06 maj 2025·8 min
Nyckel-värde-butiker för cache, sessioner och snabba uppslag
Lär dig hur nyckel-värde-butiker driver caching, användarsessioner och snabba uppslag—inklusive TTL, evictions, skalningsalternativ och praktiska trade-offs att tänka på.
Lär dig hur nyckel-värde-butiker driver caching, användarsessioner och snabba uppslag—inklusive TTL, evictions, skalningsalternativ och praktiska trade-offs att tänka på.
Huvudmålet med en nyckel-värde-butik är enkelt: minska latens för slutanvändare och minska belastningen på din primära databas. Istället för att köra samma dyra fråga eller räkna om samma resultat kan din app hämta ett förberäknat värde i ett enda, förutsägbart steg.
En nyckel-värde-butik är optimerad kring en operation: “givet denna nyckel, returnera värdet.” Det smala fokuset möjliggör en mycket kort kritisk väg.
I många system kan ett uppslag ofta hanteras med:
Resultatet är låga och konsekventa svarstider—precis vad du vill ha för caching, sessionslagring och andra snabba uppslag.
Även om din databas är vältrimmad måste den fortfarande parsa frågor, planera dem, läsa index och koordinera samtidighet. Om tusentals förfrågningar frågar efter samma lista över “top produkter” så hopar sig det upprepade arbetet.
En key-value-cache flyttar bort den upprepade lästraffiken från databasen. Din databas kan lägga mer tid på förfrågningar som verkligen kräver den: skrivningar, komplexa joins, rapportering och konsistenskritiska läsningar.
Hastighet är inte gratis. Nyckel-värde-butiker ger ofta upp rika frågemöjligheter (filter, joins) och kan ha andra garantier kring persistens och konsistens beroende på konfiguration.
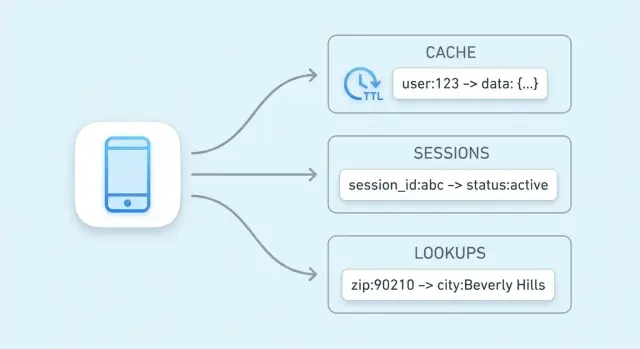
De passar när du kan namnge data med en tydlig nyckel (till exempel user:123, cart:abc) och vill ha snabb hämtning. Om du ofta behöver “hitta alla objekt där X,” är en relations- eller dokumentdatabas vanligtvis en bättre primär lagring.
En nyckel-värde-butik är den enklaste typen av databas: du lagrar ett värde (några data) under en unik nyckel (en etikett), och senare hämtar du värdet genom att ange nyckeln.
Tänk på en nyckel som en identifierare som är lätt att upprepa exakt, och ett värde som det du vill ha tillbaka.
Nycklar är oftast korta strängar (som user:1234 eller session:9f2a...). Värden kan vara små (en räknare) eller större (en JSON-bblob).
Nyckel-värde-butiker byggs för “ge mig värdet för denna nyckel”-frågor. Internt använder många en struktur lik en hash-tabell: nyckeln transformeras till en plats där värdet snabbt kan hittas.
Det är därför du ofta hör om konstant-tids uppslag (ofta skrivet som O(1)): prestandan beror mer på hur många förfrågningar du gör än på hur många poster som finns totalt. Det är ingen magi—kollisioner och minnesgränser spelar fortfarande roll—men för typisk cache/session-användning är det mycket snabbt.
Hot data är den lilla del av information som efterfrågas upprepade gånger (populära produktsidor, aktiva sessioner, räknare för hastighetsbegränsning). Att hålla hot data i en key-value-butik—särskilt i minnet—undviker långsammare databasfrågor och håller svarstider förutsägbara under belastning.
Caching betyder att behålla en kopia av ofta behövda data någonstans som är snabbare att nå än originalkällan. En key-value-butik är en vanlig plats för detta eftersom den kan returnera ett värde i ett enda uppslag per nyckel, ofta på några millisekunder.
Caching är effektiv när samma frågor ställs om och om igen: populära sidor, upprepade sökningar, vanliga API-anrop eller dyra beräkningar. Det är också användbart när den “äkta” källan är långsam eller har begränsningar—som en primär databas under tung belastning eller ett tredjeparts-API du betalar per förfrågan.
Bra kandidater är resultat som läses ofta och inte behöver vara helt i realtid:
En enkel regel: cacha outputs du kan återskapa om det behövs. Undvik att cacha data som förändras konstant eller måste vara konsistent över alla läsningar (t.ex. ett bankkonto-saldo).
Utan caching kan varje sidvisning trigga flera databasfrågor eller API-anrop. Med en cache kan applikationen svara många förfrågningar från key-value-butiken och bara falla tillbaka till primärdatabasen eller API:t vid cache-miss. Det minskar frågevolym, reducerar anslutningskonkurrens och kan förbättra tillförlitligheten vid trafiktoppar.
Caching byter färskhet mot snabbhet. Om cachade värden inte uppdateras snabbt kan användare se föråldrad information. I distribuerade system kan två förfrågningar kortsiktigt läsa olika versioner av samma data.
Du hanterar dessa risker genom att välja lämpliga TTL:er, bestämma vilken data som kan få vara “lite gammal”, och designa din applikation att tolerera cache-missar eller fördröjningar i uppdateringar.
Ett cache-“mönster” är ett återanvändbart arbetsflöde för hur din app läser och skriver data när en cache är inblandad. Att välja rätt mönster beror mindre på verktyget (Redis, Memcached etc.) och mer på hur ofta den underliggande datan ändras och hur mycket föråldrade läsningar du kan tolerera.
Med cache-aside kontrollerar din applikation cachen explicit:
Bäst för: data som läses ofta men ändras sällan (produktsidor, konfiguration, offentliga profiler). Det är också ett bra standardval eftersom fel degraderar graciöst: om cachen är tom kan du fortfarande läsa från databasen.
Read-through betyder att cachelagret hämtar från databasen vid miss (din app läser “från cache”, och cachen vet hur den ska ladda). Operationellt förenklar det applikationskoden, men det lägger komplexitet i cachelagret (du behöver en loader-integration).
Write-through betyder att varje skrivning går till cachen och databasen synkront. Läsningar är vanligtvis snabba och konsistenta, men skrivningar blir långsammare eftersom de måste slutföra två operationer.
Bäst för: data där du vill ha färre cache-missar och enklare läskonsistens (användarinställningar, feature flags), och där skrivlatens är acceptabel.
Med write-back skriver din app först till cachen, och cachen flushar förändringar till databasen senare (ofta i batcher).
Fördelar: mycket snabba skrivningar och minskad belastning på databasen.
Nackdel: om cache-noden fallerar innan flush kan du förlora data. Använd detta endast när du kan tolerera förlust eller har starka hållbarhetsmekanismer.
Om data förändras sällan är cache-aside med en rimlig TTL oftast tillräckligt. Om data förändras ofta och föråldrade läsningar är problematiska, överväg write-through (eller väldigt korta TTL:er plus explicit invalidering). Om skrivvolymen är extrem och tillfällig förlust är acceptabelt kan write-behind vara värt trade-offen.
Att hålla cachad data “tillräckligt färsk” handlar mest om att välja rätt expiration-strategi för varje nyckel. Målet är inte perfekt noggrannhet—det är att undvika att förvåna användare med föråldrade resultat samtidigt som du får prestandafördelarna med caching.
En TTL sätter automatisk utgångstid på en nyckel så att den försvinner efter en tid. Korta TTL:er minskar föråldring men ökar cache-missar och backend-belastning. Längre TTL:er förbättrar träffgrad men riskerar att servera utdaterade värden.
Ett praktiskt sätt att välja TTL:er:
TTL är passivt. När du vet att data har ändrats är det ofta bättre att aktivt invalidera: ta bort den gamla nyckeln eller skriv det nya värdet omedelbart.
Exempel: efter att en användare uppdaterar sin e-post, ta bort user:123:profile eller uppdatera den i cachen direkt. Aktiv invalidering minskar tidsfönstret för föråldring, men kräver att din applikation pålitligt utför dessa cache-uppdateringar.
Istället för att ta bort gamla nycklar inkluderar du en version i nyckelns namn, som product:987:v42. När produkten ändras höjer du versionen och börjar läsa/skriva v43. Gamla versioner får naturligt löpa ut senare. Detta undviker race-conditions där en server tar bort en nyckel samtidigt som en annan skriver den.
En stampede händer när en populär nyckel går ut och många förfrågningar bygger upp den samtidigt.
Vanliga lösningar inkluderar:
Sessiondata är det lilla paket av information din app behöver för att känna igen en återvändande webbläsare eller mobilklient. Minst är det en session-ID (eller token) som pekar på server-side state. Beroende på produkt kan det också innehålla användartillstånd (inloggad-flagga, roller, CSRF-nonce), temporära preferenser och tidskänsliga data som kundvagnsinnehåll eller steg i checkout.
Key-value-butiker är ett naturligt val eftersom sessionläsningar och -skrivningar är enkla: slå upp en token, hämta ett värde, uppdatera det och sätt expiration. De gör det också lätt att applicera TTL:er så att inaktiva sessioner försvinner automatiskt, vilket håller lagringen ren och minskar risken om en token blir stulen.
Ett vanligt flöde:
Använd tydliga, scopade nycklar och håll värdena små:
sess:\u003ctoken\u003e eller sess:v2:\u003ctoken\u003e (versionering hjälper vid framtida ändringar).user_sess:\u003cuserId\u003e -> \u003ctoken\u003e för att tvinga “en aktiv session per användare” eller för att återkalla sessioner per användare.Logout bör ta bort sessionsnyckeln och eventuella relaterade index (som user_sess:\u003cuserId\u003e). För rotation (rekommenderas efter inloggning, privilegieändringar eller periodiskt), skapa en ny token, skriv den nya sessionen och ta sedan bort den gamla nyckeln. Detta minskar tidsfönstret där en stulen token är användbar.
Caching är det vanligaste användningsfallet för en key-value-butik, men det är inte det enda sättet den kan snabba upp ditt system. Många applikationer förlitar sig på snabba läsningar för små, ofta refererade tillstånd—saker som är “nära sanningskällan” och måste kontrolleras snabbt på nästan varje förfrågan.
Auktoriseringskontroller ligger ofta i den kritiska vägen: varje API-anrop kan behöva svara på “får denna användare göra detta?” Att hämta behörigheter från en relationsdatabas vid varje förfrågan kan ge märkbar latens och belastning.
En key-value-butik kan hålla kompakt auktorisationsdata för snabba uppslag, till exempel:
perm:user:123 → en lista/set med permiss-koderentitlement:org:45 → aktiverade planfunktionerDetta är särskilt användbart när din permissionsmodell är lästung och ändras relativt sällan. När behörigheter ändras (rolländringar, planuppgraderingar) kan du uppdatera eller invalidera en liten uppsättning nycklar så att nästa förfrågan återspeglar de nya rättigheterna.
Feature flags är små, ofta lästa värden som måste vara snabbt och konsekvent tillgängliga över många tjänster.
Ett vanligt mönster är att lagra:
flag:new-checkout → true/falseconfig:tax:region:EU → JSON-bblob eller versionerad konfigKey-value-butiker fungerar bra här eftersom läsningar är enkla, förutsägbara och extremt snabba. Du kan också versionera värden (t.ex. config:v27:...) för säkrare utrullningar och snabb rollback.
Rate limiting handlar ofta om räknare per användare, API-nyckel eller IP-adress. Key-value-butiker erbjuder ofta atomiska operationer som låter dig incrementera en räknare säkert även när många förfrågningar kommer samtidigt.
Du kan spåra:
rl:user:123:minute → inkrementera varje förfrågan, gå ut efter 60 sekunderrl:ip:203.0.113.10:second → kortfönster för burstkontrollMed en TTL på varje räknarnyckel återställs begränsningarna automatiskt utan bakgrundsjobb. Detta är en praktisk bas för att skydda inloggningsförsök, skydda dyra endpoints eller upprätthålla planbaserade kvoter.
Betalningar och andra “gör detta exakt en gång”-operationer behöver skydd mot reties—oavsett om det orsakas av timeouts, klienters retry eller meddelandefördelning.
En key-value-butik kan lagra idempotensnycklar:
idem:pay:order_789:clientKey_abc → sparat resultat eller statusVid första förfrågan processar du och sparar utfallet med en TTL. Vid senare retries returnerar du det sparade utfallet istället för att köra operationen igen. TTL förhindrar obegränsad tillväxt samtidigt som den täcker rimliga retry-fönster.
Dessa användningar är inte “caching” i klassisk mening; de handlar om att hålla latens låg för frekventa läsningar och om koordinationsprimtiv som behöver snabbhet och atomäritet.
En “key-value-butik” betyder inte alltid “sträng in, sträng ut”. Många system erbjuder rikare datastrukturer som låter dig modellera vanliga behov direkt i butiken—ofta snabbare och med färre rörliga delar än att lägga allt i applikationskoden.
Hashes (även kallade maps) är idealiska när du har en sak med flera relaterade attribut. Istället för att skapa många nycklar som user:123:name, user:123:plan, user:123:last_seen kan du hålla dem tillsammans under en nyckel som user:123 med fält.
Det minskar nyckelsprawl och låter dig hämta eller ändra bara det fält du behöver—användbart för profiler, feature flags eller små konfigurationsbblobbar.
Sets är bra för “är X i gruppen?”-frågor:
Sorted sets lägger till ordning via en score, vilket passar leaderboards, “top N”-listor och rankning efter tid eller popularitet. Du kan lagra scores som visningsräkningar eller tidsstämplar och snabbt läsa toppobjekten.
Samtidsproblem visar sig ofta i små funktioner: räknare, kvoter, engångsaktioner och rate limits. Om två förfrågningar kommer samtidigt och din app gör “läs → addera 1 → skriv” kan du tappa uppdateringar.
Atomära operationer löser detta genom att utföra förändringen som ett enda odelbart steg i butiken:
Med atomiska inkrement behöver du inga lås eller extra koordinering mellan servrar. Det betyder färre race-conditions, enklare kodvägar och mer förutsägbart beteende under belastning—särskilt för rate limiting och användningsgränser där “nästan korrekt” snabbt blir kundpåverkande problem.
När en key-value-butik börjar hantera seriös trafik betyder “gör det snabbare” oftast “gör det bredare”: sprid läsningar och skrivningar över flera noder samtidigt som systemet förblir förutsägbart vid fel.
Replikering håller flera kopior av samma data.
Sharding delar upp nyckelrymden över noder.
Många distributioner kombinerar båda: shards för genomströmning, repliker per shard för tillgänglighet.
“High availability” betyder vanligtvis att cache/session-lagret fortsätter betjäna förfrågningar även om en nod fallerar.
Med client-side routing beräknar din applikation (eller dess bibliotek) vilken nod som håller en nyckel (vanligt med consistent hashing). Detta kan vara mycket snabbt, men klienter måste uppdateras vid topologiförändringar.
Med server-side routing skickar du förfrågningar till en proxy eller klusterendpoint som vidarebefordrar dem till rätt nod. Det förenklar klienter och utrullningar, men lägger till ett extra hopp.
Planera minne uppifrån:
Key-value-butiker känns “omedelbara” eftersom de håller hot data i minnet och optimerar för snabba läsningar/skrivningar. Den hastigheten har en kostnad: du väljer ofta mellan prestanda, hållbarhet och konsistens. Att förstå trade-offs i förväg förhindrar jobbiga överraskningar senare.
Många key-value-butiker kan köras i olika persistenslägen:
Välj läge som matchar datans syfte: caching tolererar förlust; sessionslagring behöver ofta mer omsorg.
I distribuerade uppsättningar kan du se eventuell konsistens—läsningar kan kortvarigt returnera ett äldre värde efter en skrivning, särskilt under failover eller replikationsfördröjning. Starkare konsistens (t.ex. kräva bekräftelser från flera noder) minskar anomalier men ökar latens och kan minska tillgänglighet vid nätverksproblem.
Caches blir fulla. En eviction-policy bestämmer vad som tas bort: least-recently-used, least-frequently-used, slumpmässigt eller “evict ej” (vilket gör att minnesfull blir skrivfel). Bestäm om du föredrar saknade cacheposter eller fel under tryck.
Anta att driftstörningar händer. Typiska fallback-mekanismer inkluderar:
Att designa dessa beteenden medvetet är vad som gör systemet pålitligt för användare.
Key-value-butiker sitter ofta på appens “hot path”. Det gör dem både känsliga (de kan innehålla sessionstokens eller användaridentifierare) och dyra (de är ofta minnesintensiva). Att få grunderna rätt tidigt förhindrar smärtsamma incidenter senare.
Börja med tydliga nätverksgränser: placera butiken i ett privat subnet/VPC-segment och tillåt endast trafik från de applikationstjänster som verkligen behöver den.
Använd autentisering om produkten stödjer det, och följ least privilege: separata credentials för appar, admin och automation; rotera hemligheter; undvik delade “root”-tokens.
Kryptera data in transit (TLS) när det är möjligt—särskilt om trafiken korsar hosts eller zoner. Kryptering i vila är produkt- och distributionsberoende; om det stödjs, aktivera det för managed-tjänster och verifiera att backups också är krypterade.
En liten uppsättning mätvärden berättar om cachen hjälper eller stjälper:
Sätt alerts för plötsliga förändringar, inte bara absoluta trösklar, och logga nyckeloperationer noggrant (undvik att logga känsliga värden).
De största kostnadsdrivarna är:
Ett praktiskt kostnadsverktyg är att minska värdenas storlek och sätta realistiska TTL:er, så butiken bara håller det som aktivt är användbart.
Börja med att standardisera nyckelnamn så att dina cache- och sessionsnycklar är förutsägbara, sökbara och säkra att operera mot i bulk. En enkel konvention som app:env:feature:id (t.ex. shop:prod:cart:USER123) hjälper undvika kollisioner och gör felsökning snabbare.
Definiera en TTL-strategi innan du släpper. Bestäm vilken data som är säker att låta gå ut snabbt (sekunder/minuter), vad som behöver längre livslängd (timmar) och vad som aldrig bör cacheas. Om du cacher databasrader, synka TTL:er med hur ofta underliggande data ändras.
Skriv ner en invalideringsplan för varje typ av cachad post:
product:v3:123) när du vill ha enkel “invalidera allt”-beteendeVälj några framgångsmått och följ dem från dag ett:
Övervaka också eviction-counts och minnesanvändning för att bekräfta att cachen är korrekt dimensionerad.
För stora värden ökar nätverkstid och minnespress—preferera att cacha mindre, förberäknade fragment. Undvik saknade TTL:er (föråldrad data och minnesläckor) och obegänsad nyckeltillväxt (t.ex. cacha varje sökfråga för evigt). Var försiktig med att cacha användarspecifik data under delade nycklar.
Om du utvärderar alternativ, jämför en lokal in-process-cache mot en distribuerad cache och bestäm var konsistens spelar störst roll. För implementeringsdetaljer och driftvägledning, granska /docs. Om du planerar kapacitet eller behöver prisantaganden, se /pricing.
Om du bygger en ny produkt (eller moderniserar en befintlig) hjälper det ofta att designa caching och sessionslagring som förstklassiga bekymmer från start. På Koder.ai prototypar team ofta en end-to-end-app (React på webben, Go-tjänster med PostgreSQL, och valfritt Flutter för mobil) och itererar sedan på prestandan med mönster som cache-aside, TTL:er och rate-limiting-räknare. Funktioner som planning mode, snapshots och rollback gör det enklare att testa nyckeldesign och invalideringsstrategier säkert, och du kan exportera källkoden när du är redo att köra den i din egen pipeline.
Key-value-butiker optimerar för en operation: givet en nyckel, returnera ett värde. Denna smala fokus gör att man kan använda snabba vägar som in-memory-indexering och hashing, med mindre overhead än allmänna databasmotorer.
De snabbar också upp systemet indirekt genom att avlasta upprepade läsningar (populära sidor, vanliga API-svar) så att din primära databas kan fokusera på skrivningar och komplexa frågor.
En nyckel är en unik identifierare som du kan upprepa exakt (ofta en sträng som user:123 eller sess:\u003ctoken\u003e). Värdet är vad du får tillbaka—allt från en liten räknare till ett JSON-objekt.
Bra nycklar är stabila, scopade och förutsägbara, vilket gör caching, sessioner och uppslag lätta att hantera och felsöka.
Cacha resultat som är ofta lästa och enkla att återskapa vid behov.
Vanliga exempel:
Undvik att cacha data som måste vara helt uppdaterad (t.ex. kontosaldon) om du inte har en stark invalideringsstrategi.
Cache-aside (lat inladdning) är vanligt standardmönster:
key från cachen.Det degraderar graciöst: om cachen är tom eller nere kan du fortfarande läsa från databasen (med lämpliga skydd).
Använd read-through när du vill att cachelagret automatiskt laddar vid missar (förenklar applogik, kräver loader-integration i cachelagret).
Använd write-through när du vill att läsningar ska vara mer konsekvent varma eftersom varje skrivning uppdaterar både cache och databas synkront—men det ger högre skrivlatens.
Välj beroende på om du kan acceptera den operationsmässiga komplexiteten (read-through) eller den extra skrivtiden (write-through).
En TTL (time to live) sätter automatisk utgångstid på en nyckel så att den försvinner efter en viss tid. Korta TTL:er minskar risken för föråldrade värden men ökar antal cache-missar och belastning på backend. Längre TTL:er förbättrar träffgrad men ökar risken för att servera utdaterade värden.
Praktiska tips:
En cache stampede uppstår när en het nyckel går ut och många förfrågningar återskapar den samtidigt.
Vanliga motåtgärder:
Dessa minskar plötsliga belastningstoppar mot databasen eller externa API:er.
Sessioner passar bra eftersom åtkomst är enkel: läs/skriv via token och sätt expiration.
Bra praxis:
sess:\u003ctoken\u003e (versionering som sess:v2:\u003ctoken\u003e hjälper vid migrationer).Många key-value-butiker stödjer atomisk inkrement, vilket gör räknare säkra vid samtidighet.
Ett typiskt mönster:
rl:user:123:minute → inkrementera per förfråganOm räknaren överstiger tröskeln, throttla eller avvisa förfrågan. TTL-baserad expiration återställer begränsningar automatiskt utan bakgrundsjobb.
Viktiga trade-offs att planera för:
Designa för degraderat läge: var beredd att hoppa över cachen, servera något föråldrad data där det är säkert, eller att faila stängt för känsliga operationer.