03 nov. 2025·8 min
Leslie Lamport och distribuerade system: tid, ordning, korrekthet
Lär dig Lamports centrala idéer för distribuerade system—logiska klockor, ordning, konsensus och korrekthet—och varför de fortfarande styr modern infrastruktur.
Varför Lamport fortfarande spelar roll för moderna distribuerade system
Leslie Lamport är en av de få forskarna vars "teoretiska" arbete visar sig varje gång du levererar ett riktigt system. Om du någonsin har driftat en databaskluster, en meddelandekö, en workflow-motor eller något som försöker om igen och överlever fel, så har du levt i problemlandskapet som Lamport hjälpte namnge och lösa.
Det som gör hans idéer hållbara är att de inte är bundna till en viss teknik. De beskriver de obekväma sanningarna som uppstår när flera maskiner försöker agera som ett system: klockor stämmer inte överens, nätverk fördröjer och tappar paket, och fel är norm — inte undantag.
Tre teman vi använder genomgående
Tid: I ett distribuerat system är "vad är klockan?" ingen enkel fråga. Fysiska klockor driver isär, och den ordning du ser händelser i kan skilja sig mellan maskiner.
Ordning: När du inte kan lita på en enda klocka behöver du andra sätt att prata om vilka händelser som skedde först — och när du måste tvinga alla att följa samma sekvens.
Korrekthet: "Det funkar oftast" är ingen design. Lamport drev fältet mot tydliga definitioner (safety vs. liveness) och specifikationer du kan resonera kring, inte bara testa.
Vad du kan förvänta dig (ingen tung matematik)
Vi fokuserar på koncept och intuition: problemen, de minsta verktygen för att tänka klart, och hur de verktygen formar praktisk design.
Här är kartan:
- Varför ingen delad klocka betyder ingen enda global berättelse om händelser
- Hur kausalitet ("happened-before") leder till logiska klockor och Lamport-tidsstämplar
- När partiell ordning inte räcker och du behöver en tidslinje
- Hur konsensus och Paxos hänger ihop med att enas om en ordning
- Varför state machine replication fungerar när ordningen delas
- Hur du pratar om korrekthet i specifikationer — och hur modelleringsverktyg som TLA+ hjälper
Kärnproblemet: Ingen delad klocka, ingen enhetlig verklighet
Ett system är "distribuerat" när det består av flera maskiner som koordinerar över ett nätverk för att göra ett jobb. Det låter enkelt tills du accepterar två fakta: maskiner kan falla oberoende (partiella fel), och nätverket kan fördröja, tappa, duplicera eller omordna meddelanden.
I ett enda program på en dator kan du oftast peka på "vad som hände först." I ett distribuerat system kan olika maskiner observera olika sekvenser av händelser — och båda kan vara korrekta från deras lokala synvinkel.
Varför du inte kan lita på en global klocka
Det är frestande att lösa koordination genom att tidsstämpla allt. Men det finns ingen enkel klocka du kan förlita dig på över maskinerna:
- Varje servers hårdvaruklocka driver i sin egen takt.
- Klocksynkronisering (som NTP) är best-effort, inte en garanti.
- Virtualisering, CPU-belastning eller pauser kan få tiden att hoppa eller stanna.
Så "händelse A skedde kl 10:01:05.123" på en värd kan inte pålitligt jämföras med "10:01:05.120" på en annan.
Hur fördröjningar rör till verkligheten
Nätverksfördröjningar kan vända på vad du trodde du sett. En skrivning kan skickas först men anlända som andra. En retry kan komma efter originalet. Två datacenter kan behandla samma begäran i motsatta ordningar.
Det här gör felsökning särskilt förvirrande: loggar från olika maskiner kan motsäga varandra, och "sortera efter tidsstämpel" kan skapa en berättelse som aldrig faktiskt inträffade.
Verkliga konsekvenser
När du antar en enda tidslinje som inte finns, får du konkreta fel:
- Dubbelbearbetning (en betalning debiteras två gånger efter retries)
- Inkonsistenser (två användare hävdar båda framgångsrikt att de tog det sista föremålet)
- Förefallen dataförlust (en senare ankommande uppdatering skriver över en nyare)
Lamports centrala insikt börjar här: om du inte kan dela tid, måste du resonera om ordning annorlunda.
Kausalitet och happened-before-relationen
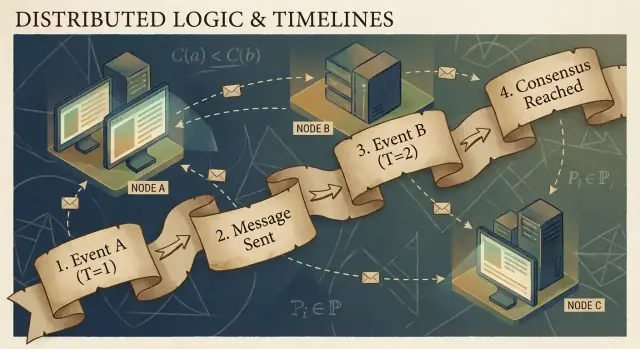
Distribuerade program består av händelser: något som händer på en viss nod (en process, server eller tråd). Exempel är "tog emot en begäran", "skrev en rad" eller "skickade ett meddelande". Ett meddelande är länken mellan noder: en händelse är en skick-händelse, en annan är mottag-händelsen.
Lamports nyckelinsikt är att i ett system utan en pålitlig delad klocka är det mest tillförlitliga du kan spåra kausalitet — vilka händelser som kan ha påverkat vilka andra händelser.
Happened-before-relationen (→)
Lamport definierade en enkel regel kallad happened-before, skriven som A → B (händelsen A hände före händelsen B):
- Samma process-ordning: Om A och B inträffar på samma maskin/process, och A observeras ske först i den processen, då A → B.
- Meddelandeordning: Om A är "skickade meddelandet m" och B är "mottog meddelandet m", då A → B.
- Transitivitet: Om A → B och B → C, då A → C.
Denna relation ger dig en partiell ordning: den säger vilka par som är ordnade, men inte alla.
En konkret berättelse: användare → begäran → DB → cache
En användare klickar "Köp." Klicket triggar en begäran till en API-server (händelse A). Servern skriver en orderrad i databasen (händelse B). Efter att skrivningen slutförts publicerar servern ett "order created"-meddelande (händelse C), och en cache-tjänst tar emot det och uppdaterar en cachepost (händelse D).
Här gäller A → B → C → D. Även om klockorna inte stämmer överens, skapar meddelande- och programstrukturen verkliga kausala länkar.
Vad "konkurrerande" egentligen betyder
Två händelser är konkurrerande när ingen orsak-verkan- relation binder dem: inte (A → B) och inte (B → A). Konkurrens betyder inte "samma tid" — det betyder "ingen kausal väg förbinder dem." Därför kan två tjänster båda hävda att de agerade "först", och båda kan ha rätt om du inte lägger till en ordningsregel.
Logiska klockor: Lamport-tidsstämplar på enkelt språk
Om du någon gång försökt återskapa "vad som hände först" över flera maskiner, har du stött på grundproblemet: datorer delar inte en perfekt synkroniserad klocka. Lamports lösning är att sluta jaga perfekt tid och istället spåra ordning.
Idén: en räknare kopplad till varje händelse
En Lamport-tidsstämpel är bara ett nummer du fäster vid varje meningsfull händelse i en process (en tjänsteinstans, en nod, en tråd — vad du än väljer). Tänk på det som en "händelseräknare" som ger dig ett konsekvent sätt att säga "den här händelsen skedde före den där", även när väggklockan är opålitlig.
De två reglerna (de är verkligen så enkla)
-
Öka lokalt: innan du registrerar en händelse (t.ex. "skrev till DB", "skickade begäran", "appenderade loggpost"), öka din lokala räknare.
-
Vid mottagning, ta max + 1: när du tar emot ett meddelande som innehåller avsändarens tidsstämpel, sätt din räknare till:
max(local_counter, received_counter) + 1
Stämpla sedan mottagandehändelsen med det värdet.
Dessa regler säkerställer att tidsstämplar respekterar kausalitet: om händelse A kunde ha påverkat händelse B (eftersom information flödade via meddelanden), kommer A:s tidsstämpel att vara mindre än B:s.
Vad Lamport-tidsstämplar kan — och inte kan — berätta
De kan berätta om kausal ordning:
- Om
TS(A) < TS(B), så kan A ha hänt före B. - Om A orsakade B (direkt eller indirekt), så är det nödvändigtvis
TS(A) < TS(B).
De kan inte berätta om klocktid i verkligheten:
- En lägre tidsstämpel betyder inte "tidigare i sekunder."
- Två händelser kan vara konkurrerande (inga orsakskedjor) och ändå få olika tidsstämplar på grund av meddelandemönster.
Så Lamport-tidsstämplar är utmärkta för ordning, inte för att mäta latens eller svara på "vad var klockslaget?"
Praktiskt exempel: ordna loggposter över tjänster
Föreställ dig att Tjänst A anropar Tjänst B, och båda skriver revisionsloggar. Du vill ha en enhetlig loggvy som bevarar orsak-och-effekt.
- Tjänst A ökar sin räknare, loggar "startar betalning", skickar begäran till B med tidsstämpeln 42.
- Tjänst B tar emot begäran med 42, sätter sin räknare till
max(local, 42) + 1, säg 43, och loggar "validerade kort". - B svarar med 44; A tar emot, uppdaterar till 45, och loggar "betalning slutförd".
När du nu aggregerar loggar från båda tjänsterna, ger sortering efter (lamport_timestamp, service_id) en stabil, förklarlig tidslinje som matchar den faktiska kedjan av påverkan — även om väggklockorna driver isär eller nätverket fördröjer meddelanden.
Från partiell ordning till total ordning: när du behöver en tidslinje
Kausalitet ger dig en partiell ordning: vissa händelser är klart "före" andra (eftersom ett meddelande eller beroende kopplar dem), men många händelser är helt enkelt konkurrerande. Det är inte ett fel — det är den naturliga formen av distribuerad verklighet.
Partiell ordning: tillräckligt för många frågor
Om du felsöker "vad kunde ha påverkat det här?" eller upprätthåller regler som "ett svar måste följa sin begäran", är partiell ordning precis vad du vill ha. Du behöver bara respektera happened-before-kanterna; allt annat kan behandlas som oberoende.
Total ordning: nödvändig när systemet måste välja en berättelse
Vissa system kan inte leva med "antingen ordningen är okej." De behöver en enkel sekvens av operationer, särskilt för:
- Skrivningar till ett delat objekt ("sätt saldo", "uppdatera profil", "appendera till logg")
- Kommandon som måste tillämpas identiskt överallt (state machine replication)
- Konflikthantering där "senast skriva vinner" måste betyda samma sak för varje nod
Utan en total ordning kan två repliker vara "korrekta" lokalt men avvika globalt: en applicerar A sedan B, en annan applicerar B sedan A, och du får olika resultat.
Hur får du en tidslinje?
Du inför en mekanism som skapar ordning:
- En sekvenserare/ledare som tilldelar en monotoniskt ökande position till varje kommando.
- Eller konsensus (t.ex. Paxos-liknande tillvägagångssätt) så att klustret enas om nästa loggpost även vid fördröjningar och fel.
De avvägningar du inte kan undvika
En total ordning är kraftfull, men den kostar:
- Latens: du kan behöva vänta på koordinering innan commit.
- Genomströmning: en enda ordnad logg kan bli en flaskhals.
- Tillgänglighet vid fel: om du inte når tillräckligt många noder för att enas kan framsteg stanna för att skydda korrektheten.
Designbeslutet är enkelt att formulera: när korrekthet kräver en gemensam berättelse betalar du koordinationskostnader för att få den.
Konsensus: att enas trots fördröjning och fel
Bygg en ordnings-demo
Förvandla dina ordningsidéer till en fungerande Go-tjänst och iterera från en enkel chatt.
Konsensus är problemet att få flera maskiner att gå med på ett beslut — ett värde att committa, en ledare att följa, en konfiguration att aktivera — trots att varje maskin bara ser sina lokala händelser och de meddelanden som råkat anlända.
Det låter enkelt tills du minns vad ett distribuerat system tillåts göra: meddelanden kan fördröjas, dupliceras, omordnas eller tappas; maskiner kan krascha och starta om; och du får sällan en tydlig signal om att "den här noden är definitivt död." Konsensus handlar om att göra överenskommelsen säker under dessa förhållanden.
Varför överenskommelse är knepigt
Om två noder tillfälligt inte kan kommunicera (nätverkspartition), kan varje sida försöka "gå vidare" på egen hand. Om båda sidor fattar olika beslut kan du hamna i split-brain: två ledare, två konfigurationer eller två konkurrerande historiker.
Även utan partitioner ställer fördröjning till problem. När en nod hör om ett förslag kan andra noder redan ha gått vidare. Utan delad klocka kan du inte pålitligt säga "förslag A hände före förslag B" bara för att A har en tidigare tidsstämpel — fysisk tid är inte auktoritativ här.
Var du möter konsensus i verkliga system
Du kanske inte säger "konsensus" i vardagen, men det visar sig i vanliga infrastrukturuppgifter:
- Ledareval (vem bestämmer just nu?)
- Replikerade loggar (vad är nästa post i den delade historiken?)
- Konfigurationsändringar (vilken uppsättning noder får rösta/committa?)
I varje fall behöver systemet ett enda utfall som alla kan konvergera till, eller åtminstone en regel som förhindrar att motstridiga utfall båda räknas som giltiga.
Paxos som Lamports svar
Lamports Paxos är en grundläggande lösning på problemet om "säker överenskommelse." Nyckelidén är inte en magisk timeout eller en perfekt ledare — det är en mängd regler som säkerställer att endast ett värde kan väljas, även när meddelanden är sena och noder fallerar.
Paxos separerar safety ("väljs aldrig två olika värden") från progress ("väljs så småningom något"), vilket gör det till en praktisk ritning: du kan trimma för verklig prestanda samtidigt som du behåller kärngarantin.
Paxos, utan huvudvärk: den viktigaste säkerhetsintuitionen
Paxos har rykte om sig att vara svårgenomträngligt, men mycket av det beror på att "Paxos" inte är ett enda enkelt algoritmrecept. Det är en familj av närliggande mönster för att få en grupp att enas, även när meddelanden fördröjs, dupliceras eller noder tillfälligt fallerar.
Rollistan: föreslagare, acceptorer och quorums
En hjälpsam mentalt modell är att separera vem som föreslår från vem som validerar.
- Föreslagare (proposers) försöker få ett värde valt (t.ex. "nästa loggpost är X").
- Acceptorer röstar om förslag.
- Ett quorum är "tillräckligt många acceptorer" för att göra framsteg — typiskt en majoritet.
Den ena strukturella idén att hålla i minnet: alla två majoriteter överlappar. Det är i den överlappningen säkerheten bor.
Säkerhetsmålet: välj aldrig två olika värden
Paxos-säkerhet är enkel att formulera: när systemet väl har beslutat ett värde får det aldrig besluta ett annat — inget split-brain.
Nyckelintuitionen är att förslag bär nummer (tänk: ballot-ID). Acceptorer lovar att ignorera äldre-numrerade förslag när de sett ett nyare. När en föreslagare försöker med ett nytt nummer frågar den först ett quorum vad de redan har accepterat.
Eftersom quorumen överlappar kommer en ny föreslagare oundvikligen att höra från minst en acceptor som "kommer ihåg" det senaste accepterade värdet. Regeln är: om någon i quorumen accepterade något måste du föreslå det värdet (eller det nyaste av dem). Den begränsningen är vad som förhindrar att två olika värden väljs.
Liveness, på hög nivå
Liveness betyder att systemet så småningom bestämmer något under rimliga förhållanden (till exempel att en stabil ledare uppstår och nätverket så småningom levererar meddelanden). Paxos lovar inte snabbhet i kaos; det lovar korrekthet och framsteg när förhållandena lugnar sig.
State Machine Replication: korrekthet genom delad ordning
Finansiera dina experiment
Få krediter genom att dela det du bygger på Koder.ai eller bjuda in kollegor att testa.
State machine replication (SMR) är mönstret bakom många högtillgängliga system: istället för att en server fattar beslut kör du flera repliker som alla bearbetar samma sekvens av kommandon.
Idén med replikerad logg
I centrum finns en replikerad logg: en ordnad lista av kommandon som "put key=K value=V" eller "överför $10 från A till B." Klienten skickar inte kommandon till varje replik och hoppas på det bästa. Den skickar kommandon till gruppen, och systemet enas om en ordning för de kommandona, sedan applicerar varje replik dem lokalt.
Varför ordning ger korrekthet
Om varje replik börjar från samma initialtillstånd och exekverar samma kommandon i samma ordning, kommer de att hamna i samma tillstånd. Det är den centrala safety-intuitionen: du försöker inte hålla flera maskiner "synkade" med hjälp av tid; du gör dem identiska genom determinism och delad ordning.
Det är därför konsensus (som Paxos/Raft-stil protokoll) ofta paras med SMR: konsensus bestämmer nästa loggpost, och SMR förvandlar det beslutet till ett konsekvent tillstånd över repliker.
Var du ser det i verkliga system
- Koordinationstjänster (t.ex. för konfiguration och ledareval)
- Databaser med replikerade write-ahead-loggar
- Meddelandesystem som kräver strikt partition-ordning
Praktiska frågor som ingenjörerna inte kan ignorera
Loggen växer för alltid om du inte hanterar den:
- Snapshots: ta periodvisa snapshots av aktuellt tillstånd så nya noder kan komma ikapp utan att spela upp hela historiken.
- Loggkomprimering: kassera säkert gamla loggposter när de finns reflekterade i ett snapshot och inte längre behövs.
- Ändringar i medlemskap: att lägga till/ta bort repliker måste också vara ordnat, annars kan olika noder vara oense om vem som är i gruppen och orsaka split-brain.
SMR är ingen magi; det är ett disciplinerad sätt att förvandla "överenskommelse om ordning" till "överenskommelse om tillstånd."
Korrekthet: safety, liveness och att skriva en tydlig specifikation
Distribuerade system går sönder på konstiga sätt: meddelanden anländer sent, noder startar om, klockor är osynkade och nätverk splittras. "Korrekthet" är inte en känsla — det är löften du kan uttrycka precist och sedan kontrollera mot varje situation, inklusive fel.
Safety vs. liveness (med konkreta exempel)
Safety betyder "inget dåligt händer någonsin." Exempel: i en replikerad key-value store får inte två olika värden committas för samma loggindex. Ett annat exempel: en låstjänst får aldrig tilldela samma lås till två klienter samtidigt.
Liveness betyder "något bra händer så småningom." Exempel: om majoriteten av repliker är uppe och nätverket så småningom levererar meddelanden, slutförs en skrivbegäran så småningom. En lånbegäran får till slut ja eller nej (inte oändlig väntan).
Safety handlar om att förhindra motsägelser; liveness handlar om att undvika permanenta stopp.
Invarians: dina icke-förhandlingsbara villkor
En invarians är ett villkor som alltid måste gälla i varje nåbar tillstånd. Exempel:
- "Varje loggindex har högst ett committat värde."
- "En ledares termnummer minskar aldrig."
Om en invarians kan brytas under en krasch, timeout, retry eller partition så var den inte korrekt upprätthållen.
Vad 'bevis' betyder här
Ett bevis är ett argument som täcker alla möjliga exekveringar, inte bara normala banan. Du resonerar om varje fall: meddelandeförlust, duplicering, omordning; nodkrascher och omstarter; konkurrerande ledare; klientretryer.
Specifikationer förhindrar överraskningar
En tydlig specifikation definierar tillstånd, tillåtna åtgärder och egenskaper som måste gälla. Det förhindrar tvetydiga krav som "systemet ska vara konsekvent" från att bli motsägelsefulla förväntningar. Specer tvingar dig att säga vad som händer under partitioner, vad "commit" betyder och vad klienter kan förlita sig på — innan produktionen lär dig på det hårda sättet.
Från teori till praktik: modellering med TLA+
En av Lamports mest praktiska lärdomar är att du kan (och ofta bör) designa ett distribuerat protokoll på en högre nivå än kod. Innan du oroar dig för trådar, RPC:er och retry-loopar kan du skriva ner systemets regler: vilka åtgärder som är tillåtna, vilket tillstånd som kan ändras och vad som aldrig får hända.
Vad TLA+ är till för
TLA+ är ett specifikationsspråk och en modellkontrolltool för att beskriva parallella och distribuerade system. Du skriver en enkel, matematisk modell av ditt system — tillstånd och övergångar — plus de egenskaper du bryr dig om (t.ex. "högst en ledare" eller "en committad post försvinner aldrig").
Sedan utforskar modelcheckern möjliga interleavingar, meddelandefördröjningar och fel för att hitta ett motexempel: en konkret sekvens av steg som bryter din egenskap. Istället för att debattera kantfall i möten får du ett exekverbart argument.
Ett buggexempel en modell kan fånga
Tänk dig ett "commit"-steg i en replikerad logg. I kod är det lätt att av misstag tillåta att två olika noder markerar två olika poster som committade på samma index under sällsynnta tidpunkter.
En TLA+-modell kan avslöja en spårning som:
- Nod A committar post X på index 10 efter att ha hört från ett quorum.
- Nod B (med föråldrade data) bildar också ett quorum och committar post Y på index 10.
Detta är en duplicate commit — ett safety-brott som kanske bara dyker upp en gång i månaden i produktion, men som dyker upp snabbt under utökad sökning. Liknande modeller fångar ofta förlorade uppdateringar, dubbla tillämpningar eller "ack men inte hållbart"-situationer.
När det är värt att modellera
TLA+ är mest värdefullt för kritisk koordineringslogik: ledareval, medlemskapsändringar, konsensusliknande flöden och alla protokoll där ordning och felhantering interagerar. Om en bugg skulle korrupta data eller kräva manuell återställning är en liten modell oftast billigare än att felsöka senare.
Om du bygger interna verktyg kring dessa idéer är ett praktiskt arbetsflöde att skriva en lättviktig spec (även informell), implementera systemet och generera tester från specens invarianskrav. Plattformar som Koder.ai kan hjälpa här genom att snabba upp build-test-loopen: du kan beskriva avsett ordnings-/konsensusbeteende i klartext, iterera på service-scaffolding (React-frontends, Go-backends med PostgreSQL eller Flutter-klienter) och hålla "vad som aldrig får hända" synligt medan du levererar.
Praktiska slutsatser för att bygga och drifta tillförlitliga system
Prototypa en replikerad logg
Prototypa ett replikerat logg-API med React-gränssnitt och en Go + PostgreSQL-backend.
Lamports stora gåva till praktiker är en mindset: behandla tid och ordning som data du modellerar, inte antaganden du ärvt från väggklockan. Denna inställning blir en uppsättning vanor du kan tillämpa direkt.
Gör teori till vardagsingenjörspraxis
Om meddelanden kan fördröjas, dupliceras eller anlända i fel ordning, designa varje interaktion så att den är säker under sådana villkor.
- Idempotens som standard: gör "gör om" ofarligt. Använd idempotensnycklar för betalningar, provisioning eller alla skrivningar du kan retrya.
- Retries med deduplicering: retries är nödvändiga, men utan deduplisering skapar du dubbla skrivningar. Spåra request-ID:n och lagra markörer för "redan behandlad".
- At-least-once delivery + exactly-once effekter: acceptera att nätverket kan leverera två gånger; se till att dina tillståndsändringar inte gör det.
Var försiktig med timeouts och klockor
Timeouts är inte sanning; de är policy. En timeout säger bara "jag hörde inte tillbaka i tid", inte "den andra sidan agerade inte." Två konkreta implikationer:
- Behandla inte en timeout som ett definitivt fel. Designa kompensationer och rekonsilieringsvägar.
- Undvik att använda lokal klocktid för att ordna händelser över noder. Använd sekvensnummer, monotona räknare eller explicit kausalt metadata (t.ex. "denna uppdatering ersätter version X").
Observabilitet som respekterar kausalitet
Bra felsökningsverktyg kodar ordning, inte bara tidsstämplar.
- Trace-IDs överallt: propagatera ett korrelations-/trace-ID genom varje hopp och loggrad.
- Kausala ledtrådar i loggar: logga meddelande-ID:n, föräldrarequest-ID:n och "vad jag trodde var senaste version" när du fattar beslut.
- Deterministiska uppspelningar: spela in inputs (kommandon) så att du kan spela upp beteendet och bekräfta om en bugg är tid-beroende eller logik-beroende.
Frågor att ställa innan du levererar
Innan du lägger till en distribuerad funktion, tvinga fram tydlighet med några frågor:
- Vad händer om samma begäran behandlas två gånger?
- Vilken ordning behöver vi ha (om någon), och var upprätthålls den?
- Vilka fel är "säkra" (inget dåligt tillstånd) vs. "högljudda" (synliga för användaren) vs. "tysta" (dold korruption)?
- Vad är återställningsvägen efter ett partiellt avbrott eller nätverkssplit?
- Vad kommer vi logga för att återskapa happened-before-berättelsen i produktion?
Dessa frågor kräver ingen doktorsexamen — bara disciplinen att behandla ordning och korrekthet som förstklassiga produktkrav.
Avslutning och föreslagna nästa steg
Lamports bestående gåva är ett sätt att tänka klart när system inte delar en klocka och inte per automatik är överens om "vad som hände." Istället för att jaga perfekt tid spårar du kausalitet (vad som kunde ha påverkat vad), representerar den med logisk tid (Lamport-tidsstämplar) och — när produkten kräver en enda historia — bygger överenskommelse (konsensus) så att varje replik applicerar samma sekvens av beslut.
Den tråden leder till en praktisk ingenjörsinställning:
Specifiera först, bygg sedan
Skriv ner reglerna du behöver: vad som aldrig får hända (safety) och vad som så småningom måste hända (liveness). Implementera sedan enligt den specen och testa systemet under fördröjningar, partitioner, retries, dubbla meddelanden och nodomstarter. Många "mystiska avbrott" beror på saknade uttalanden som "en begäran kan behandlas två gånger" eller "ledare kan bytas när som helst."
Lär dig vidare, med fokuserade steg
Om du vill gå djupare utan att drunkna i formalism:
- Läs Lamports "Time, Clocks, and the Ordering of Events in a Distributed System" för att internalisera happened-before.
- Skumma igenom "Paxos Made Simple" för säkerhetsintuitionen: när ett värde väljs kan framtida framsteg inte motsäga det.
- Titta på en introduktion till TLA+ och modellera sedan ett litet protokoll (en låstjänst eller ett register med två repliker) och kontrollera det.
Prova ett praktiskt övningsprojekt
Välj en komponent du äger och skriv ett en-sidigt "failure contract": vad du antar om nätverk och lagring, vilka operationer som är idempotenta, och vilka ordningsgarantier du erbjuder.
Om du vill göra övningen mer konkret, bygg en liten "ordningsdemo"-tjänst: ett request-API som appenderar kommandon till en logg, en bakgrundsarbetare som applicerar dem, samt en adminvy som visar kausalt metadata och retries. Att göra detta på Koder.ai kan vara ett snabbt sätt att iterera — särskilt om du vill ha snabb scaffolding, deploy/hosting, snapshots/rollback för experiment och möjlighet att exportera källkod när du är nöjd.
Görs väl minskar dessa idéer driftstopp eftersom färre beteenden är implicita. De förenklar också resonemang: du slutar bråka om tid och börjar bevisa vad ordning, överenskommelse och korrekthet faktiskt betyder för ditt system.