14 juli 2025·8 min
Strategier för minneshantering: prestanda vs säkerhet
Lär dig hur garbage collection, ägarskap och referensräkning påverkar hastighet, latens och säkerhet — och hur du väljer ett språk som passar dina mål.
Lär dig hur garbage collection, ägarskap och referensräkning påverkar hastighet, latens och säkerhet — och hur du väljer ett språk som passar dina mål.
Minneshantering är de regler och mekanismer ett program använder för att begära minne, använda det och lämna tillbaka det. Alla program behöver minne för variabler, användardata, nätverksbuffrar, bilder och mellanresultat. Eftersom minnet är begränsat och delas med operativsystemet och andra applikationer måste språk bestämma vem som ansvarar för att frigöra det och när det sker.
Dessa val påverkar två resultat som de flesta bryr sig om: hur snabbt ett program upplevs, och hur tillförlitligt det beter sig under belastning.
Prestanda är inte ett enda tal. Minneshantering kan påverka:
Ett språk som allokerar snabbt men ibland pausar för att rensa kan se bra ut i benchmarks men kännas ryckigt i interaktiva appar. En annan modell som undviker pauser kan kräva mer omsorg för att förhindra läckor och livstidsmisstag.
Säkerhet handlar om att förebygga minnesrelaterade fel, såsom:
Många högprofilerade säkerhetsproblem har sitt ursprung i minnesmisstag som use-after-free eller buffertöverskridningar.
Denna guide är en icke‑teknisk genomgång av huvudmodellerna för minneshantering som används i populära språk, vad de optimerar för och vilka kompromisser du accepterar när du väljer en.
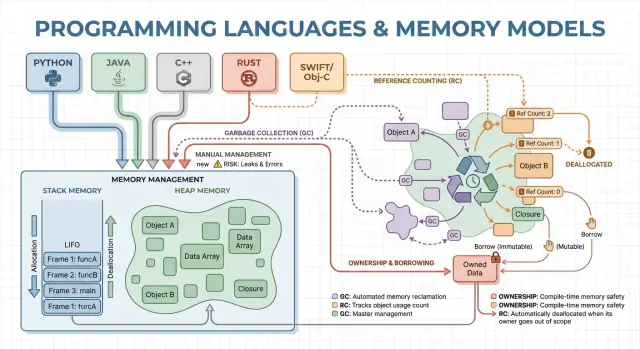
Minnet är där ditt program lagrar data medan det körs. De flesta språk organiserar detta runt två huvudområden: stack och heap.
Tänk på stacken som en prydlig hög med post‑it‑lappar för den aktuella uppgiften. När en funktion startar får den en liten “ram” på stacken för sina lokala variabler. När funktionen slutar tas hela ramen bort på en gång.
Det är snabbt och förutsägbart — men fungerar bara för värden vars storlek är känd och vars livslängd slutar med funktionsanropet.
Heapen är mer som ett förrådsrum där du kan förvara objekt så länge du behöver. Den är utmärkt för dynamiskt storleksanpassade listor, strängar eller objekt som delas mellan delar av programmet.
Eftersom heap‑objekt kan överleva ett funktionsanrop blir den avgörande frågan: vem ansvarar för att frigöra dem, och när? Det ansvaret är ett programs eller språks “minneshanteringsmodell”.
En pointer eller referens är ett sätt att nå ett objekt indirekt — som att ha hyllnumret för en låda i förrådet. Om lådan slängs men du fortfarande har hyllnumret kan du läsa skräpdata eller krascha (en klassisk use‑after‑free‑bugg).
Föreställ dig en loop som skapar en kundpost, formaterar ett meddelande och slänger det:
Vissa språk döljer dessa detaljer (automatisk städning), medan andra exponerar dem (du frigör minnet uttryckligen, eller måste följa regler för vem som äger ett objekt). Resten av artikeln utforskar hur dessa val påverkar hastighet, pauser och säkerhet.
Manuell minneshantering innebär att programmet (och alltså utvecklaren) explicit begär minne och senare frigör det. I praktiken ser det ut som malloc/free i C eller new/delete i C++. Det är fortfarande vanligt i systemsprogrammering där man behöver exakt kontroll över när minne tas i anspråk och återlämnas.
Du allokerar normalt när ett objekt måste överleva nuvarande funktionsanrop, växa dynamiskt (t.ex. en resizable buffer) eller behöva ett specifikt layout för interoperabilitet med hårdvara, OS eller nätverksprotokoll.
Utan en garbage collector som körs i bakgrunden blir det färre överraskande pauser. Allokering och deallokering kan göras mycket förutsägbart, särskilt i kombination med anpassade allocators, pooler eller fixed‑size‑buffrar.
Manuell kontroll kan också minska overhead: ingen tracing‑fas, inga write barriers och ofta mindre metadata per objekt. När koden är väl designad kan du nå snäva latensmål och hålla minnesanvändningen inom strikta gränser.
Kompromissen är att programmet kan göra misstag som runtime inte automatiskt förhindrar:
Dessa buggar kan orsaka krascher, korruption och säkerhetssårbarheter.
Team minskar risk genom att begränsa var rå allokering är tillåten och genom att luta sig mot mönster som:
std::unique_ptr) för att koda ägarskapManuell minneshantering är ofta ett bra val för inbyggd mjukvara, realtidsystem, OS‑komponenter och prestandakritiska bibliotek — där tight kontroll och förutsägbar latens väger tyngre än utvecklarkomfort.
Garbage collection (GC) är automatisk minnesstädning: istället för att du behöver freea minnet spårar runtime vilka objekt som används och återvinner de som inte längre nås. I praktiken betyder det att du kan fokusera på beteende och dataflöde medan systemet hanterar de flesta allokerings‑ och deallokeringsbeslut.
De flesta collectors identifierar först levande objekt, och återvinner sedan resten.
Tracing GC börjar från ”rötter” (som stackvariabler, globala referenser och register), följer referenser för att markera allt nåbart och sveper sedan heapen för att frigöra omarkerade objekt. Om inget pekar på ett objekt blir det aktuellt för insamling.
Generational GC bygger på observationen att många objekt dör unga. Den delar upp heapen i generationer och samlar den unga regionen ofta, vilket vanligtvis är billigare och förbättrar effektiviteten.
Concurrent GC kör delar av insamlingen parallellt med applikationstrådar för att minska långa pauser. Den kan kräva mer bokföring för att hålla minnessynkroniseringen korrekt medan programmet fortsätter köra.
GC brukar byta bort manuell kontroll mot arbete i runtime. Vissa system prioriterar hög genomströmning (mycket arbete per sekund) men kan introducera stop‑the‑world‑pauser. Andra minimerar pauser för latenskritiska appar men kan lägga till overhead under normal körning.
GC tar bort en hel klass av livstidsbuggar (särskilt use‑after‑free) eftersom objekt inte återvinns så länge de är nåbara. Det minskar också läckor som orsakas av missade deallokeringar (även om du fortfarande kan ”läcka” genom att hålla referenser längre än avsett). I stora kodbaser där ägarskap är svårt att spåra manuellt snabbar detta ofta upp iterationstakten.
Garbage‑collected runtimes är vanliga i JVM (Java, Kotlin), .NET (C#, F#), Go och JavaScript‑motorer i webbläsare och Node.js.
Referensräkning är en strategi där varje objekt håller reda på hur många “ägare” (referenser) som pekar på det. När räkningen når noll frigörs objektet direkt. Denna omedelbarhet känns intuitiv: så fort inget kan nå ett objekt återvinns minnet.
Varje gång du kopierar eller lagrar en referens ökar runtime dess räknare; när en referens försvinner minskar den. När räknaren når noll triggas städning genast.
Det gör resurshanteringen enkel: objekt släpper ofta minne nära den punkt du slutat använda dem, vilket kan minska toppminneanvändning och undvika fördröjd återvinning.
Referensräkning ger ofta jämn, konstant overhead: increment/decrement‑operationer sker vid många tilldelningar och funktionsanrop. Den overheaden är vanligtvis liten, men den finns överallt.
Fördelen är att du typiskt inte får stora stop‑the‑world‑pauser som vissa tracing‑GC kan orsaka. Latensen är ofta jämnare, även om stora deallokeringsvågor kan uppstå när stora objektgrafer mister sin sista ägare.
Referensräkning kan inte återvinna objekt som ingår i en cykel. Om A refererar B och B refererar A så håller båda räknarna sig över noll även om inget annat når dem — vilket skapar en läcka.
Ekosystem hanterar detta på några sätt:
Ägarskap och borrowing associeras mest med Rust. Idén är enkel: kompilatorn tvingar regler som gör det svårt att skapa dangling pointers, dubbel‑free eller många data‑race‑typer — utan att förlita sig på en runtime‑GC.
Varje värde har exakt en ”ägare” åt gången. När ägaren går ur scope städas värdet omedelbart och förutsägbart. Det ger deterministisk resurshantering (minne, filhandtag, sockets) liknande manuell städning, men med färre sätt att göra fel.
Ägarskapet kan också flytta: att tilldela ett värde till en ny variabel eller skicka det till en funktion kan flytta ansvaret. Efter en move kan inte det gamla bindningen användas — det förhindrar use‑after‑free genom konstruktion.
Lån låter dig använda ett värde utan att bli dess ägare.
Ett delat lån tillåter läsning och kan kopieras fritt.
Ett muterbart lån tillåter uppdateringar men måste vara exklusivt: medan det finns får inget annat läsa eller skriva samma värde. Reglerna “en skrivare eller många läsare” kontrolleras av kompilatorn.
Eftersom livstider spåras kan kompilatorn förkasta kod som skulle leva längre än datat det refererar till, vilket eliminerar många dangling‑referens‑buggar. Samma regler förhindrar också en stor klass av race‑tillstånd i konkurrent kod.
Kompromissen är en inlärningskurva och vissa designbegränsningar. Du kan behöva omstrukturera dataflöden, införa tydligare ägarskapsgränser eller använda specialiserade typer för delat muterbart tillstånd.
Denna modell passar utmärkt för systems‑kod — tjänster, inbyggt, nätverk och prestandakritiska komponenter — där du vill ha förutsägbar städning och låg latens utan GC‑pauser.
När du skapar många kortlivade objekt — AST‑noder i en parser, entiteter i en game‑frame, temporära data under en webbförfrågan — kan kostnaden för att allokera och frigöra varje objekt individuellt dominera körningstiden. Arenor (även kallat regioner) och pooler är mönster som byter finmaskig free‑hantering mot snabb bulkhantering.
En arena är en minnes"zon" där du allokerar många objekt över tiden, och sedan frigör alla på en gång genom att nollställa eller släppa arenan.
Istället för att spåra varje objekts livslängd individuellt knyter du livstider till en tydlig gräns: “allt som allokerades för denna förfrågan” eller “allt som allokerades under kompileringen av denna funktion.”
Arenor är ofta snabba eftersom de:
Detta kan öka genomströmningen och även minska latensspikar orsakade av frekventa frees eller allocator‑konkurrens.
Arenor och pooler dyker upp i:
Huvudregeln är enkel: låt inte referenser rymma regionen som äger minnet. Om något som allokerats i en arena lagras globalt eller returneras bortom arenans livslängd riskerar du use‑after‑free.
Språk och bibliotek hanterar detta olika: vissa litar på disciplin och API:er, andra kodar in regiongränsen i typer.
Arenor och pooler är inte ett alternativ till garbage collection eller ägarskap — de är ofta ett komplement. GC‑språk använder vanligtvis objektpooler för heta vägar; ägarskapsbaserade språk kan använda arenor för att gruppera allokeringar och göra livstider explicita. Använt med omsorg levererar de “snabbt som standard” allokering utan att offra tydlighet om när minnet frigörs.
Ett språks minnesmodell är bara en del av prestanda‑ och säkerhetsbilden. Moderna kompilatorer och runtimes omskriver din kod för att allokera mindre, frigöra tidigare och undvika extra bokföring. Därför bryter tumregler som “GC är långsamt” eller “manuell minneshantering är snabbast” ofta ner i verkliga applikationer.
Många allokeringar finns bara för att passera data mellan funktioner. Med escape‑analys kan en kompilator bevisa att ett objekt aldrig överlever aktuell scope och hålla det på stacken i stället för heapen.
Det kan ta bort en heap‑allokering helt, tillsammans med associerade kostnader (GC‑spårning, referensräkningsuppdateringar, allocator‑lås). I managed‑språk är detta en huvudorsak till att små objekt kan vara billigare än man tror.
När en kompilator inlinar en funktion (ersätter ett anrop med funktionens kropp) kan den plötsligt se genom abstraktioner. Denna insyn möjliggör optimeringar som:
Väl designade API:er kan bli “kostnadsfria” efter optimering, även om de ser allokeringstunga ut i källkod.
En JIT (just‑in‑time) runtime kan optimera med verkliga produktionsdata: vilka kodvägar som är heta, typiska objektstorlekar och allokeringsmönster. Det förbättrar ofta genomströmningen men kan lägga till uppvärmningstid och ibland pauser för OJIT/GC.
Ahead‑of‑time kompilatorer måste gissa mer i förväg, men levererar förutsägbar uppstartstid och jämnare latens.
GC‑baserade runtimes exponerar inställningar som heap‑storlek, paus‑mål och generationsgränser. Justera dem när du har mätbart bevis (t.ex. latensspikar eller minnespress), inte som en första åtgärd.
Två implementationer av samma algoritm kan skilja sig i dolda allokeringsantal, temporära objekt och pekar‑traverseringar. Dessa skillnader interagerar med optimerare, allocator och cache‑beteende — så prestandajämförelser kräver profilering, inte antaganden.
Minneshanteringsval förändrar inte bara hur du skriver kod — de ändrar när arbete sker, hur mycket minne du måste reservera och hur konsekvent prestandan känns för användarna.
Genomströmning är ”hur mycket arbete per tidsenhet.” Tänk en nattlig batchjobb som bearbetar 10 miljoner poster: om garbage collection eller referensräkning lägger till liten overhead men håller utvecklaren produktiv kan du ändå bli färdig snabbast totalt.
Latens är ”hur lång tid en enskild operation tar end‑to‑end.” För en webbförfrågan skadar ett långsamt svar användarupplevelsen även om genomsnittlig genomströmning är hög. En runtime som ibland pausar för att återvinna minne kan vara acceptabel för batchjobb men märkbar i interaktiva appar.
Ett större minnesfötavtryck ökar molnkostnader och kan sakta ner program. När din working set inte passar bra i CPU‑cacher väntar CPU:n oftare på data från RAM. Vissa strategier byter extra minne mot snabbare körning (t.ex. hålla fria objekt i pooler), medan andra minskar minnet men lägger till bokförings‑overhead.
Fragmentering uppstår när ledigt minne splittras i många små gap — som att försöka parkera en skåpbil i en parkering med utspridda små platser. Allocators kan behöva mer tid för att hitta utrymme, och minnet kan växa även när det tekniskt finns nog fritt.
Cache‑lokalitet betyder att relaterad data sitter nära varandra. Pool/arena‑allokering förbättrar ofta lokalitet (objekt allokerade tillsammans hamnar nära varandra), medan långlivade heapar med blandade storlekar kan driva isär data till mindre cache‑vänliga layouter.
Om du behöver konsekventa svarstider — spel, ljudappar, trading, inbyggda eller realtidskontroller — kan “mestadels snabbt men ibland långsamt” vara sämre än “något långsammare men konsekvent.” Här spelar förutsägbara deallocationsmönster och strikt kontroll över allokeringar större roll.
Minnesfel är inte bara ”programmerarmisstag”. I många system blir de säkerhetsproblem: plötsliga krascher (DoS), oavsiktlig dataexponering (läsa frigjort eller oinitialiserat minne) eller exploaterbara tillstånd där angripare får programmet att köra oavsedd kod.
Olika minneshanteringsstrategier tenderar att misslyckas på olika sätt:
Samtidighet förändrar hotbilden: minne som är ”okej” i en tråd kan bli farligt när en annan tråd frigör eller muterar det. Modeller som tvingar regler kring delning (eller kräver explicit synkronisering) minskar risken för race‑tillstånd som leder till korrupt tillstånd, dataläckor och intermittenta krascher.
Ingen minnesmodell tar bort all risk — logikbuggar (auth‑fel, osäkra standarder, bristfällig validering) händer fortfarande. Starka team lägger på skydd: sanitizers i tester, säkra standardbibliotek, noggrann code review, fuzzing och strikta gränser runt unsafe/FFI‑kod. Minnesäkerhet minskar attackytan avsevärt, men är ingen garanti.
Minnesproblem är lättare att åtgärda när du fångar dem nära den ändring som introducerade dem. Nyckeln är att mäta först, och sedan avgränsa problemet med rätt verktyg.
Börja med att avgöra om du jagar prestanda eller minnesökning.
För prestanda mät wall‑clock‑tid, CPU‑tid, allokeringshastighet (bytes/sec) och tid i GC eller allocator. För minne spåra peak RSS, steady‑state RSS och objektantal över tid. Kör samma arbetsbelastning med konsekventa input; små variationer kan dölja allokeringschurn.
Vanliga tecken: en enskild förfrågan allokerar långt mer än väntat, eller minnet stiger med trafik även när genomströmningen är stabil. Fixar inkluderar återanvända buffrar, byta till arena/pool‑allokering för kortlivade objekt och förenkla objektgrafen så färre objekt överlever cykler.
Återskapa med minimal input, slå på strängaste runtime‑kontroller (sanitizers/GC‑verifiering), och fånga:
Behandla första fixen som ett experiment; kör om mätningarna för att bekräfta att ändringen minskade allokationer eller stabiliserade minne — utan att flytta problemet någon annanstans. För mer om att tolka avvägningar, se texten "/blog/performance-trade-offs-throughput-latency-memory-use".
Att välja språk handlar inte bara om syntax eller ekosystem — dess minnesmodell formar dagligt utvecklingsarbete, driftmässig risk och hur förutsägbar prestandan blir under verklig trafik.
Karta upp produktbehoven mot en minnesstrategi genom att svara på några praktiska frågor:
Om du byter modell, planera för friktion: anrop till befintliga bibliotek (FFI), blandade minneskonventioner, verktygskedjan och rekryteringsmarknaden. Prototyper hjälper att avslöja dolda kostnader (pauser, minnesökning, CPU‑overhead) tidigt.
Ett praktiskt tillvägagångssätt är att prototypa samma funktion i de miljöer du överväger och jämföra allokeringshastighet, svanslatens och toppminne under en representativ belastning. Team gör ibland denna typ av "äpplen‑mot‑äpplen"‑utvärdering i Koder.ai: du kan snabbt skissa en liten React‑frontend plus en Go + PostgreSQL‑backend, iterera över request‑former och datastrukturer för att se hur en GC‑baserad tjänst beter sig under realistisk trafik (och exportera källkoden när du är redo att gå vidare).
Definiera de 3–5 främsta begränsningarna, bygg en tunn prototyp och mät minnesanvändning, svanslatens och felbeteenden.
| Modell | Säkerhet som standard | Latens‑förutsägbarhet | Utvecklarhastighet | Typiska fallgropar |
|---|---|---|---|---|
| Manuell | Låg–Medel | Hög | Medel | läckor, use‑after‑free |
| GC | Hög | Medel | Hög | pauser, heap‑tillväxt |
| RC | Medel–Hög | Hög | Medel | cykler, overhead |
| Ägarskap | Hög | Hög | Medel | inlärningskurva |
Minneshantering är hur ett program allokerar minne för data (som objekt, strängar, buffertar) och sedan frigör det när det inte längre behövs.
Det påverkar:
Den stack är snabb, automatisk och knuten till funktionsanrop: när en funktion returnerar tas dess stackram bort i ett svep.
Den heap är flexibel för dynamisk eller långlivad data, men kräver en strategi för när och vem som frigör den.
En tumregel: stacken är utmärkt för kortlivade, faststorleks‑lokaler; heapen används när livslängd eller storlek är oförutsägbar.
En referens/pointer låter kod komma åt ett objekt indirekt. Faran uppstår när objektets minne frigörs men en referens fortfarande används.
Det kan leda till:
Du allokerar och frigör minne explicit (t.ex. malloc/free, new/delete).
Det är användbart när du behöver:
Kostnaden är högre buggrisk om ägarskap och livstider inte hanteras noggrant.
Manuell hantering kan ge mycket förutsägbar latens om programmet är väl designat, eftersom det inte finns någon bakgrunds‑GC som kan pausa körningen.
Du kan också optimera med:
Men det är lätt att oavsiktligt skapa dyra mönster (fragmentering, konkurrens om allocators, många små alloc/free‑anrop).
Garbage collection hittar automatiskt objekt som inte längre är åtkomliga och återvinner deras minne.
De flesta tracing‑GC gör ungefär så här:
Det ökar vanligtvis säkerheten (färre use‑after‑free‑fel) men lägger även till runtime‑arbete och kan orsaka pauser beroende på collector‑design.
Referensräkning frigör ett objekt när dess “ägarantal” når noll.
Fördelar:
Nackdelar:
Ägarskap/borrowing (särskilt Rusts modell) använder kompilatorregler för att förhindra många livstidsmisstag.
Kärnidéer:
Det ger förutsägbar städning utan GC‑pauser, men kräver ofta omstrukturering av dataflöden för att tillfredsställa kompilatorns livstidsregler.
En arena/region allokerar många objekt i en “zon” och frigör dem alla på en gång genom att nollställa eller släppa arenan.
Det är effektivt när du har en tydlig livstidsgräns, till exempel:
Huvudregeln: låt inte referenser läcka utanför den arena som äger minnet.
Börja med realistiska mätningar under rätt belastning:
Använd sedan verktyg som:
Många ekosystem använder svaga referenser eller en cykeldetektor för att hantera cykler.
Justera runtime‑inställningar (t.ex. GC‑parametrar) först när du har en mätbar orsak.