18 apr. 2025·8 min
Jim Gray, transaktionsbearbetning och varför ACID fortfarande spelar roll
En praktisk genomgång av Jim Grays idéer om transaktionsbearbetning och varför ACID-principerna fortfarande håller bank, handel och SaaS-system pålitliga.
En praktisk genomgång av Jim Grays idéer om transaktionsbearbetning och varför ACID-principerna fortfarande håller bank, handel och SaaS-system pålitliga.
Jim Gray var en datavetare som var besatt av en till synes enkel fråga: när många människor använder ett system samtidigt — och fel är oundvikliga — hur ser du till att resultaten blir rätt?
Hans arbete med transaktionsbearbetning hjälpte till att förvandla databaser från “ibland korrekta om du har tur” till infrastruktur du faktiskt kan bygga ett företag på. De idéer han populariserade — särskilt ACID-egenskaperna — dyker upp överallt, även om du aldrig sagt ordet “transaktion” i ett produktmöte.
Ett pålitligt system är ett där användare kan lita på utfallen, inte bara skärmarna.
Med andra ord: korrekta saldon, korrekta ordrar och inga försvunna poster.
Även moderna produkter med köer, mikrotjänster och tredjepartsbetalningar förlitar sig på transaktionstänk i nyckelögonblick.
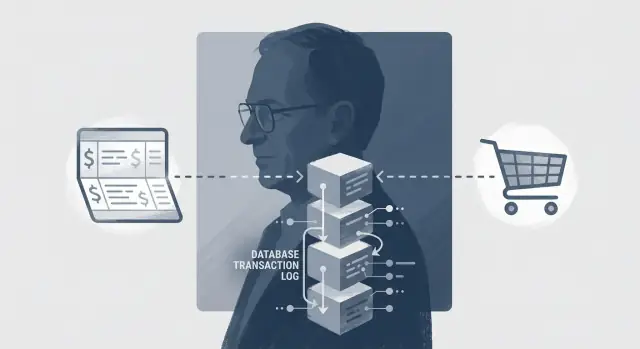
Vi håller koncepten praktiska: vad ACID skyddar, var buggar brukar gömma sig (isolation och samtidighet), och hur loggar och återställning gör fel överlevbara.
Vi täcker också moderna avvägningar — var du drar ACID-gränser, när distribuerade transaktioner är motiverade, och när mönster som sagas, retries och idempotens ger “tillräckligt bra” konsistens utan överarkitektur.
En transaktion är ett sätt att behandla en flerstegs affärsåtgärd som en enda “ja/nej”-enhet. Om allt lyckas committar du. Om något går fel rullar du tillbaka som om det aldrig hänt.
Föreställ dig att flytta 50 USD från Checkkonto till Sparkonto. Det är inte en ändring; det är minst två:
Om ditt system bara gör “enstegsuppdateringar” kan det lyckas med avdragssteget och sedan misslyckas innan insättningen sker. Nu saknar kunden 50 USD — och supportärendena börjar komma in.
Ett typiskt kassaflöde inkluderar att skapa order, reservera lager, auktorisera betalning och registrera kvitto. Varje steg rör olika tabeller (eller till och med olika tjänster). Utan transaktionstänk kan du få en order som markerats som “betald” men inget lager reserverat — eller lager reserverat för en order som aldrig skapades.
Fel sker sällan i bekväma ögonblick. Vanliga brytpunkter inkluderar:
Transaktionsbearbetning finns för att garantera ett enkelt löfte: antingen träder alla steg i affärsåtgärden i kraft tillsammans, eller så gör ingen av dem det. Det löftet är grunden för förtroende — oavsett om du flyttar pengar, lägger en order eller ändrar en prenumeration.
ACID är en checklista över skydd som gör att “en transaktion” känns pålitlig. Det är inte ett marknadsord; det är ett antal löften om vad som händer när du ändrar viktig data.
Atomicitet betyder att en transaktion antingen slutförs helt eller lämnar inga spår.
Tänk på en banköverföring: du debiterar 100 USD från konto A och krediterar 100 USD till konto B. Om systemet kraschar efter debiteringen men före krediteringen säkerställer atomicitet att hela överföringen rullas tillbaka (ingen “förlorar” pengar mitt i flytten) eller att hela överföringen slutförs. Det finns inget giltigt slutläge där bara ena sidan skett.
Konsistens betyder att dina databasregler (constraints och invariabler) håller efter varje committad transaktion.
Exempel: ett saldo kan inte gå negativt om din produkt förbjuder övertrassering; summan av debet och kredit för en överföring måste stämma; en ordertotal måste vara lika med radposter plus moms. Konsistens är delvis databasens jobb (constraints) och delvis applikationens jobb (affärsregler).
Isolation skyddar dig när flera transaktioner sker samtidigt.
Exempel: två kunder försöker köpa sista enheten av en vara. Utan korrekt isolation kan båda kassa-processerna “se” lager = 1 och båda lyckas, vilket lämnar lager på -1 eller kräver manuell korrigering.
Durability betyder att när du ser “committed” så försvinner inte resultatet efter en krasch eller strömavbrott. Om kvittot säger att överföringen lyckades måste huvudboken fortfarande visa det efter omstart.
“ACID” är inte en enkel av/på-knapp. Olika system och isoleringsnivåer ger olika garantier, och du väljer ofta vilka skydd som gäller för vilka operationer.
När folk pratar om “transaktioner” är bankexemplet tydligast: användare förväntar sig att saldon alltid är korrekta. En bankapp kan vara lite långsammare; den kan inte ha fel. Ett felaktigt saldo kan leda till övertrasseringsavgifter, uteblivna betalningar och en lång kedja av manuella åtgärder.
En enkel banköverföring är inte en enda åtgärd — det är flera som måste lyckas eller misslyckas tillsammans:
ACID-tänk ser det som en enda enhet. Om något steg misslyckas — nätverkshicka, tjänstekrasch, valideringsfel — får systemet inte “delvis lyckas”. Annars får du pengar borta från A men inte synliga på B, pengar på B utan motsvarande debet, eller inget revisionsspår för att förklara vad som hände.
I många produkter kan en liten inkonsekvens åtgärdas i nästa release. I bankvärlden blir “fixa senare” tvister, regulatorisk exponering och manuella operationer. Supportärenden ökar, ingenjörer dras in i incidentmöten och driftteam lägger timmar på att avstämma oförenliga poster.
Även om du kan korrigera siffrorna måste du fortfarande förklara historiken.
Därför förlitar sig banker på ledger och append-only-poster: istället för att skriva över historik registrerar de en sekvens av debiteringar och krediter som summerar rätt. Oföränderliga loggar och tydliga revisionsspår gör återhämtning och utredning möjliga.
Avstämning — att jämföra oberoende sanningskällor — fungerar som en sista utväg när något går fel och hjälper team att identifiera när och var en avvikelse uppstod.
Korrekthet köper förtroende. Det minskar också supportvolymen och snabbar upp felsökning: när ett problem inträffar betyder ett rent revisionsspår och konsistenta ledgerposter att du snabbt kan svara på “vad hände?” och åtgärda det utan gissningar.
E-handel känns enkel tills du når topptrafik: samma sista artikel ligger i tio varukorgar, kunder uppdaterar sidan och din betalleverantör timeoutar. Här visar sig Jim Grays transaktionsbearbetningsmentalitet i praktiska, otrendiga sätt.
Ett typiskt kassaflöde påverkar flera informationsdelar: reservera lager, skapa order och fånga betalning. Under hög samtidighet kan varje steg vara korrekt var för sig men ändå ge ett dåligt totalt resultat.
Om du minskar lagret utan isolation kan två checkouter läsa “1 kvar” och båda lyckas — hej översäljning. Om du tar betalt och sedan misslyckas med att skapa ordern har du debiterat en kund utan leverans.
ACID hjälper mest vid databasspärren: paketera ordergenerering och lagerreservation i en enda databastransaktion så att de antingen båda committar eller båda rullas tillbaka. Du kan också upprätthålla korrekthet med constraints (t.ex. “lager får inte bli negativt”) så att databasen förkastar omöjliga tillstånd även när applikationskoden beter sig fel.
Nätverk tappar svar, användare dubbelklickar och bakgrundsjobb retrys. Därför är “exactly once” svårt över systemgränser. Målet blir: högst en för pengaflöde, och säkra retries i övrigt.
Använd idempotensnycklar med din betalningsleverantör och spara ett hållbart register över “payment intent” knutet till din order. Även om tjänsten försöker igen debiteras kunden inte dubbelt.
Returer, delåterbetalningar och chargebacks är affärshändelser, inte edge cases. Tydliga transaktionsgränser gör dem enklare: du kan pålitligt länka varje justering till en order, en betalning och ett revisionsspår — så avstämning är förklarbar när något går fel.
SaaS-företag lever på ett löfte: vad kunden betalar för är vad de kan använda, omedelbart och förutsägbart. Det låter enkelt tills du blandar uppgraderingar, nedgraderingar, prorrata mitt i cykeln, återbetalningar och asynkrona betalningshändelser. ACID-tänk hjälper till att hålla “fakturerings-sanningen” och “produkt-sanningen” i linje.
En planändring triggar ofta en kedja av åtgärder: skapa eller justera en faktura, registrera proration, försöka samla in betalning, och uppdatera behörigheter (funktioner, platser, gränser). Behandla dessa som en enhet av arbete där delvis framgång är oacceptabelt.
Om en uppgraderingsfaktura skapas men behörigheterna inte uppdateras (eller tvärtom) mister kunder antingen åtkomst de betalat för eller får åtkomst de inte borde ha.
Ett praktiskt mönster är att persistera faktureringsbeslutet (ny plan, ikraftträdandedatum, prorataposter) och behörighetsbeslutet tillsammans, och sedan köra downstream-processer från den committade posten. Om betalningsbekräftelse kommer senare kan du flytta tillståndet framåt säkert utan att skriva om historiken.
I multi-tenant-system är isolation inte akademiskt: en kunds tunga aktivitet får inte blockera eller korrupta en annans. Använd tenant-scoped nycklar, tydliga transaktionsgränser per tenant och noggrant valda isoleringsnivåer så att en våg av förnyelser för Tenant A inte ger inkonsekventa läsningar för Tenant B.
Supportärenden börjar ofta med “Varför blev jag debiterad?” eller “Varför kan jag inte komma åt X?” Behåll en append-only revisionslogg över vem ändrade vad och när (användare, admin, automation) och koppla den till fakturor och behörighetstransitioner.
Det förhindrar tyst drift — där fakturor säger “Pro” men behörigheter fortfarande visar “Basic” — och gör avstämning till en fråga om att köra en fråga, inte en lång utredning.
Isolation är “I” i ACID, och det är där system ofta fallerar på subtila, dyra sätt. Kärnidén är enkel: många användare agerar samtidigt, men varje transaktion ska bete sig som om den kördes ensam.
Föreställ dig en butik med två kassörer och en sista vara på hyllan. Om båda kassörerna kontrollerar lagret samtidigt och båda ser “1 tillgänglig” kan de båda sälja den. Inget kraschar, men utfallet är fel — som en dubbelspendering.
Databaser möter samma problem när två transaktioner läser och uppdaterar samma rader samtidigt.
De flesta system väljer en isoleringsnivå som en avvägning mellan säkerhet och genomströmning:
Om ett misstag skapar finansiell förlust, rättslig exponering eller synlig inkonsekvens för kunden, luta åt starkare isolation (eller explicit låsning/constraints). Om värsta fallet är en tillfällig UI-glitch kan en svagare nivå vara acceptabel.
Högre isolation kan sänka genomströmningen eftersom databasen måste göra mer koordinering — vänta, låsa eller abortera/återförsöka transaktioner — för att förhindra osäkra inbördes ordningar. Kostnaden är verklig, men det är också kostnaden för felaktig data.
När ett system kraschar är viktigaste frågan inte “varför kraschade det?” utan “vilket tillstånd ska vi vara i efter omstart?” Jim Grays arbete gjorde svaret praktiskt: hållbarhet uppnås genom disciplinerad loggning och återställning.
En transaktionslogg (ofta kallad WAL) är en append-only-registrering av ändringar. Den är central för återställning eftersom den bevarar avsikt och ordning av uppdateringar även om databassidor är halvsparade när strömmen försvinner.
Vid omstart kan databasen:
Det är därför “vi committade det” kan förbli sant även när servern inte stängdes ner ordentligt.
Write-ahead logging betyder: loggen flushas till beständig lagring innan dataposterna får skrivas. I praktiken knyts “commit” till att relevanta loggposter är säkert på disk (eller annat hållbart medium).
Om en krasch inträffar precis efter commit kan återställning spela upp loggen och återskapa det committade tillståndet. Om kraschen inträffar före commit hjälper loggen att rulla tillbaka.
En backup är en snapshot (en punkt-i-tid-kopia). Loggar är en historia (vad som ändrats efter den snapshoten). Backuper hjälper vid katastrofal förlust (fel deploy, borttagen tabell, ransomware). Loggar hjälper dig återställa nyligen committat arbete och kan stödja point-in-time-återställning: återställ backupen och spela sedan upp loggar fram till valt ögonblick.
En backup du aldrig återställt är ett hopp, inte en plan. Schemalägg regelbundna återställningstest i en staging-miljö, verifiera dataintegritetskontroller och mät hur lång tid återställning verkligen tar. Om det inte möter dina RTO/RPO-behov, justera retention, loggshipping eller backup-frekvens innan en incident tvingar lärdomen.
ACID fungerar bäst när en databas kan vara “sanningskälla” för en transaktion. Ögonblicket du sprider en affärsåtgärd över flera tjänster (betalningar, lager, e-post, analys) går du in i distribuerade systemterritorium — där fel inte ser ut som rena “succé” eller “fel”.
I en distribuerad setup måste du anta delvisa fel: en tjänst kan committa medan en annan kraschar, eller en nätverkshicka kan dölja det verkliga utfallet. Ännu värre är att timeouts är tvetydiga — dog den andra parten, eller är den bara långsam?
Denna osäkerhet är där dubbeldebiteringar, översäljning och saknade behörigheter föds.
Two-phase commit försöker få flera databaser att committa “som ett”.
Team undviker ofta 2PC eftersom det kan vara långsamt, hålla lås längre (skada genomströmningen) och koordinatorn kan bli en flaskhals. Det binder också systemen tätt: alla deltagare måste tala protokollet och vara högtillgängliga.
Ett vanligt tillvägagångssätt är att hålla ACID-gränser småa och hantera tvärsystemarbete explicit:
Lägg de starkaste garantierna (ACID) inne i en enda databas när det är möjligt, och behandla allt bortom den gränsen som koordinering med retries, avstämning och tydligt “vad händer om det här steget misslyckas?”-beteende.
Fel ser sällan ut som rena “det hände inte”. Oftare lyckas en förfrågan delvis, klienten timeoutar och någon (webbläsare, mobilapp, jobbrunner eller partner) försöker igen.
Utan skydd skapar retries de värsta buggarna: kod som ser korrekt ut men ibland dubbeldebiterar, dubbelexpedierar eller ger dubbel åtkomst.
Idempotens är egenskapen att göra samma operation flera gånger ger samma slutresultat som att göra den en gång. För användarsystem är det “säkra retries utan dubbla effekter”.
En bra regel: GET är naturligt idempotent; många POST-åtgärder är inte det om du inte designar dem så.
Du kombinerar vanligen några mekanismer:
Idempotency-Key: ...). Servern sparar resultatet nycklat mot den värden och returnerar samma resultat vid upprepningar.order_id, en prenumeration per account_id + plan_id).Dessa fungerar bäst när unik-checken och effekten lever i samma databastransaktion.
En timeout betyder inte att transaktionen rullades tillbaka; den kan ha committat men svaret tappades. Därför måste retry-logik anta att servern kan ha lyckats.
Ett vanligt mönster är: skriv först ett idempotensregister (eller lås det), utför sidoeffekterna, markera sedan som färdig — allt inom en transaktion när det går. Om du inte kan få med allt i en transaktion (t.ex. anropa en betalgateway) persistenta en hållbar “intent” och avstäm senare.
När system “känns ostadiga” är rotorsaken ofta trasig transaktionslogik. Typiska symptom är spökorder utan motsvarande betalning, negativt lager efter samtidiga checkouter och mismatchade totaler där ledger, fakturor och analys inte stämmer överens.
Börja med att skriva ner dina invariabler — fakta som alltid måste vara sanna. Exempel: “lager sjunker aldrig under noll”, “en order är antingen obetald eller betald (inte båda)”, “varje saldoförändring har en matchande ledger-post”.
Definiera sedan transaktionsgränser kring den minsta enhet som måste vara atomisk för att skydda dessa invariabler. Om en användaråtgärd påverkar flera rader/tabeller, besluta vad som måste committa tillsammans och vad som säkert kan skjutas upp.
Slutligen välj hur du hanterar konflikter under belastning:
Samtidsbugs syns sällan i happy-path-tester. Lägg till tester som skapar press:
Du kan inte skydda det du inte mäter. Nyttiga signaler inkluderar deadlocks, väntetid på lås, rollback-frekvens (särskilt toppar efter deploys) och avstämningsdifferenser mellan sanningskällor (ledger vs saldon, orders vs betalningar). Dessa metrikervarnar ofta veckor innan kunder rapporterar “saknade” pengar eller lager.
Jim Grays bestående bidrag var inte bara en uppsättning egenskaper — det var ett gemensamt vokabulär för “vad får inte gå fel”. När team kan namnge den garanti de behöver (atomicitet, konsistens, isolation, hållbarhet) blir diskussioner om korrekthet mindre vaga (“det borde vara pålitligt”) och mer handlingsbara (“denna uppdatering måste vara atomisk med den debiteringen”).
Använd fullständiga transaktioner när en användare rimligen förväntar sig ett enda, avgörande utfall och fel är kostsamma:
Här flyttar optimering för genomströmning genom att försvaga garantier ofta kostnaden till supportärenden, manuell avstämning och förlorat förtroende.
Slappna av när temporär inkonsekvens är acceptabel och lätt att läka:
Tricket är att behålla en tydlig ACID-gräns runt “sanningskällan” och låta allt annat efterhålla sig.
Om du prototyper dessa flöden (eller bygger om en legacy-pipeline) hjälper det att börja med en stack som gör transaktioner och constraints till förstklassiga medborgare. Till exempel kan Koder.ai generera ett React-frontend plus en Go + PostgreSQL-backend från en enkel chatt, vilket är ett praktiskt sätt att snabbt upprätta verkliga transaktionsgränser (inklusive idempotensregister, outbox-tabeller och rollback-säkra arbetsflöden) innan du investerar i ett fullständigt mikrotjänstutförande.
Om du vill ha fler mönster och checklistor, referera förväntningarna från /blog. Om du erbjuder korrekthetsgarantier per nivå, gör dem explicita på /pricing så kunderna vet vilka garantier de köper.
Jim Gray var en datavetare som gjorde transaktionsbearbetning praktisk och lättare att förstå. Hans arv är en mindset: viktiga flerstegsoperationer (pengaröverföringar, kassaflöden, prenumerationsändringar) måste ge korrekta resultat även vid samtidighet och fel.
I dagligt produktarbete betyder det färre ”mystiska tillstånd”, färre manuellavstämningsbränder och tydligare garantier för vad som verkligen menas med committed.
En transaktion grupperar flera uppdateringar till en enda allt-eller-inget-enhet. Du committar när alla steg lyckas; du rullar tillbaka när något misslyckas.
Typiska exempel:
ACID är en uppsättning garantier som gör transaktioner pålitliga:
Det är inte en enda brytare—du väljer var och hur starkt du behöver dessa garantier.
De flesta ”det händer bara i produktion”-buggar kommer från svag isolation under hög belastning.
Vanliga felmönster:
Praktisk åtgärd: välj isoleringsnivå utifrån affärsrisken och backa upp med constraints/lås där det behövs.
Börja med att skriva invariablerna på ren svenska (vad måste alltid vara sant), och definiera sedan den minsta transaktionsgräns som skyddar dessa invariabler.
Mekanismer som fungerar bra tillsammans:
Se constraints som ett säkerhetsnät när applikationskoden failar under samtidighet.
Write-ahead logging (WAL) är hur databaser får ‘commit’ att överleva krascher.
Operativt:
Detta är anledningen till att en bra design kan säga: , även efter strömavbrott.
Backuper är punkt-i-tid-snapshots; loggar är historiken av ändringar sedan den snapshoten.
En praktisk återställningsstrategi:
Om du aldrig återställt från en backup så är det ännu inte en plan.
Distribuerade transaktioner försöker få flera system att committa som ett, men delvisa fel och tvetydiga timeout-situationer gör det svårt.
Two-phase commit (2PC) tillför typiskt:
Använd 2PC när du verkligen behöver atomiskheten över system och kan hantera driftkomplexiteten.
Föredra små lokala ACID-gränser och explicit koordinering mellan tjänster.
Vanliga mönster:
Det ger förutsägbart beteende vid retries och fel utan att göra varje arbetsflöde till ett globalt lås.
Anta att en timeout kan betyda “det lyckades men du fick inget svar”. Designa retries så att de är säkra.
Verktyg som förhindrar dubbletter:
Bästa praxis: håll dubblettkontrollen och tillståndsändringen i samma databastransaktion när det är möjligt.