar och tvinga server‑side metadatafilter (t.ex. , ACL‑fält).