Noam Shazeer och Transformer-arkitekturen bakom LLM:er
Lär dig hur Noam Shazeer bidrog till Transformern: självuppmärksamhet, uppmärksamhet med flera huvuden och varför denna design blev ryggraden i moderna LLM:er.
Varför Transformern fortfarande spelar roll
En Transformer är ett sätt att hjälpa datorer förstå sekvenser—ting där ordning och kontext betyder något, som meningar, kod eller en serie sökfrågor. Istället för att läsa ett token i taget och föra med sig ett skört minne framåt, tittar Transformern över hela sekvensen och bestämmer vad som är värt att uppmärksamma när den tolkar varje del.
Den enkla förändringen visade sig vara viktig. Det är en huvudorsak till att moderna stora språkmodeller (LLM:er) kan hålla kvar kontext, följa instruktioner, skriva sammanhängande stycken och generera kod som refererar till tidigare funktioner och variabler.
Varför du stöter på Transformers hela tiden
Om du har använt en chatbot, en ”summera detta”-funktion, semantisk sökning eller en kodassistent har du interagerat med system baserade på Transformer-arkitekturen. Samma grundidé driver:
- chatt- och kundsupportverktyg som håller koll på vad du sa tidigare
- sök- och rekommendationssystem som matchar betydelse, inte bara nyckelord
- sammanfattningar som kan väga vad som är centralt mot detaljer
- kodverktyg som kopplar definitioner, användning och avsikt över filer
Vad du får lära dig i den här artikeln
Vi bryter ner nyckelkomponenterna—självuppmärksamhet, uppmärksamhet med flera huvuden, positionskodning och den grundläggande Transformer-blocket—och förklarar varför denna design skalar så bra när modeller växer.
Vi nämner också moderna varianter som behåller kärn idén men ändrar den för snabbare körning, lägre kostnad eller längre kontextfönster.
Vad du kan förvänta dig (och inte)
Det här är en översikt på hög nivå med vardagliga förklaringar och minimal matematik. Målet är intuition: vad delarna gör, varför de fungerar ihop och hur det översätts till verkliga produktmöjligheter.
Noam Shazeers roll i Transformer-berättelsen
Noam Shazeer är en AI-forskare och ingenjör mest känd som en av medförfattarna till 2017-papperet “Attention Is All You Need.” Det papperet introducerade Transformer-arkitekturen, som senare blev grunden för många moderna stora språkmodeller (LLM:er). Shazeers arbete ingår i ett lagarbete: Transformern skapades av en grupp forskare på Google, och det är viktigt att ge det erkännandet.
Vad 2017-papperet förändrade
Innan Transformern förlitade sig många NLP-system på rekurrenta modeller som bearbetade text steg för steg. Transformers visade att du kunde modellera sekvenser effektivt utan rekurrens genom att använda uppmärksamhet som huvudmekanism för att kombinera information över en mening.
Skiftet var viktigt eftersom det gjorde träningen lättare att parallellisera (du kan behandla många token samtidigt) och öppnade dörren för att skala modeller och datamängder på ett sätt som snabbt blev praktiskt för verkliga produkter.
Från forskningsidé till byggsten i produktutveckling
Shazeers bidrag—tillsammans med de andra författarna—stannade inte vid akademiska benchmark-resultat. Transformern blev en återanvändbar modul som team kunde anpassa: byta ut komponenter, ändra storlek, finjustera för uppgifter och senare förtränas i stor skala.
Så reser många genombrott: ett papper introducerar ett rent, generellt recept; ingenjörer förfinar det; företag operationaliserar det; och slutligen blir det ett standardval för att bygga språksfunktioner.
Hålla erkännandet korrekt
Det är korrekt att säga att Shazeer var en nyckelbidragsgivare och medförfattare till Transformer-pappret. Det är däremot felaktigt att framställa honom som ensam uppfinnare. Effekten kommer från den kollektiva designen—och från de många efterföljande förbättringar som gemenskapen byggt ovanpå den ursprungliga skissen.
Vad som kom innan: RNNs, LSTMs och deras begränsningar
Innan Transformers dominerade, löste man sekvensproblem (översättning, tal, textgenerering) främst med Recurrent Neural Networks (RNNs) och senare LSTMs (Long Short-Term Memory-nätverk). Idén var enkel: läs text ett token i taget, håll ett löpande “minne” (en dold tillståndsvektor) och använd det till att förutsäga vad som kommer härnäst.
En snabb bild av hur de fungerade
En RNN bearbetar en mening som en kedja. Varje steg uppdaterar det dolda tillståndet baserat på det aktuella ordet och det tidigare dolda tillståndet. LSTMs förbättrade detta genom att lägga till grindar som avgör vad som ska behållas, glömmas eller användas—vilket gör det lättare att bevara användbara signaler längre.
Varför långdistansberoenden var svåra
I praktiken har sekventiellt minne en flaskhals: mycket information måste pressas genom ett enda tillstånd när meningen blir längre. Även med LSTMs kan signaler från långt tidigare ord blekna eller bli overskrivna.
Det gör vissa relationer svåra att lära pålitligt—som att koppla ett pronomen till rätt substantiv flera ord bakåt eller hålla reda på ett ämne över flera satser.
Tränings- och skalningsutmaningar
RNNs och LSTMs är också långsamma att träna eftersom de inte kan parallellisera över tid fullt ut. Du kan batcha över olika meningar, men inom en mening beror steg 50 på steg 49, som beror på steg 48, och så vidare.
Den stegvisa beräkningen blir en allvarlig begränsning när du vill ha större modeller, mer data och snabbare experiment.
Motivation för en mer parallellvänlig metod
Forskare behövde en design som kunde relatera ord till varandra utan att strikt marschera vänster-till-höger under träning—ett sätt att modellera långdistansrelationer direkt och bättre utnyttja modern hårdvara. Det lade grunden för uppmärksamhets-först-ansatsen i Attention Is All You Need.
Attention, förklarat utan matematik
Attention är modellens sätt att fråga: ”Vilka andra ord bör jag titta på just nu för att förstå det här ordet?” Istället för att läsa en mening strikt vänster-till-höger och hoppas att minnet räcker, låter attention modellen kika på de mest relevanta delarna av meningen när den behöver dem.
Idén "sök och hämta"
En hjälpsam mental modell är en liten sökmotor som körs inuti meningen.
- Query: vad det aktuella ordet letar efter (frågan)
- Keys: vad varje annat ord erbjuder (etiketterna på potentiella matchningar)
- Values: den faktiska informationen som hämtas om det finns en matchning (innehållet)
Modellen formar en query för den aktuella positionen, jämför den med keys för alla positioner och hämtar sedan en blandning av values.
Relevanspoäng → uppmärksamhetsvikter
Dessa jämförelser ger relevanspoäng: grova signaler om “hur relaterat är detta?”. Modellen omvandlar dem till uppmärksamhetsvikter, proportioner som summerar till 1.
Om ett ord är mycket relevant får det en större del av modellens fokus. Om flera ord är viktiga kan uppmärksamheten spridas över dem.
Ett enkelt exempel (pronomen och grammatik)
Ta: “Maria sa till Jenna att hon skulle ringa senare.”
För att tolka hon bör modellen titta tillbaka på kandidater som “Maria” och “Jenna.” Uppmärksamhet tilldelar högre vikt till namnet som bäst passar kontexten.
Eller: “Nycklarna till skåpet är försvunna.” Uppmärksamhet hjälper till att koppla “är” till “nycklarna” (det verkliga subjektet), inte till “skåpet”, även om “skåpet” ligger närmare. Kärnfördelen är att attention länkar betydelse över avstånd, vid behov.
Självuppmärksamhet: kärnmekanismen
Självuppmärksamhet innebär att varje token i en sekvens kan titta på andra token i samma sekvens för att avgöra vad som är viktigt just nu. Istället för att bearbeta ord strikt vänster-till-höger (som äldre rekurrenta modeller gjorde) låter Transformern varje token samla ledtrådar var som helst i indatan.
Token som uppmärksammar token
Föreställ dig meningen: “Jag hällde vattnet i koppen eftersom den var tom.” Ordet “den” bör kopplas till “koppen”, inte “vattnet.” Med självuppmärksamhet tilldelar token för “den” större vikt till token som hjälper till att lösa dess betydelse (“koppen”, “tom”) och mindre vikt till irrelevanta ord.
Hur kontext byggs
Efter självuppmärksamhet är varje token inte längre bara sig själv. Den blir en kontextmedveten version—en viktad blandning av information från andra token. Du kan tänka dig det som att varje token skapar en personlig sammanfattning av hela meningen, anpassad till vad just den token behöver.
I praktiken kan representationen för “kopp” bära signaler från “hällde”, “vatten” och “tom”, medan “tom” kan dra in vad det beskriver.
Varför träning kan parallelliseras
Eftersom varje token kan beräkna sin uppmärksamhet över hela sekvensen samtidigt behöver träningen inte vänta på att tidigare token ska bearbetas steg för steg. Den parallella bearbetningen är en stor anledning till att Transformers tränar effektivt på stora datamängder och skalar till enorma modeller.
Varför det är bra på långdistansrelationer
Självuppmärksamhet gör det enklare att koppla ihop avlägsna delar av text. En token kan direkt fokusera på ett relevant ord långt borta—utan att skicka information genom en lång kedja av mellanliggande steg.
Den direkta vägen hjälper för uppgifter som kärnreferens (”hon”, ”det”, ”de”), hålla reda på ämnen över stycken och hantera instruktioner som beror på tidigare detaljer.
Uppmärksamhet med flera huvuden: flera perspektiv på samma mening
En enda uppmärksamhetsmekanism är kraftfull, men det kan fortfarande kännas som att försöka förstå en konversation med endast en kameravinkel. Meningar innehåller ofta flera relationer samtidigt: vem gjorde vad, vad “det” syftar på, vilka ord som sätter tonen och vad huvudemnet är.
Varför en uppmärksamhetsvy inte räcker
När du läser “Trofén fick inte plats i resväskan eftersom den var för liten” kan du behöva följa flera ledtrådar samtidigt (grammatik, betydelse och verklighetskunskap). Ett huvud kan låsa sig vid närmsta substantiv; ett annat kan använda verbfrasen för att bestämma vad “den” syftar på.
Vad flera huvuden gör
Uppmärksamhet med flera huvuden kör flera uppmärksamhetsberäkningar parallellt. Varje “huvud” uppmuntras att betrakta meningen genom en annan lins—ofta beskrivna som olika delrymder. I praktiken kan huvuden specialisera sig på olika mönster, såsom:
- lokal syntax (t.ex. adjektiv → substantiv)
- långdistanslänkar (t.ex. subjekt ↔ verb över en sats)
- kärnreferens (t.ex. pronomen → entitet)
- tematisk signal (ord som sätter ämne eller sentiment)
Hur huvuden kombineras
Efter att varje huvud producerat sina insikter väljer modellen inte bara ett. Den konkatenerar (staplar sida vid sida) huvudens output och projekterar dem tillbaka till modellens huvudarbetsyta med ett inlärt linjärt lager.
Tänk på det som att slå ihop flera delanteckningar till en ren sammanfattning som nästa lager kan använda. Resultatet är en representation som kan fånga många relationer samtidigt—en av anledningarna till att Transformers fungerar så bra i stor skala.
Positionskodning: lära modellen ordningsföljd
Självuppmärksamhet är utmärkt på att hitta relationer—men ensam vet den inte vem som kom först. Om du blandar orden i en mening kan ett vanligt självuppmärksamhetslager behandla den blandade versionen som lika giltig, eftersom det jämför token utan inbyggd positionskänsla.
Positionskodning löser detta genom att injicera “var är jag i sekvensen?”-information i token-representationerna. När position läggs till kan uppmärksamheten lära sig mönster som “ordet direkt efter inte spelar stor roll” eller “subjekt kommer ofta före verb” utan att behöva härleda ordningen från grunden.
Hur positionskodningar lägger till ordning
Kärn idén är enkel: varje token-embedding kombineras med en positionssignal innan den går in i Transformer-blocket. Positionssignalen kan ses som en uppsättning funktioner som märker en token som 1:a, 2:a, 3:e… i indatan.
Det finns några vanliga ansatser:
- Absoluta (fasta) positioner: Klassiska Transformers använde deterministiska, sinusoida mönster. Dessa lägger inte till nya parametrar och kan generalisera till längder utöver träningen (upp till en gräns).
- Inlärda absoluta positioner: Modellen lär sig en vektor för “position 1”, “position 2” osv. Det fungerar ofta väl, men binder modellen till ett maxkontextfönster den tränats med.
- Relativa positioner: Istället för att koda “det här är token 57” fokuserar modellen på avstånd som “den här token är 3 steg före den där”. Moderna varianter (inklusive rotary-stilar) hamnar ofta i denna familj.
Varför det spelar roll för långkontextuppgifter
Val av positionskodning kan påverka hur väl modellen hanterar långa kontexter—såsom att sammanfatta en lång rapport, hålla koll på entiteter över många stycken eller hitta en detalj som nämndes tusentals token tidigare.
Med långa indata lär sig modellen inte bara språk; den lär sig var den ska titta. Relativa och rotary-stilar gör det ofta lättare att jämföra långt skilda token och bevara mönster när kontexten växer, medan vissa absoluta scheman kan börja falla ihop när de pressas förbi sin träningsgräns.
I praktiken är positionskodning ett lugnt designval som kan avgöra om en LLM känns skarp och konsekvent vid 2 000 token—och fortfarande sammanhängande vid 100 000.
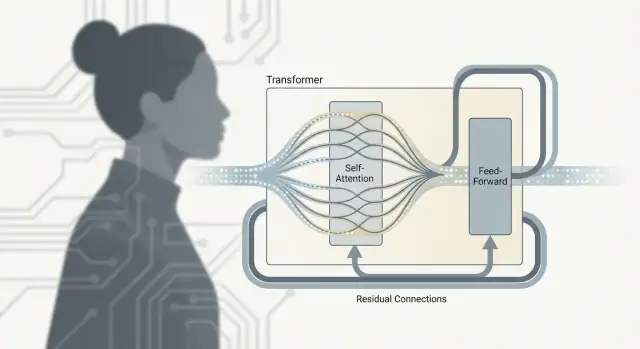
Transformer-blocket: Attention + MLP + stabilisatorer
En Transformer är inte bara “attention.” Det verkliga arbetet sker i en återkommande enhet—ofta kallad ett Transformer-block—som blandar information över token och sedan förfinar den. Stapla många av dessa block så får du det djup som gör stora språkmodeller så kapabla.
Efter attention: vad FFN/MLP gör
Självuppmärksamhet är kommunikationssteget: varje token samlar kontext från andra token.
Feed-forward-nätverket (FFN), även kallat MLP, är tänkarsteget: det tar varje tokens uppdaterade representation och kör samma lilla neurala nätverk oberoende på den.
Enkelt uttryckt omvandlar FFN vad varje token nu vet och hjälper modellen bygga rikare funktioner (som syntaxmönster, fakta eller stilistiska ledtrådar) efter att kontexten samlats in.
Varför block alternerar attention och FFN
Växlingen är viktig eftersom de två delarna gör olika jobb:
- Attention flyttar information mellan token (vem ska påverka vem)
- FFN bearbetar information inom varje token (hur omvandla kontext till användbara funktioner)
Att upprepa detta mönster låter modellen gradvis bygga högre nivåers mening: kommunicera, bearbeta, kommunicera igen, bearbeta igen.
Residuala kopplingar: “filvägarna”
Varje del-lager (attention eller FFN) omsluts av en residual koppling: ingången adderas tillbaka till utgången. Det hjälper djupa modeller att tränas eftersom gradienter kan flöda genom “filvägen” även om ett särskilt lager fortfarande lär sig. Det låter också ett lager göra små justeringar istället för att behöva lära om allt från början.
Lagernormalisering: hålla signalerna stabila
Lagernormalisering är en stabilisator som hindrar aktiveringar från att bli för stora eller för små när de passerar många lager. Tänk på det som att hålla volymnivån jämn så att senare lager inte blir överväldigade eller underförsedda med signal—det gör träningen smidigare och mer pålitlig, särskilt i LLM-skala.
Kodare–avkodare vs endera-avkodare: vad driver LLMs?
Original-Transformern i Attention Is All You Need byggdes för maskinöversättning, där du omvandlar en sekvens (franska) till en annan (engelska). Det arbetet delar naturligt in i två roller: läsa indatan väl och skriva utdata flytande.
Kodare–avkodare: “Läs, sedan skriv”
I en kodare–avkodare Transformer bearbetar kodaren hela indata på en gång och producerar en rik uppsättning representationer. Avkodaren genererar sedan utdata ett token i taget.
Avkodaren använder inte bara sina egna tidigare token. Den använder också cross-attention för att titta tillbaka på kodarens output, vilket hjälper den att hålla sig grundad i källtexten.
Denna uppsättning är fortfarande utmärkt när du måste starkt konditionera på en specifik indata—översättning, sammanfattning eller frågesvar med ett givet stycke.
Endera-avkodare: en modell som bara fortsätter förutse
De flesta moderna stora språkmodeller är endast-avkodare. De tränas för en enkel, kraftfull uppgift: förutsäga nästa token.
För att det ska fungera använder de maskerad självuppmärksamhet (kausal attention). Varje position får bara uppmärksamma tidigare token, inte framtida, så genereringen förblir konsekvent: modellen skriver vänster-till-höger och förlänger kontinuerligt sekvensen.
Detta är dominerande för LLMs eftersom det är lätt att träna på enorma textkorpusar, matchar genereringsanvändningsfallet direkt och skalar effektivt med data och beräkning.
Var encoder-only passar in
Endast-kodare Transformers (som BERT-stilen) genererar inte text; de läser hela indatan bidirektionellt. De är utmärkta för klassificering, sök och embeddings—allt där förståelse av text är viktigare än att producera en lång fortsättning.
Varför Transformers skalar till stora språkmodeller
Transformers visade sig vara ovanligt skalvänliga: om du ger dem mer text, mer beräkning och större modeller tenderar de att bli bättre på ett förutsägbart sätt.
En stor anledning är strukturell enkelhet. En Transformer byggs av upprepade block (självuppmärksamhet + en liten feed-forward-nätverk, plus normalisering), och dessa block beter sig liknande oavsett om du tränar på en miljon ord eller en biljon.
Parallell träning är superkraften
Tidigare sekvensmodeller (som RNNs) var tvungna att bearbeta token ett och ett, vilket begränsar hur mycket arbete du kan göra samtidigt. Transformers kan däremot behandla alla token i en sekvens parallellt under träning.
Det gör dem väl lämpade för GPUs/TPUs och stora distribuerade uppsättningar—exakt vad som krävs när man tränar moderna LLM:er.
“Kontextfönstret” och varför det spelar roll
Kontextfönstret är den text som modellen kan “se” åt gången—din prompt plus eventuell tidigare konversation eller dokumenttext. Ett större fönster låter modellen koppla idéer över fler meningar eller sidor, hålla koll på begränsningar och svara på frågor som beror på tidigare detaljer.
Men kontext är inte gratis.
Den nyckelbegränsningen: attentionkostnaden växer med längden
Självuppmärksamhet jämför token med varandra. När sekvensen blir längre växer antalet jämförelser snabbt (ungefär med kvadraten på sekvenslängden).
Det är därför väldigt långa kontextfönster kan bli dyra i minne och beräkning, och varför många moderna insatser fokuserar på att göra attention mer effektiv.
Skalning låste upp allmänt användbart beteende
När Transformers tränas i stor skala blir de inte bara bättre på en snäv uppgift. De börjar ofta visa breda, flexibla förmågor—sammanfatta, översätta, skriva, koda och resonera—eftersom samma generella inlärningsmaskineri appliceras över massiv, varierad data.
Moderna varianter byggda på samma grund
Originaldesignen är fortfarande referenspunkten, men de flesta produktions-LLM:er är “Transformers plus”: små, praktiska ändringar som behåller kärnblocket (attention + MLP) samtidigt som de förbättrar hastighet, stabilitet eller kontextlängd.
Vanliga förbättringar du kommer att se
Många uppgraderingar handlar mindre om att ändra vad modellen är och mer om att göra den enklare att träna och köra:
- Bättre positionsmetoder: Alternativ till klassiska sinusoida positioner (ofta rotary eller relativa metoder) som kan göra hantering av lång text smidigare.
- Attentionoptimeringar: Implementationer som minskar minnesanvändning och ökar genomströmning (t.ex. fused kernels eller mer effektiva attention-beräkningar).
- Normaliseringsjusteringar: Variationer i var och hur normalisering tillämpas kan förbättra träningsstabilitet och minska känsligheten för hyperparametrar.
Dessa ändringar förändrar sällan den fundamentala “Transformer-naturen”—de förfinar den.
Långkontextmetoder (övergripande)
Att utöka kontext från några tusen token till tiotusentals eller hundratusentals bygger ofta på sparse attention (att endast uppmärksamma valda token) eller effektiva attention-varianter (approximerar eller omstrukturerar attention för att skära ner beräkning).
Avvägningen handlar vanligtvis om noggrannhet, minne och ingenjörskomplexitet.
Mixture-of-Experts (MoE): mer kapacitet utan linjär kostnad
MoE-modeller lägger till flera “expert”-subnätverk och routar varje token genom bara en delmängd. Konceptuellt får du en större hjärna, men du aktiverar inte allt varje gång.
Det kan sänka beräkningen per token för en given parameterstorlek, men ökar systemkomplexiteten (routing, balansering av experter, serving).
Hur man värderar variantpåståenden
När en modell skryter om en ny Transformer-variant, be om:
- Benchmarkresultat som är relevanta för dina uppgifter (inte bara rubrikpoäng)
- Latenstid (time-to-first-token och token/sec)
- Kostnad (träning och inferens), inklusive minne och hårdvarubehov
De flesta förbättringar är verkliga—men de är sällan gratis.
Vad det betyder för team som bygger med LLM:er
Transformer-idéer som självuppmärksamhet och skalning är fascinerande—men produktteam känner dem mest som avvägningar: hur mycket text du kan stoppa in, hur snabbt du får ett svar och vad det kostar per förfrågan.
Att välja modell eller leverantör: fyra avvägningar
Kontextlängd: Längre kontext låter dig inkludera fler dokument, chatt-historik och instruktioner. Det ökar också tokenkostnaden och kan sakta ner svaren. Om din funktion kräver att "läsa" 30 sidor och svara, prioritera kontextlängd.
Latenstid: Användarupplevelser i chatt och copiloter lever och dör på svarstid. Strömmat utdata hjälper, men modellval, region och batchning spelar också roll.
Kostnad: Prissättning är vanligen per token (indata + utdata). En modell som är 10 % “bättre” kan kosta 2–5×. Jämför prissättning mot vad kvalitetsökningen är värd för dig.
Kvalitet: Definiera det för ditt användningsfall: faktuell korrekthet, följsamhet mot instruktioner, ton, verktygsanvändning eller kod. Utvärdera med riktiga exempel från din domän, inte bara generiska benchmarks.
När embeddings slår generation
Om du främst behöver sök, deduplicering, klustring, rekommendationer eller “hitta liknande”, är embeddings (ofta enkoder-stilmodeller) vanligtvis billigare, snabbare och mer stabila än att prompta en chattmodell. Använd generering bara i sista steget (sammanfattningar, förklaringar, utkast) efter retrieval.
För en djupare genomgång, länka ditt team till en teknisk förklaring som /blog/embeddings-vs-generation.
Var detta visar sig i verkliga arbetsflöden
När du förvandlar Transformer-förmågor till en produkt är det hårda jobbet ofta mindre om arkitekturen och mer om arbetsflödet runt den: iteration av prompts, grounding, utvärdering och säker driftsättning.
En praktisk väg är att använda en vibe-coding-plattform som Koder.ai för att prototypa och leverera LLM-drivna funktioner snabbare: du kan beskriva webbappen, backend-endpoints och datamodellen i chatten, iterera i planning-läget och sedan exportera källkod eller driftsätta med hosting, anpassade domäner och rollback via snapshots. Det är särskilt användbart när du experimenterar med retrieval, embeddings eller tool-calls och vill ha snäva iterationscykler utan att bygga om samma stomme varje gång.
En praktisk checklista för adoption
- Skriv en en-sidig specifikation: användarmål, felmoder och vad som är “bra”.
- Bestäm vad som måste grundas i dina data (RAG, citeringar eller tool-calls).
- Sätt budgetar för token, latenstid och månadskostnad; mät dem i staging.
- Lägg till säkerhetsåtgärder: avvisanden, redigering och “jag vet inte”-beteende.
- Bygg utvärdering tidigt: golden prompts, regressionstester och mänsklig granskning.
- Planera för modellbyten: håll prompts och routing konfigurerbara.
Vanliga frågor
Vad är en Transformer på vanlig svenska?
En Transformer är en neuralt nätverksarkitektur för sekvensdata som använder självuppmärksamhet för att relatera varje token till alla andra token i samma indata.
Istället för att föra information steg för steg (som RNNs/LSTMs) bygger den kontext genom att bestämma vad som är värt att uppmärksamma över hela sekvensen, vilket förbättrar förståelsen över långa avstånd och gör träningen mer möjlig att parallellisera.
Varför ersatte Transformers RNNs och LSTMs för många NLP-uppgifter?
RNNs och LSTMs behandlar text en token i taget, vilket gör träningen svårare att parallellisera och skapar en flaskhals för långdistansberoenden.
Transformers använder uppmärksamhet för att koppla ihop avlägsna token direkt, och de kan beräkna många token-till-token-interaktioner parallellt under träning—det gör dem snabbare att skala med mer data och beräkningskraft.
Vad är “attention” och hur bör jag tänka på det?
Uppmärksamhet är en mekanism för att svara: ”Vilka andra token är viktigast för att förstå denna token just nu?”
Du kan tänka på det som en intern sökning i meningen:
- en query frågar vilken information som behövs
- keys representerar vad varje token erbjuder
- values är den information som blandas ihop
Resultatet blir en viktad blandning av relevanta token, vilket ger varje position en kontextmedveten representation.
Vad är skillnaden mellan attention och self-attention?
Självuppmärksamhet betyder att token i en sekvens uppmärksammar andra token i samma sekvens.
Det är verktyget som låter en modell lösa kärnreferens (t.ex. vad ”det” syftar på), subjekt–verb-relationer över satser och beroenden som ligger långt ifrån varandra i texten—utan att föra all information genom ett enda rekurrent “minne.”
Varför använder Transformers multi-head attention?
Multi-head attention kör flera uppmärksamhetsberäkningar parallellt, och varje huvud kan specialisera sig på olika mönster.
I praktiken fokuserar olika huvuden ofta på olika relationer (syntax, långdistanslänkar, pronomen-resolution, tematisk signal). Modellen kombinerar sedan dessa vyer så att den kan representera flera typer av struktur samtidigt.
Om attention ser allt, hur vet modellen ordningsföljden?
Självuppmärksamhet i sig känner inte av ordning—utan positionsinformation kan omkastade ord se likadana ut.
Positionskodningar lägger till positionssignaler till token-representationerna så modellen kan lära sig mönster som “ordet direkt efter inte är viktigt” eller typisk subjekt–verb-ordning.
Vanliga alternativ inkluderar sinusoidala (fasta), inlärda absoluta positioner och relativa/rotary-stilar.
Vad finns i ett Transformer-block förutom attention?
Ett Transformer-block brukar kombinera:
- Attention: flyttar information mellan token
- FFN/MLP: bearbetar information inom varje token
- Residuala kopplingar: hjälper gradienter att flöda och låter lager göra stegvisa justeringar
- Lagernormalisering: stabiliserar aktiveringar för djupa nätverk
Att stapla många block ger den djup som krävs för rikare representationer och starkare beteende i stor skala.
Encoder–decoder vs decoder-only: vilken använder LLMs?
I den ursprungliga Transformer-modellen är det en kodare–avkodare:
- kodaren läser indata bidirektionellt
- avkodaren genererar utdata och använder cross-attention mot kodarens representationer
De flesta moderna LLM:er är dock endast-avkodare och tränas för att förutsäga nästa token med kausal (maskerad) självuppmärksamhet, vilket matchar vänster-till-höger-generering och skalar väl på stora korpusar.
Vad var Noam Shazeers roll i Transformers skapelse?
Noam Shazeer var en medförfattare till 2017-papperet “Attention Is All You Need,” som introducerade Transformern.
Det är korrekt att se honom som en viktig bidragsgivare, men arkitekturen skapades av ett team hos Google och dess genomslag bygger också på många efterföljande förbättringar från forskar- och industrisamhället.
Varför är långa kontextfönster dyra, och vad kan team göra åt det?
För långa indata blir vanlig självuppmärksamhet dyr eftersom antal jämförelser växer ungefär med kvadraten på sekvenslängden, vilket påverkar minne och beräkning.
Praktiska sätt att hantera detta är:
- välja modeller med större inbyggt kontextfönster
- använda RAG (retrieval-augmented generation) istället för att stoppa allt i prompten
- adoptera långkortsvarianter (sparsande/effektiva attention-metoder)
- mäta trade-offs: latenstid, tokenkostnad och uppgiftens noggrannhet på verkliga arbetsflöden