05 okt. 2025·8 min
RabbitMQ för dina applikationer: mönster, installation och drift
Lär dig använda RabbitMQ i dina applikationer: kärnkoncept, vanliga mönster, tips för tillförlitlighet, skalning, säkerhet och övervakning i produktion.
Lär dig använda RabbitMQ i dina applikationer: kärnkoncept, vanliga mönster, tips för tillförlitlighet, skalning, säkerhet och övervakning i produktion.
RabbitMQ är en meddelandeförmedlare: den sitter mellan delar av ditt system och flyttar pålitligt “arbete” (meddelanden) från producenter till konsumenter. Applikationsteam tar oftast till det när direkta, synkrona anrop (service-till-service HTTP, delade databaser, cronjobb) börjar skapa sköra beroenden, ojämn belastning och svåra kedjor av fel att debugga.
Trafiktoppar och ojämn arbetsbörda. Om din app får 10× fler registreringar eller beställningar under en kort period kan direkt bearbetning överbelasta downstream-tjänster. Med RabbitMQ kan producenter köa upp uppgifter snabbt och konsumenter arbeta igenom dem i en kontrollerad takt.
Tight koppling mellan tjänster. När Tjänst A måste anropa Tjänst B och vänta sprids fel och latenser. Messaging decouplar dem: A publicerar ett meddelande och fortsätter; B bearbetar när den är redo.
Säkrare felhantering. Inte varje fel bör bli ett synligt fel för användaren. RabbitMQ hjälper dig att göra omförsök i bakgrunden, isolera ”poison”-meddelanden och undvika att förlora arbete vid tillfälliga driftstopp.
Team får vanligtvis jämnare arbetsbörda (buffrar toppar), decouplade tjänster (färre runtime-beroenden) och kontrollerade omförsök (mindre manuell återbearbetning). Lika viktigt blir det lättare att förstå var arbete sitter fast—hos producenten, i en kö eller i en konsument.
Guiden fokuserar på praktisk RabbitMQ för applikationsteam: kärnkoncept, vanliga mönster (pub/sub, work queues, omförsök och dead-letter queues) och operationella aspekter (säkerhet, skalning, observabilitet, felsökning).
Den avser inte att vara en fullständig AMQP-specifikation eller en djupdykning i alla RabbitMQ-plugins. Målet är att hjälpa dig designa meddelandeflöden som förblir underhållbara i verkliga system.
RabbitMQ är en meddelandeförmedlare som routar meddelanden mellan delar av ditt system, så producenter kan lämna över arbete och konsumenter kan bearbeta det när de är redo.
Vid ett direkt HTTP-anrop skickar Tjänst A vanligtvis en förfrågan till Tjänst B och väntar på svar. Om Tjänst B är långsam eller nere misslyckas eller stannar Tjänst A, och du måste hantera timeouts, omförsök och backpressure i varje anropare.
Med RabbitMQ (vanligtvis via AMQP) publicerar Tjänst A ett meddelande till brokern. RabbitMQ lagrar och routar det till rätt kö(er), och Tjänst B konsumerar det asynkront. Den stora förändringen är att du kommunicerar genom ett hållbart mellanlager som buffrar toppar och jämnar ut ojämn arbetsbelastning.
Messaging passar när du:
Messaging passar sämre när du:
Synkront (HTTP):
En checkout-tjänst anropar en faktureringstjänst över HTTP: “Skapa faktura.” Användaren väntar medan faktureringen körs. Om faktureringen är långsam ökar checkout-latensen; om den är nere misslyckas checkout.
Asynkront (RabbitMQ):
Checkout publicerar invoice.requested med order-id. Användaren får omedelbar bekräftelse att ordern mottagits. Fakturering konsumerar meddelandet, genererar fakturan och publicerar invoice.created för e-post/notifieringar att plocka upp. Varje steg kan göra omförsök oberoende, och tillfälliga avbrott bryter inte automatiskt hela flödet.
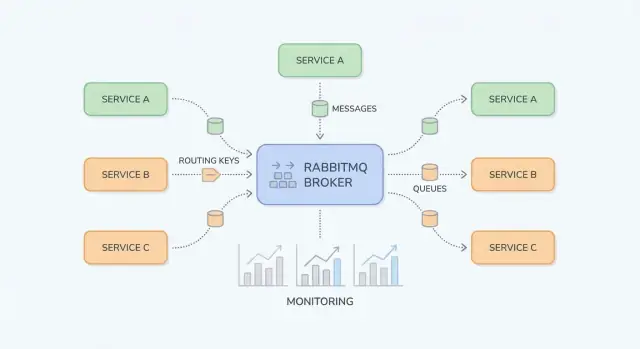
RabbitMQ är lättare att förstå om du separerar “vart meddelanden publiceras” från “vart de lagras.” Producenter publicerar till exchanges; exchanges routar till queues; konsumenter läser från queues.
En exchange lagrar inte meddelanden. Den utvärderar regler och forwards meddelanden till en eller flera köer.
billing eller email).region=eu OCH tier=premium), men håll det för speciella fall då det är svårare att överblicka.En queue är där meddelanden sitter tills en konsument bearbetar dem. En kö kan ha en eller många konsumenter (konkurrerande konsumenter), och meddelanden levereras vanligtvis till en konsument i taget.
En binding kopplar en exchange till en queue och definierar routingregeln. Tänk: “När ett meddelande träffar exchange X med routing key Y, leverera det till queue Q.” Du kan binda flera köer till samma exchange (pub/sub) eller binda en enda kö flera gånger för olika routing keys.
För direct exchanges är routingen exakt. För topic exchanges ser routing keys ut som punktskiljda ord, t.ex.:
orders.createdorders.eu.refundedBindings kan inkludera wildcards:
* matchar exakt ett ord (t.ex. orders.* matchar orders.created)# matchar noll eller flera ord (t.ex. orders.# matchar orders.created och orders.eu.refunded)Detta ger en ren metod att lägga till nya konsumenter utan att ändra producenter—skapa en ny queue och binda den med mönstret du behöver.
Efter att RabbitMQ levererat ett meddelande rapporterar konsumenten vad som hände:
Var försiktig med requeue: ett meddelande som alltid misslyckas kan loopa för evigt och blockera kön. Många team parar nacks med en retry-strategi och en dead-letter queue så fel hanteras förutsägbart.
RabbitMQ glänser när du behöver flytta arbete eller notifieringar mellan delar av ditt system utan att göra allt beroende av ett enda långsamt steg. Nedan följer praktiska mönster som dyker upp i vardagliga produkter.
När flera konsumenter ska reagera på samma event—utan att producenten känner till dem—är pub/sub en bra lösning.
Exempel: när en användare uppdaterar sin profil kan du notifiera sökindexering, analytics och en CRM-synk parallellt. Med en fanout exchange broadcastar du till alla bundna köer; med en topic exchange routar du selektivt (t.ex. user.updated, user.deleted). Detta undviker tight coupling och låter team lägga till nya subscribers senare utan att ändra producenten.
Om en uppgift tar tid, putta den till en kö och låt workers bearbeta den asynkront:
Detta håller webbförfrågningar snabba samtidigt som du kan skala workers oberoende. Det är också ett naturligt sätt att kontrollera samtidighet: kön blir din “att-göra-lista” och antalet workers blir din “throughput-knapp”.
Många arbetsflöden går över tjänstgränser: order → fakturering → frakt är klassikern. Istället för att en tjänst anropar nästa och blockerar, kan varje tjänst publicera ett event när den är klar med sitt steg. Nedströms tjänster konsumera events och fortsätter arbetsflödet.
Detta förbättrar motståndskraft (ett tillfälligt avbrott i frakt bryter inte checkout) och gör ägarskap tydligare: varje tjänst reagerar på de events den bryr sig om.
RabbitMQ är också en buffer mellan din app och beroenden som kan vara långsamma eller instabila (tredjeparts-API:er, legacy-system, batch-databaser). Du köar upp förfrågningar snabbt och bearbetar dem med kontrollerade omförsök. Om beroendet är nere ackumuleras arbete säkert och töms senare—istället för att orsaka timeouts i hela applikationen.
Om du planerar att införa köer gradvis är ett litet “async outbox” eller en enkel bakgrundsjobbkö ofta ett bra första steg.
En RabbitMQ-setup är trevlig att arbeta med när routing är lätt att förutsäga, namn är konsekventa och payloads utvecklas utan att bryta äldre konsumenter. Innan du lägger till ännu en kö, se till att meddelandets “story” är uppenbar: var det kommer ifrån, hur det routas och hur en kollega kan felsöka det end-to-end.
Att välja rätt exchange från början minskar engångsbindningar och oväntade fan-outs:
billing.invoice.created).billing.*.created, *.invoice.*). Detta är det vanligaste valet för hållbar event-stil routing.En bra regel: om du uppfinnar komplex routinglogik i kod, hör det kanske hemma i ett topic exchange-mönster istället.
Behandla meddelandekroppar som publika API:er. Använd uttrycklig versionering (t.ex. ett top-level-fält som schema_version: 2) och sikta på bakåtkompatibilitet:
Detta håller äldre konsumenter igång medan nya adopterar det nya schemat i sin egen takt.
Gör felsökning billig genom att standardisera metadata:
correlation_id: binder samman kommandon/events som hör till samma affärshändelse.trace_id (eller W3C traceparent): kopplar meddelanden till distribuerad tracing över HTTP och asynkrona flöden.När varje publisher sätter dessa konsekvent kan du följa en transaktion över flera tjänster utan gissningar.
Använd förutsägbara, sökbara namn. Ett vanligt mönster:
<domain>.<type> (t.ex. billing.events)<domain>.<entity>.<verb> (t.ex. billing.invoice.created)<service>.<purpose> (t.ex. reporting.invoice_created.worker)Konsekvens slår smarta namn: framtida du (och din on-call) kommer tacka dig.
Pålitlig messaging handlar mest om att planera för fel: konsumenter kraschar, downstream-API:er timear ut och vissa events är felaktiga. RabbitMQ ger verktygen, men din applikationskod måste samarbeta.
Ett vanligt upplägg är at-least-once delivery: ett meddelande kan levereras flera gånger, men det ska inte tyst försvinna. Detta händer vanligtvis när en konsument tar emot ett meddelande, börjar arbete och sedan misslyckas före ack—RabbitMQ requeue:ar och levererar igen.
Praktisk slutsats: dubbletter är normala, så din handler måste tåla att köras flera gånger.
Idempotens betyder “att bearbeta samma meddelande två gånger ger samma effekt som en gång.” Användbara tillvägagångssätt:
message_id (eller affärsnyckel som order_id + event_type + version) och lagra det i en “behandlad”-tabell/cache med TTL.PENDING) eller databasunikhetsbegränsningar för att förhindra dubbel-skapande.Behandla omförsök som ett separat flöde, inte en tight loop i din consumer.
Ett vanligt mönster är:
Detta skapar backoff utan att hålla meddelanden “fast” som unacked.
Vissa meddelanden kommer aldrig lyckas (fel schema, saknad referensdata, kodbugg). Identifiera dem genom:
Routa dessa till en DLQ för karantän. Behandla DLQ som en operativ inkorg: inspektera payloads, fixa grundorsaken och replaya manuellt utvalda meddelanden (helst via ett kontrollerat verktyg/script) istället för att dumpa allt tillbaka i huvudkön.
RabbitMQ-prestanda begränsas oftast av ett fåtal praktiska faktorer: hur du hanterar connections, hur snabbt konsumenter säkert kan bearbeta arbete, och om köer används som “lagring”. Målet är stabil genomströmning utan växande backlog.
Ett vanligt misstag är att öppna en ny TCP-anslutning för varje publisher eller consumer. Connections är tyngre än man tror (handshakes, heartbeats, TLS), så håll dem långlivade och återanvänd dem.
Använd channels för att multiplexa arbete över ett mindre antal connections. Tumregel: få connections, många channels. Skapa inte tusentals channels utan vidare—varje channel har overhead, och din klientbibliotek kan ha egna gränser. Föredra en liten channel-pool per tjänst och återanvänd channels för publicering.
Om konsumenter plockar för många meddelanden samtidigt ser du minnesspikar, långa process-tider och ojämn latens. Sätt en prefetch (QoS) så varje konsument bara håller ett kontrollerat antal unacked-meddelanden.
Praktisk vägledning:
Stora meddelanden minskar genomströmningen och ökar minnesbelastningen (på publishers, broker och consumers). Om din payload är stor (dokument, bilder, stora JSON), överväg att lagra den externt (objektlagring eller databas) och skicka endast ett ID + metadata via RabbitMQ.
En bra tumregel: håll meddelanden i KB-intervallet, inte MB.
Kötillväxt är en symptom, inte en strategi. Lägg in backpressure så producenter saktar ner när konsumenter inte hinner med:
När du är osäker, ändra en parameter i taget och mät: publish rate, ack rate, kölängd och end-to-end-latens.
Säkerhet för RabbitMQ handlar mest om att förstärka “kanterna”: hur klienter ansluter, vem som får göra vad och hur du håller credentials ur fel händer. Använd checklistan som baseline och anpassa efter era compliance-krav.
RabbitMQ-permissioner är kraftfulla när du använder dem konsekvent.
För operationell hårdning (ports, brandväggar och audit) håll en kort intern runbook och länka den från era interna säkerhetsdokument så team följer en standard.
När RabbitMQ beter sig konstigt visar symtomen sig ofta i din applikation först: långsamma endpoints, timeouts, saknade uppdateringar eller jobb som “aldrig blir klara”. Bra observabilitet låter dig bekräfta om brokern är orsaken, hitta flaskhalsen (publisher, broker eller consumer) och agera innan användare märker det.
Börja med ett litet set signaler som visar om meddelanden flyter.
Larma på trender, inte bara absoluta trösklar.
Broker-loggar hjälper dig skilja på “RabbitMQ är nere” och “klienter missbrukar den”. Leta efter autentiseringsfel, blockerade connections (resource alarms) och frekventa channel-fel. På applikationssidan, se till att varje bearbetningsförsök loggar en correlation ID, queue-namn och utfall (acked, rejected, retried).
Om ni använder distribuerad tracing, propagagera trace-headers genom meddelandeegenskaper så du kan koppla “API-förfrågan → publicerat meddelande → consumer-arbete.”
Bygg en dashboard per kritiskt flöde: publish rate, ack rate, djup, unacked, requeues och konsumentantal. Lägg in länkar i dashboarden till er interna runbook och en “vad att kolla först”-checklista för on-call.
När något “bara slutar röra sig” i RabbitMQ, motstå frestelsen att starta om direkt. De flesta problem blir uppenbara när du tittar på (1) bindings och routing, (2) konsumenthälsa och (3) resource-alarms.
Om producenter rapporterar “skickat framgångsrikt” men köer förblir tomma (eller fel kö fylls), kontrollera routing innan du gräver i koden.
Börja i Management UI:
topic exchanges).Om kön har meddelanden men ingen konsumerar, kontrollera:
Dubbletter kommer typiskt från omförsök (consumer-krasch efter bearbetning men före ack), nätverksavbrott eller manuella requeues. Mildra genom att göra handlers idempotenta (t.ex. dedupe via message ID i en databas).
Fel ordning kan ske när du har flera konsumenter eller requeues. Om ordning är viktig, använd en enda konsument för den kön eller partitionera per nyckel till flera köer.
Alarmer betyder att RabbitMQ skyddar sig själv.
Innan replay: åtgärda grundorsaken och förhindra poison-loopar. Requeue i små batcher, lägg till en retry-gräns och märk fel med metadata (antalsförsök, senaste fel). Överväg att skicka replayade meddelanden till en separat kö först så du kan stoppa snabbt om samma fel upprepar sig.
Att välja ett messaging-verktyg handlar mindre om “bäst” och mer om att matcha ditt trafikmönster, feltolerans och operativa komfort.
RabbitMQ glänser när du behöver pålitlig meddelandeleverans och flexibel routing mellan applikationskomponenter. Det är ett starkt val för klassiska asynkrona arbetsflöden—kommandon, bakgrundsjobb, fan-out-notifieringar och request/response-mönster—särskilt när du vill ha:
Om era applikationer är eventdrivna men huvudmålet är att flytta arbete snarare än att behålla lång event-historia, är RabbitMQ ofta ett bekvämt default.
Kafka och liknande plattformar är byggda för hög genomströmning och långlivade event-loggar. Välj ett Kafka-liknande system när du behöver:
Trade-off: Kafka-stil system kan ha högre operationellt ansvar och kan driva er mot throughput-orienterad design (batchning, partitionsstrategi). RabbitMQ tenderar att vara enklare för låg-till-måttlig genomströmning med låg end-to-end-latens och komplex routing.
Om du har en app som producerar jobb och ett worker-pool som konsumerar—och du är nöjd med enklare semantik—kan en Redis-baserad kö (eller en managed task-tjänst) räcka. Team växer oftast ur det när de behöver starkare leveransgarantier, dead-lettering, flera routingmönster eller tydligare separation mellan producenter och konsumenter.
Designa era meddelandekontrakt som om ni kan komma att byta senare:
Om ni senare behöver replaybara streams kan ni ofta bro mellan RabbitMQ-events och ett loggbaserat system samtidigt som RabbitMQ behåller operationella arbetsflöden. För en praktisk införandeplan, se en praktisk rollout-checklista.
Att rulla ut RabbitMQ funkar bäst när du behandlar det som en produkt: börja smått, definiera ägarskap och bevisa driftssäkerhet innan du expanderar till fler tjänster.
Välj ett enda arbetsflöde som vinner på asynkron bearbetning (t.ex. skicka e-post, generera rapporter, synka mot ett tredjeparts-API).
Om ni behöver en referenstmall för namngivning, retry-tier och grundläggande policies, håll den central i er interna dokumentation.
När ni implementerar dessa mönster, överväg att standardisera scaffolding över team. Till exempel genererar team som använder Koder.ai ofta ett litet producer/consumer-skelett från en chat-prompt (inklusive namngivningskonventioner, retry/DLQ-wiring och trace/correlation-headers), exporterar sedan källkoden för granskning och itererar i planeringsläge innan införande.
RabbitMQ lyckas när “någon äger kön.” Bestäm detta innan produktion:
Om ni formaliserar support eller managed hosting, synka förväntningar tidigt och definiera en kontaktväg för incidenter eller onboarding-hjälp.
Kör små, tidsbegränsade övningar för att bygga tillit:
När en tjänst är stabil i några veckor, replikera samma mönster—uppfinna inte hjulet igen per team.
Använd RabbitMQ när du vill decoupla tjänster, absorbera trafiktoppar eller flytta långsamt arbete bort från request-vägen.
Bra användningsfall är bakgrundsjobb (e-post, PDF-generering), notifieringar till flera konsumenter och arbetsflöden som ska fortsätta fungera under tillfälliga downstream-avbrott.
Undvik RabbitMQ när du verkligen behöver ett omedelbart svar (enkla läsningar/valideringar) eller när du inte kan åta dig versionering, omförsök och övervakning — det är inte valfritt i produktion.
Publicera till en exchange och routa in i queues:
orders.* eller orders.#.De flesta team väljer topic exchanges för hållbar event-stil routing.
En queue lagrar meddelanden tills en konsument bearbetar dem; en binding är regeln som kopplar en exchange till en queue.
För att felsöka routingproblem:
Dessa tre kontroller förklarar de flesta "publicerat men inte konsumerat"-incidenter.
Använd en work queue när du vill att en av många arbetare ska bearbeta varje uppgift.
Praktiska tips:
At-least-once delivery betyder att ett meddelande kan levereras mer än en gång (t.ex. om en consumer kraschar efter att ha utfört arbete men före ack).
Gör konsumenterna säkra genom att:
message_id (eller affärsnyckel) och lagra bearbetade ID:n med TTL.Anta att dubbletter är normala, och designa för dem.
Undvik tighta requeue-loopar. Ett vanligt tillvägagångssätt är “retry queues” plus DLQ:
Repa från DLQ först efter att grundorsaken är åtgärdad, och gör det i små batcher.
Börja med förutsägbara namn och behandla meddelanden som publika API:er:
schema_version i payloaden.Standardisera också metadata:
Fokusera på några signaler som visar om arbete flyter:
Larma på trender (t.ex. “backlog växer under 10 minuter”) och använd loggar som innehåller queue-namn, correlation_id och bearbetningsutfall (acked/retried/rejected).
Gör grunderna konsekvent:
Behåll en kort intern runbook så team följer en standard (länka från era interna säkerhetsdokument).
Börja med att lokalisera var flödet stoppar:
Omstart är sällan det första eller bästa steget.
correlation_id för att binda events/kommandon till en affärshändelse.trace_id (eller W3C trace-headers) för att koppla asynkront arbete till distribuerade traces.Detta underlättar onboarding och incidenthantering.