02 dec. 2025·8 min
Larry Pages ursprungliga AI-vision bakom Googles långsiktiga spel
Utforska hur Larry Pages tidiga idéer om AI och kunskap formade Googles långsiktiga strategi — från sökkvalitet till moonshots och AI-först-satsningar.
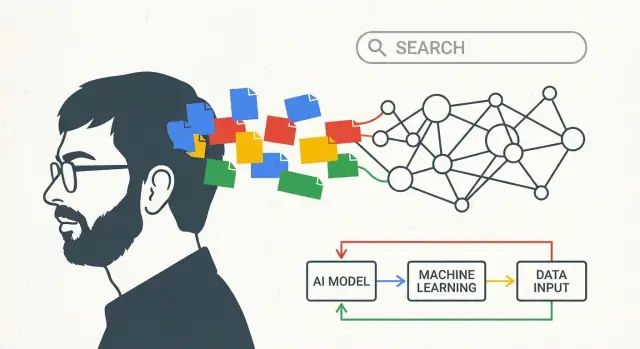
Vad den här texten menar med “Larry Pages AI-vision"
Det här är ingen hypande text om ett enda genombrott. Det handlar om långsiktigt tänkande: hur ett företag kan välja en riktning tidigt, fortsätta investera genom flera teknologiska skiften och långsamt förvandla en stor idé till vardagsprodukter.
När den här texten säger “Larry Pages AI-vision” menar den inte att “Google förutsåg dagens chattrobotar.” Det betyder något enklare — och mer hållbart: att bygga system som lär sig av erfarenhet.
En enkel definition
I den här texten syftar “AI-vision” på några sammanlänkade övertygelser:
- Datorer bör förbättra sin prestanda genom att lära av data, inte bara genom handskrivna regler.
- De bästa systemen blir bättre över tid eftersom verklig användning skapar återkoppling (vad folk klickar på, vad de ignorerar, vilka omformuleringar de gör).
- För att göra lärande praktiskt behöver du infrastruktur: snabb beräkning, pålitlig lagring och ett sätt att köra experiment säkert i stor skala.
Med andra ord handlar “visionen” mindre om en enskild modell och mer om en motor: samla signaler, lär mönster, leverera förbättringar, upprepa.
Bågen vi följer
För att göra idén konkret spårar resten av texten en enkel progression:
- Sök: börja med ett tydligt problem — hjälp människor att hitta bra svar.
- Data + infrastruktur: använd verklig användning för att lära vad “bra” betyder, och bygg maskineriet för att bearbeta det.
- AI-först-produkter: behandla lärande system som standardtillvägagångssätt, så röst, bilder och nya gränssnitt kan fungera bra utan att allt måste skrivas om från grunden.
I slutändan bör “Larry Pages AI-vision” kännas mindre som en slogan och mer som en strategi: investera tidigt i lärande system, bygg rören som matar dem, och ha tålamod medan framstegen byggs upp över år.
Problemet Google försökte lösa tidigt: hitta bra svar
Den tidiga webben hade ett enkelt problem med stora följder: plötsligt fanns det mycket mer information än någon person kunde sålla igenom, och de flesta sökverktyg gissade mer än de visste vad som var viktigt.
Om du skrev en fråga förlitade sig många motorer på uppenbara signaler — hur ofta ett ord förekom på en sida, om det stod i titeln, eller hur många gånger sajtägaren kunde stoppa in det i osynlig text. Det gjorde resultaten enkla att manipulera och svåra att lita på. Webben växte snabbare än verktygen för att organisera den.
PageRank, förklarat som en rekommendation
Larry Page och Sergey Brins nyckelinsikt var att webben redan innehöll ett inbyggt röstningssystem: länkar.
En länk från en sida till en annan är lite som en referens i en artikel eller en rekommendation från en vän. Inte alla rekommendationer är lika värdefulla. En länk från en sida som många andra anser värdefull bör räknas mer än en länk från en okänd sida. PageRank förvandlade den idén till matematik: istället för att ranka sidor bara efter vad de sa om sig själva, rankade Google sidor efter vad resten av webben “sa” om dem genom länkar.
Detta gjorde två viktiga saker samtidigt:
- Det hjälpte framlyfta auktoritativa sidor även när de inte upprepade exakta söktermer.
- Det gjorde rankningen svårare att manipulera, eftersom trovärdighet behövde förtjänas över nätverket av sajter.
Varför mätning och iteration var viktiga från dag ett
Det räckte inte att ha en smart rankningsidé. Sök är ett rörligt mål: nya sidor dyker upp, spam anpassar sig och vad folk menar med en fråga kan förändras.
Systemet måste därför vara mätbart och uppdateringsbart. Google lutade sig mot ständig testning — prova förändringar, mät om resultaten blev bättre och upprepa. Den vanan av iteration formade företagets långsiktiga syn på “lärande” system: behandla sök som något du kontinuerligt kan utvärdera, inte som ett engångsprojekt.
Data som ett svänghjul: lärande från verklig användning
Bra sök handlar inte bara om smarta algoritmer — det handlar om kvaliteten och mängden av signaler som dessa algoritmer kan lära sig från.
Tidiga Google hade en inneboende fördel: själva webben är full av “röster” om vad som betyder något. Länkar mellan sidor (grunden för PageRank) fungerar som referenser, och ankartext (“klicka här” vs. “bästa vandringskängor”) ger ytterligare mening. Därtill hjälper språkmönster över sidor ett system att förstå synonymer, stavningsvarianter och de många sätt människor ställer samma fråga på.
Återkopplingsslingan som bygger på sig själv
När människor börjar använda en sökmotor i skala skapar användningen ytterligare signaler:
- Klick visar vilka resultat som ser relevanta ut för riktiga användare för en given fråga.
- “Långa klick” kontra snabba tillbaka-till-resultaten kan indikera nöjdhet.
- Omformuleringar av frågor (söker igen med andra ord) kan avslöja felmatchningar mellan avsikt och resultat.
Detta är svänghjulet: bättre resultat lockar fler användare; mer användning skapar rikare signaler; rikare signaler förbättrar rankning och förståelse; och den förbättringen lockar ännu fler användare. Med tiden blir sök mindre som en fast uppsättning regler och mer som ett lärande system som anpassar sig efter vad människor faktiskt finner användbart.
Varför datamångfald spelar roll
Olika typer av data förstärker varandra. Länkstruktur kan visa auktoritet, medan klickbeteende speglar aktuella preferenser och språkdata hjälper tolka tvetydiga frågor (“jaguar” djuret vs. bilen). Tillsammans gör de det möjligt att svara inte bara på “vilka sidor innehåller dessa ord”, utan “vad är det bästa svaret för denna avsikt”.
En not om integritet
Detta svänghjul väcker uppenbara integritetsfrågor. Offentliga rapporter har länge noterat att stora konsumentprodukter genererar massiva interaktionsdata och att företag använder aggregerade signaler för att förbättra kvaliteten. Det är också väl dokumenterat att Google har investerat i integritets- och säkerhetskontroller över tid, även om detaljer och effektivitet är föremål för diskussion.
Poängen är enkel: att lära av verklig användning är kraftfullt — och förtroende beror på hur ansvarsfullt det lärandet hanteras.
Att bygga “maskinen”: infrastruktur som gjorde AI praktiskt
Google investerade inte tidigt i distribuerad beräkning för att det var trendigt — det var det enda sättet att hänga med i webbens stora skala. Om du vill crawla miljarder sidor, uppdatera rankningar ofta och svara på frågor på bråkdelen av en sekund kan du inte förlita dig på en enda stor dator. Du behöver tusentals billigare maskiner som arbetar tillsammans, med mjukvara som behandlar fel som normala.
Varför distribuerad beräkning var viktig tidigt
Sök tvingade Google att bygga system som kunde lagra och bearbeta enorma mängder data pålitligt. Samma “många datorer, ett system”-tänk blev grunden för allt som följde: indexering, analys, experimentering och så småningom maskininlärning.
Nyckelinsikten är att infrastruktur inte är frikopplad från AI — den bestämmer vilka typer av modeller som är möjliga.
Hur infrastruktur förvandlar AI från demo till produkt
Att träna en användbar modell betyder att visa den många verkliga exempel. Att köra modellen i produktion betyder att köra den för miljoner människor, direkt, utan avbrott. Båda är skalningsproblem:
- Träning kräver massiv compute för att bearbeta data upprepade gånger.
- Serva behöver låg-latenssystem för att göra prediktioner snabbt (ofta på millisekunder), även vid trafiktoppar.
När du väl byggt pipelines för att lagra data, distribuera beräkning, övervaka prestanda och rulla ut uppdateringar säkert, kan lärande system förbättras kontinuerligt snarare än att bara dyka upp som sällsynta, riskfyllda omskrivningar.
Enkla, vardagliga exempel på “AI som drivs av rörmokare”
Några välbekanta funktioner visar varför maskineriet spelade roll:
- Stavningskorrigering: lägga märke till mönster som “restarant” → “restaurant” kräver att man lär sig från många sökningar och klick och sedan tillämpar korrigeringar omedelbart vid frågetid.
- Autocomplete: att förutsäga vad du är på väg att skriva beror på aggregerat beteende och snabb inferens — annars känns förslagen långsamma och fel.
- Översättning: bättre översättningskvalitet kommer från att träna på stora dataset och leverera modeller som kan köras snabbt för användare världen över.
Googles långsiktiga fördel var inte bara att ha smarta algoritmer — det var att bygga den operativa motorn som lät algoritmer lära, skickas ut och förbättras i internet-skala.
Från regler till lärande: hur sök tyst blev mer “AI-likt”
Äg din leverans
Behåll kontrollen genom att exportera källkoden när du är redo att äga hela pipelinen.
Tidiga Google såg redan “smart” ut, men mycket av den intelligensen var konstruerad: länkanalys (PageRank), handjusterade rankningssignaler och många heuristiker för spam. Med tiden försköts tyngdpunkten från uttryckligen skrivna regler till system som lärde mönster från data — särskilt om vad människor menar, inte bara vad de skriver.
Hur ML förändrade sökupplevelsen
Maskininlärning förbättrade gradvis tre saker som vardagsanvändare märker:
- Rankningskvalitet: istället för att vikta signaler med fasta formler lärde modeller sig vilka kombinationer av signaler som tenderade att tillfredsställa användare (mätt via anonymiserat aggregerat beteende och bedömningar från mänskliga kvalitetssättare).
- Avsiktsförståelse: frågor som “jaguar hastighet” eller “apple support” tvingade modeller att dra slutsatser om mening, kontext och tvetydighet. Lärande system blev bättre på att mappa ordval till koncept och sannolika mål.
- Spam och förtroende: när content farms och manipulerad SEO växte hjälpte ML att upptäcka onaturliga länkmönster, tunt innehåll och andra taktiker — vilket stödde en bredare satsning på högkvalitativa resultat.
En läsarvänlig milstolpe-tidslinje
- 1998: PageRank och det ursprungliga Google-papperet lade grunden för relevans via länkar.
- Tidigt 2000-tal: statistisk stavningskorrigering och förslagsfunktioner förbättrar “menade du” och omformuleringar.
- 2011: Panda riktar in sig på lågkvalitativt innehåll; kvalitetsignaler blir mer systematiska.
- 2012: Penguin straffar länkmanipulation och går bortom manuella regler.
- 2015: RankBrain (en lärande rankningskomponent) hjälper till med ovanliga eller tvetydiga frågor.
- 2018–2019: neural matching och BERT ger starkare språkförståelse, särskilt för längre frågor och prepositioner.
- 2021+: MUM-epoken med multitask-modeller och satsningar på “helpful content” driver mot djupare avsikts- och användbarhetssignaler.
Källor värda att nämna
För trovärdighet, nämn en mix av primärforskning och offentliga produktförklaringar:
- Forskningspapper: Brin & Page (PageRank, 1998), BERT (Devlin et al., 2018).
- Officiella sökannonseringar: Google Search-blogginlägg om RankBrain, BERT, MUM, Panda/Penguin-uppdateringar.
- Tal/intervjuer/event: Amit Singhals intervjuer om rankingens utveckling; Sundar Pichais keynote (Google I/O); “Search On”-event för moderna milstolpar.
Forskningskultur: förvandla långskott till användbara system
Googles långsiktiga spel handlade inte bara om stora idéer — det berodde på en forskningskultur som kunde förvandla akademiska papper till saker miljoner människor faktiskt använde. Det innebar att uppmuntra nyfikenhet, men också bygga vägar från prototyp till pålitlig produkt.
Från “publicera” till “skicka”
Många företag behandlar forskning som en separat ö. Google pressade för en tätare loop: forskare kunde utforska ambitiösa riktningar, publicera resultat och ändå samarbeta med produktteam som brydde sig om latens, tillförlitlighet och användarförtroende. När den loopen fungerar är ett papper inte mållinjen — det är början på ett snabbare, bättre system.
Ett praktiskt sätt att se detta är hur modellidéer visar sig i “små” funktioner: bättre stavningskorrigering, smartare rankning, förbättrade rekommendationer eller mer naturligt klingande översättningar. Varje steg kan se inkrementellt ut, men tillsammans förändrar de vad “sök” känns som.
Landmärken som satte tempot
Flera satsningar blev symboler för den där papper-till-produkt-pipelines. Google Brain hjälpte till att driva in djupinlärning i företaget genom att visa att det kunde slå äldre metoder när du hade tillräckligt med data och beräkningskraft. Senare gjorde TensorFlow det enklare för team att träna och driftsätta modeller konsekvent — en otrendig men avgörande ingrediens för att skala maskininlärning över många produkter.
Forskningsarbete inom neural maskinöversättning, taligenkänning och visionssystem rörde sig också från labbresultat till vardagsupplevelser, ofta efter flera iterationer som förbättrade kvalitet och minskade kostnad.
Varför tålamod spelar roll
Avkastningskurvan kommer sällan omedelbart. Tidiga versioner kan vara dyra, inexakta eller svåra att integrera. Fördelen kommer från att stanna kvar vid idén tillräckligt länge för att bygga infrastruktur, samla återkoppling och förfina modellen tills den är pålitlig. Det tålamodet — finansiera "långskott", acceptera omvägar och iterera i åratal — hjälpte till att omvandla ambitiösa AI-koncept till användbara system som folk kunde lita på i Googles skala.
Nya indata: röst, bilder och video tvingade fram smartare modeller
Textsök gynnade smarta rankningstrick. Men i samma stund som Google började ta emot röst, foton och video slog den gamla metoden i taket. Dessa indata är röriga: accenter, bakgrundsbrus, suddiga bilder, skakig film, slang och kontext som inte finns nedskriven. För att göra dem användbara behövde Google system som kunde lära mönster från data istället för att förlita sig på handskrivna regler.
Röst: förvandla ljud till avsikt
Med röstsök och Android-diktering handlade målet inte bara om att transkribera ord. Det handlade om att förstå vad någon menade — snabbt, på enheten eller över ostabila förbindelser.
Taligenkänning drev Google mot storskalig maskininlärning eftersom prestandan förbättrades mest när modeller tränades på enorma, mångsidiga ljuddataset. Det produkttrycket rättfärdigade seriösa investeringar i beräkning (för träning), specialiserade verktyg (datapipelines, utvärderingsuppsättningar, driftsättningssystem) och att rekrytera folk som kunde iterera på modeller som levande produkter — inte som engångs forskningsdemoer.
Foton: mening, inte metadata
Foton kommer inte med sökord. Användare förväntar sig att Google Photos hittar “hundar”, “strand” eller “min resa till Paris”, även om de aldrig taggat något.
Den förväntan tvingade fram bättre bildförståelse: objektigenkänning, ansiktsgruppering och likhetssökning. Återigen kunde regler inte täcka livets variation, så lärande system blev den praktiska vägen. Att förbättra noggrannheten krävde mer etiketterad data, bättre träningsinfrastruktur och snabbare experimentcykler.
Video och rekommendationer: skala blottlägger svagheter
Video lade till en dubbel utmaning: det är bilder över tid plus ljud. Att hjälpa användare navigera YouTube — sökning, undertexter, “näst upp” och säkerhetsfilter — krävde modeller som kunde generalisera över ämnen och språk.
Rekommendationer gjorde behovet av ML ännu tydligare. När miljarder användare klickar, tittar, hoppar över och återvänder måste systemet anpassa sig kontinuerligt. Den typen av återkopplingsslinga belönade naturligt investeringar i skalbar träning, mätvärden och talang för att hålla modeller förbättrade utan att bryta förtroendet.
AI-först-svängningen: göra AI till standard, inte en funktion
Förvandla forskning till produkt
Sätt upp ett delat byggflöde som ditt team kan återkomma till, mäta och förfina över tid.
“AI-först” är enklast att förstå som ett produktbeslut: istället för att lägga till AI som ett specialverktyg vid sidan av, behandlar du det som motorn inuti allt människor redan använder.
Google beskrev denna riktning offentligt kring 2016–2017 och ramade in det som en förskjutning från att vara “mobilförst” till “AI-först.” Idén var inte att varje funktion plötsligt blev “smart”, utan att standardvägen för produktförbättringar i allt högre grad skulle vara genom lärande system — rankning, rekommendationer, taligenkänning, översättning och spamdetektion — snarare än manuellt justerade regler.
AI inuti kärnloopen
I praktiska termer visar sig ett AI-först-ansats när produktens “kärnloop” tyst förändras:
- Sökträffarna blir bättre eftersom systemet lär mönster i frågor och klick, inte för att ett team hårdkodar tusentals nya if-then-regler.
- Foton organiseras efter vad som finns i dem, inte bara filnamn och mappar.
- Gmail fångar fler oönskade meddelanden genom att lära sig utvecklande beteenden, inte bara matcha kända nyckelord.
Användaren ser kanske aldrig en knapp märkt “AI.” De märker bara färre felaktiga resultat, mindre friktion och snabbare svar.
Assistenter höjde ribban för naturligt språk
Röstassistenter och konversationsgränssnitt förändrade förväntningarna. När folk kan säga “Påminn mig att ringa mamma när jag kommer hem” börjar de förvänta sig att mjukvara förstår avsikt, kontext och vardagligt språk.
Det tvingade produkter mot naturlig språkförståelse som en grundläggande möjlighet — över röst, skrivande och till och med kameraingång (peka telefonen mot något och fråga vad det är). Svängen var lika mycket att möta nya användarvanor som att realisera forskningsambitioner.
Viktigt: “AI-först” är bäst läst som en riktning — understödd av upprepade offentliga uttalanden och produktsteg — snarare än ett påstående att AI ersatte alla andra tillvägagångssätt över en natt.
Alphabet och det långa spelet: utrymme för satsningar bortom sök
Alphabet skapades 2015 mer som ett operativt beslut än en rebranding: separera den mogna, intäktsdrivande kärnan (Google) från mer osäkra, långsiktiga satsningar (ofta kallade “Other Bets”). Den strukturen spelar roll om du ser Larry Pages AI-vision som ett flerdecennieprojekt snarare än en enda produktcykel.
Varför dela “kärna” från “satsningar”
Google Search, Ads, YouTube och Android behövde oantastlig exekvering: tillförlitlighet, kostnadskontroll och stadig iteration. Moonshots — självkörande bilar, life sciences, uppkopplingsprojekt — behövde något annat: tolerans för osäkerhet, utrymme för dyra experiment och tillåtelse att ha fel.
Under Alphabet kunde kärnan styras med tydliga prestationsförväntningar, medan satsningar kunde utvärderas på lärandemilstolpar: “Bevisade vi en viktig teknisk antagande?” “Förbättrades modellen tillräckligt med verklig data?” “Är problemet över huvud taget lösbart på acceptabla säkerhetsnivåer?”
Moonshot-logiken: experimenterande som strategi
Det här långsiktiga tänkandet antar inte att varje projekt kommer att lyckas. Det antar att ihållande experimenterande är hur du upptäcker vad som kommer att spela roll senare.
En moonshot-fabrik som X är ett bra exempel: team prövar djärva hypoteser, instrumenterar resultaten och begraver idéer snabbt när bevisen är svaga. Den disciplinen är särskilt relevant för AI, där framsteg ofta beror på iteration — bättre data, bättre träningssetup, bättre utvärdering — inte bara ett enskilt genombrott.
Vad man bör ta med sig (utan löften)
Alphabet var ingen garanti för framtida vinster. Det var ett sätt att skydda två olika arbetstakter:
- Håll kärnverksamheten fokuserad och ansvarig.
- Skapa ett uttryckligt hem för hög-varians forskning och produktspel.
För team är lektionen strukturell: om du vill ha långsiktiga AI-resultat, designa för dem. Separera kortsiktig leverans från utforskande arbete, finansiera experiment som lärandeverktyg och mät framsteg i validerade insikter — inte bara rubriker.
De svåra delarna: kvalitet, säkerhet och förtroende i skala
Sträck din byggbudget
Sträck ut din byggbudget genom att tjäna krediter när du delar vad du bygger eller refererar andra till Koder.ai.
När AI-system hanterar miljarder frågor blir små felprocent till dagliga rubriker. En modell som är “mestadels rätt” kan fortfarande vilseleda miljoner — särskilt inom hälsa, ekonomi, val eller nyheter. I Googles skala är kvalitet inte en trevlig bonus; det är ett komponerande ansvar.
De grundläggande avvägningarna
Bias och representation. Modeller lär mönster från data, inklusive sociala och historiska bias. “Neutrala” rankningar kan ändå förstärka dominerande perspektiv eller underbetjäna minoritetsspråk och regioner.
Misstag och övertygelse. AI misslyckas ofta på sätt som låter övertygande. De mest skadliga felen är inte uppenbara buggar; det är trovärdigt klingande svar som användare litar på.
Säkerhet vs. användbarhet. Starka filter minskar skada men kan också blockera legitima frågor. Svaga filter ökar täckningen men höjer risken för bedrägerier, självskada eller desinformation.
Ansvarsskyldighet. När system blir mer automatiserade blir det svårare att svara på grundläggande frågor: Vem godkände detta beteende? Hur testades det? Hur kan användare överklaga eller rätta det?
Varför skalning ökar behovet av skyddsåtgärder
Skalning förbättrar kapacitet, men det:
- Ökar antalet kantfall (språk, kulturer, känsliga kontexter)
- Ökar incitament för missbruk (spam, promptinjektion, adversarial SEO)
- Gör fel svårare att rulla tillbaka när de väl integrerats i produkter
Därför måste skyddssystemen också skalas: utvärderingssviter, red-teaming, policytillämpning, proveniens för källor och tydliga användargränssnitt som signalerar osäkerhet.
En praktisk checklista för att utvärdera AI-påståenden
Använd detta för att bedöma vilken “AI-drivna” funktion som helst — vare sig den kommer från Google eller någon annan:
- Vad är felmoden? Visar de var det bryter, inte bara demos?
- Hur mäts det? Leta efter verkliga mätvärden (noggrannhet, toxicitetsnivåer, hallucinationsfrekvens), inte vaga “förbättringar.”
- Vad tränades det på? Minst: breda kategorier, aktualitet och exklusionspolicyer.
- Vilka skydd finns? Säkerhetsregler, manuella granskningsvägar och missbrukövervakning.
- Kan användare verifiera? Citat, källhänvisningar eller förklaringar som låter dig kontrollera påståenden.
- Hur hanteras korrigeringar? Tydlig rapportering, snabba uppdateringar och auditmöjligheter.
Förtroende förtjänas genom repeterbara processer — inte av ett enda genombrottsmodell.
Lärdomar för team: hur tänka långsiktigt om AI
Det mest överförbara mönstret bakom Googles långa båge är enkelt: tydligt mål → data → infrastruktur → iteration. Du behöver inte Googles skala för att använda loopen — du behöver disciplin kring vad du optimerar för och ett sätt att lära av verklig användning utan att lura dig själv.
Kärnmönstret du kan kopiera
Börja med ett mätbart användarlöfte (hastighet, färre fel, bättre matchningar). Instrumentera det så att du kan observera utfall. Bygg minsta möjliga “maskin” som låter dig samla, märka och leverera förbättringar säkert. Iterera sedan i små, frekventa steg — behandla varje release som en lärdom.
Om ditt flaskhals är att komma från “idé” till “instrumenterad produkt” snabbt, kan moderna byggflöden hjälpa. Till exempel är Koder.ai en vibe-coding-plattform där team kan skapa webb-, backend- eller mobilappar från en chattgränssnitt — användbart för att snabbt snurra upp en MVP som inkluderar återkopplingsslingor (tummen upp/ner, rapportera problem, korta enkäter) utan att vänta veckor på en fullständig anpassad pipeline. Funktioner som planeringsläge samt snapshots/rollback kartlägger också bra mot principen “experimentera säkert, mät, iterera”.
6 insikter ledare kan tillämpa (utan att vara Google)
- Välj en nordstjärna som är användarorienterad. “Förbättra sökupplevelsen” är tydligare än “adoptera AI.” Definiera framgång i termer människor känner.
- Designa produkten för att skapa lärandedata. Lägg till återkopplingsslingor (tummen upp/ner, korrigeringar, “hjälpte detta?”) som fångar avsikt, inte bara klick.
- Investera tidigt i rörmokningen, inte bara modellerna. Datakvalitetskontroller, utvärderingsdashboards och driftsättningsflöden slår engångsprototyper.
- Behandla utvärdering som en produktfunktion. Skapa en upprepad scorecard (kvalitet, latens, kostnad, säkerhet) så iteration inte blir gissningslek.
- Leverera i skivor. Börja med smala användningsfall, rulla ut till en liten publik, mät och expandera. Momentum slår storlanseringar.
- Gör långsiktiga satsningar överlevbara. Skydda en liten del kapacitet för experiment, men kräva tydliga lärandemilstolpar för att hålla dem ärliga.
Relaterad läsning
- Blogg: AI-strategi — grunderna
- Blogg: Datadrivna svänghjul för produktteam
- Blogg: Utvärdera ML-modeller utan doktorsexamen
- Blogg: Lättviktig AI-styrning