30 aug. 2025·8 min
Nginx vs HAProxy: Välj rätt reverse proxy
Jämför Nginx och HAProxy som reverse proxies: prestanda, lastbalansering, TLS, observerbarhet, säkerhet och vanliga konfigurationer för att välja bästa passformen.
Jämför Nginx och HAProxy som reverse proxies: prestanda, lastbalansering, TLS, observerbarhet, säkerhet och vanliga konfigurationer för att välja bästa passformen.
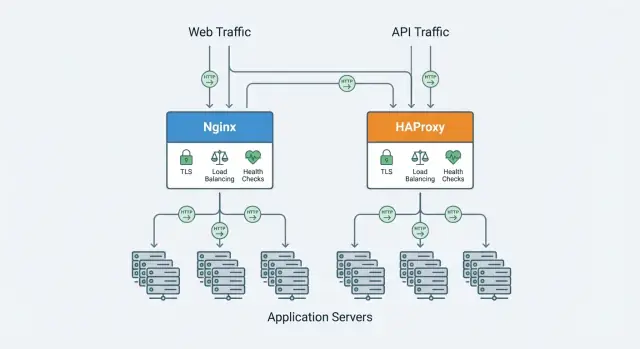
En reverse proxy är en server som står framför dina applikationer och tar emot klientförfrågningar först. Den vidarebefordrar varje begäran till rätt backend‑tjänst (dina appservrar) och returnerar svaret till klienten. Användare pratar med proxyn; proxyn pratar med dina appar.
En forward proxy fungerar tvärtom: den sitter framför klienter (till exempel i ett företagsnätverk) och vidarebefordrar deras utgående förfrågningar till internet. Den handlar mest om att kontrollera, filtrera eller dölja klienttrafik.
En lastbalanserare implementeras ofta som en reverse proxy, men med fokus på att fördela trafik över flera backend‑instanser. Många produkter (inklusive Nginx och HAProxy) gör både reverse proxying och lastbalansering, så termerna används ibland omväxlande.
De flesta distributioner börjar av en eller flera av dessa anledningar:
/api till en API‑tjänst, / till en webbapp).Reverse proxies frontar ofta webbplatser, API:er och mikrotjänster—antingen i kanten (publikt internet) eller internt mellan tjänster. I moderna stackar används de också som byggstenar för ingress‑gateways, blue/green‑distributioner och hög‑tillgängliga uppsättningar.
Nginx och HAProxy överlappar, men de skiljer sig i fokus. I följande avsnitt jämför vi beslutsfaktorer som prestanda vid många anslutningar, lastbalansering och hälsokontroller, protokollstöd (HTTP/2, TCP), TLS‑funktioner, observerbarhet och daglig konfiguration och drift.
Nginx används mycket både som webbserver och som reverse proxy. Många team börjar med den för att servera en publik webbplats och utökar sedan dess roll att sitta framför applikationsservrar—hantera TLS, routa trafik och jämna ut trafiktoppar.
Nginx glänser när din trafik huvudsakligen är HTTP(S) och du vill ha en enda “entrédörr” som kan göra lite av allt. Den är särskilt bra på:
X-Forwarded-For, säkerhetsheaders)Eftersom den både kan servera innehåll och proxy:a till appar är Nginx ett vanligt val för små till medelstora miljöer där du vill ha färre rörliga delar.
Populära kapabiliteter inkluderar:
Nginx väljs ofta när du behöver en ingångspunkt för:
Om ditt fokus är riktad HTTP‑hantering och du gillar tanken att kombinera webbserver och reverse proxy, är Nginx ofta standardvalet.
HAProxy (High Availability Proxy) används främst som en reverse proxy och lastbalanserare som sitter framför en eller flera applikationsservrar. Den tar emot inkommande trafik, tillämpar routing‑ och trafikregler och vidarebefordrar förfrågningar till friska backends—ofta samtidigt som svarstider hålls stabila under hög samtidighet.
Team använder HAProxy för trafikhantering: sprida förfrågningar över flera servrar, hålla tjänster tillgängliga vid fel och jämna ut trafiktoppar. Den är ett vanligt val i kanten (north–south) och även mellan interna tjänster (east–west), särskilt när du behöver förutsägbarhet och stark kontroll över anslutningshantering.
HAProxy är känt för effektiv hantering av ett stort antal samtidiga anslutningar. Det spelar roll när du har många klienter uppkopplade samtidigt (belastade API:er, långlivade anslutningar, pratiga mikrotjänster) och vill att proxyn ska vara responsiv.
Dess lastbalanseringsmöjligheter är en stor anledning till valet. Utöver enkel round‑robin stödjer den flera algoritmer och routingstrategier som hjälper dig att:
Hälsokontroller är också en styrka. HAProxy kan aktivt verifiera backend‑hälsa och automatiskt ta ur osunda instanser ur rotation, för att sedan lägga tillbaka dem när de återhämtat sig. I praktiken minskar detta driftstopp och förhindrar att delvis trasiga distributioner påverkar alla användare.
HAProxy kan köra på Lager 4 (TCP) och Lager 7 (HTTP).
Den praktiska skillnaden: L4 är ofta enklare och mycket snabbt för TCP‑forwarding, medan L7 ger rikare routing och förfrågningslogik när du behöver det.
HAProxy väljs ofta när huvudmålet är pålitlig, högpresterande lastbalansering med starka hälsokontroller—till exempel att distribuera API‑trafik över flera appservrar, hantera failover mellan availability zones eller fronta tjänster där anslutningsvolym och förutsägbart trafikbeteende är viktigare än avancerade webbserverfunktioner.
Prestandajämförelser går ofta fel eftersom folk tittar på ett enda tal (som “max RPS”) och ignorerar vad användare faktiskt upplever.
En proxy kan öka genomströmningen men samtidigt förvärra tail‑latens om den buffrar för mycket under belastning.
Tänk på din applikations “form”:
Om du benchmarkar med ett mönster men distribuerar ett annat kommer resultaten inte överensstämma.
Buffring kan hjälpa när klienter är långsamma eller burstiga, eftersom proxyn kan läsa hela förfrågan (eller svaret) och mata din app i ett jämnare flöde.
Buffring kan skada när din app gynnas av streaming (server‑sent events, stora nedladdningar, realtids‑API:er). Extra buffring tillför minnestryck och kan öka tail‑latens.
Mät mer än “max RPS”:
Om p95 stiger kraftigt innan fel uppstår ser du tidiga tecken på mättnad—inte frikapacitet.
Både Nginx och HAProxy kan sitta framför flera applikationsinstanser och sprida trafik, men de skiljer sig i hur djup deras lastbalanseringsfunktionalitet är ur lådan.
Round‑robin är standard och ett gott val när backends är lika (samma CPU/minne, samma kostnad per förfrågan). Det är enkelt, förutsägbart och fungerar bra för stateless‑appar.
Least connections är användbart när förfrågningar varierar i längd (filnedladdningar, långa API‑anrop, chat/WebSocket‑liknande arbetslaster). Den tenderar att hålla långsammare servrar från att bli överbelastade.
Viktad balansering (round‑robin med weights eller weighted least connections) är praktiskt när servrar inte är identiska—blanda gamla och nya noder, olika instansstorlekar eller skifta trafik gradvis under en migration.
Generellt erbjuder HAProxy fler algoritmval och finare kontroll på Lager 4/7, medan Nginx täcker vanliga fall på ett rent sätt (och kan utökas beroende på edition/moduler).
Stickiness håller en användare routad till samma backend över flera förfrågningar.
Använd persistens endast när det är nödvändigt (legacy‑server‑sidor sessioner). Stateless‑appar skalar och återhämtar sig bättre utan det.
Aktiva hälsokontroller sonderar backends periodiskt (HTTP‑endpoint, TCP‑connect, väntat status). De hittar fel även när trafiken är låg.
Passiva hälsokontroller reagerar på verklig trafik: timeouts, anslutningsfel eller dåliga svar markerar en server som ohälsosam. De är lätta för resurser men kan ta längre tid att upptäcka problem.
HAProxy är vida känt för rika hälsokontroll‑ och felhanteringsinställningar (trösklar, rise/fall‑räkningar, detaljerade checks). Nginx har också solida kontroller, med kapacitet beroende på build och edition.
För rolling deploys, titta på:
Oavsett val, kombinera draining med korta, väldefinierade timeouts och en tydlig “ready/unready”‑hälsodendpoint så trafiken flyttas smidigt under deploys.
Reverse proxies sitter i systemets kant, så protokoll‑ och TLS‑val påverkar allt från webbläsarprestanda till hur säkert tjänster kommunicerar med varandra.
Både Nginx och HAProxy kan “terminera” TLS: ta emot krypterade anslutningar från klienter, dekryptera trafiken och vidarebefordra förfrågningar till dina appar över HTTP eller återkrypterat TLS.
Den operativa verkligheten är certifikathantering. Du behöver en plan för:
Nginx väljs ofta när TLS‑terminering parats med webbserverfunktioner (statisk filservering, omdirigeringar). HAProxy väljs ofta när TLS främst ingår i ett trafikhanteringslager (lastbalansering, anslutningshantering).
HTTP/2 kan minska laddningstider i webbläsare genom multiplexing över en anslutning. Båda verktygen stödjer HTTP/2 på klient‑sidan.
Nyckelöverväganden:
Om du behöver routa icke‑HTTP‑trafik (databaser, SMTP, Redis, egna protokoll) behöver du TCP‑proxying snarare än HTTP‑routing. HAProxy används ofta för högpresterande TCP‑lastbalansering med fina anslutningskontroller. Nginx kan också proxy:a TCP (via sina stream‑funktioner), vilket räcker för enkel pass‑through.
mTLS verifierar båda sidor: klienter presenterar certifikat, inte bara servrar. Det passar bra för tjänst‑till‑tjänst‑kommunikation, partnerintegrationer eller zero‑trust‑designer. Båda proxyerna kan validera klientcertifikat i kanten, och många team använder även mTLS internt mellan proxy och upstreams för att minska antaganden om ett ”betrott nätverk”.
Reverse proxies är mitt i varje förfrågan, så de är ofta bästa platsen för att svara på “vad hände?”. Bra observerbarhet innebär konsekventa loggar, ett litet set högsignal‑metricer och ett repeterbart sätt att debugga timeouts och gateway‑fel.
Minst, ha access‑logs och error‑logs på i produktion. För access‑logs inkludera upstream‑timing så att du kan avgöra om det var proxyn eller applikationen som var långsam.
I Nginx är vanliga fält request time och upstream timing (t.ex. $request_time, $upstream_response_time, $upstream_status). I HAProxy, slå på HTTP log‑läge och fånga timingfält (queue/connect/response times) så du kan skilja "väntan på backend‑plats" från "backend var långsam."
Håll loggar strukturerade (JSON om möjligt) och lägg till ett request‑ID (från inkommande header eller genererat) för att korrelera proxy‑loggar med app‑loggar.
Oavsett om du skrapar Prometheus eller skickar metrics annat håll, exportera ett konsekvent set:
Nginx använder ofta stub status‑endpoint eller en Prometheus‑exporter; HAProxy har en inbyggd stats‑endpoint som många exporters läser från.
Exponera en lätt /health (processen är uppe) och /ready (kan nå beroenden) endpoint. Använd dem i automation: lastbalanserarens hälsokontroller, distributioner och autoscaling‑beslut.
När du felsöker, jämför proxy‑timing (connect/queue) med upstream‑responstid. Om connect/queue är hög, lägg till kapacitet eller justera lastbalansering; om upstream‑tiden är hög, fokusera på applikation och databas.
Att köra en reverse proxy handlar inte bara om topprestanda—det handlar också om hur snabbt ditt team kan göra säkra ändringar kl. 14:00 (eller 02:00).
Nginx-konfiguration är direktiv‑baserad och hierarkisk. Den läses som “block i block” (http → server → location), vilket många finner tilltalande när de tänker i termer av sajter och rutter.
HAProxy-konfiguration är mer "pipeline‑lik": du definierar frontends (vad du accepterar), backends (var du skickar trafik) och fäster sedan regler (ACLs) för att koppla ihop dem. Det kan kännas mer explicit och förutsägbart när du väl internaliserat modellen, särskilt för trafiklogik.
Nginx brukar ladda om konfig genom att starta nya workers och graciöst dränera gamla. Det är snällt för frekventa ruttuppdateringar och certifikatsförnyelser.
HAProxy kan också göra sömlösa omladdningar, men team behandlar den ofta som en “appliance”: striktare change control, versionerad konfig och noggrann koordinering kring reload‑kommandon.
Båda stöder konfigtest före omladdning (måste i CI/CD). I praktiken håller du ofta konfig DRY genom att generera dem:
Nyckelvanan: behandla proxy‑konfig som kod—granska, testa och distribuera som applikationsändringar.
När antalet tjänster växer blir certifikat‑ och routing‑sprawl verkligt. Planera för:
Om du förväntar dig hundratals hosts, överväg att centralisera mönster och generera konfigurering från service‑metadata istället för manuell filredigering.
Om ni bygger och itererar på flera tjänster är en reverse proxy bara en del av leveranspipen—ni behöver fortfarande upprepbara app‑scaffolds, miljöparitet och säkra utgåvor.
Koder.ai kan hjälpa team att röra sig snabbare från idé till körbara tjänster genom att generera React‑webbappar, Go + PostgreSQL‑backends och Flutter‑mobilappar via ett chattbaserat arbetsflöde, samt stödja source code export, deployment/hosting, custom domains och snapshots med rollback. I praktiken kan ni prototypa ett API + webbfrontend, distribuera det och sedan avgöra om Nginx eller HAProxy är bättre baserat på verkliga trafikmönster istället för gissningar.
Säkerhet handlar sällan om en magisk funktion—det handlar om att minska blast‑radius och strama åt standarder kring trafik du inte fullt ut kontrollerar.
Kör proxyn med minsta möjliga privilegier: bind privilegierade portar via capabilities (Linux) eller en frontande tjänst och håll workerprocesser icke‑privilegierade. Lås konfig och nyckelmaterial (privata TLS‑nycklar, DH‑params) till read‑only för service‑kontot.
På nätverksnivå, tillåt inkommande endast från förväntade källor (internet → proxy; proxy → backends). Försök förhindra direkt access till backends så proxyn blir den enda chokepunkten för autentisering, rate limiting och loggning.
Nginx har förstaklassiga primitiv som request rate limiting och connection limiting (ofta via limit_req / limit_conn). HAProxy använder ofta stick tables för att spåra förfrågningshastigheter, samtidiga anslutningar eller felmönster och sedan neka, långsamt eller blockera missbrukande klienter.
Välj ett tillvägagångssätt som matchar din hotbild:
Var tydlig med vilka headers du litar på. Acceptera bara X-Forwarded-For (och släktingar) från kända upstreams; annars kan angripare förfalska klient‑IP:er och kringgå IP‑baserade kontroller. Validera eller sätt Host för att förebygga host‑header‑attacker och cache‑poisoning.
En enkel tumregel: proxyn bör sätta forwarding‑headers, inte blint vidarebefordra dem.
Request‑smuggling exploaterar ofta tvetydig parsing (motstridiga Content-Length / Transfer-Encoding, konstiga blanksteg eller ogiltig header‑formatering). Föredra strikt HTTP‑parsing, avvisa malformerade headers och sätt konservativa gränser:
Connection, Upgrade och hop‑by‑hop headersDessa kontroller skiljer sig i syntax mellan Nginx och HAProxy, men målet är samma: fail‑closed på tvetydighet och tydliga gränser.
Reverse proxies introduceras oftast på två sätt: som en dedikerad ingång för en enskild applikation, eller som en delad gateway som sitter framför många tjänster. Både Nginx och HAProxy kan göra båda—vad som spelar roll är hur mycket routinglogik du behöver i kanten och hur ni vill drifta det dagligen.
Detta mönster sätter en reverse proxy direkt framför en enda webbapp (eller ett fåtal tätt relaterade tjänster). Det passar när du främst behöver TLS‑terminering, HTTP/2, komprimering, caching (om du använder Nginx) eller tydlig separation mellan "publikt internet" och "privat app."
Använd det när:
Här routar en (eller ett litet kluster) proxys trafik till flera applikationer baserat på hostname, path, headers eller andra request‑egenskaper. Detta minskar antalet publika ingångspunkter men ökar vikten av ren konfighantering och change control.
Använd det när:
app1.example.com, app2.example.com) och vill ha ett enda ingress‑lager.Proxys kan dela trafik mellan “gammal” och “ny” version utan att ändra DNS eller applikationskod. Ett vanligt tillvägagångssätt är att definiera två upstream‑pooler (blue och green) eller två backends (v1 och v2) och sedan gradvis flytta trafik.
Typiska användningar:
Detta är särskilt användbart när ditt deploy‑verktyg inte kan göra viktade rollouter eller när du vill ha en enhetlig utrullningsmetod över team.
En enda proxy är en single point of failure. Vanliga HA‑mönster inkluderar:
Välj baserat på din miljö: VRRP är populärt på traditionella VMs/bare metal; hanterade load balancers är ofta enklast i moln.
En typisk "front‑to‑back" kedja är: CDN (valfritt) → WAF (valfritt) → reverse proxy → applikation.
Om du redan använder CDN/WAF, håll proxyn fokuserad på apptillhandahållande och routing snarare än att göra den till ditt enda säkerhetslager.
Kubernetes förändrar hur du "frontar" applikationer: tjänster är flyktiga, IP:er ändras och routingbeslut sker ofta i kanten av klustret via en Ingress‑controller. Både Nginx och HAProxy kan passa bra här, men de excellerar i något olika roller.
I praktiken är beslutet sällan "vilken är bättre", snarare "vilken passar dina trafikmönster och hur mycket HTTP‑manipulation behöver du i kanten."
Om du kör en service mesh (t.ex. mTLS och trafikpolicies internt) kan du fortfarande ha Nginx/HAProxy i kanten för north–south‑trafik (internet → kluster). Mesen hanterar east–west‑trafik (tjänst → tjänst). Denna uppdelning håller kant‑bekymren—TLS‑terminering, WAF/rate limiting, grundläggande routing—separerade från interna tillförlitlighetsfunktioner som retries och circuit breaking.
gRPC och långlivade anslutningar belastar proxys annorlunda än korta HTTP‑förfrågningar. Håll koll på:
Oavsett val, testa med realistiska varaktigheter (minuter/timmar), inte bara snabba smoke‑tester.
Behandla proxy‑konfig som kod: spara i Git, validera ändringar i CI (lint, konfigtest) och rulla ut via CD med kontrollerade distributioner (canary eller blue/green). Det gör uppgraderingar säkrare och ger tydlig audit när en routing‑ eller TLS‑ändring påverkar produktion.
Det snabbaste sättet att välja är att utgå från vad du förväntar dig att proxyn ska göra dagligen: servera innehåll, forma HTTP‑trafik eller strikt hantera anslutningar och balanseringslogik.
Om din reverse proxy också är en "front door" för webbtrafik är Nginx ofta ett bekvämt default.
Om ditt fokus är exakt trafikfördelning och strikt kontroll under belastning tenderar HAProxy att glänsa.
Att använda båda är vanligt när du vill ha webbserver‑bekvämligheter och specialiserad balansering:
Denna uppdelning kan också hjälpa team att separera ansvar: webb‑bekymmer vs trafik‑engineering.
Fråga dig:
En reverse proxy sitter framför dina applikationer: klienter ansluter till proxyn, och proxyn vidarebefordrar förfrågningar till rätt backend‑tjänst och returnerar svaret.
En forward proxy sitter framför klienter och kontrollerar utgående internetåtkomst (vanligt i företagsnätverk).
En load balancer fokuserar på att fördela trafik över flera backend‑instanser. Många load balancers implementeras som reverse proxies, vilket är anledningen till att begreppen ofta överlappar.
I praktiken använder du ofta ett verktyg (som Nginx eller HAProxy) för både reverse proxy‑funktioner och lastbalansering.
Placera den där du vill ha en enda kontrollpunkt:
Nyckeln är att undvika att klienter når backends direkt så att proxyn förblir chokepunkten för policy och synlighet.
TLS‑terminering innebär att proxyn hanterar HTTPS: den tar emot krypterade klientanslutningar, dekrypterar dem och vidarebefordrar trafiken till upstreams över HTTP eller återkrypterat TLS.
Operativt måste du planera för:
Välj Nginx när din proxy också är en webb‑“front door”:
Välj HAProxy när trafikhantering och förutsägbarhet under hög belastning är prioritet:
Använd round‑robin för likartade backends och jämn förfrågningskostnad.
Använd least connections när förfrågningarnas varaktighet varierar (nedladdningar, långa API‑anrop, långlivade anslutningar) för att undvika att långsamma instanser blir överbelastade.
Använd weighted–varianter när backends skiljer sig åt (olika maskinvarustorlek, blandade noder, gradvisa migreringar) så att du kan styra trafik med avsikt.
Stickiness håller en användare kopplad till samma backend över förfrågningar.
Undvik sessionstillstånd om möjligt: stateless‑tjänster skalar, återhämtar sig och rullas ut enklare utan det.
Buffering kan hjälpa genom att jämna ut långsamma eller burstiga klienter så att din app ser mer stabil trafik.
Det kan skada när du behöver streaming (SSE, WebSockets, stora nedladdningar), eftersom extra buffering ökar minnestryck och kan förvärra tail‑latency.
Om din app är stream‑orienterad, testa och tunna buffringen istället för att förlita dig på standardinställningar.
Börja med att separera proxy‑fördröjning från backend‑fördröjning med hjälp av loggar/metrics.
Vanliga betydelser:
Bra signaler att jämföra:
Åtgärder är ofta att justera timeouts, öka backend‑kapacitet eller förbättra hälsokontroller/readiness‑endpoints.