Pålitliga webhook-integrationer: signering, idempotens och felsökning
Lär dig pålitliga webhook-integrationer med signering, idempotency-nycklar, skydd mot replay-attacker och ett snabbt felsökningsflöde för kundrapporter.
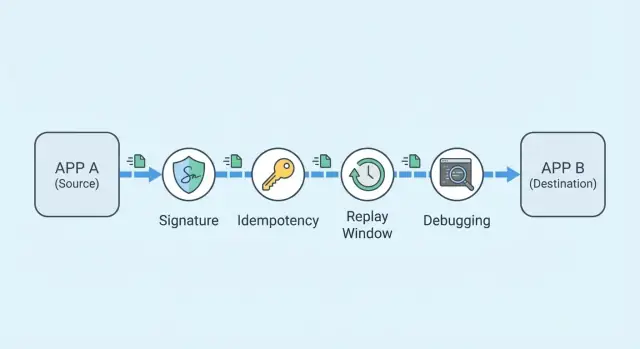
Varför webhooks misslyckas i verkligheten
När någon säger “webhooks är trasiga” menar de oftast en av tre saker: events anlände aldrig, events anlände två gånger, eller events anlände i en förvirrande ordning. Ur deras synvinkel "missade" systemet något. Ur din synvinkel skickade leverantören det, men din endpoint accepterade det inte, bearbetade det inte, eller registrerade det inte på det sätt du förväntade dig.
Webhooks lever på det publika internet. Förfrågningar försenas, försöks igen och ibland levereras i fel ordning. De flesta leverantörer försöker om aggressivt när de ser timeouts eller icke-2xx-responser. Det förvandlar en liten störning (databas som är långsam, en deploy, ett kort avbrott) till dubbletter och race-conditions.
Dåliga loggar gör att det känns slumpmässigt. Om du inte kan bevisa om en förfrågan var autentisk kan du inte agera säkert på den. Om du inte kan knyta en kunds klagomål till ett specifikt leveransförsök, hamnar du i gissningsspel.
De flesta verkliga fel faller i några kategorier:
- “Saknade” events (du timed out, returnerade ett fel, eller misslyckades efter att ha bekräftat)
- Dubbletter (retries plus en handler som inte är idempotent)
- Fel ordning (du antog att leveransordning = event-ordning)
- Mystiska förfrågningar (ingen signaturverifiering, så du kan inte skilja verkligt från falskt)
Det praktiska målet är enkelt: acceptera verkliga events en gång, avvisa falska, och lämna en tydlig spårbarhet så att du kan felsöka en kundrapport på minuter.
Hur webhooks faktiskt beter sig
En webhook är bara en HTTP-begäran som en leverantör skickar till en endpoint du exponerar. Du hämtar den inte som ett API-anrop. Avsändaren pushar när något händer, och din uppgift är att ta emot den, svara snabbt och bearbeta den säkert.
En typisk leverans inkluderar en begäranstext (ofta JSON) plus headers som hjälper dig att validera och spåra vad du mottog. Många leverantörer inkluderar en tidsstämpel, en event-typ (som invoice.paid) och ett unikt event-ID som du kan lagra för att upptäcka dubbletter.
Det som överraskar team: leverans är nästan aldrig "exakt en gång." De flesta leverantörer strävar efter "at least once", vilket betyder att samma event kan anlända flera gånger, ibland minuter eller timmar isär.
Retries händer av tråkiga skäl: din server är långsam eller time-outar, du returnerar en 500, deras nätverk ser inte din 200, eller din endpoint är kort otillgänglig under deploys eller trafiktoppar.
En timeout är särskilt knepig. Din server kan ha mottagit förfrågan och till och med slutfört bearbetningen, men svaret når inte avsändaren i tid. Ur leverantörens synvinkel misslyckades det, så de försöker igen. Utan skydd bearbetar du samma event två gånger.
En bra mental modell är att behandla HTTP-begäran som ett "leveransförsök", inte "eventet". Eventet identifieras av sitt ID. Din bearbetning ska baseras på det ID:t, inte på hur många gånger leverantören anropar dig.
Webhook-signering i enkla termer
Webhook-signering är hur avsändaren bevisar att en begäran verkligen kom från dem och inte ändrades på vägen. Utan signering kan vem som helst som gissar din webhook-URL posta falska "betalning lyckades" eller "användare uppgraderad"-events. Ännu värre, ett riktigt event kan ändras i transit (belopp, kund-ID, event-typ) och fortfarande se legitimt ut för din app.
Det vanligaste mönstret är HMAC med en delad hemlighet. Båda sidor känner till samma hemlighet. Avsändaren tar den exakta webhook-payloaden (vanligtvis den råa begäranstexten), beräknar en HMAC med den hemligheten och skickar signaturen tillsammans med payloaden. Din uppgift är att räkna om HMAC över samma bytes och kontrollera att signaturerna matchar.
Signaturdata placeras vanligtvis i en HTTP-header. Vissa leverantörer inkluderar också en tidsstämpel där så att du kan lägga till replay-skydd. Mindre vanligt är att signaturen bäddas in i JSON-kroppen, vilket är riskablare eftersom parsers eller återserialisering kan ändra formatering och bryta verifieringen.
När du jämför signaturer, använd inte en vanlig strängjämförelse. Enkel jämförelse kan läcka timing-skillnader som hjälper en angripare gissa rätt signatur över många försök. Använd en constant-time-sammanlikningsfunktion från ditt språk eller crypto-bibliotek och avvisa vid minsta mismatch.
Om en kund rapporterar "er system accepterade ett event vi aldrig skickade", börja med signaturkontroller. Om signaturverifieringen misslyckas har du sannolikt en hemlighets-mismatch eller så hashar du fel bytes (t.ex. parsad JSON istället för rå kropp). Om den passerar kan du lita på avsändaridentiteten och gå vidare till deduplikation, ordning och retries.
Steg för steg: verifiera en webhook-signatur
Pålitlig webhook-hantering börjar med en tråkig regel: verifiera vad du mottog, inte vad du önskar att du mottagit.
Det säkra sättet att verifiera
Fånga den råa begäranstexten exakt som den anlände. Pars inte och återserialisera JSON innan du kontrollerar signaturen. Små skillnader (whitespace, nyckelordning, unicode) ändrar bytes och kan få giltiga signaturer att se ogiltiga ut.
Bygg sedan den exakta payload som din leverantör förväntar sig att du signerar. Många system signerar en sträng som timestamp + "." + raw_body. Tidsstämpeln är inte dekoration. Den finns där så att du kan avvisa gamla förfrågningar.
Beräkna HMAC med den delade hemligheten och rätt hash (ofta SHA-256). Förvara hemligheten i en säker lagring och behandla den som ett lösenord.
Slutligen, jämför ditt beräknade värde med signaturheadern med en constant-time-jämförelse. Om det inte matchar, returnera en 4xx och stoppa. Acceptera inte ändå.
En snabb implementerings-checklista:
- Läs kroppen som bytes en gång, lagra den och använd samma bytes för verifiering.
- Återskapa den signerade strängen exakt, inklusive separatorer och tidsstämpelsformat.
- Beräkna HMAC med rätt hemlighet och algoritm.
- Jämför signaturvärden säkert och avvisa mismatch.
- Logga varför verifieringen misslyckades (saknad header, dålig tidsstämpel, mismatch) utan att logga hemligheten eller full signatur.
Ett snabbt exempel
En kund rapporterar "webhooks slutade fungera" efter att ni lade till JSON-parsnings-middleware. Du ser signaturmismatch, mest på större payloads. Fästen är oftast att verifiera med rå kropp innan någon parsing och logga vilken steg som misslyckades (t.ex. "signaturheader saknas" vs "tidsstämpel utanför tillåtet fönster"). Den ena detaljen kan skära ner felsökningstiden från timmar till minuter.
Idempotency-nycklar: acceptera en gång, säkert
Leverantörer försöker om eftersom leverans inte är garanterad. Din server kan vara nere en minut, en nätverkslänk kan tappa förfrågan, eller din handler kan time-outa. Leverantören antar "kanske gick det igenom" och skickar samma event igen.
En idempotency-nyckel är kvittot du använder för att känna igen ett event du redan behandlat. Det är inte ett säkerhetsverktyg och ersätter inte signaturverifiering. Det löser inte heller race-conditions om du inte lagrar och kontrollerar det säkert under samtidig åtkomst.
Valet av nyckel beror på vad leverantören ger dig. Föredra ett värde som förblir stabilt över retries:
- Event ID (bäst när ett event motsvarar en affärsförändring)
- Delivery ID eller message ID (bäst när retries behåller samma leveransidentifierare)
- En hash av stabila fält (sista utväg om inget ID finns)
När du tar emot en webhook, skriv nyckeln till lagring först med en unikhetssregel så att bara en förfrågan "vinner". Sedan bearbetar du eventet. Om du ser samma nyckel igen, returnera framgång utan att göra jobbet igen.
Håll ditt sparade "kvitto" litet men användbart: nyckeln, behandlingsstatus (mottaget/behandlat/failed), tidsstämplar (först sedd/sist sedd) och en minimal sammanfattning (event-typ och relaterat objekt-ID). Många team behåller nycklar i 7–30 dagar så sena retries och de flesta kundrapporter täcks.
Replay-skydd utan att blockera riktig trafik
Replay-skydd stoppar ett enkelt men elakt problem: någon fångar en riktig webhook-förfrågan (med giltig signatur) och skickar den igen senare. Om din handler behandlar varje leverans som ny kan den replayn trigga duplicerade återbetalningar, duplicerade inbjudningar eller upprepade statusändringar.
Ett vanligt tillvägagångssätt är att signera inte bara payloaden utan också en tidsstämpel. Din webhook inkluderar headers som X-Signature och X-Timestamp. Vid mottag, verifiera signaturen och kontrollera även att tidsstämpeln är färsk inom ett kort fönster.
Clock drift är vad som oftast orsakar falska avslag. Dina servrar och avsändarens servrar kan skilja sig en minut eller två, och nätverk kan fördröja leverans. Håll en buffert och logga varför du avvisade en förfrågan.
Praktiska regler som fungerar bra:
- Acceptera bara om
abs(now - timestamp) <= window(till exempel 5 minuter plus en liten grace). - Lita på idempotency som det verkliga säkerhetsnätet. Även inom fönstret ska retries inte dubblera effekter.
- Om du avvisar på grund av tid, returnera en tydlig 4xx och logga den mottagna tidsstämpeln och din server-tid.
Om tidsstämplar saknas kan du inte göra verkligt replay-skydd baserat på tid ensam. I så fall, lita mer på idempotency (lagra och avvisa dubbletter av event-ID) och överväg att kräva tidsstämplar i nästa webhook-version.
Hantering av hemlighetsrotation spelar också roll. Om du roterar signeringshemligheter, behåll flera aktiva hemligheter under en kort överlappningsperiod. Verifiera mot den nyaste hemligheten först, och fall tillbaka till äldre. Detta undviker kundproblem under utrullning. Om ditt team snabbt deployerar endpoints (t.ex. genererar kod med Koder.ai och använder snapshots och rollback under deploys) hjälper det här överlappningsfönstret eftersom äldre versioner kan vara live en kort stund.
Designa handlern så retries inte skadar dig
Retries är normala. Anta att varje leverans kan vara duplicerad, försenad eller i fel ordning. Din handler bör bete sig likadant oavsett om den ser ett event en eller fem gånger.
Håll request-path kort. Gör bara det som krävs för att acceptera eventet, flytta sedan tyngre arbete till ett bakgrundsjobb.
Ett enkelt mönster som håller i produktion:
- Validera grundläggande (metod, content-type, nödvändiga headers).
- Verifiera äkthet (signatur) och avvisa allt som misslyckas.
- Parsa och validera payloaden.
- Dedupe med hjälp av event ID (eller idempotency-nyckel) i en tabell med unik constraint.
- Skicka arbete till kö med event ID, och svara.
Returnera 2xx endast efter att du verifierat signaturen och registrerat eventet (eller köat det). Om du svarar 200 innan du sparat något kan du förlora events vid en krasch. Om du gör tungt arbete innan du svarar triggas timeouts och du kan upprepa sidoeffekter.
Långsamma downstream-system är huvudorsaken till att retries blir smärtsamma. Om din e-postleverantör, CRM eller databas är långsam, låt en kö absorbera förseningen. Worker kan försöka igen med backoff, och du kan larma på fastnade jobb utan att blockera avsändaren.
Events utanför ordning händer också. Till exempel kan en subscription.updated anlända före subscription.created. Bygg tolerans genom att kontrollera nuvarande tillstånd innan du applicerar ändringar, tillåta upserts och betrakta "ej hittad" som en anledning att försöka igen senare (när det är rimligt) i stället för ett permanent fel.
Vanliga misstag som orsakar svårspårade buggar
Många "slumpmässiga" webhook-problem är självförvållade. De ser ut som fladdrande nätverk, men upprepar sig i mönster, oftast efter en deploy, hemlighetsrotation eller en liten ändring i parsning.
Det vanligaste signaturfelet är att hasha fel bytes. Om du parsar JSON först kan din server omformatera det (whitespace, nyckelordning, talformat). Då verifierar du signaturen mot en annan kropp än den avsändaren signerade, och verifieringen misslyckas även om payloaden är äkta. Verifiera alltid mot de råa request-body-bytesen exakt som mottagna.
Nästa stora källa till förvirring är hemligheter. Team testar i staging men verifierar av misstag med produktionshemligheten, eller behåller en gammal hemlighet efter rotation. När en kund rapporterar fel "endast i en miljö", anta fel konfiguration eller fel hemlighet först.
Några misstag som leder till långa utredningar:
- Logga full kropp för felsökning och läcka tokens, e-post eller betalningsdetaljer i loggar.
- Returnera 500 samtidigt som du utför sidoeffekter (skickar e-post, uppdaterar order). Retries upprepar sidoeffekterna.
- Använda en idempotency-nyckel som inte är verkligt unik (t.ex. event-typ + minut). Riktiga events droppas som "dubbletter".
- Behandla en 2xx-svar som "behandlat", när din kod bara köade arbetet som senare misslyckades.
Exempel: en kund säger "order.paid anlände aldrig." Du ser signaturfel som började efter en refaktor som bytte request-parsing-middleware. Middleware läser och re-kodar JSON, så din signaturkontroll använder nu en modifierad kropp. Fixen är enkel, men bara om du vet vad du ska leta efter.
Felsök kundrapporter snabbt
När en kund säger "er webhook gick inte iväg", behandla det som ett trace-problem, inte ett gissningsproblem. Fokusera på ett exakt leveransförsök från leverantören och följ det genom systemet.
Börja med att få leverantörens leveransidentifierare, request ID eller event ID för det misslyckade försöket. Med det värdet bör du snabbt hitta motsvarande loggpost.
Kolla sedan tre saker i ordning:
- Gick signaturverifieringen igenom?
- Klarade tidsstämpel eller replay-fönstret kontrollen (om ni använder det)?
- Behandlade idempotency det som nytt eller som en dubblett?
Bekräfta sedan vad ni returnerade till leverantören. En långsam 200 kan vara lika illa som en 500 om leverantören time-outar och försöker igen. Titta på statuskod, svarstid och om er handler bekräftade innan ni gjorde tungt arbete.
Om ni behöver reproducera, gör det säkert: spara ett redigerat rått request-exempel (viktiga headers plus rå kropp) och spela upp det i en testmiljö med samma hemlighet och verifieringskod.
Snabb checklista du kan köra på 10 minuter
När en webhook-integration börjar misslyckas "slumpmässigt" är snabbhet viktigare än perfektion. Detta runbook fångar de vanliga orsakerna.
Hämta ett konkret exempel först: leverantörens namn, event-typ, ungefärlig tidsstämpel (med tidszon) och något event ID kunden kan se.
Verifiera sedan:
- Signaturverifiering använder råa request-body-bytes (före JSON-parsning) och korrekt hemlighet för den miljön.
- Replay-kontroller är rimliga för verkligt retry-beteende (och din server-klocka är sann).
- Idempotency verkligen deduplikerar (unik constraint, skriven före bearbetning, rimlig retention).
- Din handler bekräftar bara efter validering och hållbar registrering/köning.
- Loggar innehåller ett minimalt, sökbart kvitto: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Om leverantören säger "vi försökte 20 gånger", kontrollera vanliga mönster först: fel hemlighet (signatur misslyckas), klockdrift (replay-fönster), payload-storleksgränser (413), timeouts (inget svar) och kraftiga 5xx från downstream-dependencies.
Exempel: spåra en "saknat event"-rapport från början till slut
En kund mailar: "Vi saknade ett invoice.paid-event igår. Vårt system uppdaterade aldrig." Här är ett snabbt sätt att spåra det.
Först, bekräfta om leverantören försökte leverans. Hämta event ID, tidsstämpel, destinations-URL och exakt svarskod din endpoint returnerade. Om det fanns retries, notera första felorsaken och om en senare retry lyckades.
Nästa steg, validera vad er kod såg vid kanten: bekräfta signeringshemligheten konfigurerad för den endpointen, räkna om signaturverifieringen med rå begäranstext och kontrollera begärans tidsstämpel mot ert tillåtna fönster.
Var försiktig med replay-fönster under retries. Om ditt fönster är 5 minuter och leverantören försöker 30 minuter senare kan du avvisa en legitim retry. Om det är er policy, dokumentera det tydligt. Om inte, vidga fönstret eller ändra logiken så att idempotency förblir primärt skydd mot dubbletter.
Om signatur och tidsstämpel ser bra ut, följ event ID genom systemet och besvara: bearbetade ni det, deduplikera ni det, eller droppade ni det?
Vanliga utfall:
- Deduperat: idempotency-nyckeln finns redan, så ni returnerade 200 utan att köra affärslogik igen.
- Avvisat: validering misslyckades (signaturmismatch, tidsstämpel för gammal, saknade headers).
- Timed out: handlern tog för lång tid, leverantören markerade det som misslyckat och försökte igen.
När ni svarar kunden, var kort och specifik: "Vi mottog leveransförsök kl. 10:03 och 10:33 UTC. Första timed out efter 10s; retry avvisades eftersom tidsstämpeln låg utanför vårt 5-minutersfönster. Vi ökade fönstret och la till snabbare bekräftelse. Skicka gärna event ID X igen om det behövs."
Nästa steg: gör det upprepbart
Det snabbaste sättet att stoppa webhook-bränder är att få varje integration att följa samma playbook. Skriv ner kontraktet ni och avsändaren enas om: nödvändiga headers, exakt signeringsmetod, vilken tidsstämpel som används och vilka ID:n ni behandlar som unika.
Standardisera sedan vad ni registrerar för varje leveransförsök. En liten kvitto-logg räcker ofta: received_at, event_id, delivery_id, signature_valid, idempotency_result (ny/dubblett), handler_version och response status.
Ett arbetsflöde som förblir användbart när ni växer:
- Behåll en dedikerad test-endpoint som validerar signaturer och returnerar 2xx utan att köra affärslogik.
- Spara rå request-body och viktiga headers en kort tid, precis tillräckligt för felsökning och replay.
- Bygg ett replay-säkert reprocess-jobb som kör lagrade events genom samma handler-kodväg.
- Ha en intern checklista som support, QA och engineering följer.
Om ni bygger appar på Koder.ai (koder.ai), är Planning Mode ett bra sätt att först definiera webhook-kontraktet (headers, signering, ID:n, retry-beteende) och sedan generera en konsekvent endpoint och kvittopost över projekt. Denna konsekvens är vad som gör felsökning snabb i stället för hjältemodig.
Vanliga frågor
Varför verkar webhooks "slumpmässigt" misslyckas eller duplicera i produktion?
Eftersom webhook-leverans vanligtvis är at-least-once, inte exakt en gång. Leverantörer försöker om vid timeouts, 5xx-responser och ibland när de inte ser ditt 2xx i tid, så du kan få dubbletter, fördröjningar och events i fel ordning även när allt verkar "fungera".
Vad är det säkraste grundflödet för att hantera en webhook-begäran?
Standardflödet är detta: verifiera signaturen först, spara/dedupe eventet, svara 2xx, och utför tunga uppgifter asynkront.
Om du gör tungt arbete innan du svarar kommer du att drabbas av timeouts och trigga retries; om du svarar innan du sparat något kan du förlora events vid krascher.
Hur undviker jag signaturmismatch när jag verifierar webhooks?
Använd de råa bytesen av begäranskroppen exakt som de mottogs. Parsning och återserialisering av JSON kan ändra whitespace, nyckelordning och talformat, vilket bryter signaturer.
Se också till att du återskapar det som leverantören signerat exakt (ofta timestamp + "." + raw_body).
Vad ska min endpoint göra när signaturverifiering misslyckas?
Returnera en 4xx (vanligtvis 400 eller 401) och behandla inte payloaden.
Logga en minimal orsak (saknad signaturheader, mismatch, ogiltigt tidsfönster), men logga inte hemligheter eller fulla känsliga payloads.
Vad är en idempotency-nyckel för webhooks, och vilket värde bör jag använda?
Ett idempotency-nyckel är en stabil unik identifierare du sparar så retries inte återutför sidoeffekter.
Bästa val:
- Event ID (ideal när ett event motsvarar en affärsförändring)
- Delivery/message ID (om det är konstant över retries)
- Hash av stabila fält (sista utväg)
Tvinga det med en unik constraint så att endast en förfrågan "vinner" vid samtidig åtkomst.
Hur deduplicerar jag webhooks utan race conditions?
Skriv idempotency-nyckeln innan du gör sidoeffekter, med en unikhetsregel. Sedan:
- Markera som behandlad efter framgång, eller
- Registrera ett felstatus så du kan försöka igen säkert
Om insert misslyckas eftersom nyckeln redan finns, returnera 2xx och hoppa över affärslogiken.
Hur lägger jag till replay-skydd utan att avvisa legitima retries?
Signera inte bara payloaden—inkludera också en tidsstämpel. Din webhook kan ha headers som X-Signature och X-Timestamp. Vid mottag, verifiera signaturen och kontrollera att tidsstämpeln är färsk inom ett kort fönster.
För att undvika att blockera legitima retries:
- Tillåt viss clock drift
- Logga din server-tid och mottagen tidsstämpel vid avvisning
- Behandla idempotency som huvudskyddet mot dubbletter; tidsfönstret är främst för att stoppa sena replay-attacker.
Hur ska jag hantera webhook-events som kommer i fel ordning?
Anta inte att leveransordning är samma som event-ordning. Gör handlers toleranta:
- Använd upserts där det passar
- Kontrollera aktuellt tillstånd innan du applicerar ändringar
- Om ett objekt inte hittas, överväg att köra om senare (via kö) i stället för permanent fel
Spara event ID och typ så du kan förstå vad som hände även när ordningen är konstig.
Vad bör jag logga så webhook-felsökning inte blir gissningar?
Logga ett litet ”kvitto” per leveransförsök så du kan spåra ett event från början till slut:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- idempotency result (ny/dubblett)
- response_code, latency_ms
- tidsstämplar (received/first_seen/last_seen)
Gör loggar sökbara på event ID så support kan svara kundfrågor snabbt.
Vad är ett snabbt sätt att undersöka en kundrapport om att "en webhook aldrig kom"?
Börja med ett enda konkret ID: event ID eller delivery ID, plus ungefärlig tidsstämpel. Sedan kolla i denna ordning:
- Resultat av signaturverifiering
- Tidsstämpel/replay-fönster (om ni använder det)
- Idempotency-resultat (ny vs dubblett)
- Vad ni returnerade (statuskod + latens)
Om ni bygger endpoints med Koder.ai, håll handler-mönstret konsekvent (verify → record/dedupe → queue → respond). Konsekvens gör att dessa kontroller går snabbt vid incidenter.