02 sep. 2025·8 min
Protobuf vs JSON för API:er: Hastighet, storlek och kompatibilitet
Jämför Protobuf och JSON för API:er: payload-storlek, hastighet, läsbarhet, verktyg, versionering och när varje format passar bäst i verkliga produkter.
Jämför Protobuf och JSON för API:er: payload-storlek, hastighet, läsbarhet, verktyg, versionering och när varje format passar bäst i verkliga produkter.
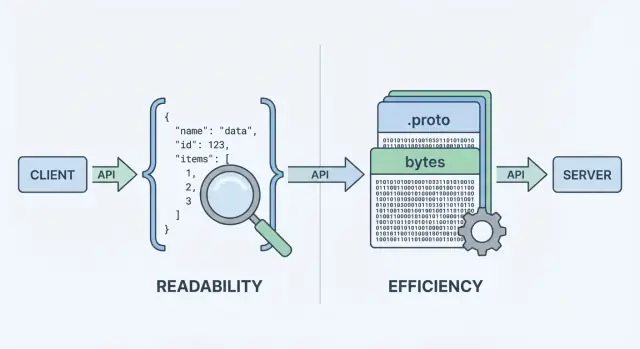
När ditt API skickar eller tar emot data behöver det ett dataformat—ett standardiserat sätt att representera information i request- och response-body. Det formatet serialiseras (omvandlas till bytes) för transport över nätverket och deserialiseras tillbaka till användbara objekt i klienten och servern.
Två av de vanligaste valen är JSON och Protocol Buffers (Protobuf). De kan representera samma affärsdata (användare, ordrar, tidsstämplar, listor med objekt), men de gör olika avvägningar kring prestanda, payload-storlek och utvecklarflöde.
JSON (JavaScript Object Notation) är ett textbaserat format byggt av enkla strukturer som objekt och arrayer. Det är populärt för REST-API:er eftersom det är lätt att läsa, lätt att logga och att inspektera med verktyg som curl och webbläsarens DevTools.
En stor anledning till att JSON är överallt: de flesta språk har utmärkt stöd, och du kan visuellt inspektera ett svar och förstå det omedelbart.
Protobuf är ett binärt serialiseringsformat skapat av Google. Istället för att skicka text skickar det en kompakt binär representation definierad av ett schema (en .proto-fil). Schemat beskriver fälten, deras typer och numeriska taggar.
Eftersom det är binärt och schema-drivet producerar Protobuf ofta mindre payloads och kan vara snabbare att parsa—vilket spelar roll när du har hög förfrågningsvolym, mobila nätverk eller latenskänsliga tjänster (vanligt i gRPC-uppsättningar, men inte begränsat till gRPC).
Det är viktigt att separera vad du skickar från hur det kodas. En “user” med id, namn och email kan modelleras både i JSON och Protobuf. Skillnaden är kostnaden du betalar i:
Det finns inget universallösning. För många publika API:er förblir JSON standard eftersom det är tillgängligt och flexibelt. För intern tjänst-till-tjänst-kommunikation, prestandakritiska system eller där kontrakt måste vara strikta kan Protobuf vara bättre. Målet med den här guiden är att hjälpa dig välja utifrån begränsningar—inte ideologi.
När ett API returnerar data kan det inte skicka “objekt” direkt över nätverket. Det måste först omvandla dem till en ström av bytes. Den omvandlingen är serialisering—tänk på det som att packa data i en sändbar form. På andra sidan gör klienten motsatsen (deserialisering), packar upp bytesen tillbaka till användbara datastrukturer.
Ett typiskt request/response-flöde ser ut så här:
Det där “kodningssteget” är där formatvalet spelar roll. JSON-kodning producerar läsbar text som {\"id\":123,\"name\":\"Ava\"}. Protobuf-kodning producerar kompakta binära bytes som inte betyder något för människor utan verktyg.
Eftersom varje svar måste packas och packas upp påverkar formatet:
Din API-stil påverkar ofta beslutet:
curl och lätt att logga och inspektera.Du kan använda JSON med gRPC (via transcoding) eller använda Protobuf över vanligt HTTP, men standardergonomin i din stack—frameworks, gateways, klientbibliotek och felsökningsvanor—bestämmer ofta vad som är enklast i vardagen.
När folk jämför protobuf vs json börjar de oftast med två mätvärden: hur stor payloaden blir och hur lång tid det tar att koda/avkoda. Rubriken är enkel: JSON är text och tenderar att vara ordrik; Protobuf är binärt och tenderar att vara kompakt.
JSON upprepar fältnamn och använder textrepresentationer för tal, booleaner och struktur, så det skickar ofta fler bytes över tråden. Protobuf ersätter fältnamn med numeriska taggar och packar värden effektivt, vilket ofta leder till märkbart mindre payloads—särskilt för stora objekt, upprepade fält och djupt nästlade data.
Med det sagt kan komprimering minska skillnaden. Med gzip eller brotli komprimeras JSON:s upprepade nycklar mycket bra, så skillnaden mellan JSON och Protobuf-storlek kan krympa i verkliga distributioner. Protobuf kan också komprimeras, men den relativa vinsten är ofta mindre.
JSON-parsers måste tokenisera och validera text, konvertera strängar till tal och hantera specialfall (escaping, whitespace, unicode). Protobuf-dekodning är mer direkt: läs tagg → läs typat värde. I många tjänster minskar Protobuf CPU-tid och skräpallokationer, vilket kan förbättra tail-latency under belastning.
I mobilnät eller hög-latenslänkar betyder färre bytes vanligtvis snabbare överföringar och mindre radio-tid (vilket även kan hjälpa batteritid). Men om dina svar redan är små kan handshake-överhead, TLS och serverbehandling dominera—vilket gör formatvalet mindre synligt.
Mät med dina verkliga payloads:
Detta förvandlar debatten om “API-serialisering” till data du kan lita på för ditt API.
Utvecklarupplevelse är där JSON ofta vinner som standard. Du kan inspektera en JSON-request eller response nästan var som helst: i webbläsarens DevTools, curl-utdata, Postman, reverse proxies och vanlig textloggning. När något går fel är “vad skickade vi egentligen?” vanligtvis ett kopiera/klistra-bort bort.
Protobuf är annorlunda: det är kompakt och strikt, men inte människoläsbart. Om du loggar råa Protobuf-bytes ser du base64-blobs eller oläsligt binärt. För att förstå payloaden behöver du rätt .proto-schema och en dekoder (t.ex. protoc, språk-specifika verktyg eller din tjänsts genererade typer).
Med JSON är det enkelt att reproducera problem: kopiera en loggad payload, redigera bort hemligheter, replaya med curl och du har ofta ett minimalt testfall.
Med Protobuf brukar du felsöka genom att:
Det extra steget är hanterbart—men bara om teamet har ett upprepat arbetsflöde.
Strukturerad loggning hjälper båda formaten. Logga request-IDs, metodnamn, användar-/kontoidentifikatorer och nyckelfält istället för hela bodies.
För Protobuf specifikt:
.proto använde vi?”.För JSON, överväg att logga kanonisk JSON (stabil fältradering) för att göra diffs och incident-tidslinjer lättare att läsa.
API:er flyttar inte bara data—de flyttar mening. Den största skillnaden mellan JSON och Protobuf är hur tydligt den meningen definieras och upprätthålls.
JSON är i grunden “schema-löst”: du kan skicka vilket objekt som helst med vilka fält som helst, och många klienter accepterar det så länge det ser rimligt ut.
Den flexibiliteten är bekväm i början, men kan också dölja misstag. Vanliga fallgropar inkluderar:
userId i ett svar, user_id i ett annat, eller saknade fält beroende på kodväg."42", "true" eller "2025-12-23"—enkelt att producera, enkelt att misstolka.null kan betyda “okänt”, “inte satt” eller “avsiktligt tomt”, och olika klienter kan behandla det olika.Du kan lägga till JSON Schema eller OpenAPI-spec, men JSON i sig kräver inte att konsumenter följer det.
Protobuf kräver ett schema definierat i en .proto-fil. Ett schema är ett gemensamt kontrakt som anger:
Det kontraktet hjälper till att förhindra oavsiktliga ändringar—som att göra en integer till en string—eftersom den genererade koden förväntar sig specifika typer.
Med Protobuf förblir tal tal, enum är begränsade till kända värden och tidsstämplar modelleras ofta med välkända typer (istället för ad hoc-strängformat). “Inte satt” är också tydligare: i proto3 är frånvaro distinkt från defaultvärden när du använder optional-fält eller wrapper-typer.
Om ditt API förlitar sig på precisa typer och förutsägbar parsing över team och språk ger Protobuf styrskenor som JSON vanligtvis uppnår genom konventioner.
API:er utvecklas: du lägger till fält, justerar beteende och pensionerar gamla delar. Målet är att ändra kontraktet utan att överraska konsumenter.
En bra evolutionsstrategi siktar på båda, men bakåtkompatibilitet är ofta minimikravet.
I Protobuf har varje fält ett nummer (t.ex. email = 3). Det numret—inte fältnamnet—är vad som går på tråden. Namn är mest för människor och genererad kod.
På grund av det:
Säkra ändringar (vanligtvis)
Riskfyllda ändringar (ofta brytande)
Bästa praxis: använd reserved för gamla nummer/namn och behåll en ändringslogg.
JSON har inget inbyggt schema, så kompatibilitet beror på era mönster:
Dokumentera deprecations tidigt: när ett fält är borttaget, hur länge det kommer att stödjas och vad som ersätter det. Publicera en enkel versionspolicy (t.ex. “additiva ändringar är icke-brytande; borttagningar kräver ny major-version”) och håll dig till den.
Valet mellan JSON och Protobuf handlar ofta om var ditt API ska köras—och vad ditt team vill underhålla.
JSON är i praktiken universellt: varje webbläsare och backend-runtime kan parsa det utan extra beroenden. I en webapp är fetch() + JSON.parse() den enkla vägen, och proxies, API-gateways och observability-verktyg tenderar att förstå JSON ur lådan.
Protobuf kan köras i webbläsaren också, men det är inte gratis. Du lägger ofta till ett Protobuf-bibliotek (eller genererad JS/TS-kod), hanterar bundlingsstorlek och bestämmer om du skickar Protobuf över HTTP-endpoints som webbläsarverktyg enkelt kan inspektera.
På iOS/Android och i backend-språk (Go, Java, Kotlin, C#, Python osv.) är Protobuf-stödet moget. Den stora skillnaden är att Protobuf förutsätter att du använder bibliotek per plattform och vanligtvis genererar kod från .proto-filer.
Kodgenerering ger verkliga fördelar:
Det tillför också kostnader:
.proto-paket, versionspinning)Protobuf är nära förknippat med gRPC, vilket ger en komplett verktygshistoria: servicedefinitioner, klient-stubbar, streaming och interceptors. Om du överväger gRPC är Protobuf det naturliga valet.
Om du bygger ett traditionellt JSON REST-API förblir JSON:s verktygsekosystem enklare—särskilt för publika API:er och snabba integrationer.
Om du fortfarande utforskar API-yta kan det hjälpa att prototypa snabbt i båda stilar innan du standardiserar. Till exempel brukar team som använder Koder.ai ofta spinna upp ett JSON REST-API för bred kompatibilitet och en intern gRPC/Protobuf-tjänst för effektivitet, och sedan benchmarka verkliga payloads innan de bestämmer vad som blir “default.” Eftersom Koder.ai kan generera fullstack-appar (React för webben, Go + PostgreSQL på backend, Flutter för mobil) och stödjer planning-läge samt snapshots/rollback är det praktiskt att iterera över kontrakt utan att formatval blir en långlivad refaktorering.
Valet mellan JSON och Protobuf handlar inte bara om payload-storlek eller hastighet. Det påverkar också hur väl ditt API passar in med caching-lager, gateways och de verktyg ditt team förlitar sig på vid incidenter.
De flesta HTTP-cachinginfrastrukturer (webbläsarcacher, reverse proxies, CDNs) är optimerade runt HTTP-semantik, inte ett visst body-format. En CDN kan cachea vilka bytes som helst så länge svaret är cachebart.
Det sagt förväntar sig många team HTTP/JSON vid kanten eftersom det är enkelt att inspektera och felsöka. Med Protobuf fungerar caching fortfarande, men du bör vara noggrann kring:
Vary)Cache-Control, ETag, Last-Modified)Om du stödjer både JSON och Protobuf, använd content negotiation:
Accept: application/json eller Accept: application/x-protobufContent-TypeSe till att caches förstår detta genom att sätta Vary: Accept. Annars kan en cache lagra ett JSON-svar och leverera det till en Protobuf-klient (eller tvärtom).
API-gateways, WAFs, request/response-transformers och observability-verktyg antar ofta JSON-bodies för:
Binär Protobuf kan begränsa dessa funktioner om inte dina verktyg är Protobuf-medvetna (eller om du lägger till avkodningssteg).
Ett vanligt mönster är JSON i kanten, Protobuf internt:
Det här håller externa integrationer enkla samtidigt som du fångar Protobuf:s prestandafördelen där du kontrollerar både klient och server.
Valet JSON eller Protobuf ändrar hur data kodas och parsas—men det ersätter inte kärnkrav som autentisering, kryptering, auktorisation och server-side validering. En snabb serializer räddar inte ett API som accepterar otrustat input utan gränser.
Det kan vara frestande att se Protobuf som “säkrare” eftersom det är binärt och mindre läsbart. Det är inte en säkerhetsstrategi. Angripare behöver inte att dina payloads är människoläsbara—de behöver bara din endpoint. Om API:t läcker känsliga fält, accepterar ogiltiga tillstånd eller har svag auth så kommer inte formatbytet att fixa det.
Kryptera transporten (TLS), verkställ authz, validera input och logga säkert oavsett om du använder JSON REST eller gRPC Protobuf.
Båda formaten delar vanliga risker:
För att hålla API:er pålitliga under belastning och missbruk, applicera samma skydd för båda format:
Slutsatsen: “binärt vs textformat” påverkar främst prestanda och ergonomi. Säkerhet och tillförlitlighet kommer från konsekventa gränser, uppdaterade beroenden och explicit validering—oavsett vilken serializer du väljer.
Att välja mellan JSON och Protobuf handlar mindre om vilket som är “bäst” och mer om vad ditt API behöver optimera för: människovänlighet och räckvidd, eller effektivitet och strikta kontrakt.
JSON är oftast det säkraste standardvalet när du behöver bred kompatibilitet och enkel felsökning.
Typiska scenarier:
Protobuf tenderar att vinna när prestanda och konsekvens är viktigare än människoläsbarhet.
Typiska scenarier:
Använd dessa frågor för att snabba upp valet:
Du kan göra följande till en tabell i din dokumentation:
Om du fortfarande är osäker är “JSON i kanten, Protobuf internt” ofta ett pragmatiskt kompromiss.
Att migrera format handlar mindre om att skriva om allt och mer om att minska risken för konsumenter. De säkraste flyttarna håller API:t användbart under övergången och gör det lätt att backa.
Välj ett låg-risk-ytområde—ofta ett internt tjänst-till-tjänst-anrop eller en enda read-only-endpoint. Det låter dig validera Protobuf-schemat, genererade klienter och observability-ändringar utan att hela API:t blir ett "big bang"-projekt.
Ett praktiskt första steg är att lägga till en Protobuf-representation för en befintlig resurs samtidigt som JSON-shapen behålls. Du lär dig snabbt var din datamodell är tvetydig (null vs saknad, tal vs sträng, datumformat) och kan lösa det i schemat.
För externa API:er är dualt stöd ofta smidigast:
Content-Type och Accept headers./v2/...) bara om negotiation är svår med era verktyg.Under den här perioden, se till att båda format genereras från samma source-of-truth-modell för att undvika subtil drift.
Planera för:
Publicera .proto-filer, fältkommentarer och konkreta request/response-exempel (både JSON och Protobuf) så att konsumenter kan verifiera att de tolkar data korrekt. En kort “migrationsguide” och changelog minskar supportbehovet och snabbar upp adoptionen.
Att välja mellan JSON och Protobuf handlar ofta om verkligheten kring din trafik, klienter och operationella begränsningar. De mest tillförlitliga vägarna är att mäta, dokumentera beslut och hålla API-förändringar tråkiga.
Kör ett litet experiment på representativa endpoints.
Spåra:
Gör detta i staging med produktion-liknande data, och validera sedan i produktion på en liten trafik-slice.
Oavsett om du använder JSON Schema/OpenAPI eller .proto-filer:
Även om du väljer Protobuf för prestanda, håll din dokumentation vänlig:
Om du underhåller docs eller SDK-guider, länka dem tydligt i din dokumentation (t.ex. docs och blog). Om prissättning eller användningsbegränsningar påverkar formatval, gör det synligt också (pricing).
JSON är ett textbaserat format som är lätt att läsa, logga och testa med vanliga verktyg. Protobuf är ett kompakt binärt format definierat av ett .proto-schema, vilket ofta ger mindre payloads och snabbare parsing.
Välj utifrån begränsningar: räckvidd och felsökningsvänlighet (JSON) vs effektivitet och strikta kontrakt (Protobuf).
API:er skickar bytes, inte in-memory-objekt. Serialisering kodar dina serverobjekt till ett payload (JSON-text eller Protobuf-binary) för transport; deserialisering avkodar dessa bytes tillbaka till klient-/serverobjekt.
Ditt formatval påverkar bandbredd, latens och CPU som spenderas på (de)serialisering.
Ofta ja, särskilt för stora eller nästlade objekt och upprepade fält, eftersom Protobuf använder numeriska taggar och effektiv binär kodning.
Men om du aktiverar gzip/brotli komprimeras JSON:s upprepade nycklar bra, så den verkliga storleksskillnaden kan minska. Mät både rå och komprimerad storlek.
Det kan vara det. JSON-parsning kräver tokenisering av text, hantering av escaping/unicode och konvertering från strängar till tal. Protobuf-dekodning är mer direkt (tagg → typat värde), vilket ofta minskar CPU-tid och allokationer.
Men om payloads är mycket små kan total latens domineras av TLS, nätverks-RTT och applikationsarbete snarare än serialisering.
Det är svårare som standard. JSON är människoläsbart och lätt att inspektera i DevTools, loggar, curl och Postman. Protobuf-payloads är binära, så du behöver normalt matchande .proto-schema och avkodningsverktyg.
Ett vanligt förbättringsflöde är att logga en avkodad, raderad debugvy (ofta JSON) tillsammans med request-id:n och nyckelfält.
JSON är flexibelt och ofta “schema-löst” om du inte använder JSON Schema/OpenAPI. Den flexibiliteten kan leda till inkonsekventa fält, “stringly-typed” värden och tvetydig null-semantik.
Protobuf tvingar fram typer via en .proto-kontrakt, genererar starkt typad kod och gör utvecklingsbara kontrakt tydligare—särskilt när flera team och språk är involverade.
I Protobuf styrs kompatibilitet av fält-nummer (taggar). Säkra ändringar är vanligtvis additiva (nya valfria fält med nya nummer). Brytande förändringar inkluderar att återanvända ett fältnummer eller ändra typ inkompatibelt. Använd reserved för borttagna nummer/namn och behåll en ändringslogg.
För JSON är bästa praxis att föredra additiva fält, hålla typer stabila och låta okända fält ignoreras.
Ja. Använd HTTP content negotiation:
Accept: application/json eller Accept: application/x-protobufContent-TypeVary: Accept så att caches inte blandar formatOm verktygen gör negotiation svårt kan en separat endpoint/version vara en tillfällig migrationsstrategi.
Det beror på miljön:
Tänk också på kostnaden för kodgenerering och versionshantering av delade scheman när du väljer Protobuf.
Båda formaten ska behandlas som otrustat input. Valet av format är ingen säkerhetsbarriär.
Praktiska skydd för båda:
Håll parsare/bibliotek uppdaterade för att minska exponering mot parser-sårbarheter.