03 nov. 2025·8 min
Multi-tenant SaaS-mönster: isolering, skalning och AI-design
Lär dig vanliga multi-tenant SaaS-mönster, avvägningar för tenant-isolering och skalstrategier. Se hur AI-genererade arkitekturer kan snabba upp design och granskning.
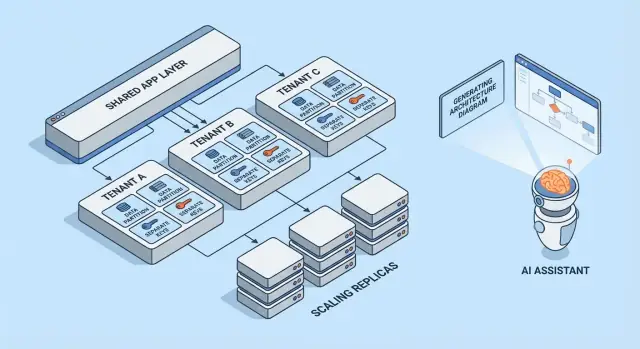
Vad multi-tenancy betyder (utan jargong)
Multi-tenancy betyder att en programvara tjänar flera kunder (tenants) från samma körande system. Varje tenant upplever att de har "sin egen app", men bakom kulisserna delar de delar av infrastrukturen — som samma webbservrar, samma kodbas och ofta samma databas.
En användbar mental modell är ett flerfamiljshus. Alla har sin låsta lägenhet (deras data och inställningar), men ni delar hiss, VVS och fastighetsskötare (appens compute, lagring och drift).
Varför team väljer multi-tenancy
De flesta team väljer inte multi-tenant SaaS för att det är trendigt — de väljer det för att det är effektivt:
- Lägre kostnad per kund: delad infrastruktur är vanligtvis billigare än att sätta upp hela stacken per kund.
- Enklare drift: en plattform att övervaka, patcha och säkra (istället för hundratals små deploymenter).
- Snabbare leverans: förbättringar når alla samtidigt och du undviker "versionsdrift" mellan kunder.
Var det kan gå fel
De två klassiska felkällorna är säkerhet och prestanda.
På säkerhetssidan: om tenant-gränser inte tillämpas överallt kan en bugg läcka data mellan kunder. Dessa läckor är sällan dramatiska "hack" — det är ofta vanliga misstag som en saknad filter, en felkonfigurerad behörighetskontroll eller ett background job som körs utan tenant-kontekst.
På prestandasidan: delade resurser betyder att en upptagen tenant kan sakta ner andra. Denna "störande granne"-effekt kan visa sig som långsamma frågor, burstiga arbetsbelastningar eller en kund som konsumerar oproportionerlig API-kapacitet.
Snabb överblick av mönstren som tas upp
Denna artikel går igenom byggstenarna team använder för att hantera dessa risker: dataisolering (databas, schema eller rader), tenant-medveten identitet och behörigheter, kontroller för störande grannar och operationella mönster för skalning och förändringshantering.
Den grundläggande avvägningen: isolering vs effektivitet
Multi-tenancy handlar om var du placerar dig på ett spektrum: hur mycket ni delar över tenants kontra hur mycket ni dedikerar per tenant. Varje arkitekturmönster nedan är bara en punkt på den linjen.
Delade vs dedikerade resurser: kärnspektrumet
I ena änden delar tenants nästan allt: samma applikationsinstanser, samma databaser, samma köer, samma cache — separerade logiskt med tenant-ID och åtkomstregler. Detta är typiskt det billigaste och enklaste att köra eftersom ni poolar kapacitet.
I andra änden får tenants sin egen "skiva" av systemet: separata databaser, separat compute, ibland även separata deploymenter. Detta ökar säkerhet och kontroll, men också driftöverhuvud och kostnader.
Varför isolering och kostnad drar åt motsatta håll
Isolering minskar chansen att en tenant kan komma åt en annan tenants data, konsumera deras prestandabudget eller påverkas av ovanliga användningsmönster. Det gör också vissa revisioner och regelefterlevnad enklare.
Effektivitet förbättras när du amorterar outnyttjad kapacitet över många tenants. Delad infrastruktur låter dig köra färre servrar, ha enklare deploy-pipelines och skala baserat på aggregerad efterfrågan snarare än värsta-fallet per tenant.
Vanliga beslutsdrivare
Din "rätta" punkt på spektrumet är sällan filosofisk — den drivs av begränsningar:
- SLA och kundförväntningar: strikta uptime- eller latensmål skjuter mot mer isolering.
- Compliance och datalokalisering: krav kan tvinga dedikerad lagring eller dedikerade miljöer.
- Tillväxtstadium: tidiga produkter startar ofta mer delat för att gå snabbare; senare kan ni erbjuda dedikerade alternativ för stora kunder.
- Operationell mognad: mer isolering betyder oftast fler saker att övervaka, patcha och migrera.
En enkel mental modell för att välja mönster
Ställ två frågor:
-
Hur stort inträdesområde (blast radius) är om en tenant beter sig illa eller blir komprometterad?
-
Vad kostar det för verksamheten att minska det inträdesområdet?
Om blast radius måste vara litet, välj fler dedikerade komponenter. Om kostnad och hastighet är viktigast, dela mer — och investera i starka åtkomstkontroller, rate limits och per-tenant-övervakning för att hålla delningen säker.
Multi-tenant-modeller i korthet
Multi-tenancy är inte en enda arkitektur — det är en uppsättning sätt att dela (eller inte dela) infrastruktur mellan kunder. Den bästa modellen beror på hur mycket isolering du behöver, hur många tenants du förväntar dig och hur mycket driftöverhuvud ditt team kan hantera.
1) Single-tenant (dedikerad) — baslinjen
Varje kund får sin egen appstack (eller åtminstone sitt eget isolerade runtime och databas). Detta är enklast att resonera om för säkerhet och prestanda, men är vanligtvis dyrast per kund och kan bromsa skalning av drift.
2) Delad app + delad DB — lägst kostnad, högst noggrannhet krävd
Alla tenants kör på samma applikation och databas. Kostnaderna är typiskt lägst eftersom du maximerar återanvändning, men du måste vara minutiös med tenant-kontekst överallt (frågor, caching, bakgrundsjobb, analysexporter). Ett enda misstag kan bli en cross-tenant-data-läcka.
3) Delad app + separat DB — starkare isolering, mer drift
Applikationen delas, men varje tenant har sin egen databas (eller databasinstans). Detta förbättrar blast-radius-kontroll vid incidenter, möjliggör enklare tenant-specifika backups/restore och kan förenkla compliance-samtal. Handikappet är operationellt: fler databaser att provisionera, övervaka, migrera och säkra.
4) Hybridmodeller för "stora tenants"
Många SaaS-produkter blandar tillvägagångssätt: de flesta kunder lever i delad infrastruktur, medan stora eller reglerade tenants får dedikerade databaser eller dedikerad compute. Hybrid blir ofta det praktiska slutläget, men det kräver tydliga regler: vem kvalificerar, vad det kostar och hur uppgraderingar rullas ut.
Om du vill gå djupare på isoleringstekniker i varje modell, se artikeln om data-isolationsmönster.
Dataisoleringsmönster (DB, schema, rad)
Dataisolering svarar på en enkel fråga: "Kan en kund någonsin se eller påverka en annan kunds data?" Det finns tre vanliga mönster, vardera med olika säkerhets- och operationella implikationer.
Radnivå-isolering (delade tabeller + tenant_id)
Alla tenants delar samma tabeller och varje rad inkluderar en tenant_id-kolumn. Detta är mest effektivt för små till medelstora tenants eftersom det minimerar infrastruktur och håller rapportering och analys enkel.
Riskerna är också tydliga: om någon fråga glömmer att filtrera på tenant_id kan du läcka data. En enda "admin"-endpoint eller bakgrundsjobb kan bli en svag punkt. Motåtgärder inkluderar:
- Tvinga tenant-filtrering i ett delat data-access-lager (så utvecklare inte handkodar filter)
- Använda databasfunktioner som row-level security (RLS) där det finns
- Lägga till automatiserade tester som medvetet försöker cross-tenant-åtkomst
- Indexera för vanliga accessvägar (ofta
(tenant_id, created_at)eller(tenant_id, id)) så att tenant-scope-frågor förblir snabba
Schema-per-tenant (samma databas, separata scheman)
Varje tenant får sitt eget schema (namnrymder som tenant_123.users, tenant_456.users). Detta förbättrar isolering jämfört med raddelning och kan göra tenant-export eller tenant-specifik tuning enklare.
Nackdelen är driftöverhuvud. Migrationer måste köras över många scheman, och fel blir mer komplicerade: du kan lyckas migrera 9 900 tenants och fastna på 100. Övervakning och verktyg är viktiga — din migrationsprocess behöver tydlig retry- och rapporteringsbeteende.
Databas-per-tenant (separata databaser)
Varje tenant får en separat databas. Isoleringen är stark: åtkomstgränser blir tydligare, bullriga frågor från en tenant påverkar mindre andra, och återställning av en enskild tenant från backup blir mycket renare.
Kostnader och skalning är de största nackdelarna: fler databaser att hantera, fler connection pools och potentiellt mer uppgraderings-/migrationsarbete. Många team reserverar detta för högvärdiga eller reglerade tenants, medan mindre kunder stannar i delad infrastruktur.
Sharding och placeringsstrategier när tenants växer
Reella system blandar ofta dessa mönster. En vanlig väg är radnivå-isolering vid tidig tillväxt, och sedan "promovera" större tenants till separata scheman eller databaser.
Sharding lägger till ett placeringslager: bestäm vilken databascluster en tenant bor på (efter region, storlekstier eller hashing). Nyckeln är att göra tenant-placering explicit och flyttbar — så att du kan flytta en tenant utan att skriva om appen, och skala genom att lägga till shards istället för att redesigna allt.
Identitet, åtkomst och tenant-kontekst
Multi-tenancy misslyckas på överraskande vardagliga sätt: ett saknat filter, ett cachat objekt delat mellan tenants eller ett admin-verktyg som "glömmer" vem förfrågan gäller för. Lösningen är inte en stor säkerhetsfunktion — det är konsekvent tenant-kontekst från första byte i en request till sista databasfrågan.
Tenantidentifiering (hur du vet "vem")
De flesta SaaS-produkter fastställer en primär identifierare och behandlar allt annat som bekvämlighet:
- Subdomän:
acme.yourapp.comär enkelt för användare och fungerar bra för tenant-brandade upplevelser. - Header: användbart för API-klienter och interna tjänster (men måste vara autentiserat).
- Token-claim: en signerad JWT (eller session) inkluderar
tenant_id, vilket gör den svår att manipulera.
Välj en sanningskälla och logga den överallt. Om du stödjer flera signaler (subdomän + token), definiera prioritet och avvisa tvetydiga förfrågningar.
Request-scoping (hur varje fråga hålls inom tenant)
En god regel: när du löst tenant_id ska allt nedströms läsa det från en enda plats (request context), inte återhämta det.
Vanliga skydd inkluderar:
- Middleware som fäster
tenant_idi request-konteksten - Dataaccess-hjälpare som kräver
tenant_idsom parameter - Databas-tillämpningar (som radnivå-policys) så att misstag misslyckas stängt
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Behörighetsgrunder (roller inom en tenant)
Separera autentisering (vem användaren är) från auktorisation (vad hen får göra).
Typiska SaaS-roller är Owner / Admin / Member / Read-only, men nyckeln är scope: en användare kan vara Admin i Tenant A och Member i Tenant B. Spara behörigheter per tenant, inte globalt.
Förhindra cross-tenant-läckor (tester och skydd)
Behandla cross-tenant-åtkomst som en högprioriterad incident och förebygg den proaktivt:
- Lägg till automatiserade tester som försöker läsa Tenant B-data medan autentisering är Tenant A
- Gör felaktiga tenant-filter svårare att släppa (linters, query builders, obligatoriska tenant-parametrar)
- Logga och larma på misstänkta mönster (t.ex. tenant-mismatch mellan token och subdomän)
Inkludera dessa regler i era drift-runbooks under säkerhetssektionen och håll dem versionshanterade tillsammans med koden.
Isolering bortom databasen
Hävda tenant-kontekst överallt
Be Koder.ai om middleware och data-access-mönster som håller tenant-kontekst konsekvent.
Databasisolering är bara halva bilden. Många verkliga multi-tenant-incidenter händer i det delade "rör" runt appen: cache, köer och lagring. Dessa lager är snabba, bekväma och lätta att av misstag göra globala.
Delade caches: förhindra nyckelkollisioner och data-läckor
Om flera tenants delar Redis eller Memcached är huvudregeln enkel: lagra aldrig tenant-agnostiska nycklar.
Ett praktiskt mönster är att prefixa varje nyckel med en stabil tenant-identifierare (inte en e-postdomän, inte visningsnamn). Till exempel: t:{tenant_id}:user:{user_id}. Detta gör två saker:
- Förhindrar kollisioner där två tenants har samma interna ID
- Gör bulk-invalidering möjlig (ta bort per prefix) vid supportincidenter eller migrationer
Bestäm också vad som får vara delat globalt (t.ex. offentliga feature flags, statisk metadata) och dokumentera det — oavsiktliga globala variabler är en vanlig källa till cross-tenant-exponering.
Tenant-medvetna rate limits och kvoter
Även om data är isolerad kan tenants fortfarande påverka varandra via delad compute. Lägg till tenant-medvetna begränsningar i kanten:
- API-rate limits per tenant (och ofta per användare inom en tenant)
- Kvoter för kostsamma operationer (exporter, rapportgenerering, AI-anrop)
Gör begränsningen synlig (headers, UI-meddelanden) så att kunder förstår att throttling är policy, inte instabilitet.
Bakgrundsjobb: partitionera köer per tenant
En enda delad kö kan låta en upptagen tenant dominera worker-tid.
Vanliga lösningar:
- Separata köer per tier/plan (t.ex.
free,pro,enterprise) - Partitionerade köer per tenant-bucket (hasha tenant_id till N köer)
- Tenant-medveten schemaläggning så varje tenant får en rättvis andel
Sprid alltid tenant-kontekst i jobpayload och loggar för att undvika felaktiga tenant-effekter.
Fil-/objektlagring: separata sökvägar, policyer och nycklar
För S3/GCS-stil lagring bygger isolering vanligen på sökväg och policy:
- Bucket-per-tenant för strikt separation (starkare gränser, mer overhead)
- Delad bucket med tenant-prefix (enklare, kräver noggrann IAM och signed URLs)
Oavsett val, säkerställ att uppladdningar/nerladdningar validerar tenant-ägarskap vid varje anrop, inte bara i UI:t.
Hantera störande grannar och rättvis resursanvändning
Multi-tenant-system delar infrastruktur, vilket innebär att en tenant kan råka (eller med avsikt) konsumera mer än sin rättvisa andel. Detta är noisy neighbor-problemet: en enda arbetsbelastning sänker prestanda för alla andra.
Hur en "störande granne" ser ut
Tänk dig en exportfunktion som genererar ett års data till CSV. Tenant A schemalägger 20 exporter klockan 09:00. De exporterna mättar CPU och databas-I/O, så Tenant B:s normala vyer börjar time-outa — trots att B inte gör något ovanligt.
Resurskontroller: limits, kvoter och workload shaping
Att förebygga detta börjar med uttryckliga resursgränser:
- Rate limits (requests per sekund) per tenant och per endpoint, så tunga API:er inte kan spamma
- Kvoter (dagliga/månatliga totalsummor) för exporter, mail, AI-anrop eller bakgrundsjobb
- Workload shaping: placera tunga uppgifter (exporter, importer, re-indexering) i köer med per-tenant-concurrency-caps och prioriteringsregler
Ett praktiskt mönster är att separera interaktiv trafik från batcharbete: håll användaransikten på en snabb fil och skjut allt annat till kontrollerade köer.
Per-tenant circuit breakers och bulkheads
Lägg till säkerhetsventiler som triggas när en tenant passerar en tröskel:
- Circuit breakers: temporärt avvisa eller skjuta upp kostsamma operationer när felrate, latens eller ködjup överstiger gränser för den tenanten
- Bulkheads: isolera delade pooler (DB-anslutningar, worker-trådar, cache) så en tenant inte kan tömma global kapacitet
Gör det rätt och Tenant A kan bara påverka sin egen exporthastighet utan att ta ner Tenant B.
När flytta en tenant till dedikerad kapacitet
Flytta en tenant till dedikerade resurser när de konstant överskrider antaganden för delad infrastruktur: ihållande hög genomströmning, oförutsägbara toppar kopplade till affärskritiska händelser, strikta compliancekrav eller när deras arbetsbelastning kräver egen tuning. En enkel regel: om ni måste permanent throttla en betalande kund för att skydda andra, är det dags för dedikerad kapacitet (eller en högre tier) istället för ständig brandkårsarbete.
Skalningsmönster som fungerar i multi-tenant SaaS
Planera din tenantmodell
Skissa en multi-tenant-appplan i chatten och iterera säkert med planning mode.
Multi-tenant-skalning handlar mindre om "fler servrar" och mer om att hålla en tenants tillväxt från att överraska alla andra. De bästa mönstren gör skala förutsägbar, mätbar och reversibel.
Horisontell skalning för stateless-tjänster
Börja med att göra web-/API-lagret stateless: lagra sessioner i en delad cache (eller använd tokenbaserad auth), lägg upp laddningar i objektlagring och skjut långkörande jobb till bakgrundsjobb. När requests inte beror på lokal minne eller disk kan du lägga till instanser bakom en load balancer och skala ut snabbt.
Ett praktiskt tips: behåll tenant-konteksten i kanten (härledd från subdomän eller headers) och vidarebefordra den till varje request-handler. Stateless betyder inte tenant-okunnig — det betyder tenant-medveten utan stickiga servrar.
Per-tenant hotspots: identifiera och jämna ut
De flesta skalningsproblem är "en tenant är annorlunda." Håll koll på hotspots som:
- En tenant som genererar oproportionerlig trafik
- Några tenants med mycket stora datamängder
- Batchig användning (månadsslut-rapporter, nattliga importer)
Jämningstaktiker inkluderar per-tenant-rate-limits, köbaserad ingestion, caching av tenant-specifika read-paths och sharding av tunga tenants till separata worker-pooler.
Read replicas, partitionering och asynkrona arbetsflöden
Använd read replicas för read-tunga arbetsflöden (dashboards, search, analytics) och håll skrivningar på primären. Partitionering (efter tenant, tid eller båda) hjälper till att hålla index mindre och frågor snabbare. För kostsamma uppgifter — exporter, ML-scoring, webhooks — föredra asynkrona jobb med idempotens så retries inte multiplicerar load.
Kapacitetsplaneringssignaler och enkla trösklar
Håll signalerna enkla och tenant-medvetna: p95-latens, felrate, ködjup, DB-CPU och per-tenant-request-rate. Sätt lättförståeliga trösklar (t.ex. "ködjup > N i 10 minuter" eller "p95 > X ms") som triggar autoscaling eller temporära tenant-caps — innan andra tenants märker det.
Observability och drift per tenant
Multi-tenant-system fallerar sällan globalt först — de fallerar vanligtvis för en tenant, en plan-tier eller en bullrig arbetsbelastning. Om dina loggar och dashboards inte kan svara på "vilken tenant påverkas?" på några sekunder, blir on-call-tiden gissningslek.
Tenant-medvetna loggar, metrics och traces
Börja med en konsekvent tenant-kontekst i all telemetri:
- Loggar: inkludera
tenant_id,request_idoch en stabilactor_id(user/service) på varje request och background job. - Metrics: emittera räknare och latenshistogram uppdelade efter tenant-tier som minst (t.ex.
tier=basic|premium) och efter hög-nivå-endpoint (inte råa URL:er). - Traces: propagagera tenant-kontekst som trace-attribut så du kan filtrera en långsam trace till en specifik tenant och se var tiden spenderas (DB, cache, tredjepartskall).
Håll kardinaliteten under kontroll: per-tenant-metrics för alla tenants blir dyrt. Ett vanligt kompromiss är tier-nivå-metrics som standard plus per-tenant-drilldown vid behov (t.ex. sampling av traces för "topp 20 tenants efter trafik" eller "tenants som för närvarande bryter SLO").
Undvik känsliga data-läckor i telemetri
Telemetri är en kanal för dataexport. Behandla den som produktionsdata.
Föredra ID:n framför innehåll: logga customer_id=123 istället för namn, e-post, tokens eller query-payloads. Lägg in redaction på logger/SDK-nivå och blocklista vanliga hemligheter (Authorization headers, API-nycklar). För supportflöden, lagra debug-payloads i ett separat, åtkomstkontrollerat system — inte i delade loggar.
SLOs per tenant-tier (utan överlöften)
Definiera SLOs som matchar vad ni faktiskt kan upprätthålla. Premium-tenants kan få snävare latens-/felbudgetar, men bara om ni också har kontroller (rate limits, workload isolation, priority queues). Publicera tier-SLOs som mål och spåra dem per tier och för ett urval av högvärdiga tenants.
On-call-runbooks: vanliga incidenter i multi-tenant SaaS
Era runbooks bör börja med "identifiera påverkade tenant(s)" och sedan snabbaste isolerande åtgärd:
- Störande granne: throttla tenanten, pausa tunga jobb eller flytta dem till en lägre prioriterad kö.
- DB-hotspots/runaway queries: aktivera query timeouts, inspektera toppfrågor per tenant, applicera index eller begränsa endpointen.
- Tenant-kontekstbuggar (data-blandning): stäng omedelbart av feature-flaggen eller endpointen och verifiera tenant-scoping i åtkomstkontroller.
- Bakgrundsjobbsköer som staplas upp: töm per-tenant-köer, begränsa concurrency och spela upp med idempotens-skydd.
Operationellt är målet enkelt: detektera per tenant, innehåll per tenant och återhämta utan att påverka alla andra.
Deployments, migrationer och tenant-för-tenant-utgåvor
Multi-tenant SaaS ändrar takten i leverans. Du deployar inte "en app"; du deployar delad runtime och delade datapaths som många kunder samtidigt beror på. Målet är att leverera nya funktioner utan att tvinga alla att uppgradera i en stor operation.
Rullande deployer och low-downtime-migrationer
Föredra deployments som tål blandade versioner ett kort fönster (blue/green, canary, rolling). Det funkar bara om dina databasändringar också är staged.
En praktisk regel är expand → migrate → contract:
- Expand: lägg till nya kolumner/tabeller/index utan att bryta befintlig kod.
- Migrate: backfyll data i batchar (ofta per tenant) och verifiera.
- Contract: ta bort gamla fält först när alla app-instanser inte längre använder dem.
För heta tabeller: gör backfills inkrementellt (och begränsa), annars skapar du din egen störande-granne-händelse under en migration.
Feature flags per tenant för säkrare utrullningar
Tenant-nivå feature flags låter dig deploya kod globalt men aktivera beteende selektivt.
Det stödjer:
- Early access-program för några tenants
- Snabb rollback genom att inaktivera en feature för påverkade tenants
- A/B-experiment utan att dela upp deployment
Håll flaggsystemet auditable: vem aktiverade vad, för vilken tenant och när.
Versionering och bakåtkompatibilitetsförväntningar
Anta att vissa tenants kan ligga efter i konfiguration, integrationer eller användningsmönster. Designa API:er och event med tydlig versionering så nya producenter inte bryter gamla konsumenter.
Vanliga interna förväntningar att sätta:
- Nya releaser måste läsa både gamla och nya format under migrationsfönster.
- Deprecationer kräver en publicerad tidslinje (även om det bara är interna anteckningar plus en kund-e-postmall).
Tenant-specifik konfigurationshantering
Behandla tenant-konfig som en produktyta: den behöver validering, standardvärden och ändringshistorik.
Spara konfiguration separat från kod (och helst separat från runtime-hemligheter), och stöd en safe-mode-fallback när konfig är ogiltig. En lätt intern sida för tenant-inställningar kan spara timmar vid incidenthantering och staged rollouts.
Hur AI-genererade arkitekturer hjälper (och deras begränsningar)
Prototypa multi-tenancy snabbt
Generera en React + Go + PostgreSQL-skelett för att testa tenant-scoping tidigt.
AI kan snabba upp tidig arkitekturtänk för multi-tenant SaaS, men det ersätter inte ingenjörsbedömning, testning eller säkerhetsgranskning. Behandla det som en högkvalitativ brainstorming-partner som producerar utkast — verifiera sedan varje antagande.
Vad AI-genererad arkitektur bör (och inte bör) göra
AI är användbar för att generera alternativ och lyfta fram typiska felpunkter (som var tenant-kontekst kan försvinna eller var delade resurser kan skapa överraskningar). Den bör inte bestämma din modell, garantera compliance eller validera prestanda. Den kan inte se din verkliga trafik, ditt teams styrkor eller kantfall i gamla integrationer.
Inputs som betyder något: krav, begränsningar, risker, tillväxt
Kvaliteten på output beror på vad du matar in. Hjälpsamma inputs inkluderar:
- Antal tenants idag vs. om 12–24 månader, och förväntad datamängd per tenant
- Isoleringskrav (kontraktuella, regulatoriska, kundförväntningar)
- Budget och driftkapacitet (on-call-mognad, SRE-stöd, verktyg)
- Latensmål, peakmönster och burstiness per tenant
- Risktolerans: vad händer om en tenant påverkar en annan?
Använd AI för att föreslå mönster med avvägningar
Be om 2–4 kandidatdesigner (t.ex. databas-per-tenant vs schema-per-tenant vs radnivå) och begär en tydlig jämförelse av avvägningar: kostnad, driftkomplexitet, blast radius, migrationsinsats och skalgränser. AI är bra på att lista gotchas du kan omvandla till designfrågor för ditt team.
Om du vill gå från "utkastarkitektur" till ett fungerande prototyp snabbare kan en vibe-coding-plattform som Koder.ai hjälpa dig att förvandla de valen till ett verkligt app-skelett via chat — ofta med en React-frontend och en Go + PostgreSQL-backend — så du kan validera tenant-kontektspropagering, rate limits och migrationsarbetsflöden tidigare. Funktioner som planning mode plus snapshots/rollback är särskilt användbara när du itererar på multi-tenant-datamodeller.
Använd AI för att generera threat models och checklista
AI kan utarbeta en enkel threat model: entry points, trust boundaries, tenant-kontektspropagering och vanliga misstag (som saknade auktoriseringskontroller i bakgrundsjobb). Använd det för att generera review-checklistor för PRs och runbooks — men validera med riktig säkerhetsexpertis och er egen incidenthistorik.
En praktisk urvalschecklista för ditt team
Att välja ett multi-tenant-tillvägagångssätt handlar mindre om "bästa praxis" och mer om passform: din datas känslighet, din tillväxthastighet och hur mycket driftkomplexitet ni kan bära.
Steg-för-steg-checklista (använd i en 30-minuters workshop)
-
Data: Vilken data delas mellan tenants (om någon)? Vad får aldrig vara samlokaliserat?
-
Identitet: Var bor tenant-identity (invite-länkar, domäner, SSO-claims)? Hur etableras tenant-kontekst på varje förfrågan?
-
Isolering: Bestäm er standardnivå för isolering (rad/schema/databas) och identifiera undantag (t.ex. enterprise-kunder som behöver starkare separation).
-
Skalning: Identifiera den första skalningspressen ni väntar er (lagring, read-trafik, bakgrundsjobb, analys) och välj det enklaste mönstret som adresserar det.
Frågor att validera med utvecklare och säkerhetsgranskare
- Hur förhindrar vi cross-tenant-åtkomst om en utvecklare glömmer ett filter?
- Vad är vår audit-story per tenant (vem gjorde vad, när)?
- Hur hanterar vi dataradering och retention per tenant?
- Vad är blast radius för en dålig migration eller runaway-query?
- Kan vi throttla, rate-limita och budgetera resurser per tenant?
Varningssignaler som kräver djupare designarbete
- "Vi lägger till tenant-kontroller senare."
- Delade admin-verktyg som kan se allt utan strikta kontroller.
- Ingen plan för per-tenant backup/restore eller incidentrespons.
- En enda kö/worker-pool utan per-tenant-rättvisa.
Exempel på "rekommenderad nästa åtgärd"-sammanfattning
Rekommendation: Starta med radnivå-isolering + strikt tenant-kontekstpåverkan, lägg till per-tenant-throttles och definiera en uppgraderingsväg till schema-/databasisolering för hög-risk-tenants.
Nästa åtgärder (2 veckor): threat-modelera tenant-gränser, prototypa enforcement i en endpoint och genomför en migrationsrepetition i en stagingkopia. För vägledning i utrullning, se interna riktlinjer för tenant-utrullningar.