Varför team fastnar med traditionella integrationer
De flesta produkter börjar med enkla punkt-till-punkt-integrationer: System A anropar System B, eller ett litet skript kopierar data från en plats till en annan. Det fungerar tills produkten växer, team splittras och antalet kopplingar multipliceras. Snart kräver varje ändring koordinering över flera tjänster, eftersom ett litet fält eller statusuppdatering kan skapa ringar på vattnet genom en kedja av beroenden.
Prestanda är ofta det första som brister. Att lägga till en ny funktion betyder att flera integrationer måste uppdateras, flera tjänster måste deployas om, och man hoppas att inget annat var beroende av det gamla beteendet.
Sedan blir felsökning smärtsamt. När något ser fel ut i UI är det svårt att svara på grundläggande frågor: vad hände, i vilken ordning, och vilket system skrev det värde du ser?
Den saknade biten är ofta ett revisionsspår. Om data skjuts direkt från en databas till en annan (eller transformeras på vägen) förlorar du historiken. Du kan se slutligt tillstånd, men inte sekvensen av händelser som ledde dit. Incidentgranskningar och kundsupport lider eftersom du inte kan spela upp det förflutna för att bekräfta vad som ändrades och varför.
Här börjar också argumentet om "vem äger sanningen". Ett team säger: "Betaltjänsten är sanningskällan." Ett annat säger: "Beställningstjänsten är det." I verkligheten har varje system en partiell vy, och punkt-till-punkt-integrationer gör den oenigheten till vardaglig friction.
Ett enkelt exempel: en order skapas, betalas och återbetalas. Om tre system uppdaterar varandra direkt kan varje system få en annan berättelse när retries, timeouts eller manuella åtgärder inträffar.
Det leder till huvudfrågan bakom Kafka event streaming: behöver du bara flytta arbete från en plats till en annan (en kö), eller behöver du ett delat, varaktigt register över vad som hände som många system kan läsa, spola tillbaka och lita på (en logg)? Svaret förändrar hur du bygger, felsöker och vidareutvecklar ditt system.
Jay Kreps, Kafka och idén om loggen
Jay Kreps var med och formade Kafka och, ännu viktigare, hur många team tänker kring datarörelse. Den användbara skiftningen är ett tankesätt: sluta behandla meddelanden som engångsleveranser och börja tänka på systemaktivitet som ett register.
Kärnidéen är enkel. Modellera viktiga förändringar som en ström av oföränderliga fakta:
- En order skapades.
- En betalning auktoriserades.
- En användare ändrade sin e-post.
Varje event är ett faktum som inte bör redigeras i efterhand. Om något ändras senare lägger du till ett nytt event som anger den nya sanningen. Med tiden bildar dessa fakta en logg: en append-only-historik av ditt system.
Det är här Kafka event streaming skiljer sig från många enkla meddelandesystem. Många köer bygger på "skicka, bearbeta, ta bort." Det funkar när arbetet är ren överlämning. Logg-perspektivet säger: "behåll historiken så att många konsumenter kan använda den, nu och senare."
Att kunna spela upp historik är den praktiska superkraften.
Om en rapport är fel kan du köra om samma event-historia genom ett fixat analysjobb och se var siffrorna förändrades. Om en bugg orsakade felaktiga mejl kan du spela upp händelser i en testmiljö och reproducera exakt tidslinje. Om en ny funktion behöver historiska data kan du bygga en ny konsument som börjar från början och hämtar ikapp i sin egen takt.
Här är ett konkret exempel. Föreställ dig att du lägger till bedrägerikontroller efter att du redan har bearbetat månader av betalningar. Med en logg av betalnings- och kontohändelser kan du spela upp det förflutna för att träna eller kalibrera regler på verkliga sekvenser, beräkna riskpoäng för gamla transaktioner och backfilla fraud_review_requested-händelser utan att skriva om din databas.
Notera vad detta tvingar dig att göra. Ett loggbaserat tillvägagångssätt får dig att namnge händelser tydligt, hålla dem stabila och acceptera att flera team och tjänster kommer att bero på dem. Det tvingar också fram användbara frågor: Vad är sanningskällan? Vad betyder detta event på lång sikt? Vad gör vi när vi gjort ett misstag?
Värdet är inte personligheten. Det är insikten att en delad logg kan bli systemets minne, och minne är vad som tillåter system att växa utan att gå sönder varje gång du lägger till en ny konsument.
Kö vs logg: den enklaste mentala modellen
En meddelandekö är som en att-göra-kö för din mjukvara. Producenter lägger arbete i kön, konsumenter tar nästa objekt, utför arbetet, och objektet försvinner. Systemet handlar mest om att varje uppgift hanteras en gång så snabbt som möjligt.
En logg är annorlunda. Det är ett ordnat register över fakta som hänt, bevarat i en hållbar sekvens. Konsumenter "tar" inte bort händelser. De läser loggen i sin egen takt och kan läsa den igen senare. I Kafka event streaming är den loggen kärn idén.
Ett praktiskt sätt att komma ihåg skillnaden:
- Kö = arbete som ska göras. När en arbetare bekräftar det försvinner det.
- Logg = historik över vad som hände. Händelser finns kvar under en retention-period.
Retention förändrar designen. Med en kö, om du senare behöver en ny funktion som beror på gamla meddelanden (analytics, bedrägerikontroller, replay efter en bugg), måste du ofta lägga till en separat databas eller börja fånga kopior någon annanstans. Med en logg är replay normalt: du kan bygga om en härledd vy genom att läsa från början (eller från en känd checkpoint).
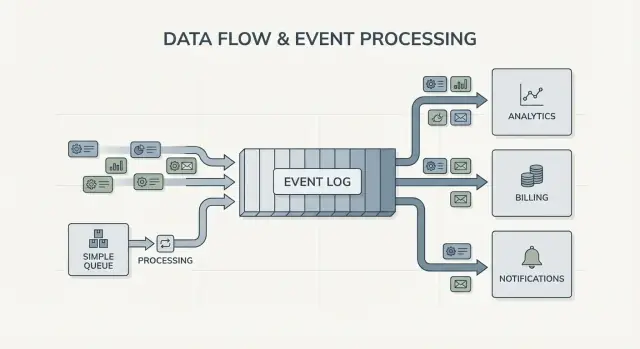
Fan-out är en annan stor skillnad. Föreställ dig att en checkout-tjänst emitterar OrderPlaced. Med en kö väljer du vanligtvis en arbetsgrupp att bearbeta det, eller duplicerar arbete över flera köer. Med en logg kan billing, e-post, lager, sökindexering och analytics alla läsa samma eventström oberoende. Varje team kan röra sig i sin egen takt, och att lägga till en ny konsument senare kräver inte att producenten ändras.
Så den mentala modellen är enkel: använd en kö när du flyttar uppgifter; använd en logg när du spelar in händelser som flera delar av företaget kan vilja läsa, nu eller senare.
Vad event streaming förändrar i systemdesign
Event streaming vänder på standardfrågan. Istället för att fråga "Vem ska jag skicka det här meddelandet till?" börjar du med att spela in "Vad hände precis?" Det låter litet, men förändrar hur du modellerar ditt system.
Du publicerar fakta som OrderPlaced eller PaymentFailed, och andra delar av systemet bestämmer om, när och hur de reagerar.
Med Kafka event streaming behöver producenter inte längre en lista över direkta integrationer. En checkout-tjänst kan publicera ett event, och den behöver inte veta om analytics, e-post, bedrägerikontroller eller en framtida rekommendationstjänst kommer att använda det. Nya konsumenter kan dyka upp senare, äldre kan pausas, och producenten beter sig fortfarande samma.
Detta förändrar också hur du återhämtar dig från misstag. I en rent meddelandebaserad värld, när en konsument missar något eller har en bugg, är datan ofta "borta" om du inte byggt anpassade backuper. Med en logg kan du fixa koden och spela upp historiken för att bygga upp korrekt tillstånd igen. Det slår ofta manuella databasändringar eller engångsskript som ingen litar på.
I praktiken visar sig skiftet i några pålitliga sätt: du behandlar händelser som ett varaktigt register, du lägger till funktioner genom att prenumerera istället för att ändra producenter, du kan bygga om read-modeller (sökindex, dashboards) från början, och du får tydligare tidslinjer över vad som hände över tjänster.
Observability förbättras eftersom eventloggen blir en delad referens. När något går fel kan du följa en affärssekvens: order skapad, lager reserverat, betalning omförsökt, leverans schemalagd. Den tidslinjen är ofta lättare att förstå än spridda applikationsloggar eftersom den fokuserar på affärsfakta.
Ett konkret exempel: om en rabattbugg prisade om beställningar fel i två timmar kan du deploya en fix och spela upp de berörda händelserna för att räkna om totalsummor, uppdatera fakturor och uppdatera analytics. Du korrigerar utfall genom att härleda om resultat, inte genom att gissa vilka tabeller som ska patchas för hand.
När en enkel kö räcker
En enkel kö är rätt verktyg när du flyttar arbete, inte bygger ett långsiktigt register. Målet är att överlämna en uppgift till en worker, köra den och sedan glömma den. Om ingen behöver spela upp historiken, inspektera gamla händelser eller lägga till nya konsumenter senare, håller en kö saker enklare.
Köer passar utmärkt för bakgrundsjobb: skicka välkomstmejl, ändra storlek på bilder efter uppladdning, generera en nattlig rapport eller anropa ett långsamt externt API. I dessa fall är meddelandet bara en arbetsticket. När en worker slutfört jobbet har även ticketen gjort sitt.
En kö passar också ägarskapsmodellen: en konsumentgrupp ansvarar för att göra jobbet, och andra tjänster förväntas inte läsa samma meddelande oberoende.
En kö räcker vanligtvis när det mesta av följande är sant:
- Datat har kortvarigt värde.
- Ett team eller en tjänst äger jobbet från början till slut.
- Replay och lång retention är inte krav.
- Felsökning beror inte på att köra om historik.
Exempel: en produkt laddar upp användarfoton. Appen skriver en "resize image"-uppgift till en kö. Worker A plockar upp den, skapar thumbnails, lagrar dem och markerar uppgiften som klar. Om uppgiften körs två gånger blir resultatet samma (idempotent), så at-least-once-leverans är okej. Ingen annan tjänst behöver läsa den uppgiften senare.
Om dina behov börjar luta mot delade fakta (många konsumenter), replay, revision eller "vad trodde systemet förra veckan?", då börjar Kafka event streaming och ett loggbaserat tillvägagångssätt ge utdelning.
När ett loggbaserat tillvägagångssätt löser problem
Ett loggbaserat system lönar sig när händelser slutar vara engångsmeddelanden och börjar bli delad historik. Istället för "skicka och glöm" behåller du ett ordnat register som många team kan läsa, nu eller senare, i sin egen takt.
Det tydligaste tecknet är flera konsumenter. Ett event som OrderPlaced kan mata billing, e-post, fraud, sökindexering och analytics. Med en logg läser varje konsument samma ström oberoende. Du behöver inte bygga en anpassad fan-out-pipeline eller koordinera vem som får meddelandet först.
En annan vinst är att kunna svara på "Vad visste vi då?". Om en kund bestrider en avgift eller en rekommendation verkar fel, gör en append-only-historik det möjligt att spela upp fakta i den ordning de anlände. Det revisionsspåret är svårt att lägga till en enkel kö i efterhand.
Du får också ett praktiskt sätt att lägga till nya funktioner utan att skriva om gamla. Om du lägger till en ny "leveransstatus"-sida månader senare kan en ny tjänst prenumerera och backfilla från befintlig historik för att bygga sitt tillstånd, istället för att be andra system om export.
Ett loggbaserat tillvägagångssätt är ofta värt det när du känner igen ett eller flera av dessa behov:
- Samma händelser måste mata flera system (analytics, sök, fakturering, supportverktyg).
- Du behöver replay, revision eller undersökningar baserade på tidigare fakta.
- Nya tjänster måste backfilla från historik utan engångsjobb.
- Ordering är viktig per entitet (per order, per användare).
- Eventformat kommer att utvecklas och du behöver en kontrollerad versionhantering.
Ett vanligt mönster är en produkt som börjar med orders och mejl. Senare vill finans ha intäktsrapporter, produkt vill ha funnels och ops vill ha en live-dashboard. Om varje nytt behov tvingar dig att kopiera data genom en ny pipeline dyker kostnader upp snabbt. En delad eventlogg låter team bygga på samma källa till sanningen, även när systemet växer och eventformat ändras.
Hur man bestämmer, steg för steg
Att välja mellan en enkel kö och ett loggbaserat tillvägagångssätt blir enklare om du behandlar det som ett produktbeslut. Börja från vad du behöver vara sant om ett år, inte bara vad som funkar den här veckan.
Ett praktiskt 5-stegsbeslut
-
Kartlägg producenter och läsare. Skriv ner vem som skapar händelser och vem som läser dem idag, och lägg till sannolika framtida konsumenter (analytics, sökindexering, fraud, notifikationer). Om du förväntar dig många team som läser samma händelser oberoende börjar en logg att kännas rimlig.
-
Fråga om ni behöver läsa om historiken. Var specifik om varför: replay efter en bugg, backfills eller konsumenter som läser i olika hastigheter. Köer är bra för engångsöverlämningar. Loggar är bättre när du vill ha ett register du kan spela upp.
-
Definiera vad "klart" betyder. För vissa arbetsflöden betyder klart "jobbet kördes" (skicka ett mejl, ändra storlek på en bild). För andra betyder klart "händelsen är ett varaktigt faktum" (en order lades, en betalning auktoriserades). Varaktiga fakta pekar mot en logg.
-
Välj leveransförväntningar och bestäm hur ni hanterar dubbletter. At-least-once-leverans är vanlig, vilket innebär att dubbletter kan ske. Om en dubblett kan skada (dubbla avgifter), planera för idempotens: spara behandlat event-ID, använd unika begränsningar eller gör uppdateringar säkra att upprepa.
-
Börja med en tunn skiva. Välj en eventström som är lätt att förstå och väx därifrån. Om ni väljer Kafka event streaming, håll det första topicet fokuserat, namnge händelser tydligt och undvik att blanda orelaterade eventtyper.
Ett konkret exempel: om OrderPlaced senare kommer att mata shipping, fakturering, support och analytics låter en logg varje team läsa i sin egen takt och spela upp vid behov. Om du bara behöver en bakgrundsworker för att skicka ett kvitto räcker oftast en enkel kö.
Exempel: orderhändelser i en växande produkt
Föreställ dig en liten webbshop. I början behöver den bara ta emot orders, debitera ett kort och skapa en leveransbegäran. Den enklaste versionen är ett bakgrundsjobb efter checkout: "process order." Det anropar betal-API, uppdaterar orderraden i databasen och anropar shipping.
Den kö-stilen funkar bra när det finns ett tydligt arbetsflöde, bara en konsument (workern) och retries och dead letters täcker de flesta fel.
Det börjar bli problematiskt när shoppen växer. Support vill ha automatiska "var är min order?"-uppdateringar. Finans vill ha dagliga intäktsrapporter. Produktteamet vill skicka kundmejl. En bedrägerikontroll bör ske innan leverans. Med ett enda "process order"-jobb hamnar du i situationen att samma worker ändras om och om igen, med många grenar och risk för nya buggar i kärnflödet.
Med ett loggbaserat tillvägagångssätt producerar checkout små fakta som events, och varje team kan bygga vidare på dem. Typiska events kan vara:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Nyckeländringen är ägarskap. Checkout-tjänsten äger OrderPlaced. Betalningstjänsten äger PaymentConfirmed. Shipping äger ItemShipped. Senare kan nya konsumenter dyka upp utan att ändra producenten: en fraud-tjänst läser OrderPlaced och PaymentConfirmed för att skatta risk, en e-posttjänst skickar kvitton, analytics bygger funnels och supportverktyg håller en tidslinje över vad som hände.
Det är här Kafka event streaming lönar sig: loggen bevarar historik, så nya konsumenter kan spola tillbaka och hämta ikapp från början (eller från en känd punkt) istället för att be varje upstream-team lägga till en webhook.
Loggen ersätter fortfarande inte din databas. Du behöver fortfarande en databas för aktuell status: senaste orderstatus, kundpost, lagersaldon och transaktionella regler (som "skicka inte innan betalning bekräftats"). Tänk på loggen som ändringshistoriken och databasen som stället du frågar efter "vad är sant just nu".
Vanliga misstag och fallgropar
Event streaming kan få system att kännas renare, men några vanliga misstag kan snabbt sudda ut fördelarna. De flesta kommer från att behandla en eventlogg som en fjärrkontroll istället för ett register.
En vanlig fälla är att skriva events som kommandon, till exempel "SendWelcomeEmail" eller "ChargeCardNow." Det gör konsumenterna tätt kopplade till din avsikt. Events fungerar bättre som fakta: "UserSignedUp" eller "PaymentAuthorized." Fakta åldras väl. Nya team kan återanvända dem senare utan att gissa vad du menade.
Dubbletter och retries är nästa stora smärtkälla. I verkliga system gör producenter retries och konsumenter bearbetar om. Om du inte planerar för det får du dubbla debiteringar, dubbla mejl och arga supportärenden. Lösningen är inte exotisk, men måste vara medveten: idempotenta handlers, stabila event-ID:n och affärsregler som upptäcker "redan applicerat."
Vanliga fallgropar:
- Använda kommando-stil händelser som berättar för tjänster vad de ska göra istället för att spela in vad som hände.
- Bygga konsumenter som går sönder om de ser samma event två gånger.
- Dela upp strömmar för tidigt så ett affärsflöde sprids över för många topics.
- Ignorera schemaregler tills en liten ändring bryter äldre konsumenter.
- Behandla streaming som en ersättning för bra databdesign.
Schema och versionering förtjänar särskild uppmärksamhet. Även om du börjar med JSON behöver du ändå ett tydligt kontrakt: obligatoriska fält, valfria fält och hur förändringar rullas ut. En liten ändring som att byta namn på ett fält kan tyst bryta analytics, fakturering eller mobilappar som uppdaterar långsammare.
En annan fälla är att överdela. Team skapar ibland en ny ström för varje feature. En månad senare kan ingen svara på "Vad är det aktuella tillståndet för en order?" eftersom historien är utspridd över för många ställen.
Event streaming tar inte bort behovet av solida datamodeller. Du behöver fortfarande en databas som representerar den aktuella sanningen. Loggen är historik, inte hela din applikation.
Snabb checklista och nästa steg
Om du sitter fast i valet mellan en kö och Kafka event streaming, börja med några snabba kontroller. De visar om du behöver enkel överlämning mellan workers eller en logg du kan återanvända i åratal.
Snabba kontroller
- Behöver du replay (för backfills, buggfixar eller nya funktioner), och hur långt tillbaka?
- Kommer mer än en konsument behöva samma händelser nu eller snart (analytics, sök, e-post, fraud, fakturering)?
- Behöver du retention så team kan läsa om historik utan att be producenten skicka om?
- Hur viktig är ordering, och på vilken nivå: per entitet (per order, per användare) eller globalt?
- Kan konsumenter vara idempotenta (säkra att köra om samma event utan dubbla avgifter, dubbla mejl eller dubbla uppdateringar)?
Om du svarade "nej" på replay, "en konsument endast" och "kortlivade meddelanden" räcker oftast en grundläggande kö. Om du svarade "ja" på replay, flera konsumenter eller längre retention börjar ett loggbaserat tillvägagångssätt löna sig eftersom det förvandlar en ström av fakta till en delad källa andra system kan bygga på.
Nästa steg
Gör svaren till en liten, testbar plan.
- Lista 5–10 kärnhändelser i klartext (exempel: OrderPlaced, PaymentAuthorized, OrderShipped) och notera vem som publicerar och vem som konsumerar varje.
- Bestäm ordering key (ofta per entitet, som orderId) och dokumentera vad "rätt ordning" betyder.
- Definiera en idempotensregel per konsument (till exempel: spara senaste behandlade event-ID per order).
- Välj en retention som matchar era behov (dagar för kö-liknande arbetsflöden, veckor/månader när replay är viktigt).
- Kör en end-to-end-slice i en sandbox innan ni låser designen.
Om du prototyper snabbt kan du skissa eventflödet i Koder.ai planning mode och iterera på designen innan du bestämmer eventnamn och retry-regler. Eftersom Koder.ai stödjer export av källkod, snapshots och rollback är det också ett praktiskt sätt att testa en producent-konsument-slice och justera eventformer utan att förvandla tidiga experiment till produktionsskuld.