10 okt. 2025·8 min
Redis för dina applikationer: mönster, fallgropar och tips
Lär dig praktiska sätt att använda Redis i dina appar: caching, sessioner, köer, pub/sub och rate limiting—plus skalning, persistence, övervakning och fallgropar.
Lär dig praktiska sätt att använda Redis i dina appar: caching, sessioner, köer, pub/sub och rate limiting—plus skalning, persistence, övervakning och fallgropar.
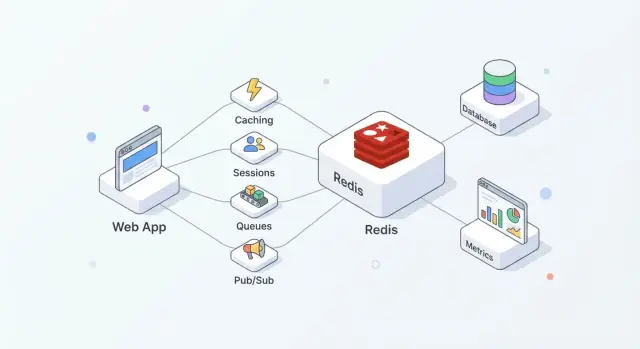
Redis är en minnesbaserad datalager som ofta används som ett delat "snabbt lager" för applikationer. Team gillar det eftersom det är enkelt att ta i bruk, mycket snabbt för vanliga operationer och tillräckligt flexibelt för att hantera mer än en uppgift (cache, sessioner, räknare, köer, pub/sub) utan att införa ett helt nytt system för varje behov.
I praktiken fungerar Redis bäst när du behandlar det som hastighet + samordning, medan din primära databas förblir sanningskällan.
En vanlig uppsättning ser ut så här:
Denna uppdelning håller databasen fokuserad på korrekthet och hållbarhet, medan Redis tar hand om frekventa läsningar/skrivningar som annars skulle öka latens eller belastning.
Använt väl levererar Redis några praktiska vinster:
Redis ersätter inte en primär databas. Om du behöver komplexa frågor, långtidslagring eller analys‑liknande rapportering är databasen fortfarande rätt plats.
Anta inte heller att Redis är "hållbart per default." Om det är oacceptabelt att förlora ens några sekunder av data måste du konfigurera persistence noggrant—eller välja ett annat system baserat på era återställningskrav.
Redis beskrivs ofta som en "key‑value store", men det är mer användbart att tänka på det som en mycket snabb server som kan hålla och manipulera små datadelar per namn (nyckeln). Den modellen uppmuntrar förutsägbara åtkomstmönster: du vet oftast exakt vad du vill ha (en session, en cache:ad sida, en räknare), och Redis kan hämta eller uppdatera det i en enda rundresa.
Redis håller data i RAM, vilket är anledningen till att det kan svara på mikrosekunder till låga millisekunder. Avvägningen är att RAM är begränsat och dyrare än disk.
Bestäm tidigt om Redis är:
Redis kan persistenta data till disk (RDB‑snapshotar och/eller AOF append‑only‑loggar), men persistence lägger till skrivöverhead och tvingar hållbarhetsval (t.ex. "snabbt men kan förlora en sekund" vs "långsammare men säkrare"). Behandla persistence som en ratt du ställer in efter affärspåverkan, inte som en ruta att automatiskt kryssa i.
Redis exekverar kommandon mestadels i en tråd, vilket låter begränsande tills du minns två saker: operationerna är oftast små, och det finns ingen lås‑overhead mellan flera worker‑trådar. Så länge du undviker dyra kommandon och överstora nyttolaster kan denna modell vara mycket effektiv under hög samtidighet.
Din app pratar med Redis över TCP via klientbibliotek. Använd connection pooling, håll förfrågningar små och föredra batching/pipelining när du behöver flera operationer.
Planera för timeouts och retries: Redis är snabbt, men nätverk är det inte, och din applikation bör degradera graciöst när Redis är upptaget eller tillfälligt otillgängligt.
Om du bygger en ny tjänst och vill standardisera dessa grundläggande delar snabbt kan en plattform som Koder.ai hjälpa dig att scaffolda en React + Go + PostgreSQL‑applikation och sedan lägga till Redis‑stödda funktioner (caching, sessioner, rate limiting) via ett chattdrivet arbetsflöde—samtidigt som du kan exportera källkoden och köra den var du behöver.
Caching hjälper bara när det finns tydligt ägarskap: vem fyller cachen, vem invalidierar den och vad "tillräckligt färskt" betyder.
Cache‑aside betyder att din applikation—not Redis—kontrollerar läsningar och skrivningar.
Typiskt flöde:
Redis är en snabb key‑value store; din app bestämmer hur du serialiserar, versionerar och förfaller poster.
En TTL är lika mycket en produktbeslut som ett tekniskt. Korta TTL:er minskar föråldring men ökar databasbelastningen; långa TTL:er spar arbete men riskerar att visa utdaterade resultat.
Praktiska tips:
user:v3:123) så gamla cache:ade format inte bryter ny kod.\n- Hantera föråldring med avsikt: för vissa vyer är lätt föråldrat innehåll okej; för andra (lager, auth) är det inte.När en het nyckel förfaller kan många förfrågningar missa samtidigt.
Vanliga försvar:
Bra kandidater är API‑svar, dyra query‑resultat och beräknade objekt (rekommendationer, aggregeringar). Att cache:a fulla HTML‑sidor kan fungera, men var försiktig med personalisering och behörigheter—cache:a fragment när användarspecifik logik är inblandad.
Redis är praktiskt för att hålla kortlivad inloggningsstatus: sessions‑ID:n, refresh‑token‑metadata och "kom ihåg den här enheten"‑flaggor. Målet är att göra autentisering snabb samtidigt som sessionslängd och återkallande är under strikt kontroll.
Ett vanligt mönster är: din app utfärdar ett slumpmässigt sessions‑ID, sparar en kompakt post i Redis och returnerar ID:t till webbläsaren som en HTTP‑only cookie. Vid varje förfrågan slår du upp sessionnyckeln och fäster användaridentitet och behörigheter i request‑kontexten.
Redis fungerar bra här eftersom sessionläsningar är frekventa och sessionsutgångar är inbyggda.
Designa nycklar så de är enkla att skanna och återkalla:
sess:{sessionId} → sessionspayload (userId, issuedAt, deviceId)\n- user:sessions:{userId} → en Set med aktiva session‑ID:n (valfritt, för "logga ut överallt")Använd en TTL på sess:{sessionId} som matchar din sessionslivslängd. Om du roterar sessioner (rekommenderas) skapa ett nytt session‑ID och ta bort det gamla omedelbart.
Var försiktig med "sliding expiration" (förlänga TTL vid varje förfrågan): det kan hålla sessioner levande på obestämd tid för tunga användare. Ett säkrare kompromiss är att bara förlänga TTL när den är nära att gå ut.
För att logga ut en enhet, radera sess:{sessionId}.
För att logga ut över enheter, antingen:
user:sessions:{userId}, elleruser:revoked_after:{userId}‑timestamp och behandla alla sessioner utfärdade före den som ogiltigaTimestamp‑metoden undviker stor fan‑out‑deletes.
Spara minimalt i Redis—föredra ID:n framför personuppgifter. Lagra aldrig råa lösenord eller långlivade hemligheter. Om du måste spara token‑relaterad data, spara hasher och använd korta TTL:er.
Begränsa vem som kan ansluta till Redis, kräva autentisering och håll sessions‑ID:n hög entropi för att förhindra gissningsattacker.
Rate limiting är ett område där Redis utmärker sig: det är snabbt, delat mellan appinstanser och erbjuder atomiska operationer som håller räknare konsekventa under tung trafik. Det är användbart för att skydda inloggningsendpoints, dyra sökningar, lösenordsåterställningar och alla API:er som kan skrapas eller bruteforcas.
Fixed window är enklast: "100 förfrågningar per minut." Du räknar förfrågningar i aktuell minut. Det är lätt, men kan tillåta burstar vid gränsen (t.ex. 100 vid 12:00:59 och 100 vid 12:01:00).
Sliding window jämnar ut gränser genom att titta på de senaste N sekunder/minuter istället för aktuell bucket. Det är rättvisare, men kostar ofta mer (du kan behöva sorted sets eller mer bokföring).
Token bucket är bra för bursthantering. Användare "tjänar" tokens över tid upp till ett tak; varje förfrågan förbrukar en token. Det tillåter korta burstar samtidigt som det upprätthåller en genomsnittlig gräns.
Ett vanligt fixed‑window‑mönster är:
INCR key för att öka en räknare\n- EXPIRE key window_seconds för att ställa in/återställa TTLTricket är att göra det säkert. Om du kör INCR och EXPIRE som separata anrop kan en krasch mellan dem skapa nycklar som aldrig går ut.
Säkrare tillvägagångssätt inkluderar:
INCR och bara sätta EXPIRE när räknaren skapas första gången.\n- Eller använd SET key 1 EX <ttl> NX för initialisering och sedan INCR efter (ofta fortfarande inpackat i ett script för att undvika race‑conditions).Atomiska operationer är viktigast när trafiken spikar: utan dem kan två förfrågningar "se" samma kvarvarande kvot och båda passera.
De flesta appar behöver flera lager:
rl:user:{userId}:{route})\n- Per‑IP begränsningar för anonyma eller pre‑auth endpoints (t.ex. inloggningsförsök)\n- Per‑route begränsningar för att skydda heta endpoints (sök, export, rapporter)För burstiga endpoints hjälper token bucket (eller ett generöst fixed window plus ett kort "burst"‑fönster) för att undvika att straffa legitima spikes som sidladdningar eller mobilåteranslutningar.
Bestäm i förväg vad "säkert" betyder:
En vanlig kompromiss är fail‑open för låg‑risk‑routes och fail‑closed för känsliga (inloggning, lösenordsåterställning, OTP), med övervakning så ni märker i samma stund som rate limiting slutar fungera.
Redis kan driva bakgrundsjobb när du behöver en lättviktskö för att skicka e‑post, ändra bildstorlekar, synka data eller köra periodiska uppgifter. Nyckeln är att välja rätt datastruktur och sätta tydliga regler för retries och felhantering.
Lists är den enklaste kön: producenter LPUSH, workers BRPOP. De är enkla, men du behöver extra logik för "in‑flight" jobb, retries och visibility timeouts.
Sorted sets glänser när schemaläggning spelar roll. Använd poängen som en tidsstämpel (eller prioritet), och workers hämtar nästa förfallna jobb. Detta passar för fördröjda jobb och prioriterade köer.
Streams är ofta det bästa standardvalet för hållbar arbetsfördelning. De stödjer consumer groups, behåller en historik och låter flera workers samordna utan att du måste uppfinna din egen "processing list."
Med Streams consumer groups läser en worker ett meddelande och senare ACK:ar det. Om en worker kraschar ligger meddelandet kvar som pending och kan hämtas av en annan worker.
För retries, spåra antal försök (i meddelandepayloaden eller en sido‑nyckel) och använd exponential backoff (ofta via en sorted set som "retry‑schema"). Efter max‑antal försök flytta jobbet till en dead‑letter‑queue (en annan stream eller list) för manuell granskning.
Anta att jobb kan köras två gånger. Gör handlers idempotenta genom att:
job:{id}:done) med SET ... NX innan sidoeffekter\n- Designa operationer som upserts istället för att "skapa blint"\n- Spela in externa request‑ID:n när du kallar tredjeparts‑API:erHåll payloads små (lagra stora data annorstädes och skicka referenser). Lägg till backpressure genom att begränsa kölängd, bromsa producenter när backloggen växer och skala workers baserat på pending‑djup och bearbetningstid.
Redis Pub/Sub är det enklaste sättet att broadcasta events: publishers skickar ett meddelande till en kanal och varje ansluten subscriber får det omedelbart. Det finns inget polling—bara en lätt "push" som fungerar bra för realtidsuppdateringar.
Pub/Sub fungerar väl när du bryr dig mer om hastighet och fan‑out än om garanterad leverans:
En användbar mental modell: Pub/Sub är som en radiostation. Alla som är inställda hör sändningen, men ingen får automatiskt en inspelning.
Pub/Sub har viktiga avvägningar:
Därför är Pub/Sub ett dåligt val för arbetsflöden där varje event måste bearbetas ("exactly once" eller ens "at least once").
Om du behöver hållbarhet, retries, consumer groups eller backpressure handling är Redis Streams vanligtvis ett bättre val. Streams låter dig lagra events, bearbeta dem med ack:ar och återhämta dig efter restarts—nära en lättviktig meddelandekö.
I verkliga distributioner har du flera appinstanser som prenumererar. Några praktiska tips:
app:{env}:{domain}:{event} (t.ex. shop:prod:orders:created).\n- Separera broadcast vs riktade kanaler: broadcasta till notifications:global, och rikta användare med notifications:user:{id}.\n- Håll nyttolasten små och självförklarande: inkludera ett ID och minimal metadata; hämta detaljer endast vid behov.Använt så här är Pub/Sub en snabb signal för events, medan Streams (eller en annan kö) hanterar events du inte har råd att förlora.
Att välja datastruktur påverkar inte bara vad som fungerar—det påverkar minnesanvändning, frågehastighet och hur enkel koden förblir över tid. En bra tumregel är att välja strukturen som matchar de frågor du kommer ställa senare (läsmönster), inte bara hur du lagrar data i dag.
INCR/DECR.\n- Hashes: bäst för "ett objekt med fält" (användarprofilfält, kundvagnssummer). Perfekt när du ofta uppdaterar enskilda egenskaper.\n- Sets: bäst för unika medlemskap och medlemskontroller (har användaren redan krävt kupong X?). Snabbt SISMEMBER och enkla set‑operationer.\n- Sorted sets (ZSETs): bäst för rankade data och "top N"‑frågor (leaderboards, prioriteringslistor, tidsbaserad score).Redis‑operationer är atomiska på kommandonivå, så du kan säkert inkrementera räknare utan race‑villkor. Sidvisningar och rate‑limit‑räknare använder ofta strings med INCR plus expiry.
Leaderboards är där sorted sets glänser: du kan uppdatera poäng (ZINCRBY) och hämta toppspelare (ZREVRANGE) effektivt utan att skanna alla poster.
Om du skapar många nycklar som user:123:name, user:123:email, user:123:plan ökar du metadata‑overhead och gör nyckelhanteringen svårare.
En hash som user:123 med fält (name, email, plan) håller relaterad data samlad och minskar oftast antalet nycklar. Det gör också partiella uppdateringar enklare (uppdatera ett fält istället för att skriva om en hel JSON‑sträng).
När du är osäker, modellera ett litet prov och mät minnesanvändningen innan du bestämmer struktur för högvolymdata.
Redis beskrivs ofta som "in‑memory", men du har val för vad som händer när en nod startar om, en disk fylls eller en server försvinner. Rätt setup beror på hur mycket dataförlust du kan acceptera och hur snabbt du behöver återhämta dig.
RDB‑snapshotar sparar en punkt‑i‑tiden dump av datasetet. De är kompakta och snabba att ladda vid startup, vilket kan göra starter snabbare. Nackdelen är att du kan förlora de senaste skrivningarna sedan senaste snapshot.
AOF (append‑only file) loggar skrivoperationer när de sker. Detta minskar vanligtvis potentiell dataförlust eftersom ändringar spelas in mer kontinuerligt. AOF‑filer kan bli större och replays vid startup kan ta längre—men Redis kan omskriva/komprimera AOF för att hålla det hanterbart.
Många team kör både: snapshotar för snabbare restarts och AOF för bättre skrivdurability.
Persistence kostar. Disksparningar, AOF fsync‑policies och bakgrundsomskrivningar kan ge latensspikar om lagringen är långsam eller mättad. Å andra sidan gör persistence restarts mindre skrämmande: utan persistence betyder en oplanerad restart en tom Redis.
Replikering håller en kopia (eller flera) på repliker så du kan faila over när primären går ner. Målet är oftast tillgänglighet först, inte perfekt konsistens. Vid fel kan repliker ligga något efter och en failover kan förlora de sista bekräftade skrivningarna i vissa scenarion.
Innan du finjusterar något, skriv ner två siffror:
Använd dessa mål för att välja RDB‑frekvens, AOF‑inställningar och om du behöver repliker (och automatisk failover) för din Redis‑roll—cache, sessionslagring, kö eller primär datalagring.
En singel Redis‑nod kan ta dig långt: enkelt att drifta, lätt att resonera om och ofta snabbt nog för många caching-, sessions‑ eller kö‑arbetsbelastningar.
Skalning blir nödvändig när du når hårda gränser—vanligtvis RAM‑taket, CPU‑saturation eller att en nod blir en oacceptabel single point of failure.
Överväg fler noder när någon av dessa är sann:
Ett praktiskt första steg är ofta att separera arbetsbelastningar (två oberoende Redis‑instanser) innan du hoppar till ett kluster.
Sharding betyder att dela dina nycklar över flera Redis‑noder så varje nod bara lagrar en del av datan. Redis Cluster är Redis inbyggda sätt att göra detta automatiskt: keyspace delas in i slots och varje nod äger några av dem.
Vinsten är mer totalminne och högre genomströmning. Avvägningen är ökad komplexitet: multi‑key‑operationer blir begränsade (nycklar måste ligga på samma shard) och felsökning innebär fler rörliga delar.
Även med "jämn" sharding kan verklig trafik bli snedfördelad. En populär nyckel (en "hot key") kan överbelasta en nod medan andra står tomma.
Mitigeringar inkluderar korta TTL:er med jitter, dela upp värdet över flera nycklar (key hashing) eller omdesigna åtkomstmönster så läsningarna sprids.
Ett Redis Cluster kräver en cluster‑aware klient som kan upptäcka topologin, routa förfrågningar till rätt nod och följa omdirigeringar när slots flyttas.
Innan migration, kontrollera:
Skalning fungerar bäst när det är en planerad evolution: validera med load‑tester, instrumentera nyckellatens och migrera trafik gradvis istället för att slå över allt på en gång.
Redis behandlas ofta som "intern infrastruktur", vilket är just varför det är ett frekvent mål: en enda exponerad port kan leda till fullständig dataläckage eller en angriparstyrd cache. Anta att Redis är känslig infrastruktur, även om du bara lagrar "temporär" data.
Börja med att aktivera autentisering och använd ACLs (Redis 6+). ACLs låter dig:
Undvik att dela ett lösenord mellan alla komponenter. Utfärda istället per‑service‑uppgifter och håll behörigheterna snäva.
Det mest effektiva skyddet är att inte vara nåbar. Bind Redis till ett privat interface, placera det i ett privat subnet och begränsa inkommande trafik med security groups/firewalls till endast de tjänster som behöver det.
Använd TLS när Redis‑trafik korsar värdgränser du inte fullt ut kontrollerar (multi‑AZ, delade nätverk, Kubernetes‑noder eller hybridmiljöer). TLS förhindrar avlyssning och credential‑stöld, och är värt den lilla overheaden för sessionsdata, tokens eller annan användarrelaterad data.
Lås ner kommandon som kan orsaka stor skada om de missbrukas. Vanliga exempel att neka eller begränsa via ACLs: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG och EVAL (eller åtminstone kontrollera scripting noggrant). Använd rename‑command med försiktighet—ACLs är ofta tydligare och lättare att granska.
Spara Redis‑referenser i din secrets‑manager (inte i kod eller containerbilder), och planera för rotation. Rotation är enklast när klienter kan ladda om uppgifter utan redeploy, eller när du stödjer två giltiga credential under en övergångsperiod.
Om du vill ha en praktisk checklista, ha en i dina runbooks tillsammans med dina /blog/monitoring-troubleshooting-redis‑anteckningar.
Redis känns ofta "fint"… tills trafiken skiftar, minnet kryper upp eller ett långsamt kommando stoppar allt. En lättviktsövervakning och en tydlig incidentchecklista förhindrar de flesta överraskningar.
Börja med en liten uppsättning som alla kan förklara:
När något är "långsamt", bekräfta det med Redis egna verktyg:
KEYS, SMEMBERS eller stora LRANGE‑anrop är ett vanligt varningstecken.Om latens ökar medan CPU ser bra ut, överväg även nätverkssaturation, överstora nyttolaster eller blockerade klienter.
Planera för tillväxt genom att hålla headroom (vanligen 20–30% fritt minne) och ompröva antaganden efter lanseringar eller feature‑flags. Behandla "stabila evictions" som ett driftstopp, inte en varning.
Under en incident, kontrollera (i ordning): memory/evictions, latens, klientanslutningar, slowlog, replikationslagg och senaste deploys. Skriv ner återkommande orsaker och åtgärda dem permanent—larm räcker inte.
Om ditt team itererar snabbt kan det hjälpa att baka in dessa driftförväntningar i utvecklingsflödet. Till exempel kan Koder.ai:s planning mode och snapshots/rollback hjälpa dig att prototypa Redis‑funktioner (som caching eller rate limiting), testa dem under belastning och återställa ändringar säkert—samt behålla implementationen i din kodbas via källkodsexport.
Redis är bäst som ett delat, minnesbaserat “snabbt lager” för:
Använd din primära databas för hållbar, auktoritativ data och komplexa frågor. Behandla Redis som en accelerator och koordinator, inte som källan till sanning.
Nej. Redis kan persistenta data, men det är inte “hållbart som standard.” Om du behöver komplexa frågor, stark hållbarhet eller analys/rapportering ska datan stanna i din primära databas.
Om att förlora även några sekunder av data är oacceptabelt bör du inte anta att standardinställningar för persistence räcker utan noggrann konfiguration (eller överväg ett annat system för just den arbetsbelastningen).
Välj efter hur mycket dataförlust och återställningstid du kan acceptera:
Skriv ner era RPO/RTO‑mål först och justera persistence efter dem.
I cache‑aside äger din applikation logiken:
Det fungerar väl när din app tål sporadiska misses och du har en tydlig plan för utgång/invalidiering.
Välj TTL efter användarpåverkan och backend‑belastning:
user:v3:123) när formatet kan ändras.\n- Var tydlig med var föråldrad data är acceptabel (flöden) vs oacceptabelt (auth, lager).Om du är osäker: börja med kortare TTL, mät databaslast och justera sedan.
Använd en eller flera av dessa:
Dessa mönster förhindrar synkroniserade cache‑missar som överbelastar databasen.
Ett vanligt tillvägagångssätt är:
sess:{sessionId} med TTL som matchar sessionslivslängden.\n- Valfritt: user:sessions:{userId} som en Set med aktiva session‑ID:n för "logga ut överallt".\n- Lagra minimalt (ID:n och tidsstämplar), inte personuppgifter.Undvik att förlänga TTL vid varje förfrågan ("sliding expiration") om du inte kontrollerar det—exempelvis förläng bara när det är nära utgång.
Använd atomiska uppdateringar så räknare inte fastnar eller får race‑villkor:
INCR och EXPIRE som separata, oskyddade anrop.\n- Föredra en Lua‑script som inkrementerar och sätter expiry endast när nyckeln skapas.Scopea nycklarna klokt (per‑user, per‑IP, per‑route), och bestäm i förväg om ni ska fail‑open eller fail‑closed när Redis är otillgängligt—särskilt för känsliga endpoints som inloggning.
Välj efter hållbarhet och driftbehov:
LPUSH/BRPOP): enkla, men du måste bygga retry, in‑flight‑tracking och timeouts själv.\n- Sorted sets: utmärkta för fördröjda jobb och prioritering (score som tidsstämpel/prioritet).\n- Streams: ofta bäst för arbetsfördelning—consumer groups, ack:ar, pending messages och återhämtning efter krascher.Håll nyttolasten liten; lagra stora binärer någon annanstans och skicka referenser.
Använd Pub/Sub för snabba realtids‑broadcasts där det är accepterat att missa meddelanden (presence, live‑dashboards). Pub/Sub har:
Om varje event måste bearbetas, välj Redis Streams för hållbarhet, consumer groups, retries och backpressure. För driftshälsa: lås också ner Redis med ACLs/nätverksisolering och övervaka latency/evictions; ha en runbook som .
/blog/monitoring-troubleshooting-redis