13 aug. 2025·6 min
Koncept för distribuerade system: Kleppmann‑idéer för SaaS‑skalning
Koncept för distribuerade system förklarade genom de verkliga val team gör när en prototyp blir en pålitlig SaaS: dataflöde, konsistens och flödeskontroll.
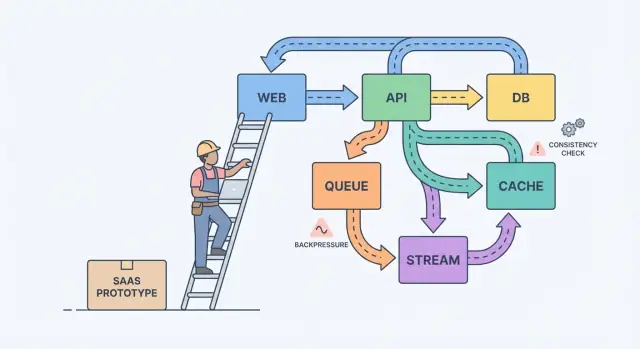
Från prototyp till SaaS: där förvirringen börjar
En prototyp bevisar en idé. En SaaS måste klara verklig användning: trafiktoppar, rörig data, retries och kunder som märker varje hack. Där blir det förvirrande, för frågan flyttas från "fungerar det?" till "fortsätter det fungera?"
Med riktiga användare räcker inte "det fungerade igår" av tråkiga skäl. Ett bakgrundsjobb körs senare än vanligt. En kund laddar upp en fil som är tio gånger större än testdata. En betalningsleverantör fastnar i 30 sekunder. Inget av detta är exotiskt, men ringarna på vattnet blir högljudda när delar av systemet beror på varandra.
Det mesta av komplexiteten visar sig på fyra områden: data (samma fakta finns på flera ställen och glider isär), latens (50 ms‑anrop blir ibland 5 sekunder), fel (timeouts, partiella uppdateringar, retries) och team (olika personer levererar olika tjänster på olika scheman).
En enkel mental modell hjälper: komponenter, meddelanden och tillstånd.
Komponenter gör arbete (webbapp, API, worker, databas). Meddelanden flyttar arbete mellan komponenter (requests, events, jobb). Tillstånd är vad du minns (beställningar, användarinställningar, betalningsstatus). Skalningsvärk kommer oftast av en mismatch: du skickar meddelanden snabbare än en komponent kan hantera, eller du uppdaterar tillstånd på två ställen utan en tydlig källa till sanning.
Ett klassiskt exempel är fakturering. En prototyp kan skapa en faktura, skicka e‑post och uppdatera en användares plan i en och samma förfrågan. Under belastning saktar e‑post ner, requesten timear ut, klienten försöker igen och nu har du två fakturor och en planändring. Pålitlighetsarbete handlar mest om att förhindra att sådana vardagsfel blir synliga buggar för kunden.
Gör koncept till dokumenterade beslut
De flesta system blir svårare för att de växer utan enighet om vad som måste vara korrekt, vad som bara behöver vara snabbt och vad som ska ske vid fel.
Börja med att rita en gräns runt vad ni lovar användarna. Inom den gränsen, namnge de åtgärder som måste vara korrekta varje gång (pengar, åtkomstkontroll, kontoägande). Skriv sedan ner vad som kan vara "eventuellt korrekt" (analysräknare, sökindex, rekommendationer). Denna uppdelning gör fuzzy teori till prioriteringar.
Nästa steg: skriv ner din source of truth. Det är där fakta skrivs en gång, hållbart, med tydliga regler. Allt annat är härlett data byggt för hastighet eller bekvämlighet. Om en härledd vy är korrupt ska du kunna återskapa den från source of truth.
När team kör fast, dyker ofta dessa frågor upp och avslöjar vad som betyder något:
- Vilken data får aldrig gå förlorad, även om det saktar ner?
- Vad kan återskapas från annan data, även om det tar timmar?
- Vad får vara föråldrat, och hur länge, ur en användares perspektiv?
- Vilket fel är värst för er: dubbletter, saknade events eller förseningar?
Om en användare uppdaterar sin betalplan kan en dashboard hänga efter. Men du kan inte tolerera att betalstatus och faktisk åtkomst inte stämmer överens.
Strömmar, köer och loggar: välj rätt form för arbete
Om en användare klickar och måste se resultatet direkt (spara profil, ladda dashboard, kontrollera behörighet) räcker oftast en vanlig request‑response API. Håll det direkt.
Så snart arbete kan göras senare, flytta det till async. Tänk att skicka mail, debitera kort, generera rapporter, ändra storlek på uppladdningar eller synka data till sök. Användaren ska inte vänta, och ditt API ska inte blockeras medan dessa körs.
En kö är en att‑göra‑lista: varje uppgift bör hanteras en gång av en worker. En stream (eller logg) är en register: events bevaras i ordning så flera läsare kan replaya dem, komma ikapp eller bygga nya funktioner senare utan att ändra producenten.
En praktisk väg att välja:
- Använd request‑response när användaren behöver ett omedelbart svar och arbetet är litet.
- Använd en kö för bakgrundsjobb med retries där bara en worker ska utföra varje jobb.
- Använd en stream/logg när du behöver replay, revisionsspår eller flera konsumenter som inte ska kopplas till en enda tjänst.
Exempel: din SaaS har en "Create invoice"‑knapp. API‑tjänsten validerar indata och sparar fakturan i Postgres. Sedan hanterar en kö "skicka faktura‑mail" och "debitera kort". Om du senare lägger till analytics, notifieringar och bedrägerikontroller, låter en stream av InvoiceCreated varje funktion prenumerera utan att göra kärntjänsten till en labyrint.
Eventdesign: vad du publicerar och vad du sparar
När produkten växer slutar events vara "bra att ha" och blir ett skyddsnät. Bra eventdesign handlar om två frågor: vilka fakta sparar du, och hur kan andra delar reagera utan att gissa?
Börja med en liten uppsättning affärsevenemang. Välj ögonblick som betyder något för användare och pengar: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Namnen lever längre än koden. Använd dåtid för fullbordade fakta, håll dem specifika och undvik UI‑formuleringar. PaymentSucceeded förblir meningsfullt även om du senare lägger till kuponger, retries eller flera betalningsleverantörer.
Behandla events som kontrakt. Undvik en catch‑all som "UserUpdated" med en salig blandning fält som ändras varje sprint. Föredra det minsta faktum du kan stå bakom i flera år.
För att utveckla säkert, föredra additiva ändringar (nya valfria fält). Om du behöver en brytande förändring, publicera ett nytt eventnamn (eller tydlig version) och kör båda tills gamla konsumenter försvunnit.
Vad ska du lagra? Om du bara behåller senaste raderna i en databas tappar du historien om hur du kom dit.
Råa events är utmärkta för audit, replay och felsökning. Snapshots är utmärkta för snabba läsningar och snabb återställning. Många SaaS‑produkter använder båda: spara råa events för nyckelflöden (fakturering, behörigheter) och håll snapshots för användargränssnittet.
Konsistensavvägningar som användarna faktiskt känner
Designa events som kontrakt
Implementera stabila affärshändelser som PaymentSucceeded så du kan replaya och återställa.
Konsistens visar sig i ögonblick som: "Jag ändrade min plan, varför står det fortfarande Free?" eller "Jag skickade en inbjudan, varför kan inte min kollega logga in än?"
Stark konsistens betyder att när du får ett lyckat svar ska varje skärm omedelbart visa det nya tillståndet. Eventuell konsistens betyder att förändringen sprids över tid, och under ett kort fönster kan olika delar av appen vara oense. Ingen är "bättre". Du väljer baserat på skadan en mismatch kan orsaka.
Stark konsistens passar ofta pengar, åtkomst och säkerhet: debitera kort, ändra lösenord, återkalla API‑nycklar, upprätthålla platsgränser. Eventuell konsistens passar ofta aktivitetsflöden, sök, analys‑dashboards, "senast sedd" och notifieringar.
Om du accepterar föråldrat innehåll, designa för det istället för att dölja det. Håll UI ärligt: visa ett "Uppdaterar…"‑läge efter en skrivning tills bekräftelse kommer, erbjud manuell uppdatering för listor och använd optimistisk UI bara när du kan rulla tillbaka rent.
Retries är där konsistens blir lismande. Nätverk faller, klienter dubbelklickar och workers startar om. För viktiga operationer, gör begäranden idempotenta så att upprepningar inte skapar två fakturor, två inbjudningar eller två återbetalningar. Ett vanligt tillvägagångssätt är en idempotency‑nyckel per åtgärd plus en serversida‑regel som returnerar ursprungligt resultat vid upprepningar.
Backpressure: att hindra systemet från att smälta ner
Backpressure behövs när requests eller events anländer snabbare än systemet kan hantera. Utan det staplas arbete i minnet, köer växer och den långsammaste beroenden (ofta databasen) bestämmer när allt fallerar.
Enkelt uttryckt: producenten fortsätter prata medan konsumenten drunknar. Om du fortsätter acceptera mer arbete blir det inte bara långsammare. Du triggar en kedja av timeouts och retries som multiplicerar belastningen.
Varningssignalerna syns oftast innan ett outage: backloggen växer konstant, latensen hoppar efter toppar eller deploys, retries ökar med timeouts, orelaterade endpoints fallerar när en beroende blir långsam och databasanslutningar sitter i taket.
När du når den punkten, välj en tydlig regel för vad som händer när du är full. Målet är inte att processa allt till vilket pris som helst. Det är att överleva och återhämta sig snabbt. Team börjar oftast med en eller två kontroller: rate limits (per användare eller API‑nyckel), begränsade köer med definierad drop/fördröjnings‑policy, circuit breakers för felande beroenden och prioriteter så interaktiva requests vinner över bakgrundsjobb.
Skydda databasen först. Håll connection pools små och förutsägbara, sätt query‑timeouts och lägg hårda gränser på dyra endpoints som ad‑hoc‑rapporter.
En steg‑för‑steg‑väg till tillförlitlighet (utan att skriva om allt)
Tillförlitlighet kräver sällan stora omskrivningar. Det kommer oftast från ett par beslut som gör fel synliga, begränsade och återställbara.
Börja med flöden som ger eller tar bort förtroende, och bygg säkerhetsräcken innan du lägger till funktioner:
-
Mappa kritiska vägar. Skriv ner exakta steg för signup, login, lösenordsåterställning och betalflöden. För varje steg, lista dess beroenden (databas, e‑postleverantör, background worker). Detta tvingar fram klarhet om vad som måste vara omedelbart kontra vad som kan fixas "efterhand".
-
Lägg till grundläggande observability. Ge varje request ett ID som syns i loggar. Spåra en liten uppsättning mätvärden som matchar användarens smärta: felrate, latens, ködjup och långsamma frågor. Lägg till traces bara där requests korsar tjänster.
-
Isolera långsamt eller risigt arbete. Allt som pratar med en extern tjänst eller regelbundet tar mer än en sekund bör flyttas till jobb och workers.
-
Designa för retries och partiella fel. Anta att timeouts händer. Gör operationer idempotenta, använd backoff, sätt tidsgränser och håll användaråtgärder korta.
-
Öva återställning. Backups betyder bara något om du kan återställa dem. Använd små releaser och ha en snabb rollback‑väg.
Om ditt verktyg stöder snapshots och rollback (Koder.ai gör), bygg det i vanliga release‑rutiner istället för att behandla det som ett nödknep.
Exempel: att göra en liten SaaS pålitlig
Prototypa tillförlitlighetsmönster
Prototypa de asynkrona jobben och retry-mönstren ditt produktionssystem behöver utan att sakta ner.
Föreställ dig en liten SaaS som hjälper team att onboarda nya kunder. Flödet är enkelt: en användare registrerar sig, väljer en plan, betalar och får ett välkomstmail plus några "kom igång"‑steg.
I prototypen händer allt i en request: skapa konto, debitera kort, markera "paid" på användaren, skicka mail. Det fungerar tills trafiken växer, retries sker och externa tjänster blir långsamma.
För att göra det pålitligt förvandlar teamet nyckelåtgärder till events och håller en append‑only‑historik. De introducerar några events: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Det ger dem ett revisionsspår, förenklar analytics och låter långsamt arbete köras i bakgrunden utan att blockera signup.
Några val gör mest arbete:
- Behandla betalningar som källan till sanningen för åtkomst, inte en enda "paid"‑flagga.
- Ge entitlements från
PaymentSucceededmed en tydlig idempotency‑nyckel så retries inte dubbelger access. - Skicka mail från en kö/worker, inte från checkout‑requesten.
- Spela in events även om en handler misslyckas, så du kan replaya och återställa.
- Lägg timeouts och en circuit breaker runt externa leverantörer.
Om betalning lyckas men åtkomst inte är beviljad än, känner användarna sig lurade. Lösningen är inte "perfekt konsistens överallt". Det är att bestämma vad som måste vara konsekvent nu och spegla det i UI med ett tillstånd som "Aktiverar din plan" tills EntitlementGranted landar.
På en dålig dag gör backpressure skillnaden. Om e‑post‑API:et hänger under en kampanj, timear den gamla designen ut checkout och användare försöker igen, vilket skapar dubbla debiteringar och dubbla mail. I den bättre designen lyckas checkout, e‑postförfrågningar köas och en replay‑job rensar backloggen när leverantören återhämtar sig.
Vanliga fallgropar när systemen skalar
De flesta outage beror inte på en heroisk bug. De kommer från små beslut som var rimliga i en prototyp och sedan blev vanor.
En vanlig fallgrop är att dela upp i mikrotjänster för tidigt. Du får tjänster som mest pratar med varandra, otydligt ägarskap och ändringar som kräver fem deploys istället för en.
En annan är att använda "eventual consistency" som ett gratispass. Användare bryr sig inte om termen; de bryr sig om att de klickade Spara och senare visar sidan gammal data, eller att en fakturastatus hoppar fram och tillbaka. Om du accepterar fördröjning måste du fortfarande ge användaren feedback, timeouter och en definition av "tillräckligt bra" på varje skärm.
Andra återkommande misstag: publicera events utan en reprocessing‑plan, obegränsade retries som multiplicerar belastning under incidenter och låta varje tjänst prata direkt mot samma databasschema så en ändring bryter många team.
Snabba kontroller innan du kallar det "production ready"
Äg din stack
Behåll fullt ägande genom att exportera källkoden när du vill köra den var som helst.
"Production ready" är ett antal beslut du kan peka på klockan 02:00. Klarhet slår listighet.
Börja med att namnge dina sources of truth. För varje nyckeltyp av data (kunder, abonnemang, fakturor, behörigheter) bestäm var slutgiltig post ligger. Om din app läser "sanningen" från två ställen kommer du förr eller senare visa olika svar för olika användare.
Titta sedan på retries. Anta att varje viktig åtgärd kommer köras två gånger någon gång. Om samma request träffar systemet två gånger, kan du undvika dubbla debiteringar, dubbla utskick eller dubbla skapanden?
En liten checklista som fångar de flesta smärtsamma felen:
- För varje datatyp kan du peka på en source of truth och namnge vad som är härlett.
- Varje viktig skrivning är säker att köra om (idempotency‑nyckel eller unik constraint).
- Ditt asynkrona arbete kan inte växa utan gräns (du övervakar lagg, äldsta meddelandeålder och larmar innan användare märker det).
- Du har en plan för förändring (reversibla migrationer, event‑versionering).
- Du kan rulla tillbaka och återställa med förtroende eftersom du övat.
Nästa steg: fatta ett beslut i taget
Skalning blir lättare när du behandlar systemdesign som en kort lista val, inte en hög teori.
Skriv ner 3–5 beslut du förväntar dig att möta nästa månad, på enkelt språk: "Flyttar vi e‑post till bakgrundsjobb?" "Accepterar vi något föråldrade analytics?" "Vilka åtgärder måste vara omedelbart konsekventa?" Använd listan för att få produkt och engineering i linje.
Välj sedan ett workflow som är synkront idag och konvertera bara det till async. Kvitton, notifieringar, rapporter och filbearbetning är vanliga första steg. Mät två saker före och efter: användarupplevd latens (kändes sidan snabbare?) och felbeteende (skapade retries dubbletter eller förvirring?).
Om du vill prototypa dessa förändringar snabbt kan Koder.ai (koder.ai) vara användbart för att iterera på en React + Go + PostgreSQL SaaS samtidigt som snapshots och rollback hålls nära till hands. Måttet är enkelt: skicka en förbättring, lär av verklig trafik, och bestäm nästa steg.
Vanliga frågor
Vad är den verkliga skillnaden mellan en prototyp och en produktions‑SaaS?
En prototyp svarar på "kan vi bygga det?" En SaaS måste svara på "kommer det fortsätta fungera när användare, data och fel dyker upp?"
Största förändringen är att designa för:
- långsamma beroenden (e‑post, betalningar, filbearbetning)
- retries och dubbletter
- data som växer och blir rörig
- tydliga regler för vad som måste vara korrekt vs vad som kan vara lite föråldrat
Hur bestämmer jag vad som måste vara starkt konsekvent kontra eventualt konsekvent?
Välj en gräns för vad du lovar användarna, och märk upp åtgärder efter påverkan.
Börja med måste vara korrekt varje gång:
- debitering/återbetalning
- åtkomstkontroll och entitlements
- kontoägarskap och säkerhetsåtgärder
Markera sedan kan vara eventualt korrekt:
Vad betyder "source of truth" i en SaaS, och hur väljer jag den?
Välj en plats där varje "faktum" skrivs en gång och betraktas som slutgiltigt (för en liten SaaS är det ofta Postgres). Det är din source of truth.
Allt annat är härlett för snabbhet eller bekvämlighet (cachar, read models, sökindex). Ett bra test: om härlett data är fel, kan du återskapa det från källan utan att gissa?
När ska jag flytta arbete till asynkront istället för att behålla det i API‑requesten?
Använd request‑response när användaren behöver ett omedelbart svar och arbetet är litet.
Flytta till async när det kan köras senare eller är långsamt:
- skicka e‑post
- debitera kort (ofta efter validering)
- generera rapporter
- filbearbetning
Async håller ditt API snabbt och minskar timeouts som triggar klientretries.
Vad är skillnaden mellan en kö och en stream, och vilken ska jag använda?
En kö är en att‑göra‑lista: varje jobb bör hanteras en gång av en worker (med retries).
En stream/logg är en ordnad händelseström: flera konsumenter kan replaya den för att bygga funktioner eller återställa.
Praktiskt standard:
- kö för bakgrundsuppgifter ("skicka välkomstmail")
- stream/logg för affärshändelser du kan vilja replaya eller auditera ("PaymentSucceeded")
Hur förhindrar jag dubbla debiteringar eller dubbla fakturor när retries sker?
Gör viktiga åtgärder idempotenta: att upprepa samma request ska ge samma utfall, inte skapa en andra faktura eller debitering.
Vanligt mönster:
- klient skickar en idempotency‑nyckel per åtgärd
- servern sparar resultatet indexerat på den nyckeln
- upprepningar returnerar det ursprungliga resultatet
Använd också unika constraint där det går (t.ex. en faktura per order).
Vad gör ett event väl utformat när min produkt växer?
Publicera en liten uppsättning stabila affärsfakta, namngivna i dåtid, som PaymentSucceeded eller SubscriptionStarted.
Håll events:
- specifika (undvik "UserUpdated" som allt i ett)
- hållbara (behandla som ett kontrakt)
- lätta att vidareutveckla (lägg till valfria fält; vid brytande förändring publicera ett nytt namn/version)
Det gör att konsumenter slipper gissa vad som hänt.
Vilka varningssignaler visar att jag behöver backpressure, och vad bör jag implementera först?
Vanliga tecken att du behöver backpressure:
- köbackloggen växer konstant
- latensen skjuter i höjden efter trafiktoppar eller deploys
- retries ökar på grund av timeouts
- en långsam beroende gör att orelaterade endpoints fallerar
- databasanslutningar når gränsen
Bra första kontroller:
Vilken observabilitet behöver jag innan jag skalar vidare?
Börja med det som matchar användarnas smärta:
- en request‑ID som syns i loggarna end‑to‑end
- mätvärden för felrate, latens, ködjup och långsamma frågor
- alerts för "äldsta meddelandeålder" i köer (inte bara storlek)
Lägg till tracing där förfrågningar korsar tjänster; instrumentera inte allt innan du vet vad du söker.
Vad bör finnas på min "production ready"‑checklista innan riktiga användare kommer?
"Produktionsredo" är en uppsättning beslut du kan peka på mitt i natten. Klarhet slår finess.
En kort checklista som fångar de flesta smärtsamma fel:
- för varje datatyp kan du peka på en source of truth och säga vad som är härlett
- varje viktig skrivning är säker att köra om (idempotency‑nyckel eller unik constraint)
- asynkront arbete kan inte växa obehindrat (du övervakar lagg/äldsta meddelandeålder)
- du har en plan för förändring (reversibla migrationer, event‑versionering)
- du kan rulla tillbaka och återställa eftersom du har övat