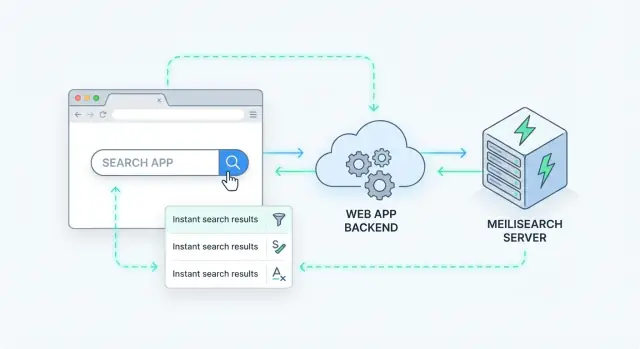
Vad omedelbar serversidesökning bör leverera
Serversidesökning betyder att frågan bearbetas på din server (eller en dedikerad söktjänst), inte i webbläsaren. Din app skickar en sökbegäran, servern kör den mot ett index och returnerar rankade resultat.
Det spelar roll när din datamängd är för stor för att skickas till klienten, när du behöver konsekvent relevans över plattformar eller när åtkomstkontroll är icke-förhandlingsbart (till exempel interna verktyg där användare bara ska se vad de får se). Det är också standardvalet när du vill ha analys, loggning och förutsägbar prestanda.
Vad användare förväntar sig (och märker omedelbart)
Folk tänker inte på sökmotorer — de bedömer upplevelsen. Ett bra “omedelbart” sökflöde innebär vanligtvis:
- Snabb återkoppling: resultat uppdateras snabbt medan användaren skriver, utan pinsamma pauser.
- Stavfel bryter inte sökningen: felstavningar, omkastade bokstäver och partiella ord hittar fortfarande rätt artiklar.
- Användbara kontroller: filtrering (kategori, status, prisklass), sortering (nyast, billigast) och facetter (antal per filter) känns naturligt.
- Relevant ordning: de “bästa” resultaten kommer först, inte bara det nyaste eller det mest keyword-fyllda.
Om något av detta saknas kompenserar användare genom att pröva andra sökningar, skrolla mer eller ge upp sökningen helt.
Vad den här guiden hjälper dig göra
Denna artikel är en praktisk genomgång för att bygga den upplevelsen med Meilisearch. Vi går igenom hur du sätter upp den säkert, hur du strukturerar och synkar dina indexerade data, hur du finjusterar relevans och rankningsregler, hur du lägger till filter/sortering/facetter och hur du tänker kring säkerhet och skalning så att sökningen förblir snabb när din app växer.
När serversidesökning verkligen lyser
Meilisearch passar särskilt bra för:
- Dokumentation och knowledge bases (hitta sidor snabbt, tolerera stavfel)
- Produktkataloger och marknadsplatser (filter och sortering är avgörande)
- Internt verktyg (behörighetsmedveten sökning över poster)
- Innehållssajter (sök över artiklar, guider, FAQ)
Målet genomgående: resultat som känns omedelbara, korrekta och pålitliga — utan att göra sökningen till ett stort ingenjörsprojekt.
Meilisearch i vanlig svenska
Meilisearch är en sökmotor du kör vid sidan av din app. Du skickar dokument (som produkter, artiklar, användare eller supportärenden) till den, och den bygger ett index optimerat för snabb sökning. Din backend (eller frontend) frågar sedan Meilisearch via ett enkelt HTTP-API och får rankade resultat på millisekunder.
Vad du får direkt
Meilisearch fokuserar på funktioner som folk förväntar sig av modern sökning:
- Felsäkerhet för stavfel så att "iphnoe" ändå kan hitta "iPhone".
- Kontroller för relevans (rankningsregler) så att du kan bestämma vad "bästa match" betyder för din verksamhet.
- Filter, sortering och facetter så att användare kan begränsa resultat efter attribut som kategori, prisintervall, tillgänglighet eller taggar.
Det är designat för att kännas responsivt och förlåtande, även när en fråga är kort, något felaktig eller tvetydig.
Vad Meilisearch inte är
Meilisearch ersätter inte din primära databas. Din databas förblir sanningskällan för skrivningar, transaktioner och begränsningar. Meilisearch lagrar en kopia av de fält du väljer att göra sökbara, filterbara eller visbara.
En bra mental modell är: databas för att lagra och uppdatera data, Meilisearch för att hitta det snabbt.
Prestandaförväntningar (vad som påverkar hastigheten)
Meilisearch kan vara extremt snabb, men resultat beror på några praktiska faktorer:
- Datamängd och form (antal dokument, antal fält och hur mycket text du indexerar)
- Hårdvara (CPU, RAM, disk)
- Konfiguration (vilka attribut som är sökbara/filterbara/sorteringsbara och hur ofta du reindexerar)
För små till medelstora dataset kan du ofta köra det på en enda maskin. När ditt index växer vill du vara mer eftertänksam om vad du indexerar och hur du håller det uppdaterat — ämnen vi tar upp i senare avsnitt.
Planera dina index och datamodell
Innan du installerar något, bestäm vad du faktiskt ska söka. Meilisearch känns "omedelbart" bara om dina index och dokument matchar hur folk bläddrar i din app.
Mappa entiteter till index
Börja med att lista dina sökbara entiteter — vanligtvis products, articles, users, help docs, locations, etc. I många appar är renast att ha ett index per entitetstyp (t.ex. products, articles). Det håller rankningsregler och filter förutsägbara.
Om din UX söker över flera typer i en ruta ("sök allt") kan du fortfarande ha separata index och slå ihop resultat i din backend, eller skapa ett dedikerat "globalt" index senare. Tvinga inte ihop allt i ett index om inte fälten och filtren verkligen är likartade.
Varje dokument behöver ett stabilt identifierare (primärnyckel). Välj något som:
- aldrig förändras (eller förändras extremt sällan)
- är unikt inom indexet
- redan finns i din databas (t.ex.
id, sku, slug)
För dokumentformen, föredra platta fält när du kan. Platta strukturer är enklare att filtrera och sortera på. Nester är okej när de representerar ett tätt, oföränderligt paket (t.ex. ett author-objekt), men undvik djup nestning som speglar hela din relationsschema — sökdokument bör vara read-optimized, inte databasformade.
Klassificera fält: sökbara, filterbara, visade
Ett praktiskt sätt att designa dokument är att märka varje fält med en roll:
- Sökbara: text användare skriver (title, name, description)
- Filterbara: attribut som används som begränsningar (category, price range, status, tags)
- Visade: vad du returnerar till UI (title, thumbnail URL, kort utdrag)
Detta förhindrar en vanlig miss: att indexera ett fält "ifall" och senare undra varför resultat är brusiga eller filter långsamma.
Planera för flerspråkigt innehåll
"Språk" kan betyda olika saker i din data:
- dokumentets språk ( varje artikel har
lang: "en" )
- användarens lokalisering (UI-språk)
- fält med blandade språk (produktnamn på flera språk)
Bestäm tidigt om du ska använda separata index per språk (enkelt och förutsägbart) eller ett enda index med språkfält (färre index, mer logik). Rätt svar beror på om användare söker på ett språk åt gången och hur du lagrar översättningar.
Installera och köra Meilisearch säkert
Att köra Meilisearch är rakt fram, men "säkert som standard" kräver några övervägda val: var du deployar, hur du persisterar data och hur du hanterar master-nyckeln.
Deploy-alternativ (välj det ni kan driftätta)
- Docker (vanligast): snabbt att starta, lätt att uppgradera, konsekvent över miljöer. Para ihop med en persistent volume.
- VM eller bare metal: bra när ni redan har en standard Linux-deploy-pipeline (systemd, log rotation, backups).
- Managed hosting: om ditt team inte vill underhålla servrar, leta efter en managed Meilisearch-leverantör eller en plattform som erbjuder det som tillägg. Du byter flexibilitet mot enklare drift.
Miljöbasics: lagring, minne, backup, övervakning
Lagring: Meilisearch skriver sitt index till disk. Lägg datakatalogen på tillförlitlig, persistent lagring (inte ephemeral container storage). Planera kapacitet för tillväxt: index kan växa snabbt med stora textfält och många attribut.
Minne: tilldela tillräckligt med RAM för att hålla sökningen responsiv under belastning. Om du ser swap påverkas prestandan negativt.
Backups: säkerhetskopiera Meilisearch data-katalog (eller använd snapshots på lagringsnivå). Testa återställning åtminstone en gång; en backup du inte kan återställa är bara en fil.
Övervakning: följ CPU, RAM, diskanvändning och disk I/O. Övervaka även processhälsa och loggfel. Minst: larma om tjänsten stoppas eller diskutrymmet blir lågt.
Sätt och lagra master-nyckeln säkert
Kör alltid Meilisearch med en master key i annat än lokal utveckling. Spara den i en secret manager eller krypterad miljövariabel-lagring (inte i Git, inte i en plaintext .env som committas).
Exempel (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
Tänk också på nätverksregler: bind till ett privat interface eller begränsa inåtgående åtkomst så att bara din backend kan nå Meilisearch.
Checklista för första start
curl -s http://localhost:7700/version
Indexera dokument och håll dem synkade
Behåll full kontroll över koden
Äg koden - exportera källan när du är redo att ta det vidare.
Meilisearch-indexering är asynkron: du skickar dokument, Meilisearch köar en task, och först när den tasken lyckas blir dokumenten sökbara. Behandla indexering som ett jobbsystem, inte en enkel förfrågan.
Ett enkelt indexeringsflöde (add → wait → verify)
- Lägg till dokument (se till att varje dokument har en stabil unik id, vanligtvis
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
- Vänta på tasken. API-svaret innehåller en
taskUid. Poll:a tills den är succeeded (eller failed).
curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Verifiera counts och grundläggande sökning. Bekräfta att indexet har förväntat antal dokument och att en enkel sökning returnerar resultat.
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Om counts inte stämmer, gissa inte — kolla task-felens detaljer först.
Batchning som inte överraskar dig senare
Batchning handlar om att hålla tasks förutsägbara och återställbara.
- Börja med 1 000–10 000 dokument per batch, eller begränsa efter payload-storlek (för många appar är 5–15 MB per förfrågan bekvämt).\n- Föredra många mindre batchar framför en enda jättestor; det är enklare att försöka igen och enklare att hitta felaktiga data.\n- Om du har frekventa ändringar, indexera kontinuerligt i batchar (t.ex. varje minut) istället för att bygga om allt.
Uppdateringar vs full reindex
addDocuments fungerar som en upsert: dokument med samma primärnyckel uppdateras, nya infogas. Använd detta för normala uppdateringar.
Gör en full reindex när:\n
- du ändrat dokumentformen avsevärt,\n- du behöver räkna om härledda fält,\n- din synk har drivit ifrån och du vill ha en ren nystart.
För borttag, kalla explicit deleteDocument(s); annars kan gamla poster ligga kvar.
Idempotens: säkra omförsök när jobb misslyckas
Indexering bör vara återkörbar. Nyckeln är stabila dokument-id.
- Om en batchupload timeoutar kan du skicka samma batch igen: upsert + stabila id betyder att du inte skapar dubbletter.\n- Spara det returnerade
taskUid tillsammans med ditt batch-/jobb-id, och försök igen baserat på task-status.\n- Om du kör en kö, gör workern "at-least-once" säker: dubbletter ska vara ofarliga.
Seed-data för snabb pre-production-test
Innan produktionsdata, indexera en liten dataset (200–500 items) som matchar dina riktiga fält. Exempel: en products-mängd med id, name, description, category, brand, price, inStock, createdAt. Detta räcker för att validera task-flöde, counts och uppdatera/radera-beteende — utan att vänta på en massiv import.
Relevans och rankningsregler du kan styra
"Relevans" är helt enkelt: vad som visas först, och varför. Meilisearch gör detta justerbart utan att tvinga dig bygga ett eget score-system.
Börja med rätt attribut
Två inställningar formar vad Meilisearch kan göra med ditt innehåll:
searchableAttributes: fälten Meilisearch söker i när en användare skriver en fråga (t.ex. title, summary, tags). Ordningen spelar roll: tidigare fält behandlas som viktigare.displayedAttributes: fälten som returneras i svaret. Detta påverkar integritet och payload-storlek — om ett fält inte visas skickas det inte tillbaka.
En praktisk baseline är att göra några högsignal-fält sökbara (title, nyckeltext) och hålla visade fält till vad UI behöver.
Hur rankningsregler påverkar resultatordningen
Meilisearch sorterar matchande dokument med hjälp av rankningsregler — en pipeline av "tie-breakers." Konceptuellt föredrar den:
- resultat som matchar frågan väl (inklusive stavfelstolerans), sedan\n2) resultat där matchningarna är starkare (närmare ord, match i viktigare attribut), sedan\n3) resultat som passar din affärslogik (egen sortering som aktualitet eller popularitet).
Du behöver inte memorera internals för att finjustera; du väljer mest vilka fält som är viktigast och när du ska applicera egen sortering.
Vanliga tuning-mål (med exempel)
Mål: "Titlar bör vinna." Sätt title först:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Mål: "Nyare innehåll ska komma först." Lägg till ett sorteringsfält och sortera vid query-tid (eller sätt en custom ranking):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Sedan anropa:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Mål: "Främja populära artiklar." Gör popularity sorteringsbar och sortera efter det när det är lämpligt.
Utvärdera ändringar med ett enkelt före/efter-test
Välj 5–10 verkliga sökfrågor som användare skriver. Spara toppresultaten före ändringar, jämför sedan efter.
Exempel:
- Före: query
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Efter (title-first + exactness): query
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Om "efter"-listan bättre matchar användarens avsikt, behåll inställningarna. Om det skadar kantfall, justera en sak i taget (attributordning, sedan sorteringsregler) så att du vet vad som orsakade förbättringen.
Filter, sortering och facetter för verklig sökning
En bra sökruta är inte bara "skriv ord, få träffar." Folk vill också begränsa resultat ("endast tillgängliga artiklar") och ordna dem ("billigast först"). I Meilisearch gör du detta med filter, sortering och facetter.
Filter och facetter (samma idé, olika UI)
Ett filter är en regel du applicerar på resultatmängden. En facett är vad du visar i UI för att hjälpa användare bygga dessa regler (ofta som kryssrutor eller antal).
Icke-tekniska exempel:
- Kategori: “Shoes”, “Jackets”, “Accessories”\n- Pris: “Under $50”, “$50–$100”\n- Status: “In stock”, “Backorder”, “Archived”
Så en användare kan söka “running” och sedan filtrera till category = Shoes och status = in_stock. Facetter kan visa antal som “Shoes (128)” och “Jackets (42)” så användaren förstår vad som finns.
Meilisearch behöver att du explicit tillåter fält som ska användas för filtrering och sortering.
- Markera fält som filterbara när du kommer att använda dem i filter:
category, status, brand, price, created_at (om du filtrerar efter tid), tenant_id (om du isolerar kunder).\n- Markera fält som sorteringsbara när du kommer att sortera efter dem: price, rating, created_at, popularity.
Håll listan snäv. Att göra allt filterbart/sorteringsbart kan öka indexstorleken och sakta ner uppdateringar.
Även om du har 50 000 träffar ser användaren bara första sidan. Använd små sidor (ofta 20–50 resultat), sätt en vettig limit och paginera med offset (eller de nyare pagineringsfunktionerna om du föredrar). Begränsa också maximalt siddjup i din app för att förhindra dyra "sida 400"-förfrågningar.
Synonymer och stop words (valfritt, använd försiktigt)
- Synonymer hjälper när olika ord betyder samma sak (t.ex. “hoodie” ↔ “sweatshirt”). Lägg till dem gradvis och granska sökanalys — för många synonymer kan ge överraskande träffar.\n- Stop words tar bort vanliga ord ("the", "and"). De kan minska brus, men kan också skada exakta sökningar som produktnamn ("The Who", "A Team"). Anpassa stop words bara om du har ett tydligt problem att lösa.
Integrera Meilisearch i din applikationsbackend
Gå från lokal till live
Distribuera och hosta din app, och iterera relevans utan riskabla manuella ändringar.
Ett rent sätt att lägga till serversidesök är att behandla Meilisearch som en specialiserad datatjänst bakom ditt API. Din app tar emot en sökförfrågan, anropar Meilisearch, och returnerar sedan ett kuraterat svar till klienten.
Ett enkelt backendmönster
De flesta team landar i ett flöde som detta:
- Klienten anropar din endpoint (t.ex.
GET /api/search?q=wireless+headphones&limit=20).\n2. Din backend validerar indata, tillämpar affärsregler och bestämmer vilket index som ska frågas.\n3. Backend anropar Meilisearchs Search API med användarfrågan plus filter/sort.\n4. Backend efterbehandlar resultat (gömmer privata fält, slår ihop med DB-data, tillämpar behörigheter).\n5. Backend returnerar en stabil responstruktur till klienten.
Detta mönster håller Meilisearch ersättbar och förhindrar att frontendkoden blir beroende av index-interna detaljer.
Om du bygger en ny app (eller bygger om ett internt verktyg) och vill ha detta mönster snabbt implementerat, kan en vibe-coding-plattform som Koder.ai hjälpa till att skaffa hela flödet — React UI, en Go-backend och PostgreSQL — och integrera Meilisearch bakom en enda /api/search-endpoint så klienten hålls enkel och dina behörigheter förblir på serversidan.
Frontend vs backend-anrop (och varför backend är säkrare)
Meilisearch stödjer klientanrop, men backend-anrop är oftast säkrare eftersom:
- Hemligheter hålls privata: du riskerar inte att exponera privilegierade API-nycklar.\n- Autorisering är konsekvent: din backend kan upprätthålla "vad denna användare får se" innan träffarna returneras.\n- Du kontrollerar fråga-komplexitet: begränsa filter, sorteringsalternativ och paginering för att skydda prestanda.
Frontend-anrop kan fungera för publika data med begränsade nycklar, men om du har användarspecifika synlighetsregler, routa sökningen via din server.
Cacha populära förfrågningar utan att bryta relevans
Söktrafik har ofta upprepningar ("iphone case", "return policy"). Lägg caching i din API-lager:
- Cacha hela svaret för korta perioder (t.ex. 10–60 sek) för anonym trafik.\n- Normalisera cache-nycklar (trimma whitespace, gemener, inkludera filter/sort).\n- Invalidera försiktigt: för snabbrörliga index, håll TTL kort istället för att försöka rensa aggressivt.
Rate limiting och skydd mot missbruk
Behandla sök som en publik endpoint:
- Applicera per-IP eller per-användare ratelimits.\n- Sätt max
limit och en maximal query-längd.\n- Överväg att mjukt blockera uppenbara bots samtidigt som riktiga användare tillåts.
Säkerhetsbasics: nycklar, åtkomstkontroll och multi-tenancy
Meilisearch placeras ofta "bakom" din app eftersom det snabbt kan returnera känslig verksamhetsdata. Behandla det som en databas: lås ner det, och exponera bara vad varje anropare bör se.
API-nycklar: master vs scoped (minsta privilegium)
Meilisearch har en master key som kan allt: skapa/radera index, uppdatera inställningar samt läsa/skriva dokument. Håll den server-sida.
För applikationer generera API-nycklar med begränsade rättigheter och begränsade index. Ett vanligt mönster:
- Bakgrundsjobb: en nyckel som kan skriva dokument och uppdatera inställningar, men bara på specifika index.\n- App-server: en read-only-nyckel för sökning.\n- Klient (om absolut nödvändigt): en strikt scoped search-only-nyckel med tvingade filter.
Minsta privilegium betyder att en läckt nyckel inte kan radera data eller läsa från orelaterade index.
Multi-tenancy: separata index eller filtrera på tenantId
Om du tjänar flera kunder (tenants) har du två huvudalternativ:
1) Ett index per tenant.\n
Enkelt att resonera kring och minskar risken för korsåtkomst. Nackdel: fler index att hantera, och settings-uppdateringar måste tillämpas konsekvent.
2) Delat index + tenant-filter.\n
Spara ett tenantId-fält på varje dokument och kräva ett filter som tenantId = "t_123" för alla sökningar. Detta kan skala bra, men bara om du säkerställer att varje förfrågan alltid applicerar filtret (helst via en scoped nyckel så anroparna inte kan ta bort det).
Förhindra dataläckor: kontrollera vad som kan returneras
Även om sökningen är korrekt kan resultat läcka fält du inte tänkt visa (email, interna anteckningar, kostpris). Konfigurera vad som kan returneras:
- Begränsa displayed/retrievable attributes till en säker allowlist.\n- Behåll känsliga fält indexerade bara om det är absolut nödvändigt — och undvik att returnera dem i resultat.
Gör ett snabbt "worst-case"-test: sök ett vanligt term och bekräfta att inga privata fält dyker upp.
Grundläggande operationell säkerhet
- Begränsa nätverksåtkomst: bind till localhost eller ett privat nätverk, och tillåt endast inåtgående trafik från dina appservrar.\n- Placera Meilisearch bakom en reverse proxy om du behöver TLS och rate limiting.\n- Spara nycklar i en secrets manager (inte i källkod eller frontend-buntar) och rotera dem periodvis.
Om du är osäker på om en nyckel ska vara klient-sida, anta "nej" och håll sök på serversidan.
Prestanda och skalning utan gissningar
Sätt upp pålitlig indexering
Skapa batch-indexeringsjobb med stabila ID så att omförsök är säkra och förutsägbara.
Meilisearch är snabbt när du håller två arbetslaster i åtanke: indexering (skriv) och sökförfrågningar (läs). Den mesta "mystiska långsamheten" är helt enkelt att en av dessa konkurrerar om CPU, RAM eller disk.
Var prestandan vanligtvis flaskhalsar
Indexeringsbelastning kan spikas när du importerar stora batchar, kör frekventa uppdateringar eller lägger till många sökbara fält. Indexering är en bakgrundsuppgift, men den använder ändå CPU och diskbandbredd. Om din task-kö växer kan sökningar börja kännas långsamma även om query-volymen inte ändrats.
Query-belastning växer med trafik, men också med funktioner: fler filter, fler facetter, större resultatuppsättningar och högre felstavningstolerans ökar arbetet per förfrågan.
Disk I/O är den tysta boven. Långsamma diskar (eller noisy neighbors på delade volymer) kan förvandla "omedelbart" till "så småningom." NVMe/SSD är typisk baseline för produktion.
Praktiska skalsteg
Börja med enkel dimensionering: ge Meilisearch tillräckligt med RAM för att hålla index varmt och tillräcklig CPU för att hantera peak QPS. Separera sedan ansvarsområden:
- Om indexering stör läsningar, schemalägg bulk-importer off-peak och föredra större batchar framför många små uppdateringar.\n- Lägg till repliker för hög tillgänglighet och läskapacitet (din app kan load-balanca sökförfrågningar över repliker).\n- Sharding: Meilisearch gör ingen automatisk distribuerad sharding. Om du växer ut en nod kan du partitionera data på applikationsnivå (t.ex. per tenant, region eller tidsintervall) i flera index eller kluster.
Vad du bör övervaka (så du inte gissar)
Följ ett litet set signaler:
- Sök-latens (p50/p95) och genomströmning\n- Task-kö-längd / task-processing-tid (en stigande kö betyder att indexering inte hinner med)\n- CPU, RAM, disk-användning och disk I/O-wait\n- Felräntor (timeouts, 4xx/5xx, failed tasks)
Backups och uppgraderingsplanering
Backups ska vara rutin, inte heroisk. Använd Meilisearchs snapshot-funktion enligt schema, lagra snapshots utanför boxen och testa återställningar regelbundet. För uppgraderingar läs release notes, testa i icke-prod och planera för reindexeringstid om en versionsändring påverkar indexbeteende.
Om ni redan använder miljösnapshots och rollback i er appplattform (till exempel via Koder.ai:s snapshots/rollback-workflow), synka er sök-rollout med samma disciplin: snapshot före ändringar, verifiera health checks och ha en snabb väg tillbaka till ett känt fungerande tillstånd.
Felsökning och en praktisk rollout-checklista
Även med en ren integration tenderar sökproblem att hamna i några återkommande kategorier. Den goda nyheten: Meilisearch ger tillräcklig insyn (tasks, logs, deterministiska inställningar) för att felsöka snabbt — om du närmar dig det systematiskt.
Vanliga problem (och vad de oftast betyder)
- "Mina filter fungerar inte": fältet lades inte till i
filterableAttributes, eller dokumenten lagrar det i en oväntad form (string vs array vs nested object).\n- "Resultaten rankas konstigt": rankningsregler, synonymer, stop words eller saknade sortableAttributes/rankingRules-ändringar flyttar upp “fel” artiklar.\n- "Sök visar gammal data": indexeringstasks körs fortfarande, du skriver till ett annat index än du läser från, eller din synkpipeline tappade uppdateringar/raderingar.
Felsökningsflöde som håller sig rimligt
Börja med att kontrollera om Meilisearch framgångsrikt tillämpade din senaste ändring.
- Inspektera task-status: varje settings-ändring och dokumentuppdatering skapar en asynkron task. Om en task misslyckades, åtgärda det först (fel payloads, fel fälttyper, för stora dokument).\n2. Använd loggar med en enkel fråga i åtanke: "Accepterade servern min förfrågan?" sedan "Slutförde den bearbetningen?" Undvik att skumma allt på en gång.\n3. Skapa en minimal reproducerbar query:\n - Välj ett index.\n - Använd en fråga som returnerar en liten, stabil mängd.\n - Lägg till begränsningar en i taget:
filter, sedan sort, sedan facets.
Om du inte kan förklara ett resultat, strippa temporärt tillbaka din konfiguration: ta bort synonymer, minska ranknings-tweaks och testa med en liten dataset. Komplexa relevansproblem är mycket lättare att hitta på 50 dokument än på 5 miljoner.
Rollout-strategi: minska blast radius
- Test-index först: bygg
your_index_v2 parallellt, applicera inställningar och spela upp ett urval av produktionsfrågor.\n- Canary-rollout: routa en liten procentandel av söktrafiken till det nya indexet eller nya inställningar, jämför klickfrekvens och "inga resultat"-frekvenser.\n- Fallback-beteende: bestäm vad användare ser om sök är långsam eller otillgänglig — cachade resultat, en förenklad fråga eller ett vänligt "försök igen"-läge. Låt inte sökfel bryta hela sidan.
Nästa steg-checklista
- Verifiera att
filterableAttributes och sortableAttributes matchar ditt UI-krav.\n- Bekräfta att indexeringstasks slutförs framgångsrikt efter varje deployment.\n- Lägg till en liten "search health"-monitor (latens + task-fel).\n- Öva rollback: växla trafiken tillbaka till föregående index.
Relaterade guider: sök på reliability, indexeringsmönster och produktions-rollout-tips.