26 dec. 2025·7 min
Interna utvecklarverktyg med Claude Code: säkra CLI-instrumentpaneler
Bygg interna utvecklarverktyg med Claude Code för att lösa loggsökning, feature toggles och datakontroller samtidigt som du upprätthåller minsta privilegier och tydliga skyddsåtgärder.
Vilket problem ditt interna verktyg egentligen bör lösa
Interna verktyg börjar ofta som en genväg: en kommando eller en sida som sparar teamet 20 minuter under en incident. Risken är att samma genväg tyst kan bli en privilegerad bakdörr om du inte definierar problemet och gränserna i förväg.
Team tar vanligtvis fram ett verktyg när samma smärta upprepas varje dag, till exempel:
- Loggsökning som är långsam, inkonsekvent eller utspridd över system
- Feature toggles som kräver en riskfylld manuell ändring eller direkt skrivning i databasen
- Datakontroller som förlitar sig på att en person kör ett skript från sin laptop
- On-call-uppgifter som är enkla, men lätta att råka göra fel på kl. 02
Dessa problem känns små tills verktyget kan läsa produktionsloggar, fråga kunddata eller växla en flagga. Då handlar det om åtkomstkontroll, revisionsspår och oavsiktliga skrivningar. Ett verktyg som är ”bara för ingenjörer” kan fortfarande orsaka ett avbrott om det kör en bred fråga, träffar fel miljö eller ändrar tillstånd utan ett tydligt bekräftelsesteg.
Definiera framgång i smala, mätbara termer: snabbare operationer utan att vidga behörigheterna. Ett bra internt verktyg tar bort steg, inte skydd. Istället för att ge alla bred databasåtkomst för att kontrollera ett misstänkt faktureringsproblem, bygg ett verktyg som svarar på en fråga: “Visa dagens misslyckade faktureringshändelser för konto X”, med read-only, avgränsade uppgifter.
Innan du väljer ett gränssnitt, bestäm vad människor behöver i stunden. En CLI är bra för repetitiva uppgifter under on-call. En webbpanel är bättre när resultat behöver kontext och delad synlighet. Ibland levererar du båda, men bara om de är tunna vyer över samma skyddade operationer. Målet är en väl definierad kapacitet, inte en ny administrativ yta.
Välj en smärta och håll scope litet
Det snabbaste sättet att göra ett internt verktyg användbart (och säkert) är att välja en tydlig uppgift och göra den väl. Om det försöker hantera loggar, feature flags, datafixar och användarhantering från dag ett kommer det att växa dolda beteenden och överraska folk.
Börja med en enda fråga som en användare ställer under verkligt arbete. Till exempel: “Givet ett request ID, visa mig felet och omgivande rader över tjänster.” Det är smalt, testbart och lätt att förklara.
Var tydlig med vem verktyget är för. En utvecklare som felsöker lokalt behöver andra alternativ än någon på on-call, och båda skiljer sig från support eller analys. När du blandar målgrupper hamnar du med ”kraftfulla” kommandon som de flesta användare aldrig bör röra.
Skriv ner indata och utdata som ett litet kontrakt.
Indata ska vara explicita: request ID, tidsintervall, miljö. Utdata ska vara förutsägbara: matchade rader, tjänstnamn, tidsstämpel, antal. Undvik dolda bieffekter som ”rensar också cache” eller ”försöker också jobbet igen.” Det är de funktionerna som orsakar olyckor.
Favoritera read-only. Du kan fortfarande göra verktyget värdefullt med sök, diff, validering och rapporter. Lägg till skrivhandlingar bara när du kan namnge ett verkligt scenario som behöver det och när du kan strikt avgränsa det.
Ett enkelt scope-utlåtande som håller team ärligt:
- En primär uppgift, en primär skärm eller kommando
- En datakälla (eller en logisk vy), inte ”allt”
- Explicit flagga för miljö och tidsintervall
- Read-only först, inga bakgrundsaktioner
- Om skrivningar finns, krävs bekräftelse och loggas varje ändring
Kartlägg datakällor och känsliga operationer tidigt
Innan Claude Code skriver något, skriv ner vad verktyget kommer att röra. De flesta säkerhets- och driftsäkerhetsproblem dyker upp här, inte i UI:t. Behandla denna kartläggning som ett kontrakt: det berättar för granskare vad som ingår och vad som är förbjudet.
Börja med en konkret inventering av datakällor och ägare. Till exempel: loggar (app, gateway, auth) och var de ligger; exakt vilka databastabeller eller vyer verktyget kan fråga; din feature flag-store och namngivningsregler; metrics och traces och vilka etiketter som är säkra att filtrera på; och om du planerar att skriva anteckningar till ticketing- eller incident-system.
Nämn sedan vilka operationer verktyget får utföra. Undvik ”admin” som en behörighet. Definiera istället auditerbara verb. Vanliga exempel är: read-only-sök och export (med begränsningar), annotera (lägg till en not utan att ändra historik), växla specifika flaggor med TTL, avgränsade backfills (datumintervall och antalet poster) och dry-run-lägen som visar påverkan utan att ändra data.
Känsliga fält behöver explicita rutiner. Bestäm vad som måste maskas (e-post, tokens, session IDs, API-nycklar, kundidentifierare) och vad som bara kan visas i trunkerad form. Till exempel: visa de sista 4 tecknen av ett ID, eller hasha det konsekvent så att man kan korrelera händelser utan att se råvärdet.
Till sist, kom överens om retention och audit-regler. Om en användare kör en sökning eller växlar en flagga, spela in vem som gjorde det, när, vilka filter som användes och antal resultat. Behåll audit-loggar längre än applikationsloggar. Även en enkel regel som ”sökningar sparas 30 dagar, audit-poster 1 år” förhindrar smärtsamma debatter under en incident.
Minsta privilegier-modell som hålls enkel
Minsta privilegier är enklast när du håller modellen tråkig. Lista först vad verktyget kan göra, och märk sedan varje åtgärd som read-only eller write. De flesta interna verktyg behöver bara läsbehörighet för de flesta användare.
För en webbpanel, använd ditt befintliga identitetssystem (SSO med OAuth). Undvik lokala lösenord. För en CLI, föredra kortlivade tokens som går ut snabbt och skopa dem till bara de åtgärder användaren behöver. Långlivade delade tokens tenderar att klistras in i tickets, sparas i shell-historik eller kopieras till personliga maskiner.
Håll RBAC litet. Om du behöver fler än några roller gör verktyget förmodligen för mycket. Många team klarar sig bra med tre:
- Viewer: read-only, säkra standarder
- Operator: läs + ett litet urval låg-risk-åtgärder
- Admin: hög-risk-åtgärder, används sällan
Separera miljöer tidigt, även om UI ser likadant ut. Gör det svårt att ”av misstag göra prod”. Använd olika behörigheter per miljö, olika konfigurationsfiler och olika API-endpoints. Om en användare bara supportar staging ska hen inte ens kunna autentisera mot production.
Högrisk-åtgärder förtjänar ett godkanningssteg. Tänk radering av data, ändring av feature flags, omstart av tjänster eller att köra tunga frågor. Lägg till en andra person-granskning när blast-radien är stor. Praktiska mönster inkluderar typade bekräftelser som inkluderar målet (tjänstnamn och miljö), loggning av vem som begärde och vem som godkände, och en kort fördröjning eller schemalagt fönster för de farligaste operationerna.
Om du genererar verktyget med Claude Code, gör det till en regel att varje endpoint och kommando deklarerar sin kräva-de-roll i förväg. Denna vana gör behörighetsgranskningar möjliga när verktyget växer.
Skyddsåtgärder som förhindrar misstag och dåliga frågor
Leverera en liten CLI snabbt
Prototypa ett snävt on-call-flöde och håll beteendet lätt att granska.
Det vanligaste felläget för interna verktyg är inte en angripare. Det är en trött kollega som kör ”rätt” kommando med fel indata. Behandla guardrails som produktfunktioner, inte kosmetika.
Säkerhetsstandarder
Börja med en säker inställning: read-only som standard. Även om användaren är admin bör verktyget öppna i ett läge som bara hämtar data. Gör skrivhandlingar opt-in och tydliga.
För varje operation som ändrar tillstånd (växla en flagga, backfilla data, radera en post), kräv explicit typ-till-bekräfta. ”Är du säker? y/N” är för lätt att göra av vana. Be användaren skriva om något specifikt, som miljöns namn plus mål-ID.
Strikt inputvalidering förhindrar de flesta katastrofer. Acceptera bara de format du verkligen stödjer (IDs, datum, miljöer) och avvisa allt annat tidigt. För sökningar, begränsa kraft: sätt gränser för resultat, tvinga rimliga tidsintervall och använd en allow-list-strategi istället för att låta godtyckliga mönster träffa din logg-backend.
För att undvika runaway-frågor, lägg till timeouts och rate limits. Ett säkert verktyg misslyckas snabbt och förklarar varför, istället för att hänga kvar och banka på din databas.
En guardrail-samling som fungerar i praktiken:
- Läs som standard, med en tydlig "skrivläge"-omkopplare
- Typ-till-bekräftelse för skrivningar (inkludera env + mål)
- Strikt validering för IDs, datum, begränsningar och tillåtna mönster
- Frågetimeouter plus per-användare rate limits
- Maskning av hemligheter i utdata och i verktygets egna loggar
Utdata-hygien
Anta att verktygets utdata kommer att kopieras in i tickets och chattar. Maskera hemligheter som standard (tokens, cookies, API-nycklar och e-post om det behövs). Rensa också vad du sparar: audit-loggar bör spela in vad som försöktes, inte de råa data som returnerades.
För en loggsökningspanel, returnera en kort förhandsvisning och ett antal, inte fulla payloads. Om någon verkligen behöver hela händelsen, gör det till en separat, tydligt gatad åtgärd med egen bekräftelse.
Hur man samarbetar med Claude Code utan att tappa kontrollen
Behandla Claude Code som en snabb juniorkollega: hjälpsam, men inte tankeläsare. Din uppgift är att hålla arbetet avgränsat, granskbart och lätt att ångra. Det är skillnaden mellan verktyg som känns säkra och verktyg som överraskar dig kl. 02.
Börja med en specifikation som modellen kan följa
Innan du ber om kod, skriv en liten spec som namnger användarens åtgärd och förväntat utfall. Håll den om beteende, inte ramverksdetaljer. En bra spec får oftast plats på en halvsida och täcker:
- Kommandon eller skärmar (exakta namn)
- Indata (flaggor, fält, format, begränsningar)
- Utdata (vad visas, vad sparas)
- Felscenarier (ogiltig indata, timeouts, tomma resultat)
- Behörighetskontroller (vad händer när åtkomst nekas)
Till exempel, om du bygger en loggsöknings-CLI, definiera ett kommando end-to-end: logs search --service api --since 30m --text \"timeout\", med ett hårt tak på resultat och ett klart ”ingen åtkomst”-meddelande.
Be om små inkrement du kan verifiera
Begär först ett skelett: CLI-wiring, konfigurladdning och ett stubbat datakall. Begär sedan exakt en funktion komplett (inklusive validering och felhantering). Små diffar gör granskningar verkliga.
Efter varje ändring, be om en förklaring på vanlig svenska av vad som ändrats och varför. Om förklaringen inte stämmer med diffen, stoppa och omformulera beteendet och säkerhetskraven.
Generera tester tidigt, innan du lägger till fler funktioner. Minst täck happy path, ogiltiga indata (dåliga datum, saknade flaggor), nekad behörighet, tomma resultat och rate limit eller backend-timeouts.
CLI vs webbpanel: välj rätt gränssnitt
En CLI och en intern webbpanel kan lösa samma problem, men de misslyckas på olika sätt. Välj det gränssnitt som gör den säkra vägen enklast.
En CLI är vanligtvis bäst när snabbhet spelar roll och användaren redan vet vad hen vill ha. Den passar också read-only-arbetsflöden bra, eftersom du kan hålla behörigheter snäva och undvika knappar som oavsiktligt triggar skrivhandlingar.
En CLI är ett starkt val för snabba on-call-sökningar, skript och automation, explicita revisionsspår (varje kommando stavas ut) och låg distributionskostnad (en binär, en konfig).
En webbpanel är bättre när du behöver delad synlighet eller guidade steg. Den kan minska misstag genom att styra folk mot säkra standarder som tidsintervall, miljöer och förgodkända åtgärder. Paneler fungerar också bra för team-översikter, skyddade åtgärder som kräver bekräftelse och inbyggda förklaringar av vad en knapp gör.
När det är möjligt, använd samma backend-API för båda. Lägg auth, rate limits, frågegränser och audit-logging i API:t, inte i UI:t. Då blir CLI och panel olika klienter med olika ergonomi.
Bestäm också var det körs, för det förändrar risken. En CLI på en laptop kan läcka tokens. Att köra den på en bastion-host eller i en intern kluster kan minska exponering och göra loggning och policyenforcement enklare.
Exempel: för loggsökning är en CLI bra för en on-call-ingenjör som drar de senaste 10 minuterna för en tjänst. En panel är bättre för ett delat incidentrum där alla behöver samma filtrerade vy, plus en guidad ”exportera för postmortem”-åtgärd som är behörighetskontrollerad.
Ett realistiskt exempel: loggsökningsverktyg för on-call
Iterera utan överraskningar
Håll experiment separata medan du itererar över scope, validering och säkra standardinställningar.
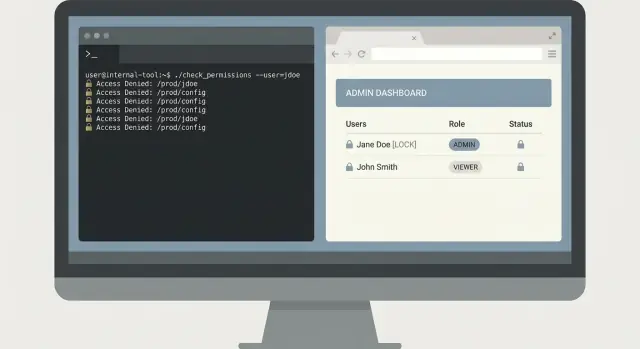
Klockan 02:10 får on-call ett meddelande: ”Klick på Betala misslyckas ibland för en kund.” Support har en skärmdump med ett request ID, men ingen vill klistra in godtyckliga frågor i ett loggsystem med admin-behörighet.
En liten CLI kan lösa detta säkert. Nyckeln är att hålla det smalt: hitta felet snabbt, visa bara vad som behövs och låt produktionsdata vara orörda.
Ett minimalt CLI-flöde
Börja med ett kommando som tvingar tidsgränser och ett specifikt identifierare. Kräv ett request ID och ett tidsfönster, och defaulta till ett kort fönster.
oncall-logs search --request-id req_123 --since 30m --until now
Returnera först en sammanfattning: tjänstnamn, felklass, antal och de tre bästa matchande meddelandena. Tillåt sedan ett explicit expand-steg som skriver ut fullständiga loggrader endast när användaren ber om det.
oncall-logs show --request-id req_123 --limit 20
Denna tvåstegsdesign förhindrar oavsiktliga datauttag. Den gör också granskningar enklare eftersom verktyget har en tydlig safe-by-default-väg.
Valfri uppföljningsåtgärd (inga skrivningar)
On-call behöver ofta lämna ett spår för nästa person. Istället för att skriva i databasen, lägg till en valfri åtgärd som skapar en ticket-note-payload eller applicerar en tagg i incident-systemet, men rör aldrig kundregister.
För minst privilegier, bör CLI:n använda en read-only loggtoken och en separat, scoped token för ticket- eller tagg-åtgärden.
Spara en audit-post för varje körning: vem körde, vilket request ID, vilka tidsgränser användes och om de expanderade detaljer. Denna audit-logg är din säkerhetsnät när något går fel eller när åtkomst behöver granskas.
Vanliga misstag som skapar säkerhets- och driftsäkerhetsproblem
Små interna verktyg börjar ofta som ”bara en snabb hjälpare.” Det är precis därför de slutar med riskfyllda standarder. Det snabbaste sättet att förlora förtroende är en dålig incident, som ett verktyg som raderar data när det var tänkt att vara read-only.
De misstag som dyker upp mest:
- Ge verktyget skrivåtkomst mot produktionsdatabasen när det bara behöver läsning, och anta ”vi kommer vara försiktiga”
- Hoppa över ett revisionsspår, så att du senare inte kan svara vem som körde ett kommando, vilka indata de använde och vad som ändrades
- Tillåta fri-form SQL, regex eller ad-hoc-filter som av misstag skannar stora tabeller eller loggar och tar ner systemen
- Blanda miljöer så att staging-åtgärder når produktion eftersom konfig, tokens eller bas-URL:er delas
- Skriva ut hemligheter till terminal, webbkonsol eller loggar och sedan glömma att dessa utskrifter kopieras till tickets och chat
Ett realistiskt fel ser ut så här: en on-call-ingenjör använder en loggsöknings-CLI under en incident. Verktyget accepterar vilken regex som helst och skickar den till logg-backenden. Ett dyrt mönster kör över timmar av högvolymsloggar, spikar kostnader och saktar sökningar för alla. I samma session skriver CLI:n ut en API-token i debug-output, och den hamnar inklistrad i ett offentligt incident-dokument.
Säkrare standarder som förhindrar de flesta incidenter
Behandla read-only som en verklig säkerhetsgräns, inte en vana. Använd separata behörigheter per miljö och separata servicekonton per verktyg.
Ett fåtal guardrails gör det mesta av jobbet:
- Använd allow-listade frågor (eller mallar) istället för rå SQL, och sätt tak för tidsintervall och rader
- Logga varje åtgärd med ett request ID, användaridentitet, målmiljö och exakta parametrar
- Kräv explicit miljöval, med en högklingande bekräftelse för produktion
- Redigera hemligheter som standard, och inaktivera debug-output om inte en privilegierad flagga används
Om verktyget inte kan göra något farligt till design, behöver teamet inte lita på perfekt uppmärksamhet under en incident kl. 03.
Snabb checklista innan du släpper verktyget
Välj panel framför skript
Skapa en React-panel med en Go-backend när en web UI är ett säkrare val.
Innan ditt interna verktyg når verkliga användare (särskilt on-call), behandla det som ett produktionssystem. Bekräfta att åtkomst, behörigheter och säkerhetsgränser är verkliga, inte underförstådda.
Börja med åtkomst och behörigheter. Många olyckor händer eftersom ”tillfällig” åtkomst blir permanent, eller eftersom ett verktyg tyst får skrivbehörighet över tid.
- Auth och offboarding: bekräfta vem som kan logga in, hur åtkomst ges och hur den återkallas samma dag någon byter team
- Roller hålls små: behåll 2–3 roller max (viewer, operator, admin) och skriv ner vad varje roll kan göra
- Read-only som standard: gör visning till standardväg och kräva en explicit roll för allt som ändrar data
- Hantering av hemligheter: lagra tokens och nycklar utanför repo och verifiera att verktyget aldrig skriver ut dem i loggar eller felmeddelanden
- Break-glass-flöde: om du behöver nödagång, gör den tidsbegränsad och loggad
Validera sedan guardrails som förhindrar vanliga misstag:
- Bekräftelser för riskfyllda åtgärder: kräva typade bekräftelser för raderingar, backfills eller config-ändringar
- Begränsningar och timeouter: sätt tak för resultatstorlek, tvinga tidsfönster och timea ut frågor så en dålig förfrågan inte kan köra för evigt
- Indatavalidering: validera IDs, datum och miljönamn; avvisa allt som ser ut som ”kör överallt”
- Audit-loggar: spela in vem gjorde vad, när och varifrån; gör loggar lätta att söka under incidenter
- Grundläggande metrics och fel: följ framgångsgrad, latens och topfeltyper så du märker avbrott tidigt
Gör ändringskontroll som för vilken tjänst som helst: peer review, ett par fokuserade tester för de farliga vägarna och en rollback-plan (inklusive ett sätt att snabbt inaktivera verktyget om det beter sig fel).
Nästa steg: rulla ut säkert och fortsätt förbättra
Behandla första releasen som ett kontrollerat experiment. Börja med ett team, ett arbetsflöde och en liten uppsättning verkliga uppgifter. Ett loggsökningsverktyg för on-call är en bra pilot eftersom du kan mäta tidsbesparing och upptäcka riskfyllda frågor snabbt.
Håll utbyggnaden förutsägbar: pilota med 3–10 användare, starta i staging, styr åtkomst med minsta privilegier-roller (inte delade tokens), sätt tydliga användningsgränser och spela in audit-loggar för varje kommando eller knappklick. Se till att du kan återställa konfigurations- och behörighetsändringar snabbt.
Skriv ner verktygets kontrakt på vanlig svenska. Lista varje kommando (eller panelåtgärd), tillåtna parametrar, vad framgång innebär och vad fel betyder. Folk slutar lita på interna verktyg när utskriften känns tvetydig, även om koden är korrekt.
Lägg till en feedback-loop som du faktiskt kontrollerar. Följ vilka frågor som är långsamma, vilka filter som är vanliga och vilka alternativ som förvirrar folk. När du ser upprepade lösningar är det oftast ett tecken på att gränssnittet saknar en säker standard.
Underhåll behöver en ägare och ett schema. Bestäm vem som uppdaterar beroenden, vem som roterar credentails och vem som blir paged om verktyget går ner under en incident. Granska AI-genererade ändringar som du skulle göra för en produktionsservice: permissions-diffar, frågesäkerhet och loggning.
Om ditt team föredrar chattdriven iteration kan Koder.ai (koder.ai) vara ett praktiskt sätt att generera en liten CLI eller panel från en konversation, behålla snapshots av kända bra tillstånd och snabbt rulla tillbaka när en ändring introducerar risk.