13 juni 2025·8 min
Palantir vs företagsmjukvara: integration, analys, distribution
Se hur Palantirs syn på dataintegration, operativ analys och distribution skiljer sig från traditionell företagsmjukvara — och vad det innebär för köpare.
Se hur Palantirs syn på dataintegration, operativ analys och distribution skiljer sig från traditionell företagsmjukvara — och vad det innebär för köpare.
Folk använder ofta “Palantir” som ett samlingsbegrepp för några relaterade produkter och ett övergripande sätt att bygga datadrivna operationer. För att hålla jämförelsen tydlig hjälper det att namnge vad som faktiskt diskuteras — och vad som inte gör det.
När någon säger “Palantir” i ett företags-sammanhang menar de vanligtvis en (eller flera) av följande:
Detta inlägg använder ”Palantir-liknande” för att beskriva kombinationen av (1) stark dataintegration, (2) ett semantiskt/ontologiskt lager som samordnar team kring betydelse, och (3) distributionsmönster som kan sträcka sig över cloud, on‑prem och frikopplade miljöer.
”Traditionell företagsmjukvara” är inte en produkt — det är den typiska stack som många organisationer sätter ihop över tid, såsom:
I detta tillvägagångssätt hanteras ofta integration, analys och drift av separata verktyg och team, kopplade via projekt och styrningsprocesser.
Det här är en jämförelse av angreppssätt, inte en leverantörsrekommendation. Många organisationer lyckas med konventionella stackar; andra drar nytta av en mer enhetlig plattformsmodell.
Den praktiska frågan är: vilka kompromisser gör du i snabbhet, kontroll och hur direkt analys kopplas till det dagliga arbetet?
För att hålla resten av artikeln jordad fokuserar vi på tre områden:
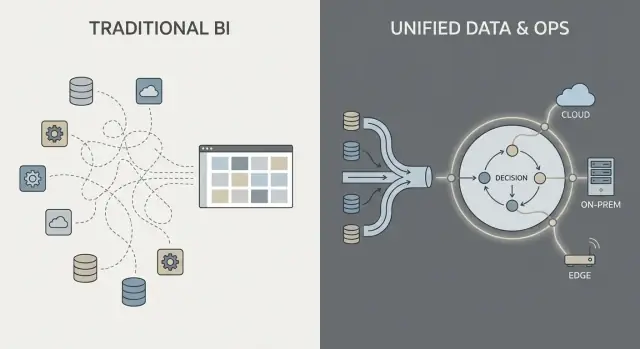
Det mesta dataarbete i en ”traditionell företagsmjukvara”-miljö följer en bekant kedja: hämta data från system (ERP, CRM, loggar), transformera det, ladda in i ett datalager eller lake, och sedan bygga BI-dashboards plus några nedströmsappar.
Det mönstret kan fungera väl, men det förvandlar ofta integration till en serie bräckliga överlämningar: ett team äger extraktionsskript, ett annat äger lagermodeller, ett tredje äger dashboarddefinitioner, och verksamhetsteamen underhåller kalkylblad som tyst ändrar vad som är “det verkliga talet”.
Med ETL/ELT tenderar förändringar att orsaka ringar på vattnet. Ett nytt fält i källsystemet kan bryta en pipeline. En ”quick fix” skapar en andra pipeline. Snart har du duplicerade mått (”intäkter” på tre ställen) och det är oklart vem som är ansvarig när siffrorna inte stämmer.
Batchbearbetning är vanligt här: data landar varje natt, dashboards uppdateras på morgonen. Nära realtid är möjlig, men blir ofta en separat streaming-stack med eget verktyg och egna ägare.
Ett Palantir-liknande angreppssätt syftar till att förena källor och applicera konsekventa semantiker (definitioner, relationer och regler) tidigt, och sedan exponera samma kuraterade data till analys och operativa arbetsflöden.
Enkelt uttryckt: istället för att varje dashboard eller app ska ”lista ut” vad en kund, tillgång, ärende eller försändelse betyder, definieras den betydelsen en gång och återanvänds. Det kan minska duplicerad logik och göra ägarskapet klarare — för när en definition ändras vet du var den lever och vem som godkänner den.
Integration misslyckas oftare på ansvar än på anslutningar:
Nyckelfrågan är inte bara ”Kan vi koppla till system X?” utan ”Vem äger pipelinen, mätvärdesdefinitionerna och affärsbetydelsen över tid?”
Traditionell företagsmjukvara behandlar ofta ”betydelse” som en eftertanke: data lagras i många app-specifika scheman, mätdefinitioner finns i individuella dashboards, och team underhåller tyst sina egna versioner av ”vad är en order” eller ”när är ett ärende löst”. Resultatet är välbekant — olika siffror på olika ställen, långsamma avstämningsmöten och oklart ansvar när något ser fel ut.
I ett Palantir-liknande tillvägagångssätt är det semantiska lagret inte bara en rapporteringsbekvämlighet. En ontologi fungerar som en delad affärsmodell som definierar:
Detta blir ”tyngdpunkten” för analys och drift: flera datakällor kan fortfarande existera, men de kartlägger till ett gemensamt set av affärsobjekt med konsekventa definitioner.
En delad modell minskar felaktiga jämförelser eftersom team inte uppfinner definitioner i varje rapport eller app. Den förbättrar också ansvarstagande: om ”I tid-leverans” definieras mot Försändelse-händelser i ontologin blir det tydligare vem som äger underliggande data och affärslogik.
Görs det väl gör en ontologi inte bara dashboards renare — den gör dagliga beslut snabbare och mindre diskussionskänsliga.
BI-dashboards och traditionell rapportering handlar främst om tillbakablick och övervakning. De svarar på frågor som ”Vad hände förra veckan?” eller ”Är vi i fas med KPI:er?” En försäljningsdashboard, en månadsavstämning eller en executives scorecard är värdefullt — men det slutar ofta vid insyn.
Operativ analys är annorlunda: det är analys inbäddad i dagliga beslut och utförande. Istället för en separat ”analysdestination” dyker analysen upp i arbetsflödet där arbetet utförs och driver ett konkret nästa steg.
BI/rapportering fokuserar typiskt på:
Det är utmärkt för styrning, resultatstyrning och ansvarstagande.
Operativ analys fokuserar på:
Konkreta exempel ser mindre ut som ”en graf” och mer som en arbetskö med kontext:
Den viktigaste skillnaden är att analys knyts till ett specifikt arbetsflödessteg. En BI-dashboard kan visa ”sent leveranser har ökat.” Operativ analys förvandlar det till ”här är de 37 försändelserna i risk idag, sannolika orsaker och rekommenderade insatser,” med möjlighet att genomföra eller tilldela nästa åtgärd direkt.
Traditionell företagsanalys slutar ofta vid en dashboardvy: någon ser ett problem, exporterar till CSV, mejlar en rapport och ett separat team ”gör något” senare. Ett Palantir-liknande angreppssätt är utformat för att korta det gapet genom att bädda in analys direkt i arbetsflödet där beslut fattas.
Arbetsflödescentrerade system genererar vanligtvis rekommendationer (t.ex. ”prioritera dessa 12 försändelser”, ”flagga dessa 3 leverantörer”, ”schemalägg underhåll inom 72 timmar”) men kräver fortfarande uttryckliga godkännanden. Det godkännandesteget är viktigt eftersom det skapar:
Detta är särskilt användbart i reglerade eller höginsatsmiljöer där ”modellen sa så” inte är en acceptabel motivering.
Istället för att behandla analys som en separat destination kan gränssnittet routa insikter in i uppgifter: tilldela en kö, begära godkännande, trigga en notis, öppna ett ärende eller skapa en arbetsorder. Viktigast är att utfallen spåras i samma system — så du kan mäta om åtgärder faktiskt minskade risk, kostnad eller förseningar.
Arbetsflödescentrerad design skiljer vanligtvis upplevelser efter roll:
Gemensam framgångsfaktor är att produkten linjerar mot beslutsrättigheter och operativa procedurer: vem får agera, vilka godkännanden krävs och vad ”klart” betyder operativt.
Styrning är där många analysprogram antingen lyckas eller stannar av. Det är inte bara ”säkerhetsinställningar” — det är den praktiska uppsättningen regler och bevis som låter människor lita på siffrorna, dela dem säkert och använda dem för att fatta verkliga beslut.
De flesta företag behöver samma kärnkontroller, oavsett leverantör:
Detta är inte byråkrati i sig. Det är hur du förhindrar problemet med ”två versioner av sanningen” och minskar risk när analys flyttas närmare drift.
Traditionella BI-implementationer sätter ofta säkerheten främst på rapportlagret: användare kan se vissa dashboards och administratörer hanterar behörigheter där. Det kan fungera när analys mest är beskrivande.
Ett Palantir-liknande angreppssätt skjuter säkerhet och styrning genom hela pipelinen: från rådataingest, till det semantiska lagret (objekt, relationer, definitioner), till modeller och till och med till de åtgärder som triggas av insikter. Målet är att ett operativt beslut (som att dispatcha en crew, släppa lager eller prioritera ärenden) ärver samma kontroller som datan bakom det.
Två principer spelar roll för säkerhet och ansvarstagande:
Till exempel kan en analytiker föreslå en mätdefinition, en data steward godkänna den och drift använda den — med ett tydligt revisionsspår.
Bra styrning är inte bara för compliance-team. När verksamhetsanvändare kan klicka in i lineage, se definitioner och lita på konsekventa behörigheter slutar de gräla om kalkylblad och börjar agera på insikten. Det förtroendet är vad som gör analys till operativ handling istället för ”intressanta rapporter”.
Var företagsmjukvara körs är inte längre en IT-detalj — det formar vad du kan göra med data, hur snabbt du kan förändra och vilka risker du kan acceptera. Köpare brukar utvärdera fyra distributionsmönster.
Public cloud (AWS/Azure/GCP) optimerar för snabbhet: provisionering är snabb, managed-tjänster minskar infraarbete och skalning är enkel. De viktigaste frågorna för köpare är dataresidens (vilken region, vilka backups, vilken supportåtkomst), integration till on‑prem-system och om din säkerhetsmodell tolererar molnanslutning.
En private cloud (single-tenant eller kundhanterad Kubernetes/VMs) väljs ofta när du vill ha cloud-lik automation men striktare kontroll över nätverksgränser och revisionskrav. Det kan minska viss compliance-friktion, men du behöver fortfarande disciplin kring patchning, övervakning och åtkomstgranskningar.
On-prem-distributioner är fortfarande vanliga i tillverkning, energi och starkt reglerade sektorer där kärnsystem och data inte kan lämna anläggningen. Nackdelen är operativt överhuvud: maskinvarulivscykel, kapacitetsplanering och mer arbete för att hålla miljöer konsekventa över dev/test/prod. Om din organisation har svårt att drifta plattformar pålitligt kan on‑prem sänka time-to-value.
Frikopplade (air-gapped) miljöer är ett specialfall: försvar, kritisk infrastruktur eller platser med begränsad anslutning. Här måste distributionsmodellen stödja strikta uppdateringskontroller — signerade artefakter, kontrollerad promotion av releaser och repeterbar installation i isolerade nätverk.
Nätverksbegränsningar påverkar också datarörelse: istället för kontinuerlig synk kan du förlita dig på staged transfers och export/import-arbetsflöden.
I praktiken är det en triangel: flexibilitet (cloud), kontroll (on-prem/air-gapped) och förändringstakt (automation + uppdateringar). Rätt val beror på residensregler, nätverksrealiteter och hur mycket plattformsdrift ditt team är villigt att ta på sig.
”Apollo-lik distribution” är i grunden kontinuerlig leverans för höginsatsmiljöer: du kan skicka förbättringar ofta (veckovis, dagligen, till och med flera gånger per dag) samtidigt som driften hålls stabil.
Målet är inte ”gå snabbt och bryt saker”. Det är ”rör dig ofta och bryt ingenting”.
I stället för att slå ihop förändringar till en stor kvartalsrelease levererar team små, reversibla uppdateringar. Varje uppdatering är lättare att testa, förklara och rulla tillbaka om något går fel.
För operativ analys spelar det roll eftersom din ”mjukvara” inte bara är ett UI — det är datapipelines, affärslogik och de arbetsflöden människor förlitar sig på. En säkrare uppdateringsprocess blir en del av det dagliga arbetet.
Traditionella uppgraderingar liknar ofta projekt: långa planeringsfönster, koordinering för driftstopp, kompatibilitetsoro, omskolning och ett hårt övergångsdatum. Även när leverantörer erbjuder patchar skjuter många organisationer upp uppdateringar eftersom risk och insats är oförutsägbara.
Apollo-liknande verktyg vill göra uppgraderingar rutinmässiga snarare än exceptionella — mer som att underhålla infrastruktur än att genomföra en större migration.
Moderna distributionsverktyg låter team utveckla och testa i isolerade miljöer, och sedan ”promota” samma build genom steg (dev → test → staging → production) med konsekventa kontroller. Den separeringen minskar sista-minuten-överraskningar orsakade av skillnader mellan miljöer.
Time-to-value handlar mindre om hur snabbt du kan ”installera” något och mer om hur snabbt team kan bli överens om definitioner, koppla rörig data och göra insikter till dagliga beslut.
Traditionell företagsmjukvara betonar ofta konfigurering: du adopterar en fördefinierad datamodell och arbetsflöden, och mappar din verksamhet in i dem.
Palantir-liknande plattformar brukar blanda tre lägen:
Löftet är flexibilitet — men det betyder också att du behöver klarhet i vad du bygger kontra vad du standardiserar.
Ett praktiskt alternativ under tidig discovery är att prototypa arbetsflödesappar snabbt — innan du förbinder dig till en stor plattformsutrullning. Till exempel använder team ibland Koder.ai (en vibe-coding-plattform) för att omvandla en arbetsflödesbeskrivning till en fungerande webbapp via chatt, och sedan iterera med intressenter med hjälp av planning mode, snapshots och rollback. Eftersom Koder.ai stödjer export av källkod och typiska produktionsstackar (React på webben; Go + PostgreSQL i backend; Flutter för mobil) kan det vara ett lågtröskel-sätt att validera "insikt → uppgift → revisionsspår" UX och integrationskrav under ett proof-of-value.
Det mesta arbetet går vanligtvis till fyra områden:
Se upp för oklart ägarskap (ingen ansvarig data/produktägare), för många bespoke-definitioner (varje team uppfinner egna mått), och ingen väg från pilot till skala (en demo som inte kan operationaliseras, supportas eller styras).
En bra pilot är avsiktligt smal: välj ett arbetsflöde, definiera specifika användare, och åtag er ett mätbart utfall (t.ex. minska ledtid med 15 %, halvera undantagskö med 30 %). Designa piloten så att samma data, semantik och kontroller kan utsträckas till nästa use case — istället för att börja om.
Kostnadsdiskussioner blir förvirrande eftersom en ”plattform” paketerar kapaciteter som ofta köps som separata verktyg. Nyckeln är att koppla prissättning till de utfall du behöver (integration + modellering + styrning + operativa appar), inte bara till en radpost som heter ”mjukvara”.
De flesta plattformsavtal formas av ett fåtal variabler:
En punktlösningsstrategi kan verka billigare initialt, men totalkostnaden sprids ofta över:
Plattformar minskar ofta verktygsspridning, men du byter det mot ett större, mer strategiskt kontrakt.
Med en plattform bör upphandling behandla den som delad infrastruktur: definiera enterprise-scope, datadomäner, säkerhetskrav och leveransmilstolpar. Be om tydlig separation mellan licens, cloud/infrastruktur och tjänster, så att du kan jämföra äpplen med äpplen.
Om du vill ha ett snabbt sätt att strukturera antaganden, se prissättning.
Palantir-liknande plattformar har ofta fördel när problemet är operativt (människor behöver fatta beslut och agera över system), inte bara analytiskt (folk behöver en rapport). Kompromissen är att du adopterar en mer ”plattform”-stil — kraftfullt, men det kräver mer av din organisation än en enkel BI-utrullning.
Ett Palantir-liknande angreppssätt passar ofta när arbetet spänner över flera system och team och du inte har råd med bräckliga överlämningar.
Vanliga exempel inkluderar tvärsystemoperationer som försörjningskedjekoordination, bedrägeri- och riskoperationer, uppdragsplanering, ärendehantering eller fordons- och underhållsflöden — där samma data måste tolkas konsekvent av olika roller.
Det passar också väl när behörigheter är komplexa (rad-/kolumnnivååtkomst, multi-tenant data, need-to-know-regler) och när du behöver ett tydligt revisionsspår över hur data användes.
Slutligen är det lämpligt i reglerade eller begränsade miljöer: on‑prem-krav, air‑gapped/disconnected distribution eller strikt säkerhetsackreditering där distributionsmodell är en första klassens krav.
Om målet mestadels är enkel rapportering — veckovisa KPI:er, några dashboards, grundläggande finansiella konsolideringar — kan traditionell BI ovanpå ett välskött datalager vara snabbare och billigare.
Det kan också bli överdrivet för små dataset, stabila scheman eller avdelningsanalys där ett team kontrollerar källor och definitioner och huvudåtgärden sker utanför verktyget.
Ställ tre praktiska frågor:
De bästa resultaten kommer från att behandla detta som ”passande efter problem”, inte ”ett verktyg ersätter allt”. Många organisationer behåller befintlig BI för bred rapportering samtidigt som de använder ett Palantir-liknande angreppssätt för högst prioriterade operativa domäner.
Att köpa en ”Palantir-liknande” plattform kontra traditionell företagsmjukvara handlar mindre om funktionskryssrutor och mer om var det verkliga arbetet kommer landa: integration, delad betydelse (semantik) och dagligt operativt bruk. Använd checklistan nedan för att tvinga fram klarhet tidigt, innan du låser in dig i en lång implementation eller ett snävt punktverktyg.
Be varje leverantör vara specifik om vem gör vad, hur det hålls konsekvent, och hur det används i verklig drift.
Inkludera intressenter som ska leva med kompromisserna:
Kör ett tidsbegränsat proof-of-value centrerat på ett högprioriterat operativt arbetsflöde (inte en generisk dashboard). Definiera succékriterier i förväg: tid-till-beslut, felminskning, reviderbarhet och ägande av löpande dataarbete.
Om du vill ha mer vägledning om utvärderingsmönster, se blogg. För hjälp att scopa ett proof-of-value eller kortlista leverantörer, kontakta oss.
I det här inlägget är ”Palantir” en förenklad beskrivning av ett plattformsliknande angreppssätt som oftast förknippas med Foundry (kommersiell data-/operationsplattform), Gotham (offentlig sektor/försvarsursprung) och Apollo (distribution/leverans över miljöer).
”Traditionell företagsmjukvara” syftar på den vanligare sammansatta stacken: ERP/CRM + datalager/sjö + BI + ETL/ELT/iPaaS och integrationsmiddleware, ofta ägd av separata team och kopplad via projekt och styrningsprocesser.
Ett semantiskt lager är där du definierar affärsbetydelsen en gång (t.ex. vad ”Order”, ”Kund” eller ”I tid-leverans” betyder) och sedan återanvänder dessa definitioner över analys och arbetsflöden.
En ontologi går längre genom att modellera:
Traditionell ETL/ELT blir ofta en stafett: extrahering från källor → transformationer → datalagermodeller → dashboards, med olika ägare i varje steg.
Vanliga fel är:
Ett Palantir-likt mönster försöker standardisera betydelsen tidigare och återanvända de kuraterade objekten överallt, vilket minskar duplicerad logik och gör förändringskontroll tydligare.
BI-dashboards handlar mest om observera och förklara: övervaka KPI:er, schemalagda uppdateringar och retrospektiv analys.
Operativ analys är besluta och göra:
Om resultatet är ”en graf” är det oftast BI. Om resultatet är ”här är vad du ska göra härnäst, och gör det här” är det operativ analys.
Ett arbetsflödescentrerat system förkortar avståndet mellan insikt och genomförande genom att bädda in analys där arbetet faktiskt utförs.
I praktiken ersätter det ”exportera till CSV och mejla” med:
Målet är inte snyggare rapporter — utan snabbare, reviderbara beslut.
”Human-in-the-loop” betyder att systemet kan rekommendera åtgärder, men människor explicit godkänner eller åsidosätter dem.
Detta skapar:
Det är särskilt viktigt i reglerade eller höginsatsmiljöer där blind automatisering är oacceptabelt.
Styrning är mer än inloggningar; det är de operationella reglerna och bevisen som gör data säkra och pålitliga.
Minimalt bör inkludera:
När styrningen är stark spenderar team mindre tid på att försona siffror och mer tid på att agera utifrån dem.
Valet av distribution begränsar snabbhet, kontroll och driftskostnad:
Apollo-lik leverans är kontinuerlig leverans anpassad för begränsade, höginsatsmiljöer: frekventa, små, reversibla uppdateringar med starka kontroller.
Jämfört med traditionella uppgraderingsprojekt betonar det:
Det är viktigt eftersom operativ analys är beroende av pålitliga pipelines och affärslogik, inte bara rapporter.
En skalbar proof-of-value är smal och operativ.
Praktisk struktur:
Den praktiska nyttan är färre konflikter i definitioner mellan dashboards, appar och team — och tydligare ansvar när definitioner ändras.
Välj efter krav på datalokalitet, nätverksrealiteter och hur mycket plattformsdrift du kan stödja.
Undvik ”generiska dashboards” som pilotmål om verklig avsikt är operativ påverkan.