02 dec. 2025·8 min
Infrastrukturabstraktion i Mitchell Hashimotos era
Infrastrukturabstraktion formar moderna verktygsval. Lär dig hur du väljer opinionerade lager som snabbar upp leveransen utan att förlora operativ insyn.
Infrastrukturabstraktion formar moderna verktygsval. Lär dig hur du väljer opinionerade lager som snabbar upp leveransen utan att förlora operativ insyn.
De flesta team saktar inte ner för att de inte kan skriva kod. De saktar ner eftersom varje produktteam i slutändan återuppfinner samma infrastrukturbeslut: hur man deployar, var konfiguration bor, hur hemligheter hanteras, och vad som räknas som klart för loggning, backup och rollback.
I början känns det säkert att bygga om grunderna. Du förstår varje ratt eftersom du själv skruvat på den. Efter några releaser visar sig kostnaden som väntan: väntan på granskningar för boilerplate-ändringar, väntan på någon som “kan Terraform”, väntan på den enda personen som kan debugga en ostadig deploy.
Det skapar den välkända avvägningen: gå snabbare med en abstraktion, eller behåll full kontroll och fortsätt betala priset för att göra allt för hand. Rädslan är inte ologisk. Ett verktyg kan dölja för mycket. När något bryter kl. 02:00 är “plattformen hanterar det” inte en plan.
Denna spänning spelar störst roll för team som både bygger och driver det de skickar ut. Om du är på call behöver du snabbhet, men du behöver också en mental modell av hur systemet fungerar. Om du inte driver produkten känns dolda detaljer som någon annans problem. För de flesta moderna dev-team är det fortfarande ert problem.
Ett användbart mål är enkelt: ta bort arbete, inte ansvar. Du vill ha färre upprepade beslut, men du vill inte mysterier.
Team hamnar i detta hörn av samma tryck: relecycler blir tajtare medan operativa förväntningar förblir höga; team växer och “tribal knowledge” slutar skala; compliance- och datakrav lägger till steg du inte kan hoppa över; och incidenter gör mer ont eftersom användare förväntar sig alltid-på-tjänster.
Mitchell Hashimoto är mest känd för att ha byggt verktyg som gjorde infrastrukturen programmerbar för vardagsteam. Den användbara lärdomen är inte vem som byggde vad. Det är vad denna stil av verktyg förändrade: den uppmuntrade team att beskriva det resultat de vill ha och låta mjukvara hantera det repetitiva arbetet.
I enkla termer är det abstraktionseran. Mer av leveransen sker genom verktyg som kodifierar standarder och bästa praxis, och mindre sker genom engångsklick i konsolen eller ad hoc-kommandon. Du rör dig snabbare eftersom verktyget gör en rörig kedja av steg till en upprepbar väg.
Molnplattformar gav alla kraftfulla byggstenar: nätverk, load balancers, databaser, identitet. Det borde ha förenklat. I praktiken flyttade komplexiteten ofta upp i stacken. Team fick fler tjänster att koppla ihop, fler behörigheter att hantera, fler miljöer att hålla konsistenta och fler sätt för små skillnader att bli till driftavbrott.
Opinionerade verktyg svarade genom att definiera en “standardform” för infrastruktur och leverans. Där börjar infrastrukturabstraktion spela roll. Den tar bort mycket oavsiktligt arbete, men den bestämmer också vad du inte behöver tänka på i vardagen.
Ett praktiskt sätt att utvärdera detta är att fråga vad verktyget försöker göra tråkigt. Bra svar inkluderar ofta förutsägbar uppsättning över dev, staging och prod; mindre beroende av tribal knowledge och handskrivna runbooks; och rollbacks och återuppbyggnader som känns rutinmässiga istället för heroiska. När det görs rätt skiftar granskningar också bort från “klickade du rätt?” till “är det här rätt ändring?”.
Målet är inte att dölja verkligheten. Det är att paketera de upprepbara delarna så att folk kan fokusera på produktarbete samtidigt som de förstår vad som händer när pagern går igång.
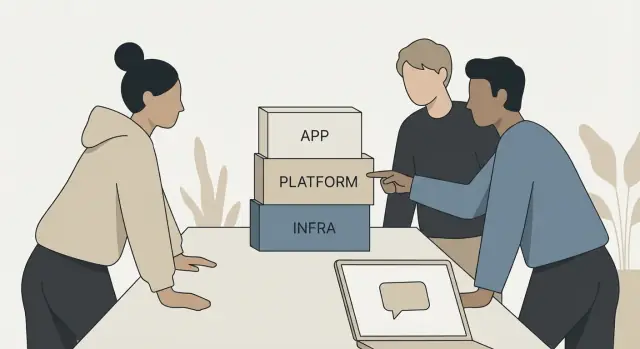
En infrastrukturabstraktion är en genväg som förvandlar många små steg till en enklare handling. Istället för att komma ihåg hur man bygger en image, pushar den, kör en databasmigration, uppdaterar en tjänst och kontrollerar hälsan, kör du ett kommando eller trycker på en knapp och verktyget gör sekvensen.
Ett enkelt exempel är att “deploy” blir en enda åtgärd. Under ytan händer fortfarande mycket: paketering, konfiguration, nätverksregler, databasåtkomst, övervakning och rollback-planer. Abstraktionen ger dig bara ett handtag att dra i.
De flesta moderna abstraktioner är också opinionerade. Det betyder att de kommer med standarder och ett föredraget arbetssätt. Verktyget kan bestämma hur din app är uppbyggd, hur miljöer namnges, var hemligheter lagras, vad en “tjänst” är och vad en “säker deploy” ser ut som. Du får hastighet för att du slutar fatta dussintals små beslut varje gång.
Denna hastighet har en dold kostnad när standardvärlden inte matchar din verkliga värld. Kanske behöver ert företag datalokalitet i ett visst land, striktare revisionsloggar, ovanliga trafikmönster eller en databasuppsättning som inte är vanlig. Opinionerade verktyg kan kännas fantastiska—tills dagen kommer då ni måste färglägga utanför linjerna.
Bra infrastrukturabstraktion minskar beslut, inte konsekvenser. Den ska spara dig från rutinarbete, samtidigt som den gör viktiga fakta lätta att se och verifiera. I praktiken betyder “bra” oftast: den snabba vägen fungerar, men ni har fortfarande undantagsmöjligheter; ni kan se vad som kommer ändras innan det ändras (planer, diffs, förhandsgranskningar); fel förblir läsbara (tydliga loggar, felmeddelanden, enkel rollback); och ägarskap förblir uppenbart (vem kan deploya, vem godkänner, vem är på call).
Ett sätt detta dyker upp i verkliga team är att använda en högre-nivåplattform som Koder.ai för att skapa och deploya en app via chat, med hosting, snapshots och rollback tillgängligt. Det kan ta bort flera dagars uppsättning. Men teamet bör fortfarande veta var appen körs, var loggar och mätvärden finns, vad som händer under en migration och hur man återhämtar sig om en deploy går fel. Abstraktionen ska göra dessa svar lättare att nå, inte svårare att hitta.
De flesta team försöker leverera mer med färre personer. De stödjer fler miljöer (dev, staging, prod och ibland per-branch previews), fler tjänster och fler integrationer. Samtidigt blir release-cyklerna kortare. Opinionerade verktyg känns lättnad eftersom de förvandlar en lång lista beslut till ett litet antal standardval.
Onboarding är en stor lockelse. När arbetsflöden är konsekventa behöver en nyanställd inte lära sig fem olika sätt att skapa en tjänst, sätta hemligheter, köra migrationer och deploya. De kan följa samma väg som alla andra och bidra snabbare. Den konsistensen minskar också problemet med tribal knowledge, där bara en person minns hur build eller deployment egentligen fungerar.
Standardisering är nästa uppenbara vinst. När det finns färre sätt att göra samma sak får ni färre engångsskript, färre specialfall och färre undvikbara misstag. Team tar ofta till sig abstraktioner av denna anledning: inte för att dölja verkligheten, utan för att paketera det tråkiga i upprepbara mönster.
Upprepbarhet hjälper även med compliance och tillförlitlighet. Om varje tjänst skapas med samma bas (loggning, backup, minst-behörighet, alerts) blir interna granskningar enklare och incidenthantering snabbare. Ni kan också svara “vad ändrades och när?” eftersom förändringar flyter genom samma väg.
Ett praktiskt exempel är ett litet team som väljer ett verktyg som genererar en standard React-frontend och Go-backend, upprätthåller konventioner för miljövariabler och erbjuder snapshots och rollback. Det tar inte bort operativt arbete, men det tar bort gissningsarbete och gör “rätt sätt” till standard.
Abstraktioner är fantastiska—tills något går sönder kl. 02:00. Då är det enda som betyder något om den som är på call kan se vad systemet gör och säkert ändra rätt ratt. Om en abstraktion snabbar upp leverans men blockerar diagnos, byter du snabbhet mot återkommande driftstörningar.
Några saker måste förbli synliga, även med opinionerade standarder:
Insyn betyder också att du snabbt kan svara grundläggande frågor: vilken version körs, vilken konfiguration gäller, vad ändrades sedan igår, och var arbetsbelastningen körs. Om abstraktionen gömmer dessa detaljer bakom en UI utan revisionsspår blir on-call gissningsarbete.
Den andra nödvändigheten är en escape hatch. Opinionerade verktyg behöver ett säkert sätt att överstyra standarder när verkligheten inte matchar den snälla vägen. Det kan innebära att justera timeouts, ändra resursgränser, låsa en version, köra ett enstaka migrationsjobb eller rulla tillbaka utan att vänta på ett annat team. Escape hatches bör vara dokumenterade, permissionerade och reversibla—inte hemliga kommandon kända av en person.
Ägarskap är sista linjen. När team antar en abstraktion, bestäm i förväg vem som ansvarar för utfallen, inte bara användningen. Du undviker jobbig oklarhet senare om du kan svara: vem bär pagern när tjänsten fallerar, vem kan ändra abstraktionsinställningar och hur granskas ändringar, vem godkänner undantag, vem underhåller mallar och standarder, och vem undersöker incidenter och slutför åtgärder.
Om ni använder en högre-nivåplattform, inklusive något som Koder.ai för att snabbt skicka appar, håll den till samma standard: exportbar kod och konfig, tydlig runtime-information och tillräcklig observability för att debugga produktion utan att vänta på en grindvakt. Så håller abstraktioner sig hjälpsamma utan att bli en svart låda.
Att välja ett abstraktionslager handlar mindre om vad som ser modernt ut och mer om vilken smärta du vill ta bort. Om du inte kan namnge smärtan i en mening kommer du sannolikt sluta med ännu ett verktyg att underhålla.
Börja med att skriva ner den exakta flaskhalsen du försöker fixa. Gör den specifik och mätbar: releaser tar tre dagar eftersom miljöer är manuella; incidenter spikar eftersom konfiguration driver isär; molnkostnaden är oförutsägbar. Det håller samtalet grundat när demo börjar se glänsande ut.
Lås sedan era icke-förhandlingsbara krav. Dessa inkluderar oftast var data får ligga, vad ni måste logga för revision, uppetidsförväntningar och vad ert team realistiskt kan hantera kl. 02:00. Abstraktioner fungerar bäst när de matchar verkliga begränsningar, inte aspirativa sådana.
Utvärdera sedan abstraktionen som ett kontrakt, inte ett löfte. Fråga vad ni ger (inputs), vad ni får tillbaka (outputs) och vad som händer när saker går fel. Ett bra kontrakt gör fel tråkiga.
Ett enkelt sätt att göra detta:
Ett konkret exempel: ett team som bygger en liten webbapp kan välja en opinionerad väg som genererar en React-frontend och en Go-backend med PostgreSQL, men fortfarande kräva tydlig åtkomst till loggar, migrationer och deploy-historik. Om abstraktionen döljer schemändringar eller gör rollback gissningsarbete är den riskfylld även om den levererar snabbt.
Var också strikt med ägarskap. Abstraktionen ska minska upprepade jobb, inte skapa en ny svart låda som bara en person förstår. Om er on-call-ingenjör inte kan svara “Vad ändrades?” och “Hur rullar vi tillbaka?” inom några minuter är lagret för ogenomskinligt.
Ett fempersoners team behöver en kundportal: en React-webb-UI, ett litet API och en PostgreSQL-databas. Målet är enkelt: leverera på veckor, inte månader, och hålla on-call-smärtan rimlig.
De överväger två vägar.
De sätter upp moln-nätverk, en container-runtime, CI/CD, hemligheter, loggning och backup. Det är inget “fel” med denna väg, men den första månaden försvinner i beslut och limning. Varje miljö blir lite olika eftersom någon “bara tweakat” för att få staging att fungera.
När kodgranskningen sker är halva diskussionen om deploy-YAML och behörigheter, inte portalen själv. Den första produktionsdeployen fungerar, men teamet äger nu en lång checklista för varje ändring.
Istället väljer de ett opinionerat arbetsflöde där plattformen ger ett standardiserat sätt att bygga, deploya och köra appen. Till exempel använder de Koder.ai för att generera webappen, API:t och databasuppsättningen från chatten, och förlitar sig på dess distribution och hosting-funktioner, anpassade domäner samt snapshots och rollback.
Vad som går bra är omedelbart:
Några veckor senare visar sig avvägningarna. Kostnader är mindre uppenbara eftersom teamet inte designade fakturan rad för rad. De når också begränsningar: ett bakgrundsjobb behöver särskild tuning och plattformens standarder är inte perfekta för deras arbetsbelastning.
Under en incident blir portalen långsammare. Teamet kan se att något är fel, men inte varför. Är det databasen, API:t eller en upstream-tjänst? Abstraktionen hjälpte dem att leverera, men den suddade ut detaljerna de behövde när de var på call.
De åtgärdar detta utan att överge plattformen. De lägger till ett litet antal dashboards för förfrågningsfrekvens, fel, latens och databasens hälsa. De skriver ner de få godkända överstyrningarna de får ändra (timeouts, instansstorlekar, connection pool-gränser). De sätter också tydligt ägarskap: produktteamet äger appbeteendet, en person äger plattformsinställningarna, och alla vet var incidentanteckningar finns.
Resultatet är en hälsosam mittväg: snabbare leverans plus tillräcklig operativ insyn för att hålla sig lugn när saker går fel.
Opinionerade verktyg kan kännas som lättnad: färre beslut, färre rörliga delar, snabbare starter. Problemet är att samma räcken som hjälper er att röra er snabbt också kan skapa blinda fläckar om ni inte kontrollerar vad verktyget antar om er värld.
Några fallgropar som återkommer:
Popularitet är särskilt vilseledande. Ett verktyg kan vara perfekt för ett företag med ett dedikerat plattforms-team, men smärtsamt för ett litet team som bara behöver förutsägbara deploys och tydliga loggar. Fråga vad ni måste stödja, inte vad andra pratar om.
Att skippa runbooks är ett annat vanligt fel. Även om er plattform automatiserar builds och deploys blir någon fortfarande uppringd. Skriv ner grunderna: var kollar man hälsa, vad gör man när deployer hänger, hur roterar man hemligheter, och vem kan godkänna en produktionsändring.
Rollback förtjänar extra uppmärksamhet. Team antar ofta att rollback betyder “gå tillbaka en version”. I verkligheten misslyckas rollback när databas-schemat ändrats eller när bakgrundsjobb fortsätter skriva ny data. Ett enkelt scenario: en webbapp-deploy inkluderar en migration som tar bort en kolumn. Deployen kraschar, du rullar tillbaka koden, men den gamla koden förväntar sig den saknade kolumnen. Ni är nere tills ni reparerar datan.
För att undvika luddigt ägarskap, kom överens om gränser tidigt. Att namnge en ägare per område räcker oftast:
Lämna inte data och compliance till slutet. Om ni måste köra arbetsbelastningar i specifika länder eller möta regler för datatransfer, kontrollera om ert verktyg stöder regionsval, revisionsspår och åtkomstkontroller från dag ett. Verktyg som Koder.ai tar ofta upp detta tidigt genom att låta team välja var appar körs, men ni måste fortfarande bekräfta att det matchar era kunder och avtal.
Innan ni satsar ett team på en abstraktion, gör ett snabbt “commit test”. Poängen är inte att bevisa att verktyget är perfekt. Det är att försäkra att abstraktionen inte förvandlar rutinmässig drift till ett mysterium när något går sönder.
Be någon som inte var med i utvärderingen att gå igenom svaren. Om de inte kan göra det köper ni sannolikt snabbhet idag och förvirring senare.
Om ni använder en hostad plattform, mappa dessa frågor till konkreta kapabiliteter. Till exempel gör källkodsexport, snapshots och rollback samt tydliga distributions- och hostingkontroller det lättare att återhämta sig snabbt och minska lock-in om behoven ändras.
Att anta en infrastrukturabstraktion fungerar bäst när det känns som en liten uppgradering, inte en omskrivning. Välj en snäv arbetsdel, lär er vad verktyget döljer, och expandera först efter att teamet sett det bete sig under verklig press.
En lättvikts-adoptionsplan som håller er ärliga:
Gör framgång mätbar. Spåra några siffror före och efter så samtalet förblir grundat: tid till första deploy för en ny medarbetare, tid att återhämta sig från en trasig release, och hur många manuella steg som krävs för en rutinändring. Om verktyget gör leverans snabbare men återhämtningen långsammare bör den avvägningen vara tydlig.
Skapa en enkel “abstraction README” och håll den nära koden. En sida räcker. Den ska säga vad abstraktionen gör, vad den döljer och var man tittar när något går sönder (var loggar finns, hur genererad konfig ser ut, hur hemligheter injiceras och hur man reproducerar deploy lokalt). Målet är inte att lära ut varje detalj. Det är att göra felsökning förutsägbar kl. 02:00.
Om ni vill röra er snabbt utan att ge upp ägarskap kan verktyg som genererar och kör riktiga projekt vara en praktisk bro. Till exempel låter Koder.ai (koder.ai) ett team protypa och skicka appar via chat, med planning-läge, distributioner, snapshots och rollback, plus export av källkod så ni kan behålla kontroll och flytta vidare senare om ni vill.
En praktisk nästa åtgärd: välj ett arbetsflöde att standardisera den här månaden (deploy av en webbapp, köra migrationer eller skapa preview-miljöer), skriv abstraction-README för det och kom överens om två mätvärden ni granskar om 30 dagar.
En infrastrukturabstraktion gör många operativa steg (bygga, deploya, konfigurera, behörigheter, hälsokontroller) till ett mindre antal åtgärder med rimliga standardinställningar.
Vinsten är färre upprepade beslut. Risken är att man förlorar insyn i vad som faktiskt ändrades och hur man återställer när något går sönder.
För att upprepade arbete: miljöer, hemligheter, deploy-pipelines, loggning, backup och rollback.
Även om du kan koda snabbt, saktar leverans ner när varje release kräver att samma operativa pussel löses om eller när ni väntar på den enda personen som kan de “speciella” skripten.
Huvudfördelen är snabbhet genom standardisering: färre val, färre engångsskript och mer upprepbara deployment-flöden.
Det förbättrar också onboarding, eftersom nya ingenjörer följer ett konsekvent arbetsflöde istället för att behöva lära sig olika processer per tjänst.
Välj inte efter popularitet. Börja med en mening: Vilket problem tar vi bort?
Sedan validerar du:
Om du är on-call måste du snabbt kunna svara:
Om ett verktyg gör de svaren svåra att hitta är det för ogenomskinligt för produktion.
Sökbara loggar med tydliga tidsstämplar
Om du inte på några minuter kan avgöra “är det appen, databasen eller deployen?” så lägg till insyn innan ni skalar upp.
En rollback-knapp är hjälpsam, men den är ingen magi. Rollbacks misslyckas ofta när:
Standardpraxis: designa migrationer för att vara reversibla (eller i två steg) och testa rollback under realistiska “dålig deploy”-scenarier.
En escape hatch är ett dokumenterat, permissionerat sätt att överstyra standarder utan att bryta plattformsmodellen.
Vanliga exempel:
Om överstyrningar är “hemliga kommandon” återskapar ni tribal knowledge.
Starta smått:
Skala upp först när teamet sett verktyget fungera under riktig belastning.
Koder.ai kan hjälpa team att generera och skicka riktiga appar snabbt (vanligtvis React i frontenden, Go med PostgreSQL i backenden och Flutter för mobil), med inbyggd distribution, hosting, snapshots och rollback.
För att behålla kontroll bör team fortfarande kräva: tydlig runtime-information, tillgängliga loggar/mätvärden och möjlighet att exportera källkod så systemet inte blir en svart låda.