Vad det här inlägget täcker (och varför det fortfarande är viktigt)
Joe Armstrong var inte bara med och skapade Erlang—han blev också dess klaraste och mest övertygande förklarare. Genom föredrag, artiklar och en pragmatisk syn populariserade han en enkel idé: om du vill ha programvara som håller igång, designar du för fel i stället för att låtsas att du kan undvika dem.
Det här inlägget är en guidad rundtur i Erlangs tankesätt och varför det fortfarande spelar roll när du bygger pålitliga realtidsplattformar—sådant som chatt, samtalsrouting, live-notifikationer, multiplayer-samordning och infrastruktur som måste svara snabbt och konsekvent även när delar beter sig dåligt.
“Realtid” i enkla ord
Realtid betyder inte alltid “mikrosekunder” eller hårda deadlines. I många produkter betyder det:
- snabba svar som användaren känner (inga mystiska pauser)
- förutsägbart beteende under belastning (det kan sakta ner, men det bör inte spåra ur)
- fortsatt tjänst vid partiella fel (en dålig komponent ska inte ta ner allt)
Erlang byggdes för telekomsystem där dessa förväntningar var icke-förhandlingsbara—och den pressen formade dess mest inflytelserika idéer.
De tre pelare vi fokuserar på
I stället för att dyka ner i syntaxen fokuserar vi på de koncept som gjorde Erlang berömt och som återkommer i modern systemdesign:
- Samtidighet som standard: bygg mjukvara av många små, isolerade arbetare i stället för några få jättar.
- Feltolerans som designmål: anta att buggar, timeouter och krascher kommer att hända—och planera vad som ska hända härnäst.
- ”Låt det krascha”: överförsvara inte varje rad kod; krascha snabbt och återhämta dig rent med struktur (inte hjältedåd).
Under vägen kopplar vi dessa idéer till aktormodellen och meddelandepassning, förklarar övervakningsträd och OTP på ett tillgängligt sätt och visar varför BEAM VM gör hela angreppssättet praktiskt.
Även om du inte använder Erlang (och aldrig kommer göra det) kvarstår poängen: Armstrongs ramverk ger dig en kraftfull checklista för att bygga system som förblir responsiva och tillgängliga när verkligheten blir rörig.
Joe Armstrongs motivation: bygga system som håller igång
Telefonswitchar och samtalsroutingplattformar kan inte “stängas av för underhåll” på samma sätt som många webbplatser kan. De förväntas hantera samtal, faktureringshändelser och signaltrafik dygnet runt—ofta med strikta krav på tillgänglighet och förutsägbara svarstider.
Erlang började inom Ericsson i slutet av 1980‑talet som ett försök att möta de verkligheterna med mjukvara, inte bara specialiserad hårdvara. Joe Armstrong och hans kollegor jaktade inte på elegans som mål i sig; de försökte bygga system som driftspersonal kunde lita på under konstant belastning, partiella fel och röriga verkliga förhållanden.
Vad “pålitlig” betydde i praktiken
En viktig tankeskift är att pålitlighet inte är samma sak som “aldrig falla”. I stora, långlivade system kommer något att gå sönder: en process får oväntad input, en nod startar om, en nätlänk fladdrar eller en beroende tjänst stannar av.
Målet blir då:
- fortsätt betjäna användare även när delar beter sig dåligt
- upptäck fel snabbt
- återställ automatiskt med minimal mänsklig inblandning
- isolera fel så att en bugg inte tar ner allt
Detta tankesätt gör senare idéer som övervakningsträd och “låt det krascha” rimliga: du designar för fel som en normal händelse, inte en exceptionell katastrof.
Mindre myt, mer problemlösning
Det är frestande att berätta historien som en ensam visionärs genombrott. En mer användbar syn är enklare: telekombegränsningar tvingade fram andra avvägningar. Erlang prioriterade samtidighet, isolation och återhämtning för att det var de praktiska verktygen som behövdes för att hålla tjänster igång medan omvärlden förändrades.
Just detta problem‑fokuserade synsätt är också varför Erlangs lärdomar fortfarande översätts väl idag—överallt där upptid och snabb återhämtning är viktigare än perfekt förebyggande.
Samtidighet som standard: många små arbetare
En kärnidé i Erlang är att “göra många saker samtidigt” inte är en specialfunktion du lägger på senare—det är det normala sättet att strukturera ett system.
Lätta processer, förklarat enkelt
I Erlang delas arbetet upp i många små “processer”. Tänk på dem som små arbetare, var och en ansvarig för en sak: hantera ett telefonsamtal, spåra en chattsession, övervaka en enhet, försöka om en betalning eller hålla koll på en kö.
De är lätta, vilket betyder att du kan ha mycket många av dem utan att behöva enorm hårdvara. I stället för en tungviktig arbetare som försöker jonglera allt får du en mängd fokuserade arbetare som kan starta snabbt, stoppa snabbt och ersättas snabbt.
Varför “ett stort program” brister annorlunda
Många system är designade som ett enda stort program med många tätt kopplade delar. När ett sådant system träffas av en allvarlig bugg, ett minnesproblem eller en blockerande operation kan felet sträcka sig utåt—som att slå om en säkring och mörklägga hela byggnaden.
Erlang driver motsatsen: isolera ansvar. Om en liten arbetare beter sig dåligt kan du ta bort och ersätta just den arbetaren utan att ta ner orelaterat arbete.
Meddelandepassning som “skicka lappar”
Hur koordinerar dessa arbetare? De rotar inte i varandras interna tillstånd. De skickar meddelanden—mer som att lämna lappar än att dela en rörig whiteboard.
En arbetare kan säga: “Här är en ny förfrågan”, “Denna användare kopplade ner” eller “Försök igen om 5 sekunder.” Den mottagande arbetaren läser lappen och bestämmer vad som ska göras.
Huvudfördelen är inneslutning: eftersom arbetare är isolerade och kommunicerar via meddelanden är fel mindre benägna att sprida sig genom hela systemet.
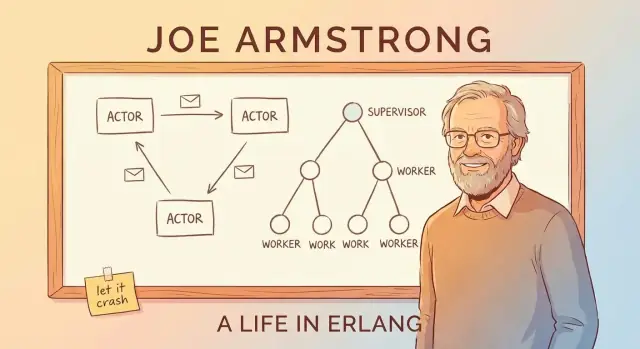
Meddelandepassning och aktormodellen (utan jargong)
Ett enkelt sätt att förstå Erlangs “aktormodell” är att föreställa sig ett system byggt av många små, oberoende arbetare.
Aktorer: små arbetare som bara pratar via meddelanden
En aktor är en självständig enhet med sitt eget privata tillstånd och en brevlåda. Den gör tre grundläggande saker:
- tar emot meddelanden (en i taget) från sin brevlåda
- uppdaterar sitt eget interna tillstånd
- skickar meddelanden till andra aktorer
Det är allt. Inga dolda delade variabler, inget “rör i en annan arbetarens minne”. Om en aktor behöver något från en annan så frågar den genom att skicka ett meddelande.
Varför undvikande av delat tillstånd tar bort hela kategorier av buggar
När flera trådar delar samma data kan du få race conditions: två saker ändrar samma värde nästan samtidigt, och resultatet beror på timingen. Det är där buggar blir intermittenta och svåra att reproducera.
Med meddelandepassning äger varje aktor sina data. Andra aktorer kan inte mutera dem direkt. Det eliminerar inte alla buggar, men minskar dramatiskt problem orsakade av samtidig åtkomst till samma tillstånd.
Back‑pressure, förklarat som en kö på ett kafé
Meddelanden kommer inte “gratis.” Om en aktor får meddelanden snabbare än den kan bearbeta dem växer dess brevlåda (kö). Det är back‑pressure: systemet säger indirekt “den här delen är överbelastad.”
I praktiken övervakar du brevlådstorlekar och bygger begränsningar: avlasta, batcha, sampelera eller skicka arbete till fler aktorer i stället för att låta köerna växa oändligt.
Ett konkret exempel: chattnotifikationer
Föreställ dig en chattapp. Varje användare kan ha en aktor som ansvarar för att leverera notiser. När en användare går offline fortsätter meddelanden att anlända—så brevlådan växer. Ett väl designat system kan kapa kön, tappa icke-kritiska notiser eller växla till digest-läge i stället för att låta en långsam användare degradiera hela tjänsten.
“Låt det krascha” förklarat: krascha snabbt, återställ snabbare
”Låt det krascha” är inte en slogan för slarvig engineering. Det är en strategi för tillförlitlighet: när en komponent hamnar i ett dåligt eller oväntat tillstånd bör den stänga ner snabbt och tydligt i stället för att stappla vidare.
Vad det egentligen betyder
I stället för att skriva kod som försöker hantera varje tänkbart kantfall i en process uppmuntrar Erlang att hålla varje arbetare liten och fokuserad. Om den arbetaren ställs inför något den verkligen inte kan hantera (korrupt tillstånd, brutet antagande, oväntad input) så avslutas den. En annan del av systemet ansvarar för att starta upp den igen.
Det flyttar huvudfrågan från “Hur förhindrar vi fel?” till “Hur återställer vi rent när fel inträffar?”
Avvägningen: färre defensiva kontroller, klarare logik
Defensiv programmering överallt kan förvandla enkla flöden till en labyrint av villkor, retries och partiella tillstånd. “Låt det krascha” byter en del av den in-process-komplexiteten mot:
- enklare, mer läsbara kodflöden
- snabbare upptäckt av brutna antaganden
- återställning som är konsekvent (eftersom den är centraliserad)
Den stora idén är att återställning bör vara förutsägbar och reproducerbar, inte improviserad i varje funktion.
När det passar—och när det inte gör det
Det passar bäst när fel är återställbara och isolerade: ett tillfälligt nätverksproblem, en dålig förfrågan, en fastnad arbetare eller en third‑party timeout.
Det passar dåligt när en krasch kan orsaka oåterkallelig skada, såsom:
- dataförlust utan hållbar sanning
- säkerhetskritiska operationer där “försök igen” inte är acceptabelt
Snabba omstarter och känt bra tillstånd
Att krascha hjälper bara om återkomst är snabb och säker. I praktiken betyder det att starta om arbetare i ett känt, korrekt tillstånd—ofta genom att ladda om konfiguration, bygga upp in-memory-cachar från uthållig lagring och fortsätta arbetet utan att låtsas att det trasiga tillståndet aldrig fanns.
Övervakningsträd: designa för fel med avsikt
Bygg och tjäna krediter
Tjäna krediter genom att skapa innehåll om Koder.ai eller bjuda in andra med din referral-kod.
Erlangs “låt det krascha”-idé fungerar bara eftersom krascher inte lämnas åt slumpen. Nyckelmönstret är övervakningsträdet: en hierarki där supervisors fungerar som chefer och workers gör själva jobbet (hantera ett samtal, spåra en session, konsumera en kö osv.). När en worker beter sig dåligt märker chefen det och startar om den.
Chefer som startar om arbetare
En supervisor försöker inte “fixa” en trasig worker på plats. I stället tillämpar den en enkel, konsekvent regel: om workern dör, starta en ny. Det gör återställningsvägen förutsägbar och minskar behovet av ad-hoc-felhantering utspridd i koden.
Lika viktigt är att supervisors kan avgöra när de inte ska starta om—om något kraschar för ofta kan det signalera ett djupare problem, och upprepade omstarter kan göra saken värre.
Strategier för omstart (övergripande)
Övervakning är inte en universallösning. Vanliga strategier inkluderar:
- One-for-one: bara den misslyckade workern startas om. Passar oberoende uppgifter där ett fel inte bör störa andra.
- Grupperade omstarter: om en worker fallerar startas en relaterad uppsättning om tillsammans. Passar tätt kopplade komponenter som måste vara synkade.
Beroenden: delen du måste tänka igenom
Bra övervakningsdesign börjar med en beroendekarta: vilka komponenter förlitar sig på vilka andra, och vad betyder en “färsk start” för dem?
Om en sessionhandler beror på en cacheprocess kan det räcka att bara starta om handlern lämna den kopplad till ett dåligt tillstånd. Att gruppera dem under rätt supervisor (eller starta om dem tillsammans) förvandlar röriga felmoder till konsekvent, reproducerbar återställningslogik.
OTP: återanvändbara byggstenar för pålitliga tjänster
Om Erlang är språket så är OTP (Open Telecom Platform) satsen med delar som gör “låt det krascha” till något du kan köra i produktion i åratal.
OTP som en verktygslåda med beprövade mönster
OTP är inte ett enskilt bibliotek—det är en uppsättning konventioner och färdiga komponenter (kallade behaviours) som löser de tråkiga men kritiska delarna av att bygga tjänster:
gen_server för en långlivad worker som håller state och hanterar förfrågningar en i tagetsupervisor för att automatiskt starta om misslyckade workers enligt tydliga reglerapplication för att definiera hur en hel tjänst startas, stoppas och ingår i en release
Det här är ingen magi. Det är mallar med väldefinierade callbacks, så din kod passar in i en känd form i stället för att uppfinna en ny form för varje projekt.
Varför standardmönster slår egna ramverk
Team bygger ofta ad‑hoc bakgrundsworkers, hembyggda övervakningskrokar och engångslogik för omstart. Det fungerar—tills det inte gör det. OTP minskar den risken genom att styra alla mot samma vokabulär och livscykel. När en ny ingenjör kommer in behöver de inte lära sig ditt egna ramverk först; de kan förlita sig på delade mönster som är allmänt förstådda i Erlang‑ekosystemet.
Hur OTP styr arkitektur i vardagen
OTP uppmuntrar dig att tänka i termer av processroller och ansvar: vad är en worker, vad är en koordinator, vad ska starta om vad och vad ska aldrig startas om automatiskt.
Det främjar också god hygien: tydlig namngivning, explicita startordningar, förutsägbar nedstängning och inbyggda övervakningssignaler. Resultatet är mjukvara designad för att köras kontinuerligt—tjänster som kan återhämta sig från fel, utvecklas över tid och fortsätta göra sitt jobb utan konstant mänsklig tillsyn.
BEAM VM: runtime som gör modellen praktisk
Planera din felhantering
Använd Planning Mode för att kartlägga felgränser, retries och återställning innan du genererar kod.
Erlangs stora idéer—små processer, meddelandepassning och “låt det krascha”—skulle vara mycket svårare att använda i produktion utan BEAM‑virtuella maskinen (VM). BEAM är runtime som får dessa mönster att kännas naturliga, inte sköra.
Schemaläggning: rättvisa framför “en stor tråd”
BEAM är byggt för att köra enorma mängder lätta processer. I stället för att förlita sig på ett fåtal OS‑trådar och hoppas att applikationen uppför sig, schemalägger BEAM Erlang‑processer själv.
Den praktiska vinsten är responsivitet under belastning: arbete skivas upp i små bitar och roteras på ett rättvist sätt, så ingen ensam intensiv arbetare ska dominera systemet länge. Det passar perfekt för en tjänst bestående av många oberoende uppgifter—var och en gör lite jobb, sedan ger den plats.
Isolation och per‑process minnesstädning
Varje Erlang‑process har sin egen heap och sin egen garbage collection. Det är en nyckeldetalj: att rensa minne i en process kräver inte att stoppa hela programmet.
Lika viktigt är att processer är isolerade. Om en kraschar korruptar den inte andra processers minne och VM:en fortsätter att leva. Denna isolation är grunden som gör övervakningsträd realistiska: fel innesluts och hanteras genom att starta om den trasiga delen i stället för att riva ner allt.
Distribution: flera noder, ett system
BEAM stöder också distribution på ett rakt‑på‑sak‑sätt: du kan köra flera Erlang‑noder (separata VM‑instanser) och låta dem kommunicera genom att skicka meddelanden. Har du förstått “processer pratar via meddelanden” så är distribution en förlängning av samma idé—vissa processer råkar bara bo på en annan nod.
BEAM handlar inte om löften om rå prestanda. Det handlar om att göra samtidighet, felinhägnad och återställning till standard, så att tillförlitlighetshistorien blir praktisk i stället för teoretisk.
Uppgraderingar utan att stoppa systemet (hot code, försiktigt)
En av Erlangs mest omtalade tricks är hot code swapping: att uppdatera delar av ett körande system med minimal driftstörning (när runtime och verktyg stödjer det). Löftet i praktiken är inte “aldrig starta om igen”, utan “skicka fixar utan att en liten bugg blir ett långt avbrott.”
Vad “hot code” egentligen betyder
I Erlang/OTP kan runtime hålla två versioner av en modul laddad samtidigt. Befintliga processer kan avsluta arbete med den gamla versionen medan nya anrop kan börja använda den nya. Det ger utrymme att laga en bugg, rulla ut en funktion eller justera beteende utan att kicka av alla användare.
Görs det väl stödjer det pålitlighetsmålen direkt: färre fulla omstarter, kortare underhållsfönster och snabbare återhämtning när något slinker ut i produktion.
De begränsningar ingen bör ignorera
Inte alla förändringar är säkra att byta live. Exempel på ändringar som kräver extra omsorg (eller en omstart) inkluderar:
- förändringar i statens struktur (en process förväntar sig data i ett format men ny kod förväntar sig ett annat)
- protokoll‑ eller meddelandeformat som måste matcha över tjänster
- schemamigreringar som tar tid eller kräver koordination
Erlang erbjuder mekanismer för kontrollerade övergångar, men du måste fortfarande designa uppgraderingsvägen.
Mindset: uppgraderingar och rollback är normalt
Hot upgrades fungerar bäst när uppgraderingar och rollbacks betraktas som rutinoperationer, inte sällsynta nödsituationer. Det betyder att planera versionering, kompatibilitet och en tydlig “ångra”-väg från början. I praktiken parar team live‑upgrade‑tekniker med staged rollouts, hälsokontroller och övervakningsbaserad återställning.
Även om du aldrig använder Erlang: lärdomen överförs—designa system så att att ändra dem säkert är ett förstklassigt krav, inte en eftertanke.
Realtidsplattformar handlar mindre om perfekt timing och mer om att vara responsiv medan saker konstant går fel: nätverk vinglar, beroenden saktar ner och användartrafik spikar. Erlangs design—främjad av Joe Armstrong—passar denna verklighet eftersom den antar fel och behandlar samtidighet som normal, inte exceptionell.
Vanliga realtidsanvändningsfall
Du ser Erlang‑stil tänk lysa överallt där många oberoende aktiviteter händer samtidigt:
- Meddelanden och chatt: miljoner små konversationer, var och en med eget tillstånd och retries.
- Realtidskommunikation: röst/video‑signalering, presence‑uppdateringar och sessionssamordning.
- IoT‑samordning: flottor av enheter som checkar in, försvinner och återkommer oförutsägbart.
- Betalningsflöden: flerstegsprocesser där vissa steg är långsamma, otillgängliga eller kräver kompensationsåtgärder.
Vad “soft real-time” brukar betyda
De flesta produkter behöver inte hårda garantier som “varje åtgärd slutförs inom 10 ms.” De behöver soft real-time: konsekvent låg latens för typiska förfrågningar, snabb återhämtning när delar fallerar och hög tillgänglighet så användare sällan märker incidenter.
Fel är normalt: designa för det
Riktiga system stöter på problem som:
- Hoppade anslutningar (mobilnät, Wi‑Fi‑handoffs)
- Timeouts när en downstream‑tjänst är långsam
- Partiella störningar där en region eller beroende degraderas
Erlangs modell uppmuntrar att isolera varje aktivitet (en användarsession, en enhet, ett betalningsförsök) så ett fel inte sprider sig. I stället för att bygga en gigantisk “försök att hantera allt”-komponent kan team resonera i mindre enheter: varje worker gör en sak, pratar via meddelanden och om den går sönder startas den om rent.
Denna förflyttning—från “förhindra varje fel” till “begränsa och återställ från fel snabbt”—är ofta vad som får realtidsplattformar att kännas stabila under press.
Vanliga missförstånd och verkliga begränsningar
Gå från idé till distribution
Distribuera och hosta din app när du är redo, utan att ändra ditt arbetsflöde.
Erlangs rykte kan låta som ett löfte: system som aldrig går ner eftersom de bara startar om. Verkligheten är mer praktisk—och mer användbar. “Låt det krascha” är ett verktyg för att bygga pålitliga tjänster, inte ett tillstånd att ignorera svåra problem.
Omstarter är ingen plåsterlösning
Ett vanligt misstag är att betrakta övervakning som ett sätt att dölja djupa buggar. Om en process kraschar direkt efter start kan en supervisor fortsätta starta om den tills du hamnar i en crash loop—som bränner CPU, spammar loggar och potentiellt orsakar en större incident än den ursprungliga buggen.
Bra system lägger till backoff, gränser för omstartsfrekvens och tydligt “ge upp och eskalera”-beteende. Omstarter ska återställa hälsosam drift, inte dölja ett brutet antagande.
Tillstånd är den svåra delen
Att starta om en process är ofta enkelt; återställa korrekt tillstånd är det inte. Om tillstånd bara lever i minnet måste du bestämma vad som är “korrekt” efter en krasch:
- Ska du bygga upp det från uthållig lagring?
- Kan du spela upp events säkert (idempotens)?
- Vad händer med pågående arbete eller delvis applicerade uppdateringar?
Feltolerans ersätter inte noggrann datadesign. Den tvingar dig att vara uttrycklig kring den.
Du behöver fortfarande observabilitet
Krascher hjälper bara om du kan se dem tidigt och förstå dem. Det betyder investering i loggning, metrik och spårning—inte bara “det startade om, så vi är ok.” Du vill upptäcka stigande omstartsfrekvenser, växande köer och långsamma beroenden innan användare känner av det.
Verkliga operativa begränsningar finns
Även med BEAMs styrkor kan system falla på mycket vardagliga sätt:
- Minnesökning från läckor, caches eller stora heapar
- Mailbocklog när producenter kör ifrån konsumenter (latensspikar och timeouter)
- Beroendefel (databaser, tredjeparts‑API:er, DNS) där omstart av koden inte löser roten
Erlangs modell hjälper dig att innesluta och återhämta dig från fel—men den kan inte eliminera dem.
Hur du använder lärdomarna idag (även om du inte använder Erlang)
Erlangs största gåva är inte syntax—det är uppsättningen vanor för att bygga tjänster som fortsätter fungera när delar oundvikligen fallerar. Du kan använda dessa vanor i nästan vilken stack som helst.
Översätt idéerna till konkreta åtgärder
Börja med att göra felgränser explicita. Dela upp ditt system i komponenter som kan falla oberoende, och säkerställ att varje komponent har ett tydligt kontrakt (input, output och vad “dåligt” betyder).
Automatisera sedan återställning i stället för att försöka förhindra varje fel:
- Isolera komponenter: kör riskfyllt arbete i separata processer/containers/trådar så en krasch inte förgiftar allt.
- Definiera gränser: timeouts, retries med backoff, circuit breakers och bulkheads för att stoppa kaskadfel.
- Gör återställning rutin: health checks, auto‑restarts och säkra standarder så systemet snabbt återgår till ett känt bra tillstånd.
Ett praktiskt sätt att göra dessa vanor verkliga är att baka in dem i verktyg och livscykel, inte bara i koden. Till exempel, när team använder Koder.ai för att vibe‑koda web, backend eller mobilappar via chat uppmuntrar arbetsflödet naturligt explicit planering (Planning Mode), reproducerbara deployment‑flöden och säkra iterationer med snapshots och rollback—koncept som stämmer överens med samma operativa tankesätt som Erlang populariserade: anta förändring och fel, och gör återställning tråkig.
Startpunkter utanför Erlang
Du kan approximera “supervision”-mönster med verktyg du kanske redan använder:
- Supervisors: systemd, Kubernetes Deployments eller en process‑manager (restart‑on‑failure, readiness probes).
- Processisolation: separata worker‑tjänster för CPU‑tunga eller otrustade uppgifter.
- Meddelandepassning: köer/streams (RabbitMQ, SQS, Kafka) för att lösgöra producenter och konsumenter och jämna ut spikar.
En snabb beslutschecklista
Innan du kopierar mönster, bestäm vad du faktiskt behöver:
- Förväntade felmoder: överbelastning, partiella störningar, långsamma beroenden, felaktig input, minnesläckor.
- Latensbehov: kräver du realtidssvar eller räcker eventual processing?
- Återställningsmål: snabb omstart, graciell degradering eller manuell intervention?
- Teamskicklighet och verktyg: vem äger on‑call, observabilitet och incidenthantering?
Om du vill ha praktiska nästa steg, se fler guider i /blog, eller granska implementationsdetaljer i /docs (och planer i /pricing om du utvärderar verktyg).